
基于模态特异及模态共享特征信息的多模态细粒度检索
2023-01-09 14:28陈乔松陈鹏昌朴昌浩
计算机工程 2022年11期
李 佩,陈乔松,陈鹏昌,邓 欣,王 进,朴昌浩
(1.重庆邮电大学 计算机科学与技术学院,重庆 400065;2.数据工程与认知计算重庆市重点实验室,重庆 400065)
0 概述
在移动互联网时代,人们能够随时随自由地通过网络发布信息、传递信息和接收信息,这些信息中通常包含文字、音频、图片、视频等多模态数据。飞速增长的多模态数据带来了大量的跨模态检索应用需求,但这些跨模态检索需求不能由以文检文等单模态检索技术来解决,因此亟需发展适用于跨模态检索的理论、方法和技术。
近年来,深度神经网络在计算机视觉[1-2]、自然语言处理[3-4]、语音识别[5-6]等各个领域都取得了显著的成果,展现出了深度学习模型在处理不同模态信息时具有的优异特征提取能力。当前,基于深度学习的多模态检索逐渐成为多模态检索方法的主流。
在传统的多模态检索模型[7-9]中,一般针对不同的模态使用不同的神经网络提取特征向量,或者使用一个主干网络同时提取不同模态的特征向量。前者着重利用模态特异信息,但难以提取模态间联系与不同模态样本的共性,后者着重提取模态间联系与共性,但共性与联系只是所有数据的一小部分,造成了大量有效的模态特异信息的损失[10]。
针对以上问题,本文提出一种多模态细粒度检索框架MS2Net。通过提取并融合不同模态细粒度样本的模态特异信息及模态公共信息,得到包含丰富语义信息及模态间联系与共性的特征向量,并通过改进discriminate loss[11]、center loss[12]、triplet loss[13]等损失函数,将其组成适合多模态细粒度检索任务的目标函数。
1 相关工作
1.1 跨模态检索
跨模态检索的目标是用户给定任意一个样本作为查询样例,系统检索得到并反馈与查询样例相关的各个模态样本。目前主流的基于深度学习的跨模态检索方法过程是使用不同的分支网络提取不同模态数据的特征向量,再将这些不同模态数据提取出的特征向量映射到一个高维公共空间中,在该高维公共空间中,对不同模态的公共空间向量进行直接比较得到最佳匹配项。这种方法利用神经网络优异的特征提取能力消减了不同模态数据间的异构鸿沟,并利用在高维空间中的聚类函数消减不同模态数据间的语义鸿沟,达到较优的检索效果。在此基础上,文献[14]利用上述基本框架提取公共空间向量,并通过多目标函数的方式增强了公共空间向量的多模态检索性能,具体方法是通过监督学习保证分支网络提取的特征向量的质量,并设计目标函数减小同类别样本的类内差异,增加不同类样本的类间差异。文献[15]通过设置模态内的注意力机制及模态间注意力机制,建立图像中部分位置与文本中单词的强联系,来增强不同模态的相同类别样本间的语义相似性。文献[16]在公共空间中引入了对抗神经网络GAN 中的对抗思想,使得图像向量与文字向量尽可能地相融合。
1.2 细粒度检索
跨模态细粒度检索相较于跨模态检索的最大困难是样本类间差异小、类内差异大。为了解决这个问题,文献[17]通过对输入信息进行预处理的方式,建立样本不同部位图像与文字之间的强监督学习,进行多模态表征学习,并用于跨模态细粒度检索。文献[18]验证了使用单一主干网络不仅可以提取用于各模态数据分类的模态特异信息,还可以提取出不同模态数据间的联系,实现跨模态检索。同时,通过多任务目标函数的协作减小类内差异,增大类间差异,实现最优的多模态细粒度检索性能。
1.3 多模态表征学习
优秀的多模态表征学习能够有效地提取不同模态样本的有效信息,使得特征向量含有丰富的原始样本中的语义信息,能极大地提升后序检索工作的准确性。文献[19]在ReID 任务中同时利用了模态特异特征及模态共享特征,通过两个分支分别提取各个模态特异信息,将分支信息进行多损失函数约束的转换得到模态公共特征,再进行充分的特征融合,在ReID 任务中取得了较好的性能。文献[20]使用卷积神经网络提取图像特征,同时利用一个双阶段特征提取网络提取文本特征,具体是在第1 个阶段使用两个LSTM 分支分别提取食物实体以及长句子的特征,最后通过正则化联合两个特征得到菜单文本特征。
1.4 高维公共空间方法
将样本映射到高维公共空间是各种多模态任务中的重要方法,可以有效地化解不同模态数据之间的异构鸿沟,而对于检索任务,公共空间向量聚类效果的好坏,直接决定了多模态检索的效果。文献[21]通过监督学习保证特征向量的质量,再通过增大不同类别但相同模态样本对及不同类别不同模态样本对之间的类间距离,减少相同类别不同模态样本对之间的距离,对公共空间向量进行聚类。文献[22]则通过类别单词的预训练嵌入向量作为锚点,将提取出的对应类别的样本对的特征向量以这个锚点作为中心进行聚类。为了更有效地提高triplet loss 的训练效果,文献[23]通过L2 正则化将高纬空间向量限制在一个球形空间中,并通过预训练的音频锚点,保证了类别中心的稳定,增强了聚类效果。
2 本文方法
2.1 公式化


2.2 MS2Net 结构
2.2.1 多模态特征提取
若要实现多模态检索,则首要任务是必须有效地提取多模态数据的特征。相较于传统方法通常只提取模态特异特征,多模态特征应同时具备模态特异信息及模态共享信息,本文使用模态共享主干网络及模态特异分支网络分别提取这两种特征信息。
由于在数据预处理阶段,图像、视频及音频模态的数据都被转换成了四维矩阵的图像形式,文本模态数据也通过卷积神经网络升维成了四维矩阵,因此本文采用计算机视觉领域常见的基准网络作为主干网络进行监督分类实验,目的是为了选择对样本特征提取能力更强的网络,更利于模型学习到共享信息。
MS2Net 的特征提取部分由1 个主干网络及4 个分支网络构成,主干网络层数过深或者结构过于复杂会导致模型无法收敛或者训练时间超出预期,ResNet-50 网络结构简单,参数量不大,更适合用于进行端到端学习,考虑到分类精度和训练难度的平衡,本文最终采用在ImageNet 上预训练的ResNet-50作为主干网络的初始状态。
MS2Net 框架包含4 个分支网络,为了减少整个网络的参数量,需要选择轻量级网络,同时MixNet-S[24]中的深度混合卷积包含不同大小的卷积核,不仅保证了提取图像特征时精度与参数量的平衡,还在提取矩阵形式的声音及文本特征时,能够提取到不同范围内的时序特征,在多种轻量级网络中进行监督分类的效果最佳。
MS2Net 网络结构如图1 所示。

图1 MS2Net 网络结构Fig.1 MS2Net network structure
监督分类实验结果如表1 所示(加粗数字为最优值)。可以看出,MixNet-S 在单独一个模态的F1-score 指标明显高于ResNet-50,但是当MixNet-S 作为主干网络进行多模态分类时,平均F1-score 指标不及ResNet-50 的50%。
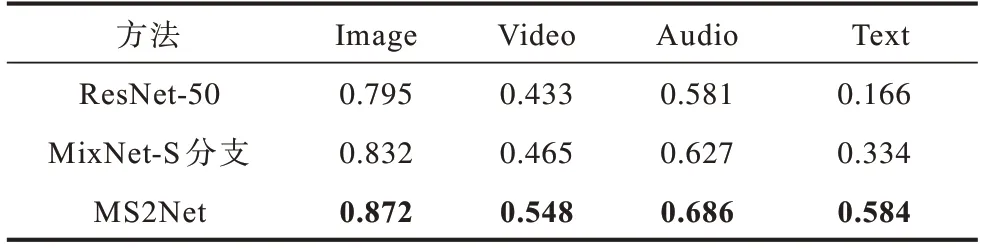
表1 多跨模态监督分类的F1-score 值Table 1 F1-score values of multi-span modal supervised classification
从实验结果可以看出,主干网络ResNet-50 提取的是各个模态共有的粗粒度共有特征,能同时对4 个模态的数据进行分类,而分支网络专注于提取单个模态的细粒度特异特征信息,因此在特定模态分类效果上明显优于主干网络,结合主干网络的粗粒度特征及分支网络的细粒度特征,经过多模态特征融合模块之后,MS2Net 的效果相较于主干网络ResNet-50 提升了36.2%,进一步佐证了模态特异特征及模态共享特征思想的有效性。同时,模态共享主干网络及模态特异分支网络可以根据实际情况进行更换,模态特异分支还可以根据实际数据中的模态数量进行增减,使得整个网络具有良好的可扩展性及鲁棒性。
2.2.2 多模态特征融合
在得到多模态特征向量后,需要有效地利用多模态特征向量。相较于传统方法将不同模态样本特征进行拼接后直接传入映射层中,本文的方法在多模态特征融合更注重于不同模态信息的充分混合及高效利用,在多模态融合模块中,先将各个模态的模态特异特征与模态公共特征进行拼接,通过注意力机制[25],使得模型能更有效地选择信息。最终对于每个模态产生一个模态融合特征,即zi=映射层使用全连接层,将模态融合特征映射到d3维度,即
通过以上的操作,将4 种不同模态的数据分别提取了模态共享特征及模态特异特征,并对这两个特征进行了特征融合,最后将其融合之后的特征映射到公共空间中,并通过multi-center loss 函数进行聚类。
多模态特征融合模块结构如图2 所示。
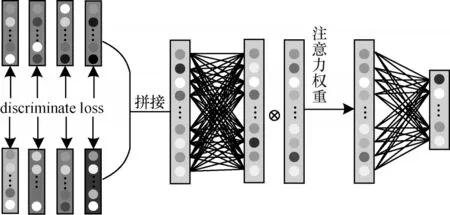
图2 多模态特征融合模块结构Fig.2 Structure of multi-modal feature fusion module
2.3 损失函数
损失函数的目标是引导上述网络结构来学习一种语义映射,可以将同类别的样本映射到公共空间中距离相近的区域,即使这些样本属于不同的模态。
为了使得模型能区分细粒度样本的所属类别,本文方法首先通过ohem loss 函数来进行监督学习,并且通过将易分类样本cross entropy loss 函数值置0,使得模型更加专注于学习相似样本间的细节差异。其次为了使提取出来的模态共享特征与模态特异特征包含不同的信息,使用discriminate loss 函数来加大这两种信息的差异,最后通过multi-center loss 函数对映射到公共空间中的向量进行聚类。相较于传统的center loss 函数,multi-center loss 函数给每个模态数据都分配一个类别中心,通过类别中心之间的距离减小,间接地聚合不同模态数据。以上3 个loss 函数的组合,使得本文方法在高位空间中克服了不同模态数据间的语义鸿沟及异构鸿沟,使不同模态下的同类别样本相较于同模态的不同类别样本能够呈现更相似的特征向量。
2.3.1 supervised loss 函数
监督学习是保证网络提取特征向量的质量的重要手段,同时为了驱使网络学习细粒度样本间的细节信息,本文方法选用ohem loss 函数,如式(1)所示,即在原始的cross-entropy 函数的基础上,对每个batch 的样本只学习损失较大的一部分样本,使得模型更加专注于提取不同样本间的细节差异。
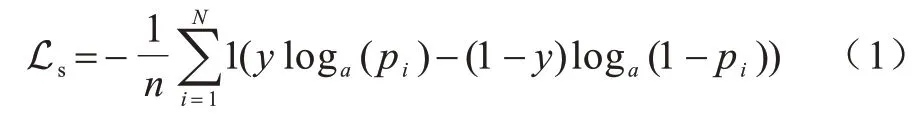
其中:y是样本的label 值;pi是网络的输出值;1(·)为指示函数,如果loss 值大于阈值,则值为1,否则值为0。
2.3.2 discriminate loss 函数
为了避免主干网络及分支网络学习到过于相近的特征,本文方法使用discriminate loss 函数,如式(2)所示,保证主干网络提取的信息与分支网络提取的信息既包含足够多的样本特征信息,又具有足够的差异性。

其中:Φi=为特征相似性函数,用于计算模态公共特征向量和模态特异特征向量的相似性;δ(·)为sigmoid 函数,即y=为 一个自 定义阈值,当模态共享特征向量和模态特异特征向量的相似性小于该阈值时,模型不再计算其的loss。随着vi与ui的相似度越来越高,即δ(Φi)越大,Ldis值也越大。因此,discriminate loss 函数在确保模态公共特征向量和模态特异特征向量质量的基础上,同时保证这两个向量的差异性,使得MS2Net 提取的特征向量包含原始样本中更全面的信息。
2.3.3 multi-center loss 函数
为了更好地提高多模态细粒度检索效果,不同模态的相同类别样本向量,相较于同模态不同类别样本向量在公共空间中应该更加相邻,但是在多模态场景下,不同模态样本在公共空间中概率分布相差较大,传统center loss 函数的聚类能力有限,所以本文针对多模态聚类场景设计了multi-center loss 函数,通过在每个类别的所有模态中都分别引入一个类内中心,提升整体的聚类效果,计算公式如式(3)所示:

其中:表示m模态的第i个样本向量;表示该样本向量在m模态下的类内中心;Cy为y类别下的所有模态的类内中心;μ是权重参数;D(·)为类内中心的距离函数。
D(·)计算公式如式(4)所示:
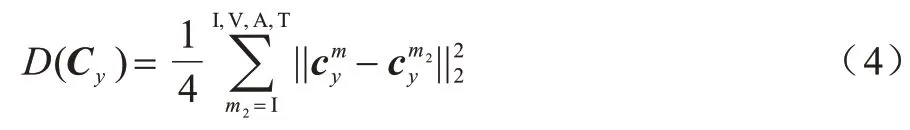
multi-center loss 函数的思想可以概括为:先将相同模态、相同类别的样本分别聚集到该模态下的类内中心周围,再通过减小不同模态、相同类别的类内中心的距离,间接地将不同模态、相同类别的样本聚集到一起。
综上所述,最终目标函数定义如式(5)所示:

目标函数由3 个经典的损失函数改进组成,更加适合于多模态细粒度检索的场景,在下文的消融实验中将证明该目标函数的有效性。
3 实验
为了验证本文提出方法的有效性,在公开数据集FG-Xmedia 上进行实验,首先和之前的最优结果进行对比,然后对MS2Net 进行更深入的分析,包括各个组件的消融实验以及通过降维的公共空间向量可视化。
3.1 数据集
本文使用的数据集是当前唯一的跨四模态细粒度检索公开数据集FG-Xmedia,该数据集的图像部分采用CUB-200-2011[26],视频部分采用YouTube Bird[27],并从公开数据集上收集了相应的文本和音频部分。总地来讲,该数据集包含了“鸟类”这一粗粒度大类中的200 种细粒度子类的4 个模态的信息,分别为11 788 张图像、8 000 段文本、18 350 个视频及12 000 段音频。
数据集的划分方法如下:对于图片数据集,训练集包含5 994 张图片,测试集包含5 794 张图片;对于视频数据集,训练集包含12 666 个视频,测试集包含5 684 个视频;对于音频数据集,训练集和测试集同时包含6 000 份音频;对于文本数据集,训练集和测试集同时包含4 000 份文本。
3.2 数据处理
为了降低模型训练难度及尽量消除数据的异构性,使得主干网络可以统一提取不同模态的公共特征,音频数据通过傅里叶变换转化为频谱图,文字通过词嵌入转换为一维词向量,再通过卷积操作拼接成为类图像的矩阵形式。视频通过抽帧的方式转换为图像形式,这样4 种数据都可以被组织成为相同的矩阵形式传入到主干网络中。
3.3 评价指标
对于多模态细粒度检索任务,本文使用平均精度均值(mean Average Precision,mAP)分数来衡量其性能,首先对于每一个查询样例计算其平均准确率,然后再计算这些平均准确率的平均值,作为mAP 查询分数。
为了更加全面地了解模型的检索效果,需要分别计算每个模态对于其他单个模态的检索分数,并计算每个模态对其他所有模态的检索分数。
3.4 实现细节
MS2Net 使用ResNet-50 作为主干网络,将Mixnet-L 作为分支网络,数据经过预处理后由这两个网络提取特征向量,之后通过一个512 维的全连接层映射到公共空间,公共空间向量再通过一个200 维的全连接层,以类别为标签进行监督学习。
网络使用PyTorch 编写,并通过RTX-2070 显卡训练。在训练过程中使用SGD 优化器,初始学习率设置为3e-3,学习率衰减策略使用PyTorch 框架提供的ReduceLROnPlateau 策略,并训练200 轮。
3.5 实验结果
表2 所示为某模态数据作为查询样本对其他某单一模态的样本进行检索的mAP 值结果(加粗数字为最优值),箭头左右两端分别代表查询样本的模态及待检索的目标模态,可以看到MS2Net 在大多数模态的检索任务中都明显优于FGCrossNet 算法。在I→T、T→I、T→V、V→T、A→T 等场景例中,MS2Net相较于FGCrossNet 算法提升超过100%。整体上一对一模态检索的平均检索mAP 值相较FGCrossNet算法提升了65%。
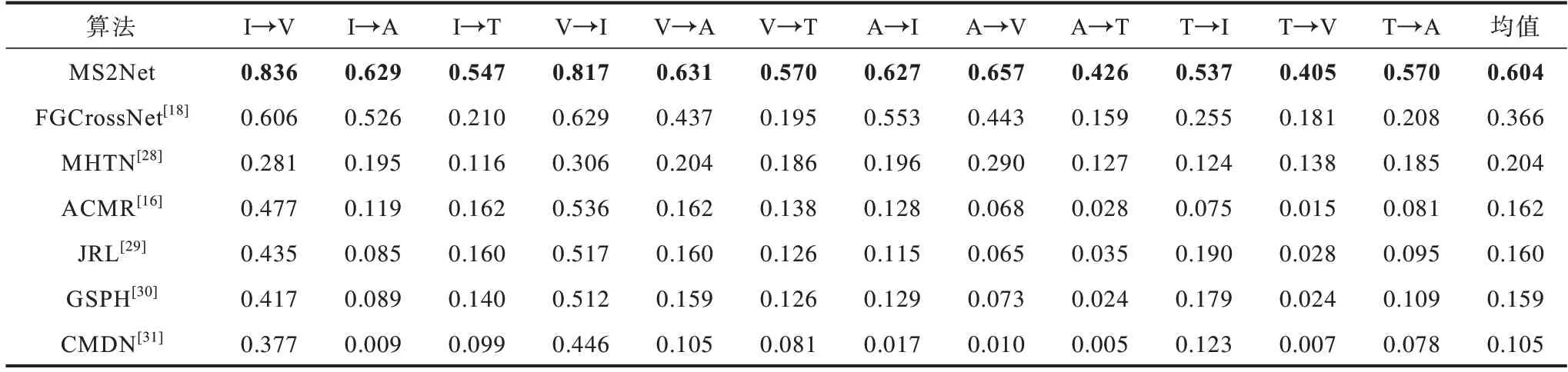
表2 一对一跨模态检索的mAP 值Table 2 mAP values of one-to-one cross-modal retrieval
表3 所示为某一个模态数据作为查询对其他所有模态检索的mAP 值(加粗数字为最优值),该项测试中T→ALL 相较于FGCrossNet 算法提升超过100%,其他场景也有明显提升。整体上多模态的平均检索mAP 值相较FGCrossNet 算法提升48%,充分证明了MS2Net 在多模态细粒度检索任务上的有效性。

表3 一对多跨模态检索的mAP 值Table 3 mAP values of one-to-all cross-modal retrieval
3.6 消融实验
为了验证MS2Net 中各个组件的有效性,本文进行了消融实验,结果如表4 和表5 所示(加粗数字为最优值),MS2Net 表示利用MS2Net 网络提取并直接拼接使用模态公共特征及模态特异特征得到的结果,MMFM 表示引入注意力机制优化了特征融合过程,并使用单独的映射层输出的512 维的向量作为公共空间向量。由消融实验结果可知,经过特征融合和注意力机制之后单模态检索性能提升13.5%,多模态检索性能提升19%,multi-center loss 函数表示使用本文提出的multi-center loss 函数替代传统的center loss 函数对公共空间向量进行聚类。一对一跨模态检索实验与一对多跨模态检索实验性能分别提升10%与8%。

表4 一对一跨模态检索的消融实验结果Table 4 Ablation experiment results of one-to-one cross-modal retrieval
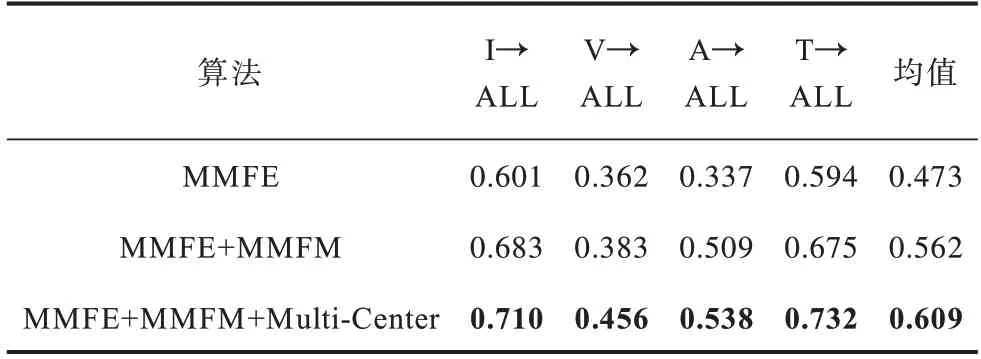
表5 一对多跨模态检索的消融实验结果Table 5 Ablation experiment results of one-to-all cross-modal retrieval
消融实验的结果验证了联合模态间共性与模态特性思路及本文提出的multi-center loss 函数的有效性。同时也可看出,高维公共空间向量相较于同类别数相等维度的特征向量,在检索任务中更合适作为原始样本的表达形式。
3.7 聚类效果可视化
为展示改进后multi-center loss 的聚类效果,本文对其进行了可视化分析,聚类结果可视化结果如图3 所示。

图3 降维可视化图聚类结果示意图Fig.3 Schematic diagram of clustering result of dimensionality reduction visual view
为了直观地感受不同方法产生的公共空间向量的聚类情况,本文统一使用VTSne 算法对数据集中前5 个类别产生的高维向量进行降维。
在上述图像中,相同的灰度代表样本属于相同的类别,相同的形状表示样本属于相同的模态。多模态细粒度检索的困难就是类间差异小和类内差异大,这在图3(a)中可以清晰地看到,各个模态的样本相互混杂,公共空间向量没有以类别为中心聚集,图3(b)为采用了MS2Net 及center loss 函数之后的结果,因为特征向量质量的提升与类别中心的引入,聚类效果相较于之前有明显提升,图3(c)为采用multi-center loss 函数替换center loss 函数,可以看到,同类别之间的公共空间向量,相较于图3(b)聚集的更加紧密,不同类别的公共空间向量在高维空间中的分布也更加稀疏,验证了multi-center loss 函数在多模态数据聚类中的有效性。
4 结束语
本文提出一种多模态细粒度检索方法,该方法包括MS2Net 多模态特征提取框架及相应的目标函数。MS2Net 通过利用模态公共特征及模态特异特征提升公共空间向量的性能,同时给出目标函数组合,通过监督学习保证特征的质量和模态公共特征及模态特异特征的可区分性,从而进行有效的多模态特征向量聚类。消融实验结果表明,MS2Net 性能明显提高,验证了各组件的有效性。由于当前多模态检索的数据集稀少,且数据集达标成本明显高于单模态数据集,下一步利用当前的公开数据集对多模态特征提取网络进行预训练,并加入判别器网络判断样本对类别,以提高在无标签检索数据集上的检索效果。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
红外技术(2022年11期)2022-11-25
保定学院学报(2022年2期)2022-04-07
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
安阳工学院学报(2020年2期)2020-06-05
数学大世界(2019年7期)2019-05-28
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
中华建设(2017年1期)2017-06-07
