
基于时域波形的半监督端到端虚假语音检测方法
2023-02-03 03:02黄泽鑫张聿晗付中华高建清刘俊华
计算机应用 2023年1期
方 昕,黄泽鑫,张聿晗,高 天*,潘 嘉,付中华,高建清,刘俊华,邹 亮
(1.语音及语言信息处理国家工程实验室(中国科学技术大学),合肥 230027;2.科大讯飞股份有限公司 AI研究院,合肥 230088;3.中国矿业大学 信息与控制工程学院,江苏 徐州 221116;4.西安讯飞超脑信息科技有限公司,西安 710000)
0 引言
文献[1-2]中已将声纹识别分支下的自动说话人验证(Automatic Speaker Verification,ASV)系统应用到身份识别系统等领域。随着语音技术的发展,特别是高效语音合成、语音转换等算法的提出,高质量的虚假语音让人很难分辨真伪。Das 等[3]针对ASV 系统的各种欺骗攻击进行概述,认为现有的ASV 系统的安全性面临极大挑战。虚假语音攻击在诈骗、向公众传播负面信息等方面具有潜在威胁,因此研究虚假语音攻击检测技术具有迫切需求和重大意义。
虚假语音产生方法主要包括逻辑形式以及物理形式。逻辑形式包含有语音合成、音色转换等技术,这类伪造方式通常是通过参数合成、深度学习模型等生成声学特征,并通过声码器制造出虚假的语音信号进行攻击;物理形式包含有捕获和重放语音信号等技术,这类伪造方式通常使用录音设备在暗处对目标人进行录音,再由扬声器播放目标人的录音进行攻击。自动说话人确认欺骗攻击与防御对策挑战赛(Automatic Speaker Verification spoofing and countermeasures challenge,ASVspoof)在2015 年第一次举办,文献[4-5]中概述了最近两届ASVspoof 挑战赛的相关结果,学术界对假音检测任务研究的热度也越来越高。虚假语音检测任务主流方法是对语音信号进行预处理以后,提取人工设计的相关声学特征并利用分类器判断是否为真实语音,即利用测试语音在检测系统上的得分与某个阈值比较的结果,判断测试语音的真假。一般来说,语音相关的任务都需要在前端提取声学特征,传统的声学特征包含有幅频特征(如对数频谱幅度特征和残差对数频谱幅度特征);相频特征(如相对相移特征、群延迟特征、修正群延迟特征、基带相差特征等)[6]。另外,在许多语音处理任务(例如语音识别、说话人识别)中被广泛使用的倒谱特征(如线频倒谱系数特征、梅尔倒谱系数特征,以及余弦正则相位倒谱系数特征与修正群延迟滤波器组倒谱系数特征等)和局部二值模式特征、i-vector 特征,以及调制特征等也被尝试用来解决虚假语音检测任务[7]。
现有技术针对特征提取进行了大量的实验,尝试寻求一种能够有效区分虚假语音与自然语音的声学特征。Patel等[8]在首届ASVspoof 挑战赛提出了一种基于耳蜗滤波器倒频谱系数和瞬时频率变化相结合的检测器,用于检测自然语音和欺骗语音。Witkowski 等[9]在ASVspoof2017 年的挑战中提出了基于微调的常数Q 倒谱系数特征的检测器,尽管该系统仍不能完全检测出欺骗语音,但对未知语音数据表现出更强的泛化能力。一些研究发现相比静态声学特征,动态声学特征更适用于虚假语音检测任务。近年来,基于深度神经网络(Deep Neural Network,DNN)的特征提取算法被应用于多个领域并取得成功。Tom 等[10]假设随着录音和回放设备的进步,传统特征的辨别能力下降,而采用端到端DNN 直接建模声谱图来代替手工的特征提取,实验结果表明将原始波形应用于虚假语音检测较为有效。Zeinali 等[11]采用一个具有单通道对数功率谱图特征的VGG(Visual Geometry Group)网络,在开发集上表现优异,然而在未知的测试集上的性能显著下降。Jung 等[12]提出了一个端到端系统,由两个深度神经网络组成,一个前端用于说话人原始波形嵌入特征的提取,另一个用于后端分类。
现有的假音检测方法性能仍有待提高,面临以下问题:1)人工设计的特征往往有较强的针对性,在面对不同领域的虚假语音时,检测器效果往往不能令人满意。多数研究基于频域人工特征而设计的卷积神经网络不能对语音的时域特性进行捕捉,训练过程中缺少局部特征之间的信息整合,可能造成关键性鉴别信息丢失,从而影响检测效果。2)随着虚假语音生成方式的多样化和复杂化,训练模型所需的大量有标注样本较难获取,以ASVspoof2019 为例,模型的生成需要50 224 条真音和已知类型的假音数据。现有语音数据库中存在大量无标注样本,仅利用有标注的数据训练模型会导致检测器在面对训练集域外的攻击时泛化能力显著下降。为了解决以上问题,本文提出一种基于时域波形的半监督端到端虚假语音检测方法,主要工作内容如下:
1)提出一种以原始语音为输入的一维卷积时域网络结构,该结构中的双路径Res2Net(Dual-Path Res2Net,DP-Res2Net)基础块能够扩大感受野,整合局部信息,从而提升模型性能。该方法不提取人工声学特征,而使用原始语音采样数据作为输入,最大限度地保留了数据中的关键鉴别信息。
2)将无标注语音数据加入训练过程,利用标记数据和额外的未标记数据来增强检测器领域迁移能力,扩大训练数据域的多样性,从而使模型在面对未知的虚假语音攻击时仍具有一定的有效性。实验结果表明本文方法与仅利用标注数据训练的模型相比,泛化能力有较大提升。
3)将基于角度距离的损失函数与交叉熵损失函数结合,以AM-softmax 损失函数主导训练,以Cross-entropy 伪标签损失函数辅助训练,使类内距离更小且学到的深层表征更有区分性,从而提高模型泛化能力。
1 系统设计
本文提出的系统及训练策略主要包含三个方面:一是时域网络结构,整个网络由浅层卷积模块、特征融合模块、全局平均池化组成,保留原始语音信息的完整性并增大了感受野,能大幅提升模型的泛化能力;二是结合基于附加边际(Additive Margin,AM)的softmax 损失函数[13],增大类间距离、减小类内距离;三是结合交叉伪标签半监督训练方法[14],利用未标注数据训练模型,以进一步提高模型泛化能力。
1.1 时域网络结构
受文献[15-16]中关于残差网络(Residual Network,ResNet)、Res2Net 相关研究的启发,本文结合最近的双路径DP(Dual Path)-Res2Net 结构[17],提出一种基于时域波形的端到端虚假语音检测方法,其框架如图1 所示。

图1 基于一维卷积的DP-Res2Net结构Fig.1 Structure of DP-Res2Net based on one-dimensional convolution
本文系统的输入为原始语音波形(96 000采样点);浅层卷积模块由数个一维卷积层(Conv1d)、一维最大池化层(Maxpool1d)、一维批归一化层(Batch Normalization,BN)以及带泄露修正线 性单元(Leaky Rectified Linear Unit,LeakyReLU)激活函数组成,可从原始语音信号提取浅层特征;该网络结构的特征融合模块由DP-Res2Net-basic-block和一维最大池化层交替组成,其中,基础块的结构如图2[17]所示。

图2 DP-Res2Net-basic-block结构Fig.2 DP-Res2Net-basic-block structure
每个块的输入经过1 维卷积层后分成4 份,即xi(i∈{1,2,3,4})。除了x4外都经过一个卷积核大小为1 的Ki以及一个卷积核大小为3 的Li卷积滤波器处理,并且xi会加上L(i-1)再送入Ki,计算公式如式(1):

将基础块的输入与融合了z1~z4的特征图相加得到基础块的输出这种双路径的残差式连接增加了可能的接受域,融合了多个特征图的信息,在面对未知的虚假语音攻击方式时可以提高网络的性能。
1.2 损失函数的使用
AM-softmax-loss 在人脸识别以及说话人识别任务中表现较为优异。本文系统引入AM-softmax-loss,并与交叉熵进行融合。其中,AM-softmax-loss 定义如下:

其中:cos为样本i输出特征向量与模型权重向量的余弦角度;m为角度余量;s为尺度因子用以加速收敛;N为当前minibatch 的大小。通过控制角度余量m,来达到使同类相似度比最大的非同类相似度更大的目的。
在测试过程中,此处假设第0 类为虚假语音,第1 类为真实语音。从最后一层全连接层中得到cos,该变量的最大值即为样本i的得分,最大值所对应的索引即为样本i的预测类别。
1.3 训练策略
给定N个标记语音的集合DL和M个未标记图像的集合DU,半监督虚假语音任务旨在通过探索标记和未标记语音来学习判别网络。本文分别利用Kaiming Initialization[18]和Xavier Initialization[19]两种不同的网络初始化对检测网络的参数进行初始化。本文方法由两个并行的检测模型组成:

如图3 所示,这两个网络具有相同的结构,但二者的权重θ1和θ2初始化不同。输入input(x)具有相同的特征处理,score1 和score2 是判别后的置信概率,是softmax 归一化后的网络输出。所用方法逻辑说明如下:

图3 交叉标签半监督训练流程Fig.3 Cross-label semi-supervised training process

这里Pseudo label 是预测的one-hot 伪标签。训练目标包含两个损失:有监督学习损失Ls(Supervised Learning Loss)和半监督学习损失Lssl(Semi-supervised Learning Loss)。Ls是使用两个并行判别网络上标记语音的AM-softmax-loss:

未标记数据上的交叉Lssl为:

整个训练程中的总损失是标记和未标记数据损失的组合:

其中λ是权衡权重。

其中:length为超参数;epoch为当前训练周期。
2 实验与结果分析
2.1 实验数据
本文所用数据集来源于ASVspoof2019 中的逻辑访问Logical Access,LA)和深度伪造(Deep Fake,DF)公开数据集,ASVspoof2019LA 数据集中虚假语音包含文本语音合成以及音色转换等逻辑层面的造假方式。其中,训练集与开发集包含了相同的造假方式(2 种音色转换和4 种文本语音合成),测试集1 则包含了除此之外的其他造假方式。为了进一步测试所提系统的泛化能力,本文引入了其他未知类型的语音数据,如VCC(Voice Conversion Challenge)作为测试集2。数据集具体构成如表1 所示。

表1 实验数据集Tab.1 Experimental datasets
2.2 数据预处理
本文对训练集进行速度扰动处理,从而实现了数据增强。特征使用96 000 时域采样点(16 kHz 进行采样),针对采样点不足和多于96 000 点的样本,采用复制扩充和截取的方式,以保证相同的特征维度。
2.3 与基线系统的对比
本节将本文提出的半监督方法与ASVspoof2021 DF 比赛中官方公布的4 个基线系统进行比较,评价指标为等错误率(Equal Error Rate,EER)。EER 是指错误接受的比例等于错误拒绝的比例时的概率值,对比结果如表2 所示。四个基线系统中,B03 和B04 性能较好,EER 分别为23.48% 和22.38%。本文提出的半监督DP-Res2Net 系统EER 得分为19.97%,相较于官方公布的基线效果有了较大提升。
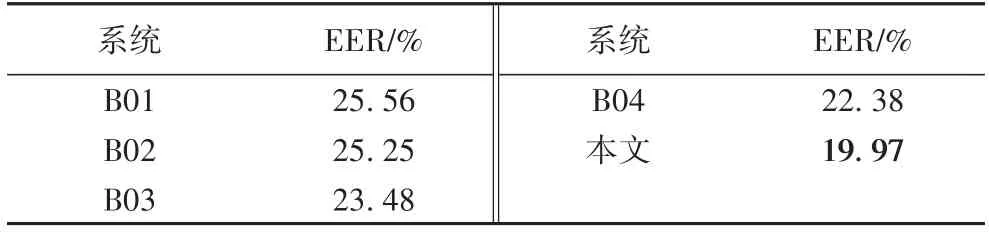
表2 基线系统和DP-Res2Net系统的对比Tab.2 Comparison between baseline systems and DP-Res2Net system
鉴于假音样本较多,本文以1∶1 的真音假音比例在ASVspoof2021DF 数据集上随机采样,并利用t 分布随机邻域嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)对中间特征进行可视化,如图4 所示。其中:bona 代表真音样本,spoof 代表假音样本。可见,针对两类样本,网络所提取的特征分布存在较大差异,特征对真假音检测具有一定的区分能力。

图4 在ASVspoof2021DF数据集上随机采样的t-SNE可视化Fig.4 Visualization of t-SNE randomly sampled on ASVspoof2021DF dataset
2.4 SSL-DP-Res2Net结构有效性
对采用不同训练策略(监督学习和半监督学习策略)的DP-Res2Net 进行对比,结果如表3 所示。从表3 中可以看出,基于半监督策略下训练得到的模型SSL-DP-Res2Net 性能在不同测试集上均有较大提升。从表3 中还可以看出,采用VCC 数据进行测试时,训练数据和测试数据的分布存在较大的差异,本文提出的半监督检测网络取得的EER 为30.60%,虽然弱于使用ASVspoof2021DF 数据为测试集时的性能(19.97%),但显著优于有监督学习方法(38.11%)。可见,本文所提出的基于时域波形的半监督虚假语音检测方法具有较好的泛化能力;然而,检测器性能仍有待提高,跨域的虚假语音检测仍是一项具有挑战性的工作。

表3 不同训练策略在不同测试集上的EER对比 单位:%Tab.3 EER comparison of different training strategies on different test sets unit:%
3 结语
虚假语音攻击在诈骗、向公众传播负面信息等方面具有潜在威胁,研究虚假语音攻击检测技术具有迫切需求和重大意义。本文提出一种不依赖于人工特征的、基于原始音频时域波形的半监督学习端到端虚假语音检测方法,主要包括:其一,提出一种以原始语音为输入的基于一维卷积的时域网络结构,该结构中的DP-Res2Net 基础块能够扩大感受野,实现信息融合;其二,将无标签语音数据加入训练过程,扩大训练数据的多样性使模型在面对未知类型的虚假语音攻击时仍具有有效性;其三,在训练过程中将基于角度距离的损失函数与交叉熵损失函数结合,以AM-softmax 损失函数主导训练,以交叉熵伪标签损失函数辅助训练,以减小类内距离、增大类间距离,提高模型的泛化能力。本文在公开数据集ASVspoof2021 及VCC 上的表现验证了算法的有效性。但本文系统也存在一定不足,在Deep Fake 任务中,系统所表现出的检测性能仍有很大提升空间,如何更好地利用无标签跨域数据是提升检测器性能的关键;另一方面,可以对提取的时域语音特征进一步挖掘处理,提高检测性能。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
军事运筹与系统工程(2019年4期)2019-09-11
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
今日农业(2019年15期)2019-01-03
小说界(2018年5期)2018-11-26
中国港湾建设(2017年11期)2017-12-19
系统工程与电子技术(2016年7期)2016-08-21
西北工业大学学报(2015年4期)2016-01-19
