
基于F-Faster-RCNN算法的摔倒检测研究
2023-01-16 07:27张德育王国杰
沈阳理工大学学报 2023年1期
崔 悦,张德育,王国杰
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
随着社会老龄化日益严重,老年人摔倒的自动检测问题得到了广泛的关注。在基于深度学习的摔倒检测研究中,文献[1]将反向传播神经网络应用在摔倒检测中,仅需视觉传感器即可检测,解决了传统佩戴方式检测带来的不适以及环境传感器检测方式的高成本问题。文献[2]利用长短期记忆(LSTM)模型进行摔倒检测。文献[3]提出了一种基于注意力双向LSTM网络结合卷积神经网络(CNN)模型进行摔倒检测。文献[4]使用YOLOv3结合LSTM模型进行摔倒检测。文献[5]使用区域卷积网络(R-CNN)预先训练,得到一个高效的深度学习网络模型,使摔倒检测更加快速准确,但受到环境影响或光线干扰时,该模型检测的精度较低。本文提出基于金字塔结构(Feature Pyramid Networks,FPN)[6]的快速卷积神经网络(Faster-RCNN)的摔倒检测模型,简称F-Faster-RCNN。将该算法与多目标跟踪算法Deepsort[7]结合,完成运动目标跟踪。F-Faster-RCNN采用3D卷积神经网络(3D CNN)[8]提取帧间特征,对支持向量机(SVM)[9]参数调优的过程进行改进,得到全局最优解后对提取的帧间特征进行摔倒判别。
1 基于深度学习的运动目标跟踪
1.1 目标检测
Faster-RCNN是一种基于深度学习的目标检测算法。该算法使用视觉几何群网络(Visual Geometry Group 16 Network,VGG16)[10]作为主干网络。虽然Faster-RCNN算法在检测方面表现良好,但在人体有遮挡及光线干扰等情况下容易漏检。为提高人体检测的精度、降低损失,需要加深网络层次,但VGG16不能在原有的基础上加深网络层次,否则会造成梯度爆炸或梯度消失。
本文采用残差网络(Residual Network,Res-Net)代替Faster-RCNN算法原有的VGG16网络,并通过参考FPN结构对Faster-RCNN算法的网络结构进行改进,提出了F-Faster-RCNN算法。不仅解决了梯度爆炸和消失的问题,又保留大量的浅层信息,提升了人体检测的精度。
F-Faster-RCNN算法网络结构如图1所示。其中:Conv代表卷积层;s1代表步距,令步距值为1;Conv2d代表卷积核。区域生成网络(Region Proposal Network,RPN)生成预选框。
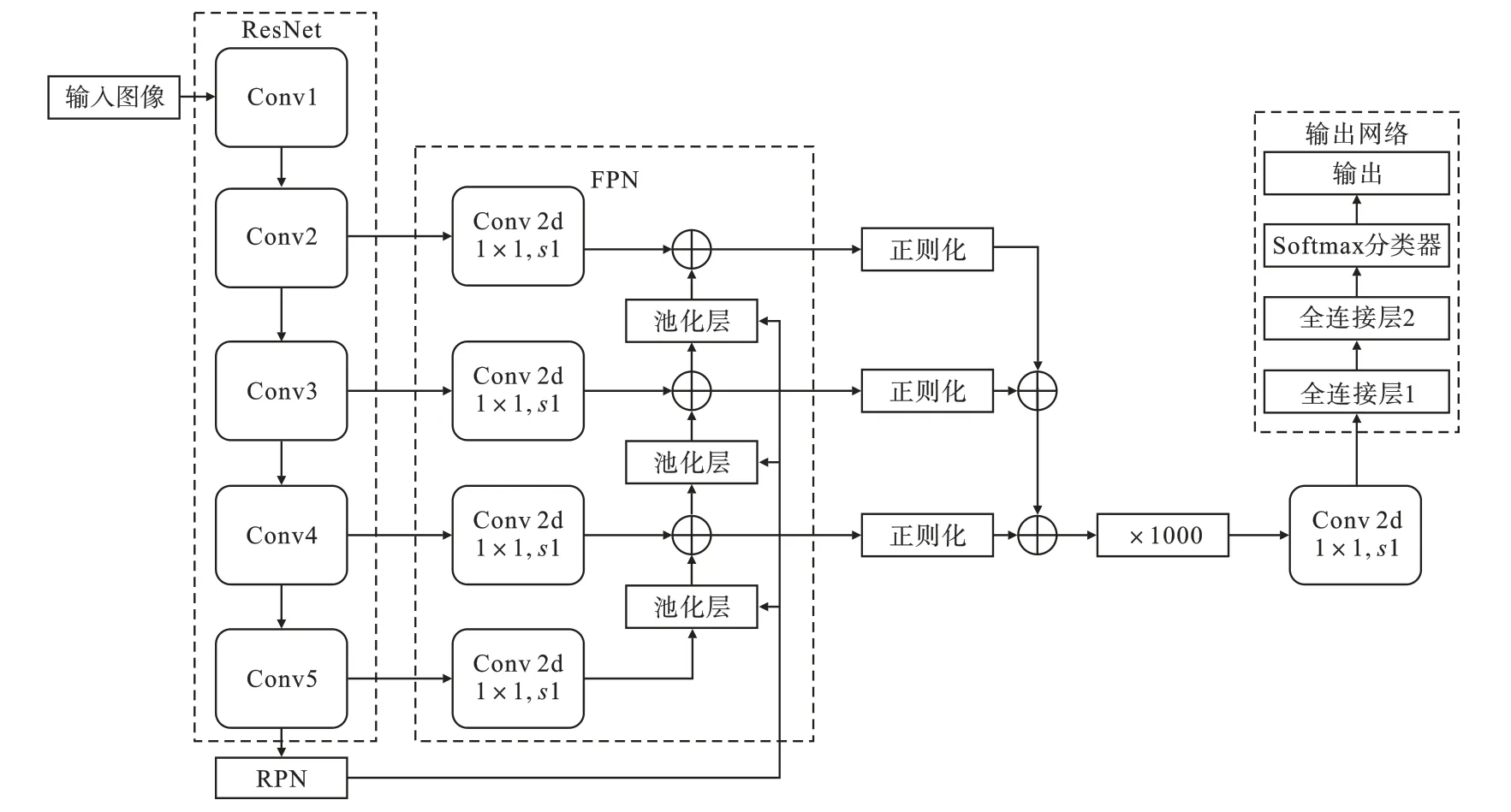
图1 F-Faster-RCNN算法结构图
原始图像经过F-Faster-RCNN算法的主干网络ResNet进行特征提取,并将卷积层Conv2、Conv3、Conv4、Conv5输出的特征图经过1×1的卷积核降维处理。将Conv5层得到的特征图输入到RPN网络中。经RPN网络生成预选框后,分别在Conv3、Conv4、Conv5层降维后的特征图上进行池化,再将每层输出的特征在深度方向上进行第一次相加融合。对第一次融合后输出的三层特征图分别进行正则化,并进行第二次融合。将第二次融合后输出的特征图像素放大1000倍,经过1×1的卷积核进行降维处理。最后,将得到的特征图送入输出网络判断预选框的类别并得出预选框坐标的位置后输出。
F-Faster-RCNN算法的损失函数由两部分组成,分别为分类损失和标定框回归损失。总损失表达式为

分类损失Lcls和标定框回归损失Lre分别为


式中:N表示目标检测网络要训练的样本总数;pi表示第i个样本的预测标定框预测对的概率;表示标志变量,当样本为正样本时,其值为1,当样本为负样本时,其值为0;ti表示第i个样本的预测标定框的回归参数;表示第i个样本的预测标定框对应的真实标定框的值;Ncls表示第一个最小批次所用的样本总数,取值为256;Nre表示预测标定框的个数,约定为2400;Soomth为标定框回归损失函数。
1.2 目标跟踪
本文采用多目标跟踪算法Deepsort与F-Faster-RCNN算法结合以确定人体运动轨迹,算法流程图如图2所示,其中Tracks为跟踪器。

图2 运动目标跟踪算法流程图
从Tracks开始经过卡尔曼滤波[11]预测跟踪框,判断跟踪框内的对象,若不是人体,则设置标识变量confirm为0,将跟踪框与当前帧的FFaster-RCNN检测框面积进行最大交并比匹配;若是人体,则设置confirm为1,将跟踪框与当前帧的F-Faster-RCNN检测框进行数据关联。
采用马氏距离计算两者关联程度,如公式(4)所示。

式中:yi表示第i个跟踪器对目标预测的位置;dj表示第j个检测框的位置;Si表示检测位置与平均跟踪位置之间的协方差矩阵。对马氏距离阈值化处理后得

式中:t为设定的阈值;Π为阈值化处理的门限函数。如果马氏距离小于指定阈值t,则关联成功。
如果数据关联成功则送入Tracks更新并循环上述过程。如果没有关联成功,可能由两种情况导致:第一种情况是Tracks匹配失败,可能是某一时刻发生了漏检(如人体被遮挡、不在拍摄范围之内),预测的轨迹还在,但是检测不到与之对应的目标;另一种情况是F-Faster-RCNN检测框匹配失败,可能是检测范围内出现新的目标。对上述两种情况先将跟踪框与当前帧的F-Faster-RCNN检测框面积进行最大交并比匹配,如果匹配成功,则送入更新循环。如果没匹配成功,针对第一种情况,检测confirm的值,如果为0,则删除;如果为1,则将更新次数与阈值相比较,若更新次数大于阈值(代表目标已不在检测范围内)则删除,若更新次数小于阈值,则送入Tracks更新循环。针对第二种情况,建立一个新的Tracks。
2 基于深度学习的分类器
本文先选取3D CNN进行摔倒动作的特征提取。3D CNN能挖掘帧与帧之间的关系,提取包含视频动作上下文信息的帧间特征。选用SVM作为分类器。SVM的分类效果与核函数参数c和惩罚因子δ有关。惩罚因子越小,分类越细,易出现过拟合,反之易欠拟合。核函数越大,SVM模型的复杂度越大,易出现过拟合,反之易欠拟合。SVM采用铰链最小损失准则寻找c和δ的最优解,将使分类损失为最小值的c和δ的值作为最优解[12],没有考虑到两个参数的范围,仅获得局部最优解。要达到更好的分类效果需要求两个参数的全局最优解。
本文通过参考遗传算法的编码、选择和交叉变异的过程[13]对SVM的两个参数调优过程进行改进,使优化后得到的核函数参数c和惩罚因子δ能达到全局最优解。
SVM参数调优方法如下。
(1)对SVM模型中的c和δ分别进行初始化,并对其进行20位二进制编码,然后随机形成初始种群。
(2)对c和δ分别进行解码,并带入SVM的适应函数中进行训练,得到适应值。
(3)通过适应值把概率大于0.5的个体当作父类进行编码,其余丢弃。
(4)对(3)中父类个体的参数c和δ进行两点交叉[14]操作,根据交叉概率创造新的子类个体。
(5)对(3)中父类个体的参数c和δ进行随机变异操作,根据变异概率改变父类基因,创造新的子类个体。
(6)设定适应度阈值和迭代次数,若达到适应度阈值或迭代次数,则终止,得到最优核函数参数c和惩罚因子δ的值。若没有达到,则返回到(3)。
SVM在摔倒检测中的适应度函数为

约束条件为

式中:ai为拉格朗日因子;xi和xj为样本变量;k(xi,xj)为非线性映射核函数;b为分类阈值。
3 实验结果分析
3.1 实验平台
实验系统CPU采用Intel(R)Core(TM)i7-10875H@2.30 GHz八核;GPU采用NVIDIA Ge-Force RTX 2060;显存为6 GB;操作系统环境为Ubuntu18.04;深度学习框架采用pytorch1.8、tensorflow;编程语言采用python。
3.2 实验结果及分析
3.2.1 运动目标检测实验
分别采用F-Faster-RCNN和Faster-RCNN对数据集进行训练,共训练200轮,初始学习率为10-4,训练的总损失、标定框回归损失及分类损失如表1所示。

表1 不同目标检测算法训练损失对比
由表1可见,本文提出的F-Faster-RCNN算法总损失为0.022 0,较Faster-RCNN算法总损失下降了0.010 5,并且分类损失和标定框回归损失都有所下降。
采用训练好的F-Faster-RCNN模型与Deepsort算法结合进行跟踪,得到视频帧。目标跟踪效果如图3所示。

图3 目标跟踪效果图
由图3可见,图中的行人均被检测到,未出现目标(object)漏检情况,在人体遮挡且受光线较强影响时,算法仍能对小目标object59进行跟踪。此外,该算法在多人且背景复杂的情况下鲁棒性较强。
3.2.2 分类器参数调优实验
首先将跟踪器中输出视频分割为不同帧数的图像序列,设置帧数W={4,8,16,32,64,128}。
W为不同帧数的集合,将每一份图像序列的图像尺寸按照3×l×112×112进行裁剪,其中l表示该份图像序列中的帧数,l∈W。对完成分割和裁剪的图像序列送入训练好的3D CNN,提取特征数据。
将提取出的特征数据送入SVM分类器训练,设定初始种群数为50,交叉概率为0.7,变异概率为0.1,迭代次数为150,适应度阈值为97.5%,图4为SVM的适应度曲线。

图4 SVM的适应度曲线
图4是SVM训练了100次得到的适应度曲线,可以看到训练次数越高,适应度的值越高,当训练到85次时曲线趋于平稳,训练第100次时适应度达到97.5%,停止训练,此时适应度对应的最佳核函数参数c为5.2,最佳惩罚因子δ为230.8。
3.2.3 摔倒检测实验
深度学习在检测过程中常用精确率和召回率评价模型的好坏,每个类别都可以根据精确率和召回率绘制一个关系曲线(PR曲线),其与横轴围成的面积即为准确率。多个类别的平均准确率越高,代表检测效果越好。
基于F-Faster-RCNN算法的摔倒检测PR曲线如图5所示,图6为采用Faster-RCNN作为目标检测算法且SVM分类器没有进行参数优化的传统检测算法的PR曲线。

图5 F-Faster-RCNN算法PR曲线

图6 传统摔倒检测算法PR曲线
由图5可见,对摔倒类别(fall)的检测准确率达到0.938,非摔倒类别(nofall)的检测准确率达到0.750,所有类别(all classes)的平均准确率(mAP)达到0.844。与图6相比,本文提出的算法对摔倒类别检测准确率提高了8.2%,平均准确率提高了6.9%。可见,F-Faster-RCNN模型对摔倒检测具有较好的效果。对非摔倒类别,F-Faster-RCNN模型检测效果一般,这是因为非摔倒样本对于二分类的SVM分类器来说类别复杂度较大。
摔倒检测效果如图7所示。

图7 摔倒检测效果图
由图7可以看出,在俯视拍摄的情况下没有发生漏检的情况,图中摔倒的准确率达到92%;在行人有一半的身体已经超出检测范围且有遮挡的情况下仍能对人体进行检测且准确率为72%;在有摊位遮挡的情况下检测精度达到88%。由此可见,本文提出的检测模型在俯视、有遮挡、检测目标不清晰的情况下仍能对运动目标进行检测,且检测效果较好,可达到一定精度。
4 结论
通过改进Faster-RCNN算法的主干网络并参考FPN,提出了F-Faster-RCNN算法,提升了目标检测的精度。采用Deepsort算法与F-Faster-RCNN算法结合,实现了运动目标的跟踪。通过对SVM算法的参数调优过程进行改进,使优化后得到核函数和惩罚因子的全局最优解。采用3D CNN网络提取帧间特征,并与SVM算法结合实现了对摔倒行为的判别。仿真结果表明,基于FFaster-RCNN的摔倒检测算法在有遮挡、俯视和目标模糊的情况下,仍能检测出运动目标,对比采用Faster-RCNN作为目标检测算法且SVM分类器没有进行参数优化的摔倒检测模型,准确度有一定提升,能有效完成摔倒动作检测。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
数学小灵通·3-4年级(2021年5期)2021-07-16
汽车维修与保养(2020年11期)2020-06-09
今日农业(2019年15期)2019-01-03
郑州大学学报(工学版)(2018年2期)2018-04-13
中国惯性技术学报(2017年1期)2017-06-09
光学精密工程(2016年3期)2016-11-07
中国塑料(2016年11期)2016-04-16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
