
基于级联神经网络的型钢表面缺陷检测算法
2023-02-03 03:02于海涛李健升刘亚姣李福龙张春晖于利峰
计算机应用 2023年1期
于海涛,李健升,刘亚姣,李福龙,王 江,张春晖,于利峰
(1.天津大学 电气自动化与信息工程学院,天津 300072;2.河北津西钢铁集团股份有限公司,河北 唐山 064302)
0 引言
型钢是一种经济高效的型材,已被广泛应用在民用和工业领域,是工业生产当中的一种重要钢材。由于环境和生产工艺等因素,型钢生产过程当中总会不可避免地产生各种表面缺陷,若不能及时调整生产过程当中的问题,将严重影响型钢产品的质量和安全系数[1-2]。型钢表面采集的图像具有背景复杂、光照不均匀和噪声等问题,传统的基于机器视觉的表面缺陷检测方法主要采用手工提取特征与机器学习分类算法相结合的分离式设计,过程繁琐,鲁棒性差,缺陷识别效率较低[3]。
深度学习提供了一种端到端的学习范式,并借助其强大的挖掘数据潜在特征的能力,已成为缺陷检测领域的主要方法。Weimer 等[4]将深度卷积神经网 络(Deep Convolution Neural Network,DCNN)应用于工业缺陷检测领域,验证了该方法可以通过大量的训练数据与分层学习策略获得有效的缺陷图像特征,并且展示了出色的缺陷分类效果;邓泽林等[5]构建了基于最大稳定极值区域分析与卷积神经网络协同的疵点实时检测系统,通过预检测与精确检测两级检测机制,能够精确地检测无纺布中的疵点;Chen 等[6]在语义分割模型的基础上,仅使用了少量的训练数据即可对缺陷图像实现特征提取与像素级预测,进而得到表面缺陷轮廓。上述研究均针对提高缺陷识别准确率的问题给出了解决方案,但是生产过程中的型钢运动速度可达5~10 m/s,并且由于缺陷出现位置的不确定性,需要同时采集型钢的各个表面图像。由此产生的大量图像数据对检测方法的实时性要求高,缺陷检测难度大,使得上述方法难以满足要求。
Ren 等[7]提出 Faster R-CNN(Faster Region-based Convolutional Neural Network)的两阶段检测方法,由区域推荐网络(Region Proposal Network,RPN)替代原始分割算法生成候选框,据此得到的特征提取结果送入分类网络,最终实现目标的分类与定位,大幅提升了网络推理速度;Redmon等[8-10]则脱离两阶段目标检测框架,提出了单阶段的目标检测网络YOLO(You Only Look Once)系列,通过顶端的检测网络直接预测每一个提前设定好的锚框的类别、位置信息和置信度,由包含物体中心的锚框负责检测当前物体,这种单阶段检测方法进一步缩短了模型检测的时间;Yin 等[11]采用极限学习机算法作为目标检测的特征提取网络,提出了一种Faster-YOLO 目标检测算法,其检测速度较YOLOv3 模型提高了2 倍。目前,基于上述方法的拓展与应用在保证检测效果的同时通过优化网络结构和预测推理过程提高了网络的检测效率。
经现场实验数据统计可知,型钢生产过程中产生的大量图像数据中,有缺陷图像数量仅占总图像数量的7%左右。有缺陷图像的出现概率低,导致上述的表面缺陷检测算法将计算时间主要集中在了大量的无缺陷图像上,从而严重拖慢了检测环节在整体上的有效检测速度。其中,整体上的有效检测速度指的是一段时间内检测算法处理的有缺陷图像数量除以总时间。因此,本文提出了一种基于级联式网络的型钢表面缺陷检测算法SDNet(Select and Detect Network)用于型钢表面缺陷检测任务。该算法首先在ResNet 为基准的预检测分类网络中引入深度可分离卷积(Depthwise Separable Convolution,DSC)与多通道并行卷积操作,将图像准确分类为有缺陷图像和无缺陷图像;然后,在以YOLOv3 模型为基础的检测网络中引入对偶注意力模块(Dual Attention)和改进空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块,将有缺陷图像送入检测网络当中完成缺陷的分类与定位。SDNet 将缺陷分类算法的快速性与缺陷检测算法的精准定位特性相结合,能够同时兼顾检测的效率与精度。本文的主要工作如下:
1)构建了基于深度可分离卷积的DSC-ResNet 轻量化预检网络,以图像预检测分类任务为驱动,将ResNet 模型中的残差单元替换为多尺度并行残差卷积模块,并利用深度可分离卷积替代原有卷积操作,提升模型分类效果的同时减少了运算量。
2)提出了AA-YOLOv3(ASPP and Attention YOLOv3)缺陷检测模型,基于原有YOLOv3 模型作出改进:在特征提取主干网络中引入改进ASPP 模块保持感受野,提升网络小尺寸物体特征提取能力,并在YOLOv3 的预测网络分支加入了对偶注意力层(Dual Net),增强模型特征聚合与选择的能力,提升模型检测效果。
3)以级联方式融合DSC-ResNet 预检测网络和AAYOLOv3 检测网络,提出了一种型钢表面缺陷快速检测算法SDNet。与原始YOLOv3 模型相比,所提算法显著提高了检测速度和检测精度,适用于型钢表面缺陷的快速检测。
1 SDNet缺陷检测模型
1.1 SDNet总体设计框架
本文提出了一种级联式型钢表面缺陷快速算法——SDNet,由DSC-ResNet 预分类模型和AA-YOLOv3 缺陷检测模型构成,在检测过程中剔除了对无缺陷图像的无效检测,大幅提升了缺陷检测效率。具体地,在以ResNet 为基础网络构建预分类模型时,引入多尺度并行卷积残差模块以提升网络特征提取能力,与此同时采用深度可分离卷积替代标准卷积操作,使卷积过程的运算量极大减少;在缺陷检测模型YOLOv3 的基础上,通过将改进ASPP 模块嵌入主干特征提取网络DarkNet53 的残差模块之前,增强了对于微小尺寸缺陷的特征提取能力,提升了型钢表面缺陷检测效果。预测过程如图1 所示,由工业相机实时采集得到的型钢表面图像送入预分类模型,如果预分类模型判断型钢表面存在缺陷分布,则采用缺陷检测模型进行精确分类与定位。

图1 型钢表面缺陷检测模型Fig.1 Section steel surface defect detection model
1.2 DSC-ResNet预分类模型
普通卷积神经网络在误差反向传播过程中存在梯度消失现象,He 等[12]通过将残差模块引入到卷积神经网络构建了残差神经网络(Residual Neural Network,RNN),有效地解决了深度神经网络模型训练困难的问题。ResNet18 是ResNet 浅层网络的一种实现形式,其残差块使用两个3×3 卷积和跨层连接,相较于LeNet、AlexNet 等经典卷积神经网络,分类准确率更高[13-14]。残差网络定义如下:

其中:H(x,wh)为非线性层,x为输入特征,wh为特征层参数;y为输出特征,由输入引入的短连接与非线性层的输出相加得到。
然而,与经典神经网络模型类似,ResNet18 采用的标准卷积使用多通道特征融合采样方式造成了网络参数量过大、计算效率较低等问题,不利于目标检测的快速性与实时性。因此,本文在以ResNet 为预分类网络的基础上作出改进。该模型最终将特征提取结果经过最大池化层与全连接层,分类结果由softmax 函数将输出映射为(0,1)。值得注意的是,考虑到型钢图像当中大部分属于背景区域,最大池化有助于输出中显著区域部分特征在训练过程中得到最大响应[15-16]。最大池化输入特征X的尺寸为m×n、卷积核尺寸p×q、步长为1 时,最大池化计算过程如下:

当前最大池化输出特征层Y尺寸为g×h,经过前向传播与误差计算可得:

误差对最大池化输出Y的梯度∇e(Y)为:

则误差对输入层X的梯度计算过程为:

可见,包含最大池化层的神经网络的误差反向传播过程只针对输出特征图当中最大响应的权重参数进行更新,这样的操作使图像当中的显著性区域受到更多关注。
一般的ResNet 模型随着残差网络深度逐渐加深而导致卷积运算过程中的感受野不断增大,难以提取小尺度特征。针对上述问题,本文改进了ResNet 中的残差单元ResBlock,如图2 所示。输入特征将分别经过1 × 1、3 × 3、5 × 5 三种不同的卷积核对特征层进行并行卷积,分别得到在不同感受野上的特征输出层F1、F2、F3,最后经过特征维度拼接得到ResBlock 的输出Oresblock。

图2 DSC-ResNet框架Fig.2 Architecture of DSC-ResNet
拆分-合并拓扑策略在一定程度上能够获得分类精度的提升,但是随之而来的是参数规模的指数级上升[17],因此本文引入DSC 替代普通模型中的标准卷积操作[18-19]。深度可分离卷积的过程如图3 所示,它将普通卷积分为逐通道卷积和点向卷积。如逐通道卷积过程所示,各通道之间相互独立,采用与输入特征层通道数相同的卷积核分别对每一层特征层卷积,该计算过程忽略了通道之间的特征融合,因此在图3 中使用点向卷积,将中间输出结果经过1×1 的卷积核进行卷积运算,完成深度方向的信息聚合,得到输出特征层。

图3 深度可分离卷积Fig.3 Depthwise separable convolution
1.3 AA-YOLOv3缺陷检测模型
YOLOv3 将缺陷定位和分类集成在单一阶段的神经网络中,输入图像经过一次推断,便能同时得到图像中所有缺陷的位置和其所属类别,大幅提升了检测速度。该模型主要由特征提取模块BackBone、特征融合模块Neck 和检测目标输出模块Head 三部分组成。Backbone 模块使用基于残差网络的Darknet53 作为特征提取主干网络。Neck 模块使用金字塔结构将不同特征提取阶段的输出进行拼接,实现了多层次特征信息的有效整合,并将融合特征图输入到Head 模块,最终得到3 种不同尺度特征预测图像中的目标类别、位置和置信度。在预测网络中将输出特征图划分为S×S网格,每一个网格预测B个锚定框,每一个锚定框的置信度Con为:

如果当前网格包含目标中心,即Pr(Obj)=1,那么:
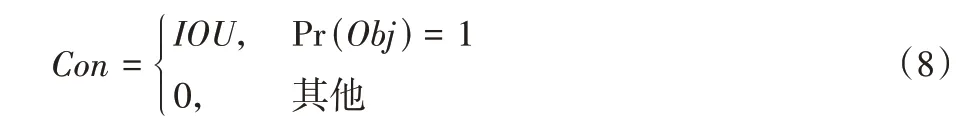
当前网格包含的物体属于某一类别的条件概率为Pr(classi|Obj),那么包含特定类别物体的概率为条件概率与置信度的乘积:

YOLOv3 通过引入了空间金字塔拓扑结构有效地融合特征提取过程中不同层次的输出结果,增强了对于图像的细节信息和全局信息的理解,但仍存在少量目标漏检现象[20]。这是由于在YOLOv3 的主干特征网络当中随着特征层数的加深,卷积操作使得特征层上的感受野不断增大,导致部分缺陷检测丢失。另外,在预测网络当中并未选择性地聚合来自各层级的特征,大量冗余特征的存在将导致网络预测效果下降。因此,在YOLOv3 模型结构中作出两点改进:在主干特征提取网络当中加入改进ASPP 模块;在预测网络中的3个预测分支加入对偶注意力模块(Dual Attention),提出了AA-YOLOv3 模型,如图4 所示。

图4 AA-YOLOv3模型结构Fig.4 Architecture of AA-YOLOv3 model
Darknet53 主干特征提取网络中,将改进ASPP 模块分别置于每一部分残差模块的最前端,增加特征提取网络感受野的灵活性,从而改善小目标物体的检测能力缺失的问题。如图5 所示,改进空洞空间金字塔池化结构包含两部分:第一部分由多扩张率空洞卷积和最大池化组成;第二部分针对原有ASPP 模块,对输入特征图增加了最大池化分支以及1×1卷积部分的同时添加了残差连接操作,以提取更加丰富的特征信息。

图5 改进空洞空间金字塔池化模块Fig.5 Module of improved ASPP
相较于普通卷积需要降采样增加感受野,空洞卷积在保持空间分辨率的前提下增大了特征图的感受野,有效解决了由于空间分辨率降低导致的信息丢失问题;同时,通过设置不同的空洞卷积扩张率,可以动态捕获多尺度上下文信息,有利于强化视觉检测任务中的小目标特征提取能力。ASPP模块分别加入扩张率为1、3 和5 的空洞卷积,通过并行的空洞卷积操作和特征融合组成空洞空间金字塔池化结构。空洞卷积在普通卷积的基础上加入扩张率参数d用来表示空洞数。普通卷积的扩张率默认为1,空洞卷积的卷积核根据设定的扩张率进行膨胀。设空洞卷积的卷积核大小为k,扩张率为d,则空洞卷积等效的卷积核大小k*计算式为:

改进的空洞空间金字塔池化利用不同扩张率的空洞卷积以及最大池化操作,得到基于多种感受野的特征图,从多尺度角度进行特征提取和学习训练,同时通过残差分支使模型在不丢失输入特征图的基础上聚集高层语义信息,提升了型钢表面多尺度缺陷的检测性能。
由于卷积操作会受到局部感受野的限制,在特征提取过程当中缺少了全局信息的聚合过程,导致缺陷识别准确率下降。因此,引入具有全局上下文信息探索能力的对偶注意力模块(Dual Attention)[21],分别在空间与通道两个层面上自适应地聚合长距离信息,增强网络的特征表达能力,从而提升缺陷检测效果,如图6 所示。
在空间长距离注意力部分,通过获取特征图中任意两个位置的特征相似性计算特征权重掩膜。具体地,输入特征图I(I∈RC×H×W)经过3 个并行1×1 卷积分别得到特征嵌入后结果Q1(Query)、K1(Key)、V1(Value),大小均为m×H×W。
Q1和K1分别经过矩阵重塑、矩阵相乘与权重归一化操作之后得到空间位置特征掩膜S,并与经过矩阵重塑后的V1进行相乘并重塑,最终经过1×1 卷积与恒等映射连接,得到空间注意力选择后输出特征Op∈RC×H×W。上述过程计算式为:

其中:Sji为空间位置i对于j的关联性值;OP为空间长距离注意力部分的输出特征;Vj为原位置j的自身特征值。通道注意力部分属于无参数注意力掩膜生成过程,其结构如图6(b)所示。相同的输入特征分别作为K2、Q2经过特征矩阵重塑与矩阵相乘操作后,得到通道注意力掩膜C∈RC×C,最终与V矩阵相乘输出通道特征选择后的Oc,计算式表达如下:

其中:Cji是位于通道索引i的特征对于j的关联性值,空间长距离注意力部分的输出特征为Oc(Oc∈RC×H×W)。
Dual Attention 分别被嵌入在AA-YOLOv3 的3 个预测分支中,输入输出特征图尺寸保持不变,即C×H×W分别为27 × 52 × 52、27 × 26 × 26 和27 × 13 × 13。如图6 所示,由于空间长距离注意力模块的1 × 1 卷积操作将占据大量的内存访问,因此特征嵌入后的Q1、K1和V1的通道数m为3;而Q2、K2和V2则不需要进行特征嵌入操作,因此在矩阵重塑之前与输入尺寸相同为C×H×W。

图6 对偶注意力模块Fig.6 Module of dual attention
2 网络训练
2.1 型钢表面数据集
型钢表面数据集共有1 600 张型钢表面图像,分为有缺陷类型和无缺陷类型。本文所用型钢表面缺陷数据集包含结疤、剥落、划伤和击伤四种缺陷类型用于训练缺陷检测模型,每类缺陷200 张,共计800 张缺陷图像,均为1 024 像素×1 024 像素的BMP 格式单通道灰度图。另外,为了与现场缺陷数据分布相同,数据集包含800 张无缺陷表面图像,用于训练预分类模型。
2.2 损失函数
2.2.1 预检网络损失函数
预检网络训练时,本文采用了具有权值的二值交叉熵函数(Binary Cross Entropy Loss,BCELoss)作为损失函数:

其中:xi和yi表示训练集的数据与标注;f(·)表示预分类模型分类函数;ω1和ω2分别为关于有缺陷和无缺陷两种类别的损失函数权重,具体数值与训练策略在2.3 节展开介绍。
2.2.2 精检网络损失函数
精简网络训练过程中,损失函数分为三部分:Ecoord表示坐标误差,Econ表示目标置信度误差,Ecls表示分类误差。

坐标误差Ecoord采用均方误差(Mean Square Error,MSE)损失函数,具体计算过程为:

2.3 实验设置与评价指标
模型训练过程将型钢表面数据集通过图像垂直翻转、水平翻转、旋转、随机填充等方式将样本量扩充10 倍。在预检模型训练过程当中,采用所有型钢表面数据集图像,学习率设置为0.000 1,二值交叉熵损失函数中的正负样本权重比值为10∶1,使用随机梯度下降算法(Stochastic Gradient Descent,SGD)优化。在精检模型的训练过程中仅使用缺陷图像,数据集按照7∶2∶1 的比例被划分为训练集、验证集和测试集。特别地,为了模拟在工业生产过程中的实际情况,本文在总体表现的测试过程中,将无缺陷图像和有缺陷图像数量比例设为14∶1。实验采用批次迭代训练法,训练批大小设置为32,迭代次数设置为100,动量设置为0.9,权重衰减率为0.000 2,学习率设置为0.001,使用SGD 算法优化。实验在PC 上进行,使用Intel Xeon Silver 4110 CPU,2080Ti GPU。预检模型迭代损失曲线如图7(a)所示,精检模型迭代损失曲线如图7(b)所示。预分类模型和精检模型在训练前期损失均快速下降,预检模型在迭代100 次以后趋于稳定,精检模型在迭代300 次以后趋于稳定。

图7 损失函数迭代过程Fig.7 Loss function iteration process
在预检网络的验证结果中,本文使用了二分类模型的分类精确率以及有缺陷图像的召回率作为预检模型的评价指标。在缺陷检测的实验结果验证中选用多类别平均精度(mean Average Precision,mAP)和每秒帧数(Frames Per Second,FPS)作为模型评价指标。mAP 为模型检测精度评价指标,表示所有缺陷类别的平均预测效果。单类别的评价指标AP 为该类别的PR 曲线下面积。召回率(Recall,R)和精度(Precision,P)的计算中,设置IOU 阈值为0.5,计算式如下:

mAP 的计算式为所有类别AP 值的平均:

FPS 表示每秒可以完成缺陷检测的图像帧数,为模型检测速度评价指标,计算式如下:

式中Tavg表示处理一张图像的平均时间,单位为秒(s)。
3 实验与结果分析
3.1 预检网络结果分析
SDNet 算法的核心思想就是通过预检模型将占比更高的无缺陷图像通过预分类的方式剔除,避免无效运算。因此,预检模型的分类精确率以及正样本召回率对于模型整体检测效果至关重要,只有预检模型拥有足够高的召回率和良好的分类效果,表面缺陷算法SDNet 才能有较好的检测效果。为了观察本文所提出的DSC-ResNet 的分类效果,采用了图像分类中的常用深度学习模型进行对比,分别包括ResNet18、VGGNet[22]、DenseNet[23]和MobileNet[24]。如表1 所示为在相同验证集下5 种模型的分类准确率和针对有缺陷图像的召回率。

表1 不同预分类模型的性能 单位:%Tab.1 Performance of different pre-classification models unit:%
ResNet18 模型在分类效果上与DSC-ResNet 相差较大:ResNet18 网络漏检率(漏检率=1-召回率)为5.74%,分类准确率为94.25%,同等条件下的DSC-ResNet 网络漏检率为1.09%,分类准确率达到97.63%,明显高于原模型。采用了28 层卷积神经网络的MobileNet 同样使用了深度可分离卷积,然而MobileNet 在型钢表面数据集上的分类正确率只有92.35%,漏检率为4.98%,相较于DSC-ResNet,分类正确率下降了5.28 个百分点,说明本文改进的ResBlock 中多尺度并行卷积操作对DSC-ResNet 整体分类效果有着显著的提升。同样地,与VGGNet 和DenseNet 相比,DSC-ResNet 也具有明显的优势。
3.2 精检网络结果分析
3.2.1 消融实验
为分析AA-YOLOv3 检测算法中各改进方法对型钢表面缺陷检测结果的影响,本文设计消融实验来评估对应改进部分的检测效果。具体实验内容以及检测结果如表2 所示。其中,“√”表示使用了对应方法。

表2 AA-YOLOv3检测算法消融实验结果Tab.2 Ablation experimental results of AA-YOLOv3 detection algorithm
算法1(YOLOv3+ASPP)的主要改进在于缺陷检测网络的主干特征提取网络中,通过改进空洞空间金字塔卷积操作有效地保持了特征提取过程中感受野的大小,且提供了更加丰富的特征表示,从而解决了缺陷检测网络中尺寸不变性的问题。因此,相较于原YOLOv3 检测算法,算法1 的平均检测精度提高了4.5 个百分点,表明了空洞空间金字塔的有效性。算法2(YOLOv3+Dual Attention)中,对偶注意力模块主要作用于YOLOv3 预测网络当中的3 个预测分支,增加缺陷位置的特征权重以及抑制背景位置的特征权重,进而提高缺陷检测效果,其平均检测精度相较于原YOLOv3 算法提高了11.2 个百分点,同时检测速度FPS 降低至22.88。综合考虑上述改进方法,本文所提出的AA-YOLOv3 在型钢缺陷检测任务上表现最好,相较于原YOLOv3 算法检测精度提升了13.4 个百分点,同时,检测速度19.51 FPS 仍然可以满足检测要求。
3.2.2 横向对比
为验证本文所提出的AA-YOLOv3 检测算法的有效性,将缺陷检测中常用的深度学习算法进行横向对比,包括两阶段检测算法Faster R-CNN 和单阶段检测算法SSD[25]、YOLOv3、YOLOv5-s。图8 为5 种检测模型在部分缺陷图像中的检测效果。

图8 5种模型的检测效果对比Fig.8 Detection effects comparion of five models
表3 为不同模型检测效果的横向对比,与SSD 和Faster R-CNN 两种模型相比,YOLO 系列模型取得了相对较高的检测准确率。YOLOv3 模型在YOLO 系列模型中的检测效果最差,mAP 值为81.7%,但仍比SSD 提高了11.1 个百分点,比Faster R-CNN 仅低4.5 个百分点。AA-YOLOv3 的平均检测精度为95.1%,与YOLOv5-s 模型90.4%的准确率相比提升了4.7 个百分点,主要因为改进的ASPP 与Dual Attention 使得YOLOv3 模型检测能力提升,从而提高了其在整体数据集上的缺陷检测准确率。

表3 不同模型的横向对比 单位:%Tab.3 Horizontal comparison of different models unit:%
通过分析不同模型针对单一类型缺陷的检测性能,验证各类缺陷的检测特异性。图9 所示为上述五种检测模型在四种缺陷类型上的PR 曲线。可以发现,由于缺陷图像的自身特征表达的不同,导致上述五种模型均对不同类型缺陷的检测结果有明显差别,对于剥落和划伤两种缺陷整体检测效果更好,准确率更高,而对于结疤和击伤缺陷检测准确率则显著下降。但AA-YOLOv3 缺陷检测模型在四种缺陷类型上的检测效果上均优于其他缺陷检测模型,进一步表明了AAYOLOv3 的优越性。

图9 不同检测模型的四类缺陷PR曲线Fig.9 PR curves of four types of defects of different detection models
3.3 SDNet总体表现
为进一步分析该缺陷检测方法的有效性,本文通过改变测试集中缺陷图像占比,并以FPS 为衡量指标进行了充分的实验分析,结果如图10 所示。该实验在测试集图像数量保持不变的情况下改变缺陷图像占比,在不同比例的情况下分别进行了5 次实验,并将平均值标记为三角形,同时上下带状区域表示95%置信区间。该缺陷检测方法的FPS 随着比例增大而增大,同时上升速度减小,逐渐逼近极限检测速度。可见,该方法有效地解决了因缺陷图像小概率发生事件的偶发性而导致的有效检测速度被严重拖慢的问题。

图10 不同缺陷图像占比下的检测速度Fig.10 Detection speed under different defect image ratio
为准确衡量所提出SDNet 模型的检测性能,使用3.2 节中的五种检测模型(Faster R-CNN、SSD、YOLOv3、YOLOv5-s、SDNet)进行横向对比实验。其中,检测速度直接决定其能否满足实时性要求,是本文所提出SDNet 检测模型要解决的核心问题;检测精度由mAP 指标衡量,决定模型能否准确识别并检测到缺陷。5 种检测模型在测试集上的实验结果如表4所示,测试集中无缺陷图像和有缺陷图像的比例设为14∶1。

表4 不同模型的检测速度对比Tab.4 Comparison of detection speed of different models
SDNet 模型检测速度达到了120.63 FPS,为原YOLOv3模型检测速度的3.7 倍,与两阶段目标检测算法Faster RCNN 相比提升了约5.4 倍,同样相较于SSD 和YOLOv5-s 也有着显著的提升,主要原因是本文模型为了模拟实际生产情况,验证集中主要由无缺陷图像和少量的有缺陷图像组成,无缺陷图像经过预分类模型之后已被排除,节省了大量的计算时间。可见,在相同的情况下,本文所提出的级联式型钢表面缺陷检测算法具有非常大的优势。
4 结语
针对型钢生产过程中无缺陷图像检测过程造成的大量冗余计算问题,本文结合了缺陷分类的快速性和目标检测的精准定位特性,提出了级联式缺陷检测模型SDNet。通过预检测网络首先判断实时产生的图像数据当中是否存在缺陷,将筛选出的有缺陷图像再次送入缺陷检测模型进一步检测,大幅提高了缺陷检测模型的检测效率。另外,使用了深度可分离卷积和多尺度并行卷积扩展了网络模型宽度,提高了缺陷预分类网络的分类准确率;同时,使用了改进空洞空间金字塔池化结构与对偶注意力模块,改善了YOLOv3 模型对缺陷的特征提取能力,提高了检测精度。实验结果表明,所提模型对剥落、划伤、击伤和结疤四种缺陷的平均检测速度达到了120.63 FPS,与原始YOLOv3 模型和Faster-RCNN 等模型相比,检测速度提升了2~5 倍,满足了检测实时性要求;对剥落、划伤、击伤和结疤四种缺陷的平均检测准确率达到了92.9%,满足快速检测的要求。后续可对该级联缺陷检测模型进一步优化,采用更合理的权重分配使得先分类后检测的策略能够在有效降低漏检率的同时提高检测速度,广泛应用至型钢、钢轨等表面缺陷检测领域中。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
山东冶金(2019年5期)2019-11-16
电子制作(2019年15期)2019-08-27
山东冶金(2019年3期)2019-07-10
山东冶金(2019年3期)2019-07-10
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
