
改进YOLO v4-tiny的火焰实时检测*
2022-12-22 11:31王冠博赵一帆杨俊东丁洪伟
计算机工程与科学 2022年12期
王冠博,赵一帆,李 波,杨俊东,丁洪伟
(1.云南大学信息学院,云南 昆明 650504;2.云南民族大学电气信息工程学院,云南 昆明 650031)
1 引言
在现实生活中,火灾具有传播速度快、破坏性强等特点,严重威胁着自然环境和社会安全。因此,构建一个快速、有效的火焰识别系统具有重要的现实意义。
目标检测是计算机视觉领域的一项挑战性任务。近几年,得益于深度神经网络的发展及硬件计算能力的提升[1,2],目标检测取得了一系列重大突破,如SSD(Single Shot Multibox Detector)[3]、YOLO(You Only Look Once)[4-7]系列等算法在速度和精度二者之间达到了均衡,在实际中得到了广泛应用。YOLO v4-tiny是YOLO系列轻量级网络的最新改进,与YOLO v4相比,模型的参数量已大幅缩减,适合部署在移动设备上,但其计算量和准确度仍有改进的空间。
针对火焰实时检测的实时性需求,以及火焰特征复杂、火焰检测易受周围环境干扰的特点,为了能在算力有限的移动设备上部署更高效的目标检测模型,本文对YOLO v4-tiny进行了改进,在缩小模型尺寸的同时提升了模型的准确性与实时性。本文做的改进主要有以下3点:
(1)采用结构化修剪的方法对YOLO v4-tiny的卷积核进行了修剪。针对火焰图像噪声干扰较大、明暗度差别较大且火焰尺寸大小不一的特点,采用膨胀卷积扩大模型的感受野,并修改CSP(Cross Stage Partial connections)模块的部分卷积核尺寸,提出沙漏型CSP-ResNet结构;
(2)为使模型在网络浅层即可获取不同尺度的火焰特征,在模型的前端加入CSP-RFBs(Receptive Field Block)结构,增大模型的感受野,生成具有更高分辨率的特征;
(3)为了使模型能够检测不同尺度的火焰图像,在网络深层采用了改进型SPPs(Spatial Pyramid Pooling),对多重感受野进行进一步融合。
2 相关工作
2.1 基于深度卷积神经网络的目标检测方法
基于深度学习的目标检测依靠卷积和池化技术已达到优异性能,但其参数量和计算成本比较大,无法部署在移动平台上。现实中的目标检测任务(如自动驾驶)旨在有限的计算能力下达到最佳精度,这促使研究人员提出了一系列速度更快、精度更高的轻量级网络结构,主要包括Retinanet[8],Xception[9],MobileNetV1[10],MobileNetV2[11],MobileNetV3[12],ShuffleNet[13]和ShuffleNet V2[14]。
2.2 膨胀卷积
膨胀卷积首先出现在DeepLab[15]中,其通过稀疏式的卷积操作来生成具有更高分辨率的特征图,同时保持相同的参数量,无需增加计算成本即可捕获更大区域信息,已被广泛应用于语义分割任务中大规模上下文信息的合并[16]。这种设计也被一些目标检测器采用,如R-FCN(Region-based Fully Convolutional Network)[17]和DetNet(Deterministic Networking)[18],以提高检测速度和准确性。针对火焰图像场景复杂、噪声干扰较多且火焰形态不一等问题,若要进一步提升模型检测的准确率,需要扩大模型的感受野以获取更密集的特征。此外,采用膨胀卷积代替传统卷积,并不会对图像特征进行压缩,在处理单类别问题和较大尺度物体时,具有明显优势。
2.3 感受野
在卷积神经网络CNN(Convolutional Neural Network)中,感受野可决定某一层输出结果中一个元素对应的输入层的区域大小。在人体关键点检测、图像分割等领域,已有采用增大感受野的方法来提高模型性能的研究。Luo等[19]提出了有效感受野的概念,采用扩张卷积和逆高斯分布的权重初始化等方法,抵消感受野的高斯分布影响。Singh等[20]提出了HetConv,在大幅减少参数量的前提下扩大了感受野,同时保证了卷积操作的低延迟和准确性。
在目标检测领域,也可以通过增加感受野的方法来提高模型的特征提取能力,改善模型性能。感受野块RFB(Receptive Field Block)把人类视觉中的感受野机制引入目标检测,增加模型的感受野,增强了轻量级网络结构的特征表示。TridentNet[21]以ResNet-101为骨干网络,引入膨胀卷积层增加模型感受野,使模型可适用于多尺度特征提取。
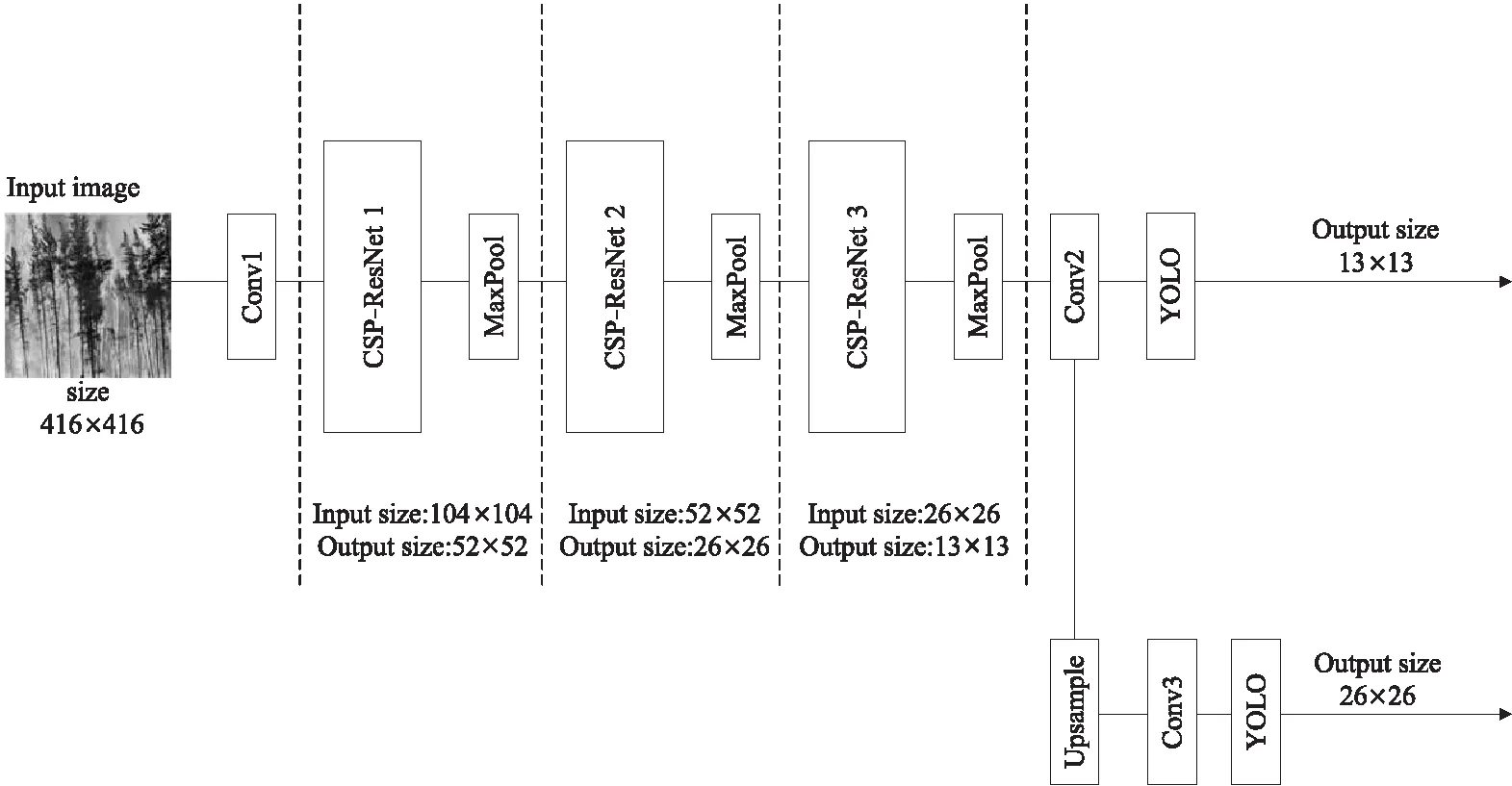
Figure 1 Structure of YOLO v4-tiny network
3 模型设计
3.1 YOLO v4-tiny网络结构
YOLO v4-tiny网络结构如图1所示。为了减少计算量,YOLO v4-tiny仅采用了3个级联的CSP-ResNet[21]模块,逐步输出具有更高分辨率的特征图。网络的检测层分别连接2种尺寸的YOLO层,分别对输出的特征图进行分类和定位,并未采用其它技巧来提升模型性能。
YOLO v4-tiny的模型中端采用3个CSP-ResNet(如图2所示)进行特征提取。CSP-ResNet将CSPNet与ResNet[22]进行有效结合,将梯度变化集成至特征图,可在减少计算量的同时保证模型的准确率。
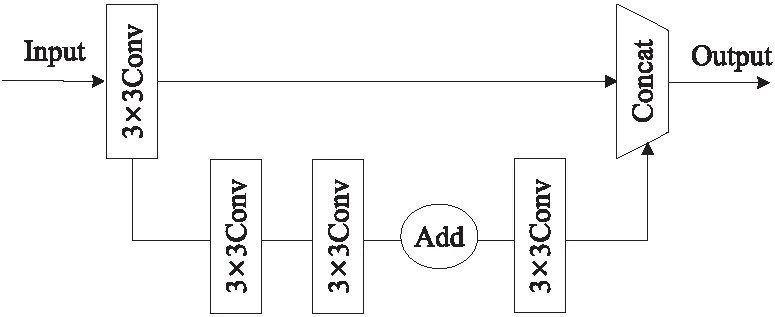
Figure 2 Structure of CSP-ResNet
与YOLO v3-tiny堆叠卷积层和池化层的方法不同,YOLO v4-tiny采用了3个残差模块来提取图像特征。YOLO v4-tiny网络深层采用了512的卷积滤波器,模型参数量较大,影响了模型的检测速度。此外,模型均采用3×3的卷积核,这就使得模型的感受野受限,不利于多尺度特征提取。
为了解决YOLO v4-tiny的问题,本文提出了改进型YOLO v4-tiny。改进型YOLO v4-tiny旨在在算力有限的移动设备上处理速度更快、准确率更高、性能更好。首先,本文减少了模型参数,并在模型中端的CSP-ResNet引入膨胀卷积,提出沙漏型CSP-ResNet结构。为了解决YOLO v4-tiny感受野有限的问题,在不大量增加额外计算参数的情况下,本文提出了改进型CSP-RFBs并将其应用于模型网络浅层,以获取具有更高分辨率的特征。此外,本文在网络深层采用了改进型CSP-SPPs,对多重感受野进行进一步融合。图3为改进后的YOLO v4-tiny结构图。
3.2 改进型YOLO v4-tiny的网络结构
3.2.1 模型参数修剪
本文主要采用调整卷积层滤波器数目的方法对YOLO v4-tiny进行修剪。由于模型剪枝不是本文的主要研究工作,因此采用了一种同时修剪多个卷积层滤波器数量的剪枝方案。
目前的模型修剪方法大多是在VGG(Visual Geometry Group)和ResNet等大型神经网络模型上进行的,而用于YOLO v4-tiny、MobileNet和ShuffleNet等的剪枝方法很少,其中一个主要原因是轻量级模型的冗余度明显低于重量级模型。
表1为模型参数修剪前后网络结构对比。本文主要对模型中卷积层的滤波器数量进行了修剪。对于具有修剪弹性的层,这种修剪方法可以去除网络中的重要部分,并且可以在短时间内通过重新训练来恢复准确性(小于原来的训练时间)。然而,当敏感层的一些过滤器被修剪或大部分网络被修剪时,可能无法恢复原来的准确性。本文的消融实验结果显示,修剪后模型的参数量仅为原始模型的32.9%,权重文件大小为原始模型的55.7%,但模型的准确率仅比原始模型下降了2.2%,这充分表明了本文采用的修剪方法的有效性。
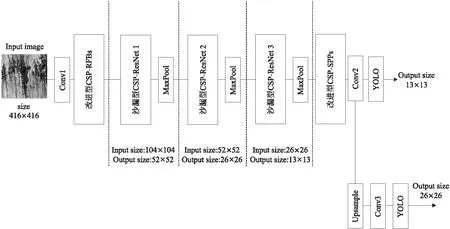
Figure 3 Structure of improved YOLO v4-tiny network proposed in this paper
3.2.2 改进骨干网络
为减少模型的计算量,本文对YOLO v4-tiny卷积滤波器数量进行了修剪,并将CSP-ResNet模块两端的卷积核尺寸改为1×1,其结构如图4b所示。这确实大幅度减少了模型的计算量,但带来了准确度损失,如表1 所示。为了在缩减参数的同时尽可能提高模型的准确性,受MobileNext中沙漏型残差瓶颈结构的启发,本文尝试将膨胀卷积层加入CSP-ResNet,提出沙漏型CSP-ResNet结构,如图4c所示。

Table 1 Comparison of network structures before and after model pruning

Figure 4 Structure of CSP-ResNet before and after pruning
图4a为YOLO v4-tiny中CSP-ResNet的原始结构,包括由b层3×3卷积核组成的基础层、b/2层3×3卷积核组成的ResNet、b层1×1卷积核组成的过渡层。图4b为修剪参数后的CSP-ResNet层,对模型的参数进行了大量修剪,基础层3×3的卷积核修改为1×1卷积核,模型的整体结构与图4a的保持一致。图4c为本文提出的沙漏型CSP-ResNet,在图4b基础上,在基础层和过渡层中加入了膨胀卷积层。
膨胀卷积最初来自DeepLab[15],可在保持参数量和相同卷积核尺寸的情况下获取更高分辨率的特征。
膨胀卷积既带有常规卷积层的卷积滤波功能,也具有池化层的泛化作用。此外,膨胀卷积不会随着步长Stride的增加而减小特征图尺寸。膨胀卷积支持指数级拓展的感受野,在模型中采用膨胀卷积的操作不会丢失分辨率和覆盖范围。膨胀卷积的平面计算层如图5所示。感受野的尺寸呈指数增长,模型的参数量则为线性增长。
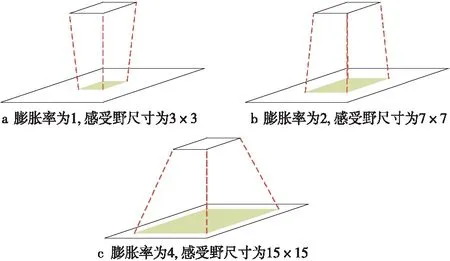
Figure 5 Planar computational layers of the 3×3 convolution kernel at different expansion rates
膨胀卷积可扩大模型的感受野,以获取更高分辨率的特征图。将膨胀卷积应用于CSP-ResNet的基础层和跨阶段连接层,可以极小的计算代价拓宽CSP-ResNet感受野,缓解梯度混淆的问题,进而提升模型性能。
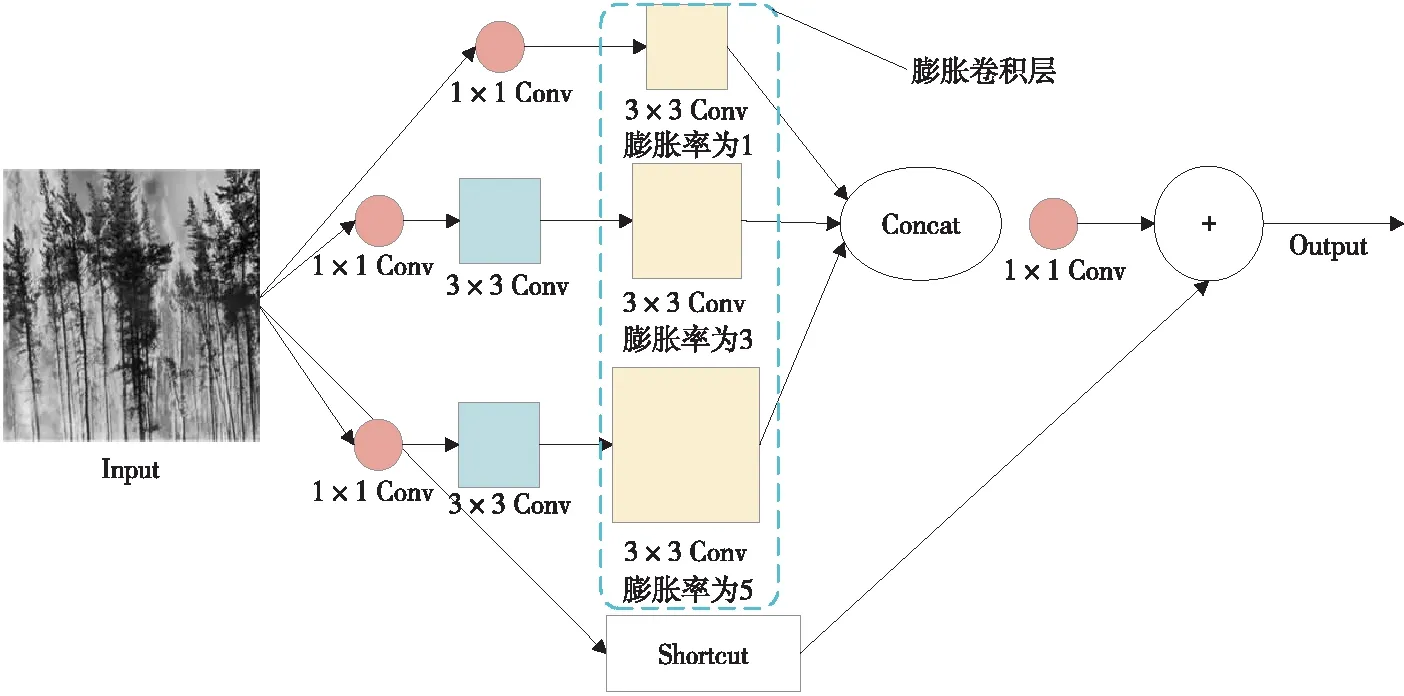
Figure 6 Structure of RFB
表2为在对模型进行参数修剪后,不同的膨胀率对模型性能的影响,其中BFLOPs(Billion FLoat Operations Per second)表示每秒钟执行的百万次浮点运算次数。膨胀卷积不会额外增加模型的参数量,因此3组实验的参数量相同。但是,较大膨胀率的膨胀卷积层在计算过程中需要更多的推理时间,且权重较大,这会直接影响模型的推理时间。因此,采用更大的膨胀率后模型的准确率略有提升,但模型的FPS下降了0.4。膨胀率设为1时,即为普通卷积。当膨胀率为2和4时,模型的FPS分别下降了0.2和0.4,但模型的准确率提升了4.8%,这表明膨胀卷积层的引入是有效的。综合考虑模型的准确率和实时性,本文选取膨胀率为2的膨胀卷积层。

Table 2 Inflated convolutional layers performance comparison of pruned model with different ratios
3.2.3 扩大模型的感受野
Bochkovskiy[7]在YOLO v4中提到,扩大模型的感受野是一种以较小推理成本提高目标检测准确性的方法。由于火焰图像尺度变化较大,模型的沙漏型CSP-ResNet结构的膨胀卷积可对大尺度的火焰图像进行检测处理,但膨胀卷积由于网格效应,在检测小物体时性能较差。如果能在模型浅层获取较小尺度的火焰特征,将有助于模型针对较小火焰的识别与检测。为了在模型浅层就能获取到更高分辨率的特征图,且不大量增加计算量,本文在模型前端加入CSP-RFBs。RFB借鉴了Inception的多分支结构,加入了膨胀卷积层,可使轻量级CNN模型提取到更深层特征,有效扩大了模型的感受野。RFB的结构包括多分支卷积层和膨胀卷积层,其结构如图6所示。
RFB网络中采用了多尺度的膨胀卷积,并设置瓶颈结构减少特征图的通道数。为获取更高分辨率的特征,RFB的每个分支都在正常卷积运算后面连接不同尺寸的膨胀卷积运算。最终,将所有的分支进行级联合并特征图。与RFB不同,RFBs(图7)采用3×3的卷积层来替换5×5的卷积层,以减少RFBs的参数量。然而,这种方法并不适用轻量级目标检测网络。

Figure 7 Structure of RFBs
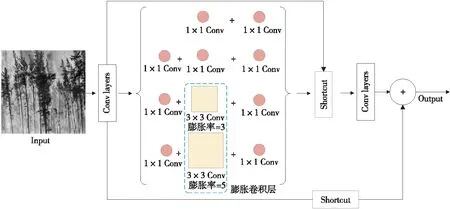
Figure 8 Improved CSP-RFBs
为了达到速度与实时性的均衡,本文在RFB的基础上提出了实时性与准确性均衡的CSP-RFBs。Wang等[22]引入了CSPNet,这种结构可以应用于各种CNN的架构中,减少了模型的参数量和计算量。此外,CSPNet的结构可以减少网络的推理时间,已被广泛应用于目标检测的YOLO v4、YOLO v4-tiny等算法。因此,本文将CSPNet的网络结构与RFBs相结合,提出了CSP化的RFBs,图8为其结构图。
RFBs是为了大型目标检测网络设计的,参数量较大。虽然RFBs采用了1×3和3×1的卷积层,但对于轻量级的目标检测来说,仍然存在较多的冗余参数。因此,为了进一步降低计算成本,增加网络中非线性模块的数量,本文采用多个1×1 卷积层来加深和拓宽网络结构。此外,本文还在1×1卷积层中加入非线性激励层,以增强网络的表现力。然而,仅修改卷积核尺寸并不能达到预期的效果,所以本文还改进了RFB的结构,在RFBs中加入了一个Shortcut层,以增强特征表达。为了进一步增强输出特征,本文提出了CSP-RFBs。CSP-RFBs增加了3个3×3的卷积层和深度分离的卷积,使模型能够获得更深的特征,增强CSP-RFBs的鲁棒性。
为了验证CSP-RFBs的有效性,本文将RFBs与改进型RFBs、CSP-RFBs在火焰数据集上进行对比。表3为分别采用RFB、RFBs和改进型RFBs时模型的性能对比。RFB是针对通用型大型卷积神经网络设计的,因此模型参数量最大,实时处理速度最慢。采用RFBs之后,模型的参数量得到了缩减,准确率和FPS也得到了进一步提升。采用本文提出的改进型CSP-RFBs之后,模型的参数量得到进一步缩减,整体性能优于RFB的和RFBs的。

Table 3 Model performance comparison respectively using RFB, RFBs, and improved RFBs
3.2.4 改进型CSP-SPPs
由于真实火焰图像的尺寸变化较大,为了使模型可以检测不同大小的火焰图像,使模型整体具有较强的鲁棒性,本文在模型深层将不同尺寸的特征进行了融合。He 等[23]首先提出SPP结构,将空间金字塔匹配模块融合至卷积神经网络,并采用了最大池化层。YOLO v3、YOLO v4和Scaled-YOLO v4均对SPP进行了改进,并达到了最优效果。但是,这些改进的SPP结构都是为参数量和计算量都比较大的大型目标检测网络设计的,并不适用于轻量级目标检测网络。因此,本文对SPP重新进行了设计,分别删除了CSP-SPP中的1×1和3×3卷积层,如图9所示。消融实验结果表明了改进型CSP-SPPs的有效性。
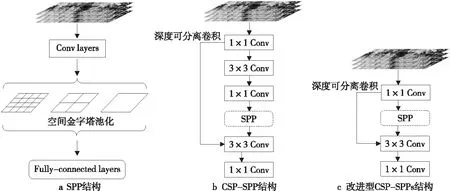
Figure 9 Structure of CSP-SPP and improved CSP-SPP
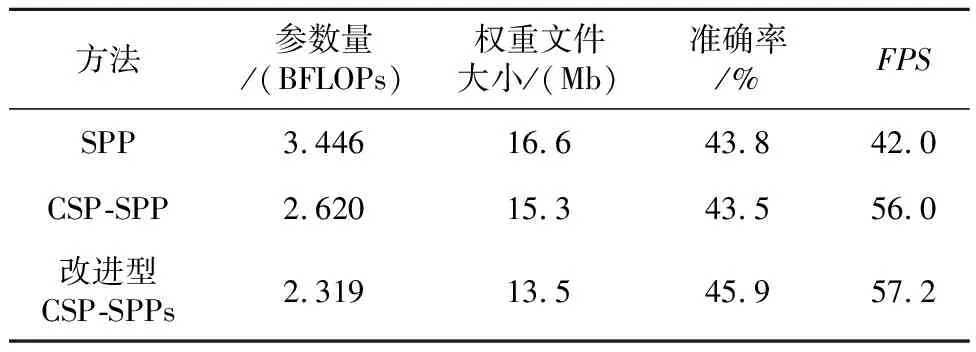
Table 4 Models performance comparison respectively using SPP, CSP-SPP,and improved CSP-SPPs
表4为修剪后的模型分别采用SPP、CSP-SPP和改进型CSP-SPPs时的性能对比。由于SPP是针对大型目标检测网络设计的,基础层的卷积层较多,参数量较大,因此采用SPP后,模型的参数量最大,实时处理速度最慢。采用CSP-SPP之后,模型的参数量和权重文件大小得到缩减,实时处理速度提升了14,但模型的准确率下降了0.3%。采用改进型CSP-SPPs之后,模型的参数量和权重文件大小分别减少了0.301 BFLOPs和1.8 Mb,准确率和FPS分别提升了2.4%和1.2。因此,在移动设备采用改进型CSP-SPPs是有效的。
4 实验及结果分析
4.1 实验平台与数据集
本节在NVIDIA RTX 2080Ti平台上训练改进型YOLO v4-tiny,在NVIDIA Jeston Xavier NX开发板上测试FPS。NVIDIA Jeston Xavier NX开发板具有384个CUDA核心,48个tensor核心和2个NVIDIA引擎,性能是NVIDIA Jetson TX2的10倍以上,具有精确多模式的AI推理功能,在15 W功率下AI性能可达21 TOPS(Tera Operations Per Second)。以下实验采用15W 2核心的功率模式进行测试。

Table 5 NVIDIA RTX 2080Ti vs NVIDIA Jetson Xavier NX
本文采用的实验火焰图像数据集分别来自kaggle火焰数据集(https://www.kaggle.com/phylake1337/fire-dataset)、火焰公开数据集(http://signal.ee.bilkent.edu.tr/VisiFire/)以及互联网采集,一共967幅火焰图像,其中,70%(711幅)组成训练集,30%(256幅)组成测试集。所有数据集均用LabelImg进行标注。
本文实验以YOLO v4作者提供的模型参数为基础,经过大量实验选取最优参数,并对部分参数进行了调整。本实验采用DarkNet框架在2080Ti平台上对改进型YOLO v4-tiny进行训练,它是一个用C和CUDA编写的开源神经网络框架,支持CPU和GPU。模型默认输入图像尺寸为416×416,采用SGD优化器,批量大小设为64,动量为0.9,学习率在初期设为0.002 61,在迭代至训练次数的80%和90%时,学习率分别降至初始值的10%和1%,迭代次数设为8 000。
4.2 消融实验
为了证明改进方法的有效性以及每个模块对模型的影响,本文首先对YOLO v4-tiny的网络参数进行了缩减,之后依次加入CSP-RFBs模块、沙漏型CSP-ResNet模块和改进型CSP-SPPs模块分别进行实验。表4为消融实验结果,实验结果包括准确率(mAP)、模型权重文件大小、模型参数量和实时处理速度FPS。

Figure 10 Comparison of detection results between YOLO v4-tiny and the improved model in this paper
由表6可知,对YOLO v4-tiny的模型参数进行修剪之后,模型的参数量仅为2.23 BFLOPs,模型的权重文件大小为13.1 Mb,约为原始模型的55.7%。由于参数量和模型的计算量得到了极大缩减,因此模型的推理时间也大幅减少,FPS提升了20.6,但同时也带来了准确率的损失,模型的准确率相比原始模型的下降了2.2%。加入CSP-RFBs后,在浅层网络扩大了模型的感受野,仅额外增加0.13 BFLOPs的计算量,模型的准确率却得到了14.6%的提升。由于增加了一个CSP网络层,因此模型的FPS下降了5.3。加入沙漏型CSP-ResNet模块后,参数量增加了0.06 BFLOPs,模型的准确率得到了进一步的提升。由于膨胀卷积层的加入,模型的权重文件大小增加了2.9 Mb,FPS损失了6.3。最后,在模型中加入改进型CSP-SPPs模块,参数量仅增加了0.03 BFLOPs,模型的FPS与之前相比并无较大变化,但准确率得到了1.8%的提升。因此,本文在减小模型尺寸、减少计算量的基础上,提升了模型的检测精度和检测速度。
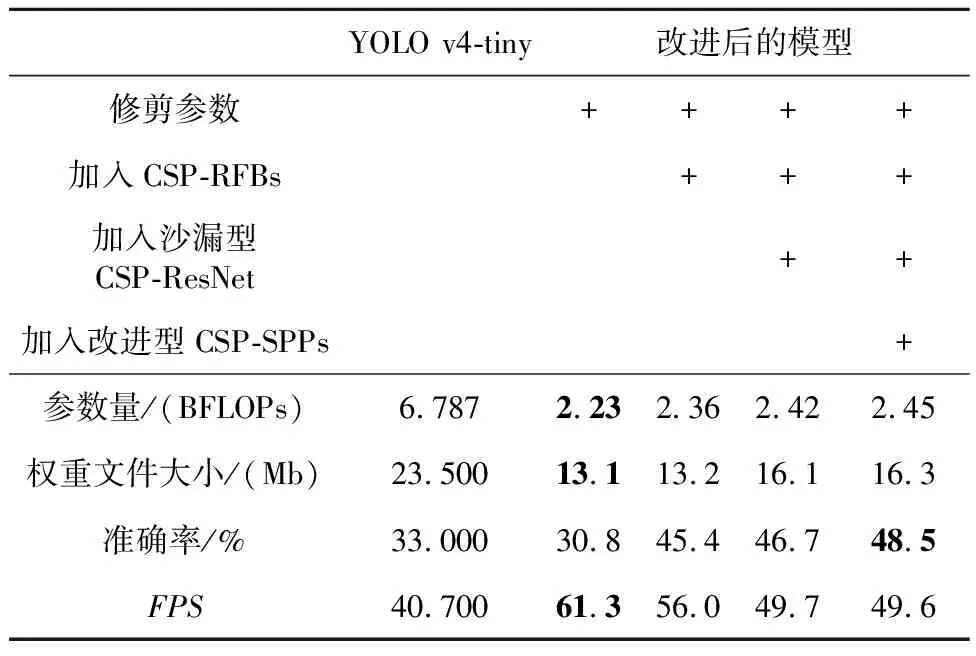
Table 6 Analysis of the ablation experimental results of the improved YOLO v4-tiny model
图10为YOLO v4-tiny与本文改进模型针对火焰图像的检测结果对比图。从图10中可看到,在较为简单的检测场景中,本文改进模型的准确度均优于原始模型的。在检测目标较多、火焰尺度变化较大的复杂场景中,原始模型会出现漏检、虚检情况。本文提出的改进模型在实际检测中,准确度和检测效果均有较大提升,模型整体优于原始模型。
4.3 与其他轻量级目标检测模型性能对比
本节选取SqueezeNet SSD、MobileNet SSD与改进型YOLO v4-tiny进行对比,数据集同样采用火焰数据集,在NVIDIA RTX 2080Ti平台上进行训练,在NVIDIA Jetson Xavier NX平台上进行测试,与前文实验环境保持一致。
表7为模型性能对比的实验结果。从表7可以看出,改进型YOLO v4-tiny在权重、参数量和FPS方面均取得了较好的结果。改进型YOLO v4-tiny的参数量约为SqueezeNet SSD的54.6%,权重文件大小减小了5.9 Mb,mAP提高了17.3%,实时处理速度也高于SqueezeNet SSD的。MobileNet SSD的准确率高于表6中的YOLO v4-tiny的准确率。为了进一步比较MobileNet SSD与改进型YOLO v4-tiny的性能,本文对MobileNet SSD的卷积核进行了修剪,在保证模型参数量相近的情况下,比较模型的性能。修剪卷积核之后的MobileNet SSD的模型权重文件大小和FPS均有较大改进,但准确率却急剧下降。因此,就整体性而言,改进型YOLO v4-tiny是一种部署在计算能力有限平台上的竞争模型。
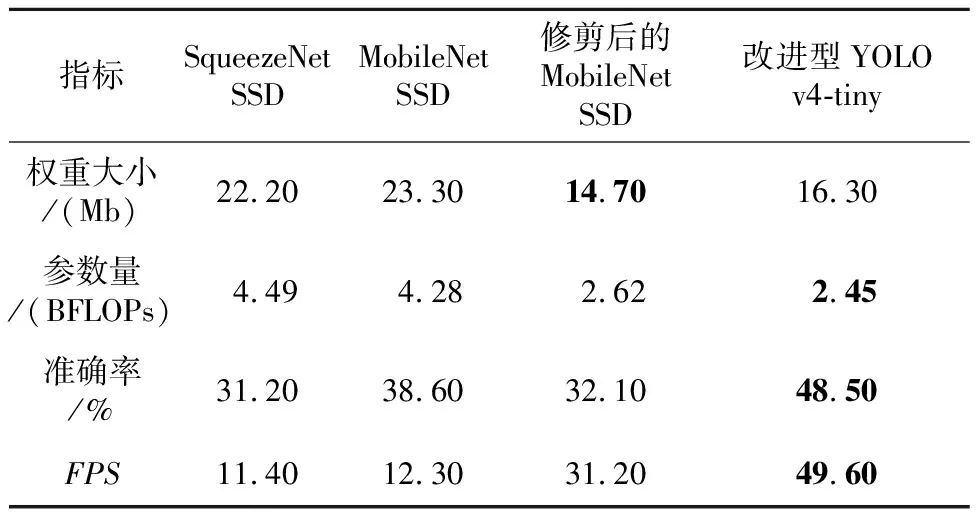
Table 7 Comparison with other lightweight target detection models on the flame dataset
5 结束语
本文提出一种针对火焰实时检测的改进型轻量级目标检测模型。本文在YOLO v4-tiny的基础上,对模型参数量进行了缩减。为达到准确率与实时性的均衡,本文首先对CSPNet模块进行改进,增强了模型特征提取能力;之后加入RFBs模块以扩大感受野,使模型可获取到更高分辨率的特征图;最后在网络深层加入改进型CSP-SPPs,对多重感受野进行进一步融合。实验结果表明,本文提出的改进YOLO v4-tiny模型的整体性能均优于YOLO v4-tiny的,但针对复杂场景的火焰检测,会出现虚检和误检的现象,这是由于网络较浅,学习能力较差。因此,为解决这个问题,接下来准备将特征金字塔网络进行轻量化改进,并将其应用至轻量化检测模型,以获得更优的性能。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
学苑创造·A版(2021年2期)2021-03-11
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
动漫星空(兴趣百科)(2019年5期)2019-05-11
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年20期)2017-04-26
