
基于增强自适应原型重构模型的小样本图节点分类
2023-02-09 12:01徐钰坪李治江
无线电通信技术 2023年1期
徐钰坪,李治江,2*
(1.武汉大学 图像传播与印刷包装研究中心,湖北 武汉 430079;2.武汉大学 信息管理学院,湖北 武汉 430072)
0 引言
图结构数据在现实生活中十分常见,比如社交网络数据、文献引用网络数据和生物化学领域的分子结构等。但是在很多场景下的图数据会出现标注困难、训练数据匮乏等问题,比如在社交网路中,新注册用户的相关数据有限,需要根据少量的好友关系进行用户身份标签分类或者进行兴趣群组推荐;另外在用户商品推荐网络中,新用户或新商品也需要基于极其有限的数据或拓扑关系进行用户商品分类。这些问题无法依赖传统的大规模图学习进行解决,需要基于小样本学习范式[1]模拟人类快速学习过程,仅通过少量的参考数据完成图上的节点分类任务。与主流的小样本学习方式相同,图数据的小样本学习也遵循两类基本框架,并且都存在着明显的问题:一是基于优化的方法[2-5]需要进行精心调参才能获得较好的性能表现,模型的鲁棒性不足;二是基于度量的方法[6-8]在预测表现上远远比不上传统的基于大规模训练数据的深度学习方法。
通过比较样本与类别原型的相似程度来进行分类是一类经典的基于度量的小样本学习方法[6-7],该方法高度依赖于样本的编码质量,并且对于原型提取过程中的噪声节点比较敏感[9-10]。基于以上假设,本文主要从以下两方面对图数据的小样本学习任务进行优化。首先,基于GNN编码[11]的节点特征学习能够充分利用图数据的拓扑结构进行消息传播和更新,进而更好地学习到图的全局和局部特征;其次,为了降低噪声节点在原型提取过程中的干扰,需要对支持集节点进行重要性评估和权值分配。传统原型提取方案是对支持集节点进行均值化[7]或者加权求和[12],受到图网络全局节点的启发[13],为了在获取类别原型的过程中抑制噪声干扰,并更好地关注到全部支持节点的信息。在支持集中引入哑节点作为初始原型节点,再基于注意力机制进行原型节点的自适应权重分配和特征学习。
基于以上几点考虑,本文提出增强自适应原型重构模型(Enhanced Self-adaptive Prototype Rebuilt , ESPR),即一个基于原型网络框架的元学习模型,用来解决属性图上的小样本节点分类问题。ESPR采用GCN[14]进行节点编码,并在原型提取过程中基于transformer[15]框架对原型节点进行自适应重构,最终度量查询节点与原型节点的距离进行标签预测。ESPR相比于目前最优模型,在准确率和F1值上获得大幅提升,特别是在reddit这类大型图数据集上获得了超过20%的提升效果。总而言之,本文的贡献主要有以下三点:
① 提出了ESPR模型,高效、鲁棒地解决了属性图上的小样本图节点分类问题。在4个数据集上进行了对比测试实验,结果表明ESPR能够获得3%~20%的性能提升;
② 提出了一种新的原型提取方式,通过构造原型节点进行类别表征,是对图领域度量学习方法的有效补充;
③ 优化了原型学习过程,通过增强自适应方式进行原型重构和特征学习,有效抑制了噪声干扰。
1 增强自适应原型重构模型
本文的算法流程分为元训练和元测试两个过程,整体的模型结构如图1所示。
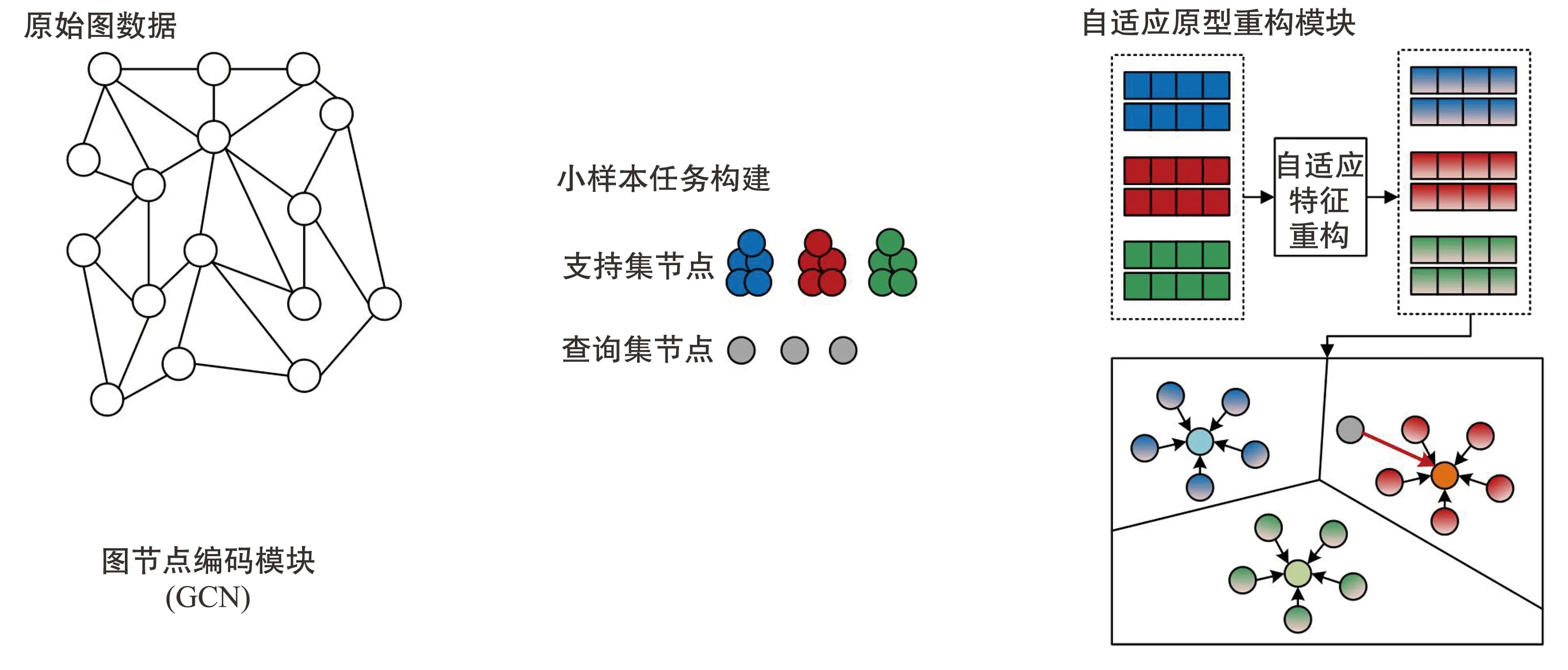
图1 ESPR模型整体结构示意图
在元训练过程中,首先构建一个元训练任务作为一个Episode[6-8],Episode 是一种基本的小样本学习范式,主要通过构建训练任务的方式让模型学习如何根据少量的参考样本对未知样本进行分类。一个Episode由支持集和查询集构成,利用支持集中的参考样本指导查询集中样本的分类,如式(1)所示。
(1)
式中,Tt表示一个任务,St表示支持样本集,Qt表示查询样本集,每个元学习任务针对N个类别的样本进行分类,其中支持集中的每个类别具有K个样本,查询集中的每个类别具有M个样本。在训练过程中,模型不断降低查询集样本的预测损失直到收敛,最终获得对新任务的泛化能力。
在元测试过程中,也需要构建与元训练任务类似的元测试任务,不同的是该过程不需要进行节点特征学习,而是直接提取节点特征后构造类别原型节点,然后进行原型节点的自适应重构,最后进行节点类别判断。
1.1 图节点编码模块
图编码过程是对邻居节点信息的迭代聚合和更新,学习图结构信息和节点特征信息以获得每个节点新的特征向量。本文采用GCN作为节点特征学习器,通过对局部邻居信息进行循环聚合和压缩来获取节点的潜在语义表征,具体操作如下:
① 基于空间连接性获取每个节点的直接邻居集合;
② 对邻居节点进行聚合操作(如求和、求均值计算);
③ 使用聚合结果更新中心节点隐含状态。
第l层GCN有如下定义, AGGREGATE表示步骤①和步骤②的聚合过程,UPDATE表示步骤③的更新过程:
(2)
(3)

在图结构中不同节点之间通过边相连,而通过多条边头尾相连的节点之间存在长距离依赖关系,为了能够获取这些节点之间的长距离依赖关系,可以将几个图卷积层进行堆叠。值得注意的是,如果堆叠层数过多可能会导致过平滑现象[16],所以本文中只使用了两层GCN。
1.2 自适应原型重构模块
类别原型是指在一个样本簇中,存在一个表征可以归纳描述该簇样本的基本特点,从而作为该簇的原型表征[7, 17]。但是对于常见的类别原型度量学习,提取类别原型的过程只采用了简单的、不可学习的方法,比如对支持集样本进行均值化[7, 18]。考虑到构建支持集时是通过随机采样的方式进行训练样本的提取,采集到的部分样本可能是噪声或离群点,即对类别原型正确表征的贡献很小,甚至起了不良效果[19]。因此无参的、不可学习的类别原型提取方法是一种对噪声高度敏感的、极度依赖训练样本构建质量的方法[10]。针对以上问题,部分工作对原型提取过程进行了优化[12, 20-21],本质上是通过评估每个标签的样本信息率和重要程度来优化原型提取的结果,实际上可以看作是一定程度的修正操作,但是这些方法尚不能达到令人满意的效果。
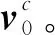
(4)

(5)
为了能够将任务无关的编码转化为任务相关的编码,一般将查询节点和支持节点放入同一个序列中进行转化,或者同时基于查询节点和支持节点的交互来获取各个支持节点的权重分配[12, 22]。但是这些做法会在提取原型的过程中引入查询节点的信息,最终会给与查询节点类别不同的原型表征造成干扰。本文为了获取纯粹的类别原型,在原型提取的过程中不引入查询节点的信息,而是基于自注意力机制只对支持集节点进行自适应学习。
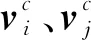
(6)
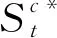
经过注意力分配和加权求和后得到的转化哑节点作为最终的类别原型,如下所示:
(7)
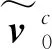
利用这些学习到的类别原型可以构建一个softmax分类器,通过比较查询节点到各个类别原型的距离来获取属于相应类别的可能性,如式(8)所示:
(8)
dEuclidean=‖vi-vj‖2。
(9)
在训练过程中,每个任务的目标是减少查询集中所有查询样本的分类损失,因此损失函数有如下定义:
(10)
2 实验与分析
2.1 实验设置
2.1.1 数据集
目前常用的图数据集包括引文网络数据集(cora/citeseer/Pubmed)、社交网络数据集(BlogCatalog/Reddit)、生物化学结构数据集(PPI)等。由于本文研究的是图结构数据下的小样本节点分类问题,而且要求节点是包含属性特征的单标签节点,所以实验要求的数据集必须满足以下三点要求,以验证模型处理小样本分类能力:① 具有节点特征的属性图;② 每个节点只能属于一种标签;③ 整个数据集中包含的节点类别足够多。
根据以上三点要求,本文选取了以下4个公开数据集。
① Amazon-Clothing[23-25]是根据亚马逊上“Clothing, Shoes and Jewelry”相关商品构建起来的图结构数据,其中每个节点表示一个商品,节点的特征由商品的描述转化而来,节点的标签是商品所属的类别。边关系表示两个商品被同时浏览过。本文将数据集标签划分40类训练样本、17类验证样本和20类测试样本。
② Amazon-Electronics[23-25]与上一个数据集类似,不同的是两个电子商品之间的边关系表示它们被一起购买过。数据集标签划分成“训练/验证/测试”的数目类别为“90/37/40”。
③ DBLP[26-27]是引文网络,网络节点为文章,节点特征由文章摘要转化得到,两篇文章之间存在引用关系则构建边。最终数据集标签划分成“训练/验证/测试”的数目为“80/27/30”。
④ Reddit[14, 28]是一个基于大型在线论坛Reddit建立起来的post-to-post graph。节点表示用户发的帖子,节点标签表示帖子所属的社区或“subreddit”。当两个帖子被同一个用户评论时则构建边关系。本文按照16/10/15的比例划分训练集、验证集和测试集。
2.1.2 模型设置
图节点编码模块采用两层GCN对节点特征进行学习,两层GCN的输出维度分别为64和32。自适应原型重构模块直接采用transformer API进行模型设计,其中transformer encoder layer 包含了4个头,feedforward层的输出维度为64。模型中的三个模块均采用了相同的ReLU激活函数,并且dropout都设置为0.5。在训练过程中,不同模块有独立的Adam优化器,学习率均为0.005。
本文共采用了8种对比基线模型,各个模型的基本特点如表1所示。

表1 对比基线模型介绍
2.2 实验结果
针对每种数据集,本文设计了两种小样本学习的任务场景:5 ways 5 shots和10 ways 5 shots。在测试过程中,查询集的样本数目与支持集样本数目相同。为了避免实验结果的偶然性,每个任务场景下都要随机进行50次meta-test tasks,并将这些测试结果的平均值作为模型在该场景下的性能评价。采用Accuracy(ACC)和Micro-F1(F1)两个评价指标作为实验评价标准。
重复以上过程10次并求均值,最终获得的模型评价结果如表2所示。

表2 4个数据集上不同模型的对比结果
通过对所有的实验结果观察分析,可以得到以下结论:
① 实验结果表明,本文提出的方法均优于所有的对比基线模型,不同的数据集提升的幅度不同,其中针对Reddit数据集的准确率和F1值的提升最大,比原来最优模型GPN的实验结果最高提升了20%左右。即使是性能提升幅度较小的DBLP数据集,准确率和F1值的提升幅度也在2%~3%左右。至于Amazon-Clothing数据集和Amazon-Electronics 数据集,MSPR获得的性能提升效果也非常可观,最终的测试结果充分证明了ESPR的有效性。
② 总体而言,DeepWalk和node2vec这两种基于无监督学习的图编码方式的测试表现最差。因为如果要让所有的节点都获得较好的特征编码结果,往往需要构造大量的节点序列进行训练。当面对像Reddit这种大型图结构数据时,计算效率十分低下。
③ GCN和SGC的表现也一般,但是由于是GNN-based的方法,利用了图的拓扑结构进行节点信息的传播和特征的学习,能够有效提高特征学习效率和质量,因此测试表现普遍优于DeepWalk和node2vec。但是GCN和SGC这种半监督学习方法往往依赖于大量的标记样本进行训练,而在小样本的场景中可用于训练的标记样本非常少,因此GNN-based的方法具有较大的局限性。
④ 对于PN、MAML这些元学习方法,在实验中各有优势和不足。原型网络是一种基于度量的小样本学习方式,它对于样本的特征十分敏感,当出现节点的特征学习较差或者在计算类别原型时有噪声节点干扰等情况时,模型的性能就会大大降低。MAML是一种基于参数优化的元学习方式,模型表现的稳定性不足,而且需要进行大量的参数调优才能获得性能良好的模型。
⑤ Meta-GNN和GPN的表现均大幅优于其他所有基线模型。Meta-GNN是将MAML与GNN进行结合,能够较好地适应图结构数据上的小样本节点分类问题。GPN将GNN与PN结合,使用GNN进行节点表征学习,同时引入节点重要性评分对提取的类别原型进行优化,所以能够获得相对稳定且良好的实验结果。相较于GPN,本文舍弃了节点评分器,而是对支持集中的每个样本进行自适应权重分配,进而获得类别原型,最终结果表明MSPR大幅度优于以上两种对比模型。
2.3 模块消融实验
为了证明各个模块的有效性,本文还设计了额外的实验进行消融分析。在5 ways 5 shots测试场景中,将模型中的各个模块进行逐步去除或简化,通过比较准确率的变化来比较模型性能。
ESPR是本文提出的完整模型,MLP表示只采用简单的全连接层对节点进行编码,w/GNN表示使用图编码模块后的模型,w/PN表示使用本文提出的自适应原型重构模块进行小样本学习。最终消融实验的结果如表3所示。
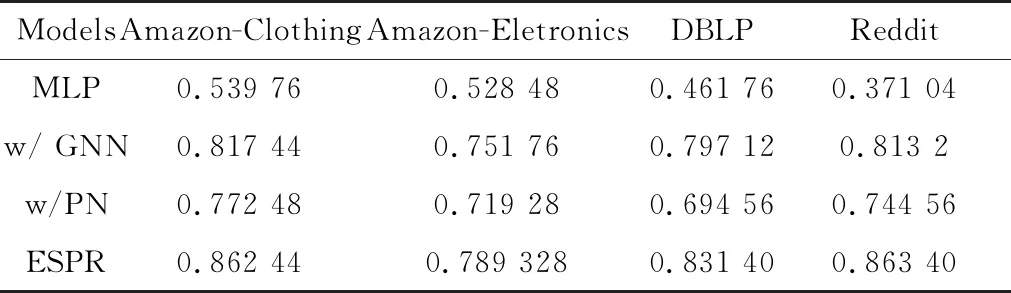
表3 5 ways 5 shots任务上消融实验结果
实验结果表明,将GNN编码替换全连接编码后,各数据集上的预测准确率得到了大幅提升,说明图编码层能高效地进行节点的表征学习,特别是对于Reddit这类大规模图数据,GNN算法比普通的MLP编码学得更快,汇集的数据更多。另外,在不引入图编码,仅使用MLP编码和原型学习时,模型也能够获得性能的明显提升,表明所提出的原型提取模块能够有效抑制噪声和其他无效信息的干扰,进而提高模型的性能。
3 结论
本文针对标注数据匮乏时的图节点分类问题提出了ESPR模型,为了获得高质量的节点编码,采用双层GCN进行特征传播和表征学习;同时针对噪声高度敏感问题,对所构造的原型节点进行自适应重构,最后通过度量计算进行节点分类。对比实验和消融实验充分验证了ESPR模型的有效性,抑制了噪声和离群点的干扰,是一种简单的、可迁移性强的图度量学习方法。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
小资CHIC!ELEGANCE(2021年45期)2021-01-11
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
英美文学研究论丛(2018年2期)2018-08-27
民族古籍研究(2018年1期)2018-05-21
剑南文学(2016年14期)2016-08-22
新校长(2016年8期)2016-01-10
人间(2015年20期)2016-01-04
