
面向新冠新闻的三阶段篇章级事件抽取方法
2023-02-14 10:31高彩翔王素格王雪婧
计算机工程与应用 2023年3期
郭 鑫,高彩翔,陈 千,2,王素格,2,王雪婧
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
新冠疫情于2019年底爆发,面对该公共卫生突发事件,各国政府积极采取应对措施,新闻媒体实时聚焦疫情事件报道,世界各国学者迅速投身新冠病毒及防治领域的研究。如何从海量的新闻中梳理出疫情发展的脉络,成为科研人员研究的热点问题。
作为信息抽取的一个子任务,事件抽取[1]旨在从非结构化数据中快速获取关键的结构化事件信息。事件抽取主要分为两个任务:事件类型检测[2]、事件论元抽取[3]。事件类型检测是识别句子中的触发词,接着对触发词分类,即对这句话所包含的事件进行分类;事件论元抽取是基于已经获取的事件触发词及事件类型,去识别事件中其余的事件相关论元。
事件检测中的触发词是指句子中能让一个事件发生的核心词语,触发词所对应的类别就是该句子当中所包含的事件类别;事件论元则通常指一个事件的参与者,事件论元角色则是该参与者在事件当中所代表的具体含义[4]。事件抽取任务中存在一些挑战,对于简单事件可以直接从一句话中抽取出事件相关信息。但是对于部分复杂事件而言,句子级抽取不能涵盖事件的全部论元,需要从多个句子中才能完整地抽取出整个事件。如图1所示,s1中“捐赠”触发一个爱心捐赠事件,“中国政府”“加拿大”“11日”在该事件中分别扮演捐赠方、接收方、时间的事件角色。但是只抽取出部分事件论元,在s2中补充了具体的捐赠物,即“医用防护服”“护目镜”“口罩”“隔离衣”。s1和s2组合抽取出该事件中所包含的所有事件论元以及在该事件中所扮演的角色,从而组成一个完整的事件:
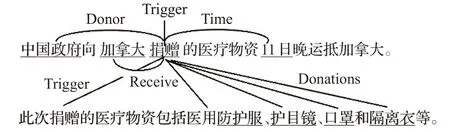
图1 爱心捐赠类篇章级事件抽取实例Fig.1 Doc-level event extraction sample of caring donation
s1:中国政府向加拿大捐赠的医疗物资11日晚运抵加拿大。
s2:此次捐赠的医疗物资包括医用防护服、护目镜、口罩和隔离衣等。
从已有研究近况来看,面向新冠肺炎新闻的篇章级事件抽取还存在如下问题:(1)事件抽取主要还是集中在从单一句子中抽取事件;(2)大部分已有的事件联合抽取工作都是基于ACE 2005数据集进行实验,该数据集仅在句子范围内标记事件联合模型,而且不包含面向新冠肺炎新闻数据集。
针对以上问题,本文的贡献在于以下三点:
(1)本文通过爬虫技术,构建了近6 644条基于篇章级的面向新冠肺炎的精标注新闻数据集以及15万左右的未标注新冠肺炎新闻数据集。
(2)通过改进的TextRank算法抽取关键的事件句,接着利用序列标注从篇章级角度进行事件抽取,进而获取到更加全面的事件信息。
(3)提出一种三阶段的管道方法,结合有监督和无监督模型,在降低人力成本的同时,将句子级事件抽取任务扩展到篇章级,实验证明该方法采用的篇章级事件抽取技术在新冠新闻数据集上的F1指标达到74%,从而验证了方法的有效性。
1 相关工作
已有的事件抽取方法大体上分为三大类:模式匹配方法、机器学习方法、深度学习方法。早期事件抽取方法采用模式匹配技术,首先构造特定事件模板,然后通过模板匹配从文本中提取事件。Riloff等人[5]通过建立触发词词典和事件匹配模式进行事件识别与抽取,但手动标注事件模式耗时费力,需要领域专家的指导。近年来基于机器学习的事件抽取技术得到迅速发展。Li等在2013年[6]和2014年[7]提出基于结构预测的事件抽取联合模型。Liu等人[8]研究了事件与事件关联和主题与事件关联两种全局信息。机器学习方法不仅需要人工设计特征,还需要借助外部NLP工具抽取特征,特征抽取过程中会产生误差。随着深度学习技术的兴起,端对端的神经网络模型被广泛应用于事件抽取。Zeng[9]和Liu[10]分别结合CNN和BiLSTM来进行事件触发器检测。Wu等人[11]应用参数信息训练BiLSTM网络的注意力来进行事件抽取。Chen等人[12]提出了一个HBTNGMA模型用于提取和融合句内和句间上下文信息,增强事件检测。
事件抽取也可以分为句子级和篇章级。现阶段事件抽取的研究主要基于ACE 2005数据的句子级事件抽取任务上,Chen等人[13]提出了一种动态多池卷积神经网络来评估句子的每个部分,捕获句子最重要的信息。Feng等人[14]基于递归神经网络对输入句子进行序列建模来获取整个句子的上下文信息。Nguyen等人[15]提出一种基于RNN的事件识别和角色分类联合学习模型。Miao等人[16]提出CNN-BiGRU模型,通过CNN获取词级别特征,BiGRU获取句子级特征。Ding等人[17]提出分层语义融合模型。Wu等人[18]提出FB-Latiice-BiLSTM模型,对仅能捕获字粒度语义信息的BiLSTM-CRF模型进行词语和实体维度的信息增强,但句子级的事件抽取会造成论元角色的缺失,忽略重要事件信息。近年来篇章级事件抽取也有所突破。Huang等人[19]利用基于管道的方法进行篇章级事件抽取。仲伟峰等人[20]提出基于自注意力机制的实体事件联合标注模型。Yang等人[21]基于句子抽取结果,利用上下文元素补齐策略得到篇章事件结构化信息。Du等人[22]将文档级事件角色填充符提取形式化为端到端序列标记问题。关于新冠事件抽取,Dimitrov等人[23]构建了COVID-19的语义标注Tweets语料库。Wang等人[24]提出从Twitter中抽取COVID-19事件。
综上,现有的新冠数据集大多数是基于英文语料库,且篇章级事件抽取任务存在输入篇幅过长的问题。本文构造中文新冠新闻数据集来扩充语料库,并提出一种事件句抽取的三阶段篇章级事件抽取方法。
2 三阶段COVID-19事件抽取方法
2.1 整体框架
本文提出一种基于三阶段的管道方法来实现篇章级的事件抽取。图2描述了事件抽取模型的总体架构。模型主要包含3个阶段:(1)事件类型识别,利用无监督算法进行事件类型分类;(2)事件句抽取,基于改进的TextRank算法进行含有论元的事件句抽取;(3)篇章级事件论元抽取,利用BiLSTM-CRF的序列标注模型,对事件句进行预测标注,采用拼接技术完成篇章级事件抽取。最终利用论元补充得到完整事件信息。
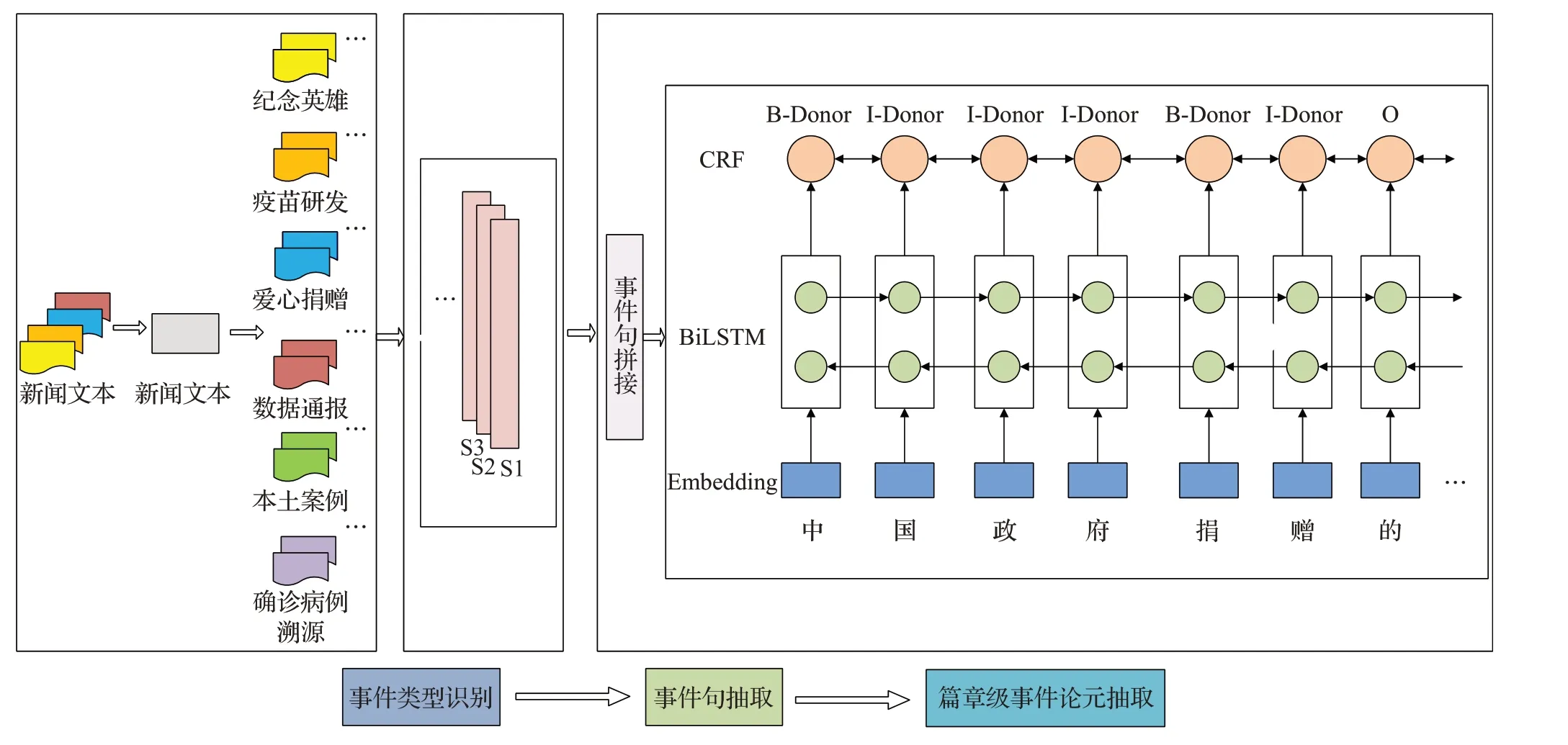
图2 篇章级事件抽取模型框架Fig.2 Framework of document-level event extraction model
2.2 事件类型定义
已抓取的新冠肺炎新闻数据集根据预定义事件类型采用多人协同标注方式。根据卡帕值将事件大概分为六类,分别是确诊病例溯源、数据通报、本土案例、爱心捐赠、疫苗研发和纪念英雄,在每个大类下建立不同的触发词和与之对应的论元角色。如表1所示。

表1 新冠肺炎新闻事件类型Table 1 COVID-19 news event types
2.3 事件类型识别
事件类型识别是发现事件的触发词并为其分配预定义的事件类型。只有识别出事件类型,才能指导事件句的抽取,并进行相应事件的要素抽取。
输入是一个文档的集合D={d1,d2,…,dl},同时还需要聚类的类别个数为t;然后算法会将每一篇文档di在所有的主题上分布一个概率值p;这样每篇文档都会得到一个概率的集合di={dp1,dp2,…,dpt},通过概率值来对每篇文档进行聚类。
为了在大量的新闻中快速区分各种事件类型,采用无监督聚类算法来分类。LDA和KMeans模型被广泛应用于文本分类。
2.4 基于衰减机制的TextRank事件句抽取
2.4.1 事件句分布统计
一般新闻类的文章,事件句出现在段首或者段尾的情况相当普遍,大多数都采用先总后分的方式,并且段落之间存在联系可能不是那么紧密,但是段落本身结构更紧凑的情况。通过统计事件句在篇章中的分布,得到如图3的汇总情况。
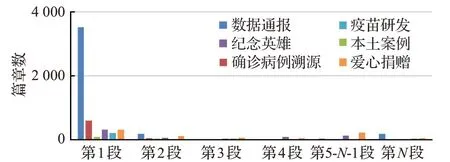
图3 新冠新闻事件句分布情况Fig.3 Distribution of COVID-19 news event sentences
2.4.2 事件句抽取
事件句是包含事件触发词和事件论元的句子。由于事件句基本上是一篇新闻中较为重要的摘要句,为了从大量新闻中快速找到事件句,采用TextRank算法[25]来抽取。TextRank算法是一种基于图的用于关键词抽取和候选句抽取的排序算法,通过把文本分割成若干个句子,构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,给新闻正文的每个句子进行打分,之后选取排名靠前的k个句子最后抽取排名高的句子,作为文本候选句。然而原始的TextRank算法仅利用文本自身的信息进行抽取,不能充分利用词语之间的语义相关等信息。基于此,提出基于衰减机制的词嵌入TextRank算法。根据图3统计可知,事件句往往会在段落开始位置提及。设计加权因子decay_rate,即对每个段落的段首做适当的加权,往后逐渐衰减,呈梯度模型。decay_rate取值范围为(0,1],值越小,倾斜越大,默认为1代表无任何倾斜。
词语间语义信息可以通过预训练的词向量来实现。首先对给定的篇章级文本d进行了断句处理,利用规则的方法进行断句di={s1,s2,…,sm};然后利用jieba分词技术将句子进行分词,得到每个句子的词集合si={w1,w2,…,wn};接着利用Word2vec将文档集中所有词汇进行向量表征,在生成词向量之后,基于Word2vec模型实现句子中每个词语相似度的计算进而计算句子相似度。即根据s1的句子,找到s1中第一个词语在s2所有词语中最大相似值的词语,再依次找到s1中第二个,第三个,直到第n个词语在s2所有词语中最大相似值的词语,取平均值作为s1和s2句子的单项匹配pipei_reverse(s1,s2);接着,同理反过来计算s2和s1句子的单项匹配pipei_reverse(s2,s1);最后取双向匹配的平均值作为s1和s2的句子相似度。
2.5 基于BiLSTM-CRF的新冠新闻事件抽取
为了实现对新冠肺炎新闻事件的抽取,本文构建基于BiLSTM-CRF的事件抽取模型。双向长短期记忆网络(BiLSTM)具有捕获数据的时序性和解决长序列信息依赖问题的优点,能主动学习新冠肺炎新闻事件的抽象特征和提高检测性能。条件随机场层(CRF)使用条件随机场模型对全连接层的输出进行解码,能有效地考虑了序列前后的标签信息,通过学习标签间的约束条件提升标签预测的准确性,得到最终的预测标签序列。事件抽取模型的具体步骤如下:
在预处理阶段,本文采用word-embedding将文本的每个字符映射成一个字符向量,即输入向量s={x1,x2,…,xn},其中n表示该句中字符个数,xi表示文本中每一个维度的数据。
首先,将s作为神经网络的输入,得到输入层输出向量Oi={o1,o2,…,on}。其次,将Oi输入到BiLSTM层前向的LSTML,通过前向学习输出特征向量q={q1,q2,…,qn},qn为经过BiLSTM层后每一维度的数据;将Oi输入到BiLSTM层后向的LSTMR,通过后向学习输出特征向量h={h1,h2,…,hn};将前向特征q和后向特征h进行拼接,得到BiLSTM提取出的抽象特征b=[q:h]={q1,q2,…,qn,h1,h2,…,hn}。然后,经过softmax层,得到网络输出结果,做论元角色类别的分类处理。最后,加上CRF层融合。CRF层的作用在于加入一些约束来保证最终预测结果是有效的。目标是让真实序列的概率在整个序列所有概率中最大。最终得到预测标签序列y={y1,y2,…,yn}。当前序列得分为:
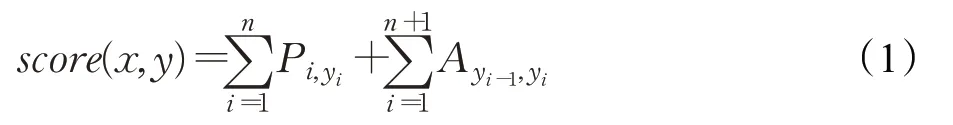
式中,yi是第i个位置的标签值;Pi,yi是第i个位置softmax输出为yi的概率;Ayi-1,yi为yi-1到yi的转移概率。最后利用softmax计算归一化后的概率,公式为:
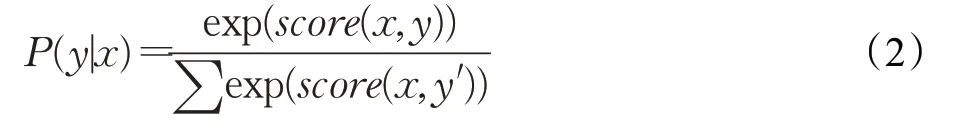
采用最大化对数似然函数优化目标函数,训练样本(x,y)的对数似然为:
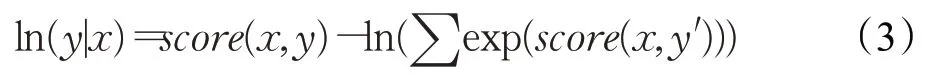
在预测时,使用动态规划的Viterbi算法求解最优路径,得到序列标注任务中每个字对应的标签概率,最大概率对应的标签即为正确标签,概率公式为:

采用BIO标注法对事件进行标注。B_label代表字符为触发词或论元的开始位置,I_label代表字符为触发词或论元的中间位置,O_label代表字符为非触发词或论元。
3 实验设计与结果分析
3.1 数据集
实验使用的面向新冠肺炎新闻数据集来自于网络信息,借助网络爬虫技术从信息门户网站、论坛等地获取新冠疫情相关的新闻语料,包括山西省人民政府网、CCTV新闻网、各省卫健委网站、中国新闻网等。其中中国新闻网上爬取的新闻占80%(约5 500条新闻数据)。这些网站上的新闻舆情通常都是紧跟时事热点、内容完整度较高、主题较明确的高质量文本信息,对事件抽取模型具有较好训练作用。作为实验的数据,根据定义的事件模型,对所有语料进行标注。其中,标注内容包括:事件类型、事件触发词、事件论元、事件角色,以及事件触发词和事件论元在文本中的位置信息。
在进行标注前,首先对篇章级文本进行了断句处理,包含“。”“?”“;”“!”符号的位置进行断句处理。然后多人一起进行标注,标注的时候同时进行交叉检验,保证了标注数据的质量。具体标注过后最终的生成格式为.ann格式,其中每列分别对应:标号、论元角色、起始位置、结束位置、具体论元。如图4所示。

图4 新闻数据集.ann格式Fig.4 News dataset.ann format
卡帕值用于计算标注者之间标注结果的吻合程度。如表2所示,表2中统计了标注者的标注情况,第一行第一个数“698”表示R1和R2都判断为确诊病例溯源类行的个数,第一行第二个数表示“R1判断为确诊病例溯源类而R2判断为数据通报类”的个数。基于混淆矩阵的kappa系数计算公式如下:

表2 事件类型分类检验Table 2 Event type classification test

pe表示所有类别分别对应的“实际与预测数量的乘积”总和除以“样本总数的平方”。计算得到kappa值为0.978,因此将新冠肺炎新闻数据集分为6类,分别为确诊病例溯源、数据通报、本土案例、爱心捐赠、疫苗研发和纪念英雄。
其中关于各类新闻事件的数据分布中数据通报类数据占多数,本土案例和疫苗研发占比较少。采用无监督方法对新闻数据进行分类。按照8∶2划分为训练集和测试集,数据集的统计基本情况如表3所示。
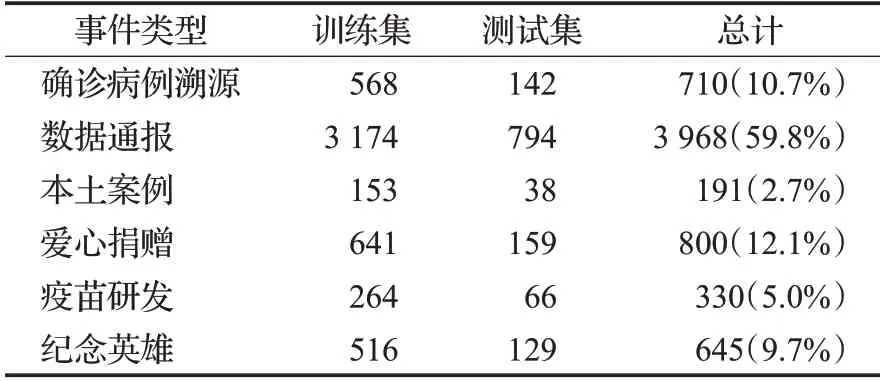
表3 新冠肺炎新闻数据集统计情况Table 3 Statistics on COVID-19 news dataset
3.2 实验设置
事件类型分类阶段本文采用无监督聚类算法。判断一个LDA模型是否合理的标准一般有两个,一个是一致性(coherence),另一个是困惑度(perplexity)。对于LDA主题模型中的困惑度用于在语料库中确定合理的主题个数。

其中,M是测试语料库中的文本的数量,Nd是第d篇文本的单词数,p(w)代表文本的概率。
如图5、图6所示,通过困惑度和一致性这两个指标,确定最优的主题个数为7。
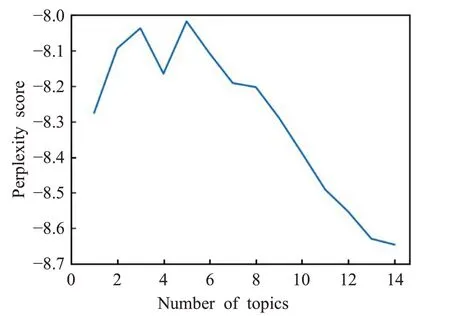
图5 困惑度随主题个数的变化情况Fig.5 Perplexity varies with number of topics

图6 一致性随主题个数的变化情况Fig.6 Coherence varies with number of topics
事件句抽取阶段中本文采用jieba分词技术将句子进行分词,过滤掉文本中无意义的停用词,然后使用Gensim库中的Word2vec模块,设置维度为60、窗口大小为2对该数据集进行学习训练得到词向量模型文件。通过多次实验,选定的权重值decay_rate为0.1,达到效果最佳。
事件论元抽取阶段本文实验基于TensorFlow框架,编程语言为Python 3.6。通过多次实验,选定的实验参数如下:优化器为Adam,learning-rate值为0.005,batchsize值为270,epoch值为20。
3.3 评价指标
本文改进的TextRank算法性能的评估中,算法为每篇文章都识别事件句,实验中使用准确率作为算法的评估指标。

本文利用系统自动抽取信息,再对抽取结果进行评估。LDA、KMeans无监督聚类算法和论元抽取模型在实验中的评估度量方式一致,都是使用准确率(precision,P)、召回率(recall,R)、F1(F1-measure)值作为算法的评估指标。其中,论元抽取是基于句子级和篇章级的多分类任务,而论元是基于词级别的,所以词语的BIO标签预测都计入评估。精确率P是指分类结果预测为正确的数据占所有预测为正确的数据的比重,召回率R是指分类结果预测为正确的样本占所有真实为正确的样本的比重。其中,无监督聚类算法评估是看预测正确的篇章数;论元抽取模型算法评估是看预测正确的标签数。
3.4 无监督聚类实验
将已有的6 644条新闻数据利用LDA和KMeans模型进行聚类,定义主题个数num_topic=7,生成7个主题文档;将分类结果得到的7个主题文档和人工标注好的6类数据作比较,计算P、R、F1值,结果取每类占比最大的类别(Max)。实验结果如表4。
由表4可知,LDA能识别出5类数据。爱心捐赠、疫苗研发、纪念英雄、数据通报这四类新冠疫情新闻聚类效果要比其他两类好;确诊病例溯源、本土案例这两类新冠疫情新闻聚类效果相对较差一些。因为本土案例类数据较少,不易识别,而且本土案例和确诊病例溯源的事件论元较为相似,不易于区分,导致这两类易于混淆,聚类效果相对较差。
表4中,KMeans只能识别出4类数据,没有识别出易于混淆的本土案例和确诊病例溯源类数据。而且,从总的平均结果的评估指标来看,也是LDA算法优于KMeans算法。
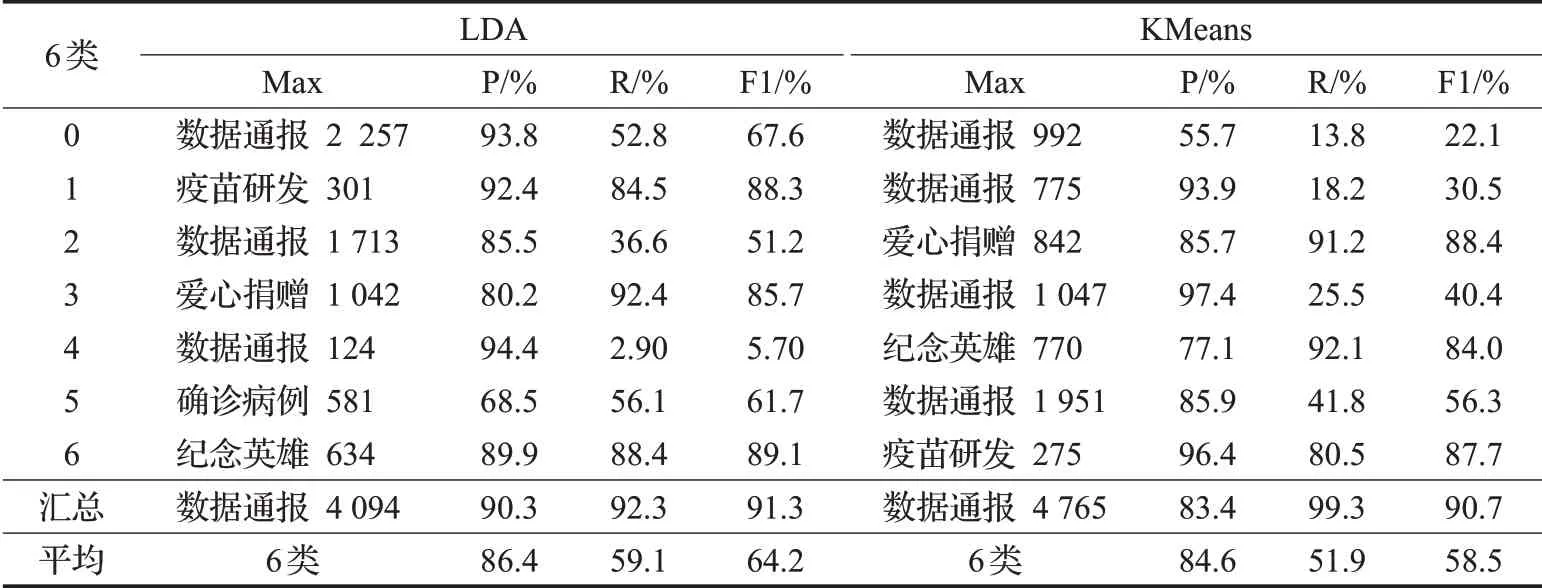
表4 LDA、KMeans模型的事件聚类Table 4 Event clustering of LDA model and KMeans model
由上述分析可知,选择利用LDA模型进行聚类,效果更佳。所以,爬取到的6 644条新冠新闻数据选择利用LDA模型进行聚类,可以更快速准确地获取到爱心捐赠、疫苗研发、纪念英雄、数据通报这四类新冠疫情新闻。部分易于混淆的本土案例类和确诊病例溯源类,可以加上人工干预,进行区分。
3.5 消融实验
为证明加入衰减机制的TextRank算法能提高抽取关键事件句的精度,将未加衰减机制和加入衰减机制的TextRank进行了消融实验。结果如表5所示。
表5中,2_Sents、3_Sents、5_Sents分别表示对每篇文档分别抽取了2、3、5个事件句进行比较。实验结果表明,利用TextRank算法抽取事件句和人工抽取的正确事件句进行论元识别相比,TextRank算法抽取事件句的效果欠佳。但确诊病例溯源类、数据通报类论元的识别效果相对较好,这是因为这两类事件构成相对简单,包含的修饰性词语较少,结构性较强,如许多数据通报类实体都包含“新增确诊病例”“新增疑似病例”“新增死亡病例”等词。实验结果表明,数据通报类事件在2句事件句抽取的论元识别效果最好。本土案例、纪念英雄和疫苗研发类事件类型利用改进过的+decay_rate算法抽取事件句抽取,效果明显提升,且整体效果较好。确诊病例溯源和爱心捐赠类事件抽取2个事件句,改进过的+decay_rate算法效果更佳。总体来看,抽取2、3个事件句,使用改进过的+decay_rate算法效果更佳。
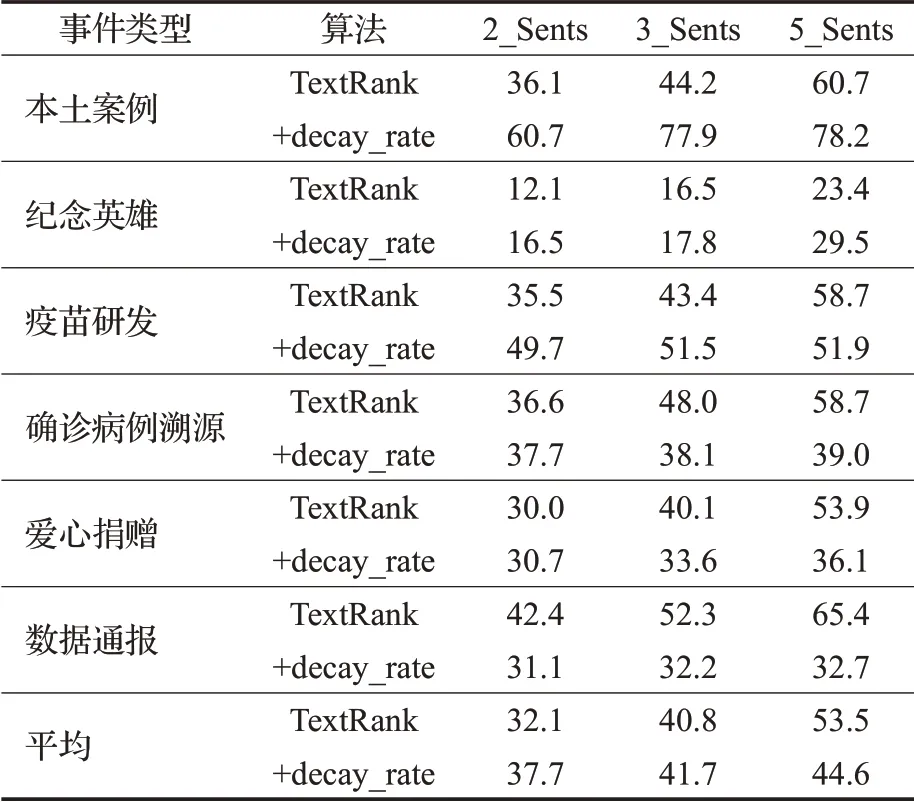
表5 抽取事件句2种算法准确率比较Table 5 Comparison of accuracy of two algorithms for event sentences extraction 单位:%
选择表5中抽取的事件句和人工精标注的正确事件句作为事件抽取的训练数据对六类新冠疫情事件进行实验。图7显示了不同标注类别的实体识别结果,及自动抽取事件句和人工抽取事件句对论元识别的影响。

图7 关于不同事件类型的P、R、F1值Fig.7 P,R,F1 values for different event types
实验结果表明,数据通报类事件在2句事件句抽取的论元识别效果最好,准确率(precision,用P表示)、召回率(recall,用R表示)和F1(用F表示)分别为75.0%,73.0%、74.0%。
3.6 篇章级事件句个数对比
为进一步确定篇章级事件抽取中关键事件句个数,分别比较了2、3、5句事件句对篇章级事件抽取的论元识别的F1指标效果影响,结果如图8所示。
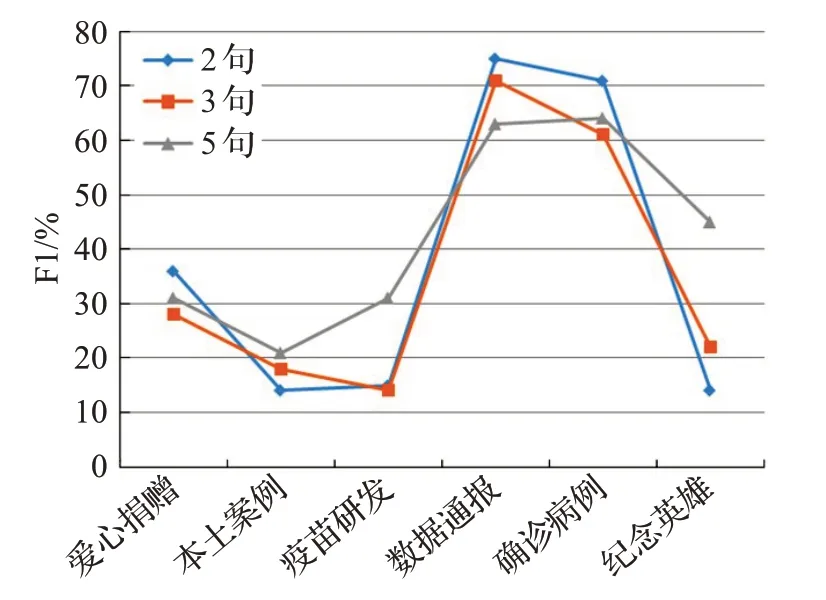
图8 对比不同类型新闻事件句个数Fig.8 Number of sentences forvarious types of news events
实验结果表明,爱心捐赠、数据通报、确诊病例溯源类事件在2句事件句抽取中性能较好,抽取更多的事件句,会减低篇章级事件抽取的效果。
4 结论与展望
针对新冠肺炎领域的事件抽取任务中存在缺乏中文的新冠疫情新闻数据集和跨句抽取论元的问题,本文设计了三阶段的管道方法。并且通过人工参与的方式进行数据集标注。实验表明,该方法能够更快捷地进行事件抽取,对于数据通报、确诊病例溯源类事件在事件句抽取的论元识别效果较好。
本文主要聚焦面向新冠肺炎的篇章新闻数据,目前该领域未见公开数据集,因此未进行其他领域的公开数据集下的对比实验。在利用TextRank算法进行事件句抽取的过程中,发现爱心捐赠、纪念英雄等事件句的精度较低。对后续事件论元的抽取影响较大。在接下来的工作中,会考虑对TextRank算法进行改进,通过引入句子位置、句子相似度和论元词信息融合3个影响因素,以此计算句子之间的影响权重。进而提升事件句的抽取精度。
猜你喜欢
今日农业(2021年2期)2021-11-27
今日农业(2021年1期)2021-03-19
新世纪智能(英语备考)(2020年5期)2020-08-11
恋爱婚姻家庭·养生版(2020年3期)2020-04-13
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
现代语文(2015年27期)2015-11-26
中文信息学报(2012年2期)2012-06-29
