
实时光线追踪相关研究综述
2023-02-18 07:15黄立波王永鑫张鑫铖张鸿儒
计算机与生活 2023年2期
闫 润,黄立波,郭 辉,王永鑫,张鑫铖,张鸿儒
国防科技大学 计算机学院,长沙410073
渲染是将三维场景的描述转换为二维图像的过程。在动画[1-2]、电影特效[3]、高端游戏[4]、几何建模、纹理处理等应用中都必须通过某种形式的渲染过程传递3D 场景的结果。渲染主要包括光栅化(rasterization)[5]和光线追踪[6]两种方式。光栅化渲染采用局部光照原理,根据光源照射到物体上直接可见的光照效果,将场景中的几何图元映射到图像的像素点上。这种方式用硬件实现较为简单,且便于并行处理,通常用作实时渲染处理。光线追踪采用全局光照模型,通过物理原理对光线和物质之间的交互行为进行建模,不仅考虑直接光照的效果,也考虑物体间相互光照影响,比传统的光栅化渲染效果更加立体,色彩更柔和更逼真,通常用于离线渲染处理。两种渲染方式的区别如图1 所示。
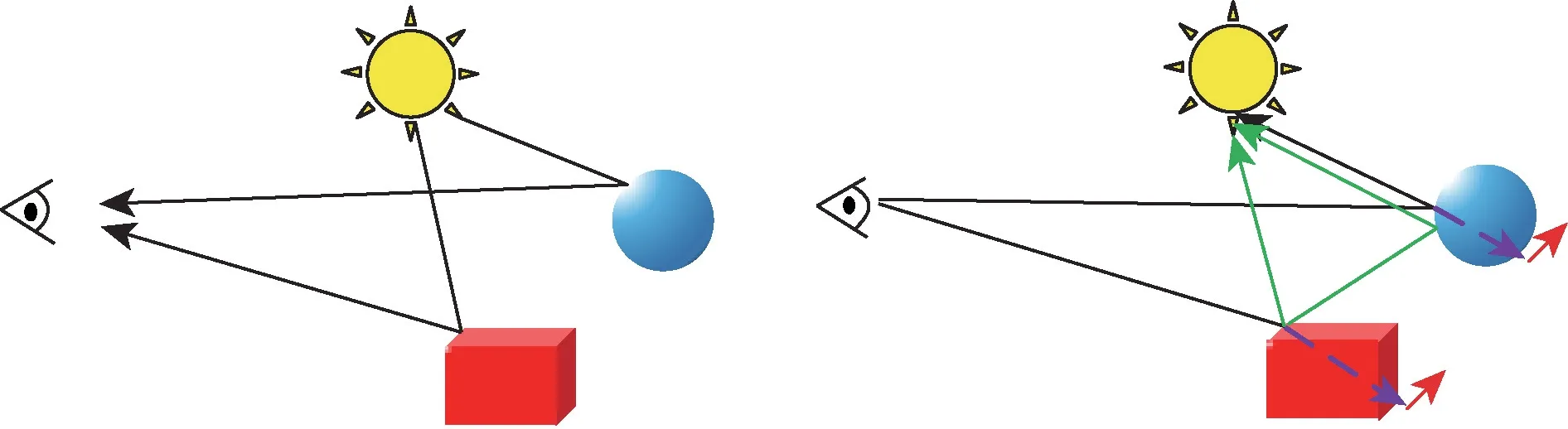
图1 光栅化与光线追踪Fig.1 Rasterization and ray tracing
由于光线追踪渲染计算量巨大且非常耗时,实时光线追踪存在很多挑战。首先,光线追踪算法需要迭代测试光线与场景图元是否相交,并计算光线与图元的最近交点,这个计算量是巨大的;其次,光线的反射和折射会产生大量的二次光线(secondary rays),这些光线随着迭代次数的增加会变得越来越不连续(incoherent),不规则的内存访问会导致带宽的瓶颈。针对这些问题,研究者做了大量的工作,为给后续研究者提供参考。本文从商用光线追踪平台、算法优化、硬件优化三方面综述光线追踪的发展,并对未来可能的研究方向做出展望。
1 光线追踪研究相关理论
1979 年Whitted[6]利用光线的可逆性,提出了光线追踪算法。这个算法模拟真实的光照效果,在场景中的光线与物体相交后会因反射、折射和阴影等产生二次光线,二次光线再次到场景中进行相交测试。如此进行迭代计算,直到光线的反弹次数达到预期设置的值。
光线追踪的本质在于寻找与光线相交的最近物体。为了加快遍历速度,最初的方式是有规律地划分空间网格(grid)[7-8],但这种方法存在着空间划分不合理、冗余计算较多等问题。在后续的研究中提出加速数据结构(acceleration structure)的概念,其思路是将场景中的图元划分到不同的分层空间结构(hierarchical spatial structure)中,在这种结构下,可以快速剔除那些不相关的空间,进而识别出与光线最接近的图元。现在广泛应用在学术界和工业界的是一种树形数据结构,树的叶节点包含所有场景图元,树的内部节点用于将一个较大的空间表示细分为多个较小的空间区域kd-tree[9]或将场景中的对象分解为更小的对象集合BVH(bounding volume hierarchy)[10]。为简化运算,通常采用轴对齐边界框(axis-aligned bounding box,AABB)进行场景的划分。
kd-tree 之前被认为是最适合光线追踪的加速数据结构[11],但由于kd-tree 在判断包围盒与图元是否有交集等方面存在的局限性,越来越多的研究倾向于使用BVH。相比kd-tree,BVH 有着可预测内存、更好的鲁棒性、更有效的遍历和多变的构建算法等[12]优势,使得BVH 成为离线和实时渲染领域应用的标准加速数据结构。
2 商用光线追踪平台
现代计算机、移动平台和游戏机使用GPU 进行渲染,为满足日益增长的视觉需求,GPU 已经成为最强大的单芯片计算单元。GPU 通常分为两类,通用GPU 和移动端GPU,这两种GPU 是针对不同应用场景和硬件资源约束下设计的。前者允许更高的硬件开销来追求高性能,而后者需要考虑能耗开销的限制。目前,NVIDIA 和AMD 是高端通用GPU 的两大厂商,Intel 在中低端GPU 市场占有相当大的份额。移动端GPU 市场主要包括Imagination Technologies(Power VR)、ARM(Immortalis)和Qualcomm(Snap-Dragon)等。本文选择NVIDIA Ampere 架构[13]、AMD RDNA 2 架 构[14]和Imagination PowerVR Photon 架 构[15]进行介绍。
2.1 NVIDIA Ampere
NVIDIA 于2018 年在Turing 架构[16]中推出初代RT core,RT core 被集成到Turing 架构的流多处理器(streaming multiprocessors,SM)中。在2021 年推出的Ampere 架构[13]对初代RT core 进行了升级,该架构的GPU 集成了84 个二代RT core,相对于初代RT core,光线与三角形相交测试的速率提升了一倍。二代RT core见图2[13]。
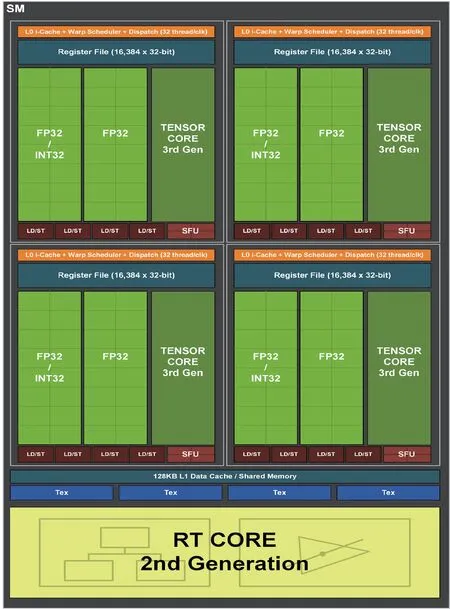
图2 二代RT coreFig.2 The second generation of RT core
两代支持光线追踪的GPU 均采用多指令多数据流(multiple-instruction,multiple-data,MIMD)架构。RT core 可以执行BVH 的遍历以及光线与三角形相交测试,光线从流多处理器发送到RT core,RT core获取并解码BVH 的内存,使用专用的硬件测试每条光线与BVH 的相交,判断出当前节点是内部节点或是叶子节点,如此迭代有选择地找到最近的交点。确定合适的交点后,将结果返回到流多处理器进行进一步处理。二代RT core 中增加了差值三角形位置单元,主要用于光线追踪中的运动模糊[17]功能。NVIDIA 推出的深度学习超级采样(deep learning super sampling,DLSS)[18]技术结合GeForce RTX GPU上的Tensor Core,利用深度学习神经网络来提高帧率,将视觉保真度提升至全新高度。
2.2 AMD RDNA 2
2020 年,AMD 不仅在游戏中引入了对实时光线追踪的支持,而且还发布了RX 6000 系列的三款GPU。与此同时,引入一些RDNA 2 架构设计的关键元素来实现这一功能,为了提高光线追踪的性能,在核心计算单元设计中加入了光线加速器(ray accelerator)[14],该加速器是用于处理光线相交计算的专用硬件。RX 6600 XT 集成28 个光线加速器,2022 年推出RX 6950 XT 集成80 个光线加速器。RDNA 2 架构采用了AMD Infinity Cache 的高效缓存技术,能够以低功耗和低延迟提供卓越的带宽性能,整个显卡核心均可访问这个全局高速缓存。除此之外,还采用了AMD FidelityFXTMSuper Resolution(FSR)[19]的优化升级技术,能够在无需用户升级显卡的情况下帮助提高部分游戏的帧率,带来高质量、高分辨率的游戏体验。
2.3 Imagination PowerVR Photon
2016 年,Imagination 公司推出了世界上首个满足实时光线追踪的加速器专用芯片。2021 年,Imagination 将PowerVR Photon 架构[15]的光线加速集群(ray acceleration cluster,RAC)加入到C 系列的GPU中,为手机市场提供光线追踪的IP 技术。
在IMG CXT 中,使用RAC 来完成所有的光线追踪活动,示意图可见图3[15]。本文对RAC 的主要模块进行简要说明。每个RAC 包含多个光线测试单元(ray testing units),也即框图中的BTU(box tester unit)、DTTU(dual triangle tester unit)和PTU(procedural tester unit),这个模块主要完成光线和BVH 的遍历和光线与图元的测试。为了提高执行效率,在硬件上设计了高度并行的“双三角形测试(DTTU)单元”,可以同时进行光线对两个三角形的相交测试,并将测试结果用于过程性测试单元(procedural tester unit),过程性测试单元主要用于与API 的交互着色;光线存储(ray store)单元用于保证RAC 中所有单元的高带宽读写访问;连续光线束收集(packet coherence gather)单元主要用来分析所有活跃的光线,并创造轨迹相似的连续(coherence)光线的分组,这里涉及到光线重排序的概念,具体内容将在本文3.3 节中进行描述。光线任务调度(ray task scheduler)单元主要负责RAC 与GPU 的交互以及RAC 内部各处理阶段之间的协调通信。Power VR 架构包括许多受专利保护的创新,其中包括延迟渲染(tile-based deferred rendering,TBDR)技术、Imagination 图像压缩(IMGIC)技术、去中心化多核(decentralised multi-core)技术等。

图3 Imagination PowerVR RAC 架构Fig.3 Architecture of imagination PowerVR RAC
Imagination Power IMG CXT 的GPU 分为单核和多核两款,分别应用于移动端配置和非移动端配置,峰值性能可以达到1.3 Gray/s和7.8 Gray/s。
表1 列出了三款GPU 的详细对比数据。可以看出,AMD RX 6900 XT 系列光线加速器与NVIDIA GeForce RTX30 系列RT core 相比在光线追踪功能上相似,但RT core 已经是第二代产品,在技术和架构上都有了很多改进,包括使用GPU 中的Tensor Core 利用DLSS 技术扩展性能,这使得RT core 比AMD 的光线加速器实现更高效、更强大的光线追踪性能。AMD 的RX 6950 XT 采用了更先进的工艺,具有更高的时钟频率。NVIDIA 的GeForce RTX 3090 Ti 拥有更强大的性能和几乎两倍的内存带宽。另一个主要区别是功耗,NVIDIA 的GPU 比AMD 的多出115 W的功率。除此之外,二者的价格差距也非常明显,NVIDIA GeForce RTX 3090 Ti 价格约为AMD RX 6950 XT 价 格 的1.7 倍。Imagination PowerVR 架 构 主要面向移动端的IP 市场,相对于两款桌面系统的GPU 性能稍差,但是由于其架构的优异性,可以预见,将来会广泛应用在移动端市场。

表1 支持光线追踪GPU 的比较Table 1 Comparison of supporting ray tracing GPU
3 光线追踪算法的优化
由于光线追踪算法需要递归地检查光线与加速数据结构和图元的相交,最终找到与光线相交最近的图元,这个过程运算量大耗时长。为满足实时性需求,研究者提出了基于硬件架构的算法优化方法,包括光线束并行、无栈遍历、光线重排序和多分支BVH 等。另一方面,将降噪技术和神经网络技术与光线追踪相结合,可以实现更好的交互性和实时性。
3.1 光线束(packet)遍历
在早期利用单指令多数据流(single-instruction,multiple-data,SIMD)架构进行光线遍历的方法中,光线束是最简单的并行组织形式,将多条光线当作一个光线束,调度到GPU 的线程束(warp)或CPU 的不同线程中进行处理,不同光线共享遍历栈。因此同一个光线束遍历的顺序是一致的。只要其中的一条光线与某个节点相交,那么整个光线束都遍历该节点的子树,如图4 所示。光线会访问一组节点,包括它们不相交的节点,如果光线的连续性很好,那么这种方式性能会十分理想,但是如果连续性较差,那么执行效能会因为冗余的计算大打折扣,此外该方式的性能也受到内存带宽的限制。
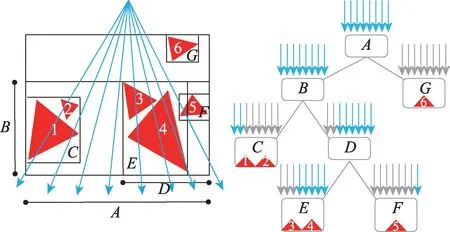
图4 光线束遍历Fig.4 Ray packet traversal
Wald等[20]使用CPU 的SSE(streaming SIMD extensions)向量指令最早提出了光线束的遍历算法,连续光线和阴影光线性能得到了巨大提升。Boulos 等[21]主要探索在BVH 作为加速数据结构的情况下,将二次光线分成阴影光线、反射光线和折射光线三种光线束来进行光线追踪,使得光线束的组合更加合理,性能得到较大的提升。Gunther 等[22]采用了BVH 在GPU 上进行光线束的并行处理,同时利用GPU 快速构建BVH,通过实验结果来看,渲染速度在1 024×1 024 的分辨率下,可以达到3 FPS(frame per second)。Mansson 等[23]探索了使用不同的方式来重新组织光线束的连续性,并在研究中限制4×4 光线束,仅在文献[24]中的算法使用。Overbeck 等[25]在总结优化先前研究成果基础上,提出了一种32×32 光线束的更宽遍历范围的优化算法。Aila等[26]使用NVIDIA GTX285 GPU 对各类光线追踪算法进行了测试。实验数据表明,由于连续的内存访问,在访问少量冗余节点的情况下,光线束的性能可能会达到模拟的最佳性能,但实际性能不如预期。一种可能的解释是即使连续光线性能也受到内存带宽的限制,或者也可能是在实践中未能充分发挥架构的运算能力。Benthin 等[27]提出将光线束遍历和单条光线遍历的方式相结合,根据光线束的利用率在两种方式之间进行切换。Fuetterling等[28]结合向量指令提出了一种新颖的单条光线遍历的WiVe 算法,将这个算法作为块来构建基于光线束的遍历用于处理连续光线。相较于经典的光线束遍历的方式,该方式采用了区间运算(interval arithmetic,IA)的方式减少了包围盒相交测试的次数。根据他们的工作,总结光线束遍历方法如表2 所示。
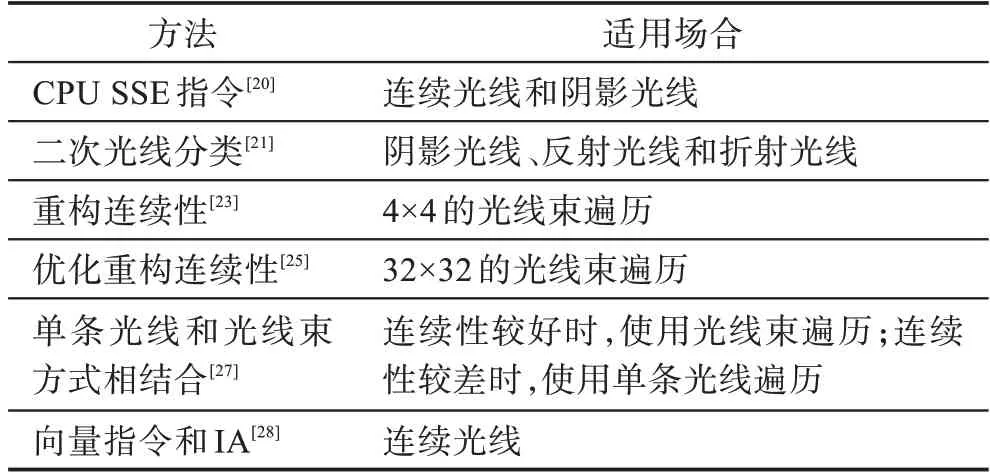
表2 光线束遍历的方法Table 2 Methods of ray packet traversal
3.2 无栈遍历
无栈遍历算法是光线追踪中常用的技术。这种算法的提出源于GPU 或CPU 中有限的寄存器空间,栈的编程复杂度和定制化硬件单元有限的片上存储资源。无栈的遍历算法带来了两点好处:一是按照特定的格式构造加速数据结构在遍历时可以减少内存的访问;二是无栈的遍历算法在GPU 平台可以提高并行度,提升计算性能。但通常需要在加速数据结构中设置标记位或进行冗余操作才可以完成无栈遍历。
Smits[29]提出了无栈的方法,使用跳跃指针(skip pointers)的方式将传统子节点的连接替换成命中(hit)或未命中(miss)的连接,在遍历的过程中,选择合适的连接。在当时的硬件体系结构中获得了大幅度的加速,但该方法导致代码的复杂度显著提升。Foley 等[30]最早提出了两种基于kd-tree 的无栈遍历方法:kd-restart 以及kd-backtrack。其中kd-backtrack 实现较为复杂,因此并不常用,之后的许多研究基于kdrestart 进行改进,两种算法虽然都实现了遍历加速数据结构,但是大量的重复节点遍历,导致效率并不理想。Thrane 等[31]采用BVH 作为加速数据结构,指出无栈的遍历方式会促进GPU 的高效实现,但是受制于算法对访存带宽的需求,性能提升仍是有限的。Popov 等[32]提出了可以显著提升GPU 性能的基于光线束的无栈算法。在这种算法中,采用绳索(ropes)将节点进行连接。该算法在迭代遍历的过程中,光线束中的一些光线可能不活跃,但是在递归返回父节点时,会再次激活这些光线。Laine[33]采用了无堆栈的重启轨迹技术,其主要思路是从根节点多次遍历,跳过之前访问过的子树,然后继续访问尚未访问的子树。为了做到这一点,每个层次结构设置一位,在遍历时设置一组短栈,当短栈不能被弹栈时,遍历会重启。Hapala 等[34]提出了一种新的迭代遍历算法,这个算法基于三种状态,为每个节点存储一个父指针,使用简单的逻辑状态推断下一步要遍历的节点。这就意味着整个BVH 不但可以从上到下遍历,还可以通过父节点方向回溯,结合标记可以到达对应的上一个待遍历的节点。如图5 所示,当遍历完当前节点C之后,假设遍历过程中记录了节点C是较近的节点,那么需要遍历节点F,因此可以通过读取父节点来得到节点F的地址后继续遍历。如果当前节点是较远的,可知节点N已经遍历过了,再根据父节点做类似的决策。但是这样的算法缺点是显而易见的,即每次回溯都需要读取父节点的数据,会造成冗余的读写操作。Binder 等[35]提出了一种具有恒定时间回溯的高效无栈算法。其主要思路是设置位集(bitset)来保存编码的当前节点路径,遍历的路径是显式存储的。为了在恒定时间回溯,作者提出了使用完美哈希表将编码路径转换为节点索引的方法。Vaidyanathan 等[36]在文献[33]的基础上将加速数据结构扩展到多分支BVH 无栈遍历的光线追踪应用中。光线追踪的无栈算法主要相关工作的总结与分析如表3 所示。
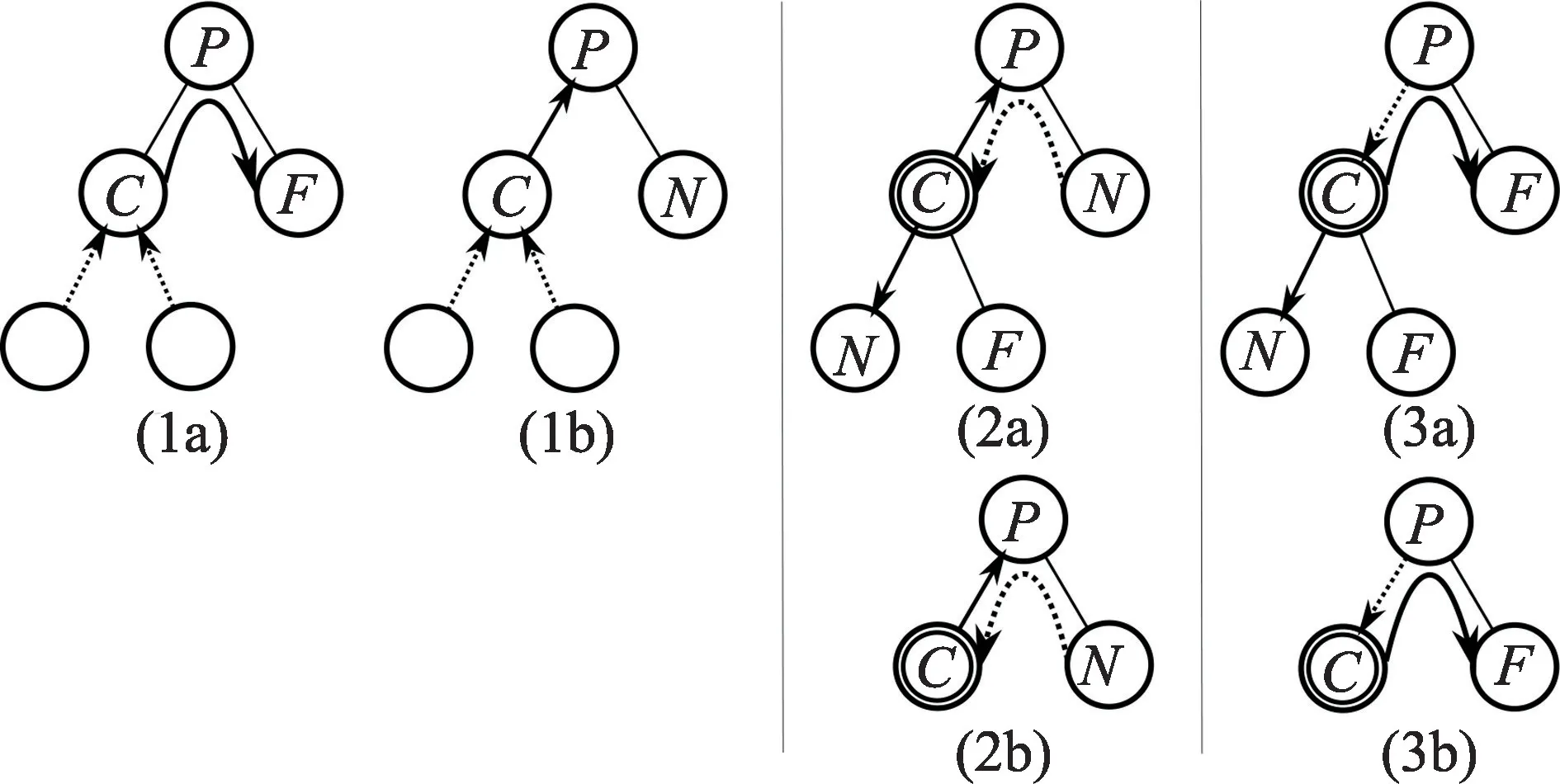
图5 无栈遍历Fig.5 Stackless traversal

表3 无栈算法的比较Table 3 Comparison of stackless approaches
3.3 光线重排序
现代光线追踪技术如路径追踪由于漫反射和光泽反射会产生越来越不连续的光线。光线束的遍历方法也需要连续的光线才能够保证高性能。此外不连续的光线会造成更高的内存带宽、更高的cache 缺失率和计算分支。光线重排序的方法可以在一定程度上缓解这一问题。
通过不同的方法可以实现不连续光线的重排序,其中运用最广泛的是将多维光线空间映射到使用标准排序算法排序键的一维空间,这个方法主要包括如下几种实现方式:(1)源点。按照源点对光线进行重排序是最简单的办法,形成一个3D 空间填充曲线,得到的子集有一致的源点,但这种方法排序的光线方向可能会大相径庭。(2)源点-方向。Reis 等[37]将方向的低位排到键中来参数化方向,使用这个键来对相同的源点进行排序,而后整合到同一个光线子集中,这个子集的光线个数是由排序键中表示分配的位数来确定。这种技术提高了光线的连续性,但是如果使用太多位数排序方向,光线的子集可能会覆盖整个方向范围。(3)方向-源点。该方法是源点-方向的一种替代方法,由Costa 等[38]提出主要用于阴影光线(shadow)和环境光遮蔽(ambient occlusion)排序,这种技术解决了排序键中方向和源点位数分配的问题。(4)源点-方向交叉。Aila 等[39]利用该技术研究了追踪不连续光线的行为。该策略采用排序键交替编码了源点和方向,因此它对于源点或方向占据的位数并不敏感。(5)两点键排序。该方法由Moon 等[40]提出,主要通过光线源点和终点来对光线进行排序来增强它们的连续性。这种划分方法会导致空间中不相交的光线子集重叠更小。但问题在于排序键需要知道光线的终点。(6)估计终点。Meister等[41]提出了两种估计终点的方法。第一种是设置恒定的比例(0.25)来估计光线的长度,另一种是基于自适应缓存之前的追踪路径的长度,而后采用一个空间哈希表来评估。基于上述几种评估方法,文献[41]采用RTX 2080Ti GPU 进行了性能测试比较。可以发现,通过光线重排序的方法使用DirectX[42]性能可以提高1.4 到2.0 倍,OptiX[43]可以提高1.3 到1.9 倍。不同方式在相同硬件下测算性能可见表4[41]。由于对光线排序需要大量的运算,在实践中收益可能不如表中的数据明显。由此可以看出,设计定制化的光线重排序硬件将对实时光线追踪产生深远的意义。
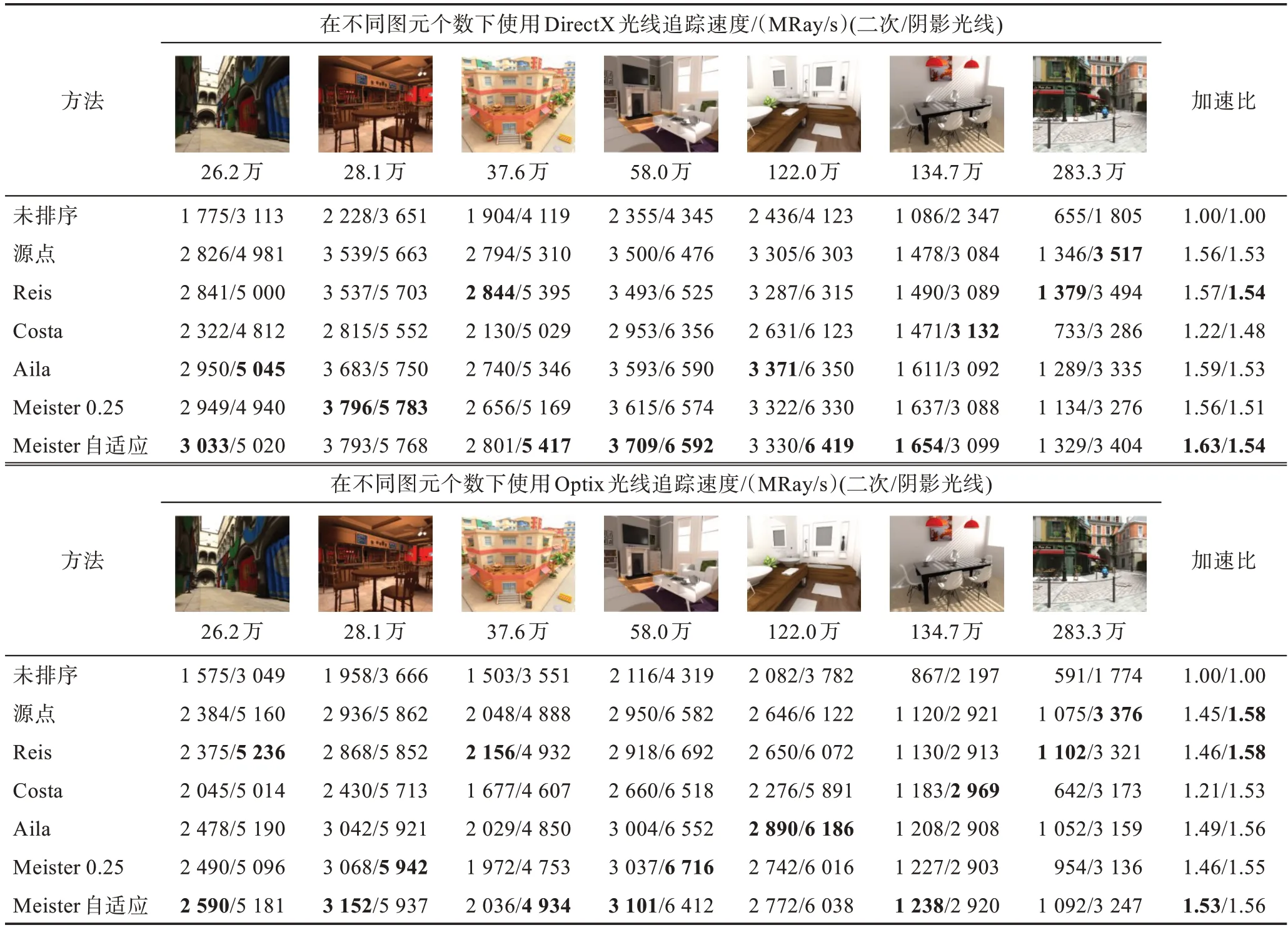
表4 不同方法光线重排序效率比较Table 4 Performance comparison of different approaches for ray reorder
3.4 多分支BVH
为了解决非连续光线的问题,研究人员提出了多分支(wide)BVH 的概念,该方法在每次遍历时只处理一条光线,在遍历某个节点时,加载某个子节点数据的同时,光线可以同时跳去处理另外一个子节点,这样的方式可以隐藏访存延时。随着子节点变宽,树的节点变小,栈的深度也减少。如果所有子节点的序号是连续的,那么栈只需要记录第一个序号和有效子节点的数量即可,因此也可以起到节省栈内存的作用。图6 以八叉树为例说明这种优化方式,可以看出这样的算法访存效率也会比较高,因为比常规二叉树包含更少的内部节点。但是这样的加速数据结构面临新的问题,对于多分支树,确定遍历需要比二叉树更多的比较和交换运算,造成巨大硬件资源的开销,此外还有一个缺陷就是多分支BVH 可能包含太多的空槽,每个节点也需要一个标记位来记录哪些节点是它的子节点,随着分支的增多,标记位需要占据更多的内存。
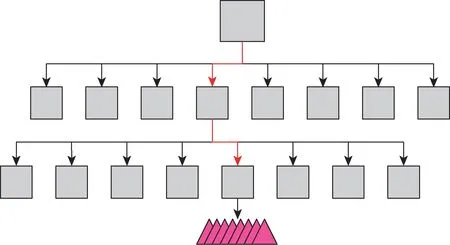
图6 八叉BVH 遍历Fig.6 8-wide BVH traversal
电影《赛车总动员(cars)》[44]是皮克斯公司使用光线追踪的第一部动画作品,该动画采用了多分支包围盒的方式进行渲染。Wald 等[45]和Aila 等[26]做了多分支树的探索,但是仅将一条光线分配到几个线程中。Ernst 等[46]首次提出了多个BVH(multi bounding volume hierarchies,MBVH)的概念。该算法将高度为2 的子树折叠为存储4 个BVH 的SIMD 节点,另外还需要每个叶节点都恰好包围4 个三角形,很好地提高了数据处理的并行性,使用CPU 处理对于随机光线追踪可以有2.8 倍的加速。Guthe[47]合并了四叉BVH,在NVIDIA Kepler和Fermi架构下,将不连续的光线性能提高20%。Ylitie 等[48]提出了一种压缩八叉BVH 的概念,这种设计可以减少内存带宽,主要是将子节点边界量化到一个局部网络,在NVIDIA Maxwell 和Pascal 架构下将不连续光线的性能提高3.3倍。Benthin 等[49]引入了专用的压缩叶子节点,通过只压缩叶子节点,降低了访存的需求,但是性能下降。Lier 等[50]在GPU 上使用模拟了传统应用在CPU上遍历的方法,分别测试了二叉树、四叉树和八叉树光线追踪的性能。这种方法使得GPU 上可以简单地实现各种宽度的BVH,同时会在不连续光线的实现上提高性能。
3.5 降噪技术
随着最新GPU 实时光线追踪解决方案的出现,在降噪领域的研究也逐步兴起。目前的降噪技术主要是基于蒙特卡洛的渲染技术进行解决。蒙特卡洛渲染是基于随机样本的累积来近似给定场景光线追踪结果的算法。目前降噪技术主要包括滤波技术、机器学习驱动的滤波器、改进采样和近似技术等。
图像滤波技术是在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制。McGuire 等[51]提出全局光照效果下球的边界处会产生可见的不连续性,在有限球体内使用3D 高斯衰减函数可平滑光照;Park 等[52]认为双边滤波由于可以同时考虑图像的空域信息(domain)和值域信息(range),用于光线追踪的降噪会取得较好的效果;Dammertz 等[53]提出了ÀTrous 滤波的降噪方式,这个方法利用蒙特卡洛计算的半球积分可能与相邻像素的半球积分非常相似的事实,使用À-Trous小波变换对全噪声图像进行运算,产生的结果接近于每个像素点具有更多采样点的方案;Schied 等[54]提出了一种基于低采样进行重构图像的时空差异导向滤波器(spatiotemporal varianceguided filtering,SVGF),结合时间和空间上的信息一起做滤波,根据历史帧信息引导当前帧的滤波。Mara 等[55]结合中值滤波的方式消除蒙特卡洛渲染图像的部分模糊和单采样点的“萤火虫”现象。Rousselle 等[56]在蒙特卡洛渲染中使用非局部均值滤波的方法迭代降噪。这种方法是一款基于特征的滤波器。
机器学习驱动的滤波器效果通常比传统的滤波器更优。Kalantari 等[57]认为基于特征的滤波器在噪声场景和理想滤波器参数之间存在着复杂的关系,因此采用非线性回归模型来学习这种关系,使用多层感知机神经网络,同时在训练和测试期间将其与匹配滤波器相结合,经过训练的神经网络驱动的滤波器参数可以生成近似基准图像的效果。Vogels 等[58]提出了一种用于降噪渲染图像噪声的模块卷积架构,主要通过将内核预测网络与一些特定任务的模块相结合,并使用非对称损失优化这一组合体,从而扩展了内核预测网络的功能。Xu 等[59]提出一种对抗性的蒙特卡洛降噪方法,生成对抗性网络通过从一组高质量蒙特卡洛光线追踪图像中学习分布,帮助降噪网络生成更真实的高频细节和全局照明效果。
Yang 等[60]对随机采样反锯齿算法(temporal antialiasing,TAA)进行了综述,指出用TAA 的时间滤波器可以有效去除以极低采样率渲染的光线追踪路径的噪声,但无法从根本上消除噪声。Schied 等[61]提出了一种新的基于时间的滤波器,可以随着时间的推移分析信号,从而得到每个像素的自适应时间累积因子,并重新调整着色采样的子集,以稀疏采样重构时间梯度。Koskela 等[62]提出了一种新的基于回归的重构流水线,叫作分块多阶特征回归(blockwise multi-order feature regression,BMFR),专门针对1 spp(sample per pixel)输入的实时光线追踪,相比其他的重构方法速度快1.8 倍,同时生成更好的渲染质量。
除此之外,还有通过近似技术优化光线追踪算法的实现。NVIDIA 在RTX 全局光照(RTXGI)[63]采样探针(probe)的数据结构中,进行实时计算和过滤照明与距离信息,构建具有可见性信息的高质量多次反弹照明缓存,主要通过光线追踪中的低频近似,为实时应用程序提供了质量和性能之间的理想平衡。近年来已经运用到商业游戏引擎中[64]。不同降噪技术的主要区别如表5 所示。
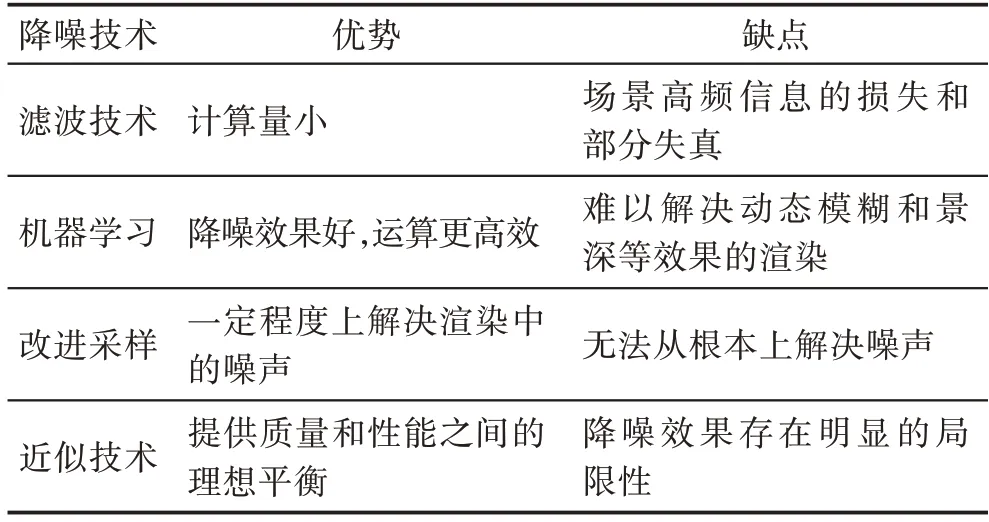
表5 降噪技术的比较Table 5 Comparison of denoising techniques
3.6 神经网络结合的实时光线追踪技术
基于神经网络的实时光线追踪技术除在降噪方面表现出强劲势头外,还可以用于图像的重构、神经辐射场(neural radiance fields,NeRF)优化、光线采样和图像超分辨率上采样等技术。
Chaitanya 等[65]采 用RNN(recurrent neural network)和自动编码器的神经网络方式,提出了一种适合蒙特卡洛渲染中噪声类别的网络变体,能够考虑更大的像素域,自动编码器可以完成图像的降噪和重构。Hofman 等[66]利用神经自适应采样技术,对光线追踪进行降噪和重构,可在单GPU上以1 920×1 080的分辨率交互运行。Kettunen 等[67]利用卷积神经网络提出了一种新的梯度域渲染重构方法,实验结果显著提高了光线追踪渲染中梯度域的质量,效果比使用其他降噪技术更优。
Verbin 等[68]结合NeRF 技术无法准确渲染光滑表面的情况,引入Ref-NeRF 的方式来解决这一情况,它用反射辐射的表示代替了NeRF 的视觉相关输出辐射的参数化,并使用空间变化的场景属性集合来构造函数,该模型显著提高了镜面反射的真实性和准确性。
Dahm 等[69]证明了增强学习方程和光传输模拟方程是相关的积分方程,基于这一对应关系,推导出了一种在采样路径空间时学习重要性的方案。主要是通过增强学习的Q-Learning 方式学习光线追踪路径散射的重要性采样,对零贡献的光采样大大减少,进而能够在固定的时间内生成噪声更少图像。
Dong 等[70]提出了一种单图像超分辨率(superresolution,SR)的深度学习方法,采用直接学习低/高分辨率图像之间端到端的映射,还扩展了神经网络以同时处理三个彩色通道,生成更好的图像质量。Ledig 等[71]提出了一种用于图像超分辨率的生成性对抗网络(super-resolution generative adversarial network,SRGAN),能够以4 倍放大因子推断照片级自然图像。Xiao 等[72]将基于神经网络的超分辨率上采样技术与实时渲染结合,通过现代渲染器中可用的特定信息(如深度和密度运动矢量)与一种新颖的时间网络设计相结合,能够在提供实时性能的同时最大限度地提高渲染质量,最高可以支持4×4 的上采样系数。Thomas 等[73]将基于机器学习的降噪技术和超采样技术结合,提出了一种用于实时渲染的新型神经网络架构,比使用两个单独的网络成本更低,效果优于与神经网络上采样相结合的最先进的滤波器。在工业界,NVIDIA 的深度学习超级采样(DLSS 2.0)[18]和Intel 的Xe 超采样技术(XeSS)[74]采用低分辨率输入重构高分辨率的输出,虽然这些方法的细节没有公开,但目前被广泛用于实时光线追踪中。与神经网络结合的方式及特点如表6 所示。
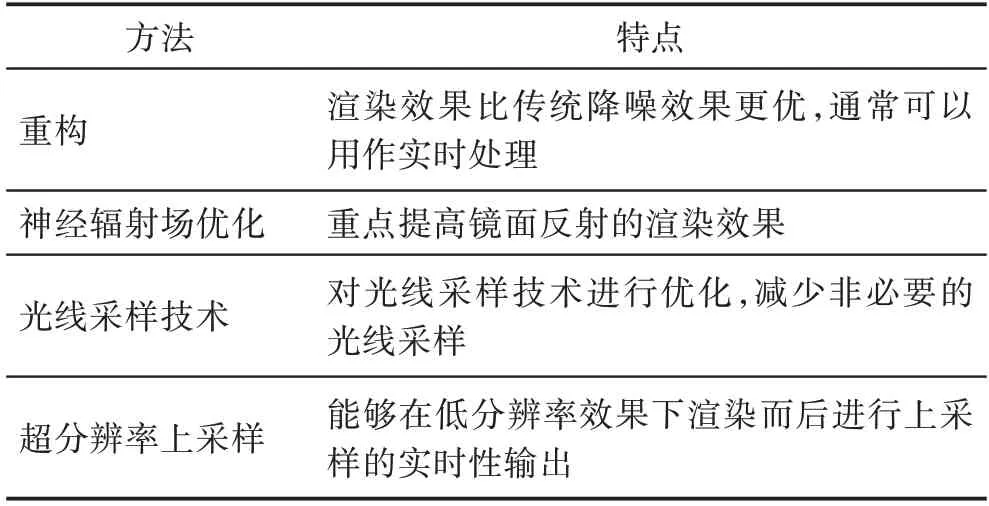
表6 与神经网络结合的技术Table 6 Techniques combined with artificial neural network
4 光线追踪硬件的优化
长期以来,实时光线追踪是研究者们孜孜以求的目标,但是巨大的计算强度限制了它在各类场景中的应用,研究者们对如何通过硬件的方式提升性能也进行了许多探索,主要包括基于GPU 进行光线追踪和采用定制化的设计来进行加速。
4.1 基于GPU 的光线追踪优化
由于早期的GPU 还不支持通用计算,光线追踪在GPU 上实现难度非常大。Carr 等[75]首次使用了GPU 硬件对光线追踪进行加速,但仅仅实现了图元求交部分。Purcell 等[76]提出了完整的光线追踪流程,划分了各个模块,从求交直至生成二次光线。由于GPU硬件架构限制严重,只支持不带有分支的kernel,导致功能模块并不能很好地加速,硬件限制了算法优化。此时以GPU 作为硬件基础的光线追踪实现依旧不及CPU 实现版本。Aila 等[26]研究并探讨了多种在GPU 上实现光线追踪的策略,并提出了一种利用常驻线程代替GPU 硬件调度任务的技术,测试结果显示,这种技术比最基本的GPU 光线追踪策略快2倍。但是,当时的GPU 对这种常驻线程技术并不敏感[77]。Hanika 等[78]、Heinly 等[79]、Keely[80]、Vaidyanathan 等[81]、Liktor 等[82]对光线追踪的精度要求进行了系统研究,提出了一种降低精度和计算复杂度且可以集成到GPU 中的解决方案。Lü等[83]提出了在GPU中增加动态光线调度(dynamic ray shuffling,DRS)的设计,该设计用来解决光线追踪中控制流分支的问题,主要记录不同光线的遍历状态,分为取数据、遍历BVH 和叶子节点处理三种。通过DRS 可以将处于相同状态的光线调度到同一线程束(warp)中。通过GPGPU-Sim 模拟器[84]测试性能,在仅增加0.11%芯片面积的情况下,光线追踪性能平均可以提升1.79倍。Liu 等[85]结合当前GPU 整合光线追踪硬件加速单元的实际,提出了光线相交预测器,预测执行省略了部分的冗余操作,可以使得光线直接与图元进行测试。该方法主要是设置了一个哈希函数并提供足够的空间信息来识别冗余的遍历。模拟结果表明在一个带有光线追踪加速单元的移动端GPU 上,给流多处理器(streaming multiprocessor)添加5.5 KB 的预测器,对环境光遮罩(ambient occlusion,AO)的性能可以提升26%。为解决光线追踪在GPU 大量光线遍历造成的不规则内存请求的问题,Ni等[86]提出了聚集内存和线程调度(agglomerative memory and thread scheduling)的调度机制,该机制将加速数据结构(kd-tree)划分为子树,完全加载到流多处理器的片上L1 cache 中,而后将线程重新分组到线程束上进行调度。研究成果可以集成到如今的高端GPU 上,只需要很小的开销,就可以将性能提升47.4%。不同GPU优化方式的比较如表7 所示。
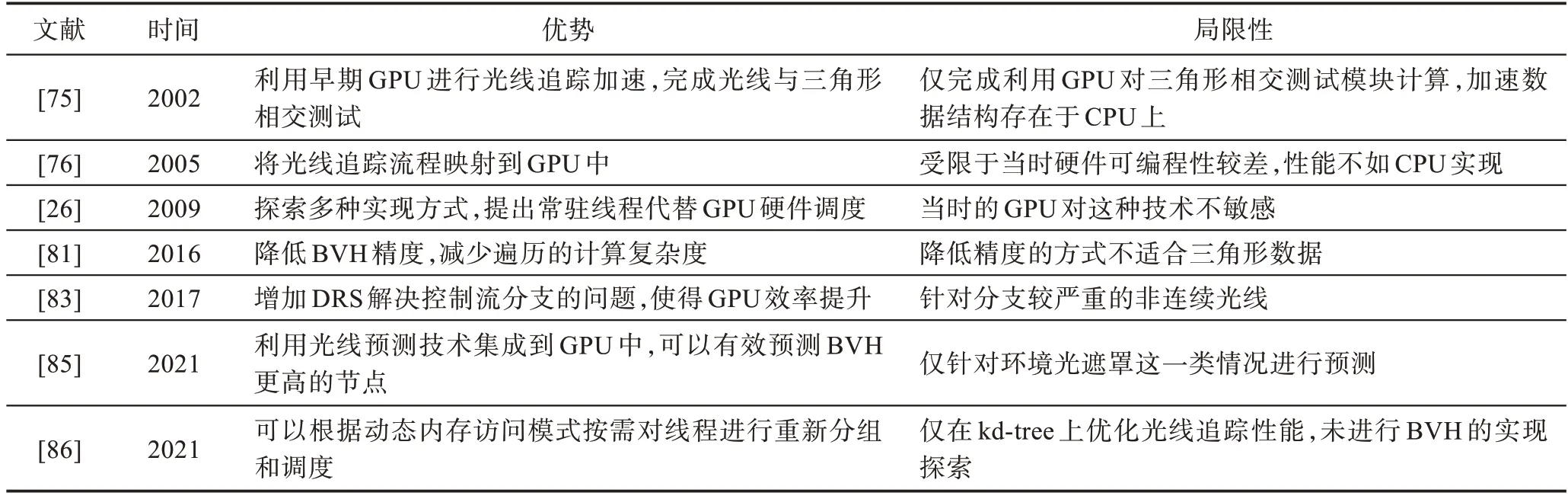
表7 GPU 优化方式比较Table 7 Comparison of GPU-based optimization approaches
4.2 面向光线追踪的硬件加速器设计
对于光线追踪硬件加速,除了基于GPU 进行优化实现的研究,通过专用硬件加速也是一种途径[87-88]。Fender 等[89]最早在FPGA(field programmable gate array)上实现了BVH 的遍历测试。早期物理渲染专用硬件设计主要关注的是加速单个光线追踪,比较有影响的是萨尔兰大学的光线处理单元(ray processing unit,RPU)[90]和SaarCOR[91-92]。SaarCOR 和RPU 都是通过FPGA 技术实现。SaarCOR 重点关注光线遍历和求交运算的硬件实现,而RPU 则重点研究光线追踪的可编程渲染过程的实现。在后续研究中,Woop等[93-94]又提出了基于ASIC(application specific integrated circuit)的可处理动态场景的DRPU(dynamic ray processing unit)设计实现。而后Nah 等也提出了专用的光线遍历和求交单元——T&I 引擎[95],并在此基础上设计了一个完整的光线追踪体系结构Ray-Core[96]。Lee 等[97-98]将并行T&I 引擎与三星可重构处理器相结合,设计实现了SGRT(Samsung reconfigurable GPU based on ray tracing),集成了光线生成与着色功能。Nah 等[99]采用混合架构的HART,采用专用光线追踪硬件完成BVH 的更新和光线遍历,CPU用于重构BVH。Kim 等[100-101]提出了一种可重构的流多处理器MRTP(mobile ray tracing processor)。Yan等[102]结合三种优化设计实现了一款高效的光线追踪硬件加速架构RT engine。
在并行光线追踪架构方面,Spjut 等[103]为了更好地应对在追踪二次光线时产生的光线分支问题,提出了基于多线程MIMD 架构的TRaX。Kopta 通过共享cache 和功能单元等硬件资源对TRaX 架构进行了优化[104]。在随后的工作中,Kopta 等又对TRaX 进行了重新设计并提出STRaTA[105-106],使其根据子树[39]来处理光线流,从而提升cache 命中率。Shkurko 等[107]提出双流(dual streaming)光线追踪硬件加速器的体系结构设计,将场景分为场景流和光线流,将内存访问组织成两个可以预测的数据流。这些流的可预测性允许完美预取,使得内存访问模式与DRAM 内存系统的行为非常匹配。Vasiou 等[108-109]提出了Mach-RT 的体系结构,通过一个大型片上缓冲区作为分布在多个芯片上的存储,最大限度地减少了对场景数据的访问,扩展了双流的概念,优化了主存访问,使同一内存系统可以同时服务于多个处理器芯片。与现有的学术和商业架构相比,提高了性能同时保持着合理的能耗。表8 为不同硬件架构的比较。每秒百万条光线(million rays per second,MRPS)是光线追踪性能测试时常用的计量单位。

表8 不同光线追踪架构比较Table 8 Comparison of ray tracing architectures
5 总结与展望
长期以来,基于光线追踪的物理渲染被视为提升视觉体验的最有效方法,但是由于过大的计算强度限制了其在实时应用领域的使用。近年来,随着算法研究和硬件技术的发展,已经处于传统光栅化渲染方式到消费者平台实时光线追踪的转折点。但是,基于实时光线追踪的研究还远未结束,目前该领域还有一些关键性的问题有待进一步研究。
在图像真实感方面,光线追踪的模型是基于理想模型做光线路径的模拟,由于真实场景中光线的折射会造成能量损失,距离完全真实地描绘3D 场景还具有一定差距。如果要更进一步地模拟光线的传递,还需要考虑辐射度量学的内容。除此之外,纹理空间技术(texture space techniques)、可变速率光线追踪(variable rate ray tracing)等新颖的提升图像真实感技术如何与光线追踪技术相结合可能是后续研究的重点方向。在算法和硬件优化方面,神经网络技术与实时光线追踪结合愈发紧密,在降噪处理、图像重构和超分辨率等方面发展迅速,下一步可能会引领人们进入神经网络渲染的新时代。从近年来的研究成果来看,硬件更倾向于“存储墙”的解决。利用定制的高效光线重排序硬件或者近存计算等会成为实时光线追踪进一步发展的突破口。此外,同样值得研究的是光线追踪硬件是否可以推广到其他不规则应用程序的架构中,可以充分发挥现代光线追踪GPU 架构的优势。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
汽车工程(2021年12期)2021-03-08
科普童话·学霸日记(2020年1期)2020-05-08
幼儿画刊(2019年6期)2019-11-04
时代人物(2019年27期)2019-10-23
中外文摘(2019年8期)2019-04-30
小天使·一年级语数英综合(2019年2期)2019-01-10
计算机测量与控制(2017年6期)2017-07-01
