
基于轻量化YOLOv4的交通信息实时检测方法
2023-02-03 03:01郭克友
计算机应用 2023年1期
郭克友,李 雪,杨 民
(北京工商大学 人工智能学院,北京 100048)
0 引言
随着相关技术的发展,人们对交通监控系统的需求不断增加,安全辅助驾驶系统的技术也逐渐走进大众的视野。车辆目标检测是安全辅助驾驶领域极具挑战的问题,该领域主要分为传统目标检测算法和基于深度学习的检测算法。
传统目标检测方法主要分为三类:以高斯混合模型(Mixture Of Gaussians,MOG)[1]、MOG2[2]和几何多重网格(Geometric MultiGid,GMG)[3]为代表的背景差分法;以两帧差法[4]、三帧差法[5]为代表的帧差分法;以及利用相邻两帧中对应的灰度保持不变原理评估二维图像变化的光流场法[6]。然而,传统目标检测算法存在鲁棒性差、适应性弱等缺陷[7]。
近年来,深度学习技术在目标检测等任务中取得了巨大的成就。基于深度学习的目标检测主要分为两大类[8]:1)基于区域建议的方法,这类算法的典型代表是R-CNN(Region Convolutional Neural Network)[9]、SPP-net(Spatial Pyramid Pooling network)[10]、Fast R-CNN[11]、Faster R-CNN[12]等;2)基于无区域建议的方法,这类方法主要采用回归的思想,比较典型的算法如YOLO(You Only Look Once)、SSD(Single Shot multi-box Detector)[13]。基于区域建议的方法精度高但速度慢,训练时间较长;基于无区域建议的方法准确度低,对小物体的检测效果较差,但速度快。
目前,应用最广泛的是YOLO 系列检测算法。YOLOv1[14]的检测速度非常快,迁移能力强,但是对很小的群体检测效果不好;YOLOv2[15]经多种改进方法后,检测速度得到大幅提升,但检测精度提升效果并不明显;YOLOv3[16]中提供了Darknet-53 以及轻量级的Tiny-Darknet 骨干网络,使用者可根据需求选择不同的骨干网络,其灵活性使得它在实际的工程中受到了大家的青睐;YOLOv4[17]在传统YOLO 的基础上添加了许多实用技巧,实现了检测速度和检测精度的最佳权衡;YOLOv5 在性能上略弱于YOLOv4,但在灵活性以及速度上都远优于YOLOv4。
为应对复杂路况下车辆多目标实时检测的挑战,本文选择检测精度和检测速度较为平衡的YOLOv4 作为研究对象。为进一步提高模型的检测精度,并且使其能够部署在移动端,提出一种轻量化的YOLOv4 交通信息实时检测方法。由于现有的大型公开数据集对道路复杂场景的适用性不强,本文针对真实交通场景构建了与之对应的数据集,并在测试前对数据集进行K-means++[18]聚类处理;除此之外,为提高检测性能,对YOLOv4 网络进行修改,大幅提高车辆目标的检测速率。
1 改进的YOLOv4
YOLOv4 网络模型结构如图1 所示,它保留了YOLOv3 的Head 部分,将主干网络修改为CSPDarkent53(Cross Stage Partial Darknet53),同时采用空间金字塔池化(Spatial Pyramid Pooling,SSP)扩大感受野,PANet(Path Aggregation Network)作为Neck 部分,并使用了多种训练技巧,对激活函数和损失函数进行了优化,使YOLOv4 在检测精度和检测的速度方面均有所提升[19-20]。

图1 YOLOv4网络结构Fig.1 Network structure of YOLOv4
CSPDarknet 作为YOLOv4 算法的主干网络,经特征融合后,输出层的尺寸分别变为输入尺寸的1/8、1/16、1/32。CSPDarknet53 将原有的Darkent53 中的残差块改为CSP 网络结构。CSP-DarkNet 在每组Residual block 加上一个Cross Stage Partial 结构;并且,CSP-DarkNet 中还取消了Bottleneck的结构,减少了参数使其更容易训练。
SPP 以及PANet 将主干网络提取的特征图进行融合,SPP对全连接层前的卷积层进行不同池化大小的池化,然后拼接,由此增加网络感受野。PANet提出了一种bottom-up的信息传播路径增强方式,通过对特征的反复提取实现了了不同特征图之间的特征交互。PANet 可以准确地保存空间信息,有助于正确定位像素点,增强实例分割的过程。
最后,YOLOv4 Head 进行大小为3×3 和1×1 两次卷积,对特征层的3 个先验框进行目标及目标种类的判别,并进行非极大抑制处理和先验框调整,最后得到预测框。
为了进一步提高模型的检测速率,减少模型的参数量,本文对YOLOv4 检测算法做如下改进:由MobileNet-v3 构成主干特征提取模块,经过特征提取后可以得到52×52、26×26、13×13 共3 个尺度的特征层,减少模型参数量;使用带泄露修正线性单元(Leaky Rectified Linear Unit,LeakyReLU)激活函数代替MobileNet-v3 浅层网络中的ReLU 激活函数,提高检测精度;利用深度卷积网络代替传统卷积网络。下面对网络结构的设计和参数设置进行阐述。
1.1 主干特征提取网络
2019 年,Google 公司在MobileNet 的基础上提出了MobileNet-v3 网络,在保持轻量化的同时,MobileNet-v3 模型进行了部分优化,经优化后的MobileNet 模型衍生出MobileNet-v3-Large 和MobileNet-v3-Small 两个版本。在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)分类任务中:MobileNet-v3-Large 的准确率与检测速度相较于MobileNet-v2 模型分别提高了3.2% 和15%,MobileNetv3-Small 模型相较于MobileNet-v2 模型则分别提高了4.6%和5%;在COCO 数据集的检测过程中,在满足精度的同时,与使用MobileNet-v2 模型相比,MoboileNet-v3-Large 的检测速率提升了25%[21]。MobileNet-v3 的整体结构如图2 所示。

图2 MobileNet-v3结构Fig.2 Structure of MobileNet-v3
MobileNet-v3 在核心构架中引入了名为Squeeze-and-Excitation 的神经网络(SeNet),该网络的核心思想是通过显式建模网络卷积特征通道之间的相互依赖关系来提高网络的质量,即通过学习来自动获取每个特征通道的重要程度,并以此为依据提升有用的特征,抑制用处较小的特征。本文将MobileNet-v3 代替传统YOLOv4 的主干的网络,以减少参数量,使模型更加轻量化。
1.2 深度可分离卷积
在深度可分离卷积出现之前,神经网络基本由不同尺度的卷积核堆叠而成,伴随技术的发展,人们对网络模型的精度要求不断提高[22]。面对不断增加的深度核模型参数量,为了在保证模型精度的情况减少参数量,2017 年谷歌公司提出了基于深度可分离卷积的MobileNet[23],随后提出了MobileNet-v2[24]、MobileNet-v3[25]系列网络。
MobileNet-v3 使用深度可分离卷积代替标准卷积块,深度可分离卷积(DepthWise Conv)由深度卷积和逐点卷积(PointWise Conv)组成,由此可大幅减少模型的理论参数(Params)和每秒峰值速度(FLoating-point Operations Per Second,FLOPs)。
设输入数据为M×M×N,卷积核大小为K×K×P,设置步长为1,标准卷积操作利用卷积内核提取特征,随后将特征进行组合产生新的表示效果[26]。如图3(a)所示,此时,标准卷积的参数量为:

计算量为:

深度可分离卷积是将提取特征和结合特征分为深度卷积和逐点卷积两步,如图3(b)所示:在深度卷积过程中,主要对每一个输入通道进行一个卷积核的操作,然后利用1 ×1 的卷积将深度卷积的输出结果结合到特征中;随后通过1 × 1 卷积计算深度卷积的输出线性特征组合为新的特征。深度卷积和1 × 1 卷积(逐点卷积)组成了深度可分离卷积[27],其参数量为:

图3 标准卷积与深度可分离卷积Fig.3 Standard convolution and depth separable convolution

计算量为:

两种卷积对应参数比为:
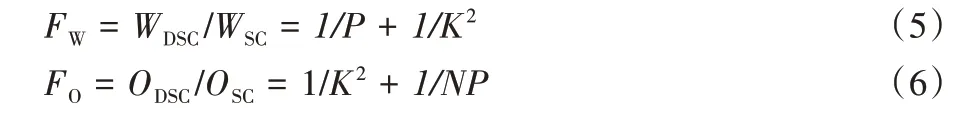
通过对比可知,深度可分离卷积与标准卷积相比更加高效,故本文用深度可分离卷积代替原始YOLOv4 网络中的标准卷积,以提高检测效率。
1.3 损失函数
MobileNet-v3 浅层部分利用线性整流单元(Rectified Linear Unit,ReLU)作为激活函数,该函数主要分为两部分:在小于0 的部分,激活函数输出为0;在大于0 的部分,激活函数的输出为输入,计算方法如式(7)。

该函数的收敛速度快,不存在饱和区间,在大于0 的部分梯度固定为1,能有效解决Sigmoid 中存在的梯度消失问题;但是当一个巨大的梯度经过ReLU 神经元时,ReLU 函数将不具有激活功能,产生“Dead Neuron”现象。
为避免“Dead Neuron”现象发生,本文中MobileNet-v3 特征提取网络采用带泄露修正线性单元(Leaky Rectified Linear Unit,LeakyReLU)代替传统的ReLU 函数,该函数可有效地避免上述现象发生。其计算方式如下:
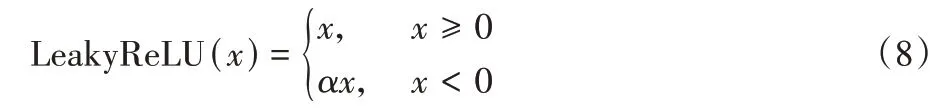
实际中,LeakyReLU 的α取值一般是0.01。在使用过程中,对于LeakyReLU 激活函数输入小于零的部分,也可以计算得到梯度,而不是像ReLU 一样值为0,由此可避免ReLU函数存在的梯度方向锯齿问题。
2 数据集构建
2.1 数据集的制作
本实验采用的数据集由搭载HP-F515 行车记录仪的实验平台在北京市内真实道路场景下进行采集,包括城市主干道、桥梁公路、信号岔口等。采集流程为:为模拟驾驶员真实驾驶情况,将行车记录仪搭载于后视镜处,行车路线全长11 km,行驶时间分别为15:00—17:00 和19:00—21:00,该时间段内,测试路线车流量较大,存在部分拥堵路段。
对录制的视频进行分帧,设置大小为1 920×1 080,并依据正常公路场景下的车辆目标类型将车辆目标分为3 种,分别是大型车(large vehicle)、中型车(medium)和小型车(compact car)。实验共计12 614 张图片,并将标签分别设置为2、3、4,具体情况如表1 所示。

表1 三种目标及其标签Tab.1 Three types of objects and their labels
2.2 性能测评指标
目标检测中,常通过准确率P(Precision)、召回率R(Recall),计算平均精度(Average Precision,AP),平均精度均值(mean Average Precision,mAP)作为目标检测的评价指标,如式(9)~(11)所示:

其中:TP为检测正确的目标数量;FP为检测错误的目标数量;FN表示漏检数量表示所有缺陷类别的AP 值总和;Nclass表示缺陷总类别数。
本文另选检测速度作为模型性能的评价指标之一,利用每秒可处理图像帧数量(Frames Per Second,FPS)作为检测速度的评价指标。FPS 计算公式如下:

其中:Numfigure表述样本检测数量;TIME表示检测耗费的时间。
2.3 锚框优化
K-means 算法随机产生聚类中心,使得每次聚类效果不尽相同,进而影响模型的检测效果。为解决初始聚类中心不断变化等问题,本文采用K-means++算法进行先验框的计算。设本文数据集内包含N个样本,数据集表示为α={xi|xi=(xi1,xi2,xi3,L,xim),i=1,2,…,N},取集合α中k个数据作为初始的聚类中心点P={pj|pj=(pj1,pj2,pj3,L,pjm),j=1,2,…,k}。通过式(13)可得样本点xi到质心pj在m维空间的欧氏距离d,随后依据式(14)遍历每个样本数据被选为下一个聚类中心的概率C[28]。

重复上述步骤,直到选出k个聚类中心。分别计算样本点数据xi到k个聚类中心的欧氏距离d,按照邻近原则将样本点归类到距离其最近的聚类中心簇中,取聚类中心簇内的样本点,计算均值用来表示聚类中心,经过迭代,计算误差平方和,直到ISSE取最小值。其中ISSE又称为畸变程度,ISSE越小,表明畸变程度越低,簇内样本点的关系越紧密。畸变程度会根据类别的增加而降低。

Si为样本点xi的轮廓系数,b(xi)是xi到聚类中心簇的平均距离,a(xi)是b(xi)中的最小值。

St是样本点轮廓系数的平均值,它反映了聚类的密集度和离散度,由式(17)可知,St介于0~1,St越大,表明类内样本的密集度越高,各类样本的离散度越高,聚类效果越好。
K-Means++算法通过轮廓系数和ISSE的值得出分类效果最好的最佳簇类数量。对自制数据集重新聚类后得到9 组先验框为(50.84,43.92),(90.80,61.82),(26,87.25),(24.26,49.68),(51.35,189.15),(81.4,57.78),(38.16,38.13),(19.64,21.95),(90.7,124.8)。
3 实验与结果分析
3.1 实验环境配置
硬件配置为Intel Core i7-7700CPU @3.60 GHz,内存为16 GB,GPU 为NVIDIA GeForce GTX1080Ti,深度学习框架为Pytorch1.2.0 版本;CUDA 版本为11.3;Python 版本为3.8.10。
本实验基于Pytorch 深度学习框架,数据集基于第2 章的数据预处理,训练过程为350 epoch,前50个epoch利用冻结网络方式进行训练,学习率为0.001;之后的300个epoch学习率为0.000 1,训练过程采用了退火余弦算法以及标签平滑。
3.2 改进模型有效性评价
为验证改进方法对YOLOv4 模型的性能影响,对上述4种改进方法进行消融实验,结果如表2 所示。其中:“√”表示在网络实验中使用了该改进策略,“—”表示未使用该策略。由表2 可知,将主干网络替换为MobileNet-v3 后,权值文件大小由161 MB 变为了53.7 MB;通过利用深度可分离卷积代替原始YOLOv4 网络中的标准卷积,大幅减少了网络结构中的参数量;轻量化后的模型与原模型相比,本文所提出轻量YOLOv4 算法的mAP 下降并不明显,仍可以保持较好的性能。

表2 消融实验结果对比Tab.2 Comparison of ablation experimental results
3.3 性能评价
AP、Recall、Precision 和F1 结果如表3 所示。YOLOv4 算法获得了90.64%的准确率均值,91.6%的召回率均值,91.33%的F1 均值;轻量化的YOLOv4 算法获得了92.9%准确率均值,90.71%的召回率均值,92%的F1 均值。

表3 轻量化YOLOv4与其他YOLO算法对比Tab.3 Comparison of lightweight YOLOv4 and other YOLO algorithms
mAP 与FPS 结果如表4 所示,可以看出,当输入分辨率一致时,轻量化的YOLOv4 检测算法在实时性上有所上升,虽然mAP 下降了0.76 个百分点,但是检测速率提升了79%,不仅可以减少误检、漏检还能保证检测精度,提高检测速度。

表4 网络模型检测速度及均值平均精度对比Tab.4 Comparison of detection speed and mAP
本文使用MobileNet-v3 和深度可分离卷积代替YOLOv4的主干网络和标准卷积使计算量下降到1.1 × 107,检测速度由原始47.74 FPS 升高至85.60 FPS。从以上分析可知,轻量化的YOLOv4 检测算法相较于YOLOv4 检测算法在保证检测精度的同时,提高了检测效率;但与同样为轻量化系列的Tiny YOLOv4 以及YOLOx 相比在检测速度方面仍有较大差距。
3.4 效果测试
为了进一步直观地展示本文算法的有效性,图4、5 展示了原始YOLO 系列检测算法和轻量化的YOLOv4 检测算法在车辆目标数据集的检测结果。
图4 是道路情况较为简单(道路中的车辆不存在遮挡情况)时的检测结果,可以看出三类检测器对车辆目标的检测效果均良好:当道路中出现较多车辆,且车辆间不存在大量重叠和遮挡的情况下,检测器的检测效果相当,均可检测出道路中的中型车以及小型车;当道路中出现不完整车辆目标、遮挡目标和小目标时,原始YOLOv4 检测模型、Tiny YOLOv4 以及YOLOx模型对远处目标的检测效果比轻量化YOLOv4略差。

图4 不存在重叠目标时的检测结果对比Fig.4 Comparison of detection results without overlapping targets
存在重叠目标时的检测结果如图5 所示。通过图5 的对比,面对道路车辆较多,且存在明显遮挡现象的情况:原始YOLOv4 检测算法可以检测出1 个大型车,无法识别远处的车辆小目标;Tiny YOLOv4 无法检测出远处车辆小目标;轻量化的YOLOv4检测算法共测出2个车辆目标,包含远处的小目标车辆;YOLOx检测器也可检测出2个车辆目标,但其检测精确度不如轻量化的YOLOv4。当车辆目标数量增多,但车辆之间的重叠情况较少时,远处的小目标可以在轻量化的YOLOv4 检测模型中被测得,但是原始YOLOv4、Tiny YOLOv4以及YOLOx 都存在远处的重叠目标的漏检现象,其中Tiny YOLOv4检测器漏检情况较原始YOLOv4检测器较为严重;当道路中出现栅栏等遮挡物且车辆目标较多的情况下,原始YOLOv4 检测器检测出了2 个车辆小目标,Tiny YOLOv4 检测器仅检测出1 个车辆小目标,YOLOx 检测出了3 个车辆目标,面对遮挡目标存在一定的漏检情况,轻量化的YOLOv4 检测器检测出了3个近处目标以及1个远处小目标。

图5 存在重叠目标时的检测结果对比Fig.5 Comparison of detection results with overlapping targets
为了对比三种模型算法针对不完整目标和小目标的检测能力,选择100 张含有大量重叠车辆目标以及小目标的图片作为测试数据集,其检测性能的对比如表5 所示,通过对比Recall、AP、F1 和Precision 值可看出,轻量化的YOLOv4 算法效果好于原始YOLOv4 和Tiny YOLOv4,略差于YOLOx。
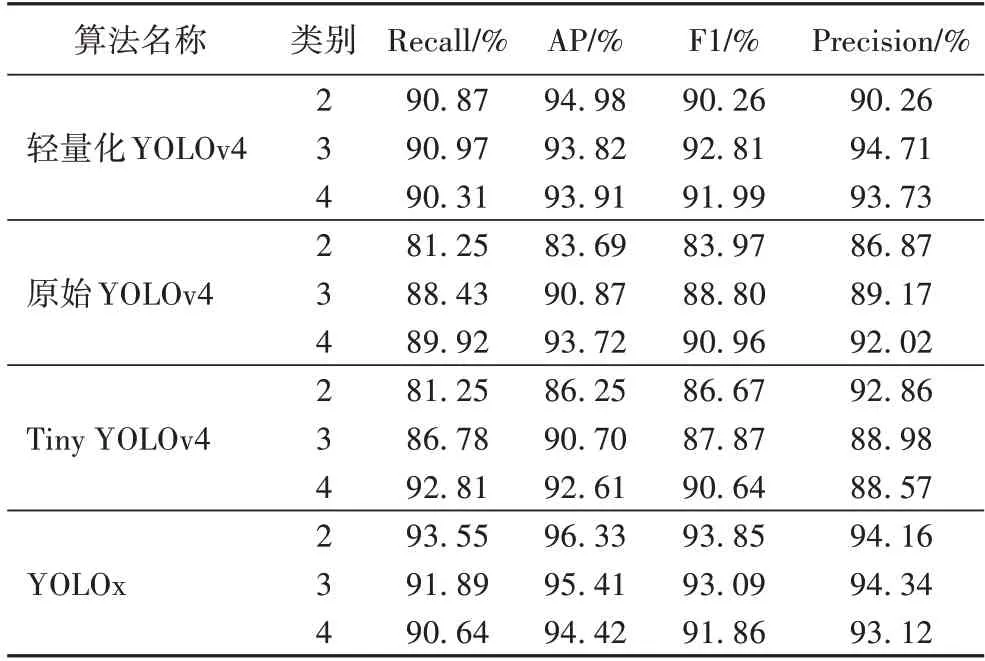
表5 针对不完整目标和小目标的检测效果对比Tab.5 Detection results comparison for incomplete targets and small targets
综合上述分析可知,轻量化的 YOLOv4 模型和其他模型都可以准确识别出近处的未被遮挡的完整目标,但是在部分复杂路况下:原始YOLOv4 无法识别出近处的被遮挡目标;Tiny YOLOv4 对近处的不完整目标存在一定的漏检,对于不完整的目标、重叠目标以及远处的小目标的漏检情况较为严重;YOLOx 面对远处遮挡小目标存在一定的漏检现象;但轻量化的YOLOv4 算法能准确地识别出不完整目标、重叠目标以及远处的小目标。
4 结语
本文提出了一种轻量化的YOLOv4 交通信息实时检测算法,为模拟真实道路路况信息,利用行车记录仪录制不同时段的北京道路场景信息并制作相应数据集,随后利用K-Means++算法对锚框进行聚类。使用MobileNet-v3 网络代替YOLOv4 主干网络,并将MobileNet-v3 网络中的浅层激活函数替换为LeakyReLU 激活函数,最后将YOLOv4 中的标准卷积替换为深度可分离卷积降低运算量。实验结果表明:轻量化的YOLOv4 检测算法与原始YOLOv4 检测算法相比,在检测速率为85.6 FPS 时,mAP 值为94.24%,本文模型可以为原始YOLOv4 检测算法进行针对复杂场景下的重叠目标、不完整目标和小目标提供辅助检测;但本模型仍有改进空间,如何提高检测速率,并使用与更丰富的检测场景是接下来待解决的问题。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年11期)2019-07-04
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
