
基于双自编码器和Transformer网络的异常检测方法
2023-02-03 03:01周佳航邢红杰
计算机应用 2023年1期
周佳航,邢红杰*
(1.河北大学 数学与信息科学学院,河北 保定 071002;2.河北省机器学习与计算智能重点实验室(河北大学),河北 保定 071002)
0 引言
在实际生活中,异常检测模型被广泛地应用于视频异常检测、欺诈检测、医疗检测、文本检测等领域[1-5]。异常检测问题可被视为“单类分类”任务,即在训练阶段,利用仅由正常数据构成的训练集训练异常检测模型;在测试阶段,由所训练的模型将待测样本识别为正常数据或异常数据。常用的异常检测方法被分为四类[6]:1)基于密度的异常检测方法;2)基于距离的异常检测方法;3)基于边界的异常检测方法;4)基于重构的异常检测方法。
近年来,深度学习得到了广泛关注,而基于深度学习的异常检测方法[7]也日益流行起来。作为一种常用的深度学习方法,自编码器(AutoEncoder,AE)被应用于许多异常检测任务。自编码器由编码器和解码器组成,编码器从输入样本中获得压缩后的瓶颈特征;解码器从瓶颈特征中重构样本。基于自编码器的异常检测方法仅能学习正常数据的特征,因此在测试阶段对正常数据重构的效果较好,而对异常数据重构的效果较差。基于自编码器的异常检测方法利用上述特点计算异常得分并进行检测,异常得分高的样本被视为异常数据,异常得分低的样本被视为正常数据。
基于自编码器的异常检测方法取得了较优的检测性能,然而它在正常数据上取得的重构误差与部分异常数据的重构误差非常接近,导致这些异常数据很难被正确检测[8]。为解决上述问题,相关学者提出许多改进方法。An 等[9]使用变分自编码器对训练样本进行建模,提出一种基于变分自编码器重构概率的异常检测方法,使用数据分布的概率度量替代传统自编码器的重构误差以区分正常数据和异常数据。Sakurada 等[10]将自编码器用于异常检测,发现自编码器可以通过数据在隐藏层的非线性表示很好地区分正常数据和异常数据。Xia 等[11]提出基于自编码器的异常检测模型,在自编码器的训练过程中逐步添加判别信息,使内点和离群点更加可分,并通过重构误差使内点和离群点分离。Zong 等[12]提出一种用于异常检测的深度自编码高斯混合模型(Deep Autoencoding Gaussian Mixture Model,DAGMM),利用深度自编码器生成样本的低维表示和重构误差,将其输入高斯混合模型,以端到端的方式联合优化深度自编码器和混合模型的参数,并利用估计网络即高斯混合模型对样本进行预测。受鲁棒主成分分析[13]的启发,Zhou 等[14]提出一种鲁棒自编码器,将训练样本拆分为正常数据和包含离群点以及噪声的数据,通过提取正常数据的特征和稀疏化包含离群点和噪声的数据来提高自编码器的鲁棒性。Gong 等[15]提出深度自编码器和内存模块的结合,称为记忆增强自编码器(Memoryaugmented AutoEncoder,MemAE),训练时鼓励内存模块存储更多样的正常数据的瓶颈特征,测试时通过样本的瓶颈特征从内存模块中检索与其相关性最大的存储项进行重构,由于存储项全为正常数据的瓶颈特征,异常数据无法通过存储项有效重构,因此可以通过重构误差分类异常数据。Lai 等[16]将鲁棒子空间恢复(Robust Subspace Recovery,RSR)层添加到Vanilla 自编码器中,RSR 层从数据的潜在表示中提取子空间,并删除远离该空间的数据,编码器将数据映射到潜在空间,RSR 层从中提取子空间,然后解码器将子空间映射回原始空间,根据原始位置和经过解码器映射的位置之间的距离来区分正常数据和异常数据。
尽管上述基于自编码器的异常检测方法及其改进方法取得了较优的检测性能,但是这些方法的模型结构中仅有一个自编码器,在训练阶段仅能通过最小化自编码器输入输出间的重构误差对编码器和解码器中的参数进行更新,由于训练集仅由正常数据构成,因此自编码器无法学习到异常数据。当异常数据与正常数据较为相似,或者异常数据的重构误差较小时,上述方法则会取得较差的检测性能。为了解决上述问题,提出一种基于并行双自编码器和Transformer 网络的异常检测方法DATN-ND(Novelty Detection method based on Dual Autoencoders and Transformer Network,该方法使用双自编码器在最小化重构误差的基础上添加新的损失函数来联合优化自编码器;Tramsformer 网络则将输入样本的瓶颈特征变换为与正常数据差别较大的瓶颈特征,称为伪异常瓶颈特征,等同于在训练集中增加了异常数据。在训练阶段,编码器将输入样本映射到特征空间,Transformer 网络将特征空间的瓶颈特征映射到距离输入样本特征空间较远的特征空间,生成伪异常瓶颈特征,通过伪异常瓶颈特征所提供的异常数据信息,解码器将带有异常数据信息的瓶颈特征尽可能映射为正常数据;在测试阶段,当异常样本经过编码后得到带有异常数据信息的瓶颈特征输入解码器时,解码器会将该瓶颈特征尽可能重构为正常数据,从而提高异常数据的重构误差。
1 基于自编码器的异常检测方法
自编码器是一种由编码器fθE(·)和解码器gθD(·)构成的前馈神经网络,其任务是使网络的输出尽可能地等于输入x,即以尽可能小的误差重构输入。自编码器中有一个描述样本非线性表示的隐藏层,样本的非线性表示称为瓶颈特征,自编码器从样本中学习到的瓶颈特征越好,重构样本的能力越强,自编码器通过最小化x和之间的误差来更新编码器和解码器的参数以学习更好的样本瓶颈特征,表示如下:

其中:θE和θD是编码器和解码器的参数集;x是输入样本,是自编码器的输出,即输入样本经过编码和解码之后的重构样本;‖·‖2表示L2 范数。令z表示自编码器学习到的样本瓶颈特征,即:

则重构样本可以表示为:

自编码器重构样本的能力主要依赖于学习到的样本瓶颈特征,但是不同类别的样本存在不同的特征,假如自编码器只学习了正常数据的瓶颈特征,那么它对异常数据的重构能力就不如正常数据,导致正常数据重构的误差较小而异常数据重构的误差较大,所以基于自编码器的异常检测方法利用该特性将重构误差作为数据的异常得分,根据异常得分对正常数据和异常数据进行分类,如图1 所示。当自编码器训练完成之后,给定一个输入样本x,x的重构误差S(x)即为异常得分,表示为:


图1 基于自编码器的异常检测方法Fig.1 Novelty detection method based on autoencoder
基于自编码器的异常检测方法通过该异常得分对样本进行分类,算法1 和算法2 给出了它的实现过程。
算法1 自编码器训练。


已有基于自编码器的异常检测方法有时在正常数据与部分异常数据上产生的重构误差非常接近,导致部分异常数据很容易被错分为正常数据。为了解决该问题,本文提出了基于双自编码器和Transformer 网络的异常检测(DATN-ND)方法。
2 DATN-DN
2.1 模型结构
DATN-ND 的模型由编码器、解码器和Transformer 网络组成。首先定义输入样本域ℝ 和特征域Z,令fE(·):ℝ →Z表示编码器;fD(·):Z →ℝ 表示解码器。给定一个输入样本x∈ℝ,编码器将其编码为瓶颈特征z∈Z;解码器将z映射到样本域ℝ 得到输入样本x的重构样本,如下所示:

Transformer 网络由前馈神经网络组成,其目的是找到与输入样本对应的特征空间Z 距离较远的另一个特征空间Zt,将输入样本的瓶颈特征z∈Z 变换成伪异常瓶颈特征zt∈Zt,Transformer 网络定义为fT(·):Z →Zt,则有:

由式(7)即可得到与正常数据的瓶颈特征z距离较远的特征空间中的伪异常瓶颈特征zt,因此,zt被视为带有异常数据的瓶颈特征,模型通过得到zt为训练集中增加异常数据。
DATN-ND 的模型训练模块如图2 所示,模型通过最小化样本x的重构误差使编码器E1能够获得更好的瓶颈特征,从而通过解码器D1获得更优的重构样本,表示如下:

图2 本文方法的训练模块Fig.2 Training module of proposed method

其中:为重构样本;θE,θD是编码器、解码器的参数集。
为了使Transformer 网络获得远离正常数据特征空间Z的特征空间Zt,并生成带有异常数据信息的伪异常瓶颈特征,通过最大化输入样本的瓶颈特征z和其通过Transformer网络变换后的瓶颈特征zt之间的误差来训练Transformer 网络,表示如下:

其中:θT是Transformer 网络的参数集。
此外,为了使解码器尽可能将带有异常数据信息的瓶颈特征映射为正常数据而非其本身,模型通过最小化和之间的误差使解码器D2将变换后的瓶颈特征zt映射为,使与正常数据尽可能地相似。表示如下:

综合考虑式(8)~(11),本文方法的模型训练目标是最小化损失函数:

其中:N为训练样本个数;α,β,γ分别是各个损失函数的权重。图2 中的编码器E1、E2和E3采用相同的网络结构且参数共享;解码器D1和D2使用相同的网络结构且参数共享。
测试模块如图3 所示,假设给定的测试样本是正常数据,编码器将其映射为正常数据的瓶颈特征,然后解码器会将其映射回正常数据,使正常数据获得较小的重构误差;假设给定的测试样本是异常数据,编码器将其映射为异常数据的瓶颈特征,解码器会将带有异常数据信息的瓶颈特征尽可能解码为正常数据而非重构其本身,使异常数据获得较大的重构误差,因此DATN-ND 方法可以使用样本的重构误差作为异常得分对样本进行分类。

图3 本文方法的测试模块Fig.3 Test module of proposed method
由于训练阶段使用的编码器结构相同且参数共享,解码器亦结构相同且参数共享,因此测试阶段仅需使用训练好的任意一组编码器和解码器就可以构成图3 中的模型,并对待测样本进行分类。给定一个测试样本xtest,由图3 中的模型获得xtest的重构样本,计算xtest的重构误差,并使用该重构误差作为异常得分S(xtest)对xtest进行分类,表示如下:

2.2 算法描述
基于双自编码器和Transformer 网络的异常检测方法训练阶段和测试阶段的算法实现过程如算法3 和算法4 所示。
算法3 DATN-ND 训练。

3 实验与结果分析
为了检验DATN-ND 方法的性能,与对比方法在4 个数据集上进行了实验对比,并通过消融实验验证了DATN-ND中Transformer 网络的有效性。使用Adam 优化器[17]并设置学习率为10-4对模型进行训练,DATN-ND 损失函数的权重参数α取值为0.1,β取值为0.01,γ取值为-0.000 1,训练阶段最大迭代次数为500,模型分类阈值δ为约登指数最大时的取值。
3.1 图像数据集
实验使用MNIST[18]、Fashion-MNIST[19]和CIFAR-10[20]图像数据集,都包含10 个类别的图像。每个数据集按顺序抽取10 个类别中的一类图像作为正常数据,其余类别的图像作为异常数据,因此每个图像数据集可构造10 个用于异常检测的数据集,所构建的异常检测数据集的训练集仅由正常数据构成,测试集既有正常数据也有异常数据。
与DATN-ND 对比的方法有:MemAE、自编码器(AE)、单类支持向量机(One-class Classification Support Vector Machine,OCSVM)[21]、RSR 自编码器(RSR-based AE,RSRAE)、深度支持向量描述(Deep Support Vector Data Description,Deep SVDD)[22]、深度结构保存支持向量描述(Deep Structure Preservation SVDD,DSPSVDD)[23]、变分自编码深度支持向量描述(Deep Support Vector Data Description based on Variational AE,Deep SVDD-VAE)[24]、f-AnoGAN(fast unsupervised Anomaly detection with Generative Adversarial Network)[25]、GANomaly[26]、记忆增强生成对抗网络(Memory augmented Generative Adversarial Network,MemGAN)[27]、RLDA(Representation Learning with Dual Autoencoder)[28]。
DATN-ND 与AE 使用相同结构的编码器和解码器,在灰度图像数据集MNIST 和Fashion-MNIST 上使用全连接网络构建模型,如表1 所示,其中:FC 代表全连接层,括号里的第1~3 个参数分别为全连接网络的输入层、输出层大小与激活函数,none 为没有激活函数。
DATN-ND 在彩色图像数据集CIFAR-10 上使用卷积网络构建模型,如表1 所示,其中:Conv2d 代表卷积层;Dconv2d代表转置卷积层,括号里的第1~4 个参数分别是卷积核大小、步长、输入通道数与输出通道数。

表1 模型结构Tab.1 Model structure
测试时,DATN-ND 通过归一化将重构误差缩放到[0,1]内,使用重构误差作为异常得分进行异常检测,并将ROC 曲线下面积(Area Under the Receiver Operating Characteristic curve,AUC)用作评估各方法性能的度量。表2~4 分别展示了由MNIST、Fashion-MNIST、CIFAR-10 图像数据集构建的10个异常检测数据集上的AUC 对比结果。
由表2 可知,对于MNIST 数据集,除了类别“2”“3”“8”,DATN-ND 在其余7 个类别的数据集上均取得了优于其他11种方法的AUC;由表3 可知,对于Fashion-MNIST 数据集,除了类别“Coat”“Bag”和“Ankle Boot”,DATN-ND 在其余7 个类别的数据集上均取得了优于其他11 种方法的AUC;由表3 可知,对 于CIFAR-10 数据集,除了类 别“car”“cat”“horse”和“truck”,DATN-ND 在其余6 个类别的数据集上均取得了优于其他11 种方法的AUC 结果。与RSRAE、RLDA、MemAE 和AE 这四种基于AE 的异常检测方法相比,DATN-ND 在所有的数据集上均取得了较优的性能。因此,由表2~4 可知:1)与传统的异常检测方法OCSVM 相比,DATN-ND 的计算能力更强,能够更好地处理高维复杂的数据。2)与基于深度学习的异常检测方法相比(包括RSRAE、Deep SVDD、DSPSVDD、Deep SVDD-VAE、f-AnoGAN、GANomaly、MemGAN、RLDA、MemAE、AE),DATN-ND 中的Transformer网络模块为仅有正常数据的训练阶段提供异常数据,使模型能够学习更多用于判别正常数据和异常数据的有用信息;另外,DATN-ND 中的双自编码器模块使异常数据的重构接近正常数据,提高了异常数据的重构误差,提高了模型的检测性能。针对MNIST、Fashion-MNIST 和CIFAR-10 三个数据集上所构建的异常检测数据集,DATN-ND 在一些数据集上的检测性能并非最优,因为Transformer 网络模块的变换方法并不适用于上述所有的异常检测数据集。

表2 不同方法在MNIST图像数据集上的AUC 单位:%Tab.2 AUC for different methods on MNIST image dataset unit:%

表3 不同方法在Fashion-MNIST图像数据集上的AUC 单位:%Tab.3 AUC for different methods on Fashion-MNIST image dataset unit:%

表4 不同方法在CIFAR-10图像数据集上的AUC 单位:%Tab.4 AUC for different methods on CIFAR-10 image dataset unit:%
为直观地展示DATN-ND 的训练和测试过程,使用MNIST 图像数据集中所构造的第10 组异常检测数据集进行训练和测试,即将数字“9”的图像用作正常数据,其余数字的图像用作异常数据。在训练阶段,从数字“9”的训练图像中选取前9 个正常数据进行展示,如图4(a)所示。训练样本对应的瓶颈特征z经过Transformer 网络变换后得到与z距离较远的特征空间中的瓶颈特征zt,zt可以被视为具有异常数据信息的瓶颈特征,解码器将zt映射为数字“9”。因此DATNND 能够通过Transformer 网络获得具有异常数据信息的瓶颈特征,并将其解码为正常数据。
在测试阶段,从9 个异常类别的测试图像中分别随机选取一幅图像,如图4(b)所示。假设给定的测试样本是异常数据,编码器将其映射为异常数据的瓶颈特征,因为异常数据的瓶颈特征与训练时Transformer 网络变换后的具有异常信息的瓶颈特征相似,所以异常数据的瓶颈特征通过解码器映射后的重构样本与正常数据相似,而没有Transformer 网络的模型不能达到相同的效果。如图4(b)所示,异常数据通过DATN-ND 模型的重构样本比AE 模型接近正常数据,使异常数据获得更大的重构误差,更容易被模型识别。
为了验证DATN-ND 模型扩大异常数据与正常数据重构误差差别的有效性,将DATN-ND 模型上异常测试样本与正常测试样本重构误差之间的差值与AE 上的差值进行对比,如图5 所示,DATN-ND 模型上异常测试样本的重构误差与正常测试样本的重构误差之间的差值更大,因此更易检测异常数据。表5 通过MNIST 数据集展示了基于深度学习的相关方法时间对比,由于DAGMM、AE、DATN-ND 均采用全连接网络,所以优于其他方法,而DATN-ND 方法仅次于AE,主要原因是添加了Transformer 网络,网络复杂性要高于AE。

图5 正常数据与异常数据重构误差的差值Fig.5 Difference of reconstruction error between normal data and novel data

表5 MNIST数据集上不同方法的时间 单位:sTab.5 Time of different methods on MNIST dataset unit:s
3.2 网络安全数据集
为了进一步验证DATN-ND 的性能,在网络安全数据集KDD-CUP99[29]上将它与其他6 种相关方法OCSVM、DCN(Deep Clustering Network)[30]、DAGMM 的变体PAE、DSEBM(Deep Structured Energy Based Model)[31]、DAGMM 和AE 进行实验比较,结果如表6 所示。本实验中将平均精度(Precision)、召回率(Recall)和F1 度量(F1)用作性能指标,而非AUC,因为文献[12]中的相关方法(包括DCN、PAE、DSEBM、DAGMM)采用了这些性能指标。按照文献[12]的设置,DATN-ND 只用KDD-CUP99 数据集中的正常数据对模型训练,KDD-CUP99 数据集中只有20%的样本标记为“正常”,其余样本的标记都为“攻击”,正常数据比较少,所以异常检测任务中,标记为“正常”的样本被视为异常数据,标记为“攻击”的样本被视为正常数据。训练阶段模型从正常数据中随机抽取50%用于训练,剩余50%和异常数据用于测试。
从表6 中的结果可以看出,DATN-ND 的平均精度、召回率和F1 评分均优于其他6 种方法。因此,与传统的异常检测方法OCSVM 相比,验证了DATN-ND 的计算能力更强,且能更好地处理高维复杂的数据;与基于深度学习的异常检测方法(DCN、PAE、DSEBM、DAGMM 和AE)相 比,验证了在DATN-ND 中所添加的Transformer 网络模块和双自编码器模块可以为仅存在正常数据的训练阶段提供异常数据的信息,使模型将异常数据重构为正常数据,提高异常数据的重构误差,有效提高异常检测的性能。

表6 不同方法在KDD-CUP99数据集上的结果Tab.6 Results of different methods on KDD-CUP99 dataset
3.3 消融实验
为检验DATN-ND 中各组成模块、Transformer 网络模块以及损失函数权重取值的有效性,在Fashion-MNIST 数据集上进行消融实验,实验结果如表7 所示。
DATN-ND-nonT:即无Transformer 网络的DATN-ND。由表7 中的结果可知,与DATN-ND-nonT 相比,DATN-ND 在10个类别的数据集上均取得了更优的AUC,验证了DATN-ND中Transformer 网络对于提高检测性能是有效的。
DATN-ND-nonL:DATN-ND 最大化损失函数(9)对Transformer 网络中的参数进行优化,为了展示损失函数(9)对DATN-ND 性能的影响,在DATN-ND 的基础上去除Transformer 网络的损失函数(9)。如表7 所示,与DATN-NDnonL 相比,DATN-ND 在10 个类别的数据集上均取得了更优的AUC,验证了DATN-NDTransformer 网络的损失函数(9)对于提高性能的有效性。
DATN-ND-nonE:DATN-ND 有三个编码器E1、E2和E3,编码器E2、E3最小化式(11)从存在异常数据信息的重构样本中获取近似正常数据的瓶颈特征,使测试阶段异常数据的重构样本更接近正常数据,DATN-ND-nonE 表示在DATN-ND 的基础上去除编码器E2、E3。如表7 所示,与DATN-ND-nonE 相比,DATN-ND 在10 个类别的数据集上均取得了更优的AUC值,验证了DATN-ND 编码器E2、E3对于提高异常检测性能的有效性。
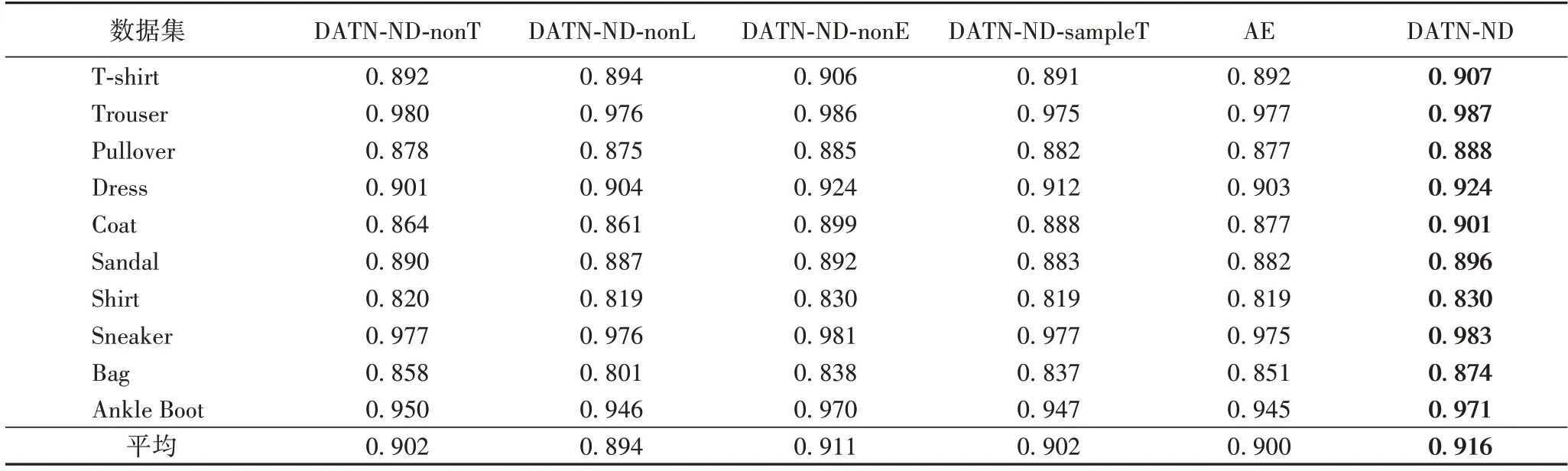
表7 Fashion-MNIST数据集上消融实验结果(AUC)Tab.7 AUC results of ablation experiment on Fashion-MNIST dataset
DATN-ND-sampleT:DATN-ND 利用Transformer 网络对输入样本的瓶颈特征进行变换以获取新的瓶颈特征,同样它也能对输入样本进行变换以获得新的样本,为了比较两者的分类性能,用Transformer 网络对输入样本进行变换,记作DATN-ND-sampleT。由表7 中的结果可知,与DATN-NDsampleT 相比,DATN-ND 取得了更优的AUC 值,因此DATNND 的Transformer 网络并未直接对输入样本进行变换,而是对输入样本的瓶颈特征进行变换。
此外,为了展示损失函数权重取值对DATN-ND 分类性能的影响,首先固定β=10-2,γ=-10-4,选取不同的α值,AUC 如图6(a)所示,当α=10-1时,模型取得最优效果;固定α=10-2,γ=-10-4,选取不同的β值,AUC 如图6(b)所示,当β=10-2时,模型取得最优结果;固定α=10-1,β=10-2,选取不同的γ值,AUC 如图6(c)所示,当γ=-10-4时,模型取得最优效果。因此合理的超参数取值能够有效提高模型分类性能,最终DATN-ND 超参数α取值为10-1,β取值为10-2,γ取值为-10-4。

图6 分别固定α、β、γ 时的超参性能影响Fig.6 Effect of parameters on performance when fixing α,β or γ
综上可知,消融实验验证了DATN-ND 各组成模块、Transformer 网络模块以及损失函数权重取值能有效提高异常检测性能。
4 结语
在解决异常检测问题时,由于训练集中没有异常数据,因此基于自编码器的异常检测方法在训练阶段无法学习异常数据的信息,导致检测性能不佳。本文提出基于双自编码器和Transformer 网络的异常检测方法DATN-ND。DATN-ND通过Transformer 网络为模型训练阶段提供异常数据信息,使异常数据的重构误差增大,有效提高模型的检测性能。尽管DATN-ND 在3 个图像数据集取得了较优的性能,但是它并不适用于实验中用到的所有异常检测数据集,在未来的工作中,可以考虑为Transformer 网络寻找更优的变换方法来解决上述问题。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
中国环境监察(2016年11期)2016-10-24
中国卫生(2016年1期)2016-01-24
探测与控制学报(2015年4期)2015-12-15
