
基于中文语义-音韵信息的语音识别文本校对模型
2023-01-08 14:31仲美玉吴培良窦燕刘毅孔令富
通信学报 2022年11期
仲美玉,吴培良,2,窦燕,3,刘毅,孔令富,2
(1.燕山大学信息科学与工程学院,河北 秦皇岛 066004;2.河北省计算机虚拟技术与系统集成重点实验室,河北 秦皇岛 066004;3.河北省软件工程重点实验室,河北 秦皇岛 066004)
0 引言
近年来,自动语音识别(ASR,automatic speech recognition)技术被广泛地应用于人机交互系统。受用户发音不清晰、环境噪声等因素的影响,实际应用场景下的语音识别准确率仍然不高[1]。中文存在大量发音相近但意义完全不同的汉语字符,语言自身的复杂性进一步导致了语音识别错误的产生[2]。从语音识别文本长度变化的角度分析,ASR 系统产生的文本错误包括多字错误、少字错误和替换错误3 种类型。从语音识别文本发音变化的角度分析,语音识别文本中存在大量谐音错误,如图1 所示,“镜”被误识为“睛”。除此之外,语音识别文本中还存在混淆音错误,如图1 中“牛郎”被误识为“流浪”。ASR 模块通常位于人机语音交互系统前端,语音识别错误文本反馈至交互界面会增加用户理解语义的难度,也会直接影响意图识别、命名实体识别等下游任务的处理[3]。语音识别后的文本校对能有效避免识别错误在ASR 系统下游任务的累积,是改进ASR 系统性能的重要方法[4]。

图1 语音识别错误示例
替换错误在语音识别错误中占有较大比重[5],故本文侧重于检测和纠正语音识别文本中的替换错误。中文文本校对方法主要分为3 种,分别是基于规则的校对方法、基于统计的校对方法和基于深度学习的校对方法。相较基于规则的校对方法和基于统计的校对方法,基于深度学习的校对方法能够捕获更深层次的语义信息,有利于提升文本校对效果[6]。针对现有基于深度学习的模型只考虑使用文本的语义信息纠正错误字符的问题,Chen 等[7]构建了融合语义信息和音韵信息的预训练语言模型来实现语音识别文本校对,该方法首先使用微调的预训练语言模型定位语句中错误字符的位置,采用掩码字符掩盖错误字符,利用模型提取的语义信息计算纠错候选字符的概率;然后,采用DIMSIM[8]计算错误字符与各候选字符的拼音距离;最后,综合考虑候选字符的概率及其与错误字符的拼音距离来完成文本纠错,实验证明了利用拼音信息能够有效地加强模型纠正语音识别文本中谐音错误字符的能力。Duan 等[9]使用一维卷积神经网络(1D-CNN,one-dimensional convolutional neural network)构建的序列到序列(Seq2Seq,sequence to sequence)模型来校对文本,该方法采用字节对编码方法生成拼音的嵌入向量(以下统称音韵嵌入向量)并将其作为模型的输入,以便模型提取并利用语句的音韵信息纠正文本错误,实验验证了字粒度切分语句的方式和带声调的拼音有助于提高语音识别文本纠错效果。综上所述,拼音携带的音韵信息对纠正ASR系统识别错误具有重要意义。由于拼音中的字母不可随意调换顺序,例如,图1 中“郎”字的拼音是“láng”,调换其拼音中任意2 个字母的位置后(如“lnág”、“lágn”),便不再是“郎”字的读音,故中文字符的拼音本质上是一种序列。然而,上述工作在生成音韵嵌入向量时没有保留拼音的时序信息,也没有对生成音韵嵌入向量的拼音编码方法及其对检测和纠正语音识别文本错误的影响做进一步研究。此外,基于深度学习的文本校对模型往往需要通过大量的标注语料来增强其对文本语义和文本结构信息的学习能力,从而提升模型的检错和纠错性能。但实际应用中的ASR 系统通常面向垂直领域,可获取的标注语料十分有限。虽然可以使用其他语料库来扩充数据集,但该方式不能促使模型学习到更多与特定对话场景相关的文本语义和文本结构信息。
为了解决上述问题,本文提出了5 种拼音编码方法来生成中文字符的含拼音时序信息的音韵嵌入向量,分别将各个拼音编码方法与带有注意力机制的编码器-解码器架构相结合来建立基于中文语义-音韵信息(CSPI,Chinese semantic and phonological information)的文本校对模型;从汉语拼音组成成分的角度分析了语音识别文本错误的特点,并据此提出了一种基于拼音声韵置换(RPIF,replacement of Pinyin’s initials or finals)的数据增强方法,该方法可利用有限的语料来生成大量的纠错数据,以便利用数据驱动的方法构建面向垂直领域的文本校对模型。本文的主要贡献可以总结为以下4 点。
1) 提出了5 种拼音编码方法来生成中文字符的音韵嵌入向量。所提方法采用不同的处理时序数据的神经网络来编码拼音序列,从而以多种方式生成含有拼音时序信息的音韵嵌入向量,便于研究不同拼音编码方法对语音识别文本校对任务的影响。
2) 构建了基于CSPI 的语音识别文本校对模型。该模型由上述拼音编码方法分别与带有注意力机制的编码器-解码器架构组合而成,能充分地提取并利用中文语句的语义和音韵信息校对语音识别文本错误。
3) 提出了一种基于RPIF 的数据增强方法。该方法能够有效模拟用户因发音不清晰、口误等造成的语音识别错误,解决了因标注语料不足而难以面向特定对话场景构建基于深度学习的文本校对模型的问题。
4) 在多人普通话语音数据集AISHELL-3 上开展了相关实验,验证了拼音携带的音韵信息有利于文本校对模型检测和纠正语音识别文本错误,归纳了不同的拼音编码方法对检测和纠正语音识别文本错误的影响。
1 相关工作
语音识别后的文本校对是提升ASR 系统性能的重要方法。文献[1]综述了ASR 系统识别错误的产生原因和处理方法。早期的研究主要是对语音识别错误检测方法的研究,对语音识别错误纠正方法的研究则相对较少。中文文本校对方法可分为3 种:基于规则的校对方法、基于统计的校对方法和基于深度学习的校对方法。文献[10-11]均通过观察文本错误出现的规律并制定相应的规则来处理文本错误。此类基于规则的校对方法仅对特定的错误类型有效,其文本校对效果也严重依赖于规则制定的好坏[12-13]。现有ASR 系统在实际对话场景中产生的识别错误具有较强的复杂性,无法使用简单的规则覆盖所有可能出现的错误。N-gram 是文本校对任务中最常用的统计语言模型[14]。文献[15]使用N-gram 语言模型和潜在语义分析方法相结合的方式来校对文本错误。文献[16]建立了基于2-gram 和3-gram 的文本校对方法,并采用了平滑技术来解决数据稀疏的问题。文献[17]结合使用语言模型和统计机器翻译方法生成错误字符的候选集,采用支持向量机对候选集排序的方式实现中文语句的自动校对。然而,基于统计的校对方法在使用混淆集纠正文本错误时,没有充分利用句子的上下文语义关系,容易出现邻近词正确,但整个句子不符合逻辑的情况。因此,上述基于规则和基于统计的文本校对方法均难以有效地处理ASR 系统实际应用过程中出现的语音识别错误。近年来,越来越多的研究将深度学习技术运用到中文文本处理任务中,基于深度神经网络的文本校对方法也不断被提出[18-21]。文献[22]将检测文本错误字符的问题视为序列标注问题,利用双向长短期记忆(LSTM,long-short term memory)网络构建了拼写文本检错模型。文献[23]构建了基于双向LSTM 的Seq2Seq 模型来检测和纠正文本中的错误字符。文献[24]构建了基于1D-CNN 的Seq2Seq 模型来实现文本校对。基于深度学习的校对方法能利用深度神经网络模型捕获更丰富的文本语义和文本结构信息来校对文本错误,通常能取得比基于规则和基于统计的校对方法更好的检错和纠错效果。
语音识别文本校对和拼写文本校对的研究目标一致,本质上都是检测和纠正文本中的错误字符。中文拼写错误主要来源于人们错误使用了某个字符的谐音或形似字符[25]。近年来,一些研究工作尝试利用文本的拼音和字形信息来提升基于深度学习的拼写文本校对模型的性能。Wang 等[26]构建了基于Lattice LSTM 和CRF 的拼写错误检测模型,该模型融合字符、词语和拼音3 种信息进行错误检测,验证了拼音信息有利于检测拼写错误。Liu 等[27]提出了使用单向门控循环单元(Uni-GRU,unidirectional gated recurrent unit)编码字符的无声调拼音和笔画来获取更有意义的字符表示,并以此作为预训练语言模型的输入。实验结果表明,融合拼音和笔画信息的预训练模型在拼写文本校对任务中表现出了十分优异的性能。与之类似,文献[28-32]也提出了多种基于深度学习的拼写文本校对方法,部分研究工作以不同方式利用字符的音韵信息来提升模型性能。表1 列举了多项研究在SIGHAN2015 拼写纠错数据集[33]上的评估结果。从表1 可以看出,基于深度学习的拼写校对模型通常比基于统计的拼写校对模型有更好的检错和纠错效果,字符的音韵信息对提升拼写校对模型的检错和纠错性能有积极影响。相较于拼写文本错误,语音识别文本错误不仅包含谐音类型的错误字符,还包含较多因用户发音不清晰、环境嘈杂等因素导致的混淆音类型的错误字符。然而,现有面向语音识别文本校对任务的相关工作没有深入地研究拼音所蕴含的音韵信息对检测和纠正语音识别文本错误的影响。考虑到汉语拼音是一种序列且带声调的拼音能完整地保留字符音韵信息,本文参考文献[27]提出了一种新的基于Uni-GRU 的拼音编码方法,同时又基于1D-CNN、双向门控循环单元(Bi-GRU,bidirectional gated recurrent unit)等处理时序数据的网络提出了4 种拼音编码方法来编码带声调的拼音序列,以生成保留完整音韵信息的嵌入向量。将各个拼音编码方法分别与带有注意力机制的编码器-解码器架构相结合来构建基于CSPI 的文本校对模型,以明确有利于检测和纠正语音识别文本错误的拼音编码方法。
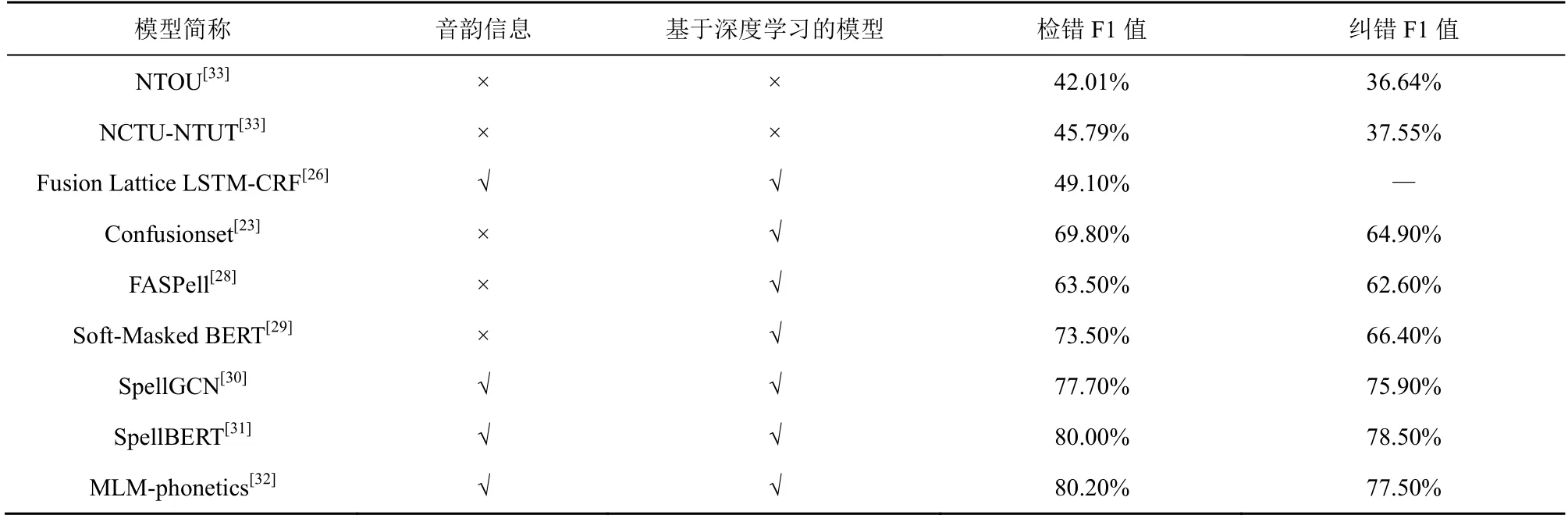
表1 多项研究在SIGHAN2015 拼写纠错数据集上的评估结果
由于标注数据有限,许多先进的深度学习模型难以被有效地应用于文本校对任务。为了满足通过大量标注数据提升模型校对性能的需求,Wang 等[22]利用基于光学字符识别和自动语音识别的方法模拟拼写错误,实现了面向拼写纠错任务的数据增强方法。Liu 等[27]和Cheng 等[30]通过上述数据增强方法生成的语料构建了大规模预训练语言模型,该模型在拼写纠错任务中取得了非常优异的成绩。然而,ASR 系统识别错误比拼写错误更复杂,主要原因是ASR 系统在用户发音不清晰或环境嘈杂的情况下获取了含较多噪声的声音信号,ASR 系统的语言模型因受噪声干扰无法将声音信号解码为正确的文本序列。值得注意的是,Wang 等[22]提出的数据增强方法根据拼写错误的特点摒弃了语音识别过程中真实产生的混淆音类别的错误文本。其他面向拼写纠错任务的数据集也存在包含较少混淆音类别的错误文本的问题。这意味着在拼写纠错数据集上表现出色的文本校对模型不一定在语音识别后的文本校对任务中具备同等优秀的纠错能力。因此,本文从汉语拼音组成成分的角度分析ASR 系统识别错误的特点,并据此提出一种基于RPIF 的数据增强方法,以便将先进的深度学习模型应用于语音识别后的文本校对任务中,进而辅助ASR 系统提升其识别准确性。
2 基于CSPI 的文本校对模型
基于CSPI 的文本校对模型受启发于神经机器翻译模型[34-35],使用带有注意力机制的编码器-解码器架构[36]来实现错误文本到正确文本的转换,模型的总体结构如图2 所示。首先,使用常见的处理时序型数据的神经网络编码中文字符的拼音序列,生成含时序信息的音韵嵌入向量。然后,分别融合错误文本中各个字符的音韵嵌入向量和字符嵌入向量,以此作为编码器的输入。接着,编码器编码错误文本,输出错误文本的语义-音韵向量,该语义-音韵向量则携带了错误文本全部的语义-音韵信息。最后,解码器以语义-音韵向量和解码起始符为输入,先采用注意力机制捕获当前解码字符与错误文本的上下文语义-音韵关系,再利用该语义-音韵关系输出预测字符,进而逐步解码预测的正确文本。
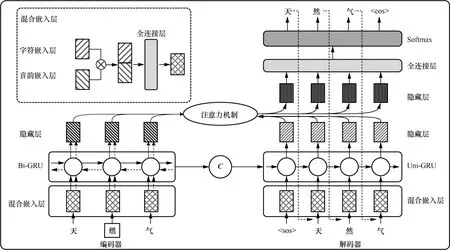
图2 基于CSPI 的文本校对模型的总体结构
接下来,先从数学角度定义模型校对语音识别错误文本的过程,再从拼音编码、编码器、解码器和优化目标4 个方面详细介绍基于CSPI 的文本校对模型。
2.1 问题定义
假设错误文本为源(source)文本序列s= {s1,···,si,···,sn},文本校对模型输出的语句是目标(target)文本序列g= {g1,···,gt,···,gm}。从概率角度分析,文本校对的过程相当于给定s,寻找g来最大化条件概率。因此,文本校对的目标是建立一个参数化模型,使用平行语料库来训练该模型,以最大化各个source-target 语句对的条件概率。当模型学习到这个条件概率分布后,给定一个错误文本,模型便可以输出一个条件概率最大的句子作为预测的正确文本。为了利用句子的音韵信息来加强模型校对语音识别错误文本的能力,本文提出了5 种拼音编码方法来构建基于CSPI 的文本校对模型。假设s对应的拼音序列为则的求解过程转化为
2.2 拼音编码
拼音是由小写拉丁字母构成的汉字发音标记,一般包含声母、韵母和声调3 个部分,如图3 所示。为了便于计算机识别,将图3 中4 种声调依次映射到数字{1,2,3,4},则4 个汉字的拼音可表示为‘fei1,yan2,zou3,bi4’。除了图3 所示的4 种声调外,中文还存在轻声这一特殊的声调。‘轻声’字符的拼音不标注声调,仅由小写拉丁字母构成,例如,‘云彩’中的‘彩’为轻声,其拼音为‘cai’。

图3 汉语拼音示例
为了建模字符间的音韵关系,本文将字符拼音视为由小写字母和声调组成的序列,使用不同的处理时序数据的神经网络(Uni-GRU、Bi-GRU 和1D-CNN)编码拼音序列,由此获取含时序信息的音韵嵌入向量,以使音似字符间有相似的音韵表示。在之前的研究工作中,Duan 等[9]验证了字粒度切分方式和带声调的拼音序列有利于语音识别文本纠错,因此,本文采用字粒度切分方式划分语句,
使用PyPinyin工具包获取各个字符的带有声调的拼音序列。本文将拼音序列的长度固定为8,当拼音序列的实际长度未达到8 时使用数字‘0’填充。根据编码拼音序列的网络类型的不同,将本文提出的5 种拼音编码方法分别命名为PC、PU、PB、PCU和PCB。图4 以‘中’的拼音‘zhong1’为例,示意了上述5 种拼音编码方法。由图4 可知,PC、PU和PB使用一种类型的神经网络编码拼音序列,本文将其统称为单网络拼音编码方法。PCU和PCB使用2 种不同类型的神经网络编码拼音序列,以获取更加全面的音韵信息,本文将其统称为混合网络拼音编码方法。以下是对5 种拼音编码方法的定义。

图4 拼音编码
定义1PC拼音编码。对于任意一个中文字符c的拼音序列cp,使用单层1D-CNN 编码cp,生成字符c的PC音韵嵌入向量,即
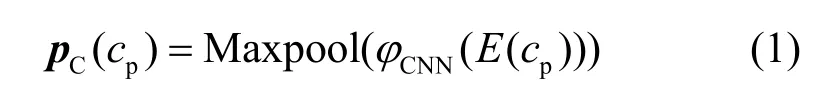
其中,φCNN是单层1D-CNN 的函数表示,Maxpool指最大池化层,E指字符嵌入层。
定义2PU拼音编码。对于任意一个中文字符c的拼音序列cp,使用单层Uni-GRU 网络编码cp,生成字符c的PU音韵嵌入向量,即

其中,φUni-GRU是单层Uni-GRU 网络的函数表示。
定义3PB拼音编码。对于任意一个中文字符c的拼音序列cp,使用单层Bi-GRU 网络编码cp,生成字符c的PB音韵嵌入向量,即

其中,φBi-GRU是单层Bi-GRU 网络的函数表示。
定义4PCU拼音编码。对于任意一个中文字符c的拼音序列cp,融合pC和pU编码cp所得结果,生成字符c的PCU音韵嵌入向量,即
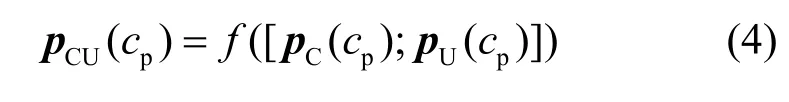
其中,f表示全连接(FC,fully connected)层,[·]表示合并操作。
定义5PCB拼音编码。对于任意一个中文字符c的拼音序列cp,融合pC和pB编码cp所得结果,生成字符c的PCB音韵嵌入向量,即

由图4 可得,cp先通过字符嵌入层获取其字母或声调的嵌入向量,而后任选一种拼音编码方法来生成字符c的音韵嵌入向量,即
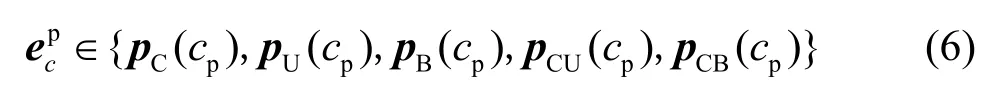
2.3 编码器
编码器由混合嵌入(FE,fusion embedding)层和单层Bi-GRU 网络构成,负责输出源文本序列s在各个时间步的隐藏(Hidden)层及其语义-音韵向量C,其结构如图2 所示。构建混合嵌入层旨在建立中文句子及其拼音序列间的关系。选用Bi-GRU 是希望编码器能通过该网络充分提取s的上下文语义-音韵信息。
首先,源文本序列s及其拼音序列sp经混合嵌入层后得到字符-音韵嵌入向量

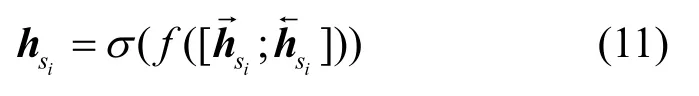
其中,σ表示激活函数tanh。则编码器在各个时间步输出的隐藏状态hs可表示为
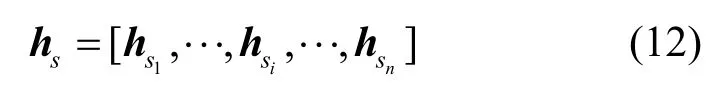
根据文献[35],本文使用编码器在最后一个时间步上的隐藏状态作为源文本序列s的语义-音韵向量C,即

2.4 解码器
解码器由混合嵌入层和单层的Uni-GRU 网络构成,使用源文本序列的语义-音韵向量C初始化Uni-GRU 层的隐藏状态,采用注意力机制输出预测的文本序列,其结构如图2 所示。


其中,是Uni-GRU 层在t时刻输出的隐藏状态。
本文采用注意力机制[37]使解码器在动态解码过程中,给予源文本序列中与目标字符相关性较高的字符以较大权重,以便模型能准确输出目标文本序列。以编码器和解码器在各个时间步输出的隐藏状态hs和hg作为注意力机制输入,将注意力机制在t时刻输出的隐藏状态记为,其计算方法如式(16)所示。

其中,ct是编码器输出的各个隐藏状态在t时刻的加权平均和,可表示为


在模型评估阶段,解码器仅以解码起始符
2.5 优化目标
一般来说,文本纠错模型在训练阶段只设置字符优化目标。本文提出的基于CSPI 的文本校对模型同时学习了句子的语义信息和音韵信息,因此设置了字符-拼音优化目标,如式(22)所示。

其中,Lc和 Lp分别是字符优化目标和拼音优化目标,可表示为
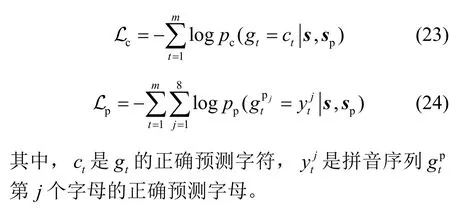
3 面向中文ASR 系统的纠错数据增强方法
本节首先根据2.2 节所述汉语拼音的组成部分来分析语音识别错误的特点,然后根据该特点提出一种基于RPIF 的纠错数据增强方法。
3.1 语音识别文本错误分析
表2 列举了Kaldi 语音识别工具包使用过程中出现的错误示例[22]。接下来,根据拼音的组成部分,即声母、韵母和声调,分析表2 所列语音识别错误示例。示例1 中,“幸”被误识为“行”,二者的声母和韵母均相同,声调“4”被误识为声调“2”。示例2 中,语音识别错误字符与正确字符有着完全不同的发音,但仔细分析可以发现,“围”和“没”有相同的韵母“ei”和声调“2”,语音识别错误来源于声母“m”被误识为“w”;“绕”和“让”有相同的声母“r”和声调“4”,语音识别错误来源于韵母“ao”被误识为“ang”。示例3 中,“院方协商”与误识的“岳风学生”有着相同的声母和声调,其语音识别错误来源于“院方协商”的韵母“uan”、“ang”、“ie”、“ang”分别被误识为“ue”、“eng”、“ue”、“eng”。由此看来,语音识别文本错误表现为语句中某些字符的拼音组成部分发生了变化,这些字符被误识为与其有相同声母或韵母的字符。

表2 Kaldi 语音识别工具包使用过程中出现的错误示例
3.2 基于RPIF 的数据增强方法
根据ASR 系统识别错误表现为语句中的某些字符被误识为其同声母或同韵母字符的特点,本文提出一种基于RPIF 的数据增强方法,如算法1 所示。在此之前,给出以下定义。
定义6同声字符集。设字符集Ci={c1,···,cn},n∈Z,若Ci中字符的声母都相同,则称Ci为同声字符集。
用咪达唑仑、舒芬太尼常规镇静镇痛,使用PB840呼吸机进行机械通气,控制潮气量为6~8 ml/kg,每次吸气时间为1~1.2 s,40 L/min,频率为14~25次/min,氧浓度控制在45~100%,控制呼气末正压为5~18 cm H 2 O,保证患者SaO2>85%。
定义7同韵字符集。设字符集Cf={c1,···,cn},n∈Z,若Cf中字符的韵母都相同,则称Cf为同韵字符集。
定义8同声字典。多个声母及其同声字符集构成的集合。
定义9同韵字典。多个韵母及其同韵字符集构成的集合。
定义10声韵混淆集。一个汉字对应一个声韵混淆集,声韵混淆集中任意一个字符都与该汉字有相同的声母或韵母。
算法1基于RPIF 的数据增强方法

算法1 展示了基于RPIF 的数据增强方法的详细过程,该过程主要是将从语句中随机抽取的n个字符分别置换为与其同声母或同韵母字符的方式来获取大量的纠错语料。算法1 中的置换概率P决定了目标语料库中生成语料与源语料的比例,生成语料随P的增大而增多。当P=0时,目标语料库的数据是对源语料库的复制扩充。当P=1时,目标语料库的数据均是采用算法1 中步骤13)~步骤28)所示方法获取的生成语料。此时,目标语料库Ce的可扩展规模受汉字集Cc大小的影响。Cc越大,单个汉字的声韵混淆集越大,纠错语料库的上限规模便会越大。值得注意的是,算法1 中的步骤14)、步骤18)和步骤25)均采用随机化方式来设置当前语句的错误字符个数n、抽取n个待替换字符及其替换字符,这能有效地模拟 ASR 系统识别错误出现的随机性。
4 实验
本节首先介绍实验所用数据集、实验环境和评估指标。然后将基于CSPI 的文本校对模型和2 个未结合拼音编码方法的模型进行比较,以验证基于 CSPI 的文本校对模型的检错和纠错性能,并对比不同拼音编码方法对模型性能的影响。最后设置2 组实验分别验证优化目标和基于RPIF 的数据增强方法对基于CSPI 的模型校对性能的影响。
4.1 实验数据

表3 AISHELL-3 数据集实验数据统计信息
4.2 实验环境及模型评估
本文实验环境如下:操作系统为 64 位Windows10 系统,CPU 为英特尔i9-10850K,GPU为16 GB 的NVIDIA A4000,内存为DDR4 32 GB。实验中涉及的深度学习模型使用Pytorch 构建。训练模型的参数设置如表4 所示。在模型训练过程中,从训练集中随机抽取20%的数据作为验证集。

表4 训练模型的参数设置
为客观评估模型性能,取模型在AISHELL-3数据集上5 次实验结果的均值作为最终的模型性能评估数据,选用文本纠错任务中常用的准确率(P,precision)、召回率(R,recall)、F1(F1-measure)作为评估指标[23],并主要通过F1 值来对比不同模型的检错和纠错性能。
4.3 实验结果与分析
4.3.1 拼音编码方法的有效性
本节将基于CSPI 的文本校对模型与以下2 个无拼音编码模型进行比较,以此检验拼音编码方法的有效性。同时,通过对比不同拼音编码模型的检错和纠错结果,验证不同拼音编码方法对模型性能的影响。无拼音编码模型简介如下。
1) MC[24]。使用2 层1D-CNN 和注意力机制构建的基于编码器-解码器架构的文本校对模型。模型参数与表4 所列各项参数保持一致。
2) MG。使用门控循环单元(GRU,gated recurrent unit)和注意力机制构建基于编码器-解码器架构的文本校对模型,即图2 所示模型仅以字符作为模型输入。
为了便于说明,将基于CSPI 的文本校对模型使用PU、PB、PC、PCU和PCB这5 种拼音编码方法时分别记为MG+PU、MG+PB、MG+PC、MG+PCU和MG+PCB,统称为拼音编码模型MG+P。各拼音编码模型和无拼音编码模型的检错和纠错结果如图5 和表5 所示。
由图5 和表5 可以看出,各个拼音编码模型的检错结果均显著优于无拼音编码模型,同时拼音编码模型的纠错结果也优于无拼音编码模型。对比2 种无拼音编码模型,MG的检错和纠错结果始终优于MC。接下来,从检错和纠错2 个方面详细地分析各个模型的文本校对性能。
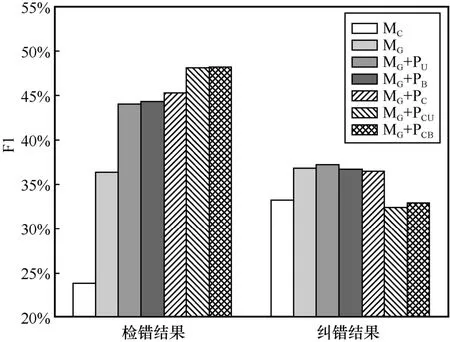
图5 拼音编码模型和无拼音编码模型的文本校对性能对比
由图5 和表5 可以看出,混合网络拼音编码模型MG+PCB的检错F1 值优于MG+PCU,且两者的检错结果明显优于单网络拼音编码模型。对比单网络拼音编码模型的检错F1 值可以看出,MG+PC优于MG+PB,MG+PB优于MG+PU。具体来说,MG+PCB取得了最高检错F1 值48.16%,相较MG和MC分别高出11.91%和24.31%,相较MG+PU、MG+PB、MG+PC和MG+PCU分别高出4.13%、3.82%、2.94%和0.13%。这与本文预期的效果相同,复杂的拼音编码网络能促使模型提取分辨能力较强的音韵信息,有助于模型检测文本错误。此外,由图5 和表5 还可以看出,拼音编码模型的检错准确率随拼音编码网络复杂度的增加而降低,但其检错召回率和F1 值随拼音编码网络复杂度的增加而不断增大,模型检错性能整体向好。这说明基于CSPI 的文本校对模型结合复杂度较高的拼音编码网络可以增强其检测错误字符的灵敏度,进而增加真实错误字符的检出率。
由表5 可得,拼音编码模型的各项纠错指标有随拼音编码网络复杂度的增加而下降的趋势。对比各个模型的纠错F1 值,拼音编码模型MG+PU取得了最高纠错F1 值37.21%,比无拼音编码模型MG和MC分别高出0.43%和3.98%。而其他拼音编码模型的纠错性能却低于无拼音编码模型,且混合网络拼音编码模型的纠错性能不如单网络拼音编码模型。拼音编码模型的纠错性能整体呈现与其检错性能相反的趋势。这是因为中文存在较多同音异义的字符,模型使用复杂的拼音编码方法提取的音韵信息分辨能力过强,导致模型认为原有错误字符或模型预测的字符在语音或语义上都能使句子有意义,本文将此称为由音韵信息引起的过纠现象。

表5 拼音编码模型和无拼音编码模型的文本校对性能对比结果
综上所述,音韵信息有利于基于CSPI 的文本校对模型检测和纠正文本错误。模型的检错能力随拼音编码网络的复杂度增加而增强。由于存在音韵信息引起的过纠现象,模型的纠错能力呈现随拼音编码网络的复杂度增加而下降的趋势。
4.3.2 优化目标对模型性能的影响
本节主要通过对比不同拼音编码模型使用字符优化目标 Lc和字符-拼音优化目标 Lcp时的检错和纠错结果来分析优化目标对模型性能的影响。各模型的文本校对结果如图6 和表6 所示。接下来,从检错和纠错2 个方面对比分析各个模型的文本校对性能。
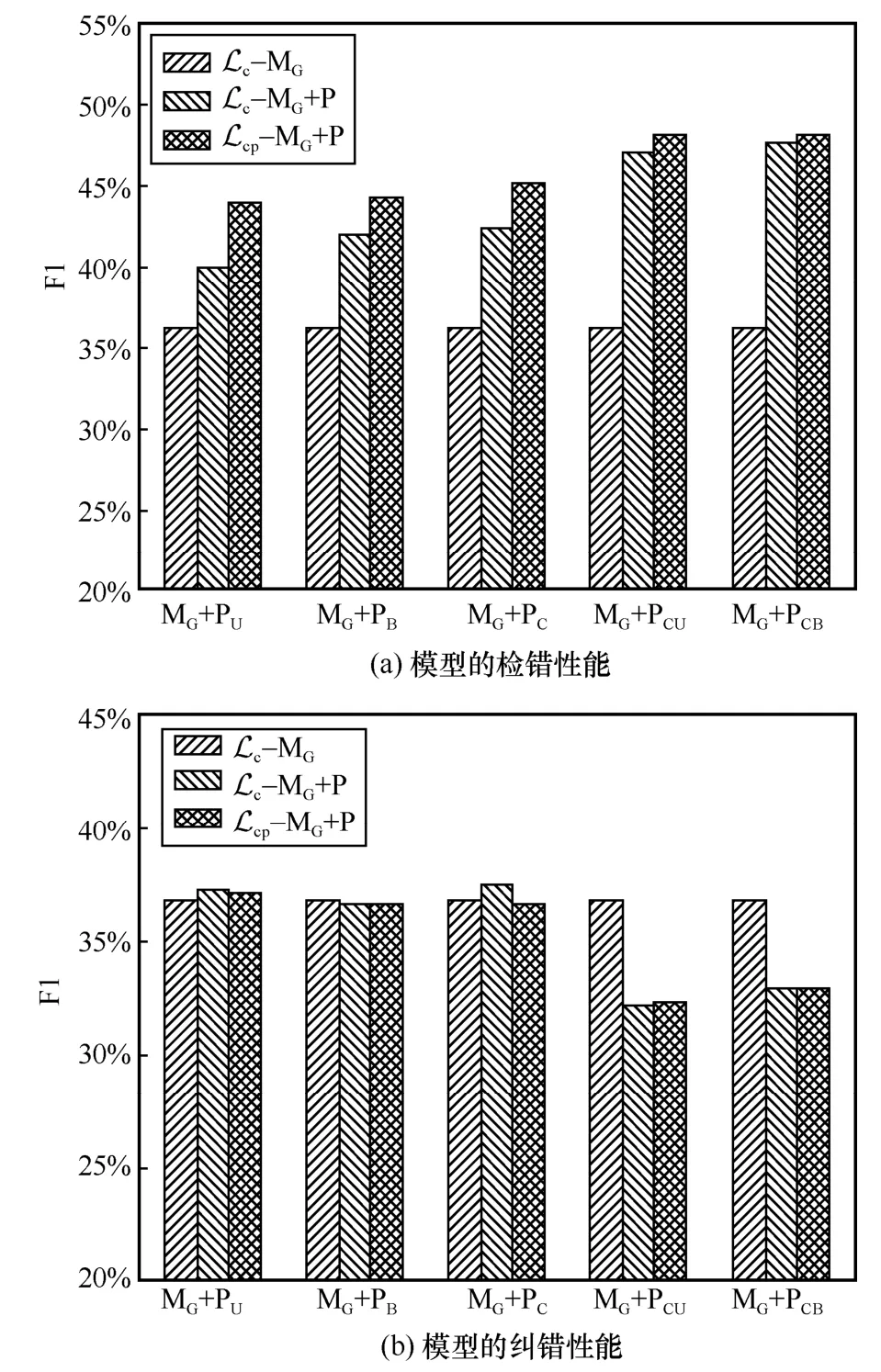
图6 基于CSPI 的模型使用不同优化目标时的文本校对性能对比
由表6 和图6(a)可以看出,拼音编码模型MG+P无论使用 Lc还是 Lcp,其检错性能均优于无拼音编码模型MG。相较使用 Lc,MG+PU、MG+PB、MG+PC、MG+PCU和MG+PCB使用 Lcp时的检错F1 值分别提升了4.13%、2.34%、2.83%、0.97%和0.42%,这说明字符-拼音优化目标能够促使模型学习分辨能力更强的音韵信息,进而提升了模型的检错性能。由表6 和图6(a)还可以看出,当模型使用 Lc时,MG+PCB的检错F1 值比MG+PCU高,且两者的检错性能仍明显优于MG+PU、MG+PB和MG+PC,这也进一步体现了模型融合复杂拼音编码网络学习的音韵信息更加有利于其辨别文本错误。
然而,由表6 和图6(b)可以看出,MG+PC使用Lc时的纠错结果高于其使用 Lcp,此时拼音编码模型取得了最优纠错F1 值37.46%,相较MG+PC使用Lcp的纠错F1 值高出0.94%,相较MG的纠错F1 值高出0.68%,相较MG+PU使用 Lcp取得的最好纠错F1 值高出0.25%。MG+PU、MG+PB和MG+PCB使用Lc和 Lcp时取得的纠错结果相当。仅MG+PCU使用Lcp时的纠错结果优于其使用 Lc。
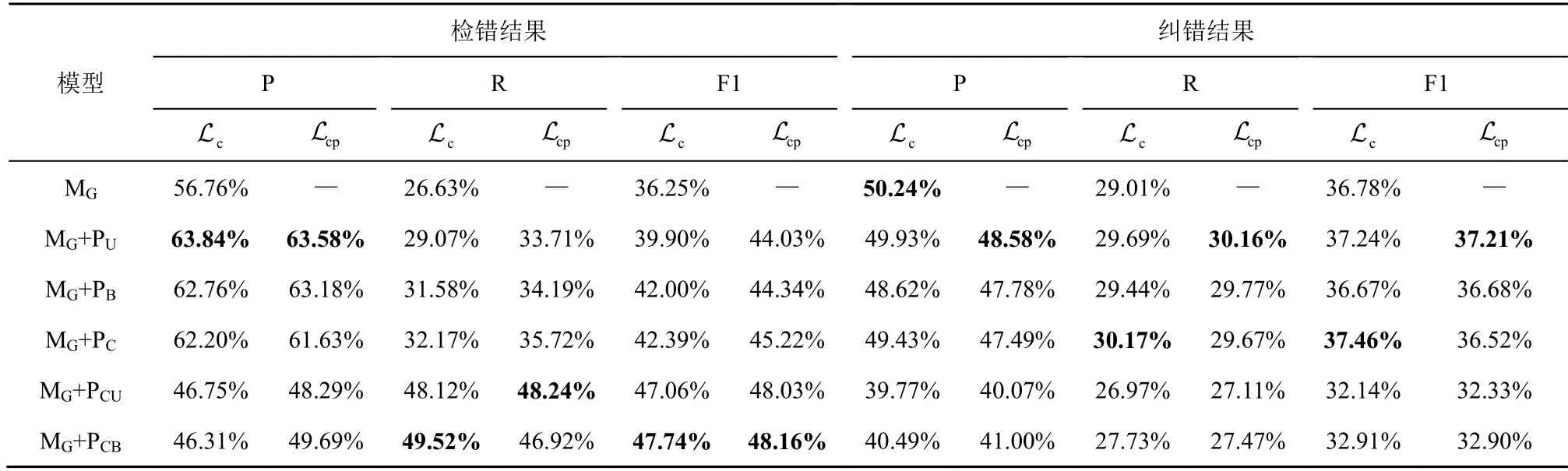
表6 基于CSPI 的模型使用不同优化目标时的文本校对性能对比结果
综上所述,在使用字符-拼音优化目标时,基于CSPI 的文本校对模型结合复杂拼音编码网络提取的音韵信息能够使其具备更好的文本错误检测能力。在使用字符优化目标时,基于CSPI 的文本校对模型结合简单拼音编码网络提取的音韵信息使其纠错能力占有一定的优势。
4.3.3 基于RPIF 的数据增强方法的影响
根据以上实验结果,本节选取单网络拼音编码模型MG+PC和混合网络拼音编码模型MG+PCB来验证基于RPIF 的数据增强方法对模型检错和纠错性能的影响。
算法1 所需输入参数如下。源语料库Cs为AISHELL-3 的训练集。汉字集Cc选用《通用规范汉字字典》[40]的一级字表和二级字表,共包含6 500 个常用汉字。单条语句的最大错误字符个数nmax=4,置换概率为P=1。目标语料库大小N分别设置为100 000、150 000 和200 000,记为10w、15w 和20w。MG+PC和MG+PCB使用不同大小目标语料库训练时的文本校对性能对比结果如表7 所示。表7 中,Origin 表示模型训练集为原始训练集大小。
由表7 可以看出,MG+PC和MG+PCB的检错召回率和F1 值随着目标语料库的增大而增大,其检错准确率也随目标语料库的增大有不同程度的提升。当训练集大小为20w 时,MG+PC和MG+PCB取得了最优检错F1 值,分别为49.57%和51.20%,相较使用原始训练集,其检错F1 值分别提升了4.35%和3.04%。这表明由基于RPIF 的数据增强方法获取的训练集能促使模型学习更多文本错误实例的音韵信息,进而加强了模型检测文本错误的能力。由表7 还可以看出,当模型使用同一语料库训练时,MG+PCB的检错结果始终优于MG+PC,这进一步验证了基于CSPI 的文本校对模型所结合的拼音编码网络的复杂度越高,其检错能力越好。
由表7 也可以看出,MG+PC和MG+PCB的纠错结果并未随着目标语料库的增大而增大。这是由于训练集中的混淆音错误字符随数据量增加而不断增多,模型学习的语义信息受到了影响。此外,从表7 还可以看出,MG+PC的各项纠错指标优于MG+PCB,这与表5 和表6 所反映的信息一致,基于CSPI 的文本校对模型结合简单拼音编码网络学习的音韵信息更有助于其纠正文本错误。
5 讨论
拼音携带的音韵信息有助于文本校对模型检测和纠正语音识别后的文本错误,这与文献[7,9]得出的结论一致。结合表5~表7 可以看出,基于CSPI的文本校对模型取得的最优检错F1 值比无拼音编码模型MC和MG分别高27.35%和14.95%;其最优纠错F1 值比MC和MG分别高4.23%和0.68%。由表5~表7 所示实验结果还可以看出,模型结合复杂拼音编码网络提取的音韵信息更有利于其检出文本错误,但模型的纠错性能会受到影响。本文认为这是一种音韵信息引起的过纠现象。模型结合复杂拼音编码网络能够提取到分辨力较强的音韵信息,进而提升了检测文本错误的灵敏度。但音韵信息过强会导致模型认为某些错误字符也能使句子在语音或语义上有意义,以致模型无法纠正此类文本错误。文献[30]中也提及了类似的问题。例如,“的”、“地”和“得”3 个字有相同的发音“de”,将语句中“地”替换为其他两者后,该语句依然有意义。
加大拼音编码网络的复杂度、加强模型训练过程中对音韵信息的优化、增加训练数据中混淆音文本错误的类别均能促使文本校对模型捕获较强分辨力的音韵信息,进而提升模型的文本检错能力。降低拼音编码网络的复杂度或在模型训练过程中适当减少对音韵信息的优化则有利于文本校对模型纠正文本错误。由表6 可以看出,基于CSPI 的文本校对模型结合任意一种拼音编码网络且使用字符-拼音优化目标时都能取得更好的检错性能;而当仅使用字符优化目标时,模型的纠错性能更好。这是由于仅使用字符优化目标能够在一定程度上削弱音韵信息引起的过纠现象。由表7 可以看出,基于CSPI 的文本校对模型结合复杂拼音编码网络且使用字符-拼音优化目标时,其检错性能随训练集中混淆音文本错误的增加有进一步提升。综上所述,本文建议借助音韵信息校对语音识别文本错误时,分开进行检错与纠错这2 个子任务,通过融合复杂拼音编码网络并在训练过程中加强对音韵信息的优化来提升文本校对模型的检错率,通过融合简单拼音编码网络或在训练过程中适当减少对音韵信息的优化来辅助提升文本校对模型的纠错率。

表7 基于CSPI 的模型使用不同大小目标语料库训练时的文本校对性能对比结果
文本长度较短及上下文语义缺失是语音识别文本校对任务的难点。由表5~表7 可以看出,各类模型的文本校对性能一般。本文认为这主要是由于来自ASR 系统的文本长度较短,模型很难根据句子的上下文语义来纠错。例如,“吃饭了吗”容易因用户发音不清晰被ASR 系统误识为“吃饭了啊”。若不考虑语境,可以认为后者是正确的,由此可见,模型校对此类短文本的难度较高。由表3可知,AISHELL 测试集中长度小于5 和小于10 的语句分别占12.91%和49.61%。此外,由表7 可知,当使用基于RPIF 的数据增强方法扩充模型的训练集后,模型的检错性能随着训练数据的逐步增加而不断提升,但其纠错性能却呈现随着训练数据的增加而降低的趋势,可能的原因有2 个,一个是训练数据中混淆音错误字符的增多加重了由音韵信息引起的过纠现象;另一个是本文用于验证拼音编码方法的文本校对模型的结构相对简单,模型学习语义信息的能力受限。在今后的工作中,尝试将大规模的预训练语言模型和拼音编码方法相结合来解决语音识别后的文本校对问题。
6 结束语
本文提出了PU、PB、PC、PCU和PCB这5 种拼音编码方法,并以此构建了基于CSPI 的文本校对模型,实现了同时利用句子的语义和音韵信息校对语音识别文本错误。针对标注数据有限造成许多先进的深度学习模型难以应用于语音识别文本校对任务的问题,本文提出了一种基于RPIF 的数据增强方法。在多人普通话语音数据集AISHELL-3 上进行了相关实验,实验结果表明,拼音携带的音韵信息有利于文本校对模型检测和纠正语音识别文本错误。基于CSPI 的文本校对模型使用混合网络拼音编码方法(PCU、PCB)所提取的音韵信息有利于其检测语音识别文本错误,使用单网络拼音编码方法(PU、PB、PC)所提取的音韵信息则更利于其纠正语音识别文本错误。所提数据增强方法能促使文本校对模型学习更多语音识别错误实例,有效地提升了模型检出语音识别文本错误的能力。在未来的研究工作中,笔者会尝试将预训练语言模型与不同的拼音编码方法相结合,分别用于语音识别文本错误的检测和纠正,以进一步辅助ASR 系统提升其识别准确性。
猜你喜欢
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
北方文学·中旬(2017年1期)2017-03-15
课外语文·下(2015年9期)2015-11-28
小天使·一年级语数英综合(2015年8期)2015-07-06
长江学术(2015年1期)2015-02-27
小天使·一年级语数英综合(2015年2期)2015-01-14
世界文学评论(2014年2期)2014-04-12
