
基于正则表达式的高性能PHP路由
2023-02-17 02:00张文豪陈平华
计算机应用与软件 2023年1期
张文豪 陈平华
(广东工业大学计算机学院 广东 广州 510006)
0 引 言
PHP路由就是网页请求地址与PHP应用系统中的处理程序的映射关系,其最大的作用就是将一个网页请求地址解析为调用的程序地址。正则表达式一般可应用于字符串的检索功能,市场主流的PHP路由就是利用正则表达式检索网页请求地址从而确定调用的程序地址。正则表达式路由分为独立的正则表达式和组合的正则表达式。独立的正则表达式路由由于正则表达式数量与路由数量相同,路由检索时,正则匹配次数较多,性能低下。Nikita[1]提出了组合的正则表达式路由,减少了正则表达式的数量和匹配次数从而提升了正则表达式路由的性能。但是随着路由数量的增加,组合的正则表达式的数量也随着增加,路由匹配性能下降太快,并且对于组合的正则表达路由的分块大小只给出简单的判断,没有进行详细的测试分析。
正则表达式编译后得到的字符串是有长度限制的[2],超过最大的长度时,正则表达式就无法进行匹配,必须对组合的正则表达式进行分块,确保不会超过正则表达式的长度限制。正则表达式的字符串越长编译后得到的字符串也越长,进行匹配时性能也会相应下降,合理的分块大小才能使性能达到最佳。组合的正则表达式为了能够准确找到命中的路由,不同的组合方式有不同的解决方案,但都需要增加辅助字符串,会减少可以进行组合的路由数量,因此采用不同的组合方式也会直接影响到路由的性能。
为了解决路由数量较多时,路由匹配给系统带来的性能压力,本文对组合的正则表达式路由的组合方式和分块大小进行测试对比,找出最优的组合方式和分块大小的规律,并对PHP内核进行深入研究,从PHP底层的机制对PHP路由的实现进行深入的优化。通过对组合的正则表达式路由的深入优化,让PHP路由的性能在极端情况下,也能保持性能的稳定。
1 相关工作
随着Ruby On Rails的火爆,PHP也随着它的盛行进入了框架开发的时代。为了解决使用开发框架后造成URL访问地址冗长的问题,开发框架都提供了路由的功能来实现URL访问地址的优化,并且有利于搜索引擎的收录,路由也成为开发框架的核心功能[3]。在开发框架强制开启路由后,每个请求地址都要经过路由匹配后才能确定要调用的程序文件,路由匹配是每个请求的必经环节,成为影响系统性能的关键因素。
正则表达式从一开始就被应用到开发框架的路由组件中,通常使用的是独立的正则表达式方案,就是一条正则表达式表示一条路由信息,路由匹配时需要逐一匹配直到找到相应的路由。由于独立的正则表达式方案具有简单、灵活的特点,在各种程序语言的开发框架上得到广泛应用。但独立的正则表达式方案在路由信息较多时,性能损耗比较严重,路由的性能直接影响到开发框架的性能,因此提升路由的性能就可以提升开发框架的性能。
2014年1月我国台湾省的林佑安发布了Pux 1.0,当时的测试数据,路由的性能比Symfony2的路由快了4倍,拉开了提升PHP开发框架路由性能的序幕。Pux取得的性能的提升引起了很多PHP开发人员的注意,其中也包括PHP核心组开发成员:Nikita Popov。Nikita Popov在研究了Pux的实现后,发现Pux只是简单地把PHP路由使用C语言编写为PHP扩展,还是采用了独立的正则表达式的方案,也就是性能的提升主要来自PHP扩展是静态的,减少了PHP程序需要一边解释一边执行的时间。2014年2月Nikita Popov提出了基于组合的正则表达式的路由方案,详细描述了两种组合的方式:GCB和GPB,并通过综合的测试,证明即使使用PHP程序进行实现,其综合性能还是明显优于Pux,并在2014年4月发布了基于组合的正则表达式的PHP路由库:FastRoute。在FastRoute发布后,全球最流行的PHP开发框架laravel的精简版本Lumen的路由就采用了FastRoute的实现。2018年2月Symfony发布4.1版本时,路由组件增加了组合的正则表达式的实现方案,并且组合的正则表达式方案使用方法和独立的正则表达式方案保持一致,同时在400条静态路由和400条动态路由的状态下,测试发现组合的正则表达式路由方案的性能比独立的正则表达式路由方案提升了5倍[4]。Symfony路由组件证明了组合的正则表达式路由方案可以在保持简单、灵活的基础上,有效地提升路由的综合性能。从此,组合的正则表达式在PHP开发框架的路由组件中得到了广泛的应用,目前也是被广泛认可的提升路由性能的有效方案。
2 定 义
定义1路由是一个网络工程的术语,是指分组从源到目的地时,决定端到端路径的网络范围的进程。Web开发中的路由是指如何定义应用的端点(URIs)以及如何响应客户端的请求,是由一个URI、HTTP请求和调用程序组成[5]。
定义2正则表达式,又称规则表达式(Regular Expression,在代码中常简写为regex、regexp),计算机科学的一个概念。正则表达式是对字符串进行描述和通配操作的一种逻辑公式,通常被用来检索、替换那些符合某个模式(规则)的文本[6]。
正则表达式是对字符串(包括普通字符(例如,a到z之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式使用小括号(……)构建分组,可以将多个正则表达式通过分组的语法组合为一个大的正则表达式。正则表达式分组分为捕获组和非捕获组,捕获组匹配时会从左到右自动生成组号,支持反向的引用,非捕获组没有生成组号,不支持反向引用[7-8]。
定义3正则表达式路由就是使用正则表达式来表示路由规则,包括路由定义和路由匹配两部分。路由定义就是使用正则表达式完成路由规则的定义。路由匹配即路由命中,就是根据路由定义时用的正则表达式与请求地址进行正则匹配,正则表达式匹配就表示该路由命中,同时根据正则匹配的结果和路由定义的规则进行处理,得到一个程序调用的目标地址。
根据正则表达式与路由的对应关系,又分为独立的正则表达式路由和组合的正则表达式路由。
独立的正则表达式路由就是一条正则表达对应一条路由,路由搜索时,通过列表循环方式,依次检测每条路由的正则表达式是否与请求地址正则匹配,如果匹配就代表该路由命中,终止循环;循环结束还是没有正则表达式匹配就代表没有路由命中。
组合的正则表达式路由就是一条正则表达式对应多条路由,通常还得使用分块限制正则表达式的长度,路由搜索时也是通过列表循环方式,依次检测每条组合后的正则表达式是否匹配,如果组合后的正则表达式与请求地址匹配,还需要根据组合的方式计算出命中的路由;如果循环结束还是没有正则表达式能匹配请求地址就代表没有路由命中。正则表达式的组合有两种格式,分别为(?:)和(?|)[7-8]。两种组合的格式都可以使用“|”构造多个分支。每个分组分支可以包含多个子组,代表一条路由信息。
3 相关数据
假设有一个资讯类网站,每个子站有5条路由信息,分别为主页、栏目页、列表页、详细页、搜索页,并且每个子站都指定了子域名(t1到tN),如表1所示。本文通过增加和减少子站数量来控制测试的路由数量。
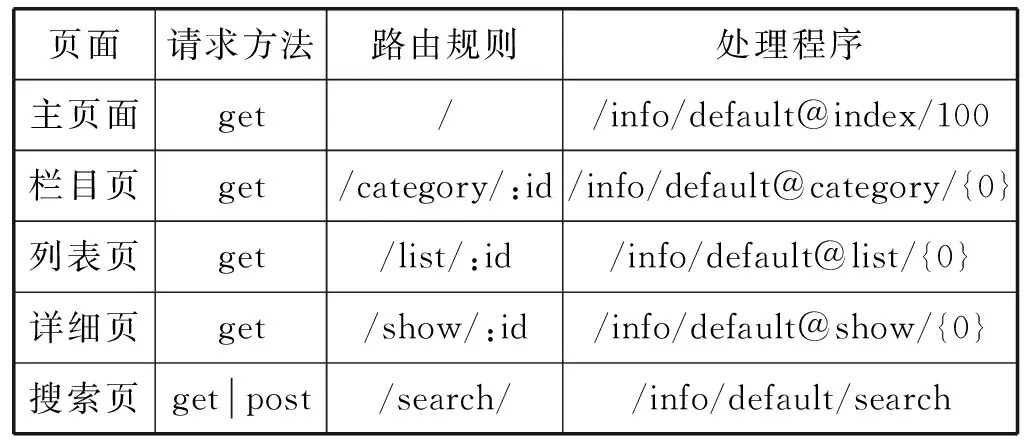
表1 子站t1的路由信息示例(域名为:t1.xqkeji.com)
举例说明:
(1) 访问http[s]://t1.xqkeji.com/后,主页面的路由被选中,得到调用程序的地址为:info模块里的default类的index方法,方法的参数为100。
(2) 访问http[s]://t1.xqkeji.com/category/1000后,栏目页的路由被选中,得到调用程序的地址为:info模块里的default类的category方法,方法的参数为路由正则匹配结果的第一个参数值(1 000)。
(3) 访问http[s]://t1.xqkeji.com/list/1001后,列表页的路由被选中,得到调用程序的地址为:info模块里的default类的list方法,方法的参数为路由正则匹配结果的第一个参数值(1 001)。
(4) 访问http[s]://t1.xqkeji.com/show/100001后,详细页的路由被选中,得到调用程序的地址为:info模块里的default类的show方法,方法的参数为路由正则匹配结果的第一个参数值(100 001)。
(5) 访问http[s]://t1.xqkeji.com/search/后,搜索页的路由被选中,得到调用程序的地址为:info模块里的default类的search方法。
4 算 法
基于正则表达式的路由算法有两种形式:独立的正则表达式路由和组合的正则表达式路由。
本文的路由的基本格式:([域名1|域名2|.*?])_([请求方法1|请求方法2|.*?])_路由规则。
4.1 独立的正则表达式路由
独立的正则表达式路由就是一条正则表达式表示一条路由信息,通常将所有的正则表达式路由信息存放到一个数组中,通过数组遍历逐条进行正则匹配,只要有一条正则表达式匹配成功,就退出数组遍历,该匹配成功的路由信息为需要调用的程序地址,如果直到数组遍历结束还没有一条正则表达式匹配成功,就表示找不到路由,返回404错误。
根据子站点t1的路由信息,给出相应的独立的正则表达式的路由信息。
$regexes=[
//主页路由正则表达式
′#^(t1.xqkeji.com)_(get|post)_/$#′,
//栏目页路由正则表达式
′#^(t1.xqkeji.com)_(get|post)_/c ategory(/.*)*$#′,
//列表页路由正则表达式
′#^(t1.xqkeji.com)_(get|post)_/list(/.*)*$#′,
//详细页路由正则表达式
′#^(t1.xqkeji.com)_(get|post)_/show(/.*)*$#′,
//搜索页路由正则表达式
′#^(t1.xqkeji.com)_(get|post)_/search/$#′,
];
算法描述:
//系统所有路由的正则表达式的数组
regexes ← 路由正则数组
//格式为:请求域名_请求方法_请求地址
//例如:t1.xqkeji.com_get_/表示主页的请求地址
url ← 特定格式的URL信息字符串
//是否路由匹配,初始0表示没有路由匹配
matched ← 0
//路由数组的索引下标,确定匹配的路由
route_index ← 0
For regex From regexes
//正则匹配就是测试url地址字符串是否符合正则表达式
//regex的规则,返回true或false,同时将正则搜索的结果存储
//到matches数组中
If 正则匹配(regex,url,matches) Then
//已经找到路由
matched ← 1
BREAK
End If
route_index ← route_index+1
End For
If matched Then
//route_index为选中的路由
Else
//没有找到路由,404错误
End If
4.2 组合的正则表达式路由
组合的正则表达式路由就是将多条正则表达式路由信息通过正则表达式的分组语法规则组合成为一条大的正则表达式,也就是用一条大的正则表达式表示多条路由信息。PHP路由的组合方式主要有三种:基于分组位置(GPB)、基本分组计数(GCB)和基本分组标记(GMB)。
1) 基于分组位置(GPB)就是根据正则表达式的匹配结果的分组位置计算出正则表达式命中的分支,也就是命中的路由。GPB组合的特点:以“(?:”开头;每个分支的分组数量一致;所有分组位置从左到右递增;分支匹配后,前面没有匹配的分支的分组位置都会填充空白符,如图1所示。
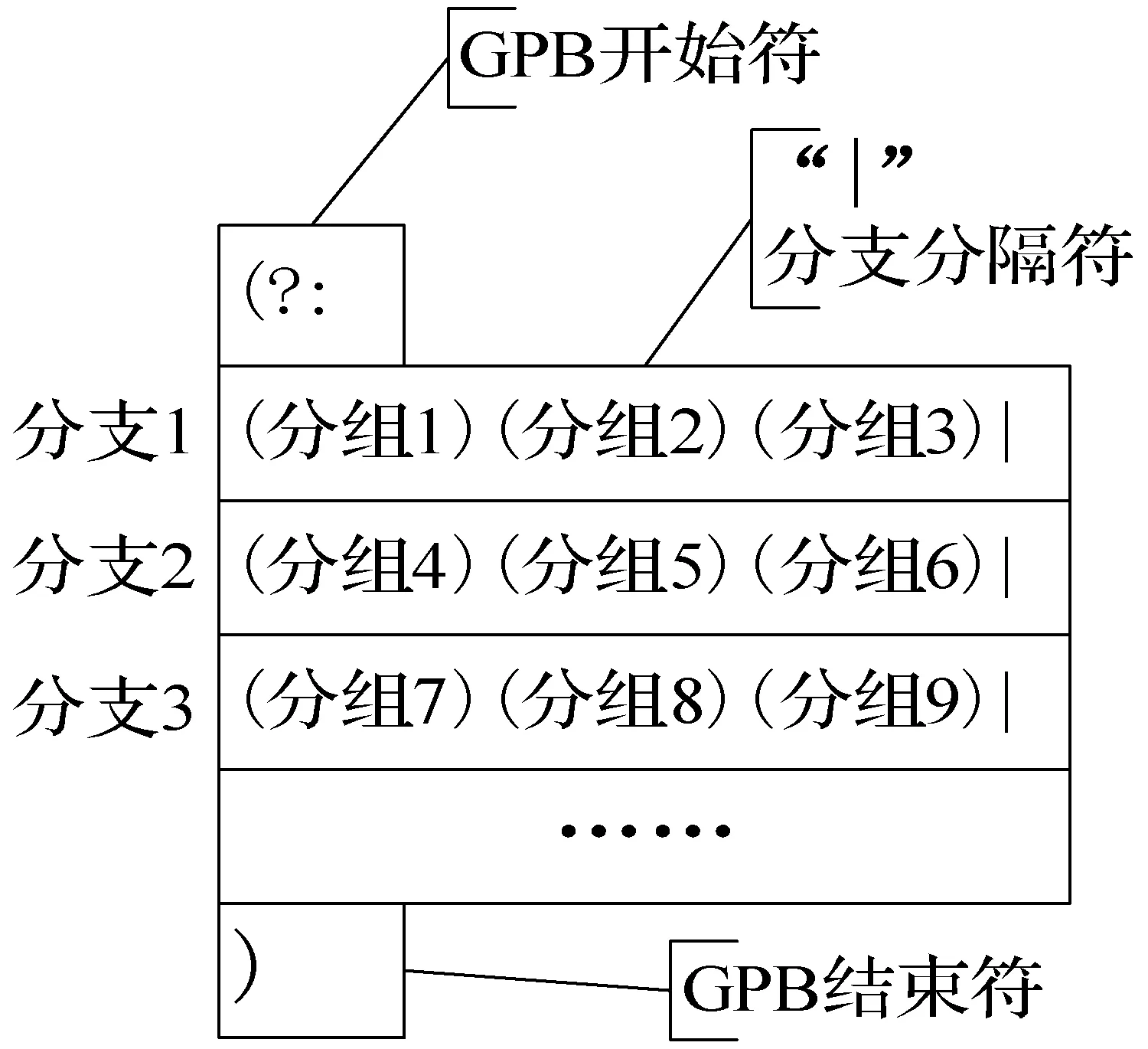
图1 GPB组合示例图
假设分支3的正则规则匹配,那么分支1和分支2的分组都会被填充空白符。正则匹配结果为:
[
0=>全匹配的结果,
1=>”,//分支1的分组1填充空白符
2=>”,//分支1的分组2填充空白符
……
7=>分支3分组7的匹配结果数据,
8=>分支3分组8的匹配结果数据,
9=>分支3分组9的匹配结果数据
]
根据匹配结果里有9个分组和每个分支有3个分组可以计算出“分支3”命中。
GPB的组合的路由的正则表达式的格式:′#^(?:主页路由正则表达式()()()()|栏目页路由正则表达式()()()|列表页路由正则表达式()()()|详细页路由正则表达式()()()|搜索页正则表达式()()()())$#’,GPB必须保证所有正则分支的子组数都相同,也就是取所有分支中的最大分组数,其他分支添加多余的空分组来确保所有分支的分组数相同,本例的最大分组数和相同的分组数为6。
算法描述:
regex ← 所有路由组合成的GPB正则表达式
//格式为:请求域名_请求方法_请求地址
//例如:t1.xqkeji.com_get_/表示主页的请求地址
url ← 特定格式的URL信息字符串
//路由数组的索引下标,确定匹配的路由
route_index ← 0
//正则匹配就是测试url地址字符串是否符合正则表达式
//regex的规则,返回true或false,同时将正则搜索的结果存储
//到matches数组中
If 正则匹配(regex,url,matches) Then
//正则表达式有匹配,说明已经找到路由
//6为所有分支最大和相同的分组数
//计算出命中路由的索引
route_index ← (统计数组元素数量(matches)-1)/6-1
Else
//没有找到路由,404错误
End If
2) 基于分组计数(GCB)就是根据正则表达式的匹配结果中每个分支的分组数量是递增计数的特点来计算出正则表达式命中的分支,也就是命中的路由。GCB组合的特点:以“(?|”开头;每个分支的分组数量不一样并且是递增的;所有分支的分组位置是独立的;分支匹配后,前面没有匹配的分支的分组位置不会填充空白符,如图2所示。
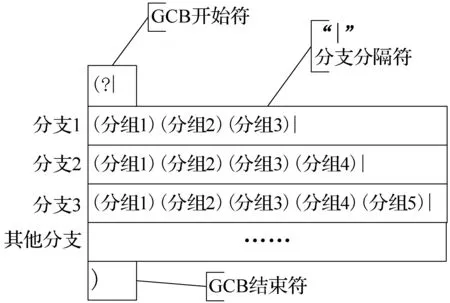
图2 GCB组合示例图
假设分支3的正则规则匹配,那么正则匹配结果为:
[
0=>全匹配的结果,
1=>分支3分组1的匹配结果数据,
2=>分支3分组2的匹配结果数据,
3=>分支3分组3的匹配结果数据,
4=>分支3分组4的匹配结果数据,
5=>分支3分组5的匹配结果数据
]
根据匹配结果里有5个分组数和分支3的分组数一致可以计算出“分支3”命中。
GCB的组合格式:′#^(?|主页路由正则表达式()()()()|栏目页路由正则表达式()()()()|列表页路由正则表达式()()()()()|详细页路由正则表达式()()()()()()|搜索页正则表达式()()()()()()()())$#’,GCB必须保证所有正则分支的分组数是递增的并且有确定的最小分组数,在这里最小的分组数是6,主页的分组数为6、栏目页的分组数为7、列表页的分组数为8、详细页的分组数为9、搜索页的分组数为10。
算法描述:
regex ← 所有路由组合成的GCB正则表达式
//格式为:请求域名_请求方法_请求地址
//例如:t1.xqkeji.com_get_/表示主页的请求地址
url ← 特定格式的URL信息字符串
//路由数组的索引下标,确定匹配的路由
route_index ← 0
//正则匹配就是测试url地址字符串是否符合正则表达式
//regex的规则,返回true或false,同时将正则搜索的结果存储
//到matches数组中
If 正则匹配(regex,url,matches) Then
//正则表达式有匹配,说明已经找到路由
//6为所有分支最大和相同的分组数
//计算出命中路由的索引
route_index ← 统计数组元素数量(matches)-7
Else
//没有找到路由,404错误
End If
3) 基于分组标记(GMB)就是根据正则表达式的匹配结果的分支标记数据来确定命中的分支,也就是命中的路由。GMB组合的特点:以“(?|”开头;每个分支的分组数量没有限制;每个分支需要设置唯一的标记;分支匹配后,该分支的标记会填充到匹配的结果中,通过分支标记的数据能很容易确定命中的路由,如图3所示。

图3 GMB组合示例图
假设分支3的正则规则匹配,那么正则匹配结果为:
[
0=>全匹配的结果,
1=>分支3分组1的匹配结果数据,
MARK=>分支标记3的数据,
]
根据匹配结果的MARK数据就能确定“分支3”命中。
GMB的组合格式:′#^(?|主页路由正则表达式(*MARK:0)|栏目页路由正则表达式(*MARK:1)|列表页路由正则表达式(*MARK:2)|详细页路由正则表达式(*MARK:3)|搜索页正则表达式(*MARK:4))$#’,GMB通过为每一个组合的分支添加一个唯一的标记,不需要添加多余的正则表达式的空分组()。
算法描述:
regex ← 所有路由的GMB正则表达式
//格式为:请求域名_请求方法_请求地址
//例如:t1.xqkeji.com_get_/表示主页的请求地址
url ← 特定格式的URL信息字符串
//路由数组的索引下标,确定匹配的路由
route_index ← 0
//正则匹配就是测试url地址字符串是否符合正则表达式
//regex的规则,返回true或false,同时将正则搜索的结果存储
//到matches数组中
If 正则匹配(regex,url,matches) Then
//正则表达式有匹配,说明已经找到路由
//计算出命中路由的索引
route_index ← matches[‘MARK’]
Else
//没有找到路由,404错误
End If
5 实现方案
本文综合了Pux、FastRoute、Symfony Routing各自的优点,采用C语言实现PHP扩展的方式,提升程序性能,并且结合PHP内核的机制进行路由性能的优化;对组合方式和分块大小进行深入研究,经测试和分析表明GMB是最优的组合方式,同时发现了最优的分块大小是动态的,是随着路由信息总数量的变化而变化的,并提出一个最优分块大小的范围。
5.1 分块大小
正则表达式是有长度的限制的,PHP默认使用的是16-bit PCRE2 library,支持的正则表达式编译后的结果的最大长度为65 536,这就造成了进行组合的正则表达式路由必须进行分块,将一条大的正则表达式分成多个小块,才能确保不会超出正则表达式长度的限制。由于限制的长度是正则表达式编译后的长度,我们很难计算出GPB和GCB组合支持最大的路由数。经过简单的测试,以每个分支最多6个分组为例,GPB组合一条正则表达式大概支持400条路由,GCB组合一条正则表达式大概支持100条路由,GMB组合一条正则表达式大概支持600条路由,如表2和表3所示。

表2 GPB组合产生的空分组数

表3 GCB组合产生的空分组数
例如使用t1-t20构建100条路由,GPB组合产生17×20=340个空分组,GCP组合产生17×20+((20×5-1)(20×5-1+1))/2=340+4 950,GMB组合只加了一个唯一的标记没有空分组。每一个空分组()由两个字符组合,GPB的空分组会产生680个字符,GCB的空分组会产生10 580个字符。这是造成GCB一条正则表达式大概最多只支持100条路由、GPB可以达到400条路由、GMB可以达到600条路由的原因。
采用分块后,GPB、GCB、GMB三种组合都不是每条正则表达式包含最多的路由数时达到性能最佳。由于正则的匹配性能是不稳定的,经过简单测试,三种组合的最佳分块大小大概等于:
最大数(最小数(路由总数量×G,GMax),GMin)
其中:G在0.3~0.7之间,一般取0.5;Gmin在GPB和GCB中一般取10,在GMB中一般取30;GMax在GPB中一般取300,在GCB中一般取70,在GMB中一般取550。
5.2 采用的组合方式
根据5.1节的描述,无论是GPB还是GCB,都需要额外添加空分组(),才能正确计算出匹配的路由,并且随着分支数的增加,空分组的数量就会越多。
同时构建t1-t20个子站点,总共100条路由信息,分别使用GPB、GCB和GMB,匹配t1、t10、t20站点的第一条路由和最后一条路由,测试验证三种组合方式的性能,结果如图4所示。

图4 三种组合方式性能测试
根据测试的结果,在t1、t10、t20中,采用GMB组合的路由性能比GCB和GPB都有明显的优势。同时从测试的结果看,在路由数量较少时,GCB和GMB的性能接近;随着路由数量的增加,GCB组合添加的辅助字符越多,与GMB组合的性能差距就越大。
GMB组合的优势在于添加的辅助字符是最少的,同时限制也是最少的,并没有最小分组数和相同分组数的限制,这就决定了GMB对比其他组合方式有明显的优势。
5.3 其 他
1) 路由格式。([域名1|域名2|.*?])_([请求方法1|请求方法2|.*?])_路由规则(*MARK:分支唯一标记)
该格式简单并且支持多域名和多个请求方法,容易编译成一条大的正则表达式。
2) 路由分类。根据路由信息的特点,将路由分为静态路由和动态路由。路由进行分类后,静态路由不需要进行正则匹配,直接根据请求的URL地址与目标程序的对应关系,可以采用哈希表进行路由匹配,从而减少了正则表达式的数量。例如t1站点的主页和搜索页,对应的规则分别为’/’和’/search’,直接与请求的URL地址对应,无须使用正则匹配,就能确定调用的目标程序地址。
3) 自定义正则匹配函数。使用preg_match进行路由匹配返回的结果中,我们只需要得到模块名称、控制器名称、动作名称和参数四个数据,其他数据只是为了辅助验证,不需要通过PHP再返回。通过自定义preg_match函数,改为调用PCRE进行正则匹配后,直接返回正则分支的MARK唯一标记,不匹配时返回false,方便直接得到选中的路由索引,并将匹配的结果修改为只返回4个我们需要的数据,可以减少PHP将PCRE的匹配结果转化为PHP数据时3次插入数据。
4) 使用持久数组存储路由信息。PHP每次请求结束都会进行垃圾回收,所有非持久的资源都会被销毁[9-10]。在没有将路由信息存储在持久数组中时,每一次请求都要加载路由信息。路由信息数量较多时,加载路由信息就会变成系统的瓶颈。将路由信息存储在持久数组中,每一个进程只需加载一次,第二次请求无须加载路由信息,可以有效解决加载大量路由信息对性能造成的影响。
5) 使用LRU缓存路由命中结果。每个请求地址对应的路由信息是固定的,它们之间是一一对应的关系,可以使用缓存来表示它们之间对应的关系,从而减少正则匹配的次数,提升路由的性能。但是一个普通的网站日点击率也会超过10万次,因此缓存必须要有淘汰的策略,不然缓存的信息量太大,会耗尽系统资源,反而会成为负担。
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰[11]。结合PHP内核提供的HashTable和双向链表数据结构,实现了一个路由命中结果的LRU缓存,如图5所示。
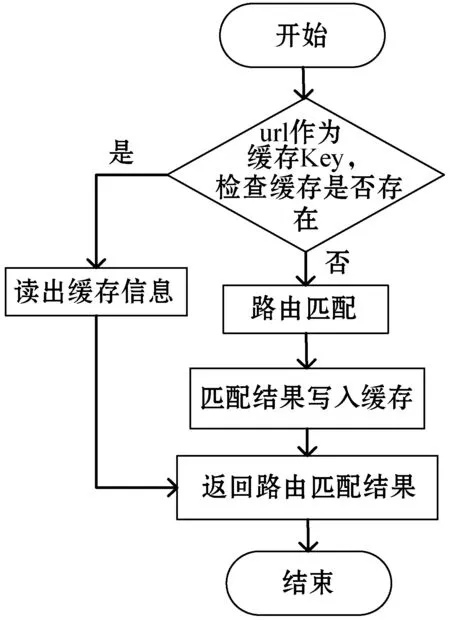
图5 使用缓存的路由匹配流程
启用LRU缓存后,使用Web请求的url地址作为HashTable的Key,然后LRU节点存储路由匹配返回的结果。路由匹配前,检查该Web请求的url地址是否存在缓存,存在时直接返回缓存中存储的路由匹配结果,不存在时进行路由匹配并将路由匹配结果写入缓存最后返回路由匹配结果。
6 实验与结果
6.1 实验环境
1) 软件环境。操作系统:Windows 10。软件环境:Docker19.03.5、PHP7.4.1。PHP基准测试库:nice/bench 1.0。
2) 硬件环境。处理器:Intel(R) Core(TM) i5- 3230M。内存:8.00 GB(1 600 MHz)。硬盘:系统盘(固态硬盘Lenovo SSD SL700 128 GB),数据盘(机械硬盘WDC WD5000LPVT- 08G33T1)。
6.2 产品对比
FastRoute是第一个实现组合的正则表达式路由方案的PHP开源项目,同时被应用于Lumen框架中。它那提出的组合的正则表达式路由的实现方案被大量的项目借鉴,使得正则表达式路由的匹配性能有了数量级的提升。
Routing(Compiled)是PHP著名的开发框架Symfony的路由组件中的一种路由匹配方式,是在Symfony 4.1版本后借鉴了FastRoute的组合的正则表达式路由的实现方案,实现了将Routing的路由信息编译为组合的正则表达式路由的实现方案,对比独立的正则表达式路由有5倍性能的提升。
XqRoute是采用本文制定的实现方案,实现的高性能的PHP路由库。
XqRoute(LRU)是在XqRoute下开启了LRU缓存,开启LRU缓存后可以让路由的匹配不受路由信息数量的影响,保持稳定的路由性能。
6.3 构建实验数据
通过构建t1-t20、t1-t100、t1-t200等,生成100条、500条、1 000条路由信息。
6.4 测试对比
1) 100条路由。连续运行10 000次,对比t1、t10、t20站点5条路由都匹配一次和一次没有路由匹配的情况,如图6所示。
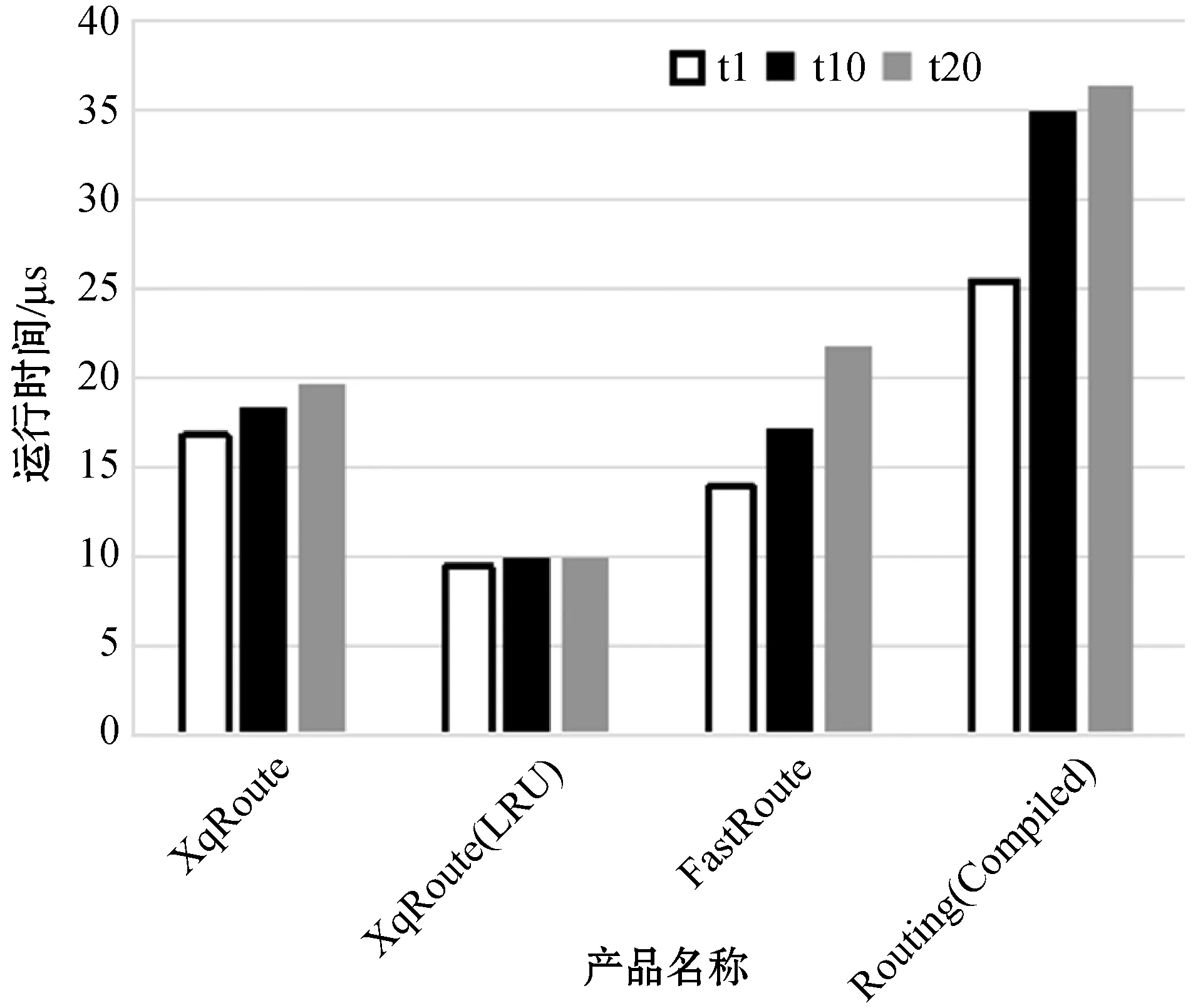
图6 100条路由(t1-t20)的路由匹配性能对比
2) 500条路由。连续运行10 000次,对比t1、t50、t100站点5条路由都匹配一次和一次没有路由匹配的情况,如图7所示。
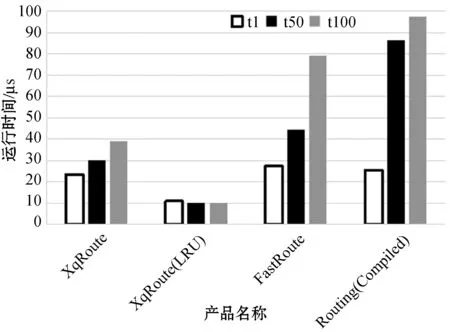
图7 500条路由(t1-t100)的路由匹配性能对比
3) 1 000条路由。连续运行10 000次,对比t1、t100、t200站点5条路由都匹配一次和一次没有路由匹配的情况,如图8所示。
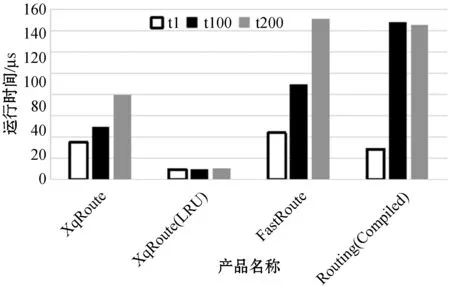
图8 1 000条路由(t1-t200)的路由匹配性能对比
6.5 测试结论
根据测试的路由信息,只有60%的路由是动态路由,也就是100条路由时,只有60条动态路由。FastRoute在动态路由信息较少时,性能表现比较好,但随着动态路由信息的增加,性能下降较快。XqRoute即使没有开启LRU缓存,综合性能也是最好的,随着动态路由信息的增加,性能只是缓慢下降,动态路由信息越多,性能优势越明显。XqRoute启用LRU缓存后,可以使得路由匹配的性能基本与动态路由信息的数量无关。
7 结 语
本文深入研究了组合的正则表达式路由的组合方式和分块大小,并制定了一个可行的高性能的PHP路由实现方案,实现了一个不受动态路由信息数量影响的高性能的PHP路由库。接下来将在此基础上,继续研究和实现开发框架的其他核心组件,最终实现一个通用的高性能的高效率的PHP开发框架。
猜你喜欢
房地产导刊(2022年4期)2022-04-19
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
无线互联科技(2020年11期)2020-12-01
山东农业工程学院学报(2020年12期)2020-03-19
数学年刊A辑(中文版)(2019年1期)2019-01-31
湖州师范学院学报(2016年2期)2016-08-21
计算机工程与设计(2014年3期)2014-12-23
燕山大学学报(2014年1期)2014-03-11
