
基于双向循环生成对抗网络的无线传感网入侵检测方法
2023-02-03 03:02刘拥民杨钰津罗皓懿谢铁强
计算机应用 2023年1期
刘拥民,杨钰津,罗皓懿,黄 浩,谢铁强
(1.中南林业科技大学 计算机与信息工程学院,长沙 410004;2.中南林业科技大学 智慧林业云研究中心,长沙 410004)
0 引言
无线传感器网络(Wireless Sensor Network,WSN)的应用前景非常广阔,如森林火灾检测、自动驾驶汽车和智能电网等[1-3]。WSN 主要负责从物理环境采集数据,将收集到的数据传输到互联网数据中心或网络云端进行处理。随着第五代移动通信技术(5th Generation mobile communication technology,5G)的推广以及物联网应用的扩充造成WSN 数据激增,WSN 面临多方威胁。由于WSN 节点资源受限、部署策略和通信信道开放等特性,WSN 系统在数据的采集和传输过程中易受到各种类型的入侵攻击,其中对数据进行的攻击常常导致数据损坏;而对网络结构、路由的攻击则可能导致网络功能丧失,甚至停止服务、网络崩溃。面对上述威胁,入侵检测是一种能够保障安全的主动防御技术,它能监测通信网络中的各种类型的入侵活动,并自动检测各种入侵企图[4],预警内部和外部的攻击。入侵检测系统分为基于规则的和基于行为的[5]两种类型,前者基于已知恶意流量既定的属性,后者侧重于与正常样本特征的偏差。基于规则的入侵检测系统对识别新攻击的效果不佳,相比之下,基于行为的入侵检测能更有效地将各种偏离正常的行为捕获为异常。
在过去,研究者们提出了许多方法来设计WSN 入侵检测系统。Selvakumar 等[4]使用Allen 区间代数和模糊粗糙集特征选择算法实现了一种自适应的入侵检测机制,通过选择大量的攻击数据对WSN 进行有效的攻击预测。结果表明,与标准模型相比,该方法提高了检测精度,降低了误报率,但它需要通过使用基于遗传的特征才能进一步提高性能。Sun等[6]引入否定选择算法(Negative Selection Algorithm,NSA)改进V-detector 入侵检测模型,通过修改检测器生成规则和优化检测器来改进V-detector 算法,并使用主成分分析来减少检测特征。Kalnoor 等[7]使用模式匹配技术检测入侵者,将提取的特征与现有模式进行比较,如果在模式匹配过程中出现偏差,则认为是异常的,然而,对于大型网络该过程过于复杂,因此不适用于大型无线传感网络。Borkar 等[8]提出了ACSO(Adaptive Chicken Swarm Optimization)模型,以突破聚类方法中的限制,还提出了一种基于自适应支持向量机的入侵检测分类模型来检测不同类型的攻击。虽然该模型融合了聚类技术提高网络效率,减少了时间消耗,提高了预测精度,但在解决高维优化问题时,容易陷入局部最优。Otoum等[9]提出了通过受限玻尔兹曼机入侵检测结构来保护WSN,分析了基于深度学习的入侵检测系统在WSN 中应用的可行性,并与自适应机器学习的入侵检测方法进行了比较,实验结果表明,构建的入侵检测结构检测率更高,但检测时间增加了一半。Gavel 等[10]将数据出现概率与全局概率密度函数相结合,判断网络中的入侵事件,并引入了皮尔逊散度以提高检测精度,降低假阳性率,但是,该研究没有考虑入侵的不平衡性。
随着5G 的应用和物联网的感知数据流量的增加,大规模、多维度的数据源源不断地产生,攻击场景变得更加复杂。现有WSN 入侵检测方法在取得一定成果的同时,也存在着处理高维、多样、不平衡数据时效果不佳,泛化能力不强的问题。针对以上问题,机器学习技术被应用于WSN 的入侵检测系统中。基于传统机器学习的WSN 入侵检测方法如K 近邻[11]、支持向量机[12]、决策树[13]以及随机森林[14]等存在许多局限性,如决策树的运行需要足够的内存,因此不适用于太大的数据集;而支持向量机在处理高维数据时很耗时。正常和异常样本数量之间的不平衡性会给这些基于统计学习模型的判断带来偏差;在数据的预处理和标记方面需要做大量的工作;它们的训练都必须是基于已知攻击类型的,对于未知攻击的检测能力非常弱。
WSN 数据具有高维、不平衡的特点。在以往的研究中,较大的数据集和高维特征数据可能会降低入侵检测系统的性能[4],随着深度学习的发展,基于深度学习的异常检测方法以其良好的性能得到了广泛的应用[15]。例如,深度自动编码高斯混合模型[16]、长短期记忆(Long Short-Term Memory network,LSTM)编码器-解码器[17]、深度自编码器与生成对抗网络(Generative Adversarial Network,GAN)的混合模型[18]显示出多元异常检测的良好性能。然而,入侵检测系统在对抗性例子下逐渐暴露其脆弱性,攻击者试图通过使用对抗的恶意流量,欺骗模型进行错误分类。GAN 是抗衡、甚至是反制这种对抗攻击的潜在方法,通过GAN 可以增加入侵检测系统的鲁棒性[19]。GAN 是由Goodfellow 等[20]最早提出生成模型中的一种,目前,主要应用于计算机视觉、时间序列和文本生成等领域[21-23]。在图像数据中,特定特征周围的特征通常相互关联。然而,网络数据流的特征大多是独立的特征,这些特征之间相关性不强。在这种情况下,经典的卷积核对特征提取的影响很小,因此本文采用了带有Dropout 操作的全连接层来构建网络。将GAN 应用于异常检测任务是通过学习正常状态的分布,然后通过测试样本和学习到的分布之间的差异,来判断测试样本是否为异常状态。尽管GAN 适用于模拟现实世界数据的高维复杂分布[24],但GAN 在异常检测中的应用还相对较少。Schlegl 等[25]最早提出的AnoGAN(Anomaly detection with GAN)方法基于深度卷积对抗网络(Deep Convolution GAN,DCGAN),通过建立真实空间和潜在空间之间的映射来更好地提取正常样本的特征,但当数据维数增加时,基于反向传播算法的映射时间成本很高。Donahue 等[26]提出BiGAN(Bidirectional GAN),当生成器学习潜在空间到真实空间的映射时,编码器同时学习从真实空间到潜在空间的映射,该方法通过加入编码器显著降低了时间成本,但检测效率不高。Zenati 等[27]提出了对抗学习异常检测(Adversarially Learned Anomaly Detection,ALAD),在加入编码器的基础上,改进了判别器,因此能更快、更有效地进行推理,异常检测性能也显著提高,并且擅长处理高维特征数据。
针对WSN 入侵检测任务,ALAD 方法仍然存在局限性,离散特征的数据会导致GAN 训练过程中出现不稳定,模式崩溃的问题[28],只能简单地提取一些局部特征,因而只能学习到一个不完全分布,在处理多样性的WSN 入侵流量数据问题上比较困难[29]。为摆脱这种困境,本文提出一种基于双向循环生成对抗网络的无线传感网入侵检测方法——BiCirGAN(Bidirectional Circulation Generative Adversarial Network),利用双向异常检测结构[27],结合谱归一化方法[30]和Wasserstein 距离[28]改进GAN 的目标函数,并对异常评分进行优化。在KDD99、UNSW_NB15 和WSN_DS 数据集上的实验结果表明,本文方法在具有离散高维特征的不平衡数据集上的精确度高于其他经典方法,具备更加优异的性能。
1 WSN结构及入侵检测模型
WSN 为多跳分布式网络,由多个簇群组成,每一个簇由簇头节点和传感器节点组成,簇头为每个簇中的汇聚节点,且由资源丰富的节点担任。簇内感知节点将采集的数据传输到簇头节点,簇头节点对本簇内的感知数据进行处理后转发至基站,如图1。采用分层结构的WSN 可对网络流量进行分布式检测,能分散能量开销减轻通信负担,实现节能[31]。
基于互联网的信息处理系统面临着各种各样的威胁,这些威胁会导致系统被破坏,进而导致WSN 中的信息严重丢失;此外,通过WSN 进行数据通信的流量也在不断增加,如此大量的数据自然成为了攻击者的目标,因此确保通过互联网进行安全有效的信息交流至关重要。如图1 所示,WSN 受到的攻击可能来自互联网、邻近的WSN 或是本身的WSN 内部,对于资源受限的传感器节点而言,检测WSN 中的入侵行为是一个挑战。由于基站(Base Station,BS)具有充足的能量和强大的运算能力,因此本文在基站上设置入侵检测系统,监控流量并训练入侵检测模型,对攻击进行检测,无需传感器节点(Sensor Node,SN)花费额外的能量参与入侵检测。

图1 与互联网连接的WSN的分布式分层系统Fig.1 Distributed hierarchical system of WSN connected with Internet
针对这种WSN 的结构,传统的检测方法在检测数据的海量性、高纬度与多样性上非常受限,无法有效地平衡检测模型在时间尺度与检测准确率上的一致性,引言中介绍了基于GAN 的方法能有效摆脱这种困境。如图2 所示,本文提出的BicirGAN 模型分为以下几个阶段:1)数据预处理阶段,WSN 中的簇头节点(Cluster Node,CN)每隔一段时间将收集的传感数据发送给无线网络中的基站,基站调整初始流量数据的格式并对调整后的数据进行数值化和归一化处理;2)训练与检测阶段,使用预处理好的训练数据集训练入侵检测模型,通过BiCirGAN 从大量流量数据中区分异常数据,对可疑数据作进一步检测,整个训练过程通过多次调整方法参数提高检测率;3)评估阶段,通过检测的结果评估训练后的入侵检测模型,如果检测率能满足实际应用需求,则停止训练,否则重复阶段2)对BiCirGAN 进行训练。

图2 WSN入侵检测模型训练流程Fig.2 Training flow of WSN intrusion detection model
2 基于改进GAN的无监督入侵检测方法
2.1 双向异常检测方法
GAN 由生成器Ge和判别器Di组成。Ge将从潜在空间(通常是高斯分布或均匀分布)中采样的随机变量z映射到真实空间,生成类似真实数据的正常样本,Di尝试区分真实数据样本x与Ge生成的样本Ge(z)。二者对抗博弈完成训练。博弈采用的是最大最小博弈,目标函数为:

其中min maxV(Di,Ge)表示:对于判别器Di,训练目标是使函数V取到最大值;而对于生成器Ge,训练目标是最小化V的值。E 表示数学期望,pX是数据x在真实空间X的分布,pZ为潜在生成器变量z在潜在空间Z的分布。固定的Ge,最优判别器为:

当且仅当pGe(x)=pX(x)时,Ge和Di同时达到全局最优。
在异常检测中,为了提高计算效率采用对抗性学习异常检测,提高GAN 的学习速度以及方法的整体异常检测性能,结构如图3,ALAD 方法包含一个生成器Ge、一个编码器En和三个判别器Dixz,Dixx,Dizz。ALAD 方法的目标函数为:

图3 ALAD方法结构Fig.3 Structure of ALAD method
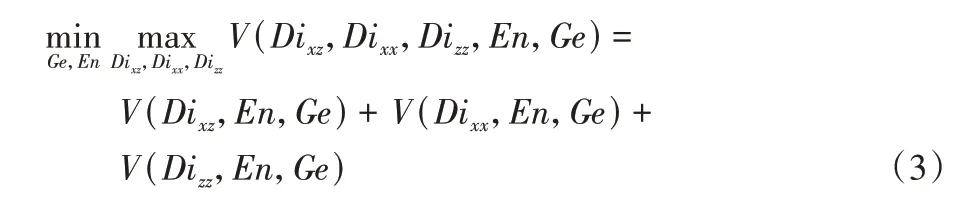
在ALAD 方法基础上,引入自适应矩估计梯度下降法不断降低三个判别器的损失,组合网络流量数据间各种有效的特征来进行对抗学习,以缩小潜在空间分布与真实空间分布的差距。BiCirGAN 具体结构信息如下:
1)编码器En。编码器En将输入的x∈X映射到潜在空间得到编码样本En(x),解码器Ge将En(x)映射回真实空间,从而重构特征Ge(En(x))。En是一个非线性函数映射的多层感知机(Multi-Layer Perceptron,MLP),由两层神经网络组成,每层都是全连接层,神经元个数逐层递减。

其中:WEn表示En的权重矩阵;bEn表示En的偏移矢量矩阵;σEn表示En的激活函数。
2)生成器Ge(解码器)。生成器Ge将随机采样的z∈Z映射到真实空间生成特征Ge(z),编码器En将Ge(z)映射回潜在空间得到En(Ge(z))。Ge由全连接的三层神经网络组成,第一层神经元个数为潜在特征空间维度,第三层的神经元个数为真实空间中原始数据的特征维度。

其中:WGe表示Ge的权重矩阵;bGe表示Ge的偏移矢量矩阵;σGe表示Ge的激活函数。
3)判别器Dixz为核心判别器,采用带有Dropout 操作的全连接层来构建网络。concat(x,En(x))和concat(Ge(z),z)作为输入进行对抗学习,得到带有判别信息的潜在表示。生成特征与潜在表示的联合概率分布分别为:

4)判别器Dixx。联合输入concat(x,Ge(En(x))) 和concat(x,x)到判别器Dixx进行对抗学习,能有效降低重新构建特征信息的损失。本文借鉴Li 等[32]提出的Hπ(x|z)=(其中π(x,z)代表x和z上的联合分布),使Dixx近似Ge和En的条件熵,从而促进循环达到一致性,目标函数为:

5)判别器Dizz。concat(z,z)和concat(z,En(Ge(z)))作为输入进行对抗学习,使生成的样本更具多样性,从而提高GAN 的学习能力以及稳定性,目标函数为:

2.2 目标函数优化
对于网络入侵检测中的离散特征数据,JS 散度(Jensen-Shannon divergence)有其局限性。对于用0-1 表示的逻辑特征与用One-Hot 编码或Dummy 编码的非数值特征,维度扩展可能非常严重,造成真实样本和生成样本之间几乎没有重叠。当两个分布几乎没有重叠时,JS 散度将不可避免地收敛到一个常数,导致梯度消失的发生。
针对上述问题,WGAN(Wasserstein Generative Adversarial Network)方法利用Wasserstein 距离代替了JS 散度来衡量两个分布的差异,该方法在离散分布上也表现良好,有助于改善区分过程,也有助于改善生成过程,从而生成更稳定、更优质的结果。即使两个没有重叠的分布,Wasserstein 距离仍然能够反映其远近。该模型的目标函数为:

其中f表示满足1-Lipschitz 约束的任意函数,也称Critic,1-Lipschitz 约束定义为:

这一约束的作用在于对相邻的两点x1和x2,函数值f对数据不会过度敏感。
WGAN 使训练过程更加稳定,避免了模式坍塌的发生。WGAN 的目标函数中的函数f可以通过神经网络模型来估计,要使每一层的神经网络都满足1-Lipschitz 约束,通过证明与推导只需要约束参数w:

WGAN 模型提出了参数裁剪(weight clipping)来约束参数的范围,使f的w保持在[-c,c]范围,但用这种方法训练出来的模型过于简单,生成能力较差,还很容易造成梯度消失或梯度爆炸。
本文采取谱归一化来约束参数范围。谱归一化约束是通过约束Critic的每一层网络的权重矩阵的谱范数来约束Critic的1-Lipschitz,这样增强了GAN 在训练过程中的稳定性。谱范数(Spectral Normalization)的定义为:

其中‖W‖s为权重矩阵W的最大特征值(maximum singular value)。对式(14)进行调整得到:

结合式(11),谱范数能更准确地反映1-Lipschitz 约束,使权重矩阵W与谱范数‖W‖s的比值等于1,得到谱归一化:

结合WGAN 的目标函数,将ALAD 模型的目标函数修改为:

通过式(18)~(21)生成的潜在空间特征的Wasserstein 距离,可以使生成的潜在空间特征更接近真实空间特征,从而生成更高质量的网络流量数据。此外添加谱归一化稳定GAN 的训练,能使模型更快地收敛。
2.3 异常评估
测试样本和正常样本的学习分布之间的差异越大,测试样本越可能异常,因此可以通过差异来评估样本,而不需要直接评估生成器生成的结果。结合Li 等[22]与Zenati 等[27]提出的计算异常分数方法,本文提出的异常率为:

其中:A表示异常率,A值越大样本异常的概率越高;n代表样本个数,λi为一个常数;LRi为重建损失,用来衡量测试样本和生成样本之间的差异;xi是输入样本,Ge(En(xi)是通过生成器重建的样本;LDi是从真实的数据分布中得到的判别损失。在判别损失中,fxxj(·,·)表示给定输入样本对的判别器Dixx网络中的特征层,k代表中间层层数,中间层产生的损失也称为特征匹配损失[26],如图4 所示。

图4 训练损失Fig.4 Training loss
异常的评估取决于生成样本与原始样本分布的距离,即生成器从潜在空间学习特征分布的能力,本文综合考虑了判别与重构损失,增强了模型识别正常样本与异常样本的能力,提高了异常检测精度。
关于异常率,一种方法是在检测中确定一个阈值来判断样本是否异常入侵。这种方法适用于在线检测,因为不需要了解正常样本和异常样本的比例,只需要从经验中获得的阈值。第二种方法将高于污染率c(异常/(正常+异常))的相关样本标记为异常入侵,通常应用于数据集上的测试。由于本文的实验是在数据集的基础上进行仿真测试的,因此采用第二种方法来评估模型的异常检测率。
3 实验与结果分析
本章从对比实验、消融实验和可视化实验来分析BiCirGAN 的检测性能。此外,通过计算方法的执行时间来评估方法的实时检测效率。
3.1 实验环境、数据集与预处理
实验环境基于Windows 操作系统,使用Python 语言,在Pytorch 框架上搭建方法,主要硬件环境为CPU Intel Core i7-4710HQ,内存8 GB,GPU NVIDIA GeForce GTX 860M。
实际上,目前的WSN 仍处于建设的初级阶段,难以进行大规模的物理测试。为了充分评估和验证所提出的方法,实验使用公开权威数据集:KDD99 数据集[27]、UNSW-NB15 数据集[33]、WSN_DS 数据集[34]。
首先对数据集进行预处理。KDD99 数据集中每条记录包含41 个固定的特征属性和1 个类标识,在41 个固定的特征属性中,9 个特征属性为离散型,对其进行One-hot 编码后,总共获得121 个特征。UNSW-NB15 数据集每条记录包含49个特征,对其中3 个离散特征使用One-Hot 进行编码,总共得到196 个特征。WSN_DS 数据集为无线传感器网络入侵检测系统专用数据集,该数据集的数据特征是基于WSN 中的LEACH(Low Energy Adaptive Clustering Hierarchy)路由协议,选择其中的18 个无标签特征属性作为实例特征。对数据集选取的样本的统计详见表1。

表1 数据集描述Tab.1 Data set description
流量数据归一化可以消除不同维度数据之间的差异,保证训练结果的可靠性。本文采用最小-最大值归一化方法处理数据:

其中Qi,j代表数据集的第i行和第j列中的特征值。
3.2 评价指标
采用经典网络异常检测系统研究相同的评估方法。为测量基于GAN 的WSN 入侵检测模型的性能,使用精确度Prec(Precision)、假阳性率(False Positive Rate,FPR)、召回率Rec(Recall)和F1 分数F1(F1 score),计算如式(24)~(27)所示。异常检测的分类混淆矩阵,如表2 所示。


表2 异常检测分类混淆矩阵Tab.2 Anomaly detection classification confusion matrix
3.3 实验参数设置
不同数据集下相关参数设置如表3 所示。其中:learning_rate表示学习率;batch_size代表每一批次的大小;latent_dim为潜在空间的维度;nb_epochs表示迭代的次数。

表3 数据集参数Tab.3 Parameters of datasets
模型的网络参数依据数据集维度进行设置,如表4 所示,其中:units表示神经元个数;σ表示激活函数;Dropout表示丢失率,连接方式为全连接。

表4 不同数据集下网络参数设置Tab.4 Network parameter settings under different datasets
3.4 实验结果分析
3.4.1 对比实验
BiCirGAN 方法与以下4 种方法进行对比:1)AnoGAN[25]是基于生成对抗网络异常检测最常见的方法;2)BiGAN[26]首次在生成对抗网络上引入了编码器;3)MAD-GAN(Multivariate Anomaly Detection with GAN)[22]是基于GAN 的多变量时间序列异常检测方法,以LSTM 为基本方法来捕获时间上的依赖关系,并将其嵌入到GAN 的框架中;4)ALAD[27]是一个基于双向GAN 的异常检测方法。
5 个方法在3 个数据集的对比实验结果如表5 所示,BiCirGAN 的效果最好,检测精确度提高了3.9%~33.0%。说明在充分考虑潜在空间分布合理性的前提下,BiCirGAN 能够有效地发挥深度生成学习方法的优势,在高维、样本多样、数据量多的UNSW-NB15 数据集和不平衡数据较多的WSN_DS 数据集上有效提升精确度、召回率、F1 分数,假阳性率(误报率)也有所下降。

表5 基于GAN模型的异常检测模型在3个数据集上的评估结果Tab.5 Evaluation results of anomaly detection models based on GAN model on three datasets
3.4.2 消融实验
为验证模型各部分的有效性,在KDD99、UNSW-NB15、WSN_DS 数据集上进行了BiCirGAN 的消融实验,不同模型的组合如下:1)ALAD+JS 模型:应用改进后的ALAD 网络结构,目标函数使用原始的JS 散度衡量异常与正常两个分布之间的差距。2)ALAD+WD 模型:应用改进后的ALAD 网络结构,目标函数采用Wasserstein 距离衡量异常与正常两个分布之间的差距,通过WGAN 原始的参数裁剪来约束参数。3)BiCirGAN 模型:在模型2)的基础上,添加谱归一化对WGAN 进行参数约束。结果如表6 所示。
从表6 中可见,将JS 散度替换成用Wasserstein 距离衡量异常和正常两个分布之间的距离,性能反而降低,是因为WGAN 的参数裁剪导致训练的不稳定,没能充分学习数据的分布。在UNSW-NB15 数据集上,BiCirGAN 方法相较于ALAD+JS 方法,Pre、Rec、F1 指标分别提高了6.74%、5.71%、7.58%;在WSN_DS 数据集上Pre、Rec、F1 分别提高了4.16%、1.85%、3.04%,在KDD99 数据集Pre、Rec、F1 分别提高了3.70%、1.00%、2.34%。从评价指标上来看,在维度更高、数据类型更多的UNSW-NB15 数据集上,效果更好,在不平衡的WSN_DS 数据集上效果次之。实验结果表明BiCirGAN 方法不仅能学到更好的特征分布,在处理高维、样本类型多样以及不平衡数据上效果会更佳。

表6 消融实验评估结果Tab.6 Evaluation results of ablation experiment
3.4.3 训练效率实验
绘制出在KDD99 数据集上训练迭代100 次的判别器损失图,如图5 所示,可以看出当生成器最小化时,BiCirGAN 方法相较于ALAD 收敛得更快,在50 代左右损失值已经达到比较低的水平。

图5 判别器模型损失值变化Fig.5 Discriminator model loss value change
即使一个方法在检测中可以达到非常好的效果,检测延迟依旧是一个重要的考虑因素,如果检测过程花费了过多的时间,攻击方仍然有足够的时间来损坏系统。由于BiCirGAN 是在ALAD 方法网络结构上进行优化的,因此选择其作为基准对推断时间进行比较。在不同数据集上两个方法的平均推断时间比较如表7 所示,实验结果表明,与ALAD方法相比,BiCirGAN 对数据的平均推断时间更短,在UNSWNB15、WSN_DS 数据集上分别为ALAD 的1/4.57 和1/4.67,因此新方法在高维离散不平衡的网络数据的异常检测上较ALAD 方法的效率更高。

表7 平均推断时间Tab.7 Average inference time
3.4.4 可视化实验
为了探索BiCirGAN 对异常数据的检测能力,实验对BiCirGAN 与ALAD 方法在UNSW-NB15 测试数据集上分别进行了异常率的计算,如图6 所示。

图6 测试样本异常率分布Fig.6 Test sample anomaly rate distribution
在BiCirGAN 的异常率分布结果中,正常与异常分布边界(c)清晰明显,重合分布较少,正常样本和异常样本在异常率下进行了有效的聚集。对比ALAD 方法的异常率分布与本文方法在可视化上有着明显的差距,重合分布较多,如图6(a)。这说明BiCirGAN 较ALAD 方法在网络异常数据上能学习到更高质量的特征分布,从而给出更加准确的异常率的值。
上述实验表明,BiCirGAN 在各项评价指标中均有提升,且针对网络高维数据异常检测的改进有效、训练更加稳定、收敛更快、检测效率更高且能更好地完成正常样本与异常样本的分离,在高维、离散、不平衡的WSN 网络流量数据的异常检测上表现出更加优异的检测性能。
4 结语
本文提出了一种双向循环生成对抗网络的入侵检测方法BiCirGAN,能对复杂网络环境下的WSN 中的异常数据进行有效的检测。该方法考虑到潜在空间表示分布的约束条件,引入了改进的ALAD 方法,通过双向内循环训练机制将高维性、多样性以及不平衡性的数据集通过潜在空间合理地表示出来,进而提高了异常检测的有效性;考虑了离散数据特征的重叠分布,结合Wassertein 距离和谱归一化改进目标函数,解决了GAN 训练的模式崩坏与不稳定等问题。实验结果表明该方法各项检测性能均高于对比方法,在训练中更加稳定,并且大大减少了测试过程中的时间成本,降低了计算资源的消耗。
但在数据少量的情况下,本方法效果较为一般。在下一步的工作中,本研究将对WSN 特定类型的攻击进行分类,此外尽管已经验证了该方法在KDD99、UNSW-NB15、WSN_DS数据集下的实验结果,但仍有必要进一步改进方法以应对训练数据集不足以及更复杂的无线传感网络传输环境。
猜你喜欢
数学杂志(2022年4期)2022-09-27
中学生数理化·高一版(2021年2期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
知识经济·中国直销(2018年8期)2018-08-23
世界知识画报·艺术视界(2017年7期)2017-07-27
自动化学报(2017年11期)2017-04-04
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
