
生成样本对抗训练的图半监督学习
2023-02-18 07:16刘全明梁吉业
计算机与生活 2023年2期
王 聪,王 杰,刘全明,梁吉业
1.山西大学 计算机与信息技术学院,太原030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原030006
传统的监督学习,如支持向量机(support vector machine,SVM)、神经网络(neural networks,NN)等,通常需要大量良好的标记样本对模型进行训练,以便获得较好的模型泛化能力。同时,在处理高维数据(如视频、语音、图像、文档)时,训练一个好的监督模型所需要的标记样本数量会进一步增长。这使得传统监督学习很难应用于一些缺乏标记训练样本的任务中。
半监督学习(semi-supervised learning,SSL)[1]是近十多年发展起来的一种新型机器学习方法,其思想是在标记样本数量很少的情况下,通过在模型训练中引入无标记样本来避免传统监督学习在训练样本不足(学习不充分)时出现性能(或模型)退化的问题。半监督学习的研究具有重要的实用价值,因为在许多实际应用中,无标记样本的获取相对容易,而标记样本的获取成本往往较高。因此,减少标记样本的使用能够大幅缩减人力、时间和资源的开销,从而降低生产成本。同时在标记样本数量减少数十或数百倍(甚至更多)的情况下,半监督算法能够取得与传统监督学习算法相近甚至更好的效果,提升生产效率。半监督学习的研究具有重要的理论价值,它是介于传统监督学习和无监督学习之间的一种新型机器学习方法,是对传统机器学习理论的拓展和补充。
图半监督学习(semi-supervised learning on graphs)作为半监督学习的一个重要分支,在理论和实践上引起了极大的关注。给定一个由少量标记节点和大量未标记节点组成的图,它的目标是为图中的未标记节点分配标签。生成对抗网络(generative adversarial networks,GAN)[2]由于其强大的表征能力已经被广泛应用于半监督学习,但它在图半监督学习任务上的工作较少。现有的工作主要关注在低密度区域生成未标记样本来削弱子图之间的信息传播,从而使决策边界更清晰,如GraphSGAN[3]通过GAN 在子图之间的低密度区域生成未标记样本,减少子图边缘节点的影响,从而提高图半监督分类效果。但受限于标记样本过少,监督信息的不足仍在一定程度上限制了其性能。针对这个问题,本文提出了一种新的图半监督学习框架(semi-supervised learning on graphs using adversarial training with generated sample,SemiGATDS),它由图嵌入模块、两个生成器、一个分类器和一个判别器五部分组成。其中,图嵌入模块将图映射到特征空间,在特征空间中,一个生成器生成服从真实样本分布的标记样本,另一个生成器生成与真实样本分布不同的未标记样本。分类器负责为给定的样本分配标签,判别器用来区分样本标签对是否来自真实分布。通过生成器、判别器和分类器的对抗训练,当模型达到稳态时,生成的标记样本扩充了标记样本训练集,生成的未标记样本削弱了子图边缘节点的影响,迫使分类界限更加清晰,从而提高了分类效果。本文在Cora、Citeseer、Pubmed[4]三个数据集上评估了SemiGATDS 的分类性能,并讨论了不同数量的标记样本和不同生成样本比例对算法的影响,实验结果验证了本文方法的有效性。
1 相关工作
半监督学习旨在利用大量未标记样本来提高模型性能。半监督学习有以下几种范式:生成式方法[5]、基于支持向量机的半监督学习算法[6]、基于分歧的方法[7]和图半监督学习[8-9]。其中,由于图半监督学习解释性强、性能优越,受到很多的关注,它的核心思想是数据集中每个样本对应于图中一个节点,若两个样本之间的相似度很高(或相关性很强),则对应的节点之间存在一条边,边的“强度”(strength)正比于样本之间的相似度(或相关性)。利用图上的邻接关系将标签从标记样本向无标记样本传播。
关于图半监督学习的研究大致分为两类,基于图的拉普拉斯正则化框架[10]是其中一个重要的研究方向。Zhou 等人[11]通过在损失函数中使用基于图的拉普拉斯正则化项,在图上平滑标签信息。文献[12]提出了一种基于高斯随机场和形式化图拉普拉斯正则化框架的算法。Belkin 等人[13]提出了一种利用几何的边缘分布理论进行半监督学习的正则化方法ManiReg。另一个研究方向是将半监督学习与图嵌入[14]相结合。文献[15]首次将深度神经网络引入图的拉普拉斯正则化框架中进行半监督学习和图嵌入。Yang 等人[16]提出了联合图嵌入学习和节点标签预测模型Planetoid。DeepWalk[17]是第一个关于图嵌入的工作,作为一种无监督图嵌入学习方法,如果与分类器相结合,很容易转化为半监督学习基线模型。图卷积神经网络(graph convolutional network,GCN)[18]是第一个用于图半监督学习的图卷积模型,它在这个问题上表现出了强大的能力。
GAN 作为一种功能强大的深度生成模型,最早用来表示自然图像上的数据分布,通过生成器和判别器的互相博弈学习产生更好的输出。最近在半监督学习框架中展示了它们的能力[19]。半监督生成对抗网络(semi-supervised generative adversarial networks,SGAN)[20]最早是在计算机视觉领域提出的。SGAN用分类器取代了GAN 中的判别器。为了防止生成器过度训练,Salimans 等人[21]首次提出特征匹配损失,将GAN 应用于关于“K+1”类的半监督学习。Li 等人[22]认识到生成器和判别器可能无法同时达到最优,并且无法控制生成样本的语义信息,提出了Triple-GAN。随着标记样本数量的减少,Triple-GAN 的性能改善更加显著,这表明生成的样本标签对可以有效地用于训练分类器。文献[23]意识到生成器也存在同样的问题,从理论上解释了为什么生成与真实样本分布不同的样本可以提高SSL 性能。通过精心设计生成器的损失,生成器可以生成与真实样本分布不同的样本,迫使分类器的决策边界位于不同类的数据流形之间,这反过来又增强了分类器的泛化能力。
基于GAN 的图半监督学习的研究工作较少,如GraphSGAN。这项工作的主要思想是在子图之间的密度间隙生成未标记样本,削弱不同类之间的信息传播,但是用于训练的标记样本过少仍然是制约其性能的关键。针对这个问题,本文提出了Semi-GATDS,该算法同时生成服从真实样本分布的标记样本和与真实样本分布不同的未标记样本,以提高图半监督学习性能。
2 基于生成样本对抗训练的图半监督学习算法
2.1 图半监督学习问题定义
设G=(V,E)表示一个图,其中V代表节点集,E⊆V×V代表边集。假设每个节点vi与d维实值特征向量wi∈Rd和标签yi∈{1,2,…,K}相关联。如果节点vi的标签yi未知,则节点vi是一个未标记节点。设标记节点集合为VL,未标记节点集合为VU=V∖VL。通常,有|VL|≪|VU|。由此,本文形式化地定义图上的半监督学习问题,给定部分标记图G=(VL⋃VU,E),使用与每个节点和图相关联的特征w来学习函数f,预测图中未标记节点的标签。
2.2 SemiGATDS 模型架构
本文模型框架如图1 所示,SemiGATDS 由五部分组成,分别是图嵌入模块、两个生成器、一个分类器和一个判别器。基于GAN 的模型不能直接应用于图数据,因此,遵循文献[3]的设置,首先使用网络表示学习算法(本文使用TADW(text-associated deepwalk)[24]对节点原始特征进行预处理)学习每个节点的潜在分布表示qi,然后将潜在分布表示qi与原始特征向量wi拼接,即xi=(wi,qi)。在模型中,将生成标记样本的生成器称为gG,它接受真实标签y和随机噪声z作为输入,并生成以y为标签的服从真实样本分布的标记样本;生成未标记样本的生成器称为bG,它接受随机噪声z为输入,生成与真实样本分布不同的未标记样本;分类器C,为给定的样本分配标签;判别器D,判断样本标签对是否来自真实样本分布。
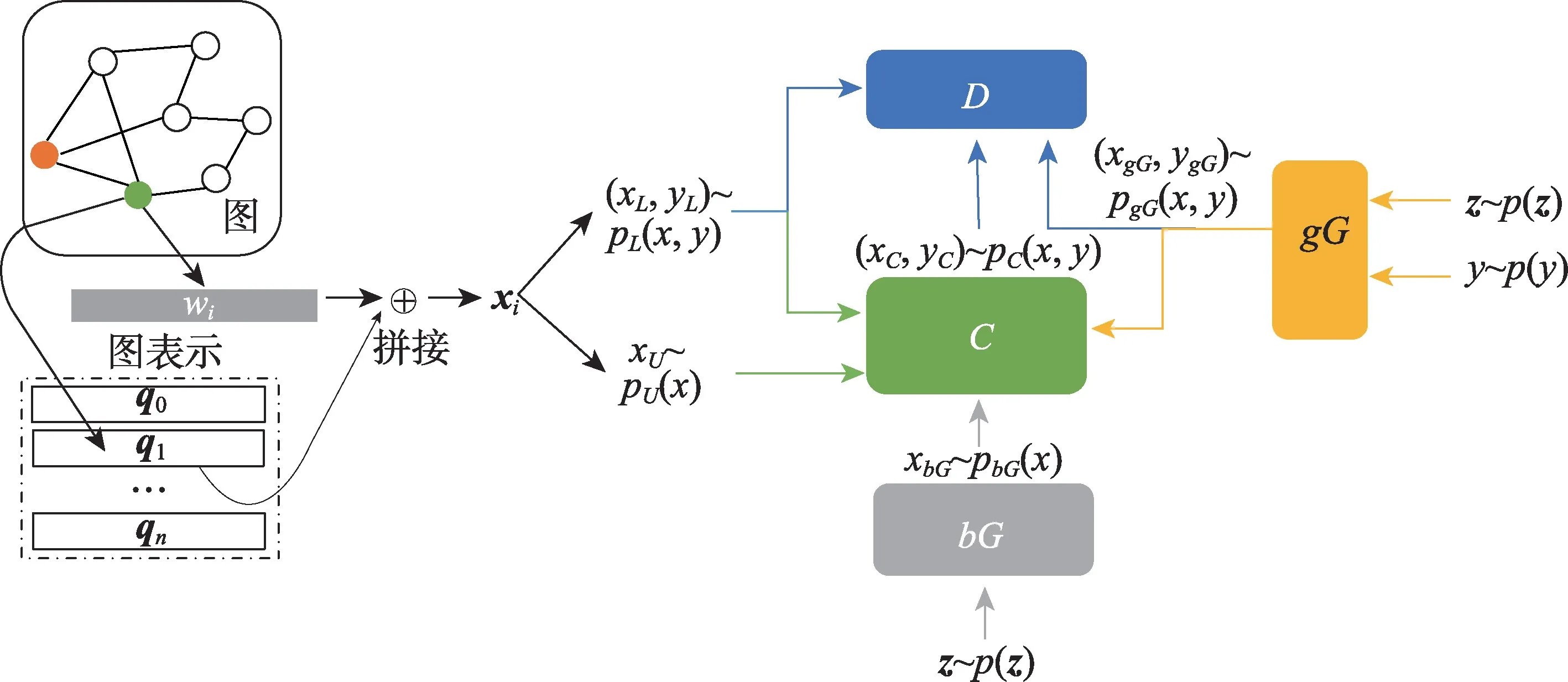
图1 SemiGATDS 模型示意图Fig.1 Illustration of SemiGATDS
2.3 SemiGATDS 算法流程
在模型中,考虑“K+1”类分类问题。gG首先通过真实标签y和200 维随机噪声z,采样于先验分布Pz(z)(实验中使用均匀分布噪声z)生成样本xgG∼PgG(x|y,z),与条件标签y组成标记样本。接着bG通过随机噪声z生成未标记样本xbG∼PbG(x|z) 。C接受四种不同类型的样本:标记样本xL、未标记样本xU、来自gG的生成样本xgG和来自bG的生成样本xbG,并依据条件分布PC(y|x)为它们产生伪标签。对于带标签的数据xL和gG生成的样本xgG,期望C为它们分配正确的标签(为xL分配标签yL,为xgG分配它的条件标签y)。对于bG生成的样本xbG和未标记样本xU,期望C将它们分别识别为第“K+1”类(即“假”类)和前K类其中之一。D接受C和gG生成的样本标签对(xC,yC) 和(xgG,ygG),以及标记样本(xL,yL)作为输入,并将标记样本标签对视为真样本,而来自gG和C的样本标签对均为假样本。定义各个部分的损失如下:
将gG的损失函数定义为:
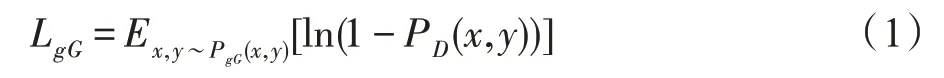
其中,PD(x,y)表示样本标签对(x,y),来自真实样本分布的概率,最小化损失函数,使得gG生成更接近真实样本分布的标记样本。
bG的损失函数定义为:
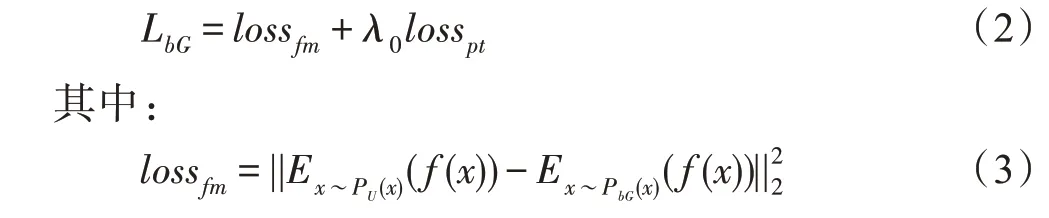
为特征匹配损失,它最小化了bG生成样本与真实样本中心点之间的距离,以确保生成器在类和类之间的密度间隙中生成样本。
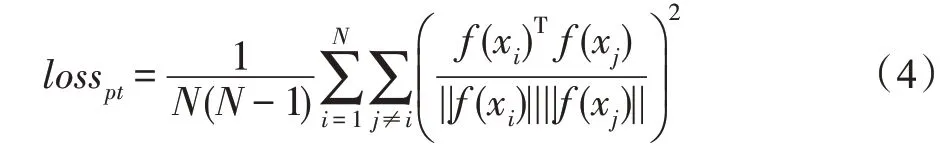
为pull-away term[11],它具有增加生成特征的多样性从而增加生成熵的效果,这里可以鼓励bG生成更多不同类别的样本。其中N是批次大小,xi、xj是同一批次的样本。λ0是用来平衡两个损失的超参数,实验中将其设置为1。
C的损失函数由四部分组成:
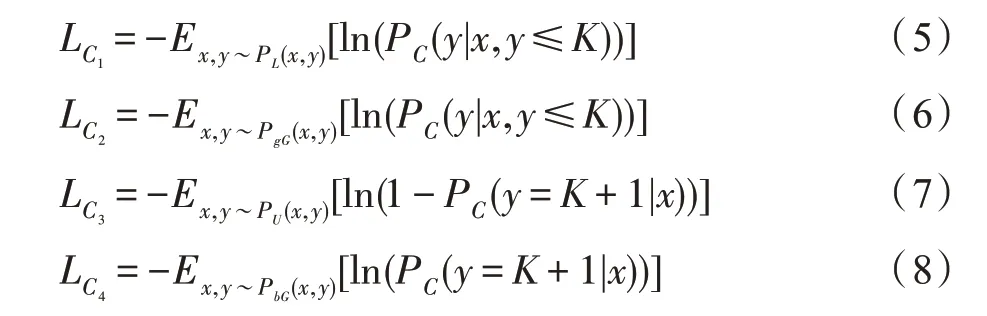
C的总损失是:
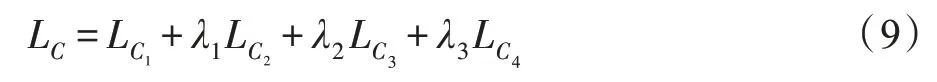
其中,损失和损失分别表示标记样本和gG生成样本的交叉熵损失,损失迫使C将未标记样本识别为前“K”类,而损失迫使C将bG生成的样本识别为“K+1”类。λ1、λ2、λ3是用于平衡每个损失的超参数,实验中将这三个超参数均设置为0.5。
最后,判别器D的损失由三部分组成,分别为:
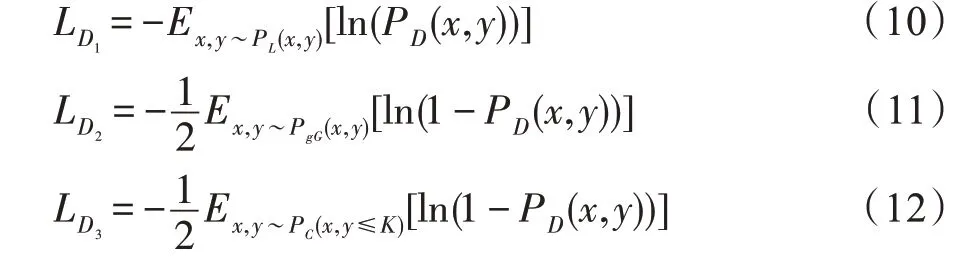
D的总损失是:

其中,损失迫使判别器D增大真实标记样本对被视为真类的概率,损失和迫使判别器D减小生成样本标签对被视为真类的概率,β1、β2是用于平衡每个损失的超参数,实验中将这两个超参数均设置为1。
在训练过程中,SemiGATDS 由三组对抗训练组成:(1)gG通过生成以标签y为条件的标记样本来与D进行对抗训练;(2)C通过为未标记样本生成置信度高的标签与D进行对抗训练;(3)bG通过生成未标记样本与C进行对抗训练。生成的未标记样本迫使分类界限更清晰,生成的标记样本对扩充了监督信息,模型从这两种生成样本中学习。详细的训练过程如算法1 所示。
算法1SemiGATDS 训练算法


2.4 算法复杂度分析
假设给定图G=(VL⋃VU,E),其中节点总数为s(包含标记节点和未标记节点),节点特征维度d,图嵌入表示维度e,节点类别数为k。本文算法的时间复杂度主要由计算节点的潜在分布表示和训练生成器、分类器、判别器四个神经网络产生。其中图嵌入算法TADW 的时间复杂度为O(s2)。
本文使用的生成器、分类器、判别器均采用全连接神经网络结构。神经网络时间复杂度依据浮点运算次数计算,一次浮点运算可以定义为一次乘法和一次加法。生成器和判别器均是拥有两个隐藏层的神经网络,分别具有(c1,c1)个神经元,bG生成器输入为随机噪声z,维度为t1,输出为节点特征和节点图嵌入表示拼接后的维度d+e,第一层执行t1×c1次乘加操作,第二层执行c1×c1次乘加操作,最后一层执行c1×(d+e) 次操作,总共执行t1×c1+c1×c1+c1×(d+e)次操作,假设每批次训练m个样本,bG生成器的总操作次数为m(t1×c1+c1×c1+c1×(d+e)),时间复杂度为O(m×c1×(d+e))。gG生成器输入为随机噪声z与标签y的拼接,标签y经过编码后其维度为t2,因此gG生成器的输入维度为t1+t2,其每批次训练m个样本,gG生成器的总操作次数为m((t1+t2)×c1+c1×c1+c1×(d+e)),时间复杂度为O(m×c1×(d+e))。判别器D的输入维度即节点特征维度为d+e,输出为真假即维度为1,其每批次训练总操作次数为m(c1×(d+e)+c1×c1+c1),时间复杂度为O(m×c1×(d+e))。分类器C输入维度即节点特征维度为d+e,拥有5个隐藏层的神经网络,分别具有(c1,c1,c2,c2,c2)个神经元输出为类别个数,其维度为k。以此类推,每批次训练总操作数为m((d+e)×c1+c1×c1+c1×c2+2c2×c2+c2×k),时间复杂度为O(m×c1×(d+e))。
综上,SemiGATDS 算法总的时间复杂度为O(s2)+O(m×c1×(d+e))。
3 实验结果与分析
3.1 数据集和实验设置
数据集统计汇总如表1 所示。在引文网络数据集Citeseer、Cora 和Pubmed 中,节点是文档,边是引文链接。标记节点数表示用于训练的标记节点的个数。每个文档都有以词袋模型(bag-of-words model)表示的特征,并根据主题赋予特定的标签。
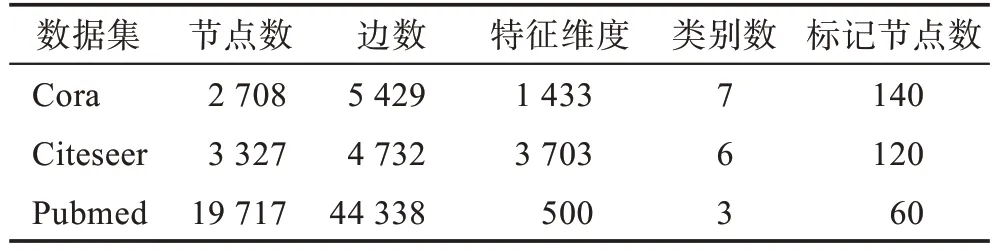
表1 数据集统计Table 1 Dataset statistics
为了避免过度调整网络体系结构和超参数,所有实验均使用默认设置进行训练与测试。具体地说,分类器C有5 个隐藏层,分别具有(500,500,250,250,250)个神经元。随机层采用零均值高斯噪声,隐藏层输入标准差为0.05,输出标准差为0.5。生成器bG具有两个500 个神经元的隐藏层,每个隐藏层后面都有一个批归一化层,输出层使用Tanh 激活函数。生成器gG和bG具有相同结构,不同的是前者以噪声z和真实标签y的拼接作为输入。判别器也采用和生成器相同的隐藏层结构,只是对输入层和输出层作了相应的调整。模型由ADAM 进行优化,所有参数均使用Xavier初始化方法。
3.2 模型比较
为了公平比较,实验遵循文献[16]中的设置,对于每个类,选择20 个样本(文档)作为标记样本用于训练,同时选择1 000 个样本作为测试样本。所有实验结果取10 次随机拆分的平均值。在这3 个数据集中,将提出的方法SemiGATDS 与4 类方法进行了比较:
(1)基于正则化的方法LP(label propagation)[11]、ICA(iterative classification algorithm)[25]和ManiReg[13];
(2)基于图嵌入的方法DeepWalk[17]、SemiEmb[15]和Planetoid[16];
(3)基于图卷积的方法Chebyshev[26]、GCN[18];
(4)基于GAN 的方法Triple-GAN[22]、GraphSGAN[3]。
由于原始Triple-GAN 并未用于图,本文在图上重新实现了Triple-GAN,并复现了GraphSGAN,在3个数据集上进行了实验。其中Triple-GAN 的生成器生成服从真实样本分布的标记样本,而GraphSGAN的生成器生成与真实样本分布不同的未标记样本。
本文在3 个数据集上均训练了200 个epoch。表2 显示了SemiGATDS 与上述方法对比的实验结果。
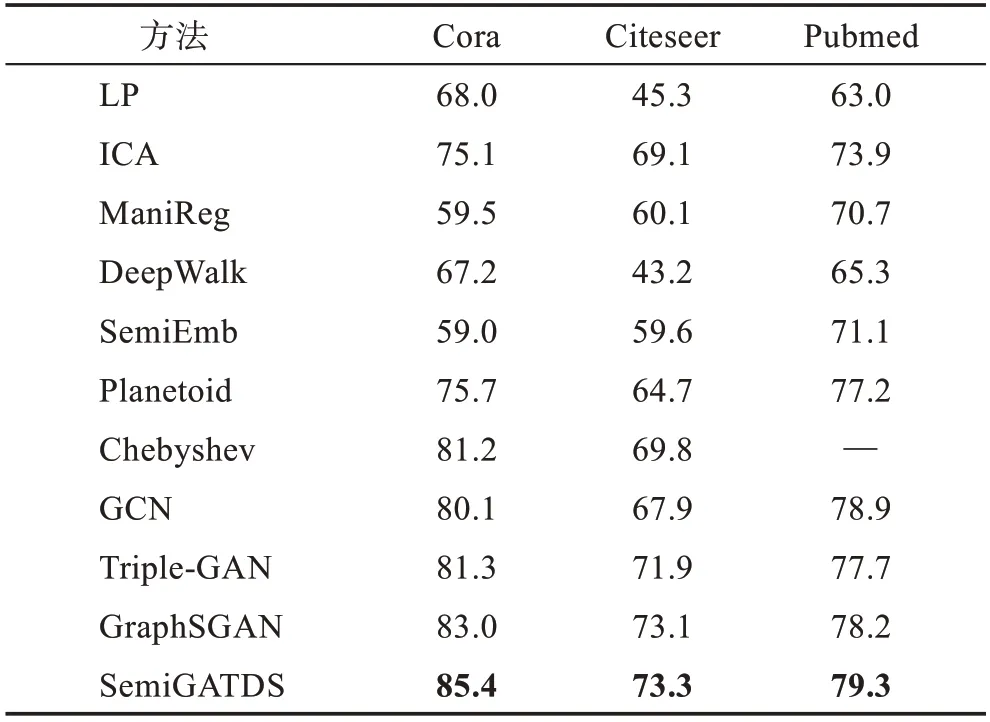
表2 分类准确率汇总Table 2 Summary of results of classification accuracy 单位:%
实验结果表明,本文方法优于所有基于正则化、图嵌入以及图卷积的方法,且比Cora、Citeseer 和Pubmed 数据集上的最佳结果分别提升了2.4 个百分点、0.2 个百分点和0.4 个百分点。同时由表可知,在Cora 和Citeseer 数据集上,基于GAN 的方法均优于其他方法,也验证了将生成对抗网络用于图半监督学习任务的有效性。而GraphSGAN 的效果优于Triple-GAN,说明产生的与真实样本分布不同的未标记样本对分类效果影响更大。SemiGATDS 结合两者的优点,同时生成的服从真实样本分布的标记样本和与真实样本分布不同的未标记样本,共同对模型产生了影响,获得了比Triple-GAN 和GraphSGAN 更好的结果,从而验证了SemiGATDS 的有效性。
3.3 不同数量的标记样本对模型的影响
为了进一步了解SemiGATDS 使用不同数量的标记样本训练时的表现,本文通过改变每类选择的标记样本的数量n获得不同的训练集。表3~表5 显示了3 个数据集上的实验结果。由表可知,随着有标记样本比例的增加,用于训练模型的数据增加,模型能够学到的信息越多,从训练数据中得到的模型的分类性能越好。以Cora 数据集为例,当n为10 时,Triple-GAN、GraphSGAN 和SemiGATDS 分类准确率分别为76.4%、82.9%和83.5%;当n为20 时,它们的分类准确率上涨到81.3%、84.0%和85.4%。并且当n值相同时,SemiGATDS 所获得的结果仍然好于GraphSGAN 和Triple-GAN。同 样的,在Citeseer 和Pubmed 数据集上也可以观察到相同的结果,说明生成的标记样本可以扩充图半监督学习中的标记样本训练集,生成的未标记样本可以强制决策边界位于正确的位置。这两种生成样本同时起作用,使Semi-GATDS 获得了更好的效果。
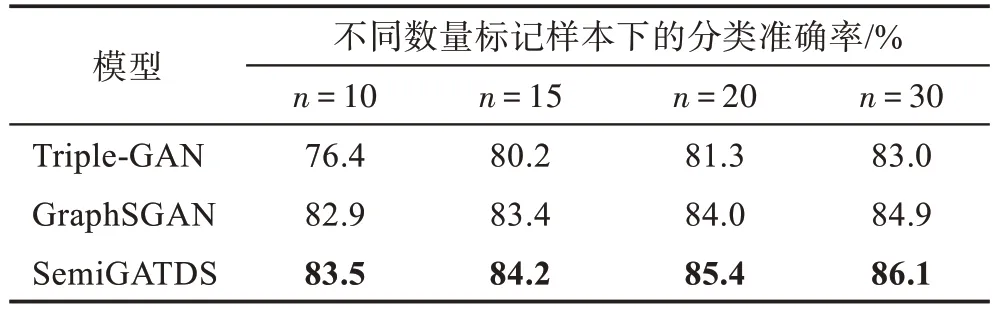
表3 Cora 数据集上不同数量标记样本下的分类准确率Table 3 Classification accuracy under different number of labeled samples on Cora dataset
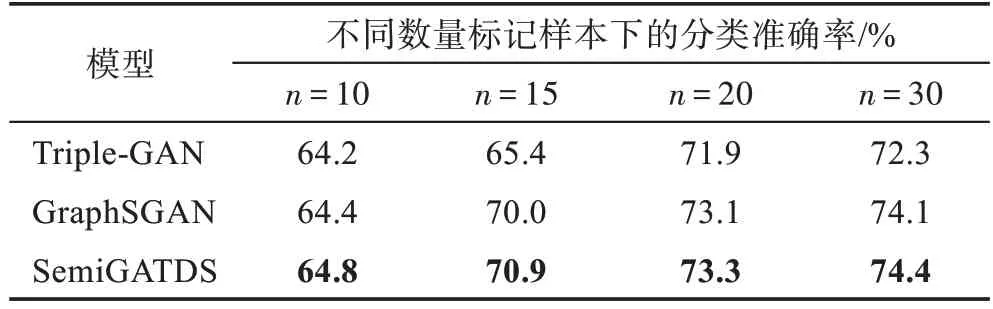
表4 Citeseer数据集上不同数量标记样本下的分类准确率Table 4 Classification accuracy under different number of labeled samples on Citeseer dataset
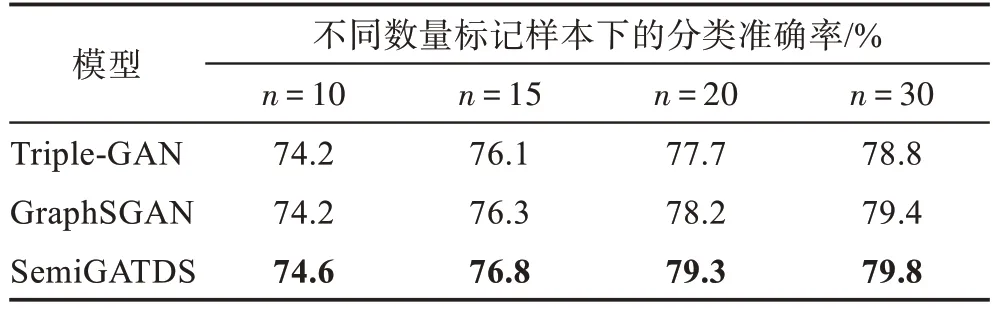
表5 Pubmed 数据集上不同数量标记样本下的分类准确率Table 5 Classification accuracy under different number of labeled samples on Pubmed dataset
3.4 模型在不同epoch 下的性能
在Cora 数据集上,本文对比了Triple-GAN、GraphSGAN 和SemiGATDS 的分类准确率与epoch的关系,实验取了前20 个epoch 的结果,如图2 所示。

图2 算法在Cora 数据集上分类准确率与训练周期的关系Fig.2 Relationship between classification accuracy and training period of algorithms on Cora dataset
通过观察发现了两个不同的训练阶段:
一阶段:三个模型训练波动比较大。推测是因为在初始阶段生成的样本质量不高,对模型造成了干扰。
二阶段:模型趋于稳定,SemiGATDS 明显超过了Triple-GAN 和GraphSGAN。从分类器的角度看,gG生成的标记样本用于扩充图半监督学习中标记样本训练集,bG生成的未标记样本减少了密度间隙中邻近节点的影响。两种生成样本的共同作用,使得分类器得到了更好的分类效果。
3.5 生成样本的比例对模型的影响
为了探究生成的未标记样本和标记样本的比例对实验结果的影响,本文对比了模型在3 种数据集Cora、Citeseer、Pubmed 上,不同生成比例下的性能,如表6~表8 所示。
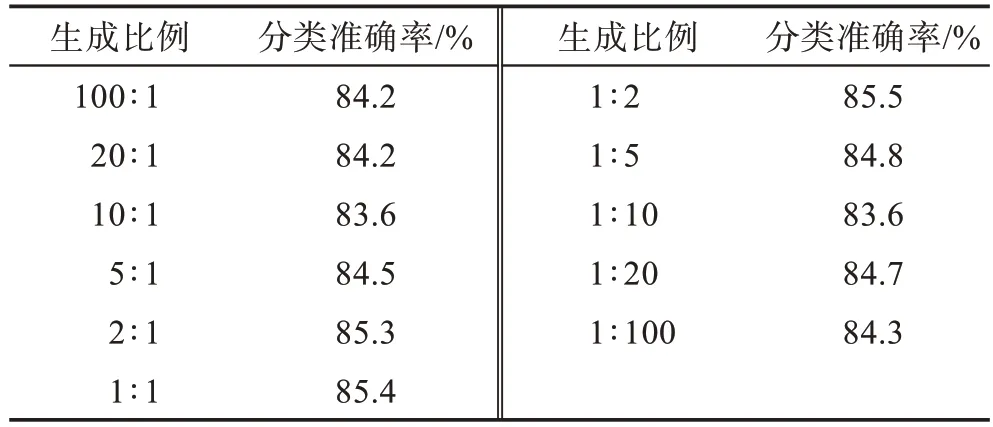
表6 SemiGATDS 在Cora 数据集上不同生成比例(未标记样本∶标记样本)的分类准确率Table 6 Classification accuracy of SemiGATDS under different generation ratios(unlabeled samples∶labeled samples)on Cora dataset
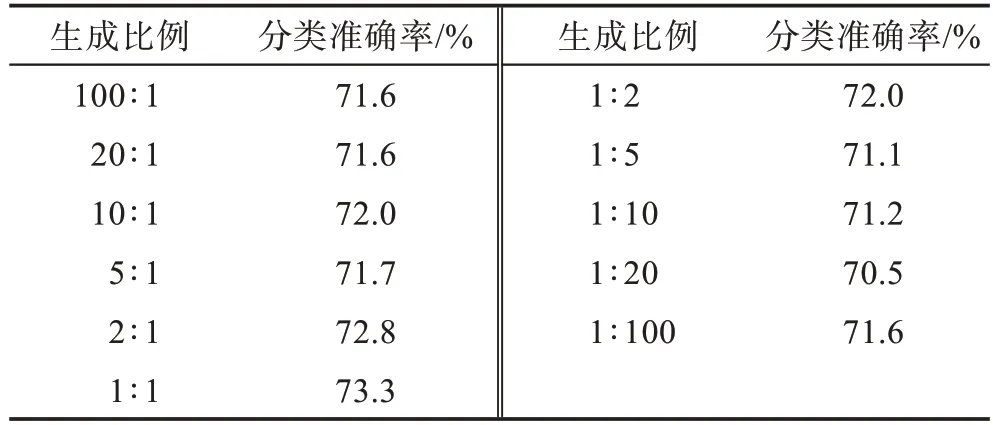
表7 SemiGATDS 在Citeseer数据集上不同生成比例(未标记样本∶标记样本)的分类准确率Table 7 Classification accuracy of SemiGATDS under different generation ratios(unlabeled samples∶labeled samples)on Citeseer dataset
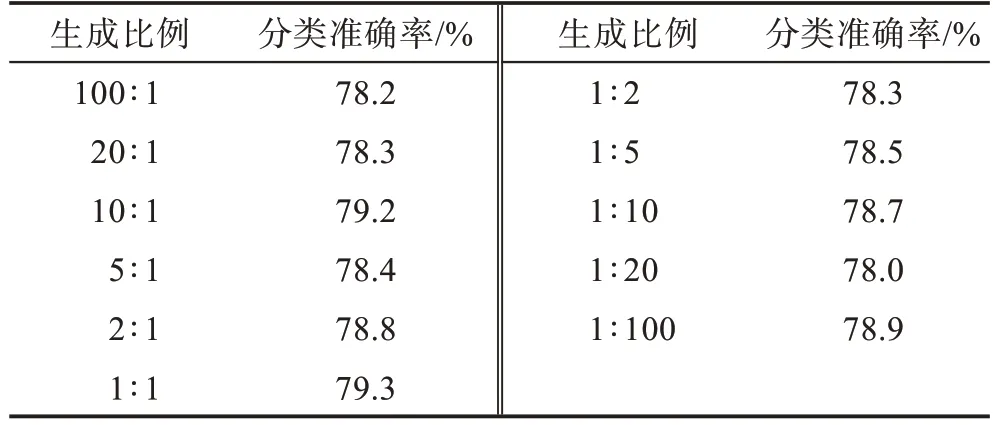
表8 SemiGATDS 在Pubmed 数据集上不同生成比例(未标记样本∶标记样本)的分类准确率Table 8 Classification accuracy of SemiGATDS under different generation ratios(unlabeled samples∶labeled samples)on Pubmed dataset
从表中结果可以得出如下结论:在Citeseer、Pubmed 两个数据集上,当生成的未标记样本和标记样本比例为1∶1 时,模型的效果更好。在Cora 数据集上,当生成的未标记样本和标记样本比例为1∶2 时模型的效果更好,但生成的未标记样本和标记样本比例为1∶1 和比例为1∶2 的效果相差不大,因此最终选取1∶1 的比例作为所有实验的基准。
4 结论
现有基于GAN 的图半监督学习算法能有效提升半监督学习的分类性能,但标记样本过少仍是其面临的主要困难。针对这个问题,本文提出了一种基于GAN 的图半监督学习框架SemiGATDS,它通过生成器、分类器以及判别器之间的对抗训练,同时生成服从真实样本分布的标记样本和与真实样本分布不同的未标记样本,当模型达到稳态时,生成的标记样本可以扩充标记样本训练集,生成的未标记样本可以减少密度间隙中邻近节点的影响,使决策边界更清晰,从而提高图半监督分类的效果。在多个数据集上本文提出的SemiGATDS 均优于现有的方法,进一步讨论了不同数量的标记样本和不同生成样本比例对SemiGATDS 性能的影响,实验结果验证了该方法的有效性。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
公民与法治(2016年10期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
