
基于模糊C均值聚类的混合动力汽车典型运行工况构建
2023-02-09 01:21王宝森杨建军高继东付雪青
机械设计与制造 2023年1期
王宝森,杨建军,高继东,付雪青
(中国汽车技术研究中心有限公司,天津 300300)
1 引言
汽车运行工况是评估汽车燃油经济性的基础组成部分,也是混合动力电动汽车(HEV)控制策略评价与优化的重要依据[1]。任意车辆在具体环境下都有其独特的运行特征,这种独特性在不同动力车型之间表现得更为明显[2]。因此,有必要针对所研究的混动车型构建符合其在道路运行特征的典型运行工况,为能量管理策略的工况适应性研究提供基础。
目前,汽车运行工况构建方法可以分为聚类法和马尔科夫链法两类。聚类法需要先将测试数据划分为运动学片段,通过聚类原理将运动学片段分类,然后挑选代表性片段合成工况[3−5]。基于聚类法得到的运行工况依据实际测试数据,汽车运行工况的可行性较强,但是合成工况的时长很难精准控制。马尔科夫链法的关键是基于大样本数据得到状态转移概率矩阵,然后预测一定时间长度的状态序列,最后将状态序列转化为速度时间曲线[6−8],是一个随机过程。为了突出不同运行工况的下的汽车运行特性,可以采用聚类算法先将原始数据分类,然后通过马尔科夫链构建类内工况,最终构建完整的汽车运行工况[9]。马尔科夫链法根据原始数据表现出的固有特征来重塑运行工况,所构建的工况有效性较强且时长可以精确控制,但是工况合成后一般需要进行平滑处理以增强工况的可行性。
综合考虑运行工况的有效性和可行性,以试验车型的城市道路测试数据为基础,通过短行程法、主成分分析法、模糊C 均值(FCM)聚类算法等方法构建了研究车型的典型运行工况,通过运行工况特征参数、速度−加速度联合分布概率、百公里油耗验证了所构建工况的有效性,并与我国现行的NEDC和WLTC轻型汽车法规测试工况进行对比,得出典型运行工况的主要特点。
2 汽车运行工况构建流程
汽车运行工况构建流程一般包括数据采集与处理、运行工况构建和运行工况验证。不同的运行工况构建方法决定了最终构建的运行工况能否反映道路实际交通状况和地形特征。根据具体的试验和数据,制定了HEV 典型运行工况构建流程,如图1 所示。

图1 汽车运行工况构建流程Fig.1 Construction Process of Vehicle Operating Condition
3 数据采集与预处理
3.1 数据采集
数据采集以网约车为例进行。由于乘客的目的地是随机的,所以该方式本质上属于自主行驶法,该方法随意性强,能够较好地覆盖目标城市道路情况[10]。考虑到不同时间段和驾驶员不同驾驶风格对测试数据的影响,整个测试过程覆盖了(7:00~22:00)的时间段,由14名驾驶员驾驶同款HEV各完成一天的数据采集,试验HEV构型,如图2所示。
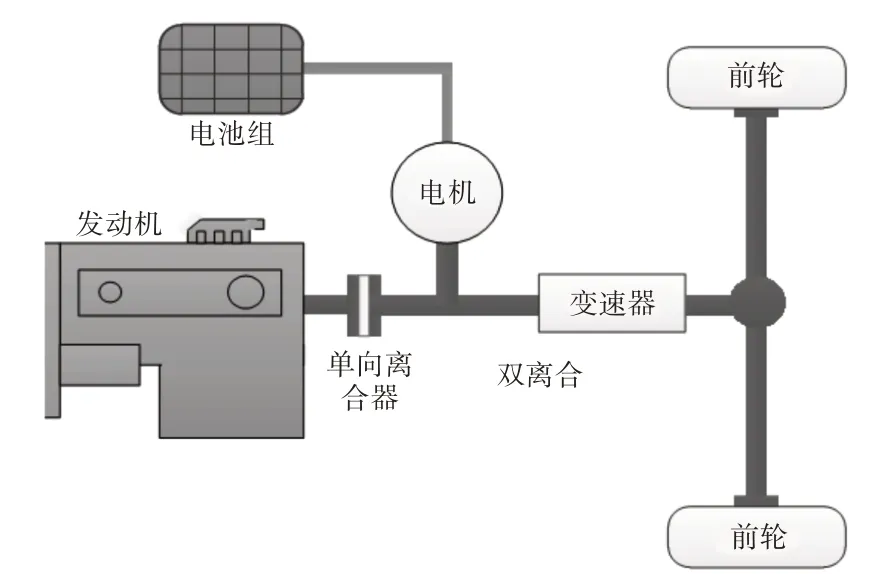
图2 试验车辆动力系统结构图Fig.2 Structure Diagram of Power System of Test Vehicle
其中,内燃机通过离合器与电力动力系统相连,使汽车可以由发动机和电机独立驱动或者共同驱动。
车载终端通过总线信号获取车速、发动机转矩、发动机转速、电动机转矩、电动机转速、变速箱档位及动力电池SOC等HEV关键参数,通过分析动力总成运行参数的合理性,确保采集的数据真实可靠。
3.2 数据预处理
为了对采集的数据进行分析,按照无效停车时段的剔除、数据平滑、运动学片段划分及筛选、特征参数提取的顺序对采集的数据进行预处理。
3.2.1 无效停车时段剔除
由于网约车具有停车等待客户的行为,且停车时长受人为因素影响较大,所以这部分数据不能反映试验HEV在目标城市道路运行工况。在工况数据处理中,假定车速持续为0的时间大于90s时为长时间停车或者等待客户的工况。这些大于90s的停车段只保留90s。
3.2.2 数据滤波
为了消除数据采集过程中噪声的影响,采用式(1)的移动平均滤波器对采集的数据进行平滑处理。

式中:vsmoothed(t)—平滑后t时刻的车速;vt—t时刻车速;n—测试数据时间长度。
一组数据在平滑处理前后的对比图,如图3所示。
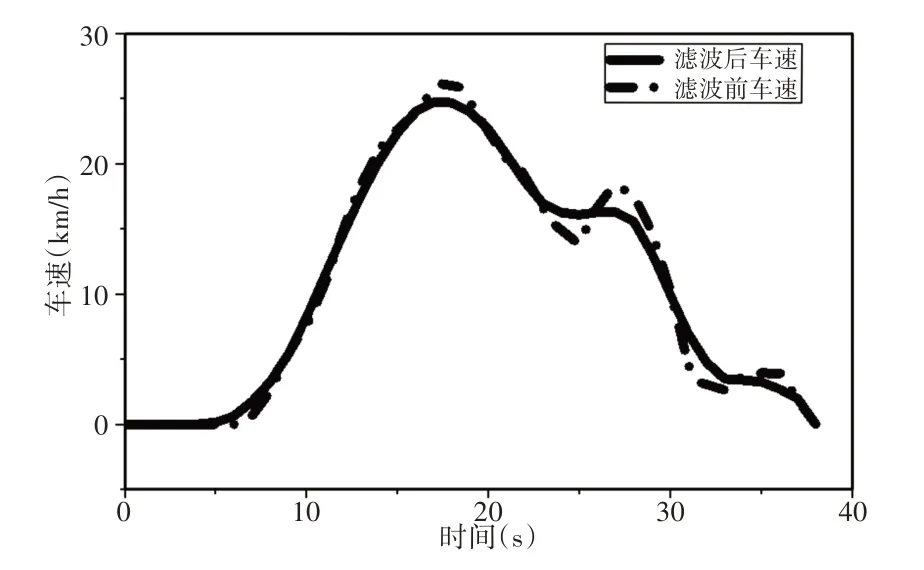
图3 平滑处理前后车速数据对比Fig.3 Vehicle Speed Comparison Befor and After the Smooth
从图3可见,采用平滑处理的工况数据去噪效果较好,可有效提高后续分析的准确性。
3.2.3 运动学片段划分与特征参数的选取
为了合理区分不同的运行工况,采用短行程方法对原始数据进行剖分,即从一个停车段开始到下一个停车段开始的区间定义为一个运行学片段[11−12],如图4所示。

图4 运动学片段示意Fig.4 Schematic Diagram of Kinematic Sequence
通过MATLAB编程,将原始数据划分为3154个相似的运动学片段。
把时长小于20s的运动学片段视为无效片段[13],筛选后共获得3020个运动学片段。
为了将运动学片段进行合理的分类,选取22个特征参数来描述短行程片段。所选特征参数,如表1所示。

表1 运动学片段特征参数Tab.1 Characteristic Parameters of Kinematic Sequence
计算每个片段的22个特征参数,得到初始特征参数矩阵:

式中:n—特征参数的个数(n=22);m—选取的有效运动学片段的个数(m=3020);dsinij—第j个片段的特征参数矩阵;Fini—由所有运动学片段第i个特征参数组成的向量。
4 汽车运行工况构建
4.1 主成分分析
由于初始特征参数矩阵维度较高,不利于后续的分析计算,所以通过主成分分析方法消除特征参数之间的相关性,然后找出几个主成分代替原来众多的变量,以达到数据降维的目的。
首先,为了消除量纲的影响,对特征变量进行标准化:
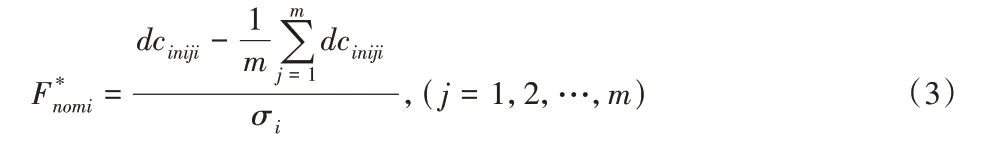
式中:σi—第i个特征参数向量的标准差。
特征参数标准化矩阵:

利用PCA算法对标准化的参数矩阵进行降维处理,得到的主成分为标准化以后的特征参数的线性组合:

式中:Con×n—主成分和标准化特征参数的相关系数矩阵。相关系数的绝对值越大,说明主成分和特征参数的相关性越强。
文献[14]表明,当主成分累积贡献率超过85%时,即可充分代表原始数据信息。
由图5 可知,选取前7 个主成分的累积贡献率即可达到87.2%。根据选取的主成分构成运动学片段新的特征参数矩阵PCm×7。

图5 主成分分析结果Fig.5 Results of PCA
4.2 聚类分析
采用模糊C均值聚类算法对降维后的特征参数矩阵PCm×7进行聚类分析,具体步骤如下:
(1)用值在[0,1]区间的随机数初始化隶属矩阵U,使其满足约束条件:

式中:uij—第i个样本对应第j类的隶属度;c—聚类中心个数。
(2)计算新的聚类中心:

式中:vj—第j个聚类中心;b—平滑因子,一般取2。
(3)计算新的隶属度函数矩阵:

式中:xi—第i个样本。计算新的价值矩阵:

若其值满足阈值则停止迭代,否则回到步骤(2)继续迭代计算。通过以上步骤计算得到每个样本对所有聚类中心的隶属度,然后根据最大隶属度原则确定每个样本点的所属类别。
最终将3020个运动学片段划分为三个簇,将每个簇中运动学片段进行拼接,从而获得三种不同类型的运行工况,如图6所示。

图6 三种不同类型的运行工况Fig.6 Three Different Types of Driving Cycles
根据表2对聚类结果影响最大的主成分pc1与22个特征参数的相关系数进行分析可知:最高车速、平均车速、(0~10)km/h速度段比例是每个片段聚类分析的代表性特征参数,对后续聚类分析影响最大。

表2 pc1与特征参数之间的相关系数Tab.2 Correlation Coefficient Between pc1 and Characteristic Parameters
由表3可知,第一类运动学片段最大车速和平均车速最低,(0~10)km/h速度段比例最高,定义为城市拥堵路况。

表3 每类运动学片段代表性特征参数Tab.3 Representative Feature Parameters of Each Type of Kinematic Sequence
第二类运动学片段最大车速和平均车速高于第一类但低于第三类,(0~10)km/h速度段比例低于第一类但高于第三类,定义为城市畅通路况。
第三类运动学片段最大车速和平均车速最高,(0~10)km/h速度段比例最低,定义为城市郊区路况。总之,三类片段的代表性特征参数区别明显。这说明聚类效果较好,能够满足预期要求。
4.3 类内工况构建
4.3.1 构建运动学片段库
利用FCM聚类得算法到三类运动学片段库,以及每个片段对相应聚类中心的隶属度。为了进一步减少后续运算的复杂度,将每类中的片段按照隶属度从大到小进行排序。每类选取前10%的运动学片段构建备选片段库1。
聚类分析前,为了对运动学片段特征参数矩阵降维,选取了累计贡献率为87.5%的前7个主成分来表征所有数据信息,导致部分数据信息流失。
为了保证运动学片段筛选过程的合理性和准确性,通过对运动学片段库1中每个片段和片段所属簇内所有片段的初始特征参数按式(10)进行相关性分析,保证筛选过程中数据信息的完整性。按照相关性排名每类选取一定数量的运动学片段构建运动学片段库2。
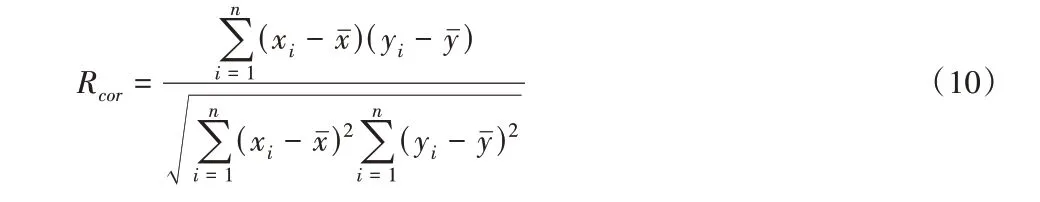
4.3.2 类内工况构建方法
根据项目要求,将目标城市典型运行工况的时间区间设为(1500~1800)s[15]。基于各个工况的持续时间在总工况的持续时间占比,确定每类工况的最终时间范围:

式中:Ti—第i类工况在构建工况中的持续时间;ti—代表最终合成工况的持续时间;toverall—所有工况块数据的持续时间;tbuildingcycle—所要构建工况的总时间。
根据式(11)可以得到目标城市三种不同交通工况的时间比例和时间范围,如表4所示。

表4 不同工况的时间比例和长度Tab.4 Time Proportion and Length of Different Driving Conditions
以加速时间比例pa、减速时间比例pd、停车时间比例ps、巡航时间比例pc、平均车速va、车速标准差vs、加速段平均加速度aaa、减速段平均减速度ada、加速度标准差as,共9个特征参数作为判定准则[16−18],计算各类工况中符合时间限制的片段组合所对应的特征参数误差,选出平均误差低于10%,且最大误差低于13%[19]的片段组合,构建类内工况片段库。
4.4 运行工况合成
按照城市拥堵、城市城区、城市郊区的顺序连接各类工况的工况片段,计算每个工况组合和原始测试数据的速度加速度联合概率分布矩阵之间的卡方值,找出卡方值最小的工况组合作为最终构建的运行工况。所构建的典型运行工况,如图7所示。

图7 目标城市典型运行工况Fig.7 Typical Operating Condition of Target City
该工况由12个运动学片段组成,总计时长为1752s。
5 典型运行工况有效性检验
为了检验所构建的工况能否满足开发要求,给出试验数据与典型运行工况的特征参数相对误差,如表5所示。

表5 典型运行工况与试验数据的特征参数对比Tab.5 Comparison of Characteristic Parameters Between Typical Operating Conditions and Measured Data
从表5中数据可知:典型运行工况的整体特征参数与实测数据相比,各特征参数误差均小于10%,平均相对误差为4.22%,基本满足开发要求。
为了进一步检验典型运行工况和试验工况的吻合度,将车速分为[0,10),[10,20),[20,30),[30,40),[40,50),[50,60),[60,70),[70,+∞)共8个区间,加速度分为[−3,−2),[−2,−1),[−1,0),[0,1),[1,2),[2,3)共6个区间,统计试验工况和典型运行工况的速度−加速度联合分布概率,如图8所示。
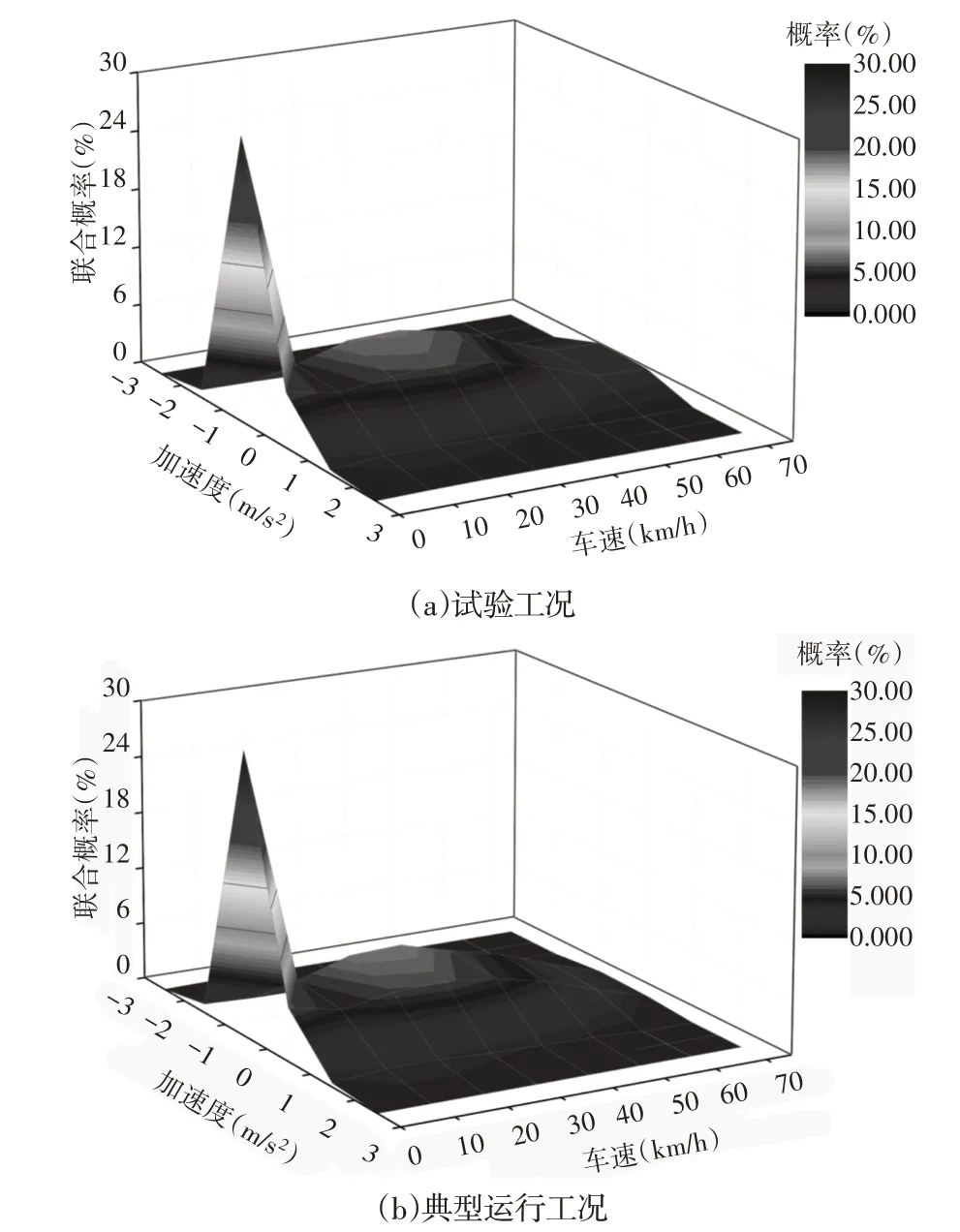
图8 速度−加速度联合概率分布Fig.8 Velocity−Acceleration Joint Probability Distribution
从图中可以看出,试验工况和典型运行工况在车速大于60km/h,加速度在[−1,1]的联合分布区间概率有较明显的差别。这是因为该区间内的试验工况的统计量较少,分布概率均低于2%,工况构建过程中很难覆盖,其他联合分布区间虽然也有略微差别,但是速度−加速度联合分布的整体趋势基本一致。
此外,采用试验车型的Cruise仿真模型计算在典型运行工况下的百公里油耗进行验证。
在仿真过程中主要修改变量为空调功率,采用实际测试过程中的平均空调功率进行仿真,计算结果为10.91L/100km,实测油耗为11.12L/100km,相对误差为1.89%。
这表明所构建的典型运行工况能够较好体现试验车型在实际道路下的油耗水平。
通过以上分析表明,所构建的运行工况与道路工况有较好的一致性,并且较准确地反映试验车型在目标城市道路工况下的油耗水平。
6 运行工况对比分析
将所构建的HEV典型运行工况与NEDC和WLTC循环工况进行对比,结果,如表6所示。

表6 循环工况特征参数对比Tab.6 Comparison of Characteristic Parameters of Driving Cycles
与NEDC 循环工况相比,典型运行工况的加速/减速时间比例较高,平均车速、减速段/加速段平均减速度较小;与WLTC 循环工况相比,所构建工况的停车时间比例较高,加速时间比例、减速时间比例、巡航时间比例、平均车速均较低。
综上,NEDC和WLTC循环工况都与所构建的运行工况差异较大,且在平均车速方面均存在明显差异。
这说明,相较于NEDC和WLTC循环工况,所构建的运行工况更能反映试验车辆在目标城市的运行特征。
7 结语
(1)运行工况构建过程中,片段优选过程本质上属于遍历寻优。通过聚类分析完成运动学片段的分类和第一轮优选,然后利用相关性分析作为主成分分析的补充,保证所选片段信息完整的前提下,继续缩小寻优范围。
通过时间限制和特征参数误差检验构建类内工况,最后通过速度−加速度联合分布概率的相似性检验选出最终的运行工况,在保证工况有效性的前提下提高了算法的效率。为混合动力汽车运行工况构建提供一定的理论和数据指导。
(2)通过特征参数分析和速度−加速度联合分布概率检验,典型运行工况与试验工况特征参数平均相对误差仅为4.22%,速度−加速度联合分布趋势相似;通过仿真分析,百公里油耗相对误差为1.89%,表明所提出的运行工况构建方法合理有效。
可以作为混合动力汽车运行工况构建方法之一。
(3)将合成的混合动力汽车运行工况与我国目前采用的NEDC和WLTC测试循环进行对比分析,所构建的典型运行工况平均车速较低,与NEDC和WLTC区别明显,可以作为法规循环工况的补充用于混合动力汽车驱动系统的测试与评价,为混合动力汽车燃油经济性的优化提供依据。
猜你喜欢
空间科学学报(2020年1期)2021-01-14
河北省科学院学报(2020年1期)2020-05-25
重型机械(2019年3期)2019-08-27
中国交通信息化(2019年12期)2019-08-13
制造技术与机床(2018年11期)2018-11-23
装备制造技术(2018年8期)2018-10-17
汽车维护与修理(2018年1期)2018-04-04
制造技术与机床(2017年11期)2017-12-18
作文周刊·小学一年级版(2017年27期)2017-08-10
中国交通信息化(2017年8期)2017-06-06
