
改进YOLOv5s的小目标烟雾火焰检测算法
2023-01-13 11:57王一旭肖小玲王鹏飞向家富
计算机工程与应用 2023年1期
王一旭,肖小玲,王鹏飞,向家富
长江大学 计算机科学学院,湖北 荆州 434023
在日常生活中,火灾会对人类带来巨大的伤害,危害人类的身体健康,同时会影响社会健康发展和人民财产安全。而火灾在发生初期是很容易被扑灭的,因此,通过对火灾发生初期的烟雾与火焰进行迅速准确的检测是非常有必要的,可以很大程度上减少火灾带来的危害与损失[1]。
早期的火灾识别是通过传感器实现的,基于温度,烟雾颗粒等物理数据采样来进行识别[2]。这种方法在特定环境中有着不错的表现,但在室外和复杂环境中会受到大量干扰,导致检测精度会大幅下降,同时这种方法也无法获取现场实时图像。随着计算机视觉技术的发展与进步,Toereyin等人[3]通过小波变换来检测火焰闪烁周期与火灾的颜色变换,结合时间与颜色的变化信息来减少对颜色相似的物体出现误检的情况。王文豪等人[4]通过采用二维最大熵自动阈值法对火灾图像进行分割处理,分割后再提取可疑区域;对可疑区域的火焰进行识别。Tian等人[5]通过像素间的相关性、主成分分析初步识别出图像中的烟雾,并通过纯烟雾图片中获得的模型,对疑似区域进一步进行分离,来提取出图片中的烟雾图像。
近年来,深度学习已在许多领域超过传统的人工方法[6],相对于传统的计算机视觉检测中的人工提取特征,深度学习方法能提取出更抽象、更深层次的特征,可以使模型泛化性更好,并且在火焰检测中也取得了不错的成绩[7]。Wu等人[8]在当时主流的目标检测框架Faster R-CNN、YOLOv1和SSD来进行火焰检测,并发现SSD精度最高,检测效率最好,提出了用于移动设备上的轻量化网络tiny-YOLO;Li等人[9]在Faster R-CNN、R-FCN、SSD、YOLOv3等目标检测算法与计算机视觉方法在火焰检测上的表现,发现目标检测算法的精度率高于手工提取特征的算法,同时YOLOv3算法拥有最高的检测精度与速度。谢书翰等人[10]在对YOLOv4网络进行改进的同时在网络预测头中加入通道注意力模块,以此来提高对烟雾的检测精度。在目前现有的大部分算法只对火焰与烟雾进行单独检测,而在火灾发生时,烟雾和火焰都是关键信息,所以烟雾和火焰的检测重要性是一致的,同时险情出现时的烟雾与火焰大多为小目标。而现有算法仍然存在检测精度低,难以准确检测到小目标,速度不满足日常需要,在复杂环境中误检、漏检率高等问题。
因此,提出一种基于YOLOv5s的小目标烟雾火焰检测算法,并针对现有问题进行改进。首先基于公开数据集创建了一个内容全面丰富的烟雾火焰数据集,并通过结构相似性算法[11]剔除相似图片,使模型在训练时效率更高,有更好的泛化能力;之后融合SimAM注意力机制[12],在不增加网络参数的情况下,加强特征提取能力,提高检测精度;通过结合加权双向特征金字塔网络(BiFPN)结构修改Neck结构[13],加强了特征提取与融合的过程,提高小目标的检测精度;最后使用遗传算法[14]在自建数据集上优化超参数,更进一步提高模型的检测能力,可以在火灾发生初期做出准确迅速的检测,保护生命与财产安全。
1 YOLOv5s网络
YOLOv5[15]是目前广泛使用的目标检测网络之一,凭借检测精度高、推理速度快等特点,在各种工业问题取得了不错的成果[16-18]。同时,YOLOv5也一直在更新迭代,目前版本为6.0,也是综合表现最好的版本。选用的YOLOv5s网络为YOLOv5的轻量化版本,更符合实时火灾检测的要求。YOLOv5s的网络结构如图1所示。

图1 YOLOv5s结构Fig.1 Structure of YOLOv5s
YOLOv5s网络主要分成4个部分:输入(input)、主干网络(backone)、颈部(neck)以及预测头(head)。其中backone由CBS、CSP1_X、SPPF构成。neck部分由CSP2、上采样(upsample)和相加模块(concat)构成,最后在head中进行预测并输出结果。其中CBS模块由卷积(Conv),批量归一化(batch normalization,BN)和SilU激活函数构成。
CSP模块借鉴了CSPNet结构[19],可以在不影响模型精度的情况下,有效地减少计算量,并提高推理速度。YOLOv5根据backone和neck的不同,分别设计出了CSP1_X和CSP2模块。CSP1_X通过Res模块[20]在不同层中控制网络的深度,结构如图2所示。
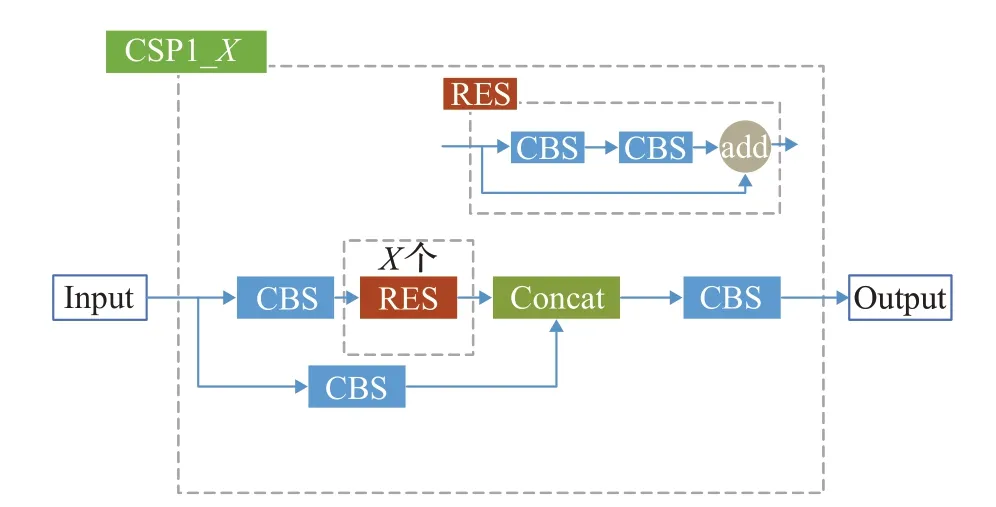
图2 CSP1结构Fig.2 Structure of CSP1
CSP2主要用在neck部分,有效地提高了网络的特征融合能力,结构如图3所示。

图3 CSP2结构Fig.3 Structure of CSP2
在backone的最后采用了快速空间金字塔池化(fast spatial pyramid pooling,SPPF),将不同感受野的特征图融合,以此提高特征图的表达能力。原理上与SPPNet[21]类似,但运行速度更快,结构如图4所示。
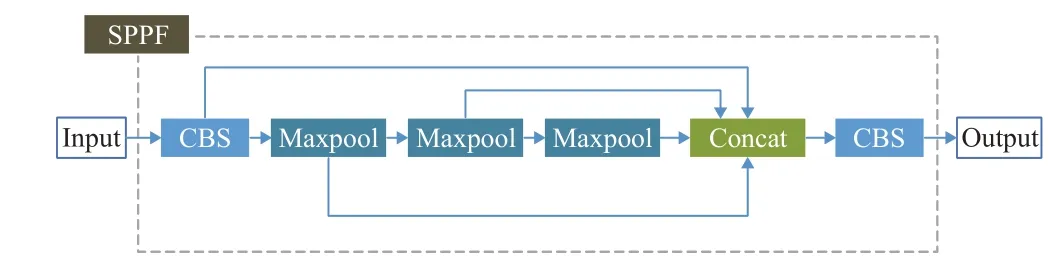
图4 SPPF结构Fig.4 Structure of SPPF
2 数据集与优化
2.1 数据集采集
数据集是深度学习网络的基本,优秀的数据集能让模型有更强的鲁棒性和泛化性,为解决现有数据集的限制,制作了一个多场景的复杂烟雾与火焰数据集,数据来源于多个公共火灾数据集,Bilkent大学火焰视频库VisiFire、BoWFire Dataset、FD-Dataset,搜索引擎搜索和网络火焰烟雾视频截取,如图5所示。

图5 数据集示例Fig.5 Dataset examples
同时获取到的数据大多没有标注或标注不全,将对数据重新标注,对数据采用最大外接矩形框标注,将显著特征都包括进去,标注为fire、smoke两个类,标注格式为YOLO格式,如图6所示。

图6 标注示例Fig.6 Annotation example
2.2 数据集整理
由于大部分数据来源于网络,存在大量的相似图片,为提高数据集中数据的质量,减少重复数据的出现,提高网络的学习效率,对数据集中的图片进行结构相似性(structural similarity,SSIM)计算,如式(1):

其中C1、C2为常数,避免分母为0的情况,常取0.01和0.03,μ表示图的平均亮度,计算过程为式(2):

其中,N为图像的像素点总数,xi标识每个图像的像素值。σ表示图的对比度,计算过程为式(3):

两张图片通过计算,可得到一个SSIM index,值在0到1之间,越大表明两张图片越相似,在数据集中,对SSIM index大于0.85的两张图片定义为相似,只保存其中一张。
2.3 数据集分析
在数据集收集与整理后,总共有9 981张图片,每张图片中至少含有一个标签,对数据集进行统计,结果如图7、8所示。
图7中,纵坐标轴为标签数量,横坐标为标签名,数据集中有足够数量的烟雾与火焰,经过相似度检查后,可以认为已经包含日常生活中绝大部分火灾中的火焰和烟雾场景。

图7 标签数量Fig.7 Number of labels
如图8表示标签的分布。图8(a)中,横坐标x为标签中心横坐标与图像宽度的比值,纵坐标y为标签中心纵坐标与图像高度的比值,数值越大或越小表示越靠近图像的边缘,从图中可知,数据分布广泛,集中在图像的中部。

图8标签分布Fig.8 Label distribution
图8(b)中,横坐标width为标签宽度与图像宽度的比值,纵坐标height为标签高度与图像高度的比值,数值越大,标签框在图像中的占比就越大。从图8中可知,数据集中包含各种大小的数据,主要为中小目标数据,更贴合实际情况。同时为保证模型的泛化性,也有一定数量的其他大小数据。
3 YOLOv5s的改进
3.1 SimAM注意力机制
计算机视觉中的注意力机制,目的是模仿人类视觉系统,能够有效地在复杂场景中找到显著区域。通过注意力机制,可以对输入图像的特征进行动态权重调整。注意力机制已经在许多视觉任务中取得了成功[22]。
SimAM注意力模块不同于现有1-D通道注意力和2-D空域注意力,无需额外参数去推导出3-D注意力权值,简单且高效,只需通过一个Energy函数来计算注意力权重。SimAM注意力模块原理如图9所示。

图9 SimAM注意力模块Fig.9 SimAM module of attention
通过3-D权重,对特征中的每个点都赋上单独的标量,通过这种统一权重,使得特征更具有全局性,很适合用于需要考虑全局性的烟雾火焰的检测。计算过程如式(4)所示:

其中输出结果为增强后的特征,X为输入的特征,⊙为点积运算,并且通过sigmoid函数限制E中可能出现的过大值,E为每个通道上的能量函数,计算过程如式(5)所示:

其中t为输入的特征的值,t∈X,λ为常数1E-4,μ和σ2分别表示X中每个通道上的均值与方差,计算过程为式(6)、(7):

其中M=H×W,表示每个通道上的值的数量。通过计算可获得每个点的权重,以此来改善网络的识别效果,同时也不会为网络增加额外的参数。在多次实验后,SimAM层加在backone中的最后一层中效果最好。
3.2 Neck结构改进
为加强网络对小目标的检测能力,且不扩大输入的分辨率,将在网络的第三层,也就是CSP1_1部分增加一个特征图输出,接入Neck部分作为P2输出,输入的大小为640×640时,P2的特征图大小为160×160,每格特征图对应输入图中以4×4的感受野,可以更好检测小目标,同时也可在特征融合的过程中为其他层提供信息。但是P2的部分仅经过4倍下采样,干扰信息较多,为更好地提取特征,将对YOLOv5s的Neck部分进行改进。
YOLOv5s的Neck参考了PANet[23]的思想,对从主干网络获取的特征,进行上采样之后再进行下采样融合,使得每个特征能包含更多的信息,如图10所示。

图10 原有Neck结构Fig.10 Structure of original Neck
在P2加入后,为了Neck能对特征进行更好地融合,将借鉴BiFPN的结构对原有的Neck部分进行改进,在P3层增加一个上采样与P2层融合,同时在P3层增加一个上采样节点。并在P3、P4层增加到输出节点的通路,可在不增加太多复杂度的情况下融合特征,最终改进的结构如图11所示。

图11 改进后的Neck结构Fig.11 Structure of improved Neck
如图11所示,改进后的结构增加了些许复杂度,但每个特征图能融合更多的信息,能在提高在检测时的精度。同时,原有的特征融合过程中并没有对不同特征进行区分,仅仅为简单的相加融合,在改进后的Neck结构中,将特征融合优化为带权特征融合,区分每个权重的重要性,使用快速归一化融合(fast normalized fusion)来计算,过程为式(8):

其中,I为输入值,O为输出值,通过计算可以使所有的权重值在0和1之间。以P3融合过程为例,计算过程为式(9)、(10):
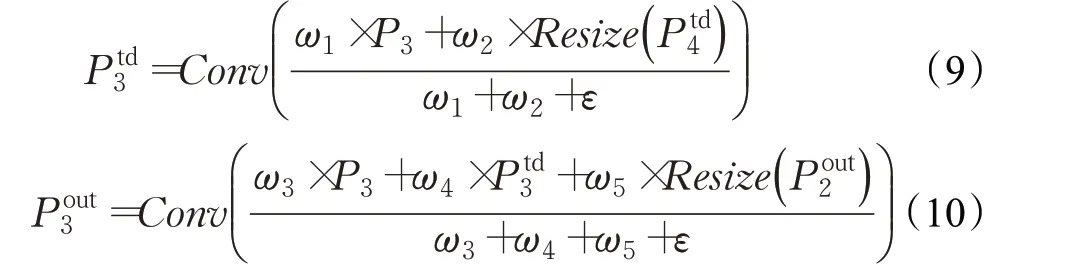
式中Conv代表卷积操作,Resize为上采样或下采样,各参数和计算流程如图12所示。

图12 计算流程与参数Fig.12 Calculation process and parameters
基于以上描述,改进后的Neck输出的每个特征图能包含更多信息,且加强了对小目标的检测能力。整体改进后的YOLOv5s网络结构如图13所示。

图13 改进后的YOLOv5s网络结构Fig.13 Network structure of improved YOLOv5s
3.3 遗传算法进化超参数
遗传算法(genetic algorithm,GA)最早是计算数学中用于解决最佳化的搜索算法,通过遗传算法可以得到问题的优质解。在深度学习领域中,最优的超参数能最大化地发挥网络的性能,从而提高模型的检测能力。通过遗传算法找出网络的最优超参数。目前已有相关成果[24-26]。使用遗传算法对优化后的YOLOv5s网络的部分超参数在自建的数据集上寻找最优值,算法流程如图14所示。
其中,编码过程就是把参数转换到遗传算法的搜索空间,转为遗传算法的染色体结构数据,解码的过程就是反过来,将染色体结构数据转换为原有数据。适应度为当前参数训练后的模型在测试集上的检测精度。
选择、交叉与变异操作都是遗传算子。选择操作是指从设定的范围中以选择前几代中优秀的数据作为遗传对象,个体的适应度越高越容易被选择。交叉操作是选择两个父代,通过一定的概率对两个染色体结构数据的交换组合,把父代的优秀特征遗传给子串,从而产生新的优秀个体。变异操作是防止遗传算法在优化过程中陷入局部最优解,在搜索过程中,需要对个体进行变异,对染色体结构数据进行变化。种群数量定义为选定的父代范围,算法只在固定的种群数量中选定父代。
在自建的数据集上进行超参数进化,将YOLOv5s原有的超参数设定为初始值,在改进后的YOLOv5s网络上进行进化,并设定选择算子的选择范围为5,交叉算子为80%的随机交叉,变异算子的概率为0.01,进化的轮次为300次,最终结果如表1所示。

表1 进化的参数列表Table 1 Evolutionary parameters list
4 实验结果与分析
4.1 实验环境与准备
实验环境硬件配置:CPU为AMD R7 5800H,GPU为NVIDIA RTX 3070 Laptop,操作系统为Windows10,编译环境为Python3.8+Pytorch1.10.1+CUDA11.3。
在训练开始前通过K-means算法对初始锚框进行聚类,结果为[18,28,43,37,52,110],[90,66,96,144,157,117],[270,150,192,237,346,221],[305,350,532,253,548,352]。训练时对数据集使用在线增强,在每个epoch中对数据进行色调、饱和度、亮度的变换,以一定的概率进行平移、缩放操作,并加上Mosaic数据增强,使得每个epoch学习的数据都有一定变化,进一步提升模型泛化能力,减少过拟合的可能性。将原始数据集按照8∶1∶1的比例划分为训练集,验证集和测试集。训练集7 985张图片,验证集和测试集的数量为998张,同时进行相关性分析,避免测试集中出现数据泄露,保证训练结果可靠真实。为保证实验结果的准确性与严谨性,所有数据皆为3次实验后统计取平均值。
4.2 评价标准
实验结果采用精确度(precision,P)、召回率(recall,R)、平均精度(average precision,AP),和平均精度均值(mean average precision,mAP)等作为评价指标,计算公式为式(11)~(14):

其中TP(true postives)为预测正确的正类样本数量,FP(false postives)为预测错误的正类样本数量,FN(false negatives)为预测错误的负类样本数量,n为数据集中的类别数。设定AP的IoU检测阈值为0.5,即评价指标为AP@0.5与mAP@0.5。同时为进一步发挥模型性能,对每个置信度阈值(confidence threshold)下的指标进行判断,如图15所示。

图15 不同置信度阈值下模型性能Fig.15 Model Performance under different confidence thresholds
从15图可知,当置信度阈值设定为0.5时,各项指标综合最高,由此表示此时的模型性能最好,其中precision为82.1%,recall为70.4%,mAP为78.9%。
4.3 对比实验
首先对自建数据集的有效性进行分析,目前还没有权威的烟雾火焰公开数据集,将与广泛使用的VisiFire火焰数据集,目前Kaggle上火焰烟雾体量最大的数据集fire smoke dataset[27]进行对比。
将YOLOv5s在3个数据集上分别进行训练,并选用1张不在数据集中的现实图片进行对比,结果如图16所示。

图16 数据集对比Fig.16 Comparison of datasets
由图16可知,VisiFire数据集中仅包含火焰标注,无法检测到烟雾类别,同时因数据量过少,训练的模型泛化性不是很好,而fire smoke dataset数据集训练的模型中虽然能检测到火焰烟雾图像,但置信度不高,同时也没有将烟雾完全检测到,自建数据集所训练模型的检测效果是最好的。
之后将SimAM注意力机制对目前广泛使用的SE、CBAM注意力机制进行对比。将3种注意力机制分别加入到YOLOv5s中的实验结果,如表2所示。

表2 注意力机制对比Table 2 Comparison of attention mechanism
对YOLOv5s和改进后的YOLOv5s进行对比实验,设定batchsize为16,输入为640×640,部分超参数采用表1中的结果。同时,为避免过拟合出现,在模型训练过程中不设定固定的epoch数量,而是在100个epoch后启用早停(early stopping)机制,当发现模型在验证集上基本没有改善时就自动停止训练,在相同的网络配置下,越早停止的训练说明模型训练的效率更高,学习速度更快。模型训练的训练损失和验证损失的对比,如图17所示。

图17 损失值对比Fig.17 Comparison of loss value
从图17可知,改进后的网络中,box_loss、obj_loss、cls_loss在训练集与验证集中都比YOLOv5s网络更小,未出现严重过拟合现象,且训练花费时间更短,学习速率更高。改进后的网络比原网络收敛更快,在训练时更有效率。
为进一步展现网络的改进效果,对网络的mAP@0.5数据进行对比,结果如图18所示。

图18 平均精度均值对比Fig.18 Comparison of mAP
从图18可知,改进后的网络比原YOLOv5s的精度指标更高,在火焰和烟雾检测中更有优势。同时因为数据集中大部分数据为小目标数据,当精度提升后,可以认定为对小目标检测效果提升。
为更全面地展示改进的网络的优势,与主流的轻量级目标检测网络YOLOv3-Tiny、YOLOv4-Tiny、
EfficentDet-D0、YOLOX-Tiny、NanoDet-p-m-1.5x、YOLOv5-lite-g进行对比实验,在与改进后网络使用的训练集上训练,之后在同一测试集对比,为保证每个网络发挥最佳性能,对每个网络设置合适的输入大小。对比结果如表3所示。
通过表3数据可知,改进后的YOLOv5s的精度远高于其他网络,参数量和权重大小也仍然满足轻量级网络的要求,同时对比原YOLOv5s网络,因为网络结构的改变,提高了少量的参数量和权重大小。但并未明显影响检测速度,仍可满足实时检测的要求。

表3 网络对比结果Table 3 Network comparison results
为进一步验证改进的有效性,对各项改进进行消融实验测试,测试结果如表4所示。
由表4数据可知,各部分改进都有效果,在加入SimAM注意力机制后,检测精度有明显提高,同时训练得也更快,其中SimAM机制中带来的3-D权重很适合用于火焰与烟雾的检测,之后加入Neck改进的部分后,加强了对小目标的检测,优化了多尺度特征的融合过程,对火焰的检测有明显改善,烟雾上也有更高的精度,同时也因为网络复杂度的提高,对训练轮次有所增加,检测速度有微量下降。最后使用遗传算法优化的超参数后,精度提升,训练效率更高,表示模型性能发挥得更好。

表4 消融实验结果Table 4 Ablation experimental results
4.4 结果分析
为更直观对比网络改进后的结果,选取测试集中部分图片与现实图片进行测试,为更明显的对比结果,对两个网络的置信度阈值都设置为0.25,结果如图19所示。
图19左边为YOLOv5s检测结果,右边为改进后的YOLOv5s检测结果。图(a)烟雾中的火焰,受到遮挡且火焰目标较小,左边虽然能检测到目标,但置信度不高,且无法细分火焰,右边准确地检测到被遮挡的火焰,且对烟雾的检测中更准确。图(b)中右图对小目标的检测效果更好,同时没有对较为稀疏的烟雾产生误检。数据中不会将类似烟雾标注,因为在火灾检测中这种烟雾并没有太多参考价值。图(c)中烟雾与背景混淆,存在一个小目标火焰,右图比左图更好地检测到了烟雾的轮廓,同时对小火焰的置信度更高。图(d)中左图漏检了被遮挡的小火焰,同时将云朵误检为烟雾,右图检测到了被遮挡的小火焰,并且没有误检,对火焰的检测效果也更好。图(e)为现实生活中的图片,火焰与烟雾中背景复杂,存在干扰。相对于左图,右图中对烟雾与火焰的置信度更高,检测框更贴近现实。

图19 检测结果对比Fig.19 Comparison of detection results
5 结束语
针对目前火灾检测算法中对烟雾误检,对小目标火焰漏检的情况,提出一种基于YOLOv5s改进的小目标火焰检测算法,首先为增加模型的鲁棒性和泛化能力,基于公开数据集制作了一个数量充足,内容复杂的烟雾火焰自建数据集,对网络改进之处为在主干网络中增加3-D注意力机制SimAM,对Neck部分进行修改,增加一个检测尺度,优化特征融合过程,提高模型对小目标的火焰以及烟雾的检测精度。通过遗传算法在自建数据集上优化网络超参数,进一步提升模型的性能。经过实验表明,改进后的网络相较于YOLOv5s,在没有过多增加参数与权重大小的情况下,对火焰与烟雾中精度更高,提升了对小目标的检测精度,能满足实时检测的需要。在后续中,可对结构进一步调整,扩充学习的数据集,以达到更好的检测效果。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
小学阅读指南·低年级版(2021年3期)2021-03-19
学苑创造·A版(2021年2期)2021-03-11
华人时刊(2019年13期)2019-11-26
动漫星空(兴趣百科)(2019年5期)2019-05-11
当代陕西(2017年12期)2018-01-19
传媒评论(2017年3期)2017-06-13
文学港(2016年12期)2017-01-06
第二课堂(课外活动版)(2016年2期)2016-10-21
