
融合时间上下文与特征级信息的推荐算法
2023-02-18 07:17沈义峰金辰曦张家想卢先领
计算机与生活 2023年2期
沈义峰,金辰曦,王 瑶,张家想,卢先领+
1.江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡214122
2.江南大学 物联网工程学院,江苏 无锡214122
当用户在面对海量的数据时,推荐系统既可以作为一种有效的方法过滤冗余的信息,也可以根据用户的标签信息和用户-物品历史交互信息得到用户的兴趣模型,从而主动地给用户推荐其感兴趣的物品。在现有推荐系统中,利用用户-物品的交互信息为基础的建模主要方式有两种。
(1)传统推荐方法:基于内容的推荐方法[1]和协同过滤的推荐方法[2]。这些方法都侧重于挖掘用户与物品的静态关联,而忽略了用户物品交互中用户的潜在偏好,未考虑到用户潜在兴趣对未来购买行为的影响。例如,当用户购买历史上有某品牌手机时,静态推荐系统只能重复推荐该品牌手机或根据协同过滤方法推荐其他用户所购买的物品,而未挖掘用户本身的潜在偏好,最终导致不可靠的推荐。
(2)序列推荐方法[3-4]:用户与物品的交互形成一系列行为序列。在早期对序列模式的处理上,经常利用基于马尔科夫链[5]的方法提取物品间的过渡矩阵,但这些方法很难有效捕捉不同信息之间的关系。随着深度学习技术的快速发展,基于循环神经网络(recurrent neural network,RNN)[6-7]的方法在序列建模上获得了巨大的成功,但基于RNN 的方法很难建模物品的长期依赖关系且耗时巨大。基于自注意力机制[8]的方法在序列建模任务上取得了很好的效果。然而大多数基于自注意力机制的方法只考虑到物品层级的关系模式,而忽略了大量的辅助信息,例如物品之间的时间间隔、物品的属性信息等。有效地融合辅助信息可以从不同的层级挖掘序列的关系模式。
因此,本文提出了一种融合时间信息及属性特征级信息的联合推荐模型。首先利用感知时间的自注意力模型建模物品与时间上下文的关系。将物品和每一个属性的嵌入表示拼接起来输入到注意力单元中,以获得每个属性的特征权重,经过属性特征加权求和可以生成新的物品嵌入表示信息。之后,将新的物品嵌入表示信息输入到自注意力区块中,学习了序列中物品-属性特征之间隐式的关系。最终将感知时间间隔的输出表示和基于属性特征级的输出表示连接起来进入全连接层做预测。
本文的主要贡献有:(1)提出了一种新的混合推荐模型;(2)利用物品和属性的联合嵌入表示共同提取物品-属性之间的关联模式;(3)在两个真实数据集中进行了实验,结果表明本文所提出的模型优于其他基准模型。
1 相关工作
1.1 序列推荐
序列推荐系统通过建模物品-物品之间的过渡矩阵来捕捉序列物品之间的关系模式。最先用于序列推荐的是基于马尔科夫链的方法。Rendle 等人[9]在2010年提出了个性化马尔科夫链分解模型(factorizing personalized Markov chains for next-basket recommendation,FPMC),通过个性化过渡矩阵预测下一个物品。因过渡矩阵只考虑了当前物品与前一个物品之间的关系,所以FPMC 模型只能通过最近的一个交互物品捕获局部的依赖关系,无法在复杂的场景下利用其他特征信息挖掘更多的隐式关系。
随着深度学习技术的快速发展,基于RNN 的推荐算法迅速涌现出来。Hidasi等人[10]提出了GRU4Rec(gate recurrent unit for recommendation)方法,首次将GRU 引入到会话推荐中用来建模序列物品之间的关系。Chen 等人[11]针对基于RNN 模型中物品之间的关联度不强的问题,提出了基于用户记忆网络的序列模型。Ying 等人[12]通过利用两层分层注意力网络模型解决了用户长期偏好随时间推移而不断演变的问题。Liu 等人[13]提出了一种新的短时注意优先模型,该模型从会话上下文的长时记忆中捕捉用户的一般兴趣,同时考虑用户最近一次点击作为当前兴趣,最后将一般兴趣和当前兴趣结合向用户做推荐。Ma 等人[14]提出了一个层级门网络和贝叶斯个性化排名相结合的方法联合捕捉用户的长期和短期兴趣。在上述基于RNN 的序列推荐算法中,虽然可以建模更复杂的序列关系,但它们都需要大量高密度的关联数据且往往不能并行化计算。
1.2 自注意力机制
近几年来,一种基于自注意力的序列-序列方法Transformer 在机器翻译任务中取得了巨大的成功。Transformer 模型极大地依赖于“自注意力”模块以便捕捉语句中的复杂结构。受Transformer 的启发,Kang 等人[15]提出了基于自注意力的序列模型,通过两层Transformer 去捕捉序列物品之间的关系,既能够捕捉较长的交互信息也能够基于相对较少的用户行为做出预测。Sun 等人[16]提出了双向的Transformer 模型,从用户-物品序列左右两个方向提取交互信息,融合左右两侧的信息来对下一个物品做预测。Li 等人[17]基于自注意力模型提出了感知时间间隔的自注意力的序列模型,探索不同的时间间隔对下一个物品预测的影响。Zhang 等人[18]提出了特征级自注意力网络的序列推荐方法,分别建模属性之间的特征级关系和物品之间的关系来更深层次地挖掘用户的潜在偏好来预测下一件可能交互的物品。Wu 等人[19]利用自注意力机制建模时间动态的影响,之后使用BiRNN 建模上下文信息加权不同的时间动态。
在现有的基于自注意力机制的方法中,大多数都未融入有效的边信息来辅助建模。因此,本文有效地融合序列中的上下文信息以及更细粒度的物品信息以挖掘序列中各类隐式的序列模式,从而增强推荐性能。
2 提出的方法
2.1 问题定义
为了便于后续的描述,本文使用U和I分别表示用户集合和物品集合,对于每一个用户u∈U,为按时间次序交互的物品序列,按交互顺序所对应的时间序列为。此外,每一个物品i都有一些属性,例如种类、商标以及描述信息等。本文目标是分别建模物品与时间信息之间的相互关系以及物品属性与物品自身的关系来预测下一个时间点用户可能感兴趣的物品。
2.2 模型描述
在现有的序列推荐算法中,大多数只关注序列物品和用户现在行为之间的建模,但在建模过去的历史行为对未来预测的影响时,往往忽略了时间上下文信息和更细粒度的信息。因此,本文提出了一种新的融合时间信息和物品特征的推荐算法(recommendation algorithm integrating time context and featurelevel information,ITFR)。ITFR 模型主要包括三部分:第一部分利用感知时间间隔的自注意力层捕捉时间间隔与物品之间的关系模式;第二部分利用基于物品属性的自注意力层,挖掘物品与属性的隐式特征的关系;第三部分是全连接层和预测层,将上述两个自注意力层的输出表示进行拼接进入全连接层,之后与物品集中的物品嵌入表示做点积来预测下一个物品的输出。ITFR 模型结构如图1 所示。
2.3 感知时间间隔的自注意力模型
从图1 中可以看出,基于时间信息的自注意力模型[17]共分为两层:第一层是物品、物品位置以及时间间隔的嵌入表示;第二层是感知时间间隔的自注意力区块层。物品的嵌入表示矩阵为M∈R|I|×d,将训练序列转为一个固定长度的序列s=(s1,s2,…,sn),n表示模型能够处理的最大长度。如果序列的长度大于n,则仅考虑最近的n个交互的物品。如果序列的长度小于n,则在序列左侧补0 向量使序列的长度为n。对于时间序列也做了相似的操作,将时间序列转成一个固定长度的序列t=(t1,t2,…,tn)。其中物品i和物品j之间的时间间隔为|ti-tj|,用户交互的固定长度序列中两个物品之间的时间间隔矩阵Ru,物品之间的最小时间间隔表示为=min(Ru)。为了避免过大的时间间隔,采用比例化时间间隔的方法。
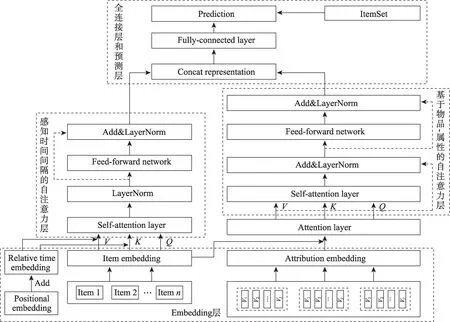
图1 ITFR 模型框架图Fig.1 Architecture diagram of ITFR model

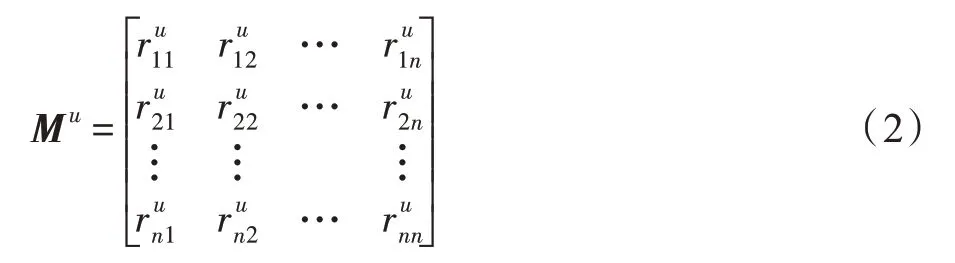
归一化时间间隔后的用户的关系矩阵Mu∈Nn×n为:
2.3.1 嵌入表示层
将用户-物品交互序列中物品的嵌入表示为EI∈Rn×d:

在基于自注意力的序列推荐(self-attentive sequential recommendation,SASRec)[15]方法中,融入位置的嵌入表示会提升自注意力模块的性能,因此在本模型中加入两个可学习的位置嵌入矩阵和分别作为自注意力机制的Key 和Value。

2.3.2 感知时间间隔的自注意力区块层
自注意力层的输入由序列物品的嵌入表示、相对时间间隔的嵌入表示和物品位置的嵌入表示三部分组成。将自注意力层的输出序列嵌入表示为:
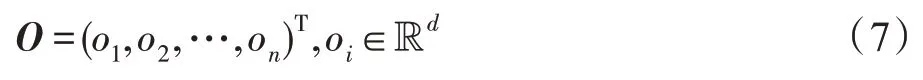
则每个输出的嵌入表示为:
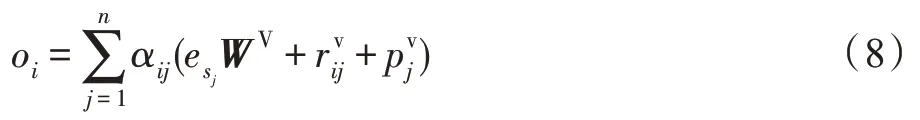
WV∈Rd×d是Value 的可学习的权重参数。权重系数αij通过Softmax 函数计算。

cij是当前物品与序列物品的关系函数。
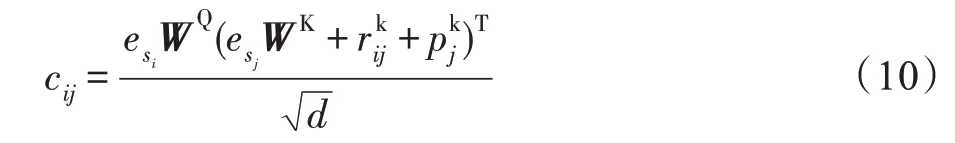
WQ∈Rd×d和WK∈Rd×d是Query 和Key 的可学习的权重矩阵。d表示每个物品的维度。为了增强模型的性能,在自注意力层后用了残差连接、层归一化函数和以ReLU 为激活函数的两层全连接层,最终得到物品信息和位置信息以及时间间隔信息的联合输出表示:
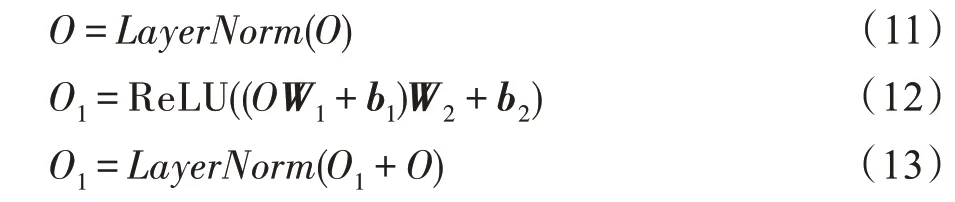
W1,W2∈Rd×d,b1,b2是d维向量,根据文献[17],在堆叠了两个自注意力模块后,得到了物品嵌入表示、位置信息以及时间间隔的联合表示O2。
2.4 基于物品-属性的自注意力模型
在实际的场景中,用户对物品的兴趣往往是基于其属性信息而言的。例如,用户往往会对某一类别的品牌感兴趣或其商标感兴趣。因此融合物品的嵌入表示和每一个属性的嵌入表示进行注意力加权,即可知道物品的哪一个属性决定了用户的选择。
2.4.1 嵌入表示层
对于物品i,将它的属性向量表示为Ai={vec1,},vecj表示第j个属性的向量表示,J表示物品属性的个数。由于物品的属性类型总是复杂多样的,包括类别型特征、数值型特征以及文本特征型。当属性是类别型特征时,其向量表示是一个one-hot 向量,需要将其转变成一个低维的稠密型向量。当属性是数值型时,其向量表示是一个标量。具体的表示如下:

其中,Vj是一个embedding 矩阵,vecj是属性的向量表示。
(1)将同一用户所有交互物品的文本属性信息拼接成长文本。利用预训练的LDA 主题模型得到长文本的主题分布,并获取每个主题下前5 个主题词。
(2)利用Word2vec 模型[22]训练新的长文本,以便获得长文本中每个词的词向量。
(3)对主题词做归一化处理,计算每个词占主题的权重。根据权重大小进行排序,权重越大的词越靠前。
(4)将每个主题词的权重和其词向量做内积并求和,得到该主题的词向量。
(5)计算单个物品描述信息的文本向量,即利用单个文本中每个词向量求和除以单个文本总的词数。
(6)利用欧氏距离判断单个文本向量和每个主题向量的相似度并根据距离从小到大排序。
(7)根据相似度排序提取前5 个主题词向量,利用平均池化的方法将5个词向量聚合为1个向量表示。
2.4.2 物品-属性的自注意力层

自注意力区块的输入为:

在基于物品-属性的自注意力模型中,自注意力区块包含了自注意力层、残差连接归一化层以及前馈网络层,和感知时间的序列模型基本是相同的,仅区块的输入和残差连接部分不一样。根据文献[15],由于物品和属性的维度设置低,在低维度下将维度分解到多个子空间的效果明显比在单个子空间的效果差。因此本文使用了单头的注意力。则经过自注意力层后的输出为:
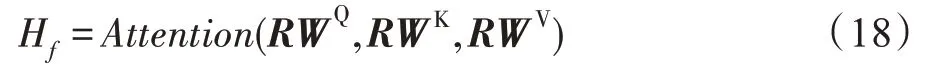
WQ,WK,WV∈R2d×2d是可学习的参数矩阵。
最终,自注意力区块的输出为:
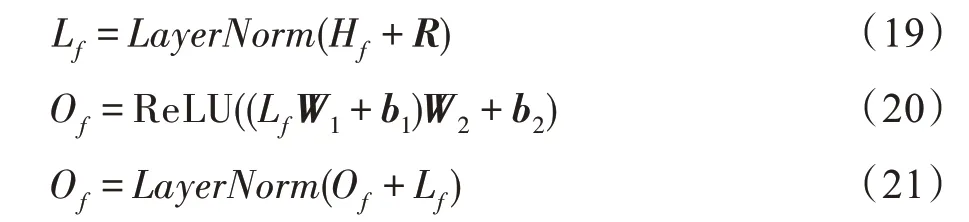
其中,W1,W2,b1,b2是模型的参数。为了捕捉到更复杂的特征关联模式,通常需要经过多个自注意力区块。因此在获得第一个自注意力区块表示后会直接进入到下一个自注意力块中,经过多个自注意力区块后的输出表示为Os。
2.5 全连接层和预测层
通过拼接感知时间间隔自注意力区块的输出O2和基于物品-属性的自注意力区块的输出Os,获得时间间隔信息的物品级关系和物品属性特征级关系的联合表示。之后将联合表示输入到全连接层。

W2s∈R3d×d,b2s∈Rd。利用联合表示和物品的嵌入表示做点积得到用户对当前物品的偏好得分。

是O2s中第t行表示,M∈RI×d是物品的嵌入表示矩阵,yt,i表示根据前t个物品的相关信息(时间间隔信息、属性特征信息)计算用户对物品i的偏好得分。
2.6 网络模型训练
模型的损失函数:
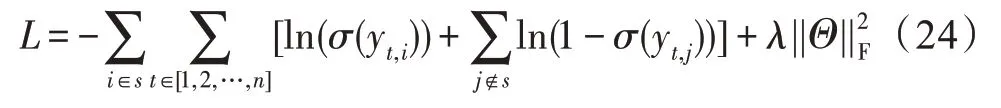
λ是正则化参数,是一组嵌入矩阵集。在每一个正样本i中,都会随机负采样一个负样本j来与之配对。
3 实验及分析
为了验证本文所提出的ITFR 模型的推荐性能,本文采用了Pytorch 深度学习框架,实验采用的操作系统是Windows 10,显卡RTX2060,CPU 型号是i7-9750H,Python 版本为3.6。在Pycharm2019 集成开发工具和Pytorch 深度学习框架下进行实验和分析。
3.1 数据集
本文实验采用了Amazon 公开数据集下的子数据集Beauty 和MovieLens-1M 数据集进行实验。两个数据集下都包含了用户-物品交互的时间戳信息,并且利用物品的细分类和品牌以及文本描述信息作为属性信息。在对数据预处理的过程中,将用户的交互记录按交互时间升序排列,利用每个用户的时间戳减去最小的时间戳,得到用户物品的相对时间间隔信息。之后,对相对时间间隔归一化处理。此外,为了避免冷启动对推荐性能的影响,过滤了交互次数少于5 次的用户和物品。表1 展示了两个数据集的详细信息。
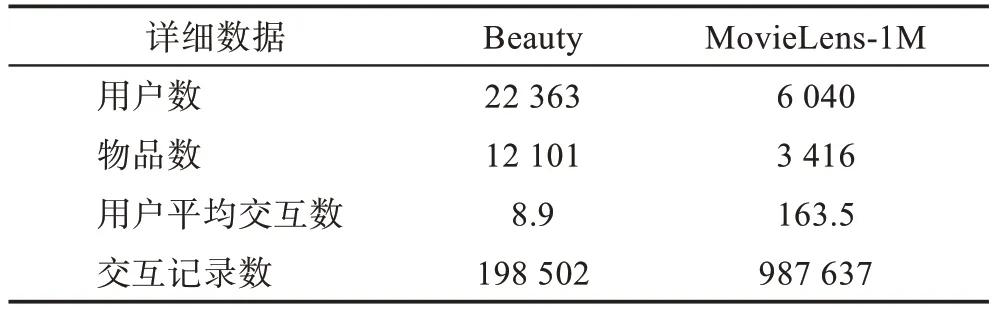
表1 两个数据集的详细数据Table 1 Statistics for two datasets
3.2 对比模型
在对比模型上,实验分别选取了基于马尔科夫链的推荐模型FPMC、基于GRU4Rec 的推荐模型GRU4Rec+、基于卷积神经网络的推荐模型(convolutional sequence embedding recommendation model,Caser)以及基于自注意力机制的推荐模型SASRec。将本文所提的ITFR 模型与对比模型进行比较:
(1)FPMC,个性化马尔科夫链分解模型,引入了基于马尔科夫链的个性化转移矩阵,用以捕捉用户的一般偏好信息和行为的动态迁移。实验中模型的参数为:用户和物品的表示向量维度为128,学习率是0.001。
(2)GRU4Rec+,基于会话的RNN 推荐模型,在基于会话的推荐中引入了GRU 模型,在此模型的基础上加入了属性信息提升推荐性能。实验中模型的参数为:迭代次数为10,物品和属性的表示向量维度是100,学习率是0.001。
(3)Caser,卷积序列嵌入推荐模型,其在序列推荐中使用基于卷积神经网络的卷积滤波器构建了高阶的马尔科夫链模型。实验中模型的参数为:迭代次数为30,用户与物品的表示向量维度为50,水平过滤器的数量是8,垂直过滤器的数量是4。
(4)SASRec,基于自注意力的序列推荐模型,利用了多头注意力机制推荐下一个物品。实验中的模型参数为:用户与物品的表示向量维度为50,自注意力区块的数量为2,自注意力区块中头的个数是1,迭代次数为30,学习率为0.001。
3.3 评价指标与实验设置
实验中,在对数据集经过处理之后,将数据集划分为训练集、验证集和测试集。即最后一个物品做测试,倒数第二个物品作为验证集,其余的物品作为训练集。采用命中率(hit ratio,HR)和归一化折损累计增益(normalized discounted cumulative gain,NDCG)作为评价指标。命中率是衡量推荐的准确程度,归一化折损累计增益则考虑了更多的推荐的物品是否放在用户更容易关注到的位置,即强调了推荐列表的顺序性。
在实验中,对于两组数据集,设置物品和属性的嵌入表示向量维度均为50,batch size 为128,正则化系数λ为5×10-5。模型采用了Adam 优化器优化,学习率为0.001。在Beauty 数据集中,最大交互序列长度为50;在MovieLens-1M 数据集中,最大交互序列的长度为200。基于物品-属性的自注意力区块的数量设置为2。
3.4 实验结果与分析
本文所提出的ITFR 模型和其他基准模型的对比如表2 所示。
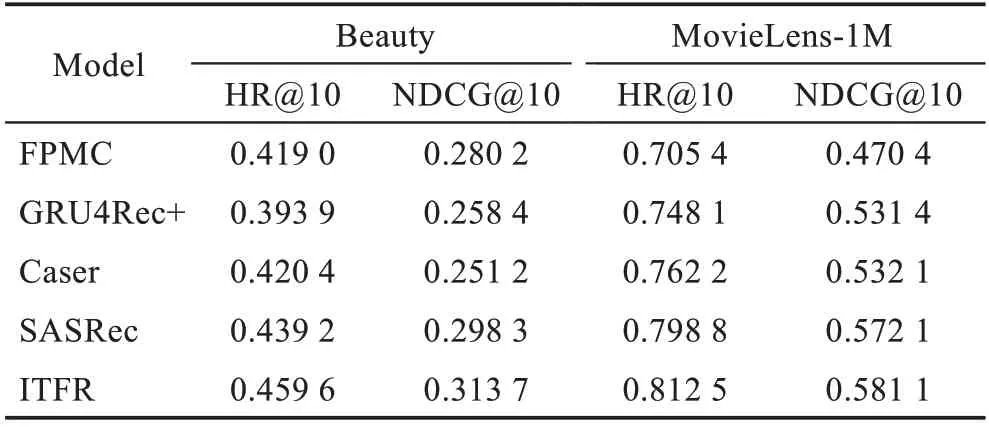
表2 ITFR 与其他基准模型的性能对比Table 2 Performance comparison of ITFR and other benchmark models
通过分析,可得出以下结论:
(1)在Beauty 数据集中,基于马尔科夫链的模型(FPMC)比基于神经网络的模型(Caser、GRU4Rec+)在NDCG@10性能指标上表现更好。而在MovieLens-1M 数据集中,FPMC 比Caser、GRU4Rec+在NDCG@10 的性能要差。由此可见,在稀疏型数据集上,时间信息对于序列物品的建模具有一定的作用。
(2)基于自注意力的模型(SASRec)在两个性能指标上比基于神经网络的模型(GRU4Rec+、Caser)表现更好,表明基于自注意力机制的方法自适应地为当前物品分配不同的权重比基于神经网络的方法能够更好地捕捉物品之间的依赖关系。
(3)本文的模型结合序列的时间信息以及物品-特征的联合信息,并利用了自注意力机制分别融合感知时间间隔的物品表示和基于物品-特征的表示。在两个不同的数据集中的两个性能指标上均好于其他的4 个基线模型。
本文提出的ITFR 算法主要优势在于:算法利用两个分离的自注意力区块分别去捕捉序列中的物品级间的关系模式及属性特征级间的关系模式。在感知时间间隔的自注意力区块中,将物品信息、绝对位置信息、时间间隔信息作为自注意力层的输入,捕捉序列物品和时间间隔的关系。与SASRec 模型[15]相比,其将时间间隔信息充分地利用起来,把时间信息作为额外辅助信息进一步挖掘物品与时间信息之间的隐式关联,进而从时间的角度去预测用户在未来点的兴趣。在物品-属性特征级的自注意力区块中,在建模物品之间的关系模式上考虑更细粒度的属性信息,将属性信息也作为辅助信息挖掘物品-属性之间的隐式关联。最后ITFR 算法结合了时间上下文信息和属性信息,将融入时间信息的物品级表示和物品属性特征级表示拼接起来,向用户做出更为合理精准的推荐。
3.4.1 超参数的影响
(1)用户和物品维度d的影响
在ITFR 模型中,超参数d是很重要的一个参数。d越大,则其向量表示也越复杂。图2、图3 展示了两个数据集中不同维度下HR@10 和NDCG@10的性能。从图中可以看出本文所提出的模型在两个性能指标上超过了其他的基准模型。其中,在Beauty数据集中,当d=50 时,本文提出的模型在NDCG@10 性能指标上较基于马尔科夫链的方法FPMC 提升了11.9%,较基于神经网络的方法GRU4Rec+提升了21.4%,较基于自注意力机制的方法SASRec 提升了5.1%。在MovieLens-1M 数据集中,当d=50 时,ITFR模型取得最好的性能。ITFR 模型在NDCG@10 性能指标上较基于马尔科夫链的方法FPMC 提升了23.5%,较基于神经网络的方法GRU4Rec+提升了9.3%,较基于自注意力机制的方法SASRec 提升了1.5%。这表明本文提出的ITFR 算法的优越性。
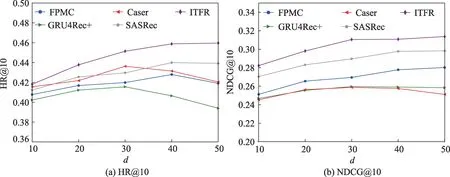
图2 在Beauty 数据集中参数d 对不同模型的影响Fig.2 Influence of d on different models in Beauty dataset
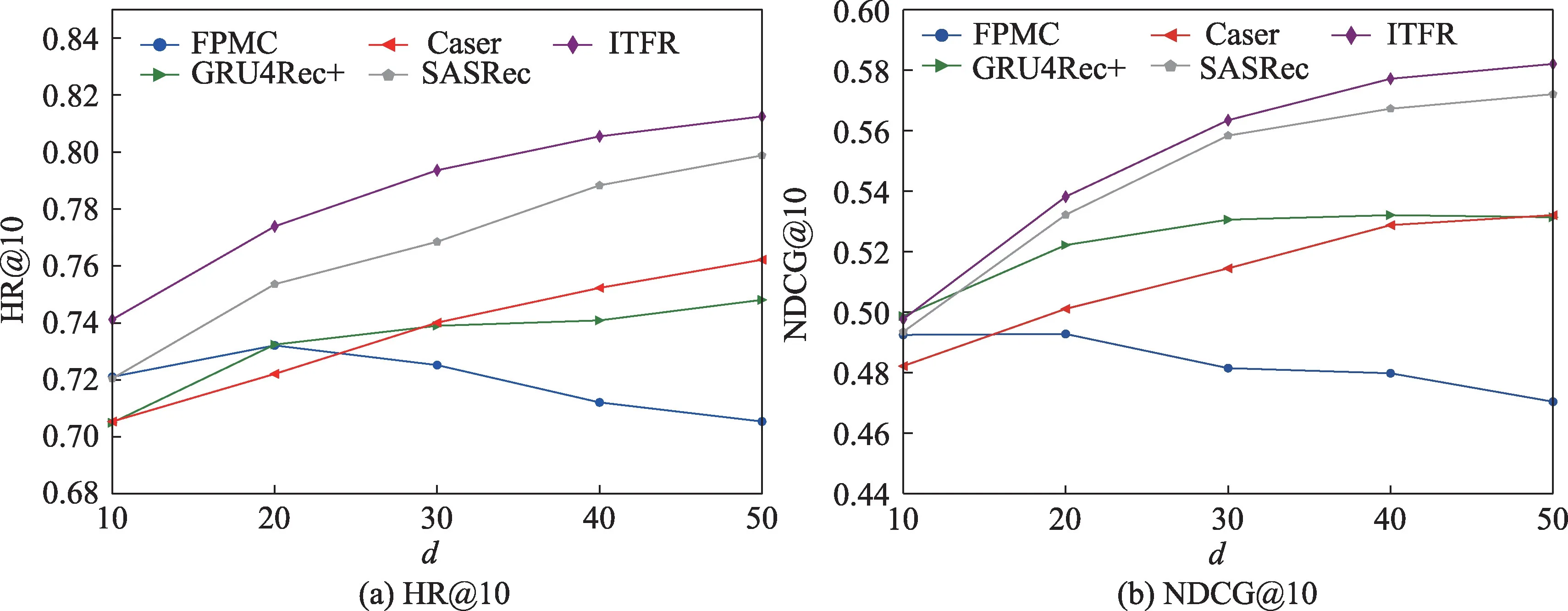
图3 在MovieLens-1M 数据集中参数d 对不同模型的影响Fig.3 Influence of d on different models in MovieLens-1M dataset
(2)序列长度N的影响
在两个数据集中序列长度N的不同也会对模型性能产生不同的影响。表3 展示了当N取不同长度时,模型在两个数据集中的性能指标。从表中可以看出,在Beauty 数据集中,当N=50 时,模型在两个性能指标上的效果最好。在MovieLens-1M 数据集中,当N=200 时,取得了最好的性能效果。通过在两种不同类型数据集中的对比,可知在稀疏数据集中,由于用户平均序列长度短,其推荐性能更容易受到最近交互物品的影响。而在稠密型数据集中,用户的平均序列长且拥有丰富的物品属性信息和物品间的时间间隔信息,使模型能够更好地捕捉物品时间和物品属性特征级之间的关系模式。

表3 在两个数据集中不同序列长度的性能对比Table 3 Performance comparison of different sequence lengths in two datasets
3.4.2 对比实验
为验证本文提出的时间上下文信息和物品属性特征级信息的融合对推荐性能的影响,通过以下实验进行对比。对比感知时间间隔的推荐算法(time interval aware self-attention for sequential recommendation,TiSASRec)[17]与基于物品属性的特征级推荐算法(item-attribute feature-level recommendation,IAFR),为了公平起见,三种算法在同一个数据集中使用相同的超参数,在Beauty数据集中设置最大序列长度为50,最大的时间间隔为512,正则化系数λ为0.000 05。在MovieLens-1M 数据集中设置最大序列长度为200,最大时间间隔为2 048,正则化系数λ为0.000 05。三种算法在两个数据集的两种性能指标对比如图4、图5 所示。从图中可以得出:(1)对比TiSASRec,在Beauty 数据集中,ITFR 算法在HR@10 和NDCG@10两个指标上分别提升了7.4%和11.2%。在MovieLens-1M 数据集中,ITFR 算法在HR@10 和NDCG@10 指标上分别提升了2.3%和2.0%。由此可以得出本文的ITFR 算法可以更深层次地挖掘物品-属性的隐式信息,从而提升推荐性能。(2)对比IAFR,在Beauty 数据集中,ITFR 算法在HR@10 和NDCG@10 指标上分别提升了3.7%和2.8%。在MovieLens-1M 数据集中,ITFR 算法在HR@10 和NDCG@10 两个指标上分别提升了0.97%和1.50%。由此可以得出本文所提出的ITFR 算法利用时间间隔作为额外辅助信息挖掘时间间隔和物品之间的关系模式的有效性。(3)从三种算法的性能对比数据上看,基于物品-属性细粒度的特征级信息对推荐性能的影响要高于时间信息对推荐性能的影响。可能的原因是,对于用户而言,属性信息相对于时间间隔信息所受到的关注更大,其对用户行为的影响更高。
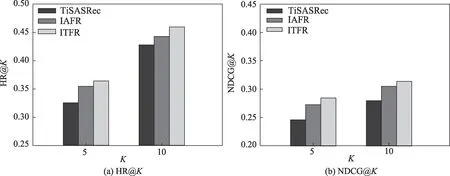
图4 Beauty 数据集中三种模型的性能Fig.4 Performance of three models in Beauty dataset
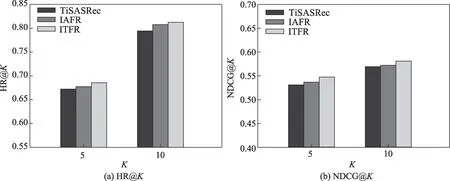
图5 MovieLens-1M 数据集中三种模型的性能Fig.5 Performance of three models in MovieLens-1M dataset
4 结束语
本文提出了融合时间上下文和特征级信息的推荐算法(ITFR),该算法首先利用两个自注意力区块分别捕捉了序列时间上下文信息与物品之间的关系以及物品-属性细粒度特征之间的关系。然后将两个自注意力区块的输出嵌入表示拼接起来输出到全连接层中做下一个物品的预测。最后,在两个真实数据集上的实验表明,本文算法在推荐性能上优于其他基线模型。
尽管ITFR 模型在两个数据集中均有提升,但是在稠密数据集上的推荐性能的提升并不是很大。因此下一步的工作是如何有效地利用各类异构信息与用户信息之间的联系来进一步挖掘它们之间的隐式特征,以构建更为精准的推荐模型。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·初中天地(2021年11期)2021-02-16
数学小灵通(1-2年级)(2020年11期)2020-12-28
少年漫画(艺术创想)(2019年2期)2019-06-06
小学生学习指导(低年级)(2019年3期)2019-04-22
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
小天使·一年级语数英综合(2015年8期)2015-07-06
读写算·小学低年级(2014年4期)2014-07-24
