
基于CNN的高光谱和多光谱图像融合方法研究
2022-12-14 08:36杨海涛
兵器装备工程学报 2022年11期
齐 济,杨海涛,孔 卓
(1.航天工程大学 研究生院, 北京 101400; 2.航天工程大学 航天信息学院, 北京 101400)
1 引言
高光谱图像的波段数通常具有数百个甚至更多,相对于多光谱图像而言,光谱特征丰富,可用于军事监测、农业、地理信息监测和天气预报等多个遥感领域[1]。在应用遥感图像时,通常需要高空间分辨率的高光谱图像,但并不能被单源传感器直接获得。在空间域和光谱域上,低空间分辨率高光谱图像与高空间分辨率多光谱图像具有一定的互补性[2],将两者用图像融合的技术结合,在很大程度上,能提升高光谱图像的空间分辨率,提高其实际应用价值[3]。
近年来,在高光谱和多光谱图像融合领域,传统方法和深度学习的方法被广泛应用。Shen等[4]提出了一种二次优化网络,并结合了矩阵分解进行图像优化,是将传统方法和深度学习方法作了结合。Hu等[5]设计了一种基于变压器的网络,用于融合低分辨率高光谱图像和高分辨率多光谱图像。Qu等[6]为了实现高光谱图像超分辨率,提出了一个无监督的稀疏Dirichler-Net框架。Wang等[7]进行多光谱和高光谱图像融合时应用深度注意力网络,可以将高光谱图像的细节信息更好地提取。Liu等[8]提出了一种双分支卷积神经网络(ResTFNET)来解决多光谱图像的泛锐化问题,本文中参考这一泛锐化的方法,并引申到高光谱的图像融合研究中。Han等[9]为了将高光谱图像的超分辨率问题解决,提出了一种深度卷积神经网络(ConSSFCNN)。Yuan等[10]基于深度CNN,引入多尺度特征提取(MSDCNN)进行遥感图像的处理。Zhang等[11]提出了一种基于CNN的空间光谱信息重构网络(SSR-NET),以提高融合高光谱图像的空间分辨率。此网络的损失函数可以很好地计算到空间边缘以及光谱边缘的信息,但是由于高光谱图像进行上采样的操作有一定的不精确性,相对于多光谱图像而言,这样处理后的高光谱图像的很多高频边缘纹理会丢失,直接的跨通道融合会产生结构性的问题[12]。
本文中结合文献[8,11]提出一种新的卷积神经网络结构。首先,将SSR-NET的第一步跨通道串联图像的像素级插值算法部分替换成文献[8]的双分支卷积神经网络结构,用深度学习的方法代替矩阵间计算的方法进行特征提取,可提取到细节更丰富的图像;然后,对提取到的特征进行融合;其次,通过图像重建网络,提取第二步融合图像中的高空间分辨率的高光谱图像;最后再对其进行空间边缘和光谱边缘的重构,得到最终的高空间分辨率的高光谱图像。
2 相关研究工作
2.1 图像预处理及数据集
预处理工作包含下采样、插值、滤波、整形、降维等步骤。融合图像的质量评估通常采用Wald的协议[13-14]。本文中的研究重点是低分辨率的高光谱图像与高分辨率的多光谱图像之间的融合,实验所用数据集采用目前已公开的数据集:Botswana和Indian Pines(IP)。Botswana数据集总共有波段数242个,在将未校准和有噪声的吸水特征波段去除后,保留剩余的145个波段,每个波段的图像为1 476×256像素,空间分辨率为30 m。IP数据集有波段数224个。在将覆盖水吸收区域的波段去除后,还剩下220个波段,每个波段的图像为145×145像素[15]。
参考的高光谱图像为原始的高光谱图像数据集,经实验估计的高光谱图像表示为Z∈RH×W×L,H和W表示高和宽的尺寸,L表示光谱带的数量。输入的高光谱图像表示为X∈Rh×w×L,多光谱图像表示为Y∈RH×W×l。X和Y通过文献[11]采用的方法在空间和光谱模式下进行下采样。
X=Gaussian(Z)
(1)
X=Bilinear(X,1/r)
(2)
Y(k)=Z(sk),k∈{1,…,l}
(3)
sk=(k-1)*L/(l-1),sk∈{s1,…,sl}
(4)
其中,X通过Z经高斯滤波器进行预先模糊后以r的比率进行下采样得到。Y以相等的波段间隔从Z采样,Y(k)表示Y的第k个波段。s1,…,sl表示高光谱图像中光谱取样的编号。
2.2 客观评价指标
本文中采用的4个客观评价指标分别为:均方根误差(root-mean-squared error,RMSE)、峰值信噪比(peak signal-to-noise ratio,PSNR)、相对无量纲全局误差(erreur relative globaleadimensionnelle de synthèse,ERGAS)以及光谱角映射(spectral angle mapper,SAM)。
2.3 损失函数
本文中采用的空间边缘损失函数和光谱边缘损失函数均采用文献[11]提出的损失函数。
2.3.1空间边缘损失
由于卷积神经网络的黑盒特性,学习特征映射是不可控的。众所周知,图像的空间边缘含有高频特征,这对于空间重建至关重要。为了使空间重构网络聚焦于空间信息的恢复,应用基于空间边缘的空间边缘损失算法。
用lspat表示,其公式为:
(5)
(6)
lspat=0.5*lspat1+0.5*lspat2
(7)
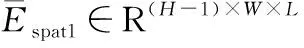
2.3.2光谱边缘损失
在空间重构后,利用一个与空间重构相同结构的卷积层进一步重构光谱信息。类似于空间边缘,频带的频谱边缘包含了对频谱重建至关重要的高频信息。为了着重于光谱信息的恢复,应用基于光谱边缘的空间边缘损失算法。
用lspec表示,其公式如下:
Espec(i,j,k)=Zspec(i,j,k+1)-Zspec(i,j,k)
(8)
(9)
(10)
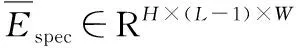
对于最终估计的高光谱图像Zfus,它的损失函数为:
(11)
最终总损失函数l为:
l=lspat+lspec+lfus
(12)
3 基于CNN的图像融合算法流程
深度学习方法的网络可以对多光谱图像中的空间信息和高光谱图像中的光谱信息综合利用,在物理上直观地获得了最佳的融合质量。神经网络的结构对CNN的性能发挥起着至关重要的作用。
LIM等[16]提出:由于不同于其他图像处理任务,进行图像融合时,批量归一化层(batch normal,BN)会破坏数字图像的对比度等信息,改变图像的色彩分布特征。因此在本文中去掉双分支卷积神经网络中残差单元的BN层,同时为了使融合后输入分量不变,本文中还将双分支卷积神经网络中的所有PRelu层删除。
模型总体结构如图1所示。输入的高光谱图像和多光谱图像在经历双分支卷积神经网络提取特征后进行特征融合以及图像重建得到初步的高分辨率高光谱图像Zpre,之后将其空间信息和光谱信息进行重构,得到最后的高分辨率高光谱图像。
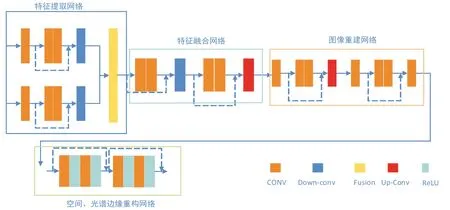
图1 模型总体结构示意图
3.1 基于双分支卷积神经网络的图像融合规则
3.1.1特征提取融合网络
在开始阶段,我们使用2个分支分别从HSI和MSI中提取特征信息。2个分支结构相似,每个分支由3层卷积和一层下采样组成。大部分CNN结构使用最大或平均池来获得尺度和旋转不变特征,但细节信息的提取更为重要,本文中采用步长为2的卷积核进行图像的下采样,而不是用简单的池化操作实现。CNN结构中,残差块的改进如图2和图3所示。
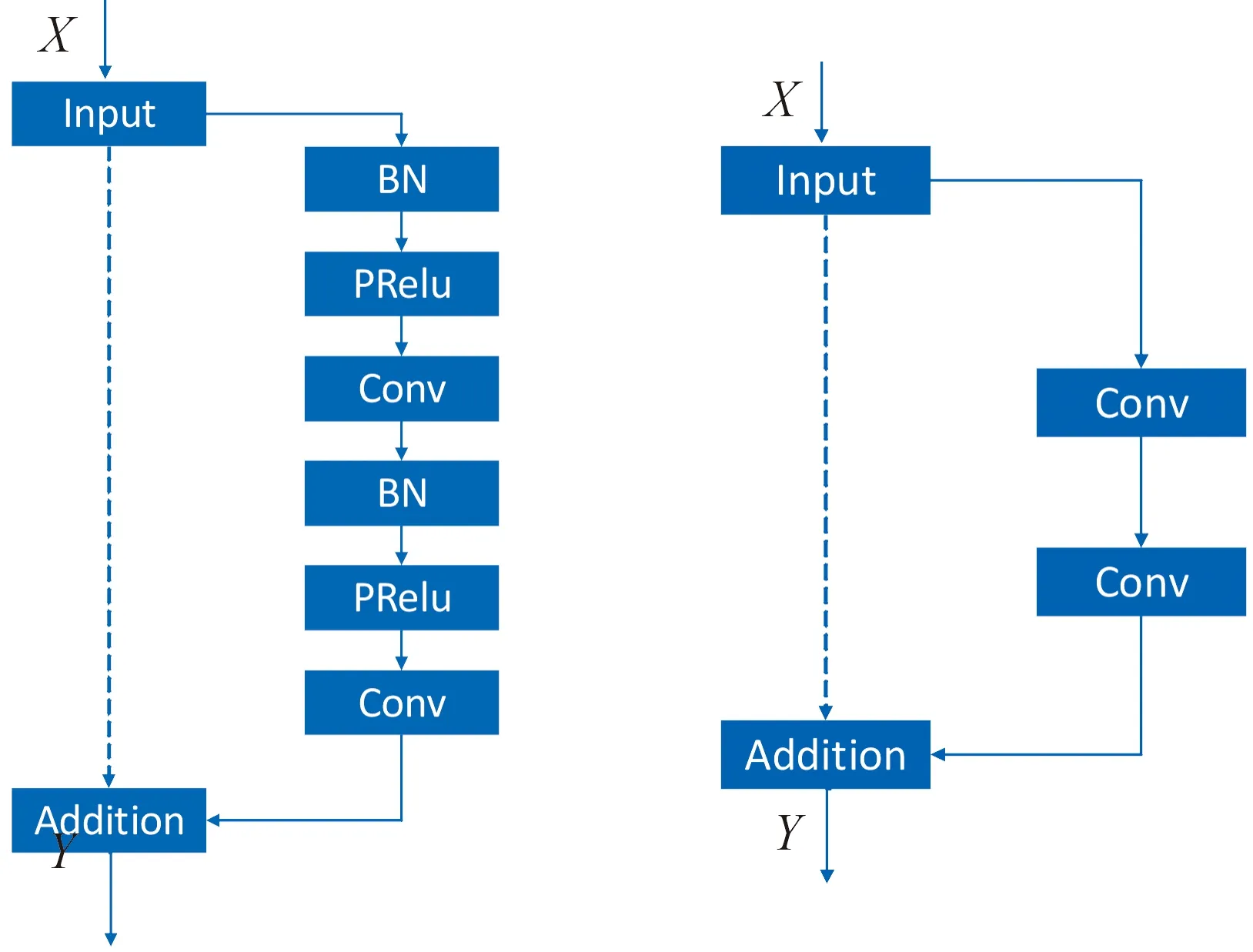
在经历特征提取步骤后,我们得到了高光谱图像和多光谱图像的特征图,介于目标高光谱图像要具有高空间以及高光谱分辨率,光谱信息和空间信息必须被特征同时捕捉到,基于此,将2个特征图拼接到一起。融合网络结构由4层卷积、一层下采样和一层上采样构成,它融合了2个输入图像的空间和光谱信息,通过CNN网络将级联的特征映射编码成更紧凑的表示,特征提取融合部分的网络结构如图4所示。其中,CONV表示卷积层,Down-conv表示下采样卷积层;Fusion表示将从输入图像提取到的特征进行融合。其中,Up-Conv表示上采样卷积层,残差网络使用图2所示的改进的网络结构。
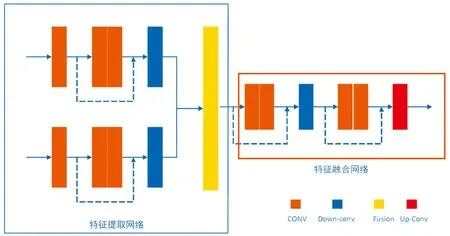
图4 特征提取融合网络结构示意图
3.1.2图像重建网络
图像重建网络是在前面已融合的特征中重建所需要的高空间分辨率的高光谱图像,图像的空间分辨率应采用逐步上采样的步骤以防止高频信息的丢失,重建得到的图像记为Zpre。特征提取网络和特征融合网络的作用相当于编码过程,而图像重建网络相当于解码的过程,从高层特征中恢复细节纹理是困难的,因为高层特征映射对图像的语义和抽象信息进行了编码。为了恢复精细和真实的细节,将所有层次的特征表示出来,仍采用图2所示的改进残差网络结构,以加强模型训练的稳定性以及恢复更多的细节信息。具体结构如图5所示。

图5 图像重建网络结构示意图
3.2 空间、光谱边缘信息重建网络
在经过前一节的3个步骤处理后,为了从Zpre中重构空间信息,采用两层卷积核为3×3的网络结构,表示为:
Zspat=Zpre+Convspat(Zpre)
(17)
式中:Convspat表示卷积层。跳过连接(skip-connection)操作用于在训练阶段提高模型的稳定性。
在空间重构后,仍使用与空间信息结构相同的卷积层作为光谱信息重构的计算。其表述如下:
Zspec=Zspat+Convspec(Zspat)
(18)
式中:Convspec(Zspat)表示卷积层,也用到了跳过连接操作。网络结构如图6所示。
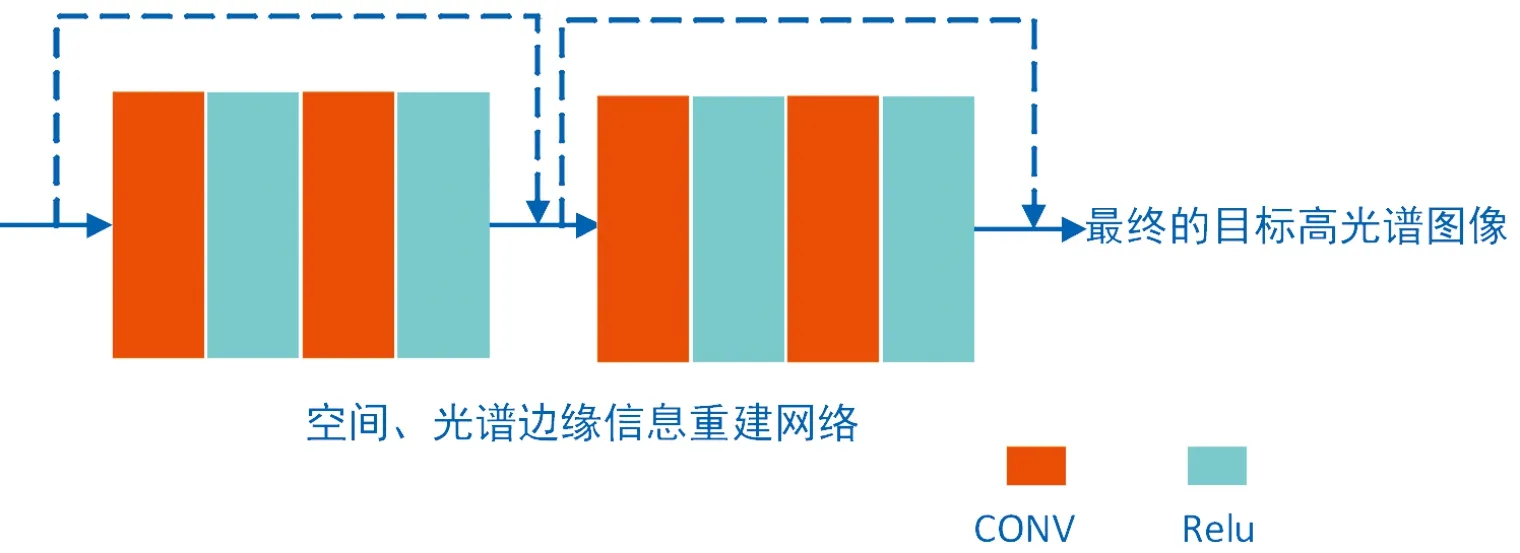
图6 空间、光谱边缘信息重构网络结构示意图
如表1所示,汇总了在前面所述的各个阶段中,Bostwana数据集的网络卷积层数量、卷积核大小、步长以及输入和输出的维度大小。
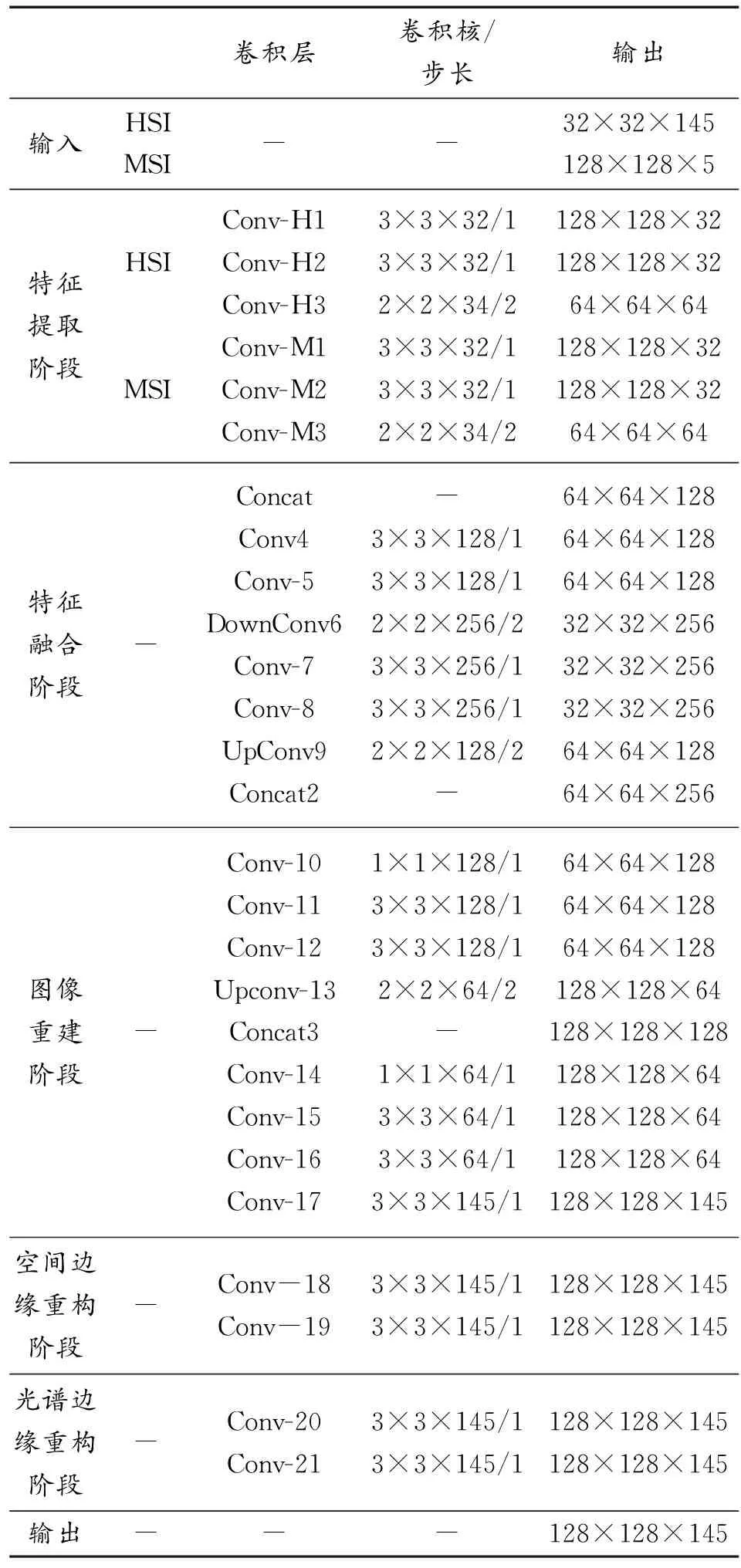
表1 Bostwana数据集中各个阶段的网络卷积层数量、卷积核大小、步长以及输入和输出的维度大小
4 实验结果及分析
对于Bostwana数据集,在每次迭代中,将中心128×128子区域裁剪,作为实验的测试图像,其余区域用于训练。在每次迭代中,从训练区域随机裁剪具有相同空间分辨率128×128的训练图像。训练和测试区域是不重叠的,这是通过在训练阶段用数据集中的零填充测试区域来实现的,对于IP数据集,因其受限的空间分辨率,在每次迭代中,将中心64×64子区域裁剪,作为实验的测试图像,其余区域作为训练图像。在每次迭代中,从训练区域随机裁剪具有相同空间分辨率64×64的训练图像,具体做法如图7所示。选择ConSSFCNN和MSDCNN以及SSR-NET三种深度学习方法作为比较方法来评估所提出方法的性能训练阶段迭代轮数为10 000,学习率为0.000 1,优化器为Adam优化器。本文中所有基于深度学习的实验都是在Python 3.9上用Pytorch 1.9.0实现的,计算机硬件设备参数为GeForce RTX 3090,主频为4.0 GHz,内存为64 GB。

图7 数据集处理
4.1 主观评价
在Bostwana数据集中,像素的空间分辨率高达30 m,因此,其空间信息比其他数据集更复杂,具有更高的特征提取要求。本文中提出的CNN模型可以在初始阶段更好的提取图像的高频信息,有利于提取非线性深度特征以及空间重建。图8和图9中第一行所列的图像表示不同方法的融合结果,第二行表示融合结果与参考图像之间的差异。

图8 不同方法在Bostwana数据集上的融合结果图
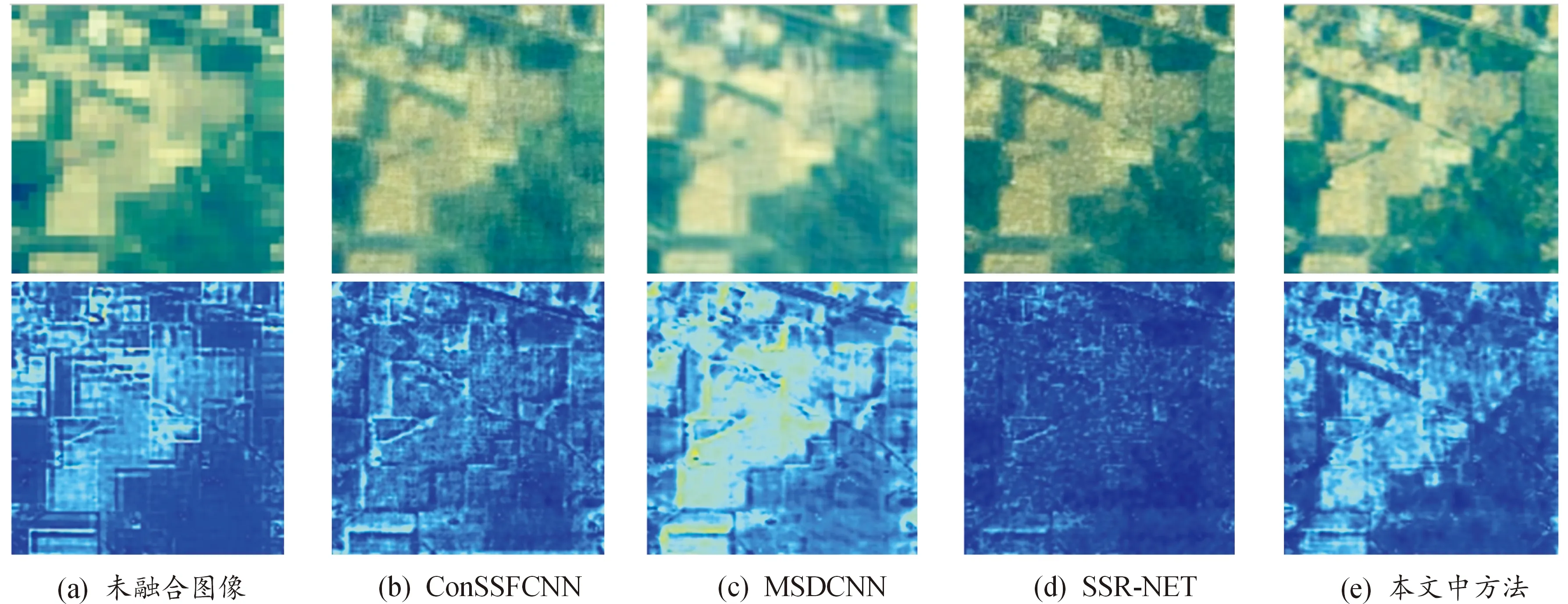
图9 不同方法在IP数据集上的融合结果图
由图8(e)可知,本文中提出算法的融合结果和参考图像相比差异更小,融合性能更好;由图8(b)可知,ConSSFCNN算法的效果并不理想,图像细节信息丢失严重;由图8(c)可知,MSDCNN算法融合结果和SSR-NET较为接近,但其对比度较差,部分纹理细节丢失。综上所述,本文中提出的融合模型融合效果最佳。
由图9(b)和图9(c)可知,在IP数据集中,ConSSFCNN模型和MSDCNN模型融合结果分辨率仍较差,图像细节信息丢失严重,图像边缘不清晰,场景信息模糊,且和参考图像相比差异较大;由图9(d)和图9(e)可知,虽然提出的方法在与参考图像对比度方面较SSR-NET模型差,但是SSR-NET模型融合结果图像整体偏暗,含有较差的对比度,本文中提出的方法得到的融合图像中,提取了相对完整的目标,含有清晰的图像纹理、适中的亮度以及较高的对比度,整体融合效果更好,更符合人类视觉的感知。因此,本文中提出的方法更适合。
4.2 客观评价
图10和图11根据2.2节所述的4项评价指标来对比本文中所提方法和其他方法的融合情况,其中图10采用的是数据集Bostwana,图11采用的是数据集IP。在四种客观评价指标中,PSNR是正向指标,数值越大说明失真越少图像越清晰,而其他3个指标RMSE值越小说明离散程度越好、ERGAS值越小表明融合质量越高、SAM值越小表示光谱失真越少,性能越好。
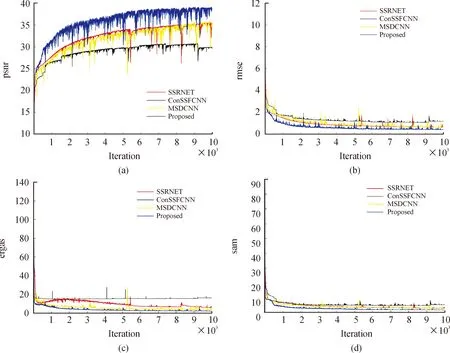
图10 不同方法在Bostwana数据集上的结果曲线
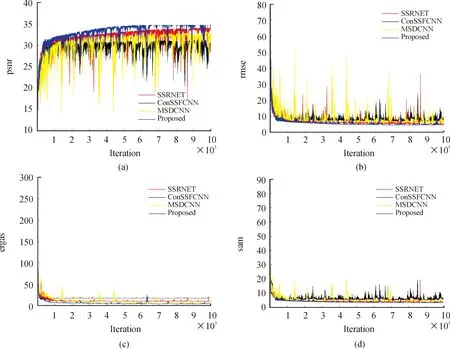
图11 不同方法在IP数据集上的结果曲线
由图10可知本文中提出的方法的PSNR和RMSE指标远高于其他3种算法,融合性能更好;在ERGAS和SAM指标方面,本文中提出的方法较其他3种算法相比,有着略微的优势。由图11可知,本文中提出的方法模型在PSNR、RMSE以及ERGAS评价指标中具有明显的性能优势,SAM指标则具有微弱的性能优势。
表2和表3所列的是在2种数据集上,不同方法评价指标的最优值。由表2可知,对于Bostwana数据集,本文中提出的方法在PSNR指标上,比SSR-NET以及MSDCNN方法高出3.5左右,比ConSSFCNN方法高出9左右,其性能在PSNR方面具有非常大的优势;本文中提出的方法在RMSE指标上,和其他3种方法相比,优势不明显,但也有略微提升;在ERGAS指标上,本文中提出的方法较ConSSFCNN而言,大约提升了13,具有良好的性能优势,和SSR-NET以及MSDCNN方法相比也是有一定的提升;在SAM指标方面,本文中方法较其他3种方法均有一定的提升。
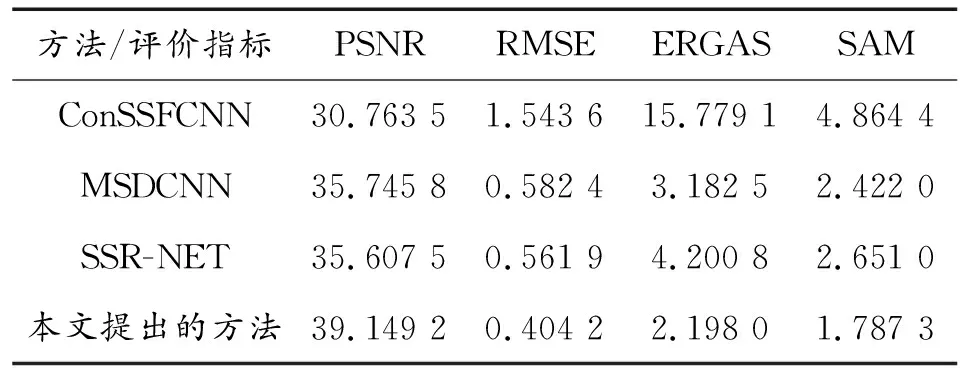
表2 不同方法在Bostwana数据集上的最优值(最优值用粗体标出)Table 2 Optimal values of different methods on the Bostwanadataset(Optimal values are marked in bold)
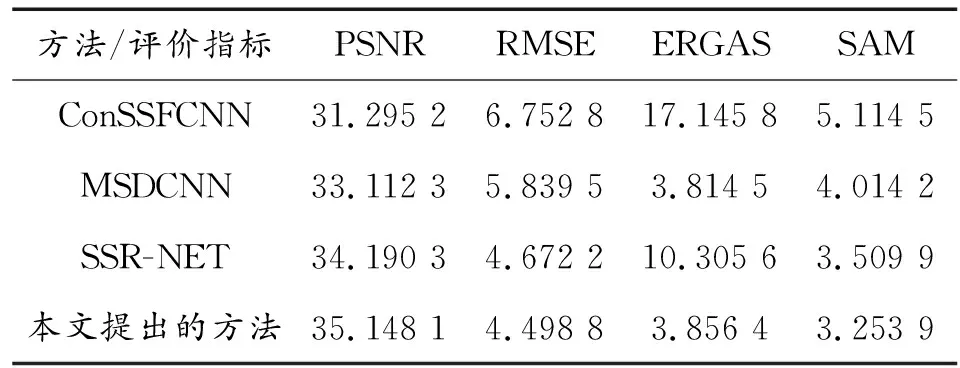
表3 不同方法在IP数据集上的最优值(最优值用粗体标出)Table 3 Optimal values of different methods on the IP dataset(Optimal values are marked in bold)
由表3可知,在IP数据集上,本文中提出的方法在PSNR指标方面,比SSR-NET提升了1左右,比MSDCNN提升了2左右,比ConSSFCNN提升了4左右;在RMSE指标方面,较SSR-NET而言,提升仅有0.2左右,较MSDCNN提升了1.4左右,较ConSSFCNN提升了2.3左右;在ERGAS方面,本文中方法较SSR-NET和ConSSFCNN而言提升较大,但稍落后于MSDCNN方法,原因是因为ERGAS度量的是全局误差,而本文中改进的方法继续采用了SSR-NET的损失函数,此损失函数计算空间、光谱的边缘特征,忽略了全局特征;在SAM指标方面,本文中提出的方法均具有不同程度的性能提升。
5 结论
提出一种基于CNN的高光谱和多光谱图像融合方法。将初始图像信息整合从图像域转化到特征域,可以更好地对图像高频信息进行提取,防止丢失细节信息;在进行空间信息和光谱信息重构时,将卷积层增加至四层,图像的更深层次特征可以由更深层次的网络结构提取到,具有更多的非线性特征,增强了网络的判别能力。并没有采用更深层的网络,避免了过深的网络产生的过拟合。实验结果表明,本文中提出的方法较SSR-NET、MSDCNN、ConSSFCNN等方法而言,具有更优越的性能。后续将进一步对图像融合耗时和模型结构等问题进行改进,以将更好的图像融合效果所达到。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
通信产业报(2016年44期)2017-03-13
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
雕塑(1999年2期)1999-06-28
