
融合自注意力的关系抽取级联标记框架研究
2023-02-14 10:31肖立中臧中兴宋赛赛
计算机工程与应用 2023年3期
肖立中,臧中兴,宋赛赛
上海应用技术大学 计算机科学与信息工程学院,上海 201418
知识图谱是近些年非常热门的一个研究方向,它在很多方面都展示出了不错的应用效果,例如问答系统、搜索引擎、推荐系统等。随着互联网的不断发展和进步,人类世界存在着海量的信息和数据。知识图谱不仅能够对这些数据进行结构化的存储,还可以在查询的时候更加全面地了解相关知识,提升搜索的深度和广度。医疗领域知识图谱在智能医疗问答领域扮演着重要的角色,患者利用医疗问答系统不仅能够初步地进行自我诊断,还能够在一定程度上节约医疗资源。知识图谱主要是由实体关系三元组构成,如何从海量的数据中抽取出实体及实体间的关系对于构建知识图谱是至关重要的一步。
从非结构化的文本中抽取出形如(head,ralation,tail)或者(h,r,t)的实体对以及关系三元组是自然语言处理领域和知识图谱构建过程中一项十分重要的任务。传统的流水线式方法,将实体识别和关系抽取视为两个独立的子任务,首先识别出句子中所有的实体,然后对所有的实体对进行关系分类,虽然这种方法比较灵活、容易操作,但是这种方法忽略了两个任务之间的相互联系,无法充分利用输入文本的特征信息[1],上一阶段的错误不能够在下一个阶段进行纠正,容易形成错误传递[2],影响模型的准确率。
因此,需要构建一种模型来同时获得实体对及其存在的关系,Li等[2]、Miwa等[3]以及Ren等[4]提出了基于特征的模型,这些方法对于特征工程有较强的依赖,需要大量的人力,耗费时间成本巨大。随着神经网络和深度学习的发展和不断地被深入研究,最近的一些工作提出了基于神经网络的模型,例如Zheng等[5]、Zeng等[6]以及Fu等[7]。虽然这些方法可以使用同一个模型对实体和关系进行抽取,实现了参数共享,减少了错误的累积,但是却并不能够解决实体重叠的问题以及同一句子中多对实体多对关系的问题。实体重叠是指一个句子中的不同关系三元组间存在某些实体相同,导致模型抽取关系不完全[8]。针对以上问题进行分析,本文提出了一种融合自注意力机制的级联标记框架Att-CasRel,不再将关系作为实体对的离散分类标签,转而将关系作为从头实体到尾实体的映射函数。首先识别出句子中所有可能的头实体,然后针对每一个头实体,使用特定关系的尾实体标注器,同时识别出所有可能的关系和相对应的尾实体。本文的主要贡献有以下几个方面:
(1)针对医疗领域文本在Bert模型的基础上继续进行训练,使得本文使用的CB-Bert(Chinese biomedical bert)模型能够更好地对文本进行编码。
(2)本文在CB-Bert编码器的基础上实现了一种级联标记框架,使得框架能够充分利用预训练的CB-Bert的强大能力和该标记框架的优势。该标记框架能够针对识别出的头实体同时识别出对应关系及与之关联的尾实体,使关系标签成为头实体到尾实体的映射函数,大大减少了误差累积和信息冗余问题。
本文在框架中融合了自注意力机制,相比较于对特征向量使用简单的求平均值的做法,能够更好地提取文本的语义特征,更加充分地考虑文本中不同位置信息的重要程度,提升了模型的性能。
1 相关工作
从非结构化的文本中抽取关系三元组是自然语言处理的一项重要任务,是信息抽取研究领域的一项研究热点,同时也是构建大型知识图谱的一个重要步骤,如Konwledge Vault[9]。
早期的工作将实体识别和关系抽取作为两个独立的任务,如Mintz等[10],他们将抽取关系三元组分为两步,首先识别出输入句子中的所有实体,然后对抽取到的实体进行配对,进行关系分类。这类方法虽然取得了不错的效果,但是容易造成错误累积的问题,实体识别阶段产生的误差将传递到关系抽取阶段,并且忽略了关系和实体之间的相互依赖,无法充分利用输入信息。为了解决这些问题,有研究者提出了实体关系联合抽取的方法,传统的基于特征的模型严重依赖于特征工程并且需要大量的人力,如Li等[2]、Miwa等[3]以及Ren等[4],因此特征工程阶段的结果将直接影响后续任务的结果,对于特征工程的要求很高。
随着神经网络的快速发展,最近一些研究提出基于神经网络的方法,虽然取得了不错的效果,但是现有的一些神经网络模型例如Miwa等[11]提出仅通过参数共享而不是联合解码来实现联合抽取。为了实现关系三元组的抽取,他们仍然是将实体识别和关系抽取作为两个独立的任务来进行。独立的解码过程造成了独立的训练目标,这将会影响抽取关系三元组的效果。Zheng等[5]提出一种联合标记策略,实现了联合解码过程,他们将关系三元组抽取问题转化成序列标注问题,不需要再使用命名实体识别和关系分类这两个步骤,由于提出的标记策略将实体和关系整合在一起,因此该方法可以直接获取关系三元组。Dai等[12]在此基础上使用多轮标注方法,有效地解决了实体嵌套的问题。
尽管之前的工作已经能够解决联合抽取的问题,但是关系三元组重叠的问题仍然没有得到较好的解决。最近的研究者,如Fu等[7]提出了一种图卷积网络来解决此问题,乔晶晶等[13]提出一种路径聚合算法来进行关系抽取。尽管这些研究取得了一定的成果,但是他们仍然是将关系作为实体对的离散的分类标签,使得模型难以解决重叠三元组的问题。Zhao等[14]提出了一种基于异构图神经网络的表示迭代融合关系抽取方法,将关系和词建模为图上的节点,并通过消息传递机制来得到更适合关系抽取任务的节点表示。Liu等[15]提出了一种基于注意力的联合关系抽取模型,该模型设计了一种有监督的多头自注意机制作为关系检测模块,分别学习每种关系类型之间的关联来识别重叠关系和关系类型。Lai等[16]提出了一种基于序列标注的联合抽取模型,该模型在句子编码信息之后添加多头注意力层以获得句子和关系的表征,并对句子表示进行序列标注来获得实体对。
早先的方法将实体关系抽取任务作为一种分类任务,这种在实体识别阶段出现的错误无法在关系分类阶段进行纠正,导致误差累积,严重影响关系抽取的准确性,后来的研究者提出联合抽取的方式,但是仍然存在实体共享的问题。本文基于以上研究,提出一种新的级联标记框架Att-CasRel,并在解码阶段融入了自注意力机制,将关系标签作为从头实体到尾实体的映射函数,有效地解决了关系抽取中存在的实体共享和错误传递等问题。
2 Att-CasRel框架结构
实体关系抽取的目标是抽取出一个句子中所有可能的形如(h,r,t)的关系三元组。由于不同的关系三元组可能共享同一个实体,为此,本文提出一种融合自注意力机制的级联标注框架,来同时从句子中抽取出多个关系三元组。首先使用经过预训练的Bert编码器对输入文本进行编码,得到每一个字符的向量表示形式,然后运行头实体标注器识别出输入句子中所有的头实体;对于识别出的每一个头实体,再运行特定关系下的尾实体标注器。不同于头实体识别阶段,在运行特定关系尾实体标注器阶段,不仅仅需要对Bert编码器的输出向量hn进行编码,还将识别出的头实体的向量表示考虑在内,针对每一个头实体,通过自注意力机制,为头实体中的每一个字符分配不同的注意力权重,得到该头实体的加权向量表示,将该向量表示和Bert编码器输出相加所得到的结果作为尾实体标注器的输入,从而识别出在特定关系下与该头实体相对应的尾实体。Att-CasRel总体框架如图1所示。

图1 Att-CasRel框架图Fig.1 Att-CasRel frame diagram
2.1 CB-Bert编码器
编码器模块主要是提取句子的特征信息,该特征信息将会输入到后续的标注模块中,Devlin等[17]提出的Bert模型一经提出,便刷新了自然语言处理领域很多子任务的SOTA模型。然而,Bert模型是在维基百科等语料库上进行训练的,在中文医疗领域,由于存在大量的专业术语,这对于Bert而言是一个很大的挑战,主要原因在于医疗领域的词向量分布不同于维基百科语料库,Bert不能够有效地对医疗领域文本进行有效的编码。Gururangan等[18]指出,在特定领域或者较小的语料库上对语言模型进行再训练可以获得性能的提升。因此,本文针对上述问题,对于Bert模型进行再训练,采用CMeIE(Chinese medical information extraction)数据集中的文本,对于Bert模型进行训练,使其对于医疗领域文本能够更好地进行编码,将训练好的Bert模型命名为CB-Bert,Bert模型结构图如图2所示。
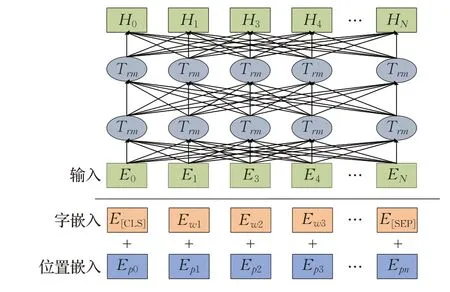
图2 Bert模型结构Fig.2 Bert model structure
Bert模型输入包含三个部分,分别为词嵌入(token embedding)、片段嵌入(segment embedding)和位置编码嵌入(position embedding)。由于分词可能存在错误,因此本文使用字嵌入信息,避免了这部分错误,片段嵌入在关系抽取任务中不适用,因此本文舍弃这部分嵌入信息,将字嵌入信息Ex和位置嵌入信息Ep相加得到输入的向量E,随后将输入向量E经过第一层及后续N-1层的Transformer网络得到文本的向量表示HN,如公式(1)和(2)所示:
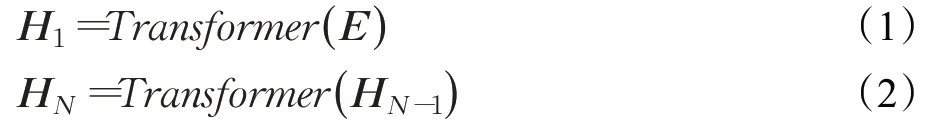
其中,HN为句子经过N层Transformer网络编码后的输出。该向量将作为后续步骤的输入。
2.2 级联标注器
级联标注部分是本文的重点部分,如图1所示,主要分为两个模块,一个是头实体标注器,另一个是特定关系尾实体标注器,通过两个级联步骤从输入句子中抽取出关系三元组。对于特定的数据集,实体类别是有限的,因此实体间的关系类别也是有限的,因此人为规定好该数据集存在的关系类别。然后,利用头实体标注器从输入句子中识别出所有可能的头实体,然后将所有的头实体在上述的每一种关系类别下去检查是否有对应的尾实体可以与其组成关系三元组,如果有,则将该三元组保存,若没有,则继续检查其他的关系类别。直至将所有关系类别检查完毕,便可识别出句子中所有可能的关系三元组。
2.2.1 头实体标注器
头实体标注器的目标是从输入的句子中识别出所有可能的头实体,通过对N层CB-Bert编码器的输出HN进行解码,便可以得到所需要的头实体。具体方法为使用两个二分类器对HN中每一个字符所对应的编码向量是否是头实体的开始位置或结尾位置进行二分类,如果是,则在相应位置将标签赋值为1,否则赋值为0。详细的操作如公式(3)和(4)所示:

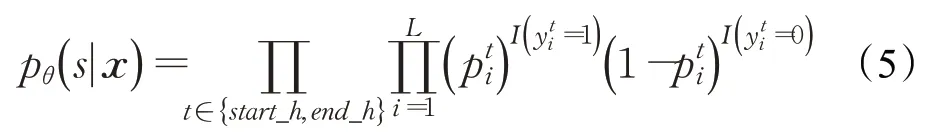
其中,L代表句子的长度,如果z为True,则I(z)=1,否则为0,表示头实体开始位置的二分类标签,表示头实体末尾位置的二分类标签,取值范围为{0,1},参数θ={Wstart,Wend,bstart,bend}。
如果一个句子中存在多个头实体,本文采用就近原则来解决头实体识别可能会出现的交叉问题,将两个距离最近的头实体开始位置和结尾位置所标记的范围视为一个头实体,如图1所示,距离头实体开始位置Steve最近的结尾位置是Jobs,因此会将SteveJobs视为一个头实体,而不是将California所对应的结尾位置和Steve组合起来视为一个头实体,在图1中使用不同颜色来区分不同的头实体。
2.2.2 特定关系尾实体标注器
如图1所示,特定关系的尾实体标注器将同时识别出尾实体及与之关联的关系。其中包含了一系列特定关系的尾实体标注器,所有的标注器将同时识别出每一个头实体所对应的尾实体。不同于头实体标注器,尾实体标注器不仅仅是对CB-Bert编码器的输出HN进行解码,而是同时将头实体的编码向量表示也考虑在内。对于每一个字符的编码向量的具体计算如公式(6)和(7)所示:
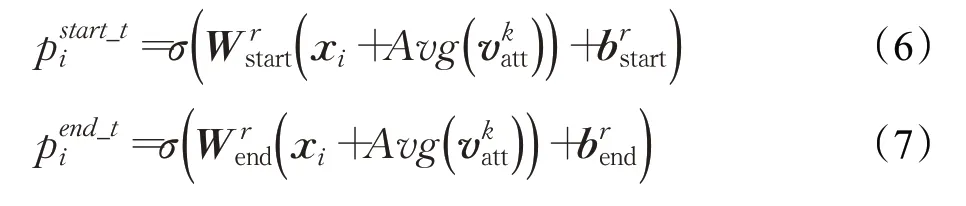
其中,和表示在输入的句子中第i个字符为尾实体的开始和结束位置的概率值。代表在头实体标注器中所识别出的第k个头实体的编码向量表示。对于每一个头实体,迭代地进行编码操作。
2.2.3 自注意力机制
对于医疗领域命名实体而言,为了更加有重点地描述实体所表示的信息,本文引入了自注意力机制,将实体中不同的词向量分配高低不同的权重,这样得到的语义向量便能更加准确地表达实体的含义,从而有效地提高关系抽取的准确性。
注意力机制是由Vaswani[19]最早提出并应用于机器翻译领域,本文借鉴该文中提出的自注意力机制思想,将自注意力机制应用于每一个头实体编码向量,来更好地对头实体的编码向量进行特征提取。计算过程如公式(8)所示:

为了得到Q、K以及V,需要引入三个矩阵WQ、WK以及WV,随机初始化矩阵的值,分别将这三个矩阵与每一个实体的向量表示相乘可以得到对应的Q、K、V。再通过公式(8)计算得到注意力分数,作为权重,通过加权求和计算得到最终的实体向量表示。
由于为某一个头实体的编码向量表示,而每一个头实体可能有多个字符,因此,为了使公式(6)和(7)可以正常计算,需要使xi和维度保持一致,因此采取求平均值的做法对进行降维操作,与xi相加得到给定一个输入句子x和一个头实体h,对于特定关系r的尾实体标注器通过优化公式(9)中的似然函数来识别出尾实体t的边界。
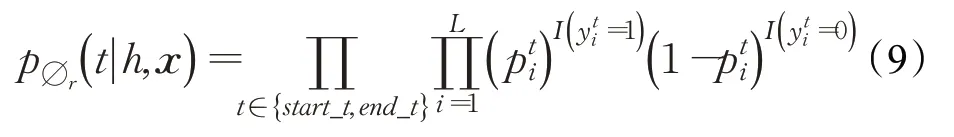
2.2.4 数据似然目标函数
一般的,在训练集D中,给定一个句子xi以及句子中一组可能存在的关系三元组Tj={(h,r,t)},训练的目标定义为最大化训练集的数据似然性L:
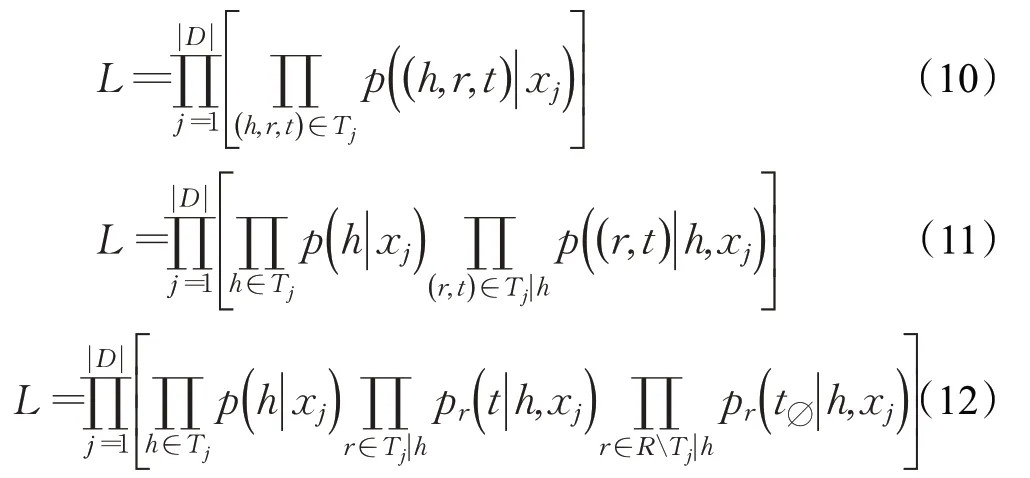
其中,h∈Tj表示三元组Tj中出现的头实体,Tj|h代表在Tj中以h为头实体的三元组;(r,t)∈Tj|h表示在三元组中以h为头实体的(r,t)对,R为所有可能的关系,RTj|h代表在三元组中除了以h为头实体的所有关系。在关系三元组中,所有与头实体h∈Tj有关的关系三元组必然存在相对应的尾实体,其他的关系在句子中一定没有尾实体,因此记作t∅。通过上述目标函数公式,可以总结出以下几个优点:(1)由于数据似然函数是针对三元组的,因此最优化该似然函数相当于最优化最终的评估函数;(2)没有假设同一个句子中可以有多少三元组共享实体,因此解决了重叠三元组的问题;(3)针对关系三元组抽取,提供了一种全新的标注方式,针对句子xj,首先学习一个头实体标注器p(h|xj)来识别出句子中的所有头实体,然后针对每一种关系r,再学习一个尾实体标注器pr(t|h,xj),可以学习到针对固定实体和关系的尾实体。通过这种方式,可以将每一种关系作为一种从头实体映射到尾实体的函数,而不是作为头实体尾实体对的分类标签。
对于公式(12)取对数函数,得到目标函数J(θ):

其中,参数θ={θ,{Φr}r∈R}。使用Kingma等[20]提出的Adam梯度下降法来优化该目标函数,对每个批次的训练数据进行随机打乱操作来避免过拟合。
3 实验与分析
3.1 实验设置
本文使用的数据集为CMeIE,该数据集共包含28 008条数据,关系种类为44种,其中训练集包含17 924条数据,验证集4 482条数据,测试集5 602条数据。根据关系三元组的不同重叠类型,将数据集划分为三种类型,分别称为Normal、Single Entity Overlap(SEO)、Entity Pair Overlap(EPO)。具体统计数据分别见表1、表2。

表1 数据集统计信息Table 1 Dataset statistics
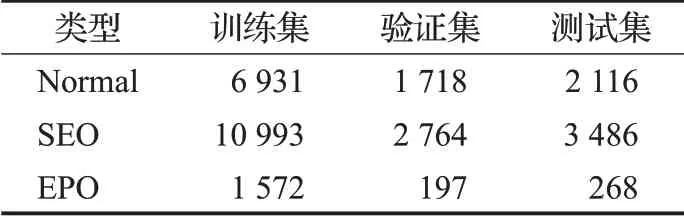
表2 实体重叠类型统计Table 2 Entity overlap type statistics
本文使用的评估标准为准确率(P)、召回率(R)以及F1值。当且仅当一个关系三元组的头实体、尾实体和关系类型均预测正确才认为该预测数据为真,否则为假。
准确率、召回率以及F1值的计算公式分别如公式(14)~(16)所示:

其中,TP表示被判定为正样本,也是正样本的样例,FP表示被判定为正样本,但事实上是负样本的样例,FN表示被判定为负样本,但事实上是正样本的样例。
3.2 实验结果及分析
3.2.1 对比实验
本文将Att-CasRel模型与其他几个关系抽取模型进行了比较,包括NovelTagging[5]、CopyR[6]、GraphRel[7]。实验结果如表3所示,其中最佳的实验结果由粗体标出。通过对比实验结果可以看到,本文提出的模型在该数据集上取得了不错的效果。对比NovelTagging和CopyR两种模型,本文模型在验证集和测试集上F1值获得了较大提升;相较于GraphyRel,在测试集提升了约25个百分点。说明本文提出的级联标记框架在进行实体关系联合抽取任务上有着不错的效果。

表3 对比实验结果Table 3 Comparative experimental results 单位:%
本文使用的数据集中存在大量的共享实体的关系三元组,由于NovelTagging模型只考虑了一个实体只属于一个三元组的情况,根据测试集上的召回率可以看出,该模型对于共享实体的问题没有得到很好的解决。而CopyR和GraphyRel模型相较于NovelTagging模型虽然有一定程度的提升,但是在编码阶段这两个模型均使用BiLSTM模型,本文提出使用经过预训练的Bert模型作为编码器,从实验结果可以看出,使用Bert模型可以大幅提高关系抽取的准确率,说明对于特定领域的实体使用经过预训练的Bert模型能够更好地编码语义向量。
3.2.2 消融实验
由于本模型使用了经过预训练的Bert模型,即CBBert,并且在尾实体解码阶段融入了自注意力机制。为此,本文进行了消融实验来验证预训练编码器和自注意力机制的有效性。使用CasRelRandom表示基础框架,Cas-RelCB-Bert表示使用经过预训练的Bert模型,但是未融入自注意力机制,仅仅是对头实体编码向量进行简单的求平均操作;Att-CasRelRandom表示仅仅融入自注意力机制的模型,而使用随机初始化的Bert模型进行编码;Att-CasRelCB-Bert表示本文所提出的模型。消融实验的结果如表4所示,其中最佳的实验结果由粗体标出。

表4 消融实验结果Table 4 Ablation experiment results 单位:%
对比表4中第一、二行和第三、四行可以看出,无论是否融入注意力机制,在本文提出框架的基础上使用预训练的Bert模型都能在较大程度上提高模型的精度,说明预训练的Bert模型能够更好地获取语言的特征信息,证明了其有效性。对比表4中第一、三行和第二、四行可以看出,引入自注意力机制对头实体进行特征关注也能在一定程度上影响模型编码效果,说明自注意力机制能够更好地对头实体的编码向量进行特征提取,识别出头实体所要表达的真实语义。
另外,通过将表4第一行与表3中其他模型的F1值进行对比可以看出,即使未融入自注意力机制,同时使用随机初始化Bert模型,本文提出的级联标记框架在测试集上的效果仍优于NovelTagging、CopyR和GraphyRel模型,证明本文提出的级联标记框架自身的优越性,从源头上解决了错误传递和实体共享的问题。
本文提出的模型所要解决的另外一个问题是实体共享的问题,因此还针对不同实体重叠类型的句子设计了额外的实验,实验结果如图3所示。

图3 不同重叠类型三元组F1值Fig.3 F1 values of triples of different overlapping types
通过图3的实验结果可以看出,本文所对比的其他模型在Normal、SEO、EPO三种类型的关系三元组抽取上的表现总体呈现下降趋势,反映出随着共享实体的增多,关系三元组抽取的难度在增加,其中Normal类型的抽取最为简单,SEO类型和EPO类型抽取难度相当。本文提出的Att-CasRel模型无论是在Normal还是在SEO或者EPO类型的关系抽取中均表现出了很好的效果,甚至在EPO和SEO类型的关系抽取中获得了比Normal更高的F1值。说明本文所提出的级联标记框架能够更好地解决关系三元组共享实体的问题。
4 结论
为了解决实体关系三元组抽取任务中存在的实体共享以及错误传递等问题,本文提出了融入自注意力机制的级联标注框架,关系类型不再作为实体对的分类标签,而是将关系作为头实体到尾实体的映射函数,重新定义了关系三元组抽取任务,减少了错误传递。对于输入文本,使用经过预训练的Bert编码器进行编码,将文本映射到低维度的向量空间中,更好地表达输入文本的语义信息。在尾实体识别阶段,通过融入自注意力机制,能够更好地对头实体的特征信息进行提取,从而提高关系三元组抽取的准确率。
实验结果表明,在CMeIE数据集上,本文所提出的模型能够更加准确全面地从句子中同时抽取到多个关系三元组,并且有效地解决了实体共享的问题。下一步的工作重点将基于关系三元组抽取的结果进行医疗领域的知识图谱构建,为后续工作,如基于知识图谱的问答系统等任务铺垫基础。
猜你喜欢
核安全(2022年3期)2022-06-29
小雪花·成长指南(2022年1期)2022-04-09
山西大学学报(自然科学版)(2021年1期)2021-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
—— “T”级联
同位素(2019年1期)2019-03-14
计算机技术与发展(2018年12期)2018-12-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
系统工程与电子技术(2016年2期)2016-04-16
原子能科学技术(2015年12期)2015-07-07
