
云平台下基于截止时间的自适应调度策略
2023-02-03 03:02吴仁彪张振驰贾云飞
计算机应用 2023年1期
吴仁彪,张振驰,贾云飞,乔 晗
(天津市智能信号与图像处理重点实验室(中国民航大学),天津 300300)
0 引言
云计算已成为流行的计算范式,近年来,由于基于云的应用需求不断增加,资源共享和复用的要求越来越迫切。如何根据云计算中心和用户的服务质量(Quality of Service,QoS)要求,高效合理地分配不同的资源是一个关键问题。传统资源分配方案难以根据用户请求有效地分配资源,因此,行业和学术界都开始了大量的研究。通常而言,云服务平台以作业为抽象单位执行计算任务,按计算任务的不同可以将作业分为长作业和短作业。短作业一般以服务的形式处理用户的请求,例如网页搜索、实时交易等服务,这类服务具备较高的实时性要求;而长作业是数据密集型的批处理作业,如数据分析作业、机器学习模型训练作业等。对于具有较高稳定性和实时性要求的作业,企业会对外提出明确的服务等级协议(Service Level Agreement,SLA)以明确的条款约定服务质量,违反SLA 会给企业带来经济损失,因此对于这种作业,往往会预留大量的资源以保证其服务质量。然而,过量资源供给策略会导致资源利用率较低。统计数据[1-2]显示,全球数据中心的资源利用率仅为10%~30%,存在大量的资源浪费,如何提升资源的利用率成为一个亟须解决的关键性技术问题。
研究[3-6]表明,通过在多个用户之间共享硬件基础设施可以有效提高利用率。例如Google 在其集群管理系统Borg[7]中利用统一调度策略实现了两种作业的混合部署,使集群规模压缩为原有集群的35%;Matrix 复用Sorlaria 和Normandy 为百度节省了数万台服务器的成本[8];阿里巴巴按照同样的做法利用Sigma[9]和Fuxi[10]组成混部系统将原有集群的利用率从10%提升至40%,节约总体成本30%以上。与此同时,共享的数据中心将面临新的挑战,即不同用户提交的任务具有不同的服务需求,各个任务之间差异很大,集群管理框架面临着如何高效托管各种工作负载的挑战[11-14]。
传统的集群调度器基于完整的集群信息作出集中的调度决策,目的是优化资源利用率并保持数据局部性。然而,这种调度策略是为长作业设计的,没有考虑到短作业延迟敏感度高的特点,因此在高负载下可能会显著延长短作业的执行时间。一些分布式调度器,如Sparrow[15]和Apollo[16],通过在每个节点部署调度器来加速调度。尽管分布式调度器可以作出敏捷的调度决策,但如果集群负载很高,在单个节点上完成长任务之前,短任务仍然会经历长时间的排队延迟。为了协调两者,混合调度器[17-18]使用分布式调度保留集群的一部分资源专门运行短作业,而使用集中式调度将长作业调度到其余的部分。此方法实现难点在于如何确定群集的最佳分区,在保证短作业低延迟的同时保持高的集群资源利用率。另外一种解决思路是实时预测应用的资源需求,并以此为基础动态按需供应资源,例如文献[19-20]中提到的方法通过作业资源匹配算法以及资源预测算法为应用按需动态供应资源。然而这种启发式的资源预测需要结合历史数据和用户给出的波峰波谷的变化周期及幅度才能准确预测下一个时间周期的资源需求。
如果短作业任务可以抢占长作业任务,短作业的调度可以变得简单快速,而长作业可以在集群中的任何服务器上运行,以保持高利用率。例如另一种资源协调者(Yet Another Resource Negotiator,YARN)[21]和Mesos[22]中,用户可以为任务设定优先级,在资源出现竞争时优先满足高优先级的任务以保证短作业的响应速度,然而目前现有的调度策略只支持kill-base 方式的任务抢占,即被抢占的任务只能取消,执行进度会丢失,这可能导致长作业的任务完成时间延长。
综上所述,对具有不同资源需求的任务进行调度时,资源预留式和资源预测等方法都有其局限性,抢占式调度简单而快速,能有效保障任务的服务质量,但现有的抢占式调度没有考虑到被抢占任务的执行情况。针对这一问题,本文提出了一种可以有效兼顾抢占任务的响应速度以及被抢占任务的完成时间调度算法。
本文的工作有:1)实现了一种以提交截止时间代替用户指定固定资源的任务提交方式;2)提出了一种自适应资源分配策略,根据任务提交的截止时间和任务的实际执行情况自适应地分配资源;3)提出了一种用于调度不同服务质量需求任务的调度策略,基于抢占式调度策略的思想,优先满足短作业的响应速度,然后补偿额外资源用于长作业的执行。
1 分布式计算框架Spark
Spark 通过在弹性分布式数据集(Resilient Distributed Datasets,RDD)[23]上实现transformations 和actions 操作来推广MapReduce[24]编程模型,如图1 所示,Spark 任务执行引擎包括任务解析和生成,任务分发调度以及分配执行任务所需的资源。对于任务的生成,在用户提交Spark 作业后,有向无环图(Directed Acyclic Graph,DAG)Scheduler 会遍历所有RDD,并根据它们执行的操作类型将它们分为不同的阶段。然后,基于同一阶段包含一组任务的RDD 分区,为就绪阶段创建任务集。与此同时,资源管理器在节点上分配相应资源并启动Executor 等待任务的发送。Spark 默认使用粗粒度调度模式分配资源,即启动相应资源的Java 虚拟机(Java Virtual Machine,JVM)维护一组线程用于执行即将分配过来的任务。对于任务的分发调度,任务集由Task Scheduler 按相应策略分发到各个节点中,Task 执行完成后会将结果返回。
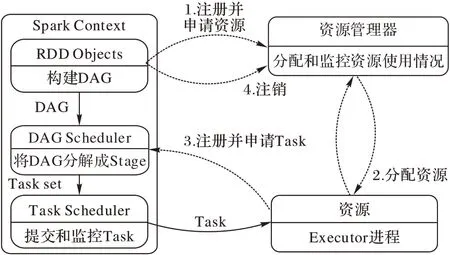
图1 Spark的任务执行模型Fig.1 Task execution model of Spark
2 基于容器的抢占式任务调度策略
目前Spark 已经成为最流行的计算框架之一,Spark 将Task 的计算结果缓存到内存中供后续Task 使用,因此在迭代计算以及Task 非常多的应用中拥有显著的优势。然而相关研究[25]表明,在面对抢占式任务调度时,Spark 更容易受到抢占式调度的影响。主要原因有以下几点:1)Spark 中运行的任务执行器采用多线程模型,对一个容器的抢占会影响多个任务;2)对于具有迭代计算的Spark 作业,任务涉及容器间的频繁切换;3)由于Spark 基于内存计算的特点,从抢占容器中回收内存可能会导致严重的内存交换。
基于以上几点原因,本文参考dynaSpark[26]的动态资源调度方法,在此基础上提出一种抢占式任务调度方法,工作流程分为以下四步:
第一步 用提交截止时间的方式替代固定的资源分配并将随任务提交的截止时间进行划分,分成每个阶段的截止时间deadlines。
第二步 根据预执行结果启发式地分配给各个Executor相应的计算资源作为初始资源。
第三步 实时监测任务执行进度,比较其与预期进度的误差,根据误差对本节点上的容器进行资源调整,保证各阶段任务以及整个应用在截止时间附近完成。
第四步 多作业并行执行时,根据用户设定的优先级分配给不同应用相应的计算资源。
为了扩展Spark 实现动态资源分配的功能,对Spark 原有的体系结构和处理模型进行修改。如图2,为改进后的系统框架,无底色部分为Spark 基础结构,有底色部分为添加的 组件。
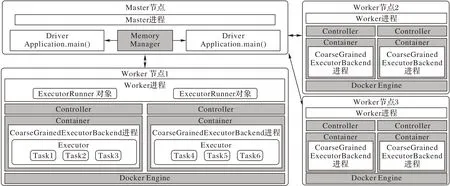
图2 改进后的Spark架构Fig.2 Improved Spark architecture
为了动态调整任务运行过程中分配给Executor 的计算资源,每个Executor 进程都运行在以Docker Engine 为基础的容器中,并且每个Worker 节点都部署有Control 组件负责实时监测每个Executor 中任务集的完成情况,根据实时任务完成情况,动态调整分配给Executor 的CPU 核数。在Master 节点中,Memory Manager 负载管理分配给应用的内存大小,根据提交的任务数量动态调整堆外内存。
2.1 Deadline划分
扩展后的Spark 利用容器(即Docker[27])来支持更灵活、细粒度的资源管理,通过将每个执行器部署在一个容器中,以允许动态地改变提供给执行器的计算资源。具体来说,用户可以使用一个额外的参数deadline来丰富命令提交,以指定此应用期望的执行时间。动态分配资源的目标是在不违反截止日期的情况下最大限度地减少资源的使用,相较于提交之前确定分配给应用固定的计算资源,这种分配资源的方式更具可控性,因为预估任务计算时间是十分困难的。
相较于给完整的应用程序分配资源,由于阶段是由具有不同复杂程度的不同操作组成的,对每个阶段进行单独的控制更为合理。因此,每个应用程序都使用基于启发式的算法来计算每个阶段的截止日期deadlines。当一个阶段s提交执行时,使用以下公式计算初步截止日期:

其中:spentTime是已经花费在执行应用程序上的时间;appDeadline是用户提交的应用的持续时间表示的截止时间;α∈[0,1]是一个常数,用来设置遵守截止时间的保守程度。如果α=1,执行时间将被控制严格地满足截止时间,而对于较小的α值,控制将更加保守。ωs为阶段的权重,计算如下:

其中:Rs是仍待执行的阶段集,包括s,ds是Rs中阶段的已分析持续时间之和与s本身的已分析持续时间之比。因此:
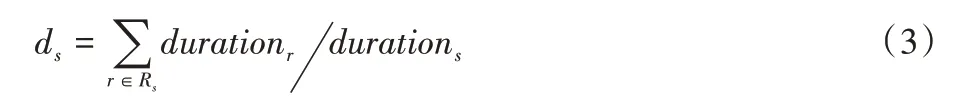
由于在分析期间也就是预执行期间,测量的性能可能不同于在运行时的性能,为了避免过度拟合分析数据,使用常数β来减轻拟合。所有的ωs都是在运行时计算的,因为如果DAG 中有并行线程,就不能先验地知道阶段执行的顺序。
2.2 启发式控制阶段
得到阶段的截止时间后,为执行阶段而分配的CPU 核心数量被估计为:

其中:inputRecords是必须由s处理的记录数量;nomRates提供s的标称速率,即单个核心每秒处理的记录数量(在分析期间获得)。输入记录取决于DAG 中父节点写入的数据总和(即父节点产生的记录总和)。
最后一步计算内核的初始数量和每个不同执行器要处理的任务数量。通过为每个Worker 节点的每个阶段创建一个执行器,在所有可用的Worker 节点之间平均分配负载。通过这种方式,每个执行器都持有相同数量的任务,因此在shuffle 过程中远程读取相同数量的数据,这意味着可以为所有执行器计算相同的截止日期。每个执行器的初始内核数计算如下:
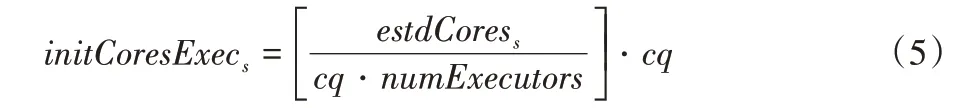
其中:numExecutors是执行器的数量,始终等于工作节点的数量;cq代表内核数量,这是一个定义应用于资源分配的量化的常数,值越小,分配越精确。
在本文的实验中,设置cq=0.05,以分配精度高达0.05的内核,并获得较低的误差。初始分配的资源不需要非常精确,因为后面会根据任务的执行进度自适应地资源分配。
2.3 基于容器的动态资源调度
初始资源分配完成后,任务开始运行,Worker 节点上的Control 组件会根据任务执行进度动态分配资源,实现动态资源调度的关键技术由两部分组成:第一部分是容器技术Docker,通过Docker 的CPU 周期分配技术实现对运行期间的Executor 进行资源调度;第二部分则是实时控制部分,通过分析实时的任务完成率,当实时完成率低于预期完成率则增加计算资源,反之则减少资源。由此,应用程序在运行过程中可以根据执行进度进行资源的分配,然后在截止时间附近完成。
2.3.1 容器技术概述
目前大多数大数据应用程序都是用托管语言(Managed Programming Language)编写,以实现跨机器的可移植性,以Spark 为例,当Executor 部署到Worker 节点上时,节点首先需要启动一个JVM 来执行它们。其中CPU 内核的分配是静态的,由一个简单的内部线程池管理,并且Executor 与应用绑定,即使当前的Executor 没有任务运行,只有当整个应用结束时,资源才能释放。另一个重要的参数是JVM 的堆大小,它的错误配置会导致任务失败:设置堆大小太小可能会导致JVM 内存不足(Out Of Memory,OOM)错误,任务将失败;设置堆大小太大可能会导致后续应用程序资源不足导致过长的延迟。在运行任务之前,很难甚至不可能确定最佳的JVM堆大小。
与基于虚拟机管理程序的虚拟化相比,基于容器的虚拟化技术,例如Docker,由于它几乎可以忽略不计的开销而变得流行。容器为容器内运行的应用程序提供独立的名称空间,并形成资源核算和分配单元。Linux 使用控制组群(cgroups)来精确控制容器的资源分配。有了容器,任务可以以大的JVM 堆大小启动,用户可以使用cgroups 来限制托管容器的内存使用,以防止系统内存崩溃。重要的是,即使任务的堆使用量超过了它的容器内存大小(因为堆的大小要大得多),任务也不会遇到OOM 错误,而是会开始内存交换。
2.3.2 动态资源分配
Docker 提供了多种向容器分配CPU 的方法,其中Quotas方法能保证CPU 分配的确定性和快速性。Quotas 为每个容器都设定一个周期和一个配额,后者表示在该周期内分配给容器的CPU 时间的百分比。设置大于周期的配额意味着容器一次应该使用多个核心,但是所有配额的总和必须始终小于设置的周期乘以可用核心数。
例如,对于拥有一个单核CPU 的节点,设定100 ms 的周期,如果给容器1 的配额为30 ms,给容器2 的配额为70 ms,那么70%的CPU 时间留给容器2,30%留给容器1。
分配原则遵循完全公平调度(Completely Fair Scheduler,CFS)[28],这种机制是确定性的,非常细粒度,实现也非常地快速,一次分配通常能在几百毫秒内完成。
Spark 的Executor 实际上是在Worker 节点中启动的CoarseGrainedExecutorBackend 类进程中维护的一组线程池,改进后的系统将其封装在Docker 镜像内,启动Executor 时分配初始参数,之后Control 组件实时监控Executor 的工作状态,计算实时的资源需求,得到需要的资源数量后,执行Docker update 命令对容器的资源进行调整。cpu-period 参数用来指定容器对CPU 的使用要在多长时间内做一次重新分配;而cpu-quota 参数是用来指定这个周期内,最多可以有多少时间来运行此容器。例如要为一个Executor 分配cores 为2.5 的CPU 资源,设置参数cpu-period 为100 000、cpu-quota 为250 000。
2.4 抢占式任务调度
2.4.1 应用内存分配
在开始执行应用程序之前,用户必须指定提供给每个executor 的内存量。足够的内存可以保证性能,而有限的内存可能会导致磁盘交换(存储)或崩溃(执行),因为执行中的任务不允许交换。在需要同时执行多个应用程序时,如果用户事先知道具体有多少应用程序并行执行,可在它们之间划分可用的内存。但这并不总是可行的,并且由于如果请求的内存不可用,Spark 会推迟应用程序的启动,因此用户划分内存必须谨慎。动态分配内存可以解决这个问题,但对于传统的框架,如果不终止进程并重新启动它,就无法调整执行器的堆内存大小。使用堆外内存是一个可行的折中方案。Spark 本身已经实现了使用堆外内存的方案,堆外内存是指由操作系统直接管理并存储在进程堆外的对象,也就是说,它们不被JVM 的垃圾收集器处理。访问堆外数据比访问堆内数据稍慢,但比读写磁盘快。
Spark 本身没有提供动态调整堆外内存大小的方法,本文添加了相应的组件进行内存管理。给定一组正在运行的应用程序A和集群的总内存M,用户可以通过这个组件决定分配给每个应用程序的固定堆内存量h。内存管理器还为每个正在运行的应用程序分配堆外内存o=(M-h·|A|)/|A|。当新应用程序提交执行时,内存管理器会重新分配堆外内存,但如果o<h,则新应用程序必须等待正在运行的应用程序终止,其内存变得可用,并且新应用程序可以启动。
对所有应用程序进行平均分配并不是最优的,但当工作负载未知时,这也是一种保守的解决方案。
2.4.2 基于优先级CPU分配策略
对于传统的Spark 框架,CPU 的分配在应用提交时就已经确定。传统的抢占式任务调度策略下,当集群资源不足以满足作业的资源要求时,就只能取消正在运行的任务并且回收资源,以便新提交任务的执行。本文提出了一种更为友好的任务抢占方法。同样地,用户提前为作业划分好优先级,系统根据优先级向应用程序分配资源;不同的是,提交作业时用户不需要提交固定的资源需求,作业不会出现排队现象,任务运行时,系统收集节点上资源请求信息,根据给定的任务优先级给提出申请的任务进行排序,按排序顺序依次分配任务的资源申请,这样在资源不足时,优先级高的任务申请的资源会被优先满足,低优先级的任务只能被分配剩余的资源。
如果任务每次的资源申请都能满足,就会在实验设定的deadline内完成任务,否则在抢占的任务完成后,对被抢占的任务进行资源补偿。
2.5 改进算法伪代码
改进的抢占式任务调度算法的伪代码如下:
输入 用户设定的应用截止时间appDeadline;
输出 算法为Executor 分配的CPU 资源correctCores。

3 实验与结果分析
本文在5 个节点集群上对改进后的方法进行了评估。所有实验都使用了带有4 个CPU、12 GB 内存和500 GB 本地固态硬盘存储的服务器,各软件版本信息如表1 所示。

表1 软件版本信息Tab.1 Software version information
实验首先测试改进后平台的动态资源调度功能(见3.1节);接下来,展示了任务抢占时的资源调度情况,描述了出现资源竞争时系统的调度结果(见3.2 节);最后对比在不同负载下本文方法与传统的调度策略的实验结果(见3.3 节)。
3.1 动态资源调度实验
为了评估算法如何动态分配CPU 内核,本文使用了来自两个基准测试套件的8 个应用程序。其中aggr-by-key(以下简称abk)、aggr-by-key-int(简称abk-int)、group-by、sort-by-key(简称sbk)和sort-by-key-int(简称sbk-int)强调基本的聚合和排序功能,来自SparkPerf。KMeans、SVM 和PageRank 来自SparkBench,这三个应用是常见的具有迭代运算的例子,前两个是用于分类的机器学习应用程序,第三个则是著名的网页排名算法。前五个应用程序不包含分支或循环,后三个是迭代的,但是迭代次数在开始时通过参数配置。这意味着每个程序的所有执行都有相同的DAG。各个应用使用的数据集是使用配套的基准测试套件中提供的工具和按照表2 中的参数设置随机生成的。

表2 测试数据集参数设置Tab.2 Test dataset parameter setting
实验分为两个步骤,首先使用Spark 来运行每个应用程序,分配给每个任务所有的可用资源,即4 台worker 节点的16 个CPU 核心,把以这种方式提交的作业的执行时间设定为测试基线(testBase)。
然后,本实验配置了如表3 所示的参数,按照同样的方式在改进后框架上提交任务,以便与Spark 进行比较。其中deadline设置为与测试基线相同(test0%)和将原始截止日期放宽20%(test20%)两种分别进行实验。在不增加资源的情况下,截止日期不能比基线更短,因此,这些实验的目标是评估调度算法满足截止日期的精度以及动态分配CPU 内核的能力。

表3 作业参数设置Tab.3 Job parameter setting
图3 显示了为PageRank 应用设定deadline=600 时动态分配CPU 核数的过程,E 代表任务所处的阶段(Stage),E0 表示初始阶段,E1 表示Stage1、E2 表示Stage2,依此类推。其中:坐标轴x轴指任务执行经过的时间;坐标轴y轴左侧指任务的完成进度,对应图中的黑线(任务实际完成率)与灰线(期望完成率);右侧y轴对应所分配到的CPU 核心数,对应图中的离散点;图中垂直的线代表用户设定的截止时间(虚线)和任务实际完成的时间(实线)。在运行时,本地控制器预见核心部分分配给执行器,当阶段的实际进度低于规定进度时,分配的核心数增加,而一旦实际进度变得更高,分配的核心数就迅速减少。改进后的系统很好地根据用户提交的deadline动态地分配资源,严格地在截止时间附近完成任务。

图3 CPU动态分配过程Fig.3 CPU dynamic allocation process
表4 显示了用不同实验测试得到的控制精度的结果。表中显示了在实验过程中是否发生了违反截止时间的现象以及任务完成时间与截止时间之间误差的最小值(errormin)、最大值(errormax)、平均值(errormed)和标准偏差(std)。

表4 截止时间测试的实验结果Tab.4 Experiment results of deadline test
表4 实验结果显示,放宽截止时间为基准测试时间的20%时,不会出现违反截止时间的情况出现,当资源充足时,能够严格地控制任务的完成时间在截止时间之内。当设定截止时间为基准测试时间时会出现违反截止时间现象,但是整体的平均误差控制在1%左右。实验结果还表明在调度计算密集型任务时的效果要比调度数据密集型任务时的效果更好,这是由于计算密集型任务对CPU 资源更为敏感。
3.2 抢占式任务调度实验结果
为了描述抢占式任务调度的资源分配过程,提交Sparkperf 中的aggr-by-key 作为短作业,SparkBench 中的PageRank作为长作业,模拟出实际生产中抢占式调度的场景。
实验结果如图4 所示,图4(a)是作业A 单独运行时的资源利用情况,图4(b)是提交任务A 抢占任务B 时两个应用的资源分配情况。结果显示优先级高的任务能抢占低优先级的任务,当抢占任务完成之后,被抢占的任务会被分配额外的资源来补偿执行的损失。
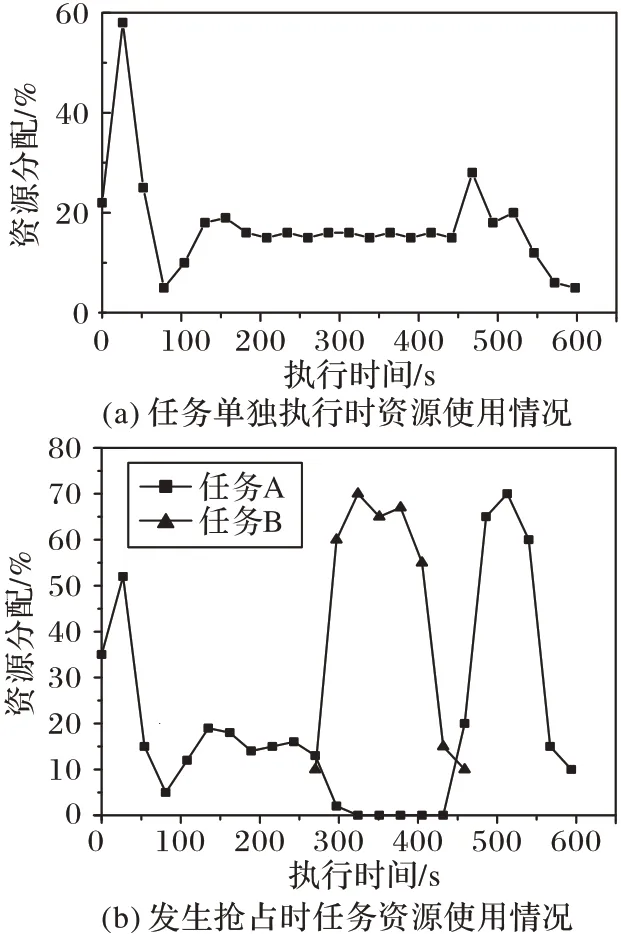
图4 抢占式调度资源分配实验结果Fig.4 Results of preemptive scheduling resource allocation experiments
由图4(b)所示:当任务B 提交后,节点同时接收来自任务A 与任务B 的资源申请,由于任务B 的优先级高,节点会优先分配资源给任务B 来满足其截止时间,此时任务A 的申请得不到响应。当任务B 结束后,任务A 的申请才会得到响应,此时由于与期望执行进度相差很大,任务A 会申请大量的资源来补偿之前执行进度的损失。
与其他的抢占式调度做对比实验结果如图5 所示:基于YARN 调度框架的抢占式调度,在响应延迟以及对长作业的执行进度的丢失都很严重;BiG-C 方法[29]用特有的方式,暂时挂起被抢占的长作业,从而避免了长作业执行进度的丢失,缩短了长作业的执行时间;而本文方法通过额外补偿长作业的模块,使长作业的执行时间更短。

图5 本文方法与其他抢占式方法的执行时间对比实验结果Fig.5 Comparison experimental results of execution time between proposed method and other preemptive methods
3.3 对比实验
经过前面的两个实验,验证了改进后框架动态调度资源的能力,以及本文算法的抢占效果。本实验则进一步与其他传统调度方法对比,模拟生成工作负载,分别在低负载和高负载环境下评估短作业的响应速度以及长作业的执行时间。
3.3.1 工作负载
工作负载使用Spark-perf 生成abk、group-by、sbk 作为短作业。为每个短作业分配4 CPU,3 GB的计算资源,通过配置生成数据集的参数,保证任务在资源充足情况下可以在30~40 s 内完成。从SparkBench 中选择了PageRank、Kmeans、SVM 作为Spark 长作业。为每个长作业分配8 CPU,8 GB的计算资源,通过配置生成数据集的参数,保证任务在资源充足情况下可以在5 min 内完成。在整个实验过程中,长作业被连续提交,它们持续利用了大约60%的集群资源。短作业被多个用户同时提交,在低负载场景下申请大约60%的集群资源,在高负载场景下申请约80%的集群资源。显然集群不足以满足所有任务的资源需求,任务的执行会受到影响。
为了进行调度效果的比较,分别配置以下几种调度方法:
1)先进先出调度(FIFO):程序以先进先出的顺序执行任务,不需要额外设置。
2)资源预留调度(Reserve):YARN 模式下配置了两个队列。为短作业保留40%的集群资源,为长作业队列配置60%的群集容量。
3)抢占式任务调度(kill-base):YARN 模式下capacity scheduler 用于强制队列之间的共享,设置短作业默认40%的资源使用,抢占时可达到80%的资源使用。
4)本文方法:先进行预执行,得到在资源充足情况下应用的平均执行时间,将平均执行时间设置为截止时间(deadline),并将短作业标记为高优先级应用。
3.3.2 对比实验结果及分析
图6 显示了低负载环境下具有不同调度器的短作业和长作业的性能。如图6(a)显示,是不同方法下短作业执行时间的累计分布图,纵坐标是累积分布函数(Cumulative Distribution Function,CDF)。在传统的调度器中,kill-base 与Reserve 都实现了对短作业的快速响应,低负载情况下,预留的集群资源足以为大多数短作业提供服务,短作业的调度延迟几乎为零,只有少量作业会进行排队等待。而本文方法获得了比kill-base 和Reserve 更好的调度效果,由于提供作业计算资源不是由用户给定而是算法计算而来的结果,其结果会比固定分配时更高,能保证任务在给定的截止时间内完成。而传统的调度方法都是给定固定的计算资源,即使是同样规模的输入,执行时间也会有差异。

图6 低负载环境下作业执行时间的实验结果Fig.6 Experimental results of job execution time in low load environment
在高负载下,由于短作业的资源预留低于峰值需求,因此Reserve 调度的效果会降低。图7(a)显示,kill-base 是高负载环境下表现最好的调度器,它通过抢占长作业的资源,始终将短延迟传递给短任务。本文方法也获得了较好的效果,由于优先级的设置,当短作业和长作业同时申请资源时,会优先将资源分配给短作业,但长作业的一部分内存还会保留,所以调度效果不如kill-base。相比之下,FIFO 调度下短作业产生了很大的延迟,由于资源的不足,短作业需要等待长作业完成后才能进行调度。
对长作业来说。FIFO 调度在两个场景下都实现了最好的调度结果,其次是Reserve 调度方法,调度效果都接近FIFO。图7(b)显示,调度结果最差的是kill-base 调度,由于需要始终满足短作业的资源申请要求,即使在低负载情况下也会有长作业被取消。本文方法取得了与FIFO 相近的调度结果,相比于kill-base 的取消长作业释放资源的抢占方式,本文方法会将长作业暂时挂起,等到短作业执行完毕后再将资源重新分配给长作业,并且会补偿挂起时损失的执行进度,使长作业的平均执行时间缩短了35%左右。

图7 高负载环境下作业执行时间的实验结果Fig.7 Experimental results of job execution time in high load environment
实验结果表明,在低负载时,集群资源充足,采用本文方法,短任务能被严格地控制在截止时间内完成以满足服务质量。相较于其他的抢占式调度方法,本文方法在高负载环境下能有效地减轻被抢占作业受到的影响。
4 结语
在云计算环境中进行任务调度时,一个重要的问题就是如何调度在共享集群中具有不同服务质量要求的应用使响应时间和任务完成时间达到最小。本文通过修改Spark 调度框架,开发了基于截止时间的调度接口,提出并实现了一种基于动态资源调度的抢占式任务调度方法。通过实验验证了算法能实现基于优先级的抢占式调度,并且能够额外补偿被抢占任务的执行进度。由于实验环境限制,本文简化了在应用执行过程中影响应用完成时间的诸多因素,只对内存和CPU 等计算资源进行了调度,但在实际生产环境中,分配的资源还包括例如网络带宽、磁盘IO、缓存等是本文没有考虑的。在未来的工作中,将尝试使用容器技术对磁盘IO 和网络带宽进行限制,并综合考虑这些因素对应用执行的影响,进一步提高算法的调度效果。
猜你喜欢
中学生数理化·八年级物理人教版(2022年4期)2022-04-26
读者·校园版(2019年24期)2019-12-10
电脑报(2019年31期)2019-09-10
电脑报(2019年12期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国计算机报(2018年30期)2018-11-12
小朋友·聪明学堂(2015年8期)2015-11-30
电脑爱好者(2015年21期)2015-09-10
计算机世界(2009年34期)2009-11-17
计算机世界(2009年29期)2009-08-14
