
利用姿态传感器多点位控制机器人交互方法
2023-02-27 12:40刘莹,邵彧
机械设计与制造 2023年2期
刘 莹,邵 彧
(郑州西亚斯学院电子信息工程学院,河南 新郑 451150)
1 引言
随着空间技术的迅猛发展和广泛应用,传统的远程机器人控制方式也越来越复杂,同时临场感也并不理想。所以,人机交互技术受到各个研究领域以及专家的广泛关注[1]。随着人机交互技术的日益完善,各种问题开始出现,例如冗余代码等[2]。为了更好解决上述问题,相关专家给出了一些较好的研究成果,例如文献[3]首先设计了一个四轮全向移动式机器人;然后,通过对车体位置偏差构建Lyapunov函数,获得符合汽车车体线性飞行速度的反控控制规律,利用牵引轮与方向速度约束,设计了逆运动学模型,在跟踪过程中获得最佳的轨迹持续时间。文献[4]研究出一种基于无线网络的采摘机器人自动化控制系统,在硬件部分选择了Exyoos441 微处理器,在运动控制模块采用的是采用DS3710高性能驱动控制器。在软件部分设计了运动传感驱动程序,完成了对采摘机器人的远程控制。文献[5]提出了一种通用势能函数,可用于为各种机器人任务和HRI 任务推导出稳定统一的控制器。通过使用所提出的方法,可以通过简单地调整某些任务参数在用户级别指定各种任务。还定义了交互权重以根据不同的HRI 应用指定机器人的交互行为。为了进一步提高人体姿态识别结果准确率、缩短操作时间,这里提出了一种利用姿态传感器多点位控制机器人交互方法。
2 人体姿态识别方法
人体能够划分为10个部分,分别为左上肢上部分、左上肢下部分、右上肢上部分、右上肢下部分、头部、左下肢上部分,左下肢下部分、右下肢上部分,右下肢下部分。各个部分之间的分割图,如图1所示。
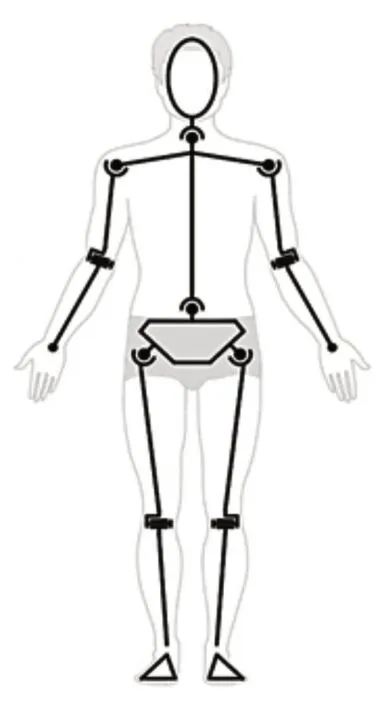
图1 人体部件分割图Fig.1 Human Body Part Segmentation Diagram
为了精准识别人体各部位的动作,需要利用检测器确定对应坐标,构建检测器的过程如下:(1)将训练图像中的身体躯干调整为主轴垂直向,同时将图像统一为相同规格,经过规范化处理的图片即为正例样本。剪力训练图像中的身体躯干部位,并且将其旋转成垂直轴。(2)采集非人体的躯干图像作为负例样本。(3)分别求解各个训练样本图像的HOG 特征,获取向量。(4)用AdaBoost算法来训练获得的向量,得到了一种类似于式(1)的强分类器。
式中:H(X)—强分类器;T—计算耗时;αi—滤波带宽;hi—滤波电容;X—向量。
当完成躯干检测器的构建后,具体的使用过程如下所示:
(1)随机选取躯干检测区域图像中的像素点。(2)将步骤(1)中选取的像素点作为中心,同时以事先设定好的代表躯干矩形边框的边长作为长和宽,设定θi代表长边的倾角,即可获取一个矩形图像块。(3)在此基础上,对矩形图像块进行HOG特征提取,并得到图像块的向量X,再代入到检测其中计算,即可获取以下形式的计算式:
其中,P(X)的取值越大,则说明该图像属于躯干图像的概率就越大。
(4)重复上两个步骤,根据躯干运动步长增加边长倾角计算P(X)。
(5)根据上一步骤结果,选取具有最大P(X)值的M图像块作为身体躯干候选点。
为了更好完成人体姿态识别,需要通过定义的评价指标对全部候选区域进行评价。
(1)部件符合度
进行候选区域评价的一项重要指标为部件符合度,当系统通过部件检测器进行候选区域检测时,需要优先计算不同部件的评价取值。同时借助Sigmoid函数将对应的评价值转换为0到1之间的数据来描述符合度[6],具体的计算式为:
式中:e—平滑系数;fdetec(X)—符合度。其中,fdetec(X)的取值越大,则说明候选区域符合条件越理想。
(2)前景覆盖率
前景覆盖率即图像前景像素数量比上图像前景像素数量与图像背景像素数量的和,其计算过程为:
①将目标图像分割为前景和背景两个部分。
②设NF为图像前景像素数量,NB为图像背景像素数量。
③计算前景中的像素数量占总像素的比例:
(3)前景覆盖熵
在进行人体躯干部位检测过程中,部分候选区域会大面积遮盖住人体的头部或者腿部,会造成这两部分的像素被重复统计,从而出现了结果偏差。
因此选择通过计算前景覆盖熵来衡量像素混杂度[7],则前景覆盖熵的计算过程如下:①将GrabCut之后获取的前景图像作为输入,通过Graph-baseg分割算法对目标图像进行分割[8],获取经过分割后的图像像素数量。②统计人体驱赶部位对应区域的图像前景像素数量。③计算各类像素占前景像素的比例。④计算候选区域内的前景覆盖熵。
(4)关联性评价
从距离、角度出发,评价人体姿态模型的各节点间的关联性
结合上述四项评价指标对各个候选区域进行综合评价,获取最优候选区域,即可完成人体姿态识别。
3 基于姿态传感器的机器人交互多点位操作方法设计
机器人交互多点位操作系统的整体框架,如图2所示。系统由五个不同的模块组成。另外,系统的实现还需要借助双虚拟机械臂显示模型,具体结构,如图3所示。
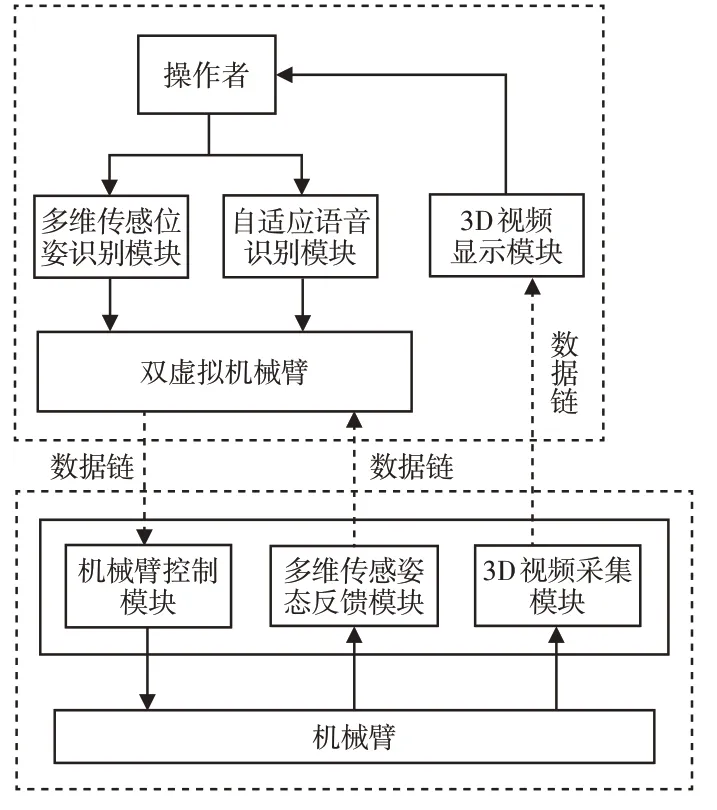
图2 机器人交互多点位操作系统结构图Fig.2 Structure Diagram of Robot Interactive Multi-Point Operating System
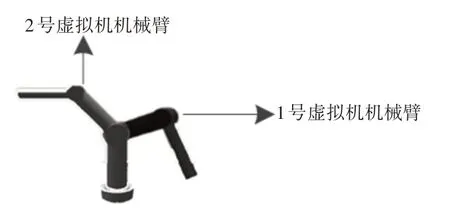
图3 双虚拟机械臂显示模型Fig.3 Dual Virtual Robotic Arm Display Model
(1)多维传感姿态识别模型
①利用两种传感器:姿态传感器、加速度传感器,采集人体的手臂信息[9],同时实时掌握手臂的角速度和加速度信息。②对步骤(1)中获取的信息进行求解,获取姿态角信息。③结合相关理论对全部信息进行融合,进而研究各个坐标的变化规律,最终实现人体姿态识别。
(2)语音识别模块
当系统自动判定1号虚拟机械臂在工作中所做出的动作是否为正确的动作时,通过系统内的“控制指令”把已经保存完成的“动作指令”全部下载至远程的机械臂中。如果一个人的姿态发生改变,系统就会根据姿态识别模块自动地对人体的姿态信息进行识别。同时把最终得到的姿态信息传输到1号虚拟机械臂中。如果系统内的“控制指令”依然由于人体运动姿态的识别模块来自主地进行传输,就可能造成系统将指令识别为错误,进而导致系统作出错误操作。为了有效地避免上述问题的产生,系统特别设计一个语音识别模块[10],系统能够利用各种语言向各个机器人发送信号和指令。其中,语音识别模块的作用是连接各个模块,同时还负责操作人员和远程机器人的姿态演示,具体的组成结构,如图4所示。
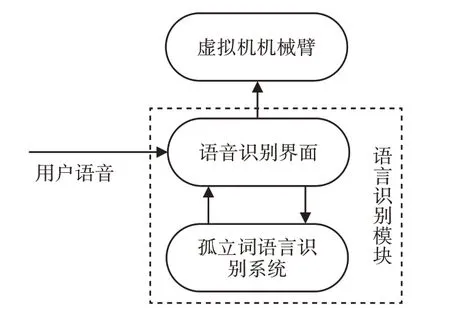
图4 语音识别模块组成结构Fig.4 Structure of Speech Recognition Module
为了更好地完成和1号虚拟机机械臂两者的交互,在系统中的语音识别模块主要利用MFC程度进行设计,这样更加方便调用系统中的孤立语言识别系统,同时将识别结果作为指令传输至机器人交互多点位操作系统的API接口进行语音识别和结果通信。
(3)虚拟机械臂显示模块:为了进一步提升远程操作的准确性和安全性,需要使系统的传输时延最小,同时还能够在任意一个角度全面反映远程机器人的运动情况。以下主要通过1号虚拟机械臂和2号虚拟机械臂相叠加的方式显示系统界面,同时将结果反馈至服务器。
(4)3D视频显示模块:通过虚拟显示的主界面同时显示两个机械臂的运动情况,操作者可以根据观看主题界面最终达到机器人交互多点位操作的目的。
(5)机械臂控制模块:机械臂控制模块主要是由控制包、姿态识别以及机械臂姿态计算三个部分组成,负责计算接收到的所有姿态数据,从而实现驱动控制机械臂作业的目的。
(6)3D视频采集模块:通过姿态传感器实时读取机械和人体姿态变化信息,获取机械臂和物体的姿态以及周围环境信息,将获取的信息及时传输至系统中进行处理。
4 实验与分析
为了验证所提机器人交互多点位操作系统的有效性,进行了实验,并选择文献[3]基于CoDeSys的全向移动机器人控制系统设计及文献[4]基于无线网络的采摘机器人控制系统设计作为对照方法。选择MSRC-12 Kinect手势数据集和Chalearn多模态代数识别(CMGR)数据集作为手势和人体姿态识别的训练集。两个数据集中的视频都是由Kinect摄像机记录的。MSRC-12数据库由594个人体动作序列组成,这些动作序列是从30个执行12个标记手势的人身上采集的。CMGR数据库是一个大型视频数据库,包括来自20个手势类别的13858个手势。为了进行人体姿态识别,手动标记与手臂运动相关的区域坐标和标签。
(1)人体姿态识别实验
在中,以图5、图6中的测试对象作为实验样本,对比文献[3]系统、文献[4]系统及这里所设计系统姿态识别的性能,测试结果,如图5、图6所示。
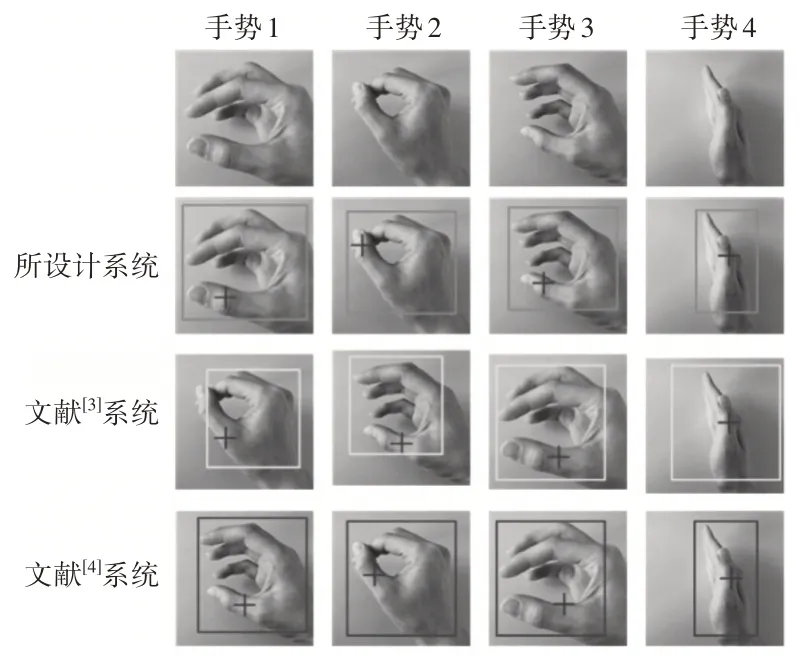
图5 不同系统的手势识别结果Fig.5 Gesture Recognition Results of Different Systems
分析图5中的实验数据可知,所设计系统能够准确识别不同类型的手势指令,同时定位准星与识别范围均在手势识别恰当位置。分析图6中的实验数据可知,所设计系统能够精准识别人体各个部位的姿态信息,确保系统能够及时根据姿态进行指定操作。综合分析上述实验数据可知,相比另外两种系统,所设计系统能够获取高精度的人体姿态识别结果,进而通过识别结果完成机器人交互多点位操作。
(2)机器人交互操作完成时间/(s)
为了更进一步验证所设计系统的性能,以下实验测试对比三种不同系统的机器人交互多点位操作完成时间,具体实验结果,如表1所示。

表1 不同系统的机器人交互多点位操作完成时间对比Tab.1 Comparison of the Completion Time of Robot Interactive Multi-Point Operations of Different Systems
分析表1中的实验数据可知,所设计系统能够以较短的时间完成机器人交互多点位操作,主要因为所设计系统在实际应用过程中,加入了人体姿态识别方法,有效降低整体的操作完成时间。
(3)机器人交互多点位操作误差/(mm):
为了验证系统性能的好坏,设定在相同的噪声环境下,对比三种系统的多点位操作误差,实验结果,如图7所示。
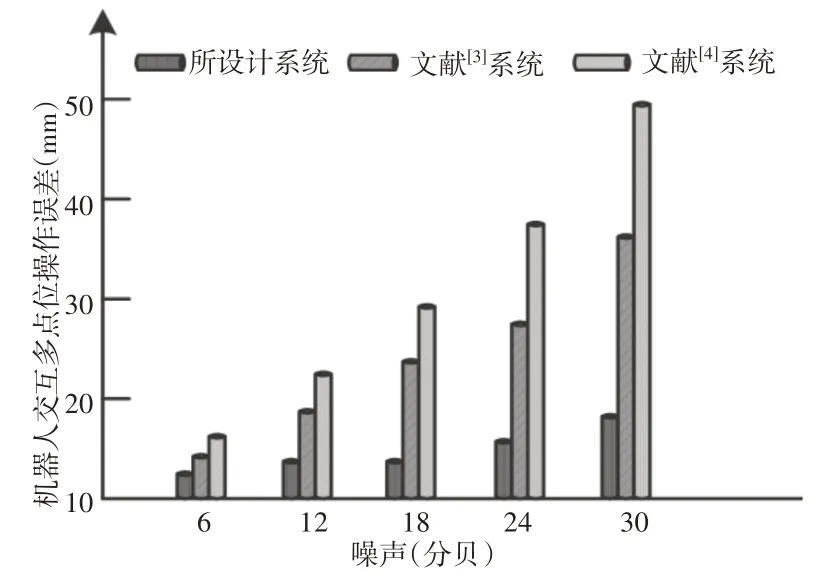
图7 不同系统的机器人交互多点位操作误差对比结果Fig.7 Comparison Results of Interactive Multi-Point Operation Error of Robots of Different Systems
分析图7中的实验数据可知,当噪声开始持续增加,各个方法的操作误差也开始呈上升趋势。但是相比另外两种系统,所设计系统的误差明显更低一些,充分验证了所设计系统的优越性,同时也说明其能够获取较为满意的操作结果。
5 结论
为了提高人机交互中手势识别的准确性,提高机器人的执行效率,这里结合了位姿传感器,设计了机器人交互多点位操作系统。构建的躯干候选点检测器可以在位置及方向两个层面同时识别人体部件,可以准确识别人体姿态。通过姿态传感器及语音控制实现了精准多点位机器人操作。测试结果表明,所设计系统能够精准识别人体姿态信息,具有较高的识别率,同时还能够降低机器人交互多点位操作完成时间和误差。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
航天制造技术(2020年4期)2020-09-11
学生天地(2020年3期)2020-08-25
红领巾·萌芽(2019年8期)2019-08-27
制造技术与机床(2018年12期)2018-12-23
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
证券市场红周刊(2018年37期)2018-05-14
中国与非洲(法文版)(2017年10期)2017-11-23
浙江大学学报(工学版)(2016年10期)2016-06-05
