
多级度量网络的小样本学习
2023-01-29 13:15韦世红刘红梅朱龙娇
计算机工程与应用 2023年2期
韦世红,刘红梅,唐 宏,朱龙娇
1.重庆邮电大学 通信与信息工程学院,重庆400065
2.重庆邮电大学 移动通信技术重庆市重点实验室,重庆400065
近年来,深度学习在计算机视觉、语音识别等领域得到广泛应用。图像分类作为计算机视觉领域一项基础性工作取得了突破性进展。尽管神经网络模型在图像分类任务中取得了很好的效果,但对数据量的要求限制了其性能的发挥。当训练样本量不足时,深度学习模型不可避免地会出现过拟合问题,导致学习失败。然而,人类拥有可以从少量的样本中快速学习理解某一类事物,并将其识别泛化的能力。受此启发,小样本学习的概念应运而生。小样本学习旨在让深度学习模型在数据量受限的情况下以人类的学习方式完成训练任务。由于在现实场景中很多数据都遵循长尾分布,获取大量标签样本费时费力,故小样本学习的应用范围非常广泛。例如,对农作物叶片中罕见病害的智能识别,或者是辅助诊断医学领域的罕见病例等。小样本学习利用训练任务之间的共性,通过学习少量的标签样本后可得到一个有效的分类器,极大地降低了数据集的获取成本和难度。故此,如何充分发挥小样本学习在图像分类任务上的潜力,正逐渐成为业内研究热点。
小样本学习领域有四种常用方法:数据增强、迁移学习、元学习以及度量学习。数据增强是解决小样本图像数据集不足最为直接的方法,通常包括旋转、加噪、裁剪、压缩等操作[1]。随着技术的发展,更多的数据增强方法被提出以生成新的样本。为了使生成样本更加接近真实样本图像,文献[2]提出了生成对抗模型(generative adversarial nets,GAN)。该模型由生成器和判别器两部分组成。生成器用于尽可能生成判别器无法区分的新样本,判别器用于判断生成样本与真实图像的相似性,并将其进行区分。文献[3]提出一种数据自适应增强分类网络模型(data adaptive enhancement and classification network,DA-ECNet)。该模型消除了训练时模型对真实噪声和去噪声图像对的要求,采用域驱动的损耗函数进行图像增强,得到数据自适应图像增强。尽管通过以上方式能扩充样本并在一定程度上缓解过拟合问题,但生成样本与真实图像间具有视觉相似性,很难从根本上解决训练样本匮乏带来的模型训练过拟合问题。在许多真实应用场景中,深度学习模型需要根据样本分布的变化利用新数据从头开始重建并训练参数和特征,但重建模型是昂贵且不可行的。为了减小模型训练的代价,迁移学习利用相似任务间有相同的学习规律可循的思想,将从源域中学习到的参数和特征进行调整并应用到目标域中,在经验信息的基础上快速习得对指定类别的判断泛化能力。从图像分类流程来看,迁移学习作用于特征提取阶段,具体有基于特征迁移、基于共享参数迁移、基于关系迁移三种学习方式。文献[4]提出一种知识迁移网络(knowledge transfer network,KTN)。该模型将视觉特征学习、知识推断和分类器学习联合在一个统一的框架中,自适应地利用显性视觉信息和隐性先验知识。通过优化基类训练数据的余弦相似度,训练基于卷积神经网络的视觉特征提取器,提取样本的表示形式,生成基于视觉的新类别分类器。文献[5]提出一种注意多对抗网络的迁移学习方法(attentional multi-adversarial networks,AMAN)。该模型首先利用高级深度编码器粗略地提取了跨域特征。之后在目标域中注释少量图像,从而创建“活动标签”,为对抗学习提供指导。然后利用基于GAN的层次模型选择跨领域类别,增强相关特征,以促进有效迁移。迁移学习的方法虽然提高了模型的泛化能力,但是模型极易遗忘经验信息,在训练过程中进行参数和特征迁移通常会造成严重的过拟合问题。同时迁移学习在不同复杂度的数据集上分类结果具有一定差异,普适性不强。元学习旨在让机器学会学习,通过利用任务之间的共性使得模型从少量标签样本中进行算法学习,确保元学习器能快速习得解决新学习任务的能力。最为典型的元学习模型为文献[6]提出的模型无关元学习(model-agnostic metalearning,MAML)。它利用基础学习器学习模型在各个任务上的初始化参数,并将优化结果通过梯度信息传递给元学习器进行反向传播,进而优化元学习器参数以获得最小梯度,最后用更新后的元学习器参数初始化基础学习器来进行下一轮的迭代。为了克服监督学习语义分割方法的局限性,文献[7]提出了一种广义的元学习框架(meta-seg)。它包括元学习器和基础学习器。元学习器从分布的少量语义分割任务中学习到良好的初始化值和参数更新策略。基础学习器理论上可以是任何语义模型,并可以在元学习器的指导下实现快速适应。元学习方法因其良好的分类效果而备受青睐,但复杂的网络结构使得模型效率较低,训练模型需要花费大量的时间。度量学习旨在将样本映射到一个公共特征空间,在学习的过程中目标函数确保相似物体之间的距离减小,不同物体之间的距离增大,最后基于距离建立相似度并根据相似度将样本划分到正确类别中。基于度量的小样本学习模型专注于研究在一个公共的特征空间下样本间的分布规律。目前最为经典的模型有匹配网络(matching networks,MN)[8]、原型网络(prototypical networks,PN)[9]以及关系网络(relation network,RN)[10]这三种。文献[11]在匹配网络的基础上提出了一种记忆匹配网络(memory matching networks,MMN)。该网络结合内部存储器和双向长短期记忆网络(long shortterm memory,LSTM)将记忆图像特征压缩进记忆间隙并进行编码,不仅提高了图像特征的表示能力,还降低了模型计算复杂度。文献[12]提出一种可转移原型网络模型(transferrable prototypical networks,TPN)。该模型学习一个嵌入空间用于自适应,使源域和目标域中每个类的原型在嵌入空间中接近,并通过重构每个类的原型距离来进行分类。相比于原型网络,该模型不仅提高了分类准确率还提高了模型的泛化能力。文献[13]提出一种自注意关系网络模型(self-attention relation network,SARN)。该网络由嵌入模块、注意模块和关系模块三个模块组成。与现有关系网络相比,SARN可以发现非局部信息,并允许远程依赖,通过将支持集替换为语义向量,可以很容易地将SARN扩展到零样本学习。度量学习不仅思想简单直接,而且相较于其他小样本学习方法能够更加快速、有效地进行学习。
尽管度量学习效果十分显著,但传统的度量学习模型采用的都是图像级全局特征。在数据样本稀缺的情况下,这些全局特征并不能有效地表征类别分布,在一定程度上影响了最终的分类结果。另外,传统的深度学习模型在利用神经网络进行特征提取时,由于逐层的卷积使得图片特征尺寸减小,不可避免地会丢失部分有价值的信息,限制了卷积神经网络的性能。针对以上两个问题,本文的工作如下:
(1)提出一种多级度量模块,在传统图像级度量的基础上融合图像-类的度量。图像-类的度量与朴素贝叶斯最近邻方法(Naive-Bayes nearest-neighbor,NBNN)[14]相似,将查询样本特征与代表某一类别图像的局部不变特征池进行相似性度量,能够弥补图像级度量不能有效表达一个类别分布的不足。同时,用一个inception模块替换原有度量学习网络中第一个卷积块以增加网络宽度,从而提高网络效率。
(2)本文将第二层、第三层卷积所得特征描述子分别进行类别级度量,再将第四层卷积所得特征向量全连接后进行图像级度量,最后再融合度量结果。该方法可有效解决图像局部细节特征在量化过程中带来的有效信息丢失的问题。
(3)不同于传统训练方法,本文在模型训练过程中参考迁移学习的思想,以上层网络训练结果作为下层网络训练的初始值来训练模型,从而提高图像级与类别级网络融合度。
(4)由于不同卷积层的度量结果对最终的图像分类结果贡献不同,本文通过交叉验证给不同卷积层所得图像关系得分或图像从属概率赋权值再融合,以得到最佳的分类结果。
1 相关工作
1.1 原型网络
原型网络是由Snell等人提出的一种较为简单有效的小样本学习算法,旨在通过学习一个新的度量空间来进行类别划分。在新度量空间中以支持集中某类标签样本嵌入空间特征向量的均值为类原型,度量查询集中样本嵌入空间特征向量到各类原型的欧式距离,采用最近邻的思想将查询样本划分到正确的类别中去。
原型网络会为支持集中每一类标签样本计算出一个类原型Ck,通过映射函数fφ:RD→RM将标签样本映射到M维嵌入空间中。如图1所示,C1、C2、C3分别代表三个不同的类原型,X代表查询集样本嵌入空间特征向量。
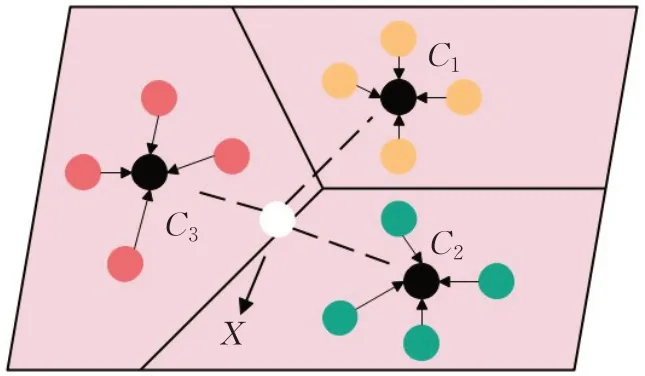
图1 原型网络分类原理图Fig.1 Prototype network classification schematic diagram
类原型Ck的计算如公式(1):

其中,Sk代表支持集中第k个类别的数据集,xi表示支持集标签样本D维特征向量,yi表示xi的样本标签,
fφ()
xi表示支持集标签样本嵌入空间特征向量。
为了得到查询集样本x的从属概率Pφ(y=k|x),将Softmax函数作用到查询集样本嵌入空间特征向量到类原型的欧式距离-d(fφ(x),Ck)。其概率分布如公式(2):

1.2 关系网络
关系网络是Sung等人在2018年提出的一种小样本学习算法,与传统的度量学习方法不同,其首次在度量样本间相似度上引入了神经网络来学习距离函数。如图2所示,关系网络由嵌入模块和关系模块两部分组成。模型首先通过嵌入模块来获取支持集标签样本和查询集样本的嵌入空间特征向量,再将两者的特征向量进行拼接,最后利用关系模块中的度量学习网络来比较样本间的相似性,并给出关系得分。
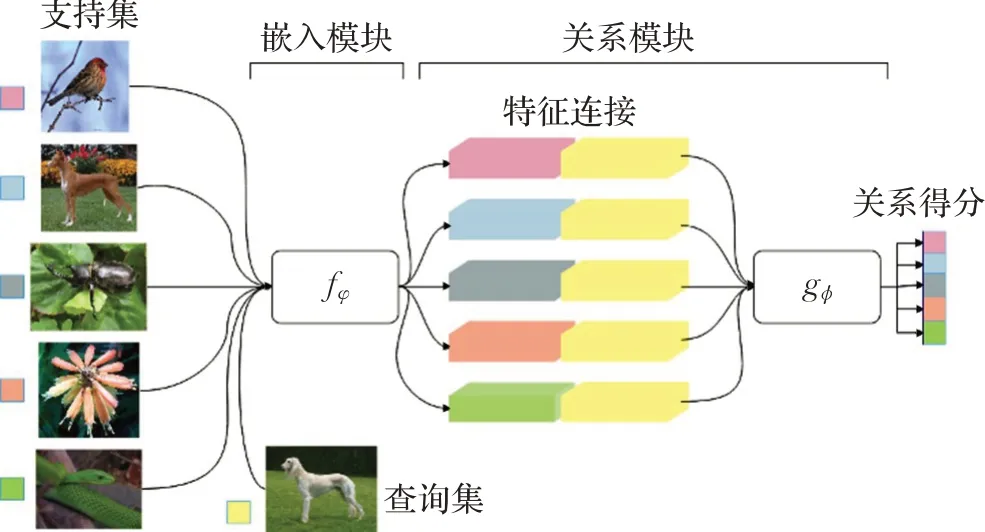
图2 关系网络结构图Fig.2 Relationship network structure diagram
关系得分ri,j的计算如公式(3):
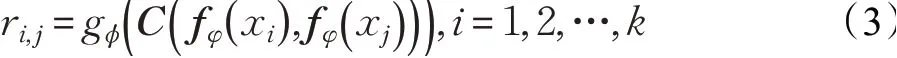
其中,fφ代表嵌入模块,gϕ为度量学习网络,fφ(xi)代表支持集标签样本嵌入空间特征向量,fφ(xj)代表查询集样本嵌入空间特征向量,C(fφ(xi),fφ(xj))代表拼接后特征向量。
1.3 图像-类的度量
传统的大规模图像分类设计都利用的是图像级全局特征进行分类。然而,将一张图像的局部细节特征进行量化编码从而得到图像级全局特征的过程中往往会丢失相当一部分判别信息,这使得图像级全局特征不能有效地表达一个类别的分布。朴素贝叶斯最近邻方法(NBNN)以此为切入点,利用计算机视觉中同一类图像的局部特征可打乱拼凑成一个全新的图像的原理,提出了图像-类的度量方式。该方法可以很好地表达一个类别的分布,且有效地避免了图像局部特征利用不足的问题。图像-类的度量旨在通过查询样本的局部特征描述子最近邻搜索某一类别的图像特征池来实现,即通过计算某一查询样本到某一类别的距离或相似度将图像划分到正确的类别中去。但是传统的图像分类任务包含大量的标签数据,在大量的局部描述子集合中进行最近邻搜索费时费力,从而限制了该方法的应用。因此,相较于传统的大规模分类任务,图像-类的度量方式更适合于解决小样本分类问题。受此启发,文献[15]提出了一种由嵌入模块和图像-类的度量模块组成的深度最近邻神经网络(deep nearest neighbor neural network,DN4)。该网络首次将图像-类的度量运用到小样本学习。不同于传统手工提取特征的方式,其利用神经网络提取深度局部描述子,并与图像-类的度量模块进行结合,构成了一个端到端的训练模型。该网络模型分类效果显著,为后续从类别级角度研究小样本学习提供参考。
2 本文方法
2.1 问题定义
小样本学习一般将数据集划分为训练集Train、验证集Val以及测试集Test三个部分。在以N-wayKshot为训练方式的小样本学习中,每个任务由支持集S与查询集Q组成。其中N代表支持集中所包含的类别数,并从每个类别中随机抽取K个标签样本来构成支持集,再从每类剩余的样本中抽取查询集。在训练过程中采用广泛应用于小样本学习的episodes训练策略来训练模型。最后通过大量的episodes学习来不断优化模型,最小化查询集样本预测损失。
2.2 多级度量网络
基于度量的小样本学习方法的核心思想是学习一个深度嵌入神经网络,并使得该网络学到的特征能够很好地泛化到新任务上。其中代表性的方法包括原型网络和关系网络。原型网络为每个支持集都学习一个原型,即一组特征向量的均值。关系网络也为每个支持集采用均值特征表示,但它更侧重于如何度量查询样本和支持集样本间的关系。具体地,关系网络通过学习一个非线性的深度度量学习网络来进行距离度量。但是,这些方法采用的都是图像级全局特征,而在数据样本稀缺的情况下,这些全局特征并不能非常有效地表征类别分布,使得最终的分类结果不准确。为了解决以上现有技术存在的问题,本文尝试引入图像-类的度量来弥补图像类别特征表达能力不足的问题。
如图3所示,本文所提模型由嵌入模块和多级度量模块两部分组成。其中,嵌入模块采用基于前馈卷积神经网络的四个卷积块标准架构。每个卷积块由一个含有64个3×3卷积的卷积层、一个批量归一化层和一个Relu激活函数层构成。前两个卷积块后各添加一个2×2最大池化层。多级度量模块以原型网络作为图像-图像的度量网络,以融合DN4思想的关系网络作为图像-类的度量网络。多级度量网络首先通过嵌入模块提取支持集和查询集中样本的特征向量;然后对经过第二层卷积和第三层卷积后得到的特征描述子分别进行图像-类的度量,对经过第四层卷积后得到的特征向量进行全连接,并做图像-图像的度量;最后利用交叉验证加权融合由多级度量模块得出的图像从属概率以及关系得分,并给出最终预测结果。
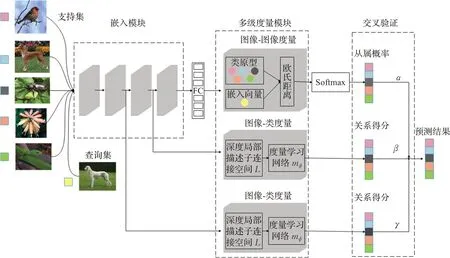
图3 多级度量网络的小样本学习方法整体框架图Fig.3 Overall block diagram of multilevel metric networks for few-shot learning
具体地,图像-类的度量由深度局部描述子连接空间L和度量学习网络mϕ构成。
深度局部描述子空间:
支持集与查询集样本在经过嵌入模块计算后分别得到特征图S和Q。每个c×h×w大小的特征图可看作包含h×w个c维深度局部描述子的深度局部描述子空间D,c为通道数,h为特征图高度,w为特征图宽度。公式(4)如下:
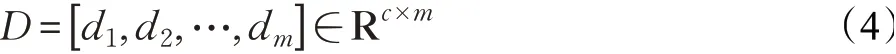
其中,m=h×w,代表的深度局部描述子的个数,di即为第i个深度局部描述子。
传统的图像-类的度量采用查询集样本的局部特征描述子最近邻搜索某一类别的图像特征池来实现,而文献[16]将DN4思想与关系网络结合,用度量学习网络来判断图像和类别的关系。采用双线性CNN(Bilinear CNN)[17]的思想,以支持集和查询集特征图之间两两点乘所得结果作为网络特征连接,得到一个维度为m×m的深度局部描述子连接空间L。特征连接表达式(5)如下:

其中,DS为支持集深度局部描述子空间、DQ为查询集深度局部描述子空间。
度量学习网络:
该网络将深度局部描述子连接空间L映射到一个新的度量空间,通过新的度量空间来度量类间相似性并给每个L生成一个关系得分。由于使用双线性运算法对特征进行连接使得新合成的特征图尺寸增大,需要通过增加网络的深度或宽度来对特征进行映射,所以本文用一个inception块来替换关系网络中度量学习网络的第一个卷积块。改进后的度量学习网络mϕ如图4所示,该部分网络由1个inception块、1个卷积块、1个2×2最大池化层和两个全连接层组成,卷积块的组成同嵌入模块。其中inception模块由三个分支组成,分别为一个3×3卷积模块、一个3×3卷积加2×2最大池化模块以及一个1×1卷积和两个3×3卷积拼接模块,最后将3个分支的输出特征进行全连接。

图4 度量学习网络mϕ结构图Fig.4 Metric learning network mϕ structure diagram
通过度量学习网络可得类别级度量关系得分Pi,j如公式(6):
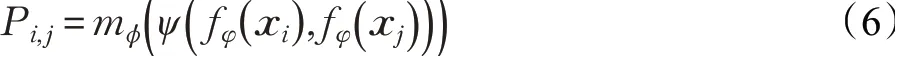
其中,xi为支持集标签样本特征向量,xj为查询集样本特征向量,fφ为嵌入模块,ψ(fφ(xi),fφ(xj))为深度局部描述子连接,mϕ为改进后的度量学习网络。
图像-类的度量模块采用均方差损失函数来优化网络参数,损失函数L1如公式(7):

其中,Pi,j为关系得分,yk为样本标签,深度局部特征描述子匹配时为1,不匹配时为0。
在图像-图像的度量模块,采用原型网络来获取图像的从属概率。
图像-图像的度量模块采用交叉熵损失函数来优化网络参数,损失函数L2如公式(8):

其中,Pφ(y=k|x)代表图像的从属概率。
最后通过交叉验证得出各模块权重,并对图像从属概率和关系得分进行加权融合从而给出模型最终预测结果。假设一个图像-图像的度量模块对类别k的分类从属概率为,两个图像-类的度量模块对类别k的关系得分分别为看作三个以类别数为长度的概率向量,计算三个向量的加权和,并取其累积最大值为最终预测结果,如公式(9):

其中,α、β、γ是各模块权重,α+β+γ=1。
3 实验
本章内容为了验证多级度量网络对小样本学习的有效性,在小样本数据集上分别做了性能对比实验、鲁棒性分析以及时间复杂度分析。
3.1 数据集
Omniglot[18]作为小样本学习的一个基准数据集,共包含来自50种不同语言的1 623类手写字符,每一类字符又包含20个样本。本文分别以90°、180°及270°旋转图像来扩张数据集,每张图片通过裁剪将尺寸统一为28×28像素。
miniImageNet是ImageNet[19]数据集的一个子集,包含100个类别,每类600张图像,共计60 000张图像。本文以其中64个类别作为训练集,16个类别作为验证集,20个类别作为测试集,所有输入图像的尺寸统一裁剪为84×84像素。
CUB[20]是由加利福尼亚理工学院提供的鸟类数据集,包含200个类别,共计11 788张常见鸟类图像。本文中的训练集、验证集及测试集分别为100、50及50个类别,图像尺寸统一裁剪为84×84像素。
3.2 模型参数设置
通过阅读文献[21-22]可知,相较于其他梯度下降算法,Adam算法能够使深度学习模型快速收敛并取得更小的分类损失。所以本文采用Adam算法来优化整个模型的参数,算法超参数设置具体如表1所示。

表1 模型算法超参数设置Table 1 Model hyperparameter
训练过程中,模型采用了5-way 1-shot和5-way 5-shot两种实验方式,每100个episodes计为一个epoch,每隔10个epoch学习率减半。在5-way 1-shot实验中,模型中每一分支网络共经过600个epoch来训练参数。在5-way 5-shot实验中,模型中每一分支网络共经过400个epoch来完成参数训练。
3.3 训练过程
与传统的结果融合网络分别单独训练模型参数再融合图像分类概率不同,本文引入迁移学习的思想进行模型训练。模型首先对第二层卷积部分采用类别级度量得出相似度得分,再用Adam算法对损失函数进行优化,得到训练特征和参数;然后将第二层及其之前的卷积部分进行冻结,以当前所得特征和参数作为第三层卷积的初始化参数和特征,再重复与第二层同样的训练;最后冻结第三层及其之前部分,以其训练所得参数和特征作为第四层图像级度量的初始化特征和参数,然后用Softmax函数对度量距离进行运算得到从属概率,再用Adam算法对模型进行训练。不断调整模型的参数,当模型的损失函数值达到最小时,完成模型的训练。
3.4 实验结果与分析
为了验证本模型训练过程的有效性,将经过传统训练过程与本文训练过程所得图像分类准确率进行对比。如表2所示,在5-way 1-shot和5-way 5-shot实验中,本文训练过程在Omniglot、CUB、miniImageNet三个数据集上准确率都有一定的提高。实验结果表明,结合迁移学习的思想进行模型融合相较于传统方法更适合本模型的训练。
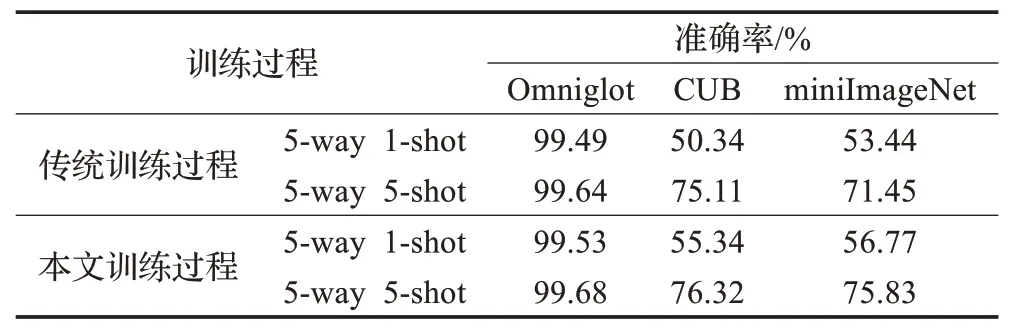
表2 训练过程对比实验Table 2 Contrastive experiment of training process
为了验证本模型在小样本图像分类上的有效性,将本模型与其他模型在Omniglot、CUB、miniImageNet三个数据集上的分类准确率进行对比。如表3所示,本模型在Omniglot数据集上相较于传统的方法准确率有一定的提高。在5-way 5-shot实验中,与MMN相比存在0.09个百分点的差距。相较于FPN、STANet-S、Spot and Learn及TPN这四个模型,本模型在5-way 1-shot实验中准确率分别提高了1.23、0.84、1.97、0.27个百分点,在5-way 5-shot实验中准确率分别提高了0.08、0.09、0.03、0.24个百分点。如表4所示,在CUB数据集上,本模型相较于MN、PN、RN这三个经典模型的准确率有显著提高。与CovaMNet相比,本模型在5-way 1-shot实验中,准确率提高了2.92个百分点,在5-way 5-shot实验中,准确率提高了12.56个百分点。与DN4相比,本模型在5-way 1-shot实验中,准确率提高了8.50个百分点,在5-way 5-shot实验中,准确率提高了1.40个百分点。与FAN相比,本模型在5-way 1-shot实验中,准确率提高了1.04个百分点,在5-way 5-shot实验中,准确率提高了5.62个百分点。如表5所示,在miniImageNet数据集上,本模型分类准确率相较于MN、PN、MN、MAML这四个模型有显著提高。本模型与元学习LSTM、MMN、TPN、DN4、FAN、CovaMNet及FEAT相比,在5-way 1-shot实验中,准确率分别提高了13.33、3.40、2.33、5.53、5.27、5.58及1.62个百分点,在5-way 5-shot实验中,准确率分别上升了15.23、8.86、8.87、4.81、5.43、8.18、4.22个百分点。与MNE相比,本模型在5-way 1-shot实验中存在3.43个百分点的差距,在5-way 5-shot实验中,本模型准确率提高了3.67个百分点。通过准确率对比实验可得,本文方法可以有效提高小样本图像分类准确率。
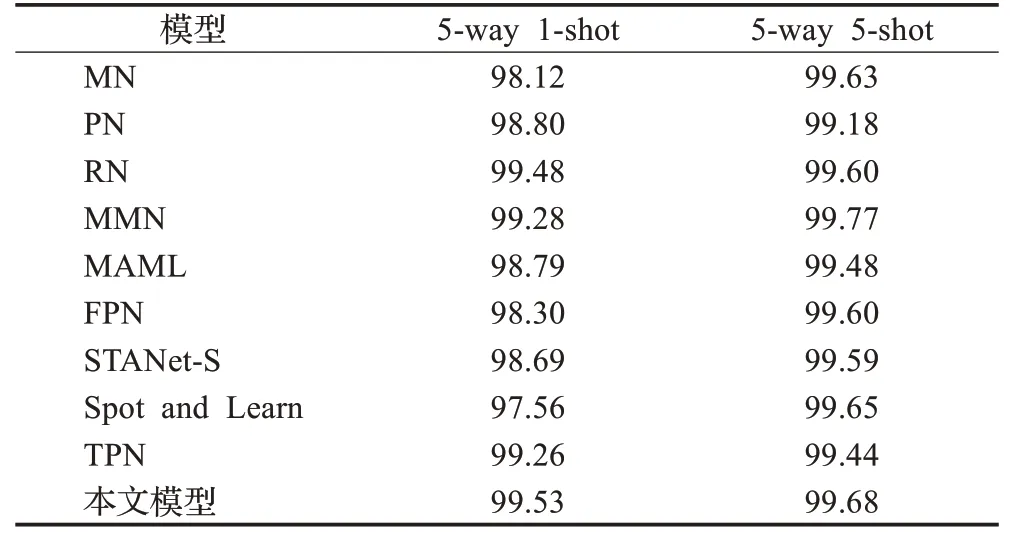
表3 不同模型在Omniglot数据集上准确率对比Table 3 Accuracy comparison of different models on Omniglot dataset 单位:%

表4 不同模型在CUB数据集上准确率对比Table 4 Accuracy comparison of different models on CUB dataset 单位:%

表5 不同模型在miniImageNet数据集上准确率对比Table 5 Accuracy comparison of different models on miniImageNet dataset 单位:%
3.5 鲁棒性分析
为了进一步验证本模型的鲁棒性,本文在CUB和miniImageNet两个数据集上保证验证集和测试集不变的情况下,对比验证了5-way 5-shot和5-way 1-shot实验中模型的分类准确率随训练集类别数的变化情况。在miniImageNet数据集上,以8类为间隔,依次改变训练集的类别数为64类、56类、48类、40类、32类、24类以及16类。在CUB数据集上,以10类为间隔,依次改变训练集的类别数为100类、90类、80类、70类、60类以及50类。
由图5~8可知,在CUB和miniImageNet两个数据集上,本模型的分类准确率随训练集类别数的减少逐渐降低。但在5-way 5-shot实验中最终仍能保持50%以上的分类准确率,在5-way 1-shot实验中最终能保持30%以上的分类准确率。本模型的鲁棒性明显优于PN和RN,和DN4相比也存在一定优势。

图5 miniImageNet数据集上5-shot鲁棒性测试图Fig.5 5-shot robustness test graph on miniImageNet dataset

图8 CUB数据集上1-shot鲁棒性测试图Fig.8 1-shot robustness test graph on CUB dataset
3.6 时间复杂度分析
传统的小样本学习模型时间复杂度分析都是基于模型迭代一次所花费的时间来进行比较。由于本文在模型训练过程中引入迁移学习的思想,以前一个网络训练所得参数作为下一个网络的初始值,所以在模型时间复杂度的计算上以三个网络分别迭代一次花费时间的累加作为整个模型迭代一次的训练时间。本文在miniImageNet数据集上采用5-way 1-shot实验对模型效率进行了对比分析。
如表6所示,本文方法与PN、DN4、MN相比耗时较高,但是分类准确率分别提高了7.35、5.53、13.21个百分点。本文方法耗时为RN的0.7倍,但分类准确率也有明显提高。元学习LSTM方法耗时为本文的1.3倍,同时分类准确率与本文相差13.33个百分点。通过以上分析可知本文方法在达到较高分类性能的同时,分类效率也能保持在一定的水平。
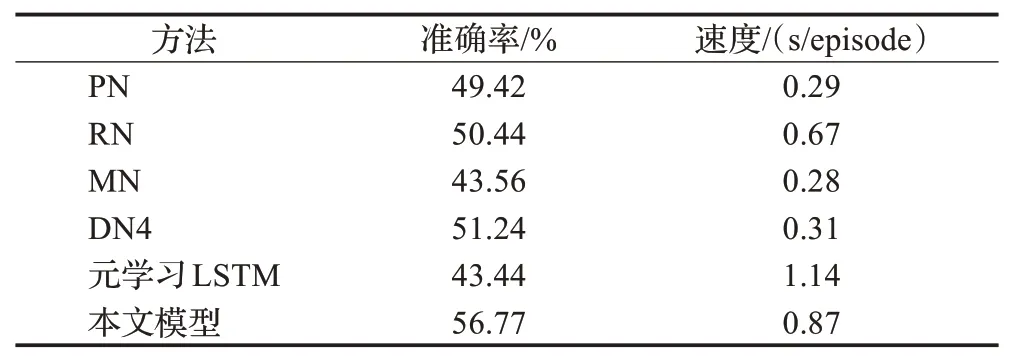
表6 不同模型在miniImageNet数据集上效率对比Table 6 Efficiency comparison of different models on miniImageNet dataset
4 结束语
本文提出了一种多级度量网络的小样本学习方法,这是首次将图像-图像的度量与图像-类的度量进行结合,从多个角度考虑图像的表达分布以有效挖掘图像语义信息的研究。不同数据集上的仿真实验结果表明,本模型在小样本分类任务上相较于传统方法有较好的分类性能,从而也进一步证明了模型能有效表达图像特征分布并有效挖掘图像的语义信息。本文研究思路虽然为小样本学习提供了另一种可能,但仍然有改进的空间。下一步工作重点是改进图像-图像的度量模块以减小图像级度量误差,优化嵌入模块和度量学习网络以提高模型效率。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2020年3期)2020-07-27
电子制作(2019年13期)2020-01-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
电子制作(2019年11期)2019-07-04
民族古籍研究(2018年1期)2018-05-21
北京航空航天大学学报(2018年1期)2018-04-20
西夏学(2016年2期)2016-10-26
中国学术期刊文摘(2016年1期)2016-02-13
