
融合频域注意力机制和解耦头的YOLOv5带钢表面缺陷检测
2023-02-03 03:02孙泽强陈炳才崔晓博陆雅诺
计算机应用 2023年1期
孙泽强,陈炳才,2*,崔晓博,王 磊,陆雅诺
(1.新疆师范大学 计算机科学技术学院,乌鲁木齐 830054;2.大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
目标检测作为计算机视觉中最基本、最具挑战性的任务之一,旨在找出图像中特定的目标,并对目标进行定位和分类,在工业质检、视频监控、无人驾驶等众多领域应用广泛[1]。带钢产品是广泛应用于我国国民经济与钢铁工业的重要产品,衡量材料效率的主要判定依据是材料的性能、几何尺寸和表面质量。目前冷轧带钢产品在材料与尺寸方面已经基本能够满足要求,但表面质量问题往往成为主要的影响因素[2]。近些年来,各种基础设施建设对于带钢的精度需求越来越高,带钢受到结构和制作工艺影响可能会出现多种表面缺陷,如:夹杂、斑块、麻点、压入氧化皮和划痕等,这些缺陷轻则减少带钢的使用寿命和用途,重则可能会影响建筑物的建设安全导致建筑事故。因此本文希望通过计算机视觉目标检测的方法快速有效地检测出带钢表面的缺陷,进而能分离出有问题的产品。
目前的目标检测算法主要分为两类[3]:第一类是以RCNN(Regions with Convolutional Neural Network features)为代表的两阶段目标检测算法,例如R-CNN 算法[4]、Fast R-CNN算法[5]、Faster R-CNN 算法[6]、Mask R-CNN 算法[7]。两阶段目标检测算法需要先提取目标候选框,也就是目标位置,然后再对候选框做分类与回归。另一类是以YOLO(You Look Only Once)算法为代表的一阶段目标检测算法,例如OverFeat 算法[8]、YOLO 算法[9]、YOLOv2 算法[10]、YOLOv3 算法[11]和SSD(Single Shot multibox Detector)算法[12]。一阶段算法不需要预测区域建议框的网络(Region Proposal Network,RPN),直接输入整张图,直接在最后的检测头上预测边界框的类别和位置,所以检测速度较快,但是检测精度相对较低。
卷积神经网络和深度学习的引入使缺陷检测实现了高准确度和高效率,逐渐成为缺陷检测的主要研究方向。文献[13]在ResNet 中加入了软注意力机制,达到了很高的图像分类精度。而在目标检测方面,文献[14]采用了改进后的Mask R-CNN 算法对带钢表面进行检测,并使用K-meansⅡ聚类算法改进RPN 的锚框生成方法,使精度有很大的提升,但是在速度上仍有很大的欠缺,每秒传输帧数(Frames Per Second,FPS)为5.9。文献[15]调整YOLOv3 网络结构并新增一层大尺度检测层,使小目标的带钢缺陷检测更准确。文献[16]中对YOLOv5 算法运用双向特征金字塔进行多尺度特征融合,采用指数线性单元函数作为激活函数,能加快网络训练收敛速度,提升算法鲁棒性。文献[17]在骨干网络中增加了一种多尺度残差增强模块,并且设计了一种注意力门控结构嵌入模型,进一步提高了YOLO 框架的性能。
为进一步提高缺陷检测的准确率,本文采用YOLOv5 算法,并在此基础上进行改进。首先将YOLOv5 的锚框聚类算法由原来的K-means 算法改进为模糊C 均值(Fuzzy C-Means,FCM)算法,根据优化目标函数得到每个真实框对所聚类的锚框(anchor)的隶属度,从而确定这些真实框的类别以达到聚类anchor 的目的;然后改进YOLOv5 原有的网络结构,加入三层频域通道注意力FcaNet(Frequency channel attention Network)[18]和更换解耦头,提高对带钢表面缺陷检测的准确率;最后在划分好的测试集NEU-DET 上进行验证,得到更好的实验结果。
1 YOLOv5目标检测算法
1.1 网络结构
YOLO 算法是一种单阶段目标检测算法,检测速度相较于R-CNN 算法更快。YOLO 算法的核心思想是将目标检测问题变成一个回归问题,在经过特征提取以及特征融合后直接回归出目标的位置以及所属的类别,使得计算资源和检测时间成本大幅降低。YOLO 系列算法经过不断的创新和改进,自YOLOv1 算法提出后,YOLOv2 算法加入K-means 聚类锚框,大大提高了检测的召回率;YOLOv3 算法首次采用Darknet53 的骨干网络,达到了更好的检测精度;YOLOv4 算法 将Backbone 改进为CSPDarknet53(Cross Stage Partial Darknet53)结构,并且采用PANet(Path Aggregation Network)特征融合的方法;YOLOv5 在YOLOv4 的基础上加入了一些改进的trick,根据网络深度和宽度大小的不同,依次有YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x 版本,版本越高,检测精度越高,速度越慢。
YOLOv5 网络架构主要分为输入端、Backbone 骨干网络、Neck 特征融合和YOLO 检测头,YOLOv5 的输入端采用Mosaic 数据增强,它的基本操作是将随机选取的4 张图片进行随机裁剪,然后将其拼接成指定分辨率的图像,以达到数据增强的目的;同时,在图像批量输入网络前,将数据集中的真实框进行聚类,YOLOv5 算法采用K-means 聚类锚框,之后计算锚框和真实框的差距,进行反向传播。
Backbone 骨干网络首先采用Focus 切片操作,将3 通道的图片切片变成12 通道,接着经过一层带有32 个卷积核的卷积层,变成32 通道,Focus 切片示意图如图1 所示;然后进入CSPDarknet53 骨干网络,借鉴了跨阶段局部网络CSPNet(Cross Stage Partial Network)[19],其在ResNetXt 中证明了基数相较于网络宽度和深度更加有效,可以显著减少参数和计算量,并提升速度。

图1 Focus切片示意图Fig.1 Schematic diagram of Focus section
Neck 由特征金字塔(Feature Pyramid Network,FPN)[20]和路径聚合网络(Path Aggregation Network,PAN)[21]组成。FPN将Backbone 提取的深层特征上采样与浅层信息逐元素相加,从而构建尺寸不同的特征金字塔结构,同时还利用了低层特征高分辨率和高层特征高语义信息。PAN 在FPN 增强语义信息的同时,又添加了一条自底向上的金字塔结构,以获取更多的位置信息,PAN 与FPN 结合就可以获取丰富的特征信息。YOLOv5 特征融合部分如图2 所示。
Head 是YOLOv5 的网络检测头部分,如图2 所示,在特征融合部分之后产生三个检测层,输入分辨率为640×640 的图像,产生20×20,40×40 和80×80 的预测结果,即分别负责预测大、中、小目标,同时每个检测层上有3 个锚框进行检测,检测结果包括目标的定位信息(x,y,w,h)、对象信息(obj)和类别信息(cls)。
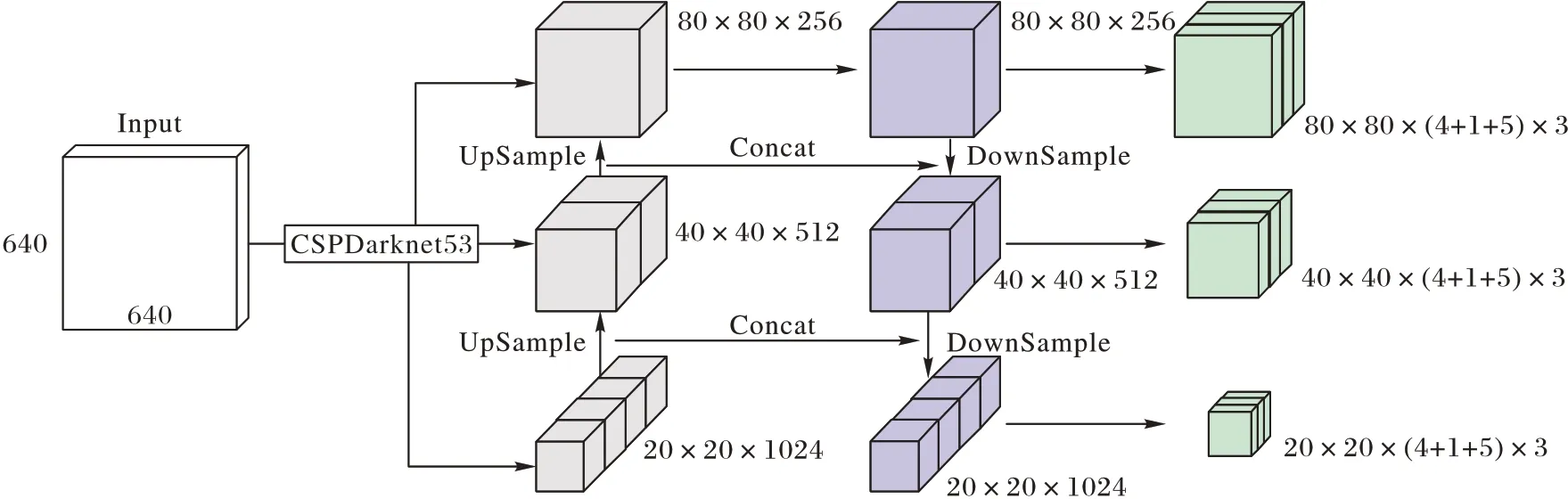
图2 YOLOv5特征融合示意图Fig.2 YOLOv5 feature fusion diagram
1.2 检测原理
YOLOv5 算法采用PAN 的特征融合方式,提取多个不同尺度的检测特征,提高了算法对不同大小目标的检测能力,如图3 所示,将最终输出的特征分成S×S的网格,虚线框代表需要调整的anchor,anchor 的宽度和高度分别是pw和ph,预测相对锚框的偏移量是tw和th,由式(1)可以得到预测框bw、bh、bx和by。

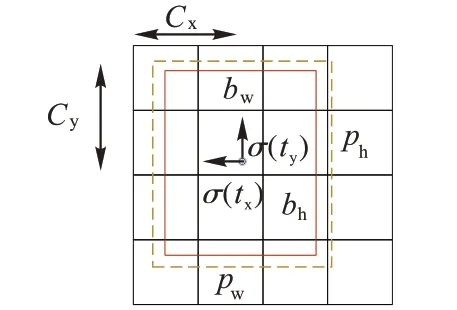
图3 预测框Fig.3 Prediction box
1.3 损失函数
YOLOv5 算法的损失函数包含置信度损失lobj、分类损失lcls以及目标框定位损失lbox,如式(2)所示:

置信度损失lobj的计算如式(3)所示:

其中:K表示图像的划分网格系数;M表示表示每个网格所预测的预测框的个数;Ci为标签值;为预测值;λnoobj为惩罚权重系数。
目标分类损失lcls的计算如式(4)所示:
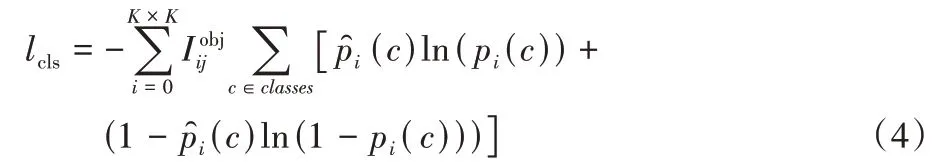
目标定位损失lbox采用完全交并比(Complete-IoU,CIoU)损失,如式(5)~(7)所示,CIOU 损失考虑到了3 个几何因素,即预测框和真实框之间的重叠面积、预测框和真实框的中心点距离和长宽比。

其中:b是预测框的中心点;bgt是真实框的中心点;ρ表示欧氏距离;c表示预测框和真实框所构成的外接矩形对角线长度;α表示权重系数;交并比IoU(Intersection over Union)为预测框与真实框的交集和并集的比值;v表示预测框和真实框之间的长宽比差异,如果一致,则v=0,且差距越大,v也越大。
2 YOLOv5算法改进
2.1 Fuzzy C-means聚类anchor算法
原始YOLOv5 算法采用K-means 算法聚类anchor,数据集中有很多目标的标注框,将这些标注框的宽和高进行聚类,就会形成大小不同的先验框,YOLOv5 在特征融合后产生3 个检测层,分别对应大、中、小尺度的Feature map,负责检测大、中、小目标,最后采用交并比(IoU)评价聚类结果。
由于K-means 聚类算法是一种硬聚类、基于划分的聚类算法,一般样本点之间的相似度是基于欧氏距离来衡量,样本点之间的欧氏距离越小,相似度就越大,是一种硬划分,将每个待聚类的对象严格地划分到某类,具有“非此即彼”的性质。文献[22]提出超像素的快速FCM 聚类算法应用于彩色图像分割,使得聚类算法更快更稳定。该算法通过优化目标函数得到每个样本点对聚类中心点的隶属度,隶属度越大样本所属该类的可能性越大。最终的聚类损失函数可以表示为式(8),其中m>1,用于控制聚类结果的模糊程度,一般取值为2。

FCM 聚类算法就是不断迭代计算隶属度uij和簇中心cj,直到达到最优。隶属度uij和簇中心cj如式(9)所示:

迭代更新的终止条件如式(10)所示:

其中:k是迭代的步数;ε是误差阈值,当迭代到隶属度不再发生较大变化的时候,说明已经达到了最优的状态。
2.2 引入FcaNet注意力机制
在计算机视觉信息处理过程中引入注意力机制,不仅可以将有限的计算资源分配给重要的目标,而且能够产生符合人类视觉认知要求的结果[23]。文献[24]在U-Net 中采用四重注意力,使用四个分支捕获通道和空间位置之间的内部和跨维度交互。通道注意力能给模型精度带来较明显的提升,如SENet(Squeeze-and-Excitation Network)[25],但由于计算开销有限,通道注意方法的核心步骤是对每个通道计算一个标量,同时采用全局平均池化(Global Average Pooling,GAP),因其简单性和高效性而成为深度学习领域的标准选择。
在 ICCV(IEEE International Conference on Computer Vision)2021 中收录的FcaNet[18]中,采用的是频域通道注意力的思想,它从不同的角度出发,将通道表示问题视为一个使用频率分析的压缩过程,而不仅仅只是一个标量,在频率分析的基础上,从数学角度证明了传统的全局平均池化(GAP)其实是频域特征分解的一种特例。因此,FcaNet 把通道的标量表示看作是一个压缩问题,即通道的信息要用标量进行压缩编码,同时尽量保持整个通道的表示能力。
2.2.1 离散余弦变换
离散余弦变换(Discrete Cosine Transform,DCT)具有较强的能量压缩特性,可以实现高质量的数据压缩比,通常典型的二维DCT[26]的基函数是式(11):
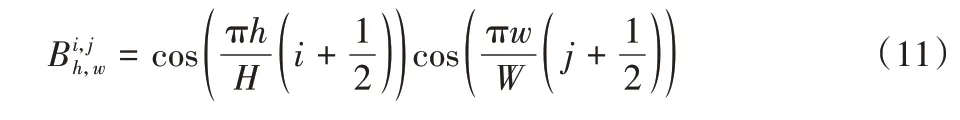
二维DCT 可以写成式(12):

其中:i∈{ 0,1,…,H-1} ;j∈{0,1,…,W-1};f2D∈ RH×W为二维DCT 频谱;x2D∈ RH×W为输入;H为x2D的高度;W是x2D的宽度。
2.2.2 多谱通道注意力模块
在FcaNet 中给出了一个定理并进行了数学证明,定理如下:全局平均池化GAP 是二维DCT 的一种特殊情况,其结果与二维DCT 的最低频率分量成正比。基于上面的定理可以看出,在通道注意机力SENet 中使用GAP 意味着只保留了最低频率的信息,而来自其他频率的分量将会被丢弃,而其他频率也可能包含一些有用的特征,如图4 所示。

图4 SENet通道注意力Fig.4 SENet channel attention
多谱通道注意力如图5 所示,首先,沿着通道维度将输入特征X分成许多部分,表示[X0,X1,…,Xn-1],其 中:Xi∈RC′×H×W,i∈{0,1,…,n-1},C′=C/n,C可被n整除。对每个部分分配相应的二维DCT 频率分量,由分配的DCT 频率分量得到每个部分的Freq向量,如式(13):
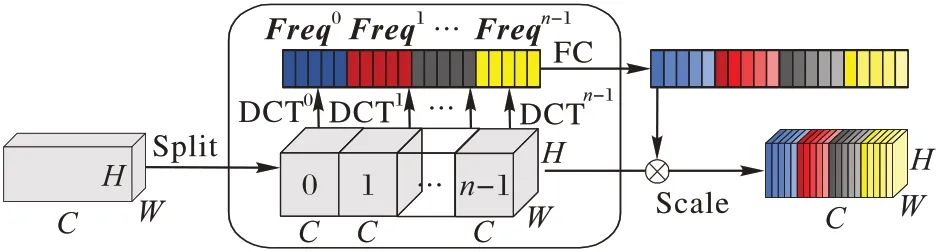
图5 多谱通道注意力Fig.5 Multi-spectral channel attention module

其中:i∈{ 0,1,…,n-1} ;[ui,vi]是与Xi相对应的频率分量的二维指数,经过压缩后,Freqi变为C′维的向量,整个压缩后的向量可以通过拼接获得式(14),其中Freq∈ RC是获取到的多谱向量。

综上,整个多谱通道注意力框架可以被写成如式(15),由式(14)、(15)可以看出,本文算法将原来的全局平均池化GAP 方法推广到一个具有多个频率分量的框架,这样可以有效地丰富压缩后的信道信息,便于表示。

2.3 引入Decoupled Head解耦检测头
YOLOX[27]使用了解耦头的方法,能加快收敛速度,提升检测精度。在目标检测中,分类和回归任务之间的冲突众所周知[28],因此用于分类和定位任务的解耦头在大多数一阶段和二阶段目标检测算法中应用广泛,然而,原始YOLOv5 算法依旧使用耦合头,即分类和回归任务不分离,如图3 所示,特征融合后直接经过一层卷积得到最终检测头,检测头耦合了分类、定位和置信度的检测。而解耦头如图6 所示,,其中nanchor为anchor个数,经过1×1卷积后,通道维数减小至256;经过两个平行的3×3卷积层,其中一个用于分类任务,另一个用于定位和置信度任务;再经过两个分别用于定位和置信度检测的平行的1×1 卷积,经过上述操作,分类、定位和置信度检测使用不同的检测层,与YOLOX 算法不同,本文并没有采用基于anchor-free 的检测机制,还是采用基于anchor 的检测,所以最后产生的检测结果有9个anchor,最终的实验也表明基于anchor的YOLOv5算法比YOLOX的检测精度更高。

图6 解耦头示意图Fig.6 Schematic diagram of decoupled head
3 实验与结果分析
3.1 实验数据集
本文采用的东北大学发布的NEU-DET 数据集是热轧带钢表面缺陷的经典数据集,收集了6 种常见的表面缺陷,包括夹杂(Inclusion,In)、划痕(Scratches,Sc)、压入氧化皮(Rolled-in Scale,Rs)、裂纹(Crazing,Cr)、麻点(Pitted Surface,Ps)和斑块(Patches,Pa),每种缺陷300 张,图像尺寸为200×200。由于裂纹类图像缺陷不明显,模糊图像不利于检测任务,删去这类图像缺陷,因此数据集有1 500 张缺陷图像,将缺陷图像按照8∶2 的比例随机划分成训练集和测试集,因此训练集有1 200 张,测试集有300 张,各类带钢缺陷如图7所示。

图7 各类带钢缺陷Fig.7 Schematic diagram of strip defects
3.2 生成anchor实验
原始的YOLOv5 算法的anchor 框是在COCO(COmmon objects in COntext)数据集上聚类得到的,由于COCO 数据集和带钢表面缺陷数据集的真实框不同,因此需要重新聚类,在YOLOv5 算法中,需要生成9 组不同的anchor,所以设置生成的聚类中心数为9,通过K-means 算法和FCM 算法生成9个anchor,最后得到每个样本点和聚类中心交并比的最大值的平均,作为评价最终聚类结果的标准,计算公式如式(16)所示:

其中:box为预测框;cen为标记框。
通过FCM 算法生成anchor 框,代替原来K-means 聚类算法,最终FCM 生成的9 个anchor 分别为[73,121,104,248,183,160],[287,267,597,89,155,410],[103,608,289,593,593,612],按照式(16)计算得到的准确率为68.15%,而通过K-means 算法聚类得到的准确率为66.56%,所以FCM 的聚类结果更好,两种算法聚类后的散点图对比如图8 所示,其中星号代表该类的聚类中心。

图8 K-means和FCM算法聚类后散点图对比Fig.8 Comparison of scatter plots after clustering between K-means and FCM algorithms
3.3 实验结果分析
本文实验是在ubuntu16.04.10 版本的操作系统下完成的,采用的硬件配置为:Intel Xeon CPU E5-2680 v4 @2.40GH,NVIDIA GeForce RTX3080;软件环境为CUDA10.2和CUDNN9.1;开发框架为PyTorch;编程语言为Python;预训练模型“yolov5-x.pt”,batch size 为8,一共训练100 个epochs。
目标检测领域通常使用召回率(Recall)、精准率(Precision)和平均精度均值(mean Average Precision,mAP)对算法性能进行评价。精准率用于描述检测为正样本的数量占所有的样本的比例;召回率用于描述检测为正样本的数量占标记为正样本的数量的比例。计算公式如(17)所示:

其中:TP(True Positive)表示标记为正样本检测也为正样本的数量;FP(False Positive)表示标记为假样本但检测为正样本的数量,即检测错误的数量;FN(False Negative)表示将样本正类预测为负类的个数,即遗漏检测的个数。本文采用mAP 作为评价指标,平均精度(Average Precision,AP)为PR曲线下的面积,mAP 衡量全部类别下的AP 的均值,N为类别数,计算公式如(19)所示:

IFPS用来衡量网络的检测速度,计算公式如式(20)所示:

其中:NumFigure表示检测的图像数量;TotalTime表示检测所用的总时长。
为验证本文算法的有效性,设计三组实验,对FCM 算法和解耦头进行分析。实验结果如表1 所示,三个实验均基于YOLOv5 算法进行改进,实验1 不采用任何改进策略,使用Kmeans 算法聚类先验框;实验2 使用FCM 算法进行先验框的聚类,最终的mAP 值提升了1.6 个百分点,检测速度相差无几,因为网络结构没有变化,只是改变先验框的聚类方式,模糊聚类算法并不会嵌入网络将聚类得好的先验框加入网络进行训练,因此不会增加额外的参数量;实验3 是在实验2 的基础上将检测头替换为解耦头,将分类任务和定位任务解耦合之后,由于增加额外的卷积层,mAP 值又提升了1.0 个百分点,但是FPS 下降5.14 个百分点。

表1 不同改进算法的对比实验结果Tab.1 Comparative experimental results of different improved algotithms
表2 是在前两个改进点的基础上加入不同的注意力机制进行对比的结果,图9 是加入不同注意力机制使用Grad_cam 在缺陷图片上的热力图展示结果。如表2 所示,加入SE(Squeeze-and-excitation)、BAM(Bottleneck Attention Module)[29]、CBAM(Convolutional Block Attention Module)[30]、CCA(Criss-Cross Attention)[31]、CA(Coordinate Attention)[32]后mAP 均有一定下降;而加入Non-Local[33]、DA(Dual Attention)[34]、FcaNet 后mAP 提高较明显,相较于改进2,分别提高1.2、1.3 和3.0 个百分点,检测速度除Non-Local 提升明显外,DA 和FcaNet 基本不变。DA 是从空间和通道两个分支并行地构建特征图的相关性矩阵;FcaNet 采用频域通道注意力,将通道看作频率压缩的过程,两者都达到了不错的检测精度。对增加注意力机制后的额外参数量进行分析,加入BAM 的额外参数量最少,但是mAP 只有81.4%;加入FcaNet相对其他注意力模块所增加的额外参数量较少,而mAP 提升较明显,达到85.5%。从热力图对比结果看出,对于“划痕”缺陷,加入FcaNet 后,对缺陷的检测效果更好,误检的目标更少,在可视化的角度证明了FcaNet 在缺陷检测上效果更优。

图9 加入不同注意力模块热力图对比结果Fig.9 Heat map comparison results after adding different attention modules

表2 加入不同注意力模块对比实验结果Tab.2 Comparison experimental results by adding different attention modules
表3 是不同算法在NEUDET 数据集上的对比结果,其中文献[14]采用改进的Mask R-CNN 两阶段算法,检测精度达到96%,但是检测速度只有5.90 FPS,虽然检测精度很高,但是难以满足检测的实时性要求;文献[15]采用改进的YOLOv3 算法,对于5 类缺陷的检测精度达到82.2%,还可以进一步提升;Faster R-CNN 算法和SSD 算法的特征提取网络均为Resnet50,是目前检测性能较好的Backbone。对比不同的算法检测结果可以发现:1)相较于原始的YOLOv5 算法,改进的YOLOv5 算法在各类缺陷的检测精度上均有明显提升,尤其是针对检测效果不佳的压入氧化皮缺陷,达到了72.7%,整体mAP 相较于原始YOLOv5 提升了4.2 个百分点,检测速度下降不多。2)改进后的YOLOv5 算法的检测速度低于文献[15]算法、原始YOLOv3 和SSD,而检测精度更高。主要因为实验使用的YOLOv5-x 版本,是YOLOv5 所有版本中网络深度和宽度最大的结构,因此在检测速度上未能胜过SSD 和YOLOv3 算法。YOLOv5 也使用解耦头来进行检测,但是采用的是anchor-free 的检测方法,所以在带钢表面缺陷检测效果并不佳。

表3 不同算法检测性能的对比结果Tab.3 Comparison results of detection performance of different algorithms
4 结语
本文针对带钢表面缺陷数据集中的五类不同的缺陷进行高精度检测的问题,提出一种改进的YOLOv5 算法,首先使用FCM 算法代替K-means 算法对先验框进行聚类,接着采用解耦的检测头,从而分离分类和定位任务,不同的任务使用不同的卷积层,最后加入了FcaNet 通道注意力模块,使用多谱通道注意力机制提取到更有效的特征信息,最后实验结果表明,本文提出的改进方法能够准确、快速地检测出不同缺陷的带钢图像。本文方法在Nvidia RTX 3080 测试条件下mAP 达到0.855,速度为27.71 FPS,实现了高精度的检测,检测精度高于通用目标检测模型,检测速度还有待提升,该方法为带钢的缺陷检测提供了有益的帮助。下一步将在嵌入式设备上进行模型的性能改进,进一步缩小网络结构,以便在移动端实时地检测带钢缺陷。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
传媒评论(2017年3期)2017-06-13
雷达学报(2017年6期)2017-03-26
第二课堂(课外活动版)(2016年2期)2016-10-21
互联网天地(2016年1期)2016-05-04
