
Transformer在计算机视觉领域的研究综述
2023-01-13 11:56魏宏杨钱育蓉
计算机工程与应用 2023年1期
李 翔,张 涛,张 哲,魏宏杨,钱育蓉
新疆大学 软件学院,乌鲁木齐 830002
Transformer[1]是一种基于自注意力机制的模型,不仅在建模全局上下文方面表现强大,而且在大规模预训练下对下游任务表现出卓越的可转移性。这种成功在机器翻译和自然语言处理(NLP)领域上得到了广泛的见证。2018年,Devlin等人[2]在Transformer的基础上提出了基于掩码机制双向编码结构的Bert模型,在多种语言任务上达到了先进水平。此外,包括Bert在内许多基于Transformer的语言模型,如GPTv1-3[3-5]、Ro-BERTa[6]、T5[7]等都展现出了强大的性能。
在计算机视觉任务中,由于CNN固有的归纳偏好[8],如平移不变性、局部性等特性,一直占据着主导地位(CNN[9]、ResNet[10]等)。然而CNN有限的感受野使其难以捕获全局上下文信息。受Transformer模型在语言任务上成功的启发,最近多项研究将Transformer应用于计算机视觉任务中。Parmar等人[11]基于Transformer解码器的自回归序列生成或转化问题提出了Image Transformer模型用于图像生成任务。Carion等人[12]基于Transformer提出了DETR(一种端到端目标检测),其性能取得了与Faster-RCNN相当的水平。最近Dosovitskiy等人[13]提出的另一个视觉Transformer模型ViT,在结构完全采用Transformer的标准结构。ViT在多个图像识别基准任务上取得了最先进的水平。除了基本的图像分类之外,Transformer还被用于解决各种其他计算机视觉问题,包括目标检测[14-15]、语义分割[16]、图像处理和视频任务[17]等等。由于其卓越的性能,越来越多的研究人员提出了基于Transformer的模型来改进广泛的视觉任务。
目前,基于Transformer的视觉模型数量迅速增加,迫切需要对现有研究进行整体的概括。在本文中,重点对视觉Transformer的最新进展进行全面概述,并讨论进一步改进的潜在方向。为了方便未来对不同结构模型的研究,将Transformer模型按结构分类,主要分为纯Transformer、CNN+Transformer混合结构以及利用Transformer改进的CNN结构。
虽然Transformer在计算机视觉领域上展现了其先进的性能,但也面临着参数量大、结构复杂、尺寸大小不可调节等问题。本文分别从训练技巧、补丁嵌入、自注意力机制、金字塔架构等多方面介绍了Transformer的各种改进结构。在本文最后一部分,给出了结论和面临的一些问题,并对未来的发展方向进行展望。
1 Transformer基本结构
2017年,Vaswani等人[1]首次提出了Transformer模型(如图1所示),它是由6个编码器-解码器模块组成,每个编码器模块由一个多头自注意层和一个前馈神经网络层组成;每个解码器模块由三层组成,第一层和第三层类似于编码器模块,中间是交叉注意力层,该注意力层k、v的输入是由相应编码器模块的输出组成。本章主要对Transformer中各个模块的特点进行介绍。
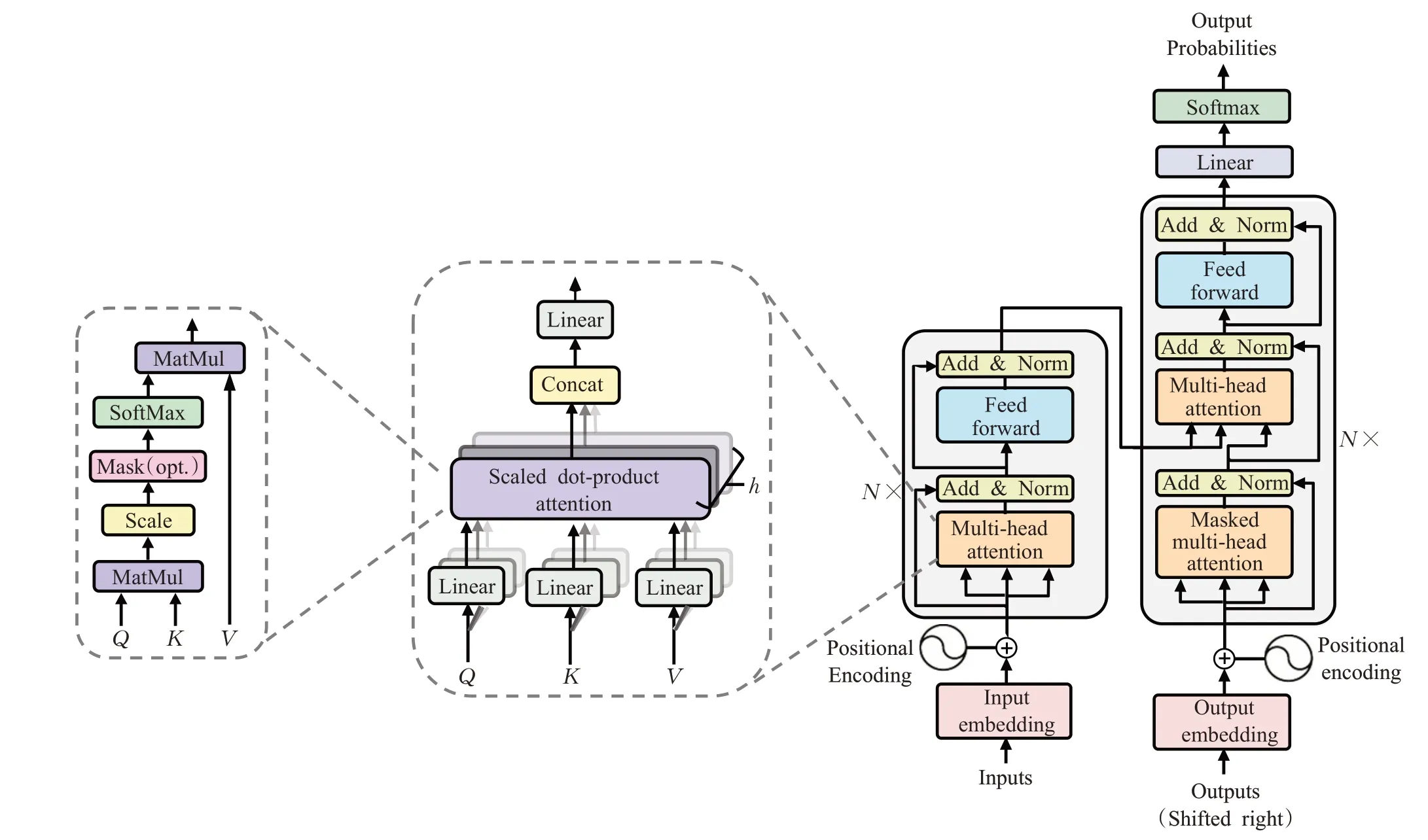
图1 Transformer整体结构Fig.1 Transformer overall structure
1.1 位置编码
由于Transformer的输入是一种单词(句子)特征序列(这种序列具有置换不变性),而Transformer中Attention模块是无法捕捉输入的顺序,因此模型就无法区分输入序列中不同位置的单词。为了得到输入序列的位置信息,Transformer将位置编码添加到输入序列中以捕获序列中每个单词的相对或绝对位置信息。
(1)绝对位置编码
绝对位置编码通过预定义的函数生成[1]或训练学习得到[2],具有与输入序列相同的维度,采用相加操作将位置信息添加到输入序列中。文献[1]中使用交替正弦函数和余弦函数来定义绝对位置编码,其公式如下:
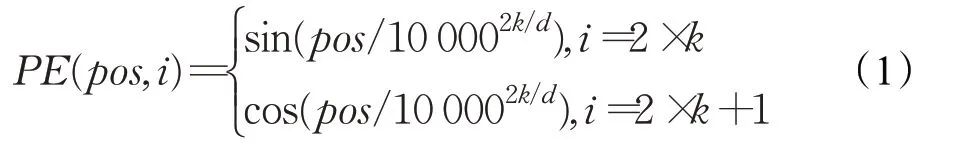
其中pos是目标在序列中的位置,i是维度,d是位置编码维度。
(2)相对位置编码。
相对位置编码不同于绝对位置编码直接在其输入序列加入位置信息,而是通过扩展自我注意机制,以有效地考虑相对位置或序列元素之间的距离。在计算Attention时考虑当前位置与被Attention位置的相对距离。文献[18]中考虑输入元素之间的成对关系在注意力计算中加入了相对位置向量Ri,j,公式如下:
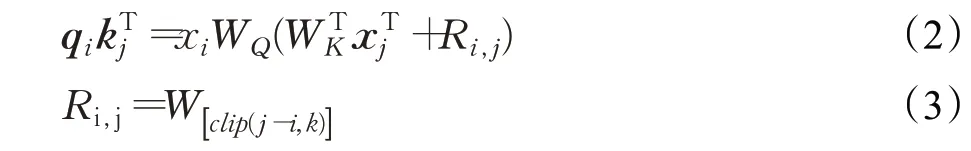
对Ri,j设置了截断、丢弃长远距离的无效信息,从而减少了计算量,可以使模型泛化到在训练过程中未见的序列长度。
其他方式的位置编码。除了上述方法之外,还有一些其他类型的位置编码,例如递归式的位置编码[19]、CNN式位置编码[20]、复数式位置编码[21]、条件位置编码CPVT[22]等。
1.2 自注意力机制
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛应用于自然语言处理、语音和计算机视觉等领域。注意力机制现在已成为神经网络领域的一个重要概念。其快速发展的原因主要有3个:首先,它是解决多任务较为先进的算法;其次,被广泛用于提高神经网络的可解释性;第三,有助于克服RNN中的一些挑战,如随着输入长度的增加导致性能下降,以及输入顺序不合理导致的计算效率低下。
自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性,通过对序列中元素之间的所有成对交互关系进行建模,让机器注意到整个输入中不同部分之间的相关性。自注意力层通过定义3个可学习的权重矩阵{WQ,WK,WV},将输入序列投影到这些权重矩阵上,得到三元组Q=XWQ,K=XWK,V=XWV。自注意力计算公式如下:
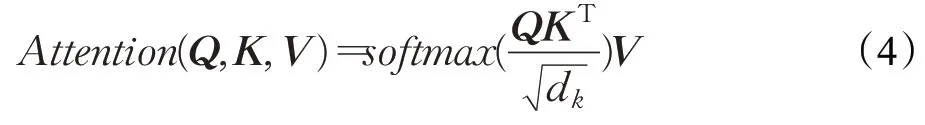
其中dk等于矩阵K的维度大小。
(1)多头注意力
多头注意力(如图1左部分)是在单头注意力的基础上将输入序列X在其通道维度上划分成h个头,即[B,dim]→[B,h,dim/h]。每个头使用不同的可学习权重{WQi,WKi,WVi},对应生成不同的{Qi,Ki,Vi}组。由于注意力在不同的子空间中分布不同,使用多头注意力机制可以形成多个子空间,从而将输入映射到不同的空间中,使模型学习到输入数据之间不同角度的关联关系。多头注意力总的参数量不变只改变每个头的维度,计算量和单头自注意力相当。
多头自注意力机制中并行使用多个自注意力模块,不同头部关注不同的信息(如全局信息和局部信息)可以丰富注意力的多样性,从而增加模型的表达能力。
(2)局部注意力
局部注意力仅在相邻的部分区域内执行注意力,解决了全局注意力计算开销过大的问题。对于视觉图像平面空间上局部区域计算,Parmar等人[11]提出了2D局部注意力模块,网络可以更均匀地平衡水平和垂直方向相邻空间上的局部上下文信息(如图2所示),大大降低了计算复杂度。其中,图2(a)是local attention整体结构(由局部注意力和前馈网络组成),输入一个单通道像素q,预测生成像素q′。mi表示先前预测生成的像素块,pq和pi是位置编码。图2(b)是2D local attention执行过程图。q表示最后预测生成的像素,白色网格表示对预测位置贡献为0具有屏蔽作用,青色矩形为最后生成的所有像素区域。
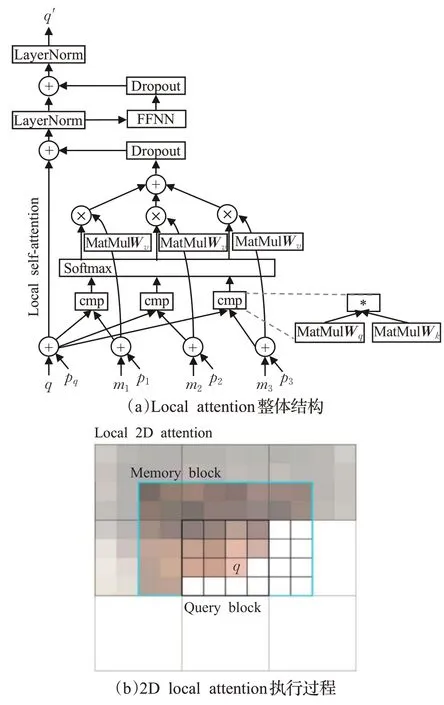
图2 局部注意力Fig.2 Local attention
(3)稀疏注意力机制
局部注意力虽然可以减少计算量,但其无法捕获全局上下文信息。Child等人[23]提出了稀疏注意力机制,通过top-k选择将全局注意退化为稀疏注意。这样可以保留最有助于引起注意的部分,并删除其他无关的信息。这种选择性方法在保存重要信息和消除噪声方面是有效的,可以使注意力更多地集中在最有贡献的价值因素上。稀疏注意力有两种方式,第一种步长注意力(如图3(c)所示)是在局部注意力的基础同时每隔N个位置取一个元素进行注意力计算。但是对于一些没有周期性结构的数据(如文本),步长注意力关注的信息可能与该元素并不一定是最相关的信,可以采用固定式注意力(如图3(d)所示)将先前预测的特定位置的信息传播到未来所有需要预测的元素中,具体公式如下:
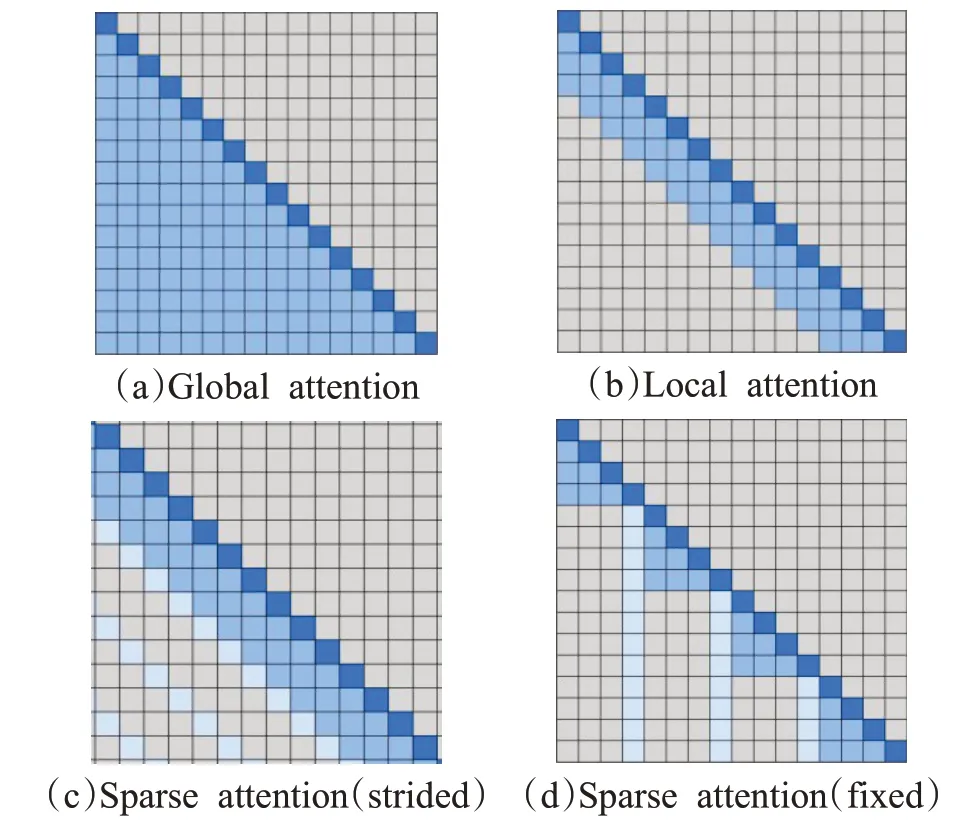
图3 4种注意力方案Fig.3 Four attention schemes
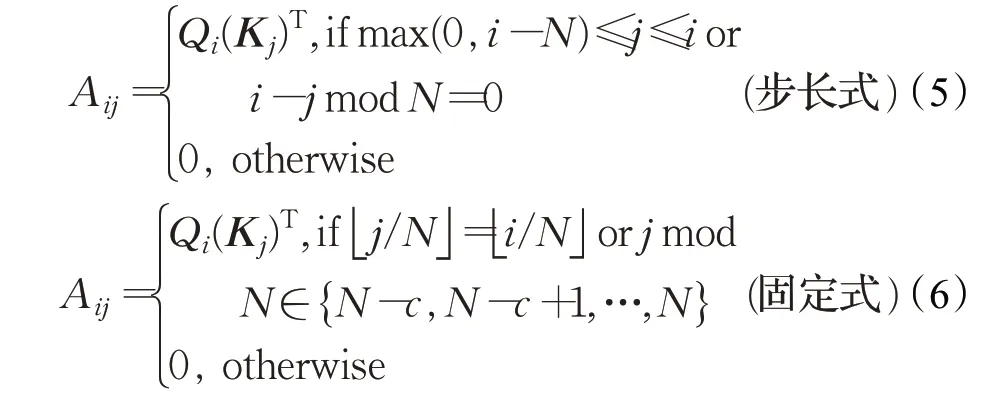
其中c是超参数。
1.3 前馈神经网络及其层归一化
Transformer中除了注意力子层之外,每个编码器和解码器都包含一个完全连接的前馈神经网络,该模块由两个线性层组成,中间包含一个ReLU激活层。前馈网络对序列中不同位置的元素使用相同的处理方式,虽然不同位置的线性变换是相同的,但它们在层与层之间使用不同的参数。其计算公式如下:
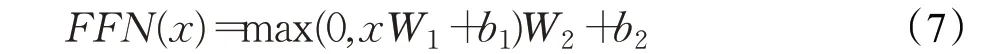
其中,输入输出维度是512,内层的维度是2 048。
随着网络深度的增加,数据的分布会不断发生变化。为了保证数据特征分布的稳定性,Transformer在注意力层和前馈网络层之前加入layer normalization层,这样可以加速模型的收敛速度,该过程也被称为前归一化,其计算公式如下:
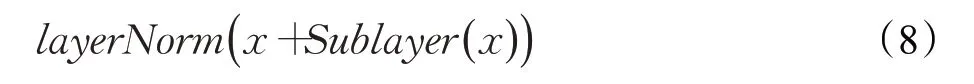
然而每个残差块输出的激活值被直接合并到主分支上。随着层数的加深该激活值会逐层累积,使得主分支的振幅会越来越大。导致深层的振幅明显大于浅层的振幅,而不同层中振幅的差异过大会导致训练不稳定。为了缓解这个问题,Swin-Transformer v2[24]提出一种后归一化处理,将layer normalization层从每个子层之前移到每个子层之后,这样可以使得每个残差块的输出在合并回主分支之前被归一化。当网络层数增加时,主分支的振幅不会累积,其激活幅度也比原始的前归一化处理要温和得多,可以大大提高大型视觉模型的稳定性。
2 视觉Transformer
2.1 Transformer在视觉上的应用
本节重点从图像分类、目标检测两个应用场景出发,介绍了Transformer在视觉任务上一些应用以及相应的改进方法。
2.1.1 图像分类ViT网络及其改进
Dosovitskiy等人[13]首次提出了ViT(如图4所示),将原始的Transformer应用于图像分类任务,是一种完全基于自注意力机制的纯Transformer结构,网络结构中不包含CNN。
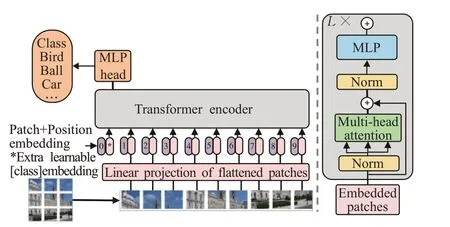
图4 视觉Transformer(ViT)Fig.4 Vision Transformer(ViT)
对于输入的2D(X∈RC×H×W)图像数据,ViT将其重新塑造成一系列扁平的2D图像块XP∈Rn×(p2×C),其中C是通道数。将输入分辨率为(H,W)的原始图像,划分为每个分辨率为(p,p)的图像块(补丁),其有效的输入序列长度为n=HW/p2。ViT也采用了与Bert类似的[class]分类标记,该标记可以表示整个图像的特征信息,被用于下游的分类任务中。ViT通常在大型数据集上预训练,针对较小的下游任务预训练。在ImageNet数据集上取得了88.55% Top-1的准确率,超越了ResNet系列模型,打破了CNN在视觉任务上的垄断,相较于CNN具有更强泛化能力。
ViT取得了突破性的进展,但在机器视觉领域中也有其缺陷:(1)ViT输入的token是固定长度的,然而图像尺度变化非常大;(2)ViT的计算复杂度非常高,不利于具有高分辨率图像的视觉应用。针对这些问题,Liu等人[25]提出了Swin Transformer,通过应用与CNN相似的分层结构来处理图像,使Transformer模型能够灵活处理不同尺度的图片。Swin Transformer采用了窗口注意力机制,只对窗口内的像素区域执行注意力计算,将ViT token数量平方关系的计算复杂度降低至线性关系。
2.1.2 目标检测DETR网络及其改进
Carion等人[12]提出的DETR,使用CNN主干网络提取紧凑特征表示,然后利用Transformer编码器-解码器和简单的前馈网络(FFN)做出最终的目标检测任务(如图5所示)。DETR将目标检测视为集合预测问题,简化了目标检测的整体流程,将需要手动设计的技巧如非极大值抑制和锚框生成删除,根据目标和全局上下文之间的关系,直接并行输出最终的预测集,实现了端到端的自动训练和学习。在COCO[26]数据集上,DETR的平均精确度AP为42%,在速度和精度上优于Faster-RCNN。
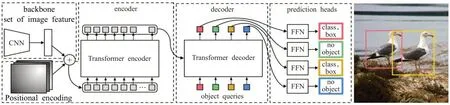
图5 DETR模型结构Fig.5 DETR model structrue
DETR具有良好的性能,但与现有的CNN模型相比,它需要更长的训练周期才能收敛。在COCO基准测试中,DETR需要迭代500次才能收敛,这比Faster R-CNN慢10到20倍。Zhu等人[14]提出的Deformable DETR模型,结合了形变卷积[27]稀疏空间采样的优点和Transformer长远关系建模提出了可变形注意模块,该模块只关注所有特征图中突出的关键元素,可以自扩展到聚合多尺度特征,而无需借助FPN(特征金字塔)模块[28],取得了比DETR更好的结果且训练收敛速度也更快。Sun等人[29]表明导致DETR收敛缓慢的主要这些问题提出了两种解决方案,即TSP-FCOS和TSP-RCNN。该方法不仅比原始DETR收敛速度快得多,而且在检测精度和其他基线方面也明显优于DETR。
其次,DETR在检测小物体的性能上相对较低。目前目标检测模型通常利用多尺度特征从高分辨率特征图中检测小物体,然而高分辨率特征图会导致DETR不可接受的复杂性。Zheng等人[30]提出的ACT模型,一种自适应聚类注意力,通过使用局部敏感哈希(LSH)自适应地对查询特征进行聚类,并使用原型键在查询键交互附件进行聚类,降低了高分辨率图像的计算成本,同时在准确性上也取得了良好的性能。
2.1.3 其他应用方面
其他基于Transformer在视觉各领域中的应用:有Image Transformer模型用于图像生成任务;SETR用于图像分割模型,使用Transformer编码器替换基于堆叠卷积层的编码器进行特征提取;ViT-FRCNN[31]模型主要是将ViT与FRCNN的结合用于大型目标检测任务中。有基于掩模的视觉Transformer(MVT)[32]用于野外的面部表情识别任务。表1对Transformer不同的应用场景进行了分类。
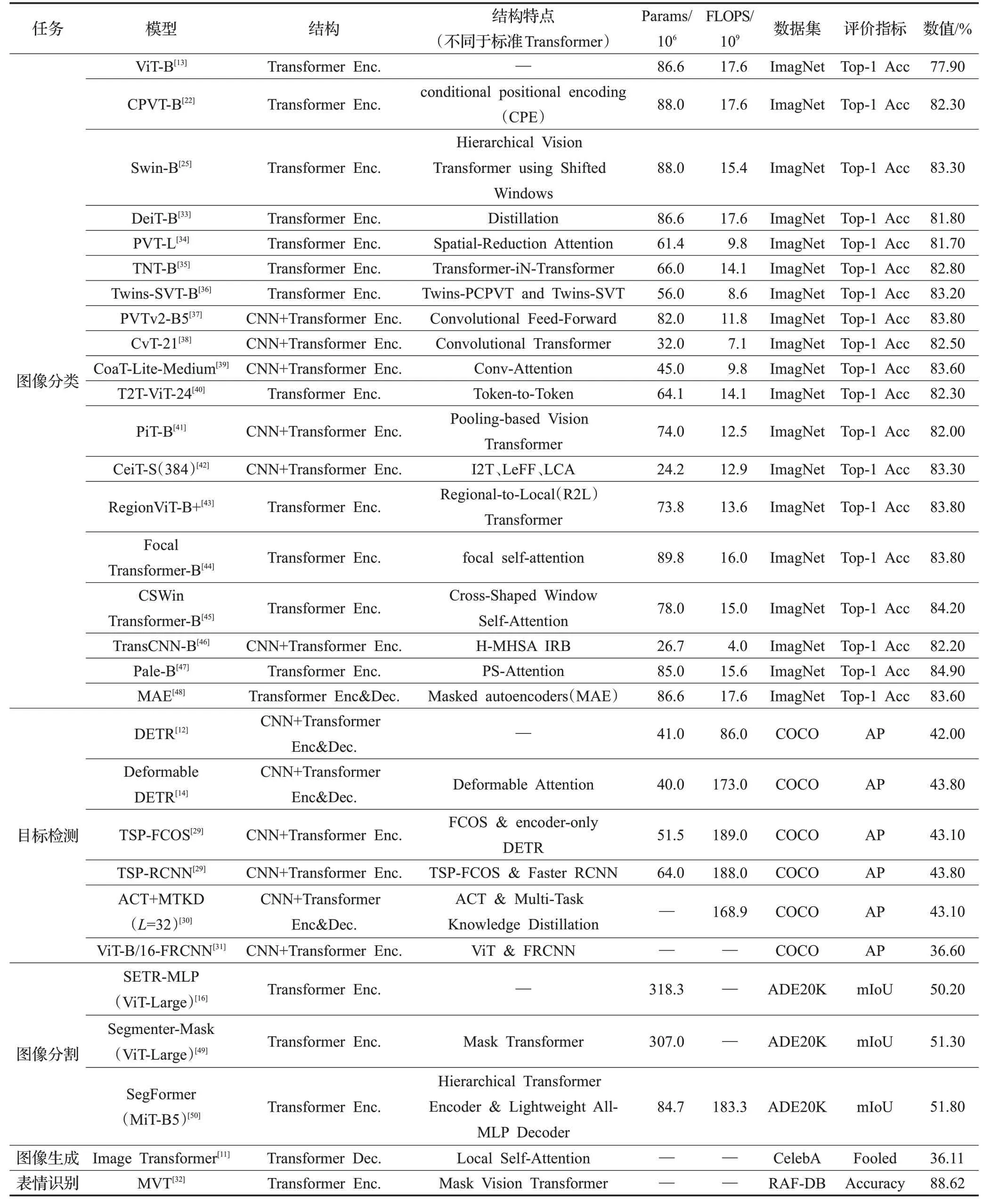
表1 关于Transformer在视觉任务中的应用Table 1 About application of Transformer in visual tasks
2.2 基于Transformer泛化性能不足的改进
本节介绍了提高Transformer泛化性能的改进方法。现有的工作主要在知识蒸馏、特征融合、样本量以及泛化能力几个方面Transformer提出各种改进进行研究。
2.2.1 基于知识蒸馏的改进
知识蒸馏可以解释为将教师网络学到的信息压缩到学生网络中。Touvron等人[33]提出的DeiT(如图6所示)在Transformer的输入序列中加入了蒸馏token,该蒸馏token与分类token地位相当都参与了整体信息的交互过程,蒸馏token通过使用Convnet教师网络对比学习,可以将卷积的归纳偏好和局部性等特性融合到网络中使DeiT更好地学习。蒸馏学习的过程有两种方式:一种是hard-label蒸馏,直接将教师网络的输出坐标标签;另一种是使用KL散度衡量教师网络和学生络的输出。实验结果表明,Transformer通过蒸馏策略可以取得更好的性能。
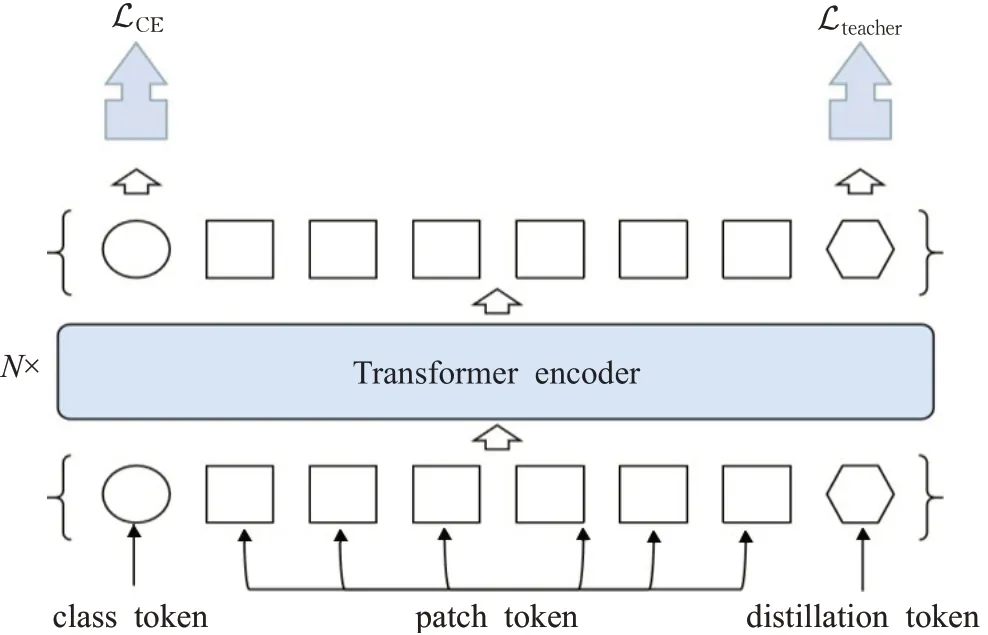
图6 DeiT模型结构Fig.6 DeiT model structure
2.2.2 针对训练样本不足的改进
最近的研究发现[13,33],基于Transformer的网络模型参数量很大,如果训练样本不足,很容易造成过拟合。为了解决这一问题,可以在训练过程中应用数据增强和正则化技术,例如Mixup[51]和CutMix等基于混合的数据增强方法能够明显提高视觉Transformer的泛化能力[33]。CutMix混合标签公式如下:
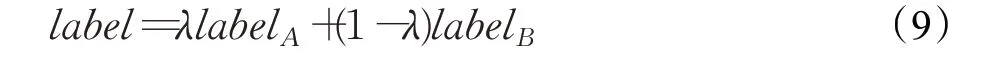
其中λ是混合标签后的裁剪面积比。如图7为上述几种数据增强方法的效果对比图。

图7 数据增强方法Fig.7 Data augmentation methods
然而基于混合生成图像中可能没有有效对象,但标签空间仍有响应。Chen等人[52]提出了TransMix方法,该方法基于Transformer中的注意力图生成混合标签。TransMix网络根据每个数据点在注意图中的响应动态地重新分配标签权重,标签的分配不再是裁剪到输入图像的显著区域而是从更准确的标签空间中分配标签,可以改进各种ViT模型性能,对下游密集预测任务(图像分割、目标检测等)表现出了较好的可移植性。其权重分配计算公式如下:

其中,·↓为最近邻下采样,M是图像覆盖区域的位置。
2.2.3 针对提高泛化能力的改进
泛化能力是指网络对新样本的可扩展能力。对于泛化能力的改进可以从两个方面进行:一方面由于网络对数据学习的不充分,导致泛化能力不足,Jiang等人[53]提出了补丁标记MixToken,将除了分类token以外的所有补丁token生成一个软标签计算loss,通过多监督的方式学习提高模型的性能,该方法有利于具有密集预测的下游任务,例如语义分割。另一方面由于高容量的ViT模型容易对训练样本过拟合,对新样本表现欠拟合,通过自监督学习图像重要的表征信息,可以提高模型的泛化能力,Chen等人[54]提出的MoCoV3,通过将同一图像不同变换作为正例,不同图像作为负例,使用双分支网络对比学习图像的表征信息。
此外,基于Transformer自监督学习在自然语言处理中的成功启发(如BERT掩码自编码等),He等人[48]提出了一种简单、有效且可扩展的掩码自编码器MAE,从输入序列中随机屏蔽掉75%的图像块,然后在像素空间中重建被屏蔽的图像块。MAE是一种非对称的编码器-解码器结构(如图8所示),其中编码器仅作用于无掩码标记块,而解码器通过隐表达与掩码标记信息进行原始图像重建.该结构采用小型解码器大幅度减少了计算量,同时也能很容易地将MAE扩展到一些大型视觉模型中。在ViT-Huge模型上使用MAE自监督预训练后,仅在ImageNet上微调就可以达到87.8%的准确率。在对象检测、实例分割和语义分割的迁移学习中,使用MAE预训练要优于有监督的预训练。
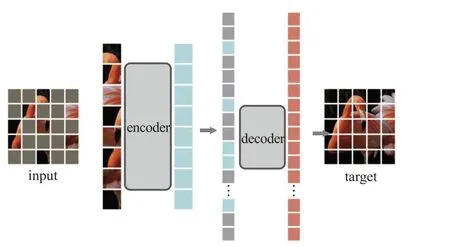
图8 非对称编码器-解码器结构(MAE)Fig.8 Asymmetric encoder-decoder structure(MAE)
2.3 基于Transformer面向结构模块的改进
目前遵循ViT的范式,已经提出了一系列Transformer变体来提高视觉任务的性能。主要的改进结构包括补丁嵌入、自注意力改进和金字塔架构等,本节主要从这几个方面介绍[35]了最新的一些研究方法。
2.3.1 针对补丁嵌入的改进方法
(1)基于提高特征提取能力的补丁嵌入方法
Han等人[35]提出的TNT(如图9所示),将补丁划分为多个更小的子补丁(例如,将27×27的补丁再细分为9个3×3的块,并计算这些块之间的注意),引入了一种新颖的Transformer in Transformer架构,用于对patch级和pixel级的表征建模。该架构利用Inner Transformer block块从pixel中提取局部特征,Outer Transformer block聚合全局的特征,通过线性变换成将pixel级特征投影到patch空间中将补丁和子补丁的特征进行聚合以增强表示能力。
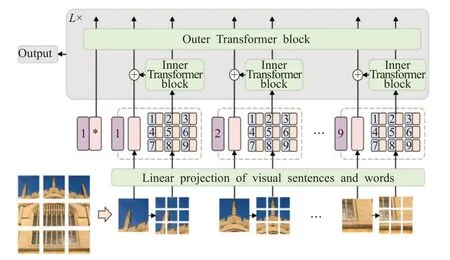
图9 TNT网络结构Fig.9 TNT network structure
Yuan等人[42]提出的CeiT,结合CNN提取low-level特征的能力设计了一个image-to-token(I2T)模块,该模块从生成的low-level特征中提取patch。
Wang等人[55]提出的CrossFormer,利用跨尺度嵌入层CEL为每个阶段生成补丁嵌入,在第一个CEL层利用4个不同大小的卷积核提取特征,将卷积得到的结果拼接起来作为补丁嵌入。
(2)基于长度受限的补丁嵌入
许多视觉Transformer模型面临的主要挑战是需要更多的补丁数才能获得合理的结果,而随着补丁数的增加其计算量平方增加。Ryoo等人[56]提出了一种新的视觉特征学习器TokenLearner(如图10所示),对于输入x,通过s个ai函数(该函数由一系列卷积组成)学到一个空间权重(H×W×1)去乘以x然后通过全局池化,最终得到一个长度为s的token序列。TokenLearner可以基于图像自适应地生成更少数量的补丁,而不是依赖于图像均匀分配补丁。实验表明使用TokenLearner可以节省一半或更多的内存和计算量,而且分类性能并不会下降甚至可以提高准确率。
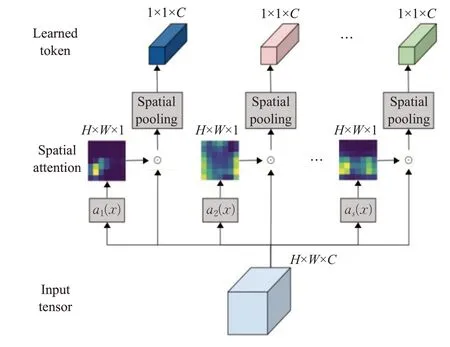
图10 TokenLearner模块Fig.10 TokenLearner module
PSViT[57]采用补丁池化在空间维度上减少补丁的数量。T2T-ViT[40]通过T2T模块递归地将相邻的补丁组合成为单个补丁,这样可以对相邻的补丁表示进行跨局部建模同时减少了一半的补丁数。
2.3.2 针对自注意力机制的改进方法
(1)基于注意力机制的改进方法
PSViT]将相邻的Transformer层之间建立注意力共享[57,以重用相邻层之间具有强相关性的注意力图。Shazeer等人[58]提出了一种交谈注意力机制,在softmax操作前引入对多头注意力之间的线性映射,以增加多个注意力机制间的信息交流。文献[59]探索了高维空间中的注意力扩展,并应用卷积来增强注意力图。Zhou等人[60]提出了DeepViT模型,通过重新生成注意力图以增加不同层的多样性。CaiT将补丁之间的自注意力层与类注意力层分离[61],使类标记专注于抽取图片的信息。XCiT利用互协方差注意力(XCA)跨特征通道执行自注意力计算[62],其操作具有线性复杂性,可以对高分辨率图像进行有效处理。表2总结了上述几种方法的参数量和计算量的一些情况。
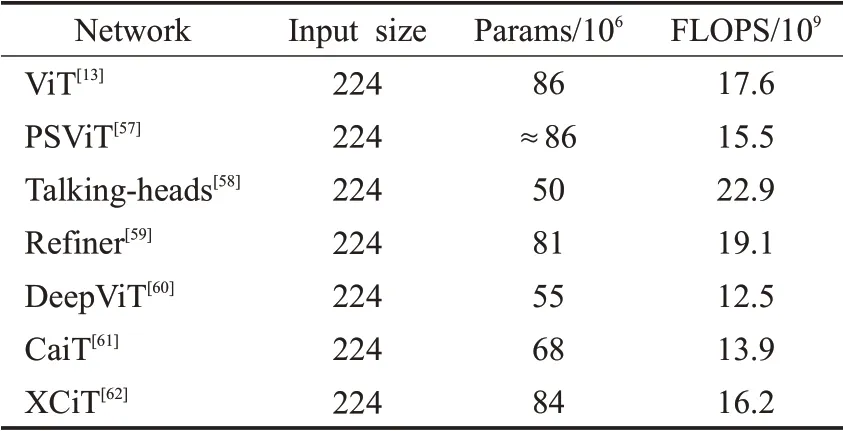
表2 模型的参数量和计算量对比Table 2 Comparison of model params and FLOPS
(2)针对局部区域改进的局部注意力机制
Swin Transformer[25]在局部窗口内执行注意力计算。RegionViT提出了区域到局部的注意力计算[43]。Multi-scale vision Longformer[63]利用Longformer[64]设计了自注意力模块,加入了局部上下文信息。KVT引入了KNN注意力[65]利用图像块的局部性通过仅计算具有前k个相似标记的注意力来忽略不相关的标记。CSWin Transformer提出了一种新颖的十字形窗口自注意力[45],在其基础上Pale Transformer提出了一种改进的自注意力机制PS-attention[47],在一个Pale-shaped的区域内进行自注意力的计算(图11中介绍了Transformer不同注意力机制的效果图),可以在与其他的局部自注意力机制相似的计算复杂度下捕获更丰富的上下文信息。DAT提出了一种新的可变形的局部自注意力模块[66],该模块以数据依赖的方式选择自注意力中key和value对的位置。这种更灵活的自注意力模块能够聚焦于更相关的区域信息。Han等人[67]从稀疏连接、权重共享和动态权重等方面揭示了局部视觉Transformer的网络特征。
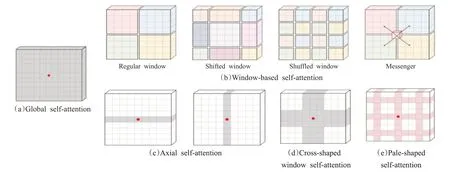
图11 Transformer中不同自注意力机制Fig.11 Different self-attention mechanisms in Transformer
(3)基于局部注意力与全局注意力相结合的改进方法
尽管局部窗口[25]的自注意力机制是计算友好的,但缺少丰富的上下文信息。为了捕获更丰富的上下文信息。Twins将每个子窗口概括为一个代表元素执行全局子采样注意力(GSA)[36]。CAT将每个通道的特征图分离并使用自注意力来获取整个特征图中的全局信息[68]。Focal Transformer引入了焦点自我注意以捕获全局和局部关系[44]。CrossFormer引入了长短距离注意力(LSDA)[55],以捕捉局部和全局视觉信息。TransCNN设计一种分层多头注意力模块(H-MHSA)[46]可以更有效地对全局关系进行建模。
2.3.3 针对提高计算效率的改进结构——金字塔结构
金字塔结构一般常用于卷积网络中,通过缩减空间尺度以增大感受野,同时也能减少计算量。但是对于Transformer其本身就是全局感受野,可以直接堆叠相同的Transformer encoder层。而对于密集预测任务中当输入图像增大时,ViT计算量会急剧上升,如果直接增大patch size(如16×16)得到粗粒度的特征,这对于密集任务来会有较大的损失。
Wang等人[34]提出的PVT是第一个采用特征金字塔的Transformer结构,包含了渐进式收缩金字塔和空间缩减注意力模块SRA(如图12所示),SRA通过reshape恢复3-D(H×W×C)特征图,重新均分为大小R×R的补丁块将K、V的补丁数量缩小R倍,相较于ViT其渐进式收缩金字塔能大大减少大型特征图的计算量,可以替代视觉任务中CNN骨干网络。
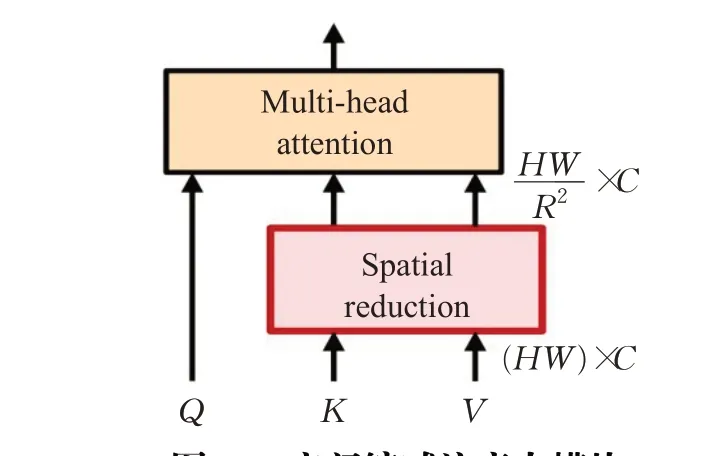
图12 空间缩减注意力模块Fig.12 Spatial-reduction attention module
PVTv2[37]和SegFormer[50]通过引入重叠补丁嵌入、深度卷积来改进原始PVT,PVTv2在空间缩减注意力模块中利用具有线性复杂度的平均池化操作代替了PVT中的卷积操作。这种特征金字塔的设计思想使Transformer成为了视觉任务骨干网络的一个替代方案,诸如Focal Transformer[44]、CrossFormer[55]、RegionViT[43]、Multiscale vision Longformer[63]等都采用了金字塔结构的设计方案。
除了上述方法之外,还有一些其他方向可以进一步改进视觉Transformer,例如位置编码CPVT[22]、iRPE[69]、残差连接优化策略LayerScale[61]、快捷连接[70]和去除注意力[51,71]、ResMLP[72]、FF Only[73]。
3 CNN+Transformer混合结构
基于深度学习的方法在计算机视觉领域最典型的应用便是CNN,通过共享卷积核来提取特征,一方面可以极大地降低参数量来避免更多冗余的计算从而提高网络模型计算的效率,另一方面又结合卷积和池化使网络具备一定的平移不变性和平移等变性。而Transformer依赖于更灵活的自注意力层,在提取全局语义信息和性能上限等方面的表现要优于CNN。目前新的研究方向是将这两种网络结构的优势结合起来。本章从架构拼接、内部改进、特征融合几个方面介绍了CNN+Transformer的混合模型。
3.1 基于结构拼接的混合结构
Carion等人[12]提出的DETR,利用ResNet主干网络提取图像紧凑特征表示生成一个低分辨率高质量的特征图,有效地减少了输入前Transformer图像尺度大小,提高模型速度与性能。
Chen等人[74]提出的Trans-UNet,将Transformer与UNet相结合,利用Transformer从卷积网络输出的特征图中提取全局上下文信息,然后结合Unet网络的U型结构将其与高分辨率的CNN特征图通过跳跃连结组合以实现精确的定位。在包括多器官分割和心脏分割在内的不同医学应用中取得了优于各种竞争方法的性能。
Xiao等 人[75]提出的ViTc,将Transformer中Patch Embedding模块替换成Convolution,使得替换后的Transformer更稳定收敛更快,在ImageNet数据集上效果更好。
3.2 基于卷积局部性改进的混合结构
Wu等人[38]提出的CvT结合了卷积投影来捕获空间结构和低级细节。Refiner应用卷积来增强自注意力的局部特征提取能力[59]。CoaT通过引入卷积来增强自注意力设计了一种卷积注意力模块该模块[39],可以作为一种有效的自注意力替代方案。Uni-Former将卷积与自注意力的优点通过Transformer进行无缝集成[76],在浅层与深层分别聚合局部与全局特征,解决了高效表达学习的冗余与依赖问题。Liu等人[46]提出的TransCNN网络,通过在自注意力块后引入CNN层使网络可以继承Transformer和CNN的优点。CeiT将前馈网络(FFN)与一个CNN层相结合[42],以促进相邻补丁之间的相关性。Le-ViT[77]在non-local[78]的基础上提出了一种用于快速推理图像分类的混合神经网络。PiT利用卷积池化层实现Transformer架构的空间降维[41]。ConViT引入了一个新的门控位置自注意力层(GPSA)[79]以模拟卷积层的局部性。
3.3 基于特征融合的改进方法
CNN与Transformer结合的另一形式是通过特征融合,采用一种并行的分支结构将中间特征进行融合。
(1)模型层特征融合
Peng等人[80]提出了Conformer(如图13),通过并行结构将Transformer与CNN各自的特征通过桥架相互结合实现特征融合,使CNN的局部特征和Transformer的全局特征得到最大程度的保留。
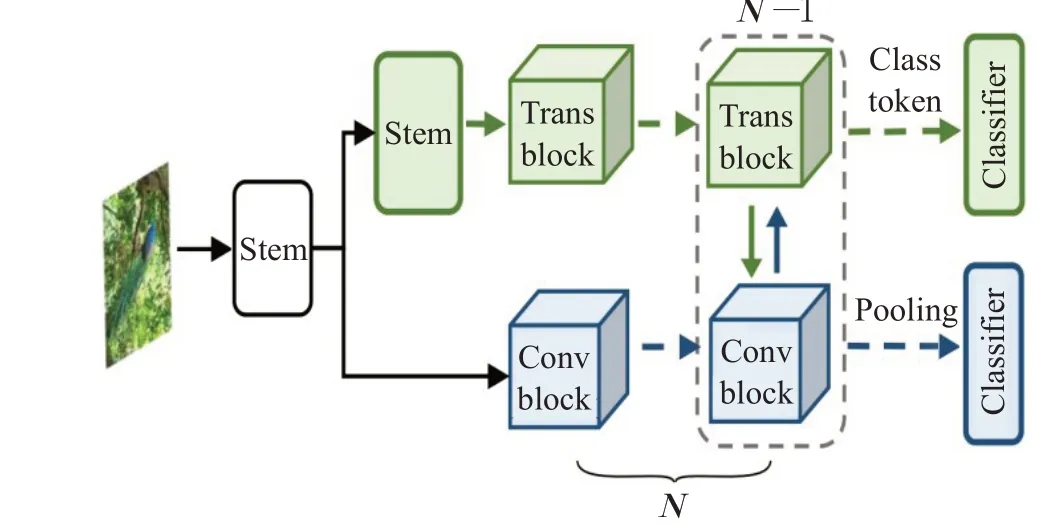
图13 DETR模型结构Fig.13 DETR model structrue
(2)交叉注意力特征融合
Chen等人[81]提出了MobileFormer,将MobileNet和Transformer并行化,使用双向交叉注意力将两者连接起来即mobile-former块,与标准注意力相比k和v通过局部特征直接投影得到,节省了计算量使注意力更多样化。实验结果表明,该方法在准确性和计算效率都取得了显著效果。
4 Transformer在CNN中的运用
4.1 基于CNN的注意力模块
Wang等人[78]提出了Non-local模块(如图14的A)旨在通过全局注意力捕获长距离依赖关系,将某个位置的输出等于特征图中所有位置的特征加权和,使局部CNN网络得到了全局的感受野和更丰富的特征信息。
此外为了减少全局注意力计算的负担,Huang等人[82]提出了十字交叉注意模块,该模块仅在十字交叉路径上生成稀疏注意图(如图14的B),通过反复应用交叉注意力,每个像素位置都可以从所有其他像素中捕获全局上下文信息。与Non-local块相比,十字交叉注意力减少了11倍GPU显存,具有O(√N)的复杂度。Srinivas等人[83]提出的BoTNet,将多头注意力模块multihead self-attention(MHSA)替代ResNet bottleneck中的3×3卷积,其他没有任何改变,形成新的网络结构,称为bottleneck Transformer,相比于ResNet等网络提高了再分类,目标检测等任务中的表现,并且比EfficientNet快1.64倍。
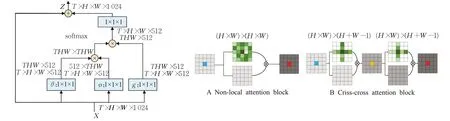
图14 Non-local块Fig.14 Non-local blocks
4.2 动态权重
动态权重是指为每个实例学习专门的连接权重,以增加模型的容量。文献[67]中利用动态权重来增加网络容量,在不增加模型复杂度和训练数据的情况下提高了模型性能。
Hu等人[84]提出了LR-Net,根据局部窗口内像素与特征之间的组合关系重新聚合其权重。这种自适应权重聚合将几何先验引入网络中,实验表明该方法可以改进图像识别任务。
大体上,动态权重在卷积网络中应用可以分为两类:一类是学习同构连接权重,如SENet[85]、动态卷积[86];另一类是学习每个区域或每个位置的权重(GENet[87]、Lite-HRNet[88]、Involution[89])。
4.3 其他方法
Trockman等人[90]提出的ConvMixer模型,仅使用的标准卷积直接将补丁作为输入,其性能要优于ViT、MLP-Mixer以及ResNet等视觉模型。这种补丁嵌入结构允许所有下采样同时发生,并立即降低内部分辨率,从而增加视觉感受野大小,使其更容易混合远处的空间信息。如表3展示了ConvMixer与几种方法的对比情况。
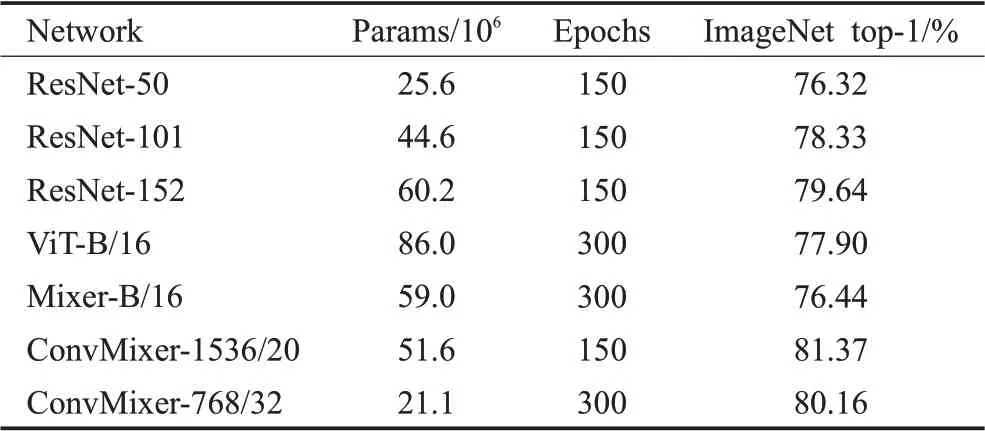
表3 ConvMixer对比实验Table 3 ConvMixer comparative experiment
5 总结与展望
本文介绍了视觉Transformer模型基本原理和结构,分别从面向性能优化和面向结构改进两个方面对视觉Transformer的关键研究问题和最新进展进行了概述和总结,同时以图像分类和目标检测为例介绍了Transformer在视觉任务上的应用情况。视觉Transformer作为一种新的视觉特征学习网络,文中结合CNN对比总结了两种网络结构的差异性和优缺点,并提出了Transformer+CNN的混合结构。CNN和Transformer相结合具有比直接使用纯Transformer更好的性能。然而两者结合的方式有很多不同的方法,如文献[7]中应用CNN提取紧凑特征,文献[50]中重叠补丁生成等。两者如何相结合才能更有效?对此,开发一个更强大通用的卷积ViT模型还需要进行更多研究。
目前,大多数Transformer变体模型计算成本很高,需要大量的硬件和计算资源[91-94]。未来一个新的研究方向是应用CNN剪枝原理对Transformer的可学习特征进行剪枝,降低资源成本,使模型可以更容易地部署在一些实时设备中(如智能手机、监控系统等)。自监督学习的方式可以在无标注数据上对模型进行表征学习,基于Transformer的自监督学习可以解决模型对数据的依赖性从而有望实现更强大的性能。此外,视觉Transformer采用了标准的感知器数据流方式,为时序数据、多模态数据融合和多任务学习提供了一种统一的建模方法,基于Transformer模型有望实现更好的信息融合和任务融合。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
学与玩(2018年5期)2019-01-21
文苑(2018年18期)2018-11-08
幼儿画刊(2018年7期)2018-07-24
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
