
生成对抗网络下的低剂量CT图像增强
2023-02-03 03:02胡紫琪李美然贺建飚
计算机应用 2023年1期
胡紫琪,谢 凯*,文 畅,李美然,贺建飚
(1.长江大学 电子信息学院,湖北 荆州 434023;2.长江大学 电工电子国家级实验教学示范中心,湖北 荆州 434023;3.长江大学 西部研究院,新疆 克拉玛依 834099;4.长江大学 计算机科学学院,湖北 荆州 434023;5.中南大学 计算机学院,长沙 410083)
0 引言
计算机断层扫描(Computed Tomography,CT)是最实用的成像方式之一,常用于临床医学,有助于疾病的诊断与治疗;但CT 检查产生的辐射远高于普通的X 光检查,通常情况下通过降低管电流、缩短曝光时间减少辐射对人体的危害,而低辐射剂量会导致CT 图像中存在噪声、边缘不清晰、细节模糊等问题,不利于医生诊判病情[1]。
常用的低剂量CT(Low-Dose CT,LDCT)去噪方法有自适应非局部均值(No-Local Means,NLM)算法[2]。Feruglio等[3]使用三维块匹配(Block Matching 3D,BM3D)去噪,能明显改善图像质量;但CT 图像中的噪声分布不均匀,处理完的图像存在过度平滑和残差等问题。传统的医学去噪算法在速度上有明显优势,且不需要大量的数据集,但去噪效果还有待提高。
近些年来,深度神经网络技术快速发展,为医学图像处理提供了新思路和新方法[4-6]。Jain 等[7]用卷积神经网络(Convolutional Neural Network,CNN)处理图像去噪问题;Zhang 等[8]提出去噪网络DNCNN(DeNoising CNN);Chen等[9]结合卷积自编码器-解码器与残差学习提出RED-CNN(Residual Encoder-Decoder CNN),从低剂量估计正常剂量的CT 图像。上述网络结构显著地提升了去噪效果,但以均方差或绝对值误差作为损失函数,去噪后的图像整体较为平滑,存在细节丢失、边缘模糊的问题。生成对抗网络(Generative Adversarial Network,GAN)[10]是基于博弈思想的网络框架,由生成器和判别器组成,在对抗损失函数的迭代优化下,能显著提升去噪效果;但原始GAN 训练较为困难,存在模式崩塌、梯度消失等问题。研究学者结合GAN 与感知损失[11],提出WGAN(Wasserstein GAN)[12]解决GAN 训练困难的问题,并采用WGAN-GP(WGAN-Gradient Penalty)[13]使网络快速收敛。Yang 等[14]提出的WGAN-VGG(WGAN-Visual Geometry Group)也取得了良好的去噪效果,但该网络只考虑了CT 图像特征一致性,未考虑结构一致性。
医生在使用CT 图像诊断的过程中,需要观察病变组织、正常组织及其他区域,对图像的亮度及对比度有着较高的要求,因此在解决CT 图像的噪声问题后,还要对去噪后CT 图像进行增强,包括边缘增强和动态灰度增强。为解决以上问题,本文提出一种LDCT 图像增强算法LDCT-IEA。该算法将WGAN-GP 与感知损失、结构损失相结合以提升去噪效果;对去噪后的CT 图像分别进行动态灰度范围增强和边缘增强;最后通过非下采样轮廓波变换Non-Subsampled Contourlet Transform,NSCT)分解增强后图像,得到高低频子图,配对后的子图用CNN 进行自适应融合,反变换后就得到最终增强结果。
1 本文算法LDCT-IEA
本文算法LDCT-IEA 流程如图1,包含图像去噪、图像增强和图像融合三个部分:1)通过修改传统GAN 的生成器、判别器及损失函数,对LDCT 图像进行去噪;2)对去噪后的图像进行动态灰度增强以及边缘增强;3)使用NSCT 和CNN 融合增强后的图像。

图1 本文算法LDCT-IEA流程Fig.1 Flowchart of proposed algorithm LDCT-IEA
1.1 图像去噪
1.1.1 生成器
生成器是结构对称的漏斗形全卷积网络,包含编码部分与解码部分。编码部分包含5 层Conv2D-LeakyReLU 组合,分别对应卷积层、激活函数层。卷积层的卷积核大小均为5×5,通道数均为128,固定步长为2,LeakyReLU 的α参数为0.2,卷积层不使用填充操作。解码部分与编码部分相对应,包含5 层Resize-Conv2D-LeakyReLU 组合(最后一层激活函数为Tanh),本文使用Resize+Conv2D 的操作代替反卷积操作,避免棋盘格效应[15]。该部分卷积层的卷积核大小、通道数与编码部分一致,固定步长为1,采用填充操作,带泄露修正线性单元(Leaky Rectified Linear Unit,LeakyReLU)的α参数为0.2。在编码与解码的过程中使用跳层连接,将编码部分和解码部分中具有相同分辨率的特征图进行融合,充分利用图像上下文信息和位置信息,网络结构如图2 所示。

图2 生成器结构Fig.2 Architecture of generator
1.1.2 判别器
判别器通过CNN 提取图像特征,以判断判别器输入是否服从真实分布。因此设计了一个包含5 层Conv2DLayerNormalization-LeakyReLU 组合的卷积网络,卷积核大小固定为5×5,首层卷积通道数为32,之后的卷积通道数均为前一层的2 倍,固定步长为2,不采用填充操作,LeakyReLU的α参数为0.2。特征图经过卷积层处理后,通过全局平均池化层和全连接层输出结果(全连接层的神经元节点数为1),结构如图3 所示。

图3 判别器结构Fig.3 Architecture of discriminator
1.1.3 损失函数
GAN 通过优化生成分布pg与真实分布pr之间的JS(Jensen-Shannon)散度来训练网络,使pg逼近pr;但pg与pr分布都是高维空间的低维流形,不存在重叠部分或重叠部分可以忽略,导致JS 散度为常数,在梯度求导的过程中梯度为0,产生梯度消失问题。为了从根本上解决GAN 训练不稳定的问题,使用EM(Earth Mover)距离作为两个分布的度量指标。在参数化的神经网中中,EM 表达式如下:
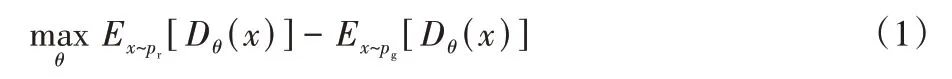
其中:Dθ为参数化的CNN。为使Dθ满足1 阶Lipschitz 约束条件,使用梯度惩罚项,定义如下:

其中x′为生成样本xr与真实样本xg的线性插值,定义如下:

结合EM 距离后本文判别网络的损失函数如下:

其中:Dθ表示判别网络;pg表示生成的常规剂量CT(Normal-Dose CT,NDCT)图像分布,pr表示真实的NDCT 图像分布;x′表示生成的NDCT 图像与真实NDCT 图像的线性插值;α表示权重系数,设为10。
本文生成网络的损失函数为:

WGAN-GP 使得生成分布逼近真实分布,从而达到去噪效果;但图像之间存在特征的差异,为保证图像之间的内在相似性,本文使用感知损失优化生成器。在生成NDCT 图像后,将其与对应的真实标签同时送入已经训练好的VGG16网络中,分别在该网络的浅层、中层及深层输出特征差值之和,表达式如下:

其中:xr表示真实的NDCT 图像,xg表示生成的NDCT 图像;Wn、Hn、Cn分别表示某层卷积的特征图的宽、高及通道数;F(·)表示特征提取。结合WGAN-GP对抗损失,目标函数为:

由于CNN 不是恒等映射,所以感知损失不能保证图像间结构的一致性,即在F(xg)-F(xr)=0 的条件下,也不能保证xg=。为保证图像结构的一致性,本文使用基于像素点的损失函数绝对值误差来优化生成器:

这样即满足特征的相似性也保证图像结构的一致性,能更好地保留图像细节信息。总的目标函数如下:

其中:λ和β为归一化因子,保证感知损失和绝对值误差损失与对抗损失量纲的一致性。
1.2 图像增强
为提升去噪后CT 图像的视觉效果,对去噪后的图像进行一定程度的增强,包括提升动态灰度范围、增强边缘轮廓。
1.2.1 动态灰度增强
Retinex[17]是对人类视觉系统进行建模的图像增强算法,在此基础上衍生出了许多有效的图像增强算法,其中常用的SSR(Single Scale Retinex)、MSR(Multi-Scale Retinex)算法均存在偏色问题,为提升图像的动态灰度范围,本文使用基于MSR 的MSRCR(Multi-Scale Retinex with Color Restoration)[18]算法。MSR 算法的定义如下:

其中:R(x,y)为增强后CT 图像;I(x,y)为待增强CT 图像。通常情况下,环境函数F(x,y)为高斯卷积函数,定义如下:

其中c、λ使得以下条件成立:

在此MSR 基础上,MSRCR 算法加入调整因子C,以此来解决降低色彩失真问题,定义如下:

其中:Ii(x,y)表示图像的某个通道;α为受控的非线性强度;β表示增益常数。
1.2.2 边缘增强
图像边缘是灰度值变化较大的位置,描述了图像局部不连续的特征,也是区分各种组织、骨头及钙化斑块的边界。图像边缘增强使得模糊的边界更加清晰,有利于区分各种组织部位。常用的一阶微分算子存在边缘定位效果较差、易丢失关键信息等不足;二阶微分算子相较于一阶可以提取更多边缘信息,但是对噪声较为敏感。因此本文使用非锐化掩膜法增强图像边缘。算法主要分为三个部分:平滑图像、生成锐化模板以及锐化模板与原图相加,公式如下:
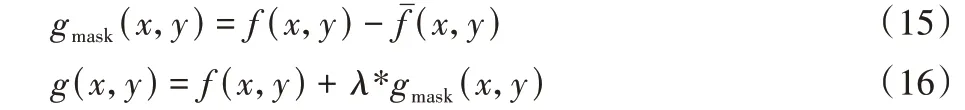
其 中:f(x,y) 表示输入图像表示平滑后图像;gmask(x,y)表示模板;λ表示控制增强效果的缩放因子。使用高斯滤波得到平滑结果,计算方法如下:

其中:s、t表示高斯模板坐标,模板中心为原点;G(s,t)表示二维高斯函数,表达式如式(18)。

其中σ表示高斯函数标准差。
1.3 图像融合
为了使CT 图像同时包含亮度增强和边缘轮廓增强两种增强效果,且避免过度增强和信息冗余的问题,本文将增强后的CT 图像进行融合。常用的融合方法可分为空域法和变换域法。基于像素点的空域融合方法细节轮廓丢失严重,融合后图像的信噪比和对比度降低;相较于空域法,变换域法是一种更为细致的融合方法,能在图像的变换域上融合不同的高低频信息。常用的融合算法是多尺度变换结合人工设计的融合规则,但是CT 图像的轮廓、病变区等一些目标区域常常是不规则的形状,而人工设计的融合规则一般基于频域系数或者一些局部窗口,不是根据不规则目标区域设计的,局限性较大。因此本文采用多波段自适应融合的思想,使用CNN 的自适应特性,结合分解特性较好的NSCT,对增强后的CT 图像在频域上进行自适应融合。
1.3.1 非下采样轮廓波变换
NSCT[19]是轮廓波变换的改进,利用非下采样金字塔滤波器和非下采样方向滤波器替换了原有滤波器,使该变换具有平移不变性,解决了轮廓波因下采样操作导致的伪吉布斯现象。第一部分的非下采用金字塔分解使图像具有多分辨率性,并输出一个低频子图和一个高频子图;第二部分的非下采样方向滤波器是实现图像多方向性的关键,由双通道扇形的非下采用滤波器组成,将高频子图分解为多个多方向子图,每个子图表示图像在某个方向上的细节信息。若对原图像进行m级分解,可得到1 个低频子图及个高频子图,其中ki表示在尺度下i下的多方向分解级数。分解流程如图4 所示。
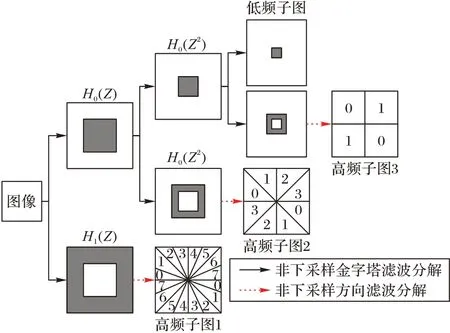
图4 非下采样轮廓波变换Fig.4 Non-subsampled contourlet transform
1.3.2 CNN自适应融合
为解决人工设计融合规则存在的问题,本文使用特征提取能力较强的CNN,设计了端到端的自适应融合方法,将分解后的高低频系数子图配对送入网络得到融合结果。该网络由两个相同的CNN 构成,输入大小均为512×512,并对两个子图进行归一化操作,结果范围为[0,1]。该网络结构如图5 所示,由4 个Conv-BN-ReLU 组合构成,其中卷积层的卷积核大小为5×5,步长为1,采用Padding 操作。

图5 图像融合网络结构Fig.5 Architecture of image fusion network
经过特征提取后,两个网络分别给两个子图不同的权重分配,进而进行特征融合,再将融合结果进行反归一化,通过非下采样轮廓波反变换得到最终结果。公式表达如下:

其中:NSCTL(x)、NSCTH(x)表示非下采样轮廓波变换后的低频子图和高频子图;fL、fH表示CNN 的映射函数;⊕表示特征融合;PL、PH、Pfinal分别表示低频、高频及最后的融合结果,NSCT()-1表示反变换。
2 实验与结果分析
2.1 实验平台
本文实验平台如下:操作系统为Windows 10,显卡为NVIDIA RTX2060,处理器为Intel Core i7-10750H;使用TensorFlow2.0 深度学习框架以及Python 3.7.4 搭建网络模型。
实验数据来自2016 年Low Dose CT Grand Challenge 比赛的公开数据集[20],为真实临床数据,包括患者的腹部扫描CT以及对应的模拟1/4 剂量下的LDCT。本文随机选取10 个匿名患者的CT 数据共2 780 对,CT 图像大小为均为512×512,切片厚度为3 mm。训练集、测试集划分比例为8∶2,训练集包含2 224 对数据,测试集包含556 对数据。在训练阶段,考虑到计算量问题,对训练集的每对图像进行5 次随机裁剪,裁剪后的图像尺寸均为64×64,当裁剪的图像均值小于0.1时,对其进行重新裁剪,保证训练数据的可靠性,最终得到13 900 对训练数据。在测试阶段,不使用裁剪操作,输入图像大小为512×512。
2.2 数据记录
2.2.1 图像去噪
为了评估本文去噪算法,选取一张典型的低剂量腹部CT 图像,与常用的去噪算法BM3D、RED-CNN、WGAN-VGG作对比,并进行损失函数消融实验。根据实验结果调整优化后,实验参数设置如下:训练次数为500,训练批次为64,生成器、判别器的学习率分别设置为0.000 1、0.000 4;优化器为Adam,其超参数设定β1=0.5、β2=0.9;归一化参数β和λ分别为10 以及0.1。图6 为不同算法的去噪结果对比。

图6 各算法的去噪结果对比Fig.6 Comparison of denoising results of different algorithms
如图6(a)、(b)所示,相较于NDCT 图像,LDCT 图像因受到量子噪声的干扰,结构信息和细节信息损失较为严重,影响医生的临床诊断。由图6(c)~(e)可知,BM3D、RED-CNN和WGAN-VGG 方法均在不同程度上抑制了噪声,基于深度学习方法的RED-CNN 和WGAN-VGG 的去噪效果明显优于BM3D,不过RED-CNN 的结果过于平滑,感兴趣边缘被模糊。
由图6(f)可知,本文算法不仅有效去除了大部分噪声及伪影,且保留了较多的细节信息。由于结合了结构损失函数,本文算法相较于WGAN-VGG,在感兴趣区域保留了更多的结构信息。为了进一步说明本文去噪算法的有效性,对比了图6 中所有去噪结果的第200 行轮廓线,如图7 所示,结果直观地展现了本文算法的去噪结果与NDCT 图像的拟合程度最高,体现了本文算法的结构一致性。

图7 图6中所有去噪结果的第200行轮廓线对比Fig.7 Comparison of contour line of the 200th row among all denoising results in Fig.6
另外,本文还定量分析了不同算法的去噪性能,使用三种常用的去噪评价指标:峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、均方根误差(Root Mean Square Error,RMSE)和结构相似度(Structural Similarity Index Measure,SSIM)作为评价标准,结果如图8 所示。由图8 可知:本文算法的PSNR取得了最大值,去噪效果优于对比算法;SSIM 也取得了最大值,RMSE 则取得了最小值,表明去噪后的结果与NDCT 图像接近,体现了结构上的一致性。

图8 不同算法的RMSE、PSNR、SSIM对比Fig.8 Comparison of RMSE,PSNR,SSIM of different algorithms
验证损失函数去噪优势的损失函数消融实验结果如图9 及表1 所示。

图9 损失函数消融实验结果对比Fig.9 Comparison of experimental results of loss function ablation

表1 消融实验结果对比Tab.1 Comparison of ablation experimental results
在损失函数消融实验上,LossGAN+Lossp与LossGAN+LossMAE两种方法均在一定程度上去除了噪声,但是前者更加注重图像特征之间的相近,去噪后的CT 图像在结构上有部分损失,后者更加关注图像之间的结构一致性,图像存在平滑现象。而本文方法的损失函数既考虑了CT 图像间特征一致性又考虑了图像间的结构一致性,在去噪效果及细节信息保留上均要优于上述两种对比方法。表1 是消融实验的评价指标对比,本文方法在三种指标上均取得最优。
2.2.2 图像增强
动态灰度范围增强实验结果如图10、11 所示,其中本文使用MSRCR 算法。可以看出,测试方法均增大了去噪后CT图像的动态灰度范围,亮度都有所增强。
图10(a)为去噪后的CT 图像(即图6(f)),如图10(b)~(f)及图11(b)~(f)所示,基于直方图均衡的方法扩大后的灰度范围相较于其他方法要窄,整体亮度较低,且部分区域模糊;SSR 的结果整体较亮,导致各组织部位区分不明显;MSR灰度分布不均匀导致背景亮度过高,存在色彩失衡现象;而MSRCR 灰度分布均匀,前景、背景分隔明显,增强亮度的同时结构清晰。

图10 动态灰度增强结果Fig.10 Dynamic gray-scale enhancement results

图11 灰度直方图统计Fig.11 Gray histogram statistics
边缘增强实验对比了一些常用的边缘增强算法,如:Robert、Sobel、Laplacian、LOG(Laplacian Of Gaussian),实验结果如图12、13 所示,图12(a)为去噪后的CT 图像(即图6(f))。从图12 可以看出,测试方法都实现了边缘增强。结合相应图13 的三维灰度热力图(颜色的深浅表示像素值的大小,颜色越深该位置的灰度值越大)可知:Robert、Sobel算子边缘定位不准确,导致外围轮廓增强较为明显,其他结构细节部分效果较差,且存在边缘轮廓模糊的现象;Laplacian、LOG 算子相较于一阶算子边缘定位更加准确,边缘增强效果较为明显,但放大了噪声信号,且但存在过度增强现象;非锐化掩膜在灰度变化较小的边界处增强效果明显,整体的边缘增强效果较好,图像结构清晰。

图12 边缘增强结果Fig.12 Edge enhancement results
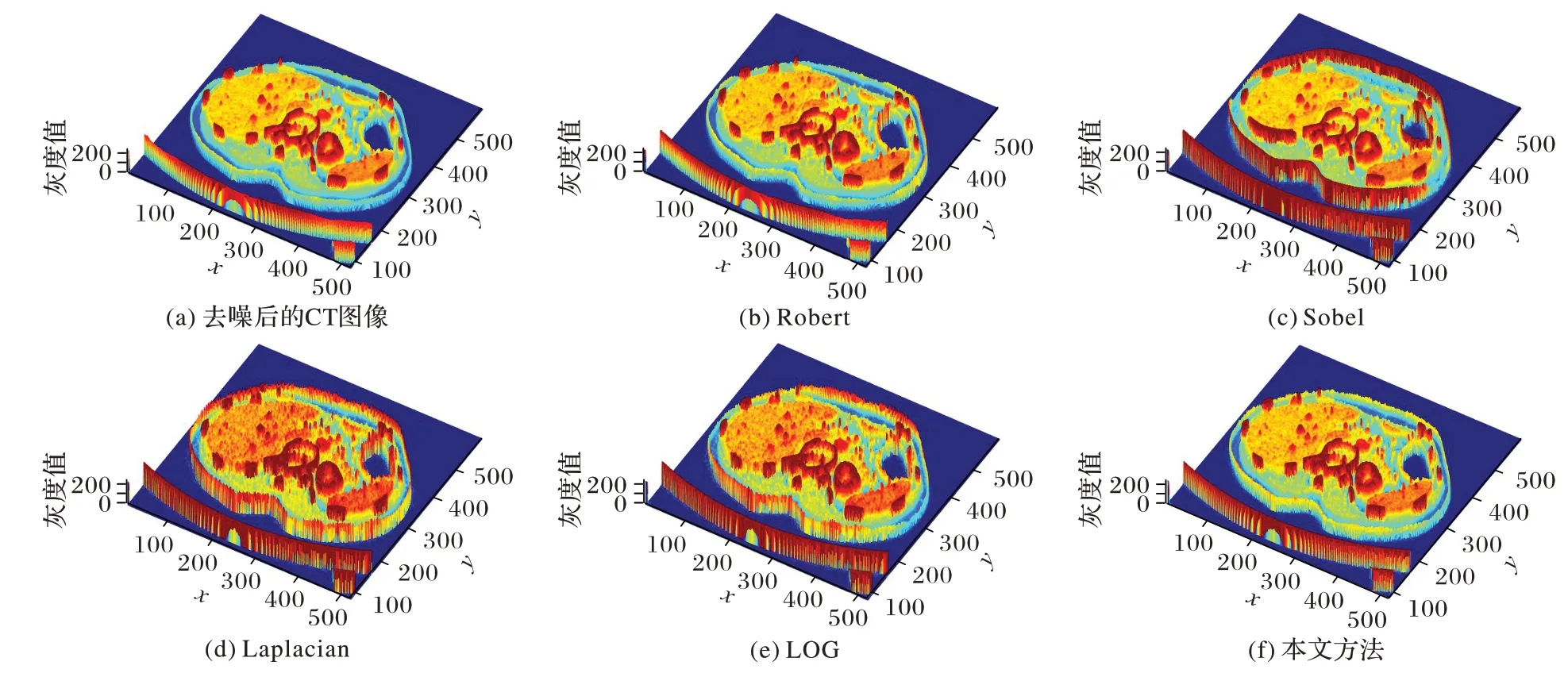
图13 三维热力图Fig.13 Three-dimensional heat maps
2.2.3 图像融合
图像融合实验使用非下采用轮廓波结合CNN 的方法与常用的融合方法,如像素点融合、频域融合及CNN 融合作对比。为提升融合效果,实验中对图像进行两级非下采样轮廓波变换,分解后包含1 张低频子图及6 张高频子图。为了训练本文的CNN,手动对NDCT 实验数据集同时进行动态灰度增强及对比度增强,调整窗位(window level)及窗宽(window width),设置为45 和350,分别训练高低频融合网络,使用MSE 作为优化损失函数,优化器、学习率、训练批次、训练次数分别为Adam、0.000 1、8、100,实验结果如图15所示。从图15 可以看出,基于像素点及非下采样轮廓波融合的结果整体噪声较为明显,PSNR 下降;而其他两种方法的融合结果更为细致。为客观分析融合效果,除PSNR、SSIM、RMSE 外,还使用了基于图像特征的三种评价指标,包括:平均梯度(Average Gradient,AG)、空间频率(Spatial Frequency,SF)和标准差(Standard Deviation,SD)。AG 用于衡量图像的清晰度,SF 用于衡量图像细节信息丰富度,SD 则反映了灰度的离散情况。分析图15、16 可知,本文方法在PSNR、SSIM、RMSE上的结果分别为33.015 5 dB、0.918 5、5.99,在AG、SF、SD 上的结果分别为109.662 7、43.407 6、28.294 2,对比其他融合方法,上述参数均为最优值。
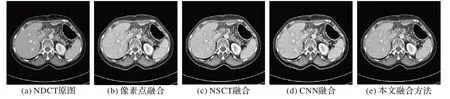
图14 融合结果对比Fig.14 Comparison of fusion results

图15 融合结果的SSIM、PSNR、RMSE对比Fig.15 Comparison of RMSE,PSNR,SSIM of fusion results

图16 融合结果的AG、SF、SD对比Fig.16 Comparison of AG,SF,SD of fusion results
相较于RED-CNN 及WGAN-VGG,本文方法LDCT-IEA 的RMSE 分别降低了2.68%、3.63%,PSNR 分别提高了2.088%、2.358%,SSIM 分别提高了1.413%、1.773%。综合实验结果可知,本文方法不仅去除了LDCT图像中的噪声,且增强了CT图像的动态灰度范围及轮廓边缘,使CT 图像更加清晰,视觉效果更好,更加有利于医生诊断病情。
3 结语
本文提出了生成对抗网络下的LDCT 图像增强算法,不仅考虑了LDCT 图像的噪声影响,还考虑了亮度及对比度。通过综合改进WGAN-GP 算法,有效地提升对LDCT 图像的去噪效果,较好地保留了图像细节信息;在图像融合方面,为使去噪增强后的CT 图像能够有效实现信息互补,消除过度增强,将非下采样轮廓波结合CNN 实现频域上子图的自适应融合,融合后不仅有效地减少了噪声,且明显地提升了动态灰度范围、增强了图像的边缘信息。实验结果也验证了本文方法的有效性和可行性。
今后还可以对算法进行更深入的探索来适应未来更加多样化的CT 数据集;将算法扩展到X 光片、核磁共振等医学图像,为医疗辅助提供可靠的算法。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
天津医科大学学报(2021年1期)2021-01-26
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
同济大学学报(自然科学版)(2019年2期)2019-04-02
计算机与数字工程(2019年3期)2019-03-26
西华师范大学学报(自然科学版)(2018年3期)2018-09-26
中国交通信息化(2017年4期)2017-06-06
自动化学报(2017年5期)2017-05-14
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
