
引入通信与探索的多智能体强化学习QMIX算法
2023-02-03 03:02邓晖奕李勇振尹奇跃
计算机应用 2023年1期
邓晖奕,李勇振,尹奇跃
(1.北京建筑大学 电气与信息工程学院,北京 102616;2.厦门大学 自动化系,福建 厦门 361002;3.中国科学院 自动化研究所,北京 100190)
0 引言
多智能体系统(Multi-Agent System,MAS)是在同一个环境中由多个交互智能体组成的系统,该系统常用于解决独立智能体以及单层系统难以解决的问题。如今,现实世界大规模决策问题的建模依靠单智能体的解决方案难以满足各种资源与条件的限制,MAS 因其较强的实用性和扩展性,能够将大而复杂的系统建设成小而彼此互相关联的易于管理的系统。自提出以来已经在诸多领域都得到广泛应用[1]。
强化学习(Reinforcement Learning,RL)作为机器学习的一类,它是为了描述和解决智能体在与环境的交互过程中以最大化奖励为目标来学习策略的问题[2]。近年来,随着科技的发展,计算能力与存储能力大幅提高,深度学习在诸多领域取得显著成就。深度学习和强化学习的结合就在此背景下应运而生,产生了深度强化学习(Deep Reinforcement Learning,DRL),同时也成为众多学者的热门研究对象,它将感知、学习、决策汇集到一个架构中,实现了从输入到执行动作“端到端”的感知与决策,并在游戏、机器人等领域取得了较大的突破[3-5]。
DRL 的巨大成功推动了多智能体领域的发展,研究人员为了解决环境中的众多复杂的问题开始尝试将DRL 方法和MAS 结合在一起,这就产生了多智能体深度强化学习(Multiagent Deep Reinforcement Learning,MDRL),科研人员研究了众多应用于各类领域的算法、规则、框架。在机器学习甚至人工智能领域中,MDRL 由于其具有极高的研究价值正在成为当下的研究热点之一[6]。
多智能体技术在各个领域深入应用的同时,也遇到了诸多瓶颈,典型如环境的非平稳性问题、非完全观测问题、多智能体训练模式问题、多智能体信度分配问题、过拟合问题等。非平稳性问题指的是在训练过程中因智能体不断改变其策略从而导致的多智能体环境的非平稳性。在单智能体强化学习中,智能体只需要根据自身动作和环境交互即可完成学习任务;而在多智能体环境中,每个智能体不仅要考虑自身动作对环境造成的影响和与之带来的回报,还要观测其他智能体的行为及其影响,由于这些交错复杂的交互和相互联系过程使得环境一直在动态地变化;同时,智能体间动作及策略的选择相互影响,这使得回报函数的准确性降低,一个良好的策略会随着学习过程的推进不断变差。环境的非平稳性大幅增加了算法的收敛难度,降低了算法的稳定性,并且打破了智能体的探索和利用平衡[7]。
为解决多智能体深度强化学习中的环境非平稳问题,许多学者基于深度Q 学习算法提出了多种改进方案:Castañeda[8]提出了两种改进方法:一种是通过改变值函数的方式;二是改变回报函数的方式分别提高智能体之间的相关联性。Diallo 等[9]将并行运算机制引入到深度Q 学习中,使多智能体可以在非平稳环境中收敛。Foerster 等[10]为了使算法适用于多智能体非平稳环境改进了记忆库机制,同时提出了两种方法:一是为标记记忆库中重要的数据,丢弃之前的不适应环境的数据;二是为每个从记忆库中取出的数据做时间标记,从而提高训练质量。目前针对该问题的解决方法种类繁多,也是未来多智能体强化学习领域研究方向的热点之一。
1 相关工作
1.1 多智能体深度强化学习
在多智能体系统中,每个智能体的策略不仅受自身的策略动作和环境的反馈奖励所影响,也会受到其他智能体的行为和合作关系的影响。比如在对环境有完全观测能力的条件下,全局状态可以在每个时间步中被获得,然后智能体能够根据相应策略选择执行动作;而当智能体对环境只有局部观测能力时,智能体就只能利用局部观测值并结合自身策略来选择执行动作。智能体之间是合作关系时,所有智能体所获得的奖励相同,它们为一个相同的目标而努力;而当智能体之间是竞争关系时,由于奖励值的多样性会使多智能体强化学习更加复杂。
将强化学习从单智能体系统推广到多智能体系统的两种思路为分布式学习和集中式学习。
分布式学习方法 对每个智能体分别做强化学习算法,对智能体而言,其他智能体被视作环境的一部分。分布式学习又分为独立式学习(Reinforcement Learning Individually,RLI)与群体式学习(Reinforcement Learning in Groups,RLG)。
1)在RLI 中每个智能体有独立的学习过程,它不用关心其他智能体的信息,只需要考虑环境中的信息,拥有极高的独立性,并且智能体个数的变化对学习收敛性影响很小。典型算法如独立式Q 学习(Independent Q-Learning,IQL)[11]算法,其主要思路是将其余智能体直接看作环境的一部分,在智能体学习的过程中每个智能体获得其局部观测值,然后调整每个智能体的策略以达到最大化整体奖励值。
2)RLG 中,智能体状态和动作都是动态组合的,每个智能体的Q 函数表是组合后的映射。与RLI 不同,RLG 中每个智能体都需要考虑其他智能体的信息,所以其状态空间和动作空间都非常大,进而导致其学习速度缓慢,所以此方法只适合智能体很少的情况,并且通常会加入加速算法进行优化。RLG 方法的限制在于其状态和动作空间都会随着智能体个数指数增长,需要花费大量的时间来学习[12]。
集中式学习方法 集中所有智能体的状态空间和动作空间,再使用单智能体强化学习算法训练,输入是整个多智能体系统的信息,输出是每个智能体的动作。随着智能体的增加,势必会造成状态空间和动作空间过大,以致于无法进行有效的探索和训练[13]。
目前多智能体深度强化学习算法常用的结构“集中式训练-分布式执行”(Centralized Training with Decentralized Execution,CTDE)结合了两者的思路,相关概念及框架叙述如下。
1.2 CTDE框架与QMIX算法
集中式训练指的是在训练中使用联合动作行为值函数对智能体进行训练,即将所有智能体看作一个整体,并且在训练时,每个智能体可以无限制地获取其他智能体的信息;而分散式执行是指智能体只能根据自身观测到的部分信息以及其他智能体的有限信息来选择执行动作。由于多智能体强化学习常在模拟环境中进行训练,因此实际硬件条件不会对智能体之间的通信造成限制,这也使智能体更容易获得额外的环境状态,有利于CTDE 结构的实际应用。也正因为其结构拥有许多优势,使它被认为是多智能体强化学习领域的典型学习结构之一。
2017 年,为了解决多智能体信用分配(Multi-Agent Credit Assignment)问题,DeepMind 团队提出了一个基于CTDE 框架的值分解网络(Value Decomposition Network,VDN)[14],其主要思路为每个智能体根据自己对团队的贡献,优化各自的目标函数。具体是把整体值函数Qtot(τ,u),τ∈T进行分解,其中T表示联合状态-动作历史,u表示联合动作。分解将会得到每个智能体a的值函数Qa(τa,ua;θa),并将其作为各智能体执行动作的依据,其中θa为每个智能体值函数的网络参数。其优点在于结构简洁,分解得到的Qa可以使得智能体可以根据自己的局部观测值选择动作来执行分布式策略:

对于一些简单的任务,VDN 算法十分高效,但同样存在对于一些大规模的多智能体优化问题,它的训练效果会大打折扣的缺点。根本原因在于VDN 只是以简单的求和方式分解Qtot函数,缺少值函数分解的有效的理论支持,使得多智能体Q 网络的拟合能力很受限制。
QMIX 算 法[15]则 在VDN 基础上采用一个混合网络(Mixing Network)替代VDN 中直接求和的操作,该网络对单智能体局部值函数进行合并,并在训练学习过程中加入全局状态信息辅助来提高算法性能:

为了能更好地利用全局状态信息,QMIX 算法采用一种超网络(Hyper Network),将状态作为输入,输出为混合网络的权值及偏移量;同时为了使权值不小于零,采用一个线性网络以及绝对值激活函数保证输出不为负数。使用相同但没有非负性的约束的方法处理偏移量,混合网络最后一层的偏移量通过两层网络以及ReLU(Rectified Linear Unit)激活函数得到非线性映射网络。由于状态信息是通过超网络混合到Qtot中的,而不只是简单地输入到混合网络中,所以它的优势在于,如果输入的状态值均大于零,那么就无法充分利用状态值来提升算法性能,等于舍弃了一半的数据量。相关实验[15]表明,在星际争霸Ⅱ学习环境(StarCraftⅡ Learning Environment,SC2LE)中的多个场景中,QMIX 算法比VDN 算法表现更优。
2 本文模型与算法
2.1 算法结构
本文在QMIX 算法的基础上引入通信模型以实现多智能体间的有效交流,同时引入好奇心机制,使智能体在稀疏奖励的环境中有更好表现。算法结构如图1 所示。

图1 算法结构Fig.1 Algorithm structure
改进后算法引入智能体网络[16]替代QMIX 结构中的Qa网络,新的Qi(ot,ht-1,·)定义为:

其中:ot、ht-1分别表示智能体在t时刻的观测值和智能体网络隐藏层历史信息,表示智能体j在t时刻的GRU 模块输出结果[16]。
这样做能有效提高智能体训练时有效信息的提取速度和利用率;同时,改进算法在智能体执行动作过程中加入智能体通信协议算法[16],让智能体有条件地交流信息,虽然这种做法与传统的“集中式训练-分布式执行”结构有所冲突,但是在保持整体结构相对完整的情况下,在执行过程中使智能体间主动且有选择地相互通信,能够消除环境所带来的噪声和有效信息量较少的信息,得到更好的训练效果。
为了在智能体之间通信时限制一个智能体从其他智能体得到信息的方差,算法引入了信息编码器的输出fenc(·)作为损失函数的一个额外损失项,算法损失函数定义为:

在这里it、rt分别表示t时刻的内在奖励和外部奖励,γ∈[0,1]为折扣因子,θ-为目标网络参数。
同时,为了进一步缓解环境非平稳性问题及其所带来的智能体探索与利用平衡问题和提高算法在稀疏环境中的鲁棒性,改进后算法引入好奇心机制即内在奖励it,其原理是当智能体访问新颖状态时予以鼓励,以此提高智能体探索未知状态的可能性,从而帮助智能体找到潜在的更好的状态。加入内在奖励后的算法奖励函数定义为:

本文算法使用“端到端”的方式进行训练,训练过程中采用在线网络与目标网络两个神经网络的方式训练。目标网络用于计算Q现实,在线网络用于计算Q估计。通过最小化Q现实与Q估计的差值训练神经网络参数,使其更逼近于真实的Q函数。
训练深度神经网络时,通常要求样本之间是相互独立的,这种随机采样的方式大幅降低了样本之间的相关性,使算法更加稳定。基于这种原因,本文算法也采用随机采样的方 式,从记忆库中随机抽取小批量样本(st,ot,ut,rt,st+1,ot+1),因此根据状态s选取的相关轨迹也是具有随机性的,这保证了算法的稳定性。算法伪代码如下所示:
输入 训练轮次N,每轮训练的长度K,观测值的步数M。
输出 智能体网络参数θ。

2.2 VBC通信模型
在多智能体强化学习中,所有智能体在一个共享的环境中相互交流,但每个智能体只能获得环境的部分观测值,同时每个智能体需要基于这些部分观测值和来自其他智能体的间接或直接的交流信息作出决策,这就导致复杂的交流模型面临巨大的挑战[7]。特别是在训练过程中,每个智能体都在动态地调整策略,这将造成环境的非平稳性。与此同时,每个智能体可能会被其他智能体的行为所影响从而使自身策略过拟合。为了缓解此问题,本文采用了基于方差控制的有效交流通信模型(Variance Based Control,VBC)算法[16]对QMIX 算法进行改进。
VBC 算法的思想是:让智能体在执行过程中只采用有效信息进行交流。具体做法是通过在交换的信息的方差上插入一个额外的损失项来提取信息中有意义的部分。这样可以提高对有效信息的提取速度和利用率,有利于每个智能体的训练;此外,与以前的传统的通信模型不同的是,VBC 不需要一个额外的决策模块来动态地调整通信模式,而是每个智能体先根据其自身信息作出初步决定,只有当它对这一初步决定的置信水平较低时才启动通信,这能大幅降低模型的复杂性;同时,在收到通信请求时,智能体只在其信息有效时才回复请求。因为只在智能体之间交换有效信息,VBC 算法既提高了智能体的性能,又大幅降低了执行过程中的通信开销。最后,从理论上证明,算法可以保证训练的稳定性。


2.3 好奇心机制
强化学习是通过最大化策略的预期收益来实现的。当环境中存在稠密奖励时,强化学习可以通过随机抽取行动序列来获得奖励,这种方法十分有效,但当奖励变得稀疏且难以找到时,往往会难以获得奖励。在现实中,为多智能体强化学习的每项任务都设计密集的奖励函数往往不切实际,所以有必要采用定向方式探索环境的方法[17]。为了在奖励稀疏环境下帮助智能体探索潜在的更好的状态,本文引入了好奇心(Curiosity)机制对算法进行改进。
本文采取了随机网络提炼(Random Network Distillation,RND)[18]算法,RND 算法是一种基于预测的奖励方法,其思想是让智能体从经验中学习下一个状态的预测模型,并使用预测误差作为内在奖励来增强智能体的“好奇心”,激励它们探索潜在的未知状态。具体而言,RND 算法设计了两个神经网络计算内在奖励:一个是固定且随机初始化的目标网络,它设定了预测问题;另一个是根据智能体收集的数据训练的预测网络。其中目标网络f:O →Rk将智能体观测值ot+1作为输入且在学习过程中不进行更新,预测网络:O →Rk同样将ot+1作为输入,在学习过程中通过梯度下降进行训练,与目标网络f进行比较来最小化均方误差并更新其网络参数。
在学习过程中,随机初始化的目标网络将会被提炼成一个经过训练的网络,当遇到与预测网络所训练的状态不同的新状态时,产生的预测误差将会变得更高,智能体内在奖励it也随之变大,以此来激励智能体采取不同的动作与环境交互。RND 算法伪代码如下所示:

3 实验与结果分析
3.1 实验环境
实验所采用的计算机硬件配置为NVIDIA Geforce1070 GPU,32 GB RAM,Intel Core i7-9700F CPU,操作系统为Windows 10。使用Pytorch 作为搭建算法的代码框架,采用PyCharm 2021.1.1 x64 作为仿真工具,在星际争霸Ⅱ学习环境(SC2LE)下对算法进行模拟测试。
3.2 实验参数设置
所有智能体的动作空间由一组离散的动作组成:Move(Direction)、Attack(EnemyID)、Stop 和 Noop。Move(Direction)表示朝某个方向移动,其中方向只有东、南、西、北4 个选项;Attack(EnemyID)表示攻击ID 为EnemyID 的单位,值得一提的是,只有敌人在攻击范围内才能执行该动作,这种做法有利于问题的离散化,并可以禁止使用游戏中一边攻击一边移动的动作;Stop 和Noop 两个动作分别表示停止行动和不采取行动。此外,实验中单位在空闲时将禁用以下动作:对敌人射击作出反应和对处在射程内的敌人进行射击。这么做的原因是可以迫使智能体进行探索,从而找到最优的战斗策略,而不是依赖SC2LE 中内置的工具。
环境的部分可观察性体现在引入了单位射击范围,它限制了智能体接受超出范围的友方智能体或敌方单位的信息。此外,智能体只能观察到在视野中活着的单位信息,不能分辨状态为死亡和不在视野范围的单位。
在每个时间步中,智能体获得的联合奖励等于对敌方单位的总伤害量。此外,智能体击败每个敌方单位都能获得100 分的奖励,如果击败所有敌军,能获得200 分的奖励。最后,为了方便比较,将所获得的奖励转换为上限为20 的奖励值。
在SC2LE 中,每个智能体控制一个单独的军队单位。为了验证算法有效性,本实验按照难度考虑了6 个不同的战斗场景:简单(3m、2s3z),较难(3s_vs_4z、3s_vs_5z)和极难(5m_vs_6m、6h_vs_8z),并使用两种算法加以验证。为了衡量每种算法的收敛速度,实验将每隔200 个epsode 停止训练并对训练模型进行保存,每隔5 000 或10 000 时间步运行20个episode 测试模型胜率。
3.3 实验结果与分析
由于场景的难度不同,所以训练的时间步数也各不相同。在每个场景中每种算法训练了3 次,图2 为每种算法在不同场景下训练的平均胜率,其中阴影部分为其置信区间(95%)。

图2 两种算法在6个场景下的胜率对比Fig.2 Win rates of two algorithms under six scenarios
实验结果表明,在简单场景中,QMIX 算法与改进算法都能收敛到较高的胜率,但改进算法在执行过程中使智能体间主动且有选择地相互通信,能够消除环境所带来的噪声和有效信息量较少的信息,所以算法在收敛速度和稳定性上有更好的表现;在较难场景中,在相同的训练步数中,改进算法训练胜率高于QMIX 算法;在极难场景中,智能体难以击败对手,奖励也难以获取,在这种奖励较为稀疏的环境且训练步数有限的情况下QMIX 算法无法训练有效的智能体,相比之下,改进后的算法引入了好奇心机制,智能体根据下一步观测值来计算出内在奖励,使智能体具有一定的探索性,在奖励较为稀疏的环境下能够提高算法的收敛速度。
3.4 消融性实验
为了进一步验证算法的有效性,实验将改进算法分别与单独引入通信的VBC 算法和单独引入好奇心机制的RND 算法进行对比,同时,给出原始的QMIX 算法训练结果以作为基线参考。
具体实验参数设置与3.3 节设置基本一致,其中不同的是此次消融性实验在两个极难的战斗场景(corridor,6h_vs_8z)下进行训练,每隔10 000 时间步运行20 个episode 测试模型胜率,同时,为了衡量每种算法的收敛速度,实验将每隔200 个episode 停止训练并对训练模型进行保存。
从图3 实验结果可以看出,当实验环境收敛难度较高时,除改进算法外的其他三种算法均不能收敛出很好的效果。在corridor 场景下,QMIX 算法难以训练出有效的模型,相比之下,VBC 算法与RND 算法的实验胜率均有小幅度提升,而改进算法所提升的性能更高,所训练出的智能体可以大概率击败对手;在6h_vs_8z 场景下,RND 算法因其具有一定的探索性,在奖励稀疏的场景中的表现比VBC 算法表现稍好,但在该收敛难度极大的场景中仍可以明显地看出,改进算法结合了两者特点训练出了性能更高的模型。总之,相较于原始的QMIX 算法,在极难环境中,引入通信的VBC 算法与引入好奇心机制的RND 算法表现更好,但所提升的幅度有限,而改进算法可以训练出更有效的模型。
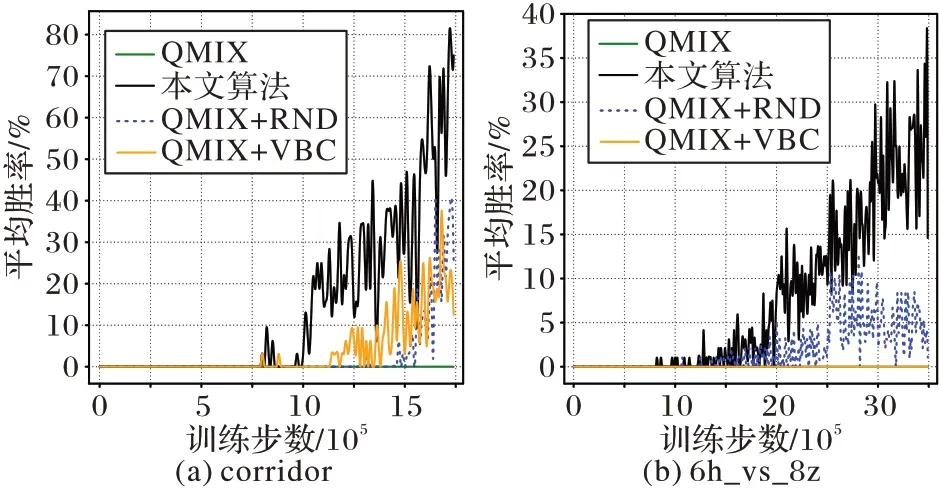
图3 两个极难场景下四种算法的胜率对比Fig.3 Win rates of four algorithms under two super hard scenarios
综合3.3 节的实验结果来看,相较于QMIX 算法,本文改进算法因引入了通信机制,加强了智能体间有效信息的交流,具有更好的性能和稳定性。此外,在VBC 算法难以收敛的奖励稀疏环境中,本文改进算法因引入了好奇心机制,提高了智能体探索未知状态的可能性,所以仍可以训练出更为有效的模型,算法性能更好。
4 结语
本文针对强化学习中环境的非平稳性问题,提出了一个基于多智能体间通信与探索的QMIX 改进算法。环境的非平稳性会增加算法的收敛难度,降低算法的稳定性,并且打破智能体的探索和利用平衡。本文提出的改进算法分别从智能体间通信和探索的两个角度出发对QMIX 算法进行改进,缓解环境非平稳性问题。实验结果表明,与原算法相比,算法性能更高。在未来研究中,将进一步在更复杂的场景下进行算法性能的验证。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
小学生作文(低年级适用)(2018年3期)2018-04-17
少儿科学周刊·少年版(2015年4期)2015-07-07
