
基于并行反向注意网络的跑道线检测
2022-12-16 14:01白俊卿张文静
中国惯性技术学报 2022年5期
白俊卿,张文静
(西安石油大学,西安 710065)
随着无人机广泛应用于军民领域,基于视觉的无人机自主着陆成为学者研究的热点[1]。无人机着陆的关键在于准确地检测出着陆跑道线。李洪等[2]提出一种基于线特征的无人机自主着陆方法。该方法根据检测到的跑道左右边线与中线建立了基于线特征的视觉相对测量模型,通过解算无人机相对于机场的相对位置,引导无人机安全着陆。V1adimir T 等[3]根据对跑道线的持续追踪得到位姿信息,首先是减小图像的处理区域,其次采用Hough 变换[4]识别跑道线,最后使用灭影线的算法估算位姿,实现其自主着陆。梅立春等[5]设计了一种基于轮廓角点快速检测算法,首先使用了Suzuki-Abe 算法获取的背景全局轮廓特征,然后通过改进Douglas-Peucker 精准检测角点[6],此算法在着陆标识不清楚的情况下检测效果较好。程国建等[7]设计了一种带有注意力机制的神经网络算法实现无人机跑道线检测,使用通道混洗模块缓解了特征融合中计算量的占用问题,并引入空洞空间金字塔池化注意力机制获取更多的图像信息。
上述方法中一部分存在着陆场景单一问题,模型的泛化能力较弱。一部分计算量大并且对于远距离的小目标检测性能较差。因此本文基于Res2Net 结构并融合反注意力机制模块、通道特征金字塔模块以及并行解码器模块设计了一种用于较远距离的着陆跑道线的检测方法。
1 FLine-Net 网络与检测算法
1.1 FLine-Net 网络架构
本文网络结构FLine-Net 采用主干网络Res2Net结构提取特征,并采用并行融合编码器获得跑道线的大致轮廓。此外,融合通道特征金字塔和轴向反向注意力机制获取更加准确的特征信息。网络结构如图1所示。

图1 FLine-Net 网络结构Fig.1 FLine-Net network structure
1.2 主干网络
为了提高网络提取特征能力,获取更细粒度的多个感受野。本文选择采用Res2Net(图2 右)作为主干网络。Res2Net 结构在保持卷积核大小和总数不变的情况下,对所有卷积核进行分组,并以一种分层的独立块内类残差连接方式将不同的卷积核分支连接,表现出较强的多尺度表示能力。与ResNet[8]相比,使用Res2Net 的运算量比例为:

图2 ResNet 残差块和改进Res2Net 残差块Fig.2 ResNet residual blocks and improved Res2Net residual blocks
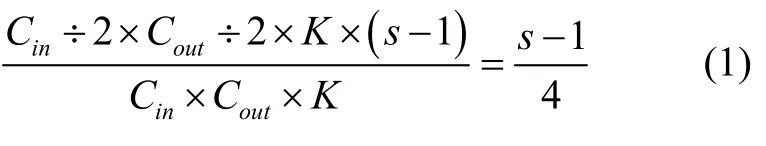
其中Cin为输入通道数,Cout为输出通道数,卷积核大小为K,s=4。
1.3 并行融合解码器
目前先进的深度神经网络基本依赖聚合编码器的多级特征,例如UNet、UNet++等模型是从编码器中提取所有级别特征[9,10]。相比于高级特征,低级特征对性能的贡献较小[11],因为高级特征有更大的空间分辨率而具有更高的计算成本,所以引入如图3 所示的并行解码器(Fusion Decoder,FD)可以聚合来自Res2Net 的高级特征{feature1、feature3、feature4、feature5},得到一个全局特征信息图。

图3 并行融合解码器Fig.3 Parallel fusion decoder
1.4 通道特征金字塔模块(CFP)
特征金字塔(Feature Pyramid,FP)[12]因其能表示多尺度特征,广泛应用于计算机视觉任务的深度学习模型中。虽然基于FP 的方法提高了检测性能但需要使用大量的参数,消耗更多的计算资源。此外本文算法将应用到资源有限的无人机平台上完成跑道线检测,所以引入一个轻量级的通道特征金字塔(Channel feature pyramid,CFP)模块。
CFP 模块的结构如图4 所示,首先本文使用1×1 卷积将高维特征映射到低维,得到四个FP 通道。并将四个通道设置为具有不同膨胀速率的平行结构。然后采用和运算逐步结合特征映射,将所有的通道连接到输入维度中,最后使用一个1 ×1 的卷积来激活输出。CFP 模块这种基于多尺度特征映射和分解的思想不仅大大减少了计算量,同时允许模块从多个大小不同的接受域中学习特征。
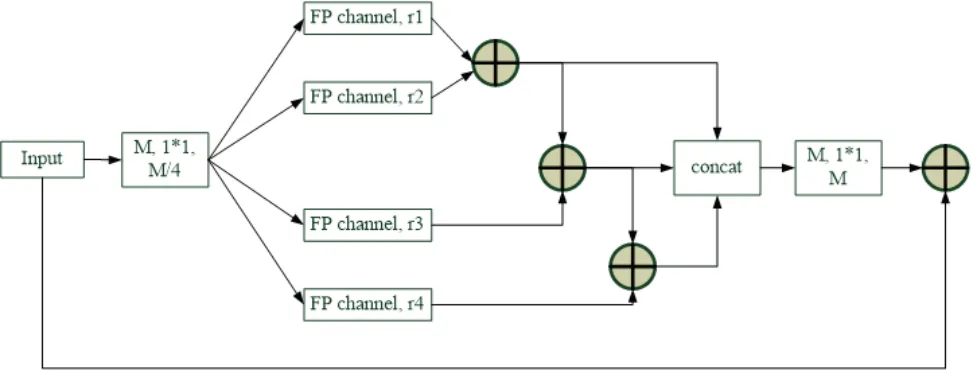
图4 CFP 模块Fig.4 CFP module
1.5 轴向反向注意力模块
并行连接解码器生成的全局特征信息图可以大致定位目标的位置,通道特征金字塔模块仅从预训练模型中提取多尺度特征。为了获得更准确、更为细节的特征信息,引入了轴向反向注意力机制模块(Axial Contrary Attention Mechanism Module,A-CA)来分析跑道线定位信息和多尺度特征。A-CA 模块的输入来自于两个方面,一个是来自通道特征金字塔模块的多尺度特征图,使用轴向注意力机制[13]来分析显著性信息,结构如图5 所示。

图5 轴向反向注意力机制模块图Fig.5 Axial reverse attention mechanism module diagram
轴向注意力基于自注意力机制(Self-attention),将一个两维注意力机制分解为两个一维注意力机制,一个在图像的高方向上定义轴向注意力层为一维的位置敏感自注意力,另一个在图像的宽方向上做类似的定义,结构示意图如图6 所示,轴向注意力将一个查询和一组键值对映射到一个输出,如式(2)所示:

图6 轴向注意力块Fig.6 Axial attention block

其中Q、K、V和dK分别表示查询、键、值和键的维度,由于当输入的空间维度很大时,self-attention会消耗大量的计算资源。轴向注意力将2D 注意力分解为沿高度和宽度轴的两个1D 注意力,可以将计算的复杂度降低。
A-CA 的第二个输入来自主干网络输出特征图反向处理的结果,对其使用反向操作检测,得到A-CA模块的输出,反向操作如式(3)所示:
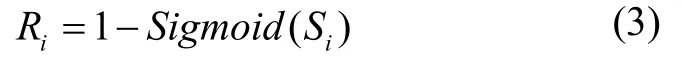
总的轴向反向注意力操作为式(4)所示:

其中⊗是逐元素乘法,AAi是轴向注意力路径的特征。
1.6 损失函数
跑道线检测从单个像素的角度看,是从场景图中分割出跑道线部分,其余都是背景,这是一个二分类问题。分析图像数据得知检测目标所占图像的比例比背景小很多。并且训练样本时像素类别极其不平衡导致了网络在训练学习中学到更多的背景特征,从而降低了检测的准确度。所以针对此问题,引入改进的二元交叉熵损失函数[14],分别给跑道线和背景相应的Loss 部分加上不同的权重,公式如式(5)。

式中,α表示跑道线的权重值,β表示背景的权重值。为了使网络学习到更多的跑道线特征,将α值相较于β值设置大一些,其中α,β∊(0,1)。本文令α=0.75,β=0.25。
虽然加权二元交叉熵损失函数使得网络更加关注跑道线的特征,但是只考虑单像素分类问题,没有考虑全局信息,导致检测到的跑道线边界相对模糊,与真实标注有较大差异。针对上述问题,我们采用加权交叉联合[15](Intersection over Union,IoU)。该方法在标准的IoU 基础上,增加了硬像素的权重,来突显跑道线像素点的重要性。
同时为了训练FLine-Net 网络,我们对三个分支的输出S1,S2,S3及全局地图S都上采样到与ground truth(G)相同的大小。总体的损失函数如式(6)所示。
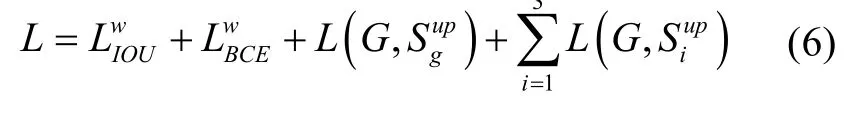
1.7 跑道线检测
无人机跑道线检测具体流程图如图7 所示,在训练过程中将验证集上的平均像素精度与保存的最佳模型做对比,如果连续三次大于模型训练前设置的平均像素精度阈值,或者达到最大迭代次数,则停止网络训练。经过对比分析,可以优化模型训练时间,提高算法的准确度,防止过拟合。

图7 检测流程图Fig.7 Inspection flowchart
2 试验与结果分析
2.1 试验环境
本文的建模是由深度学习算法和传统算法共同完成。采用Pytorch 框架,所用的CPU 是Inter Core I7-1070Ti,GPU 是NVIDIA GeForce GTX1070Ti,采用CUDA 10.1、CUDNN 并结合Python 语言实现算法内容。
2.2 评价指标
跑道线数据集的分割效果评价指标采用平均像素精度(Mean Pixel Accuracy,MPA)和平均交并比(Mean Intersection over Union,MIoU)。若MIoU 和MPA 的值越高,则表示图像语义分割的效果越好。MIoU 和MPA 的计算过程分别如式(7)和(8)所示。

设置数据集中存在g+1 个类,其中,真实类别i但预测结果j的像素数量表示为Pij,
2.3 试验结果对比分析
使用Unity3D 依据不同场景、不同环境对无人机着陆过程进行仿真,采集无人机飞行过程中每一帧图像作为图像数据集。使用Labelme 工具对9000 张图像数据集进行标注。通过增加高斯噪声、翻转以及旋转增加小目标的数据量。训练的迭代次数为300,批处量大小为8,基础学习率初始为0.0001,其中动量和权重衰减分别配置0.9 和0.0005。训练过程中优化器选用Adam,训练损失和验证损失值均采用加权交叉联合和加权二元交叉熵的损失之和,训练完成后损失值收敛到0.058148,验证误差收敛到0.1427705。图8为FLine-Net 网络模型在跑道线数据集下的训练误差和验证误差变化图。

图8 训练误差和验证误差变化图Fig.8 Variation of training error and validation error
从图8 可以观察到训练迭代到280 次左右曲线处于平稳且无明显震荡,训练集的损失平稳到0.05左右,验证集的损失值稳定在0.03 左右,模型基本收敛。
为了验证FLine-Net 网络的有效性,本文分别从ResNet 网络、Res2Net 网络、并行解码器(PD)、轴向反向注意力机制(A-CA)以及通道特征金字塔(CFP)五个方向进行对比实验,结果如表1 所示。Lab0、Lab1、Lab2 表明,通过采用并行解码器、轴向反向注意力机制在不同程度上提高了跑道线检测准确率,其中同时结合两个模块的网络检测准确率提高了9%左右,主要因为并行解码器融合了低层特征和高层特征从而降低了特征的损失程度,A-CA 模块更加关注图像中的细粒度特征,从而更加准确地判断背景与跑道线的信息。Lab2、Lab3、Lab4 表明,通过使用通道特征金字塔可以提取到多尺度的信息,并结合三层注意力机制划分细节信息,其准确率达到90.9%。Lab4、Lab5、Lab6、Lab7、Lab8 表明,使用Res2Net结构之后,不仅参数量减少了,同时主干网络提取到了更多信息,对加入的其他模块产生积极的效应,总体效果比ResNet 做主干网络提高了5%左右。

表1 不同模块对模型的影响Tab.1 The impact of different modules on the model
分析表2 可知,FLine-Net 模型复杂度没有大幅度提高,检测速度与 UNet、UNet++相差不大,比ResUNet++快了大约0.5 倍,平均像素精度比其他三种模型高,且比UNet 算法、UNet++算法的平均检测像素精度分别提高了16.7%和9.5%。

表2 四种模型进行跑道线检测的综合性能对比Tab.2 Four models perform comprehensive performance comparisons for runway line detection
FLine-Net对小目标的检测结果如图9所示,图9(a)为原始的跑道线图像,图9(b)为真实的标签值,图9(c)为模型检测的二值图像。FLine-Net 模型的分割结果将每个像素点划分为两大类,分别为跑道线类和背景类。

图9 着陆跑道线小区域检测结果示例Fig.9 Example of a small area of the landing runway line
图10 显示FLine-Net 和Line-Net[7]对远距离跑道线图像(图像中跑道线的比例<7%)的检测性能对比。其中,x轴为图像中跑道线的比例大小,y轴是Line-Net和FLine-Net 的平均检测精度。从图中可以看出,当跑道线比例在6%以下时,两个模型的平均检测精度都随着跑道线的比例增加而提高,但是FLine-Net 模型比Line-Net 模型检测小目标对象性能相对好一点,主要因为FLine-Net 结合了反向注意力机制和通道特征金字塔模块,获取到的图像细节信息和后期定位信息比较全面,进而提高了对远距离跑道线图像的检测性能。
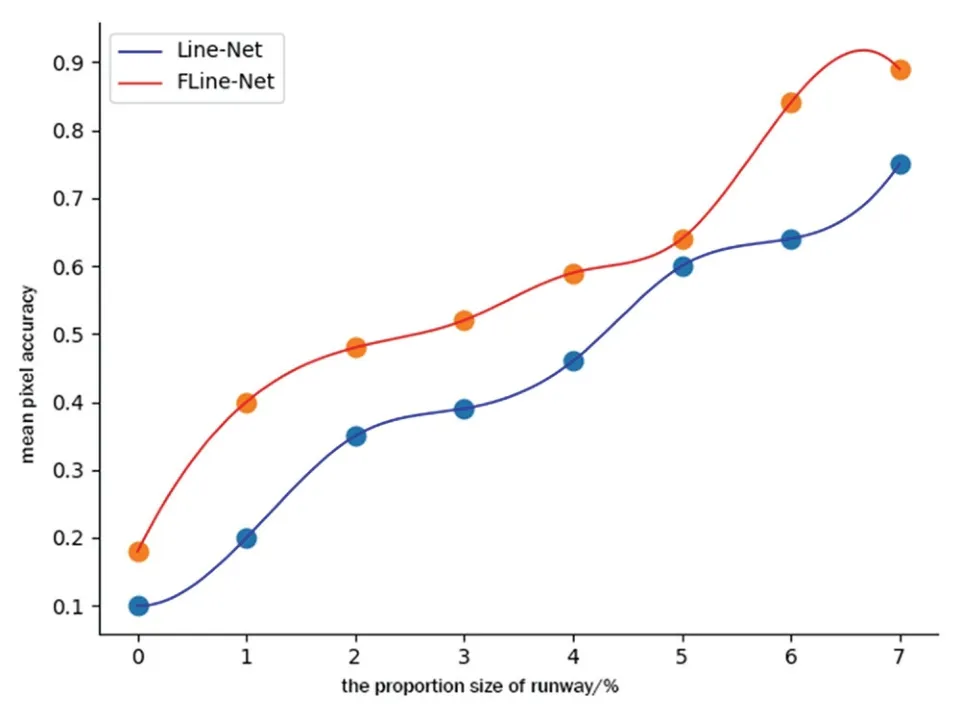
图10 远距离目标的检测精度对比Fig.10 Comparison of detection accuracy of long-distance targets
3 结论
本文主要研究在远距离下跑道线检测难的问题,提出了基于无人机视觉的着陆跑道线检测算法FLine-Net。采用了并行融合编码器将特征聚集到高级层中,从而获得粗范围的跑道线。采用轴向反向注意力模块更加关注到图像局部特征信息,增强特征的表示能力,最终的网络MIoU 达到86.3%,单帧处理时间25 ms,并与其他模型进行对比,本文模型具有较高的检测性能。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小雪花·成长指南(2022年1期)2022-04-09
水泵技术(2021年5期)2021-12-31
红领巾·萌芽(2019年8期)2019-08-27
制造技术与机床(2018年12期)2018-12-23
北京航空航天大学学报(2017年4期)2017-11-23
中国与非洲(法文版)(2017年10期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
CHIP新电脑(2016年3期)2016-03-10
