
基于随机森林算法的配电网停电研判方案设计
2023-01-30 13:22余剑锋何云良吴华华魏骁雄陈博钟震远
微型电脑应用 2022年12期
余剑锋, 何云良, 吴华华, 魏骁雄, 陈博, 钟震远
(1.国网浙江省电力有限公司, 浙江, 杭州 311100;2.国网浙江省电力有限公司营销服务中心, 浙江, 杭州 311100)
0 引言
随着智能配电网的不断应用,提高了电网的供电效率以及可靠性,同时可以实现获取电网的相关数据,提高电网的抢修效率。智能电网平台通常只能对于停电故障发生后进行业务处理的管理,无法实现根据故障数据的故障研判,因此一些研究者对配电网数据的研判方案进行了研究:文献[1]提出了基于配电网拓扑结构等效耦合故障研判方法,分析了配电网故障研究与判断的基本原理以及常见的配电网故障研究与判断逻辑,实现了分布式配电网拓扑网络结构单故障和多故障的准确判断;文献[2]提出了融入低压智能电表的配电网故障研判,结合低压GIS对配电网自动化系统等多源业务系统数据进行智能诊断,开发低压整体故障分析仪,设置配电中的定位网络,低压故障类型识别和分析等功能模块,实现低压配电网的模块化应急维修。通常采用的研判模式的开发接口较多,难以适应大型电网,且以上几种研判方案均是在故障出现导致停电后才对单一节点的数据进行处理,无法对整体数据进行关联查找。因此研判结果的准确性受到了影响,需要进一步的改进[3-4]。
1 基于随机森林算法的配电网停电研判方法设计
1.1 随机森林电网数据集样本训练
用随机森林算法对配电网中的数据进行提取和训练,包括电能运行数据、设备管理数据及故障数据,以此来获得相对应的异常数据集,并作为未来停电研判的基础[5-6]。首先设获取到的配电网存在m个样本的数据集G,而在进行数据集样本采样过程中获得的数据集为D。在数据集G随机提取样本并将样本拷贝至D内,并重复m次,得到存在数据集G内m个数据的数据集D。那么在进行m次的采样时不会抽到的概率为(1-1/m),得到极限值:
(1)
该过程可以通过Bootstrap来进行反复抽取,并保证获得数据集的集中率在37%左右。那么得出的样本就可以作为OOB样本,作为随机森林算法的样本。而在随机森林算法中通过抽取后的样本数据集D中的k类样本占比为pk(k=1,2,…,|y|),那么D的信息熵则为
(2)
其中,特征集内的特征a属于离散型的数据,则对于特征a的取值则存在V种可能,即{a1,a2,…,av},且对于样本集D的划分可以使用特征a来进行。并在其中产生出V个分支点。设在第V个分支中包含的数据集D中的特征a中取值av的样本为Dv。计算得出离散特征a的数据集D划分出的信息熵:
(3)
而当特征a属于连续数据时,特征a则可以根据取得递增情况来进行排序,并将取值得出的相邻点看作不同可能下的分裂[7-8],则对数据集D的信息熵划分则改变为
(4)
式中,DL以及DR代表通过分裂点分出的两部分子集,并以此来获得特征a所划分的集合D的熵值。在确定不同特征下的数据类型并获得相应的信息熵,进而则可以计算其中的信息增益:
Gain(D,a)=Ent(D)-Enta(D)
(4)
则增益率计算为
Gainratio(D,a)=Gain(D,a)/IV(a)
(5)
而其中IV(a)的计算式为
(6)
以此得出随机森林运算的样本训练模式,用以进行停电事件研判。
1.2 配电网分层拓扑模型建立
配电网停电通常受到其中的故障原因,在对配电网停电的研判时,需要对配电网的故障情况进行考虑[9-10]。本文采用分层拓扑模型来进行配电网故障情况的运算,建立的配电网分层拓扑模式如图1所示。

图1 配电网拓扑模型示意图


(7)
在配电网中,当用户发出故障信息或触发故障检测设备的情况下,通常可以直接获取到故障用户的位置,实现对用户的定位。在该条件下点子集为Ck=(ck1,ck2,…,ckn)T,而其中的故障信息向量为Pk=(pck1,pck2,…,pckn),那么配变层的父节点tk所对应故障信息pTk为

(8)
就此建立配电网的故障停电模型,来对故障情况下停电原因进行判断。
1.3 停电事件研判实现
相关的配电网研判方案,在具体实现时,可以使用兼容性较高的自动数据处理方法来进行,以适应当前智能电网的需求。本文对于配电网的研判采用自动数据来进行,开发通过PMS2.0来进行,并在其中导入上文中的运算方式。研判过程如图2所示。
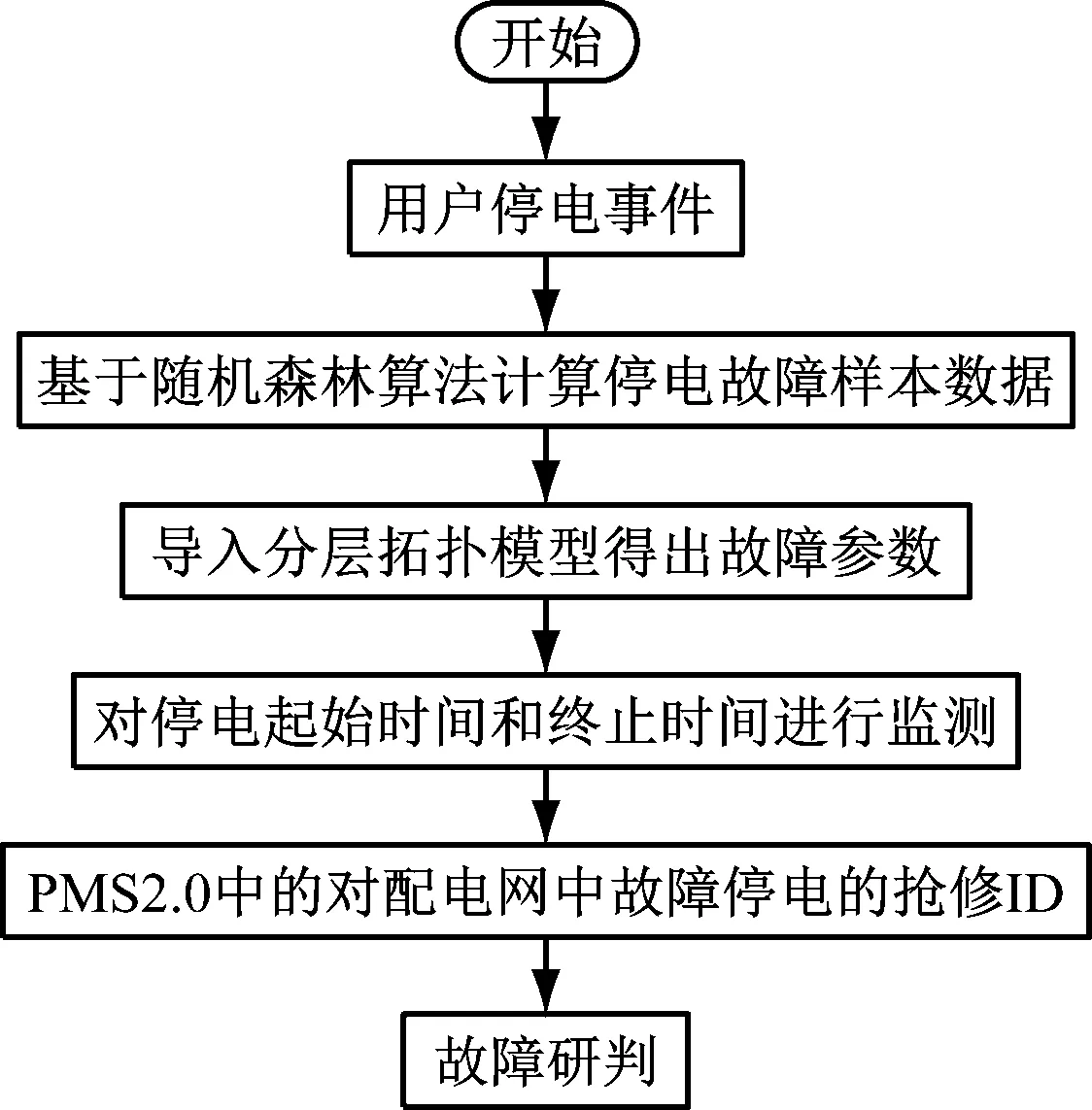
图2 停电数据研判流程图
停电数据研判流程如下:
(1)首先使用上文中的完成训练的随机森林算法,处理配电网中的数据,得出会导致停电的故障样本数据;
(2)将故障样本数据导入至配电网的分层拓扑模型,得出得到具体的故障参数;
(3)依据配电网中带有的监测对用户的停电时间和用户标识、停电起始时间和终止时间进行数据监测。同时进行判断,在可靠性的停电中,获取到用户中的表示和在研判中的PMS2.0中的对配电网中故障停电的抢修ID,并对用户的停电终止时间,进行故障研判,大致得出相应的预计电力恢复时间;
(4)最后将搭载研判方案的PMS2.0与配电网中的数据许可相联系,使方案可以随着抢修进度的推进校正得出的数据结果,从而得到实时的停电事件研判结果。
2 实验论证分析
为了验证配电网的研判方案的可行性,设计对比实验。以某地变电站构成的配电网作为停电研判方案的验证基础。并采用文献[1]、文献[2]中的研判方案与本文方案中的算法对其中的数据进行运算。并判断3种研判方案对于配电网故障数据的查全率以及查准率。
2.1 实验变电站网络
实验的对象配电网络,基于如下的变电站网络而建立,网络简化图如图3所示。

图3 简化变电站网络
配电网的信号域数据如表1所示。

表1 配电网络信息域和数据
在该配电网络中,T代表网络中的变压器,L1、L2均为用户的输电线路。A、B、C、D代表配电网络母线,图3中的M1~M8均代表配电网络中的量测装置,分别为变频电源检测器、电流检测器、高压开关装置、集中处理器、功率检测器、馈线终端装置、远程终端单元及数字量模块。
2.2 配电网停电故障预测指标计算
实验对配电网的故障网络预测,过程中的使用数据相同,并依据其中的查准率以及查全率两种指标来进行判断,实验评判指标计算方法如下:
(9)
(10)
式中,precision代表实验中研判方案对故障数据的查准率,recall代表实验中研判方案对故障数据的查全率,Np代表预测正确样本数,Nt代表进行处理的样本数,Nr代表真实样本数。
2.3 实验结果
本文实验在进行数据预处理时,对于故障量进行区间划分,共分为3类的故障量数据类别,分别为1~5、6~10、11~15。对于类别1的实验结果如表2所示。

表2 类别1数据研判结果
在表2中,COUNT_2_1代表电压等级为1的故障数据,COUNT_2_2代表电压等级为2的故障数据,COUNT_2_3代表电压等级为3的故障数据,COUNT_2_4代表电压等级为4的故障数据,COUNT_2代表该配电网下的故障总故障数据,COUNT_1代表非配电网的用户设备故障数据。在表2中可以发现,文献[1]方法的查准率维持在69%~90%之间,查全率维持在80%~91%之间;文献[2]方法的查准率较高,维持在81%~91%之间。但由于文献[2]方法查全率较低,维持在65%~76%之间,查准结果置信程度不高,而所提研判方案的查准率维持在86%~93%之间,查全率在97%~99.78%之间,在查准和查全上均存在优势。对于类别2的实验结果如表3所示。

表3 类别2数据研判结果
从表3可知,文献[1]方法的查准率维持在69%~75%,查全率在69%~88%;文献[2]方法的查准率在66%~81%之间,查全率在90%~99.37%之间;所提方案的查准率在91%~95%之间,查全率在98%~100%。对类别3的数据研判结果如表4所示。

表4 类别3数据研判结果
从表4可以看出,文献[1]方法、文献[2]方法的性能下降严重,进行分析得出,类别3的故障数据通常是由于其他节点的故障,从而导致一系列故障,从而导致停电的出现,由于其他方法均针对单一节点进行数据研判,因此无法得到可靠的研判数据。同时可以证明本文设计的配电网停电研判方法的可行性。
3 总结
利用随机森林算法,对配电网中的所有数据进行了过滤或监测,实验表明所提方案提高了研判方案的数据查全率及查准率,对不同类别故障的研判精确度较高。但本文研究由于采用了对电网数据的实时监测,容易对服务器造成过多占用,因此未来将会结合云计算技术,将部分数据的计算分离,降低服务器的运算压力。
猜你喜欢
江苏安全生产(2022年3期)2022-04-19
中国外汇(2019年20期)2019-11-25
中国外汇(2019年18期)2019-11-25
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
中国交通信息化(2017年12期)2017-06-06
计算机应用(2016年10期)2017-05-12
中国管理信息化(2009年10期)2009-06-19
