
基于多步预测的无线传感网络自适应采样技术研究
2023-03-01 07:17陈健曾培炎黎鹏
机床与液压 2023年2期
陈健,曾培炎,黎鹏
(1. 广东工业大学机电工程学院,广东广州 510006;2.中国人民解放军陆军31627部队,广东深圳 518109)
0 前言
无线传感网(Wireless Sensor Networks,WSNs)是由大量的、有无线通信和计算能力的小型传感节点组成的自组织多跳网络,通常有计算能力小、能源受限等特点[1-4]。无线传感网络设备通常由电池供电,电池的容量决定了设备的运行时长,因此,找到无线设备合适的能耗解决方案成为延长网络运行周期的关键。
目前,国内外的无线传感器网络相关学者主要从能量采集、网络控制、数据融合和自适应采样策略等方面开展WSNs的节能研究。在能量采集方面,文献[1]和文献[5]结合太阳能光伏发电技术解决设备的能源补充问题,但是增加了硬件成本且需要在有阳光的环境下实现。在网络控制方面,文献[6]基于改进的蚁群算法提出一种改进ZigBee路由算法,缩短网络中节点的传输路径;文献[7]运用模糊控制方法对网络拓扑结构进行优化,控制网络中不同位置簇的规模;文献[8]运用博弈理论建立了一种能耗均衡的拓扑控制模型,使得节点能调整自身功率。但是网络控制的角度更关注的是网络的整体节能,且系统开发难度较大、不易拓展。在数据融合方面,文献[9]基于压缩感知理论提出一种时空压缩簇内数据收集算法减少传输量,但是数据反馈时间延长,不适用于实时性和数据精度要求高的场景。从自适应采样角度出发,文献[10]通过BP神经网络预测和阈值分析的方法,实现动态采样调度,但是计算量大且需要大量的训练数据;文献[3]通过分析多个节点的数据相关性选举簇头,并调整簇内节点的采样频率,但是网络维护会带来额外的通信量;文献[4]和文献[11]通过上一个预测值与采样值的误差来决定下一步采样的步长,易受到突变值的影响,且用户端得到的数据在时间上不规则,不能很好地在用户端还原采样对象的实时情况。
针对上述节能方法的不足,文中从自适应采样角度出发,首先通过在网络的上位机端和终端节点上搭建相同的预测模型进行同步预测,实现自适应通信算法;然后在自适应通信算法的基础上进行改进,提出一种基于多步预测的自适应采样算法,在保证数据精度的前提下更有效地降低终端节点的能耗;最后在基于ZigBee的船舶下水气囊气压监测系统平台上进行能耗分析和节能实验。
1 预测模型融合自适应通信算法
1.1 自回归模型
由于无线传感网络中终端节点通常由电池供电,运算能力较低且存储空间有限,因而要选择运算量低、容易部署的预测算法,增强算法可用性和可拓展性。
自回归模型又称AR模型,是用于研究平稳时间序列的一种常用方法,有计算简单、预测准确的特点。AR(P)模型可表示为
Xt=φ0+φ1Xt-1+…+φpXt-p+εt
(1)
其中:{εt}是零均值同方差的独立同分布白噪声序列,方差为σ2,且εt与Xt-1、Xt-2、…相互独立。建模过程分为以下部分:
(1)数据预处理
设获取时间序列值为
(2)
实际获取的数据序列一般为非平稳序列,因此需要对时间序列进行d次差分运算转换为平稳序列。差分后数据经单位根检验(ADF检验)方法检验平稳性。预处理后数据记为
{Xt|t=1,2,…,n}
(3)
在实际分析中,如果一阶差分结果的平稳性检验不通过,继续进行二次差分。
(2)模型识别
模型识别和定阶问题主要确定合适的p参数。对给定的长度为n的数据样本Xt,可通过偏自相关函数(Partical Autocorrelation Coefficient Function,PACF)获取可能的p阶数。
对于平稳时间序列Xt,对n=1,2,…,有:
L(Xt|Xt-1,…,Xt-n)=φn0+φn1Xt-1+…+φnnXt-n
(4)
其中:φnn为时间序列{Xt}的偏自相关系数。
(3)定阶
通过赤池信息准则函数(Akaike Information Criterion,AIC)进行定阶:
(5)
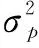
(4)参数估计及模型检验
采用最小二乘法估计AR模型参数φ0,…,φp,对拟合后残差序列进行白噪声检验。如能通过白噪声检验则说明模型能够准确刻画数据变化规律,可以对时间序列进行短期预测。若白噪声检验不通过则重新建立模型。
1.2 自适应通信算法
在一段时间的采样中,如果环境状态无变化或变化缓慢,保持固定短周期采样则会出现多个数据相同或相差不大的情况,即产生冗余数据。终端节点和上位机通过融合AR模型,利用已有数据序列的最新数据,同步预测下一次数据。终端节点在下一次采样时,若预测值与采样值的误差在设定阈值范围内,则将此次采样值视为冗余数据,不发送至上位机。由此,能够在满足一定数据精度的要求下,减少冗余数据的发送操作而实现自适应通信。
AR模型建模过程中,模型识别和定阶过程计算量较大。为了进一步降低终端节点的计算负担,将AR模型建模过程的步骤(2)—(4)搭载在上位机程序,由上位机经协调器将参数p和φnn发送至终端节点。终端节点进入节能模式,从上位机获取预设参数,以预设周期采样并上传nref次作为模型的初始数据序列。
终端节点已记录的数据序列记为Sed(i),上位机中对应的终端节点抽象对象记录的数据序列记为Scoor(i),其中i=0,1,…,n。如图1所示,在终端节点和上位机中,设置一个参考值窗口Wref,如图1所示,长度为nref,记为
Wref={Xt|t=n-nref,…,n}
(6)
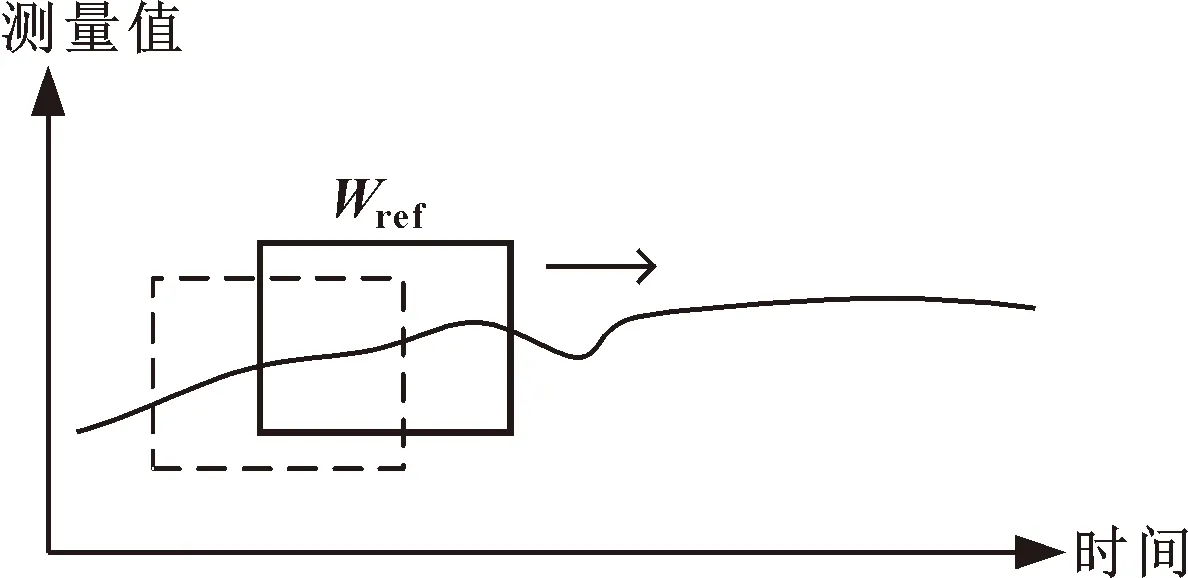
图1 参考值窗口示意
在每次采样时更新参考值窗口,确保窗口中的值为最新的采样数据。
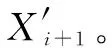
(7)
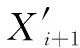
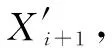
为确保AR模型的预测效果,设定最大限制错误次数nmax_err。若上位机接收到终端节点上传实测值次数大于错误限制次数,则以Wref为更新模型参数,并发送至终端节点。
2 基于多步预测的自适应采样算法
在自适应通信算法中,终端节点在每个采样周期里都进行采样操作,将浪费大量能量。从减少传感器采样次数的角度出发,对自适应通信算法进行改进,在终端节点加入步长更新机制,实现自适应采样算法。终端节点通过自适应采样算法,在环境变化不剧烈的采样周期中,保持睡眠状态,减少采样和发送操作。而当判断出环境变化剧烈时,缩短采样周期,及时采样以确保采样的精确度。
2.1 步长更新机制
为实现采样步长的自适应变化,需要制定合理有效的步长更新机制,因此在终端节点中引入趋势参考窗口。
趋势参考窗口的值为Sed(i)的最新数据,如图2所示,设长窗口为Wed,长度记为nnew;短窗口为Wed的最新一半数据,设为Wedhalf,长度记为nnew/2。
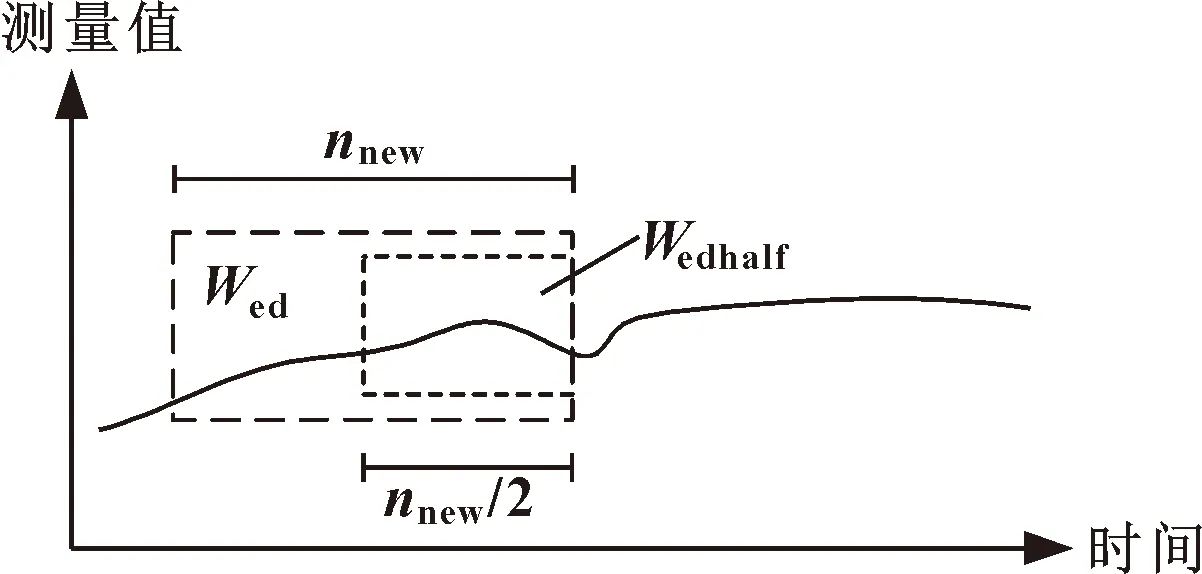
图2 趋势参考窗口示意
此窗口的数据反映了数据的最新动态变化情况,通过最小二乘法拟合参考窗口数据,可以得出此时间段中数据总体变化趋势。通过计算长窗口和短窗口的方差,可以判断出环境状态的浮动情况。当浮动较大时,以短窗口判断数据变化趋势,避免时间较旧的数据的影响;当浮动较小时,以长窗口判断数据变化趋势,避免跳变值对变化趋势的影响。
利用现有变化趋势,前向拟合接下来多个步长的数据,将拟合值与AR模型的前向预测值逐步对比,误差在设定阈值内则累计作为下一采样的步长。
把Wed的方差var(Wed)记为ved,以及Wedhalf窗口值的方差var(Wedhalf)记为vedhalf。设方差比的阈值为εed。
把拟合窗口Wref定义为
(8)
在终端节点采样得到最新的采样值后,利用AR模型进行前向预测,得到n个步长的预测值,记为{Xj|j=1,2,…,n}。利用最小二乘法拟合Wref的结果计算出接下来的n个拟合值,记为{Yj|j=1,2,…,n}。设Xj与Yj的误差阈值为εpre。
将步长新机制定义为
(9)
其中,令j从1开始,顺序判断Xj与Yj误差是否大于阈值εpre。若不大于阈值则认为该预测值Xj是可信的,继续判断下一时刻;当大于阈值,则认为当前及以后的预测值Xj不可信,退出判断,并以累计小于阈值个数S作为下一采样的步长。为提高采样精度,引入最大变化步长jmax,使得S≤jmax。
2.2 算法描述
自适应采样算法在自适应通信算法的基础上进行改进。自适应采样算法流程如图3所示。进入自适应采样算法,终端节点将根据预设模式以最小的采样频率采样nref次并上传至上位机。终端节点维护历史值序列Sed(i),上位机维护历史值序列Scoor(i)。上位机通过参考值窗口Wref的值建立AR模型,并将模型参数p和φnn发送至终端节点。然后,上位机和终端节点将进行同步预测。
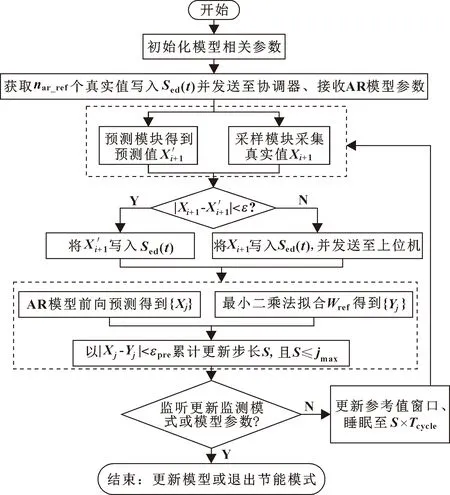
图3 自适应采样算法流程
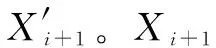
进入步长更新机制,终端节点以最新数据生成Wref参考值窗口,利用最小二乘法拟合并得到未来j个拟合值,同时利用AR模型前向预测得到j个预测值。通过顺序判断误差是否大于阈值εpre来确认更新的步长S。
更新步长S值后,终端节点将前向预测值{Xj|j=1,2,…,S}写入序列Sed(t),同时设置下一次睡眠时间为S×Tcycle。在此次采样周期结束后,终端节点在接下来的S个周期中都保持睡眠状态,直到被睡眠定时器唤醒。
同时,为减少预测模型的累计误差,在预测算法中加入修正机制。设参数Nnotsend为修正上传次数,在节点的每个工作周期中累减1,并在等于0时重置为初试值。当Nnotsend达到0时,不论预测值误差是否在设定阈值内,此周期采样后都将强制上传并存储采样值X′i+1。节点每次确定睡眠步长S时进行判定,S如果大于当前的Nnotsend值,则更改S为当前Nnotsend值,确保终端节点醒来采样并上传采样值。
由于上位机与终端节点所维护的AR模型是一致的,双方利用相同的数据进行同步预测,能够确保双方数据的一致性。同时,上位机在终端节点睡眠过程中,仍保持预设的采样周期进行数据更新,能够及时地反映数据走势。
终端节点的自适应采样算法如表1所示。

表1 终端节点自适应采样算法伪代码
3 实验验证
3.1 气压监测平台
如图4所示,在船舶下水场景中,气囊气压监测系统的ZigBee网络包含3种硬件节点类型,分别为协调器、路由节点和终端节点[12-13]。对每个气囊安装终端节点,由终端节点上的气压传感器获取气压数据。考虑从船舶起墩开始到最终成功下水,气囊位置会不断移动,因此部署多个无能量限制的路由节点以转发数据包至协调器。协调器通过RS-232接口与上位机进行通信,实现气压数据上传和网络控制命令的转发。
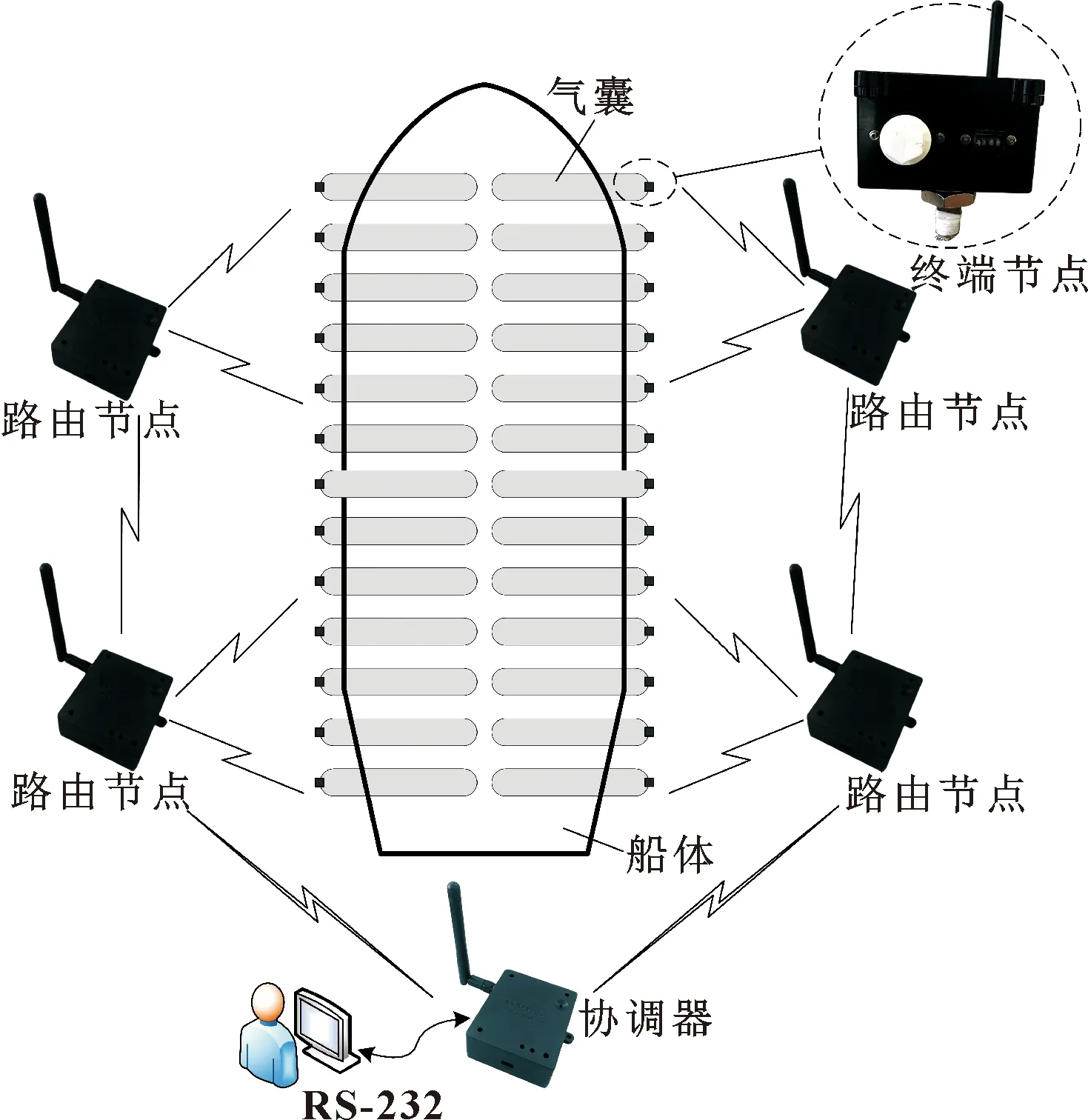
图4 船舶下水气囊气压监测场景示意
如图5所示,船舶气囊下水气压监测系统的功能结构分为上位机、ZigBee网络和数据源。
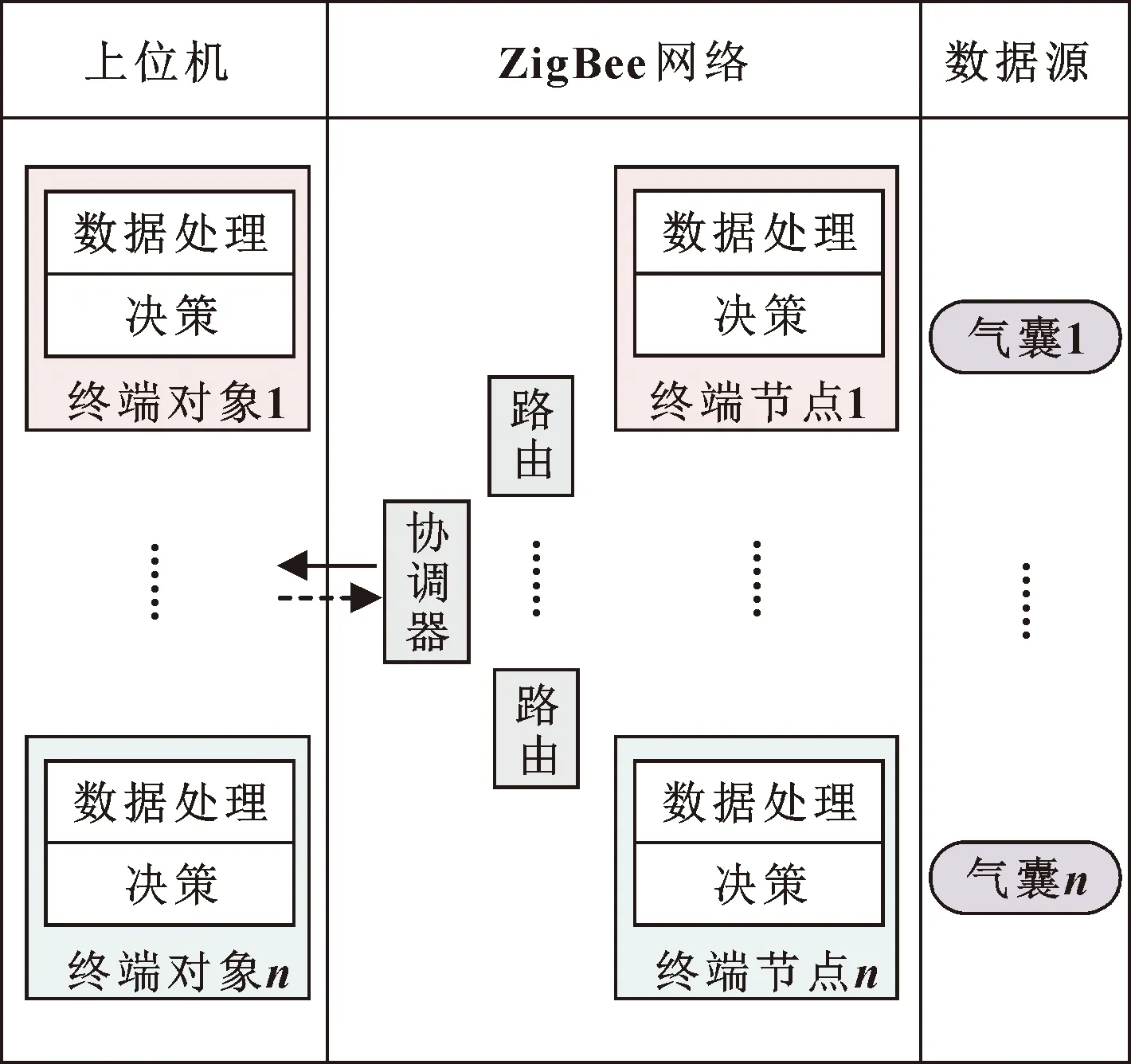
图5 监测平台功能结构
上位机为每个终端节点建立相应的抽象对象,以实现对所有终端节点进行单独的采样控制和数据处理。终端节点作为一种由电池供电、需要密封且频繁移动的部件,是节能研究的关键对象。
3.2 节点能耗分析
终端节点有5种不同的运行模式,分为主动模式、空闲模式、PM1、PM2和PM3。设定终端节点的行为分为发送数据、接收数据、空闲监听和休眠,分别对应发送状态、接收状态、监听状态和休眠状态。节点状态转换示意如图6所示。考虑到空闲状态除了CPU内核空闲,其他功能及能耗与主动模式一样,PM2模式能够由睡眠定时器唤醒,因此设定终端节点在发送状态和接收状态运行在空闲模式,监听状态工作在主动模式,休眠状态的运行模式为PM2。

图6 节点状态转换示意
考虑到实际场景中不需要全网时间同步,且信标模式比非信标模式带来额外的数据收发,故采用非信标模式。在正常的周期采样模式情况下,设定终端节点从睡眠状态被唤醒将进入监听状态,在此状态下激活气压传感器进行采样。采样结束则进入发送状态上传数据包,然后进入接收状态接收ACK数据包。在确认上传数据成功后,终端节点设置监听一定时间,如果在监听期间接收到下传的工作模式控制的数据包,将回复ACK数据包并且按照新分配的参数修改相关变量。随后在无任务进行时进入睡眠状态,直至被定时器唤醒。
参考文献[11]对终端节点进行能耗分析。在终端节点的能耗分析中,网络中数据发送冲突或数据包丢失的情况与实际网络状态相关,因此忽略数据重传、不定时的网络维护造成的数据收发以及各个状态间转换造成的能耗。
定义气压传感器的供电电压为Vsensor,平均电流为Isensor,采集时间为Tsensor,则采集一次数据,气压传感器消耗掉能量可表示为
Esensor=Vsensor×Isensor×Tsensor
(10)
定义终端节点发送一个数据包的能耗为
Etx=Vsupply×Itx×Ttx
(11)
其中:Vsupply为芯片电路平均供电电压;Itx为发送状态的平均电流;Ttx为发送一个数据包的平均时间。同理可以得到接收能耗Erx、监听能耗Elisten、睡眠能耗Esleep如下式:
Erx=Vsupply×Irx×Trx
(12)
Elisten=Vsupply×Ilisten×Tlisten
(13)
Esleep=Vsupply×Isleep×Tsleep
(14)
假设一个运行周期为Tcycle,其中设发送次数为Ntx,接收次数为Nrx,采样次数为Nsensor,则总能耗模型Etotal可以表示为
Etotal=EsensorNsensor+EtxNtx+ErxNrx+Elisten+Esleep
(15)
其中Tsleep=Tcycle-TtxNtx-TrxNrx-Tlisten。睡眠电流为最小,因此为达到节能目的,要尽可能减少采样次数Nsensor和通信次数Ntx及Nrx,尽可能延长睡眠时间。查阅器件数据手册,此实验平台的能耗模型参数如表2所示。
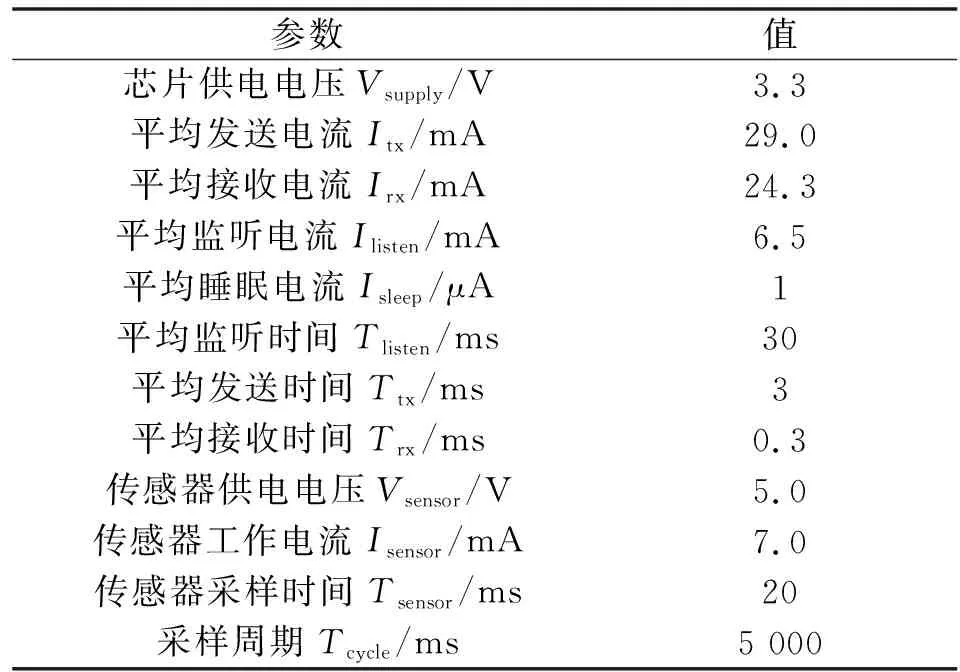
表2 功耗模型参数
3.3 实验结果
采用Berkeley大学的Intel实验室公开的传感器数据集,及作者实验室对船舶下水场景模拟所获取的气囊气压数据集,以验证所述算法的节能效果。其中Berkeley公开数据集包含54个传感器的温湿度、亮度及电压数据,文中采用了编号为22的传感节点在2004年3月20日的2 303个温度数据;作者实验室模拟数据为气囊的1 305个气压数据。将自适应通信算法记为算法1,基于多步预测的自适应采样算法记为算法2。
取Berkeley数据集在此实验平台中仿真,算法1取参数nref=20,Tcycle=5 000 ms,εerror=0.07,nmax_err=5;算法2取参数nref=20,Tcycle=5 000 ms,εerror=0.03,εed=0.5,jmax=3,Nnotsend=8。图7所示为Berkeley数据集在固定周期采样、算法1和算法2下的能耗对比。可以看出:相对于固定周期采样的方式,算法1能够节能15.137%,算法2能够节能41.809%,算法2比算法1节能31.430%。
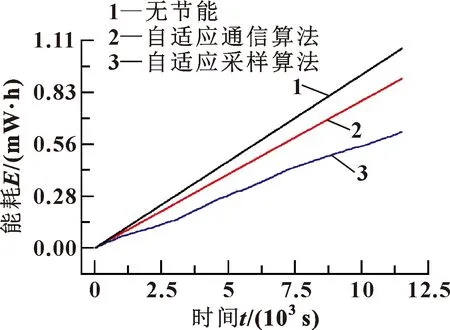
图7 Berkeley数据集能耗
图8所示为实验室数据集在固定周期采样、算法1和算法2下的能耗对比。其中算法1取参数nref=20,Tcycle=5 000 ms,εerror=0.25,nmax_err=5;算法2取参数nref=20,Tcycle=5 000 ms,εerror=0.08,εed=0.025,jmax=5,Nnotsend=8。仿真结果表明:相对于固定周期采样的方式,算法1能够节能12.770%,算法2相对于固定周期采样的方式能够节能36.252%,算法2比算法1节能26.912%。
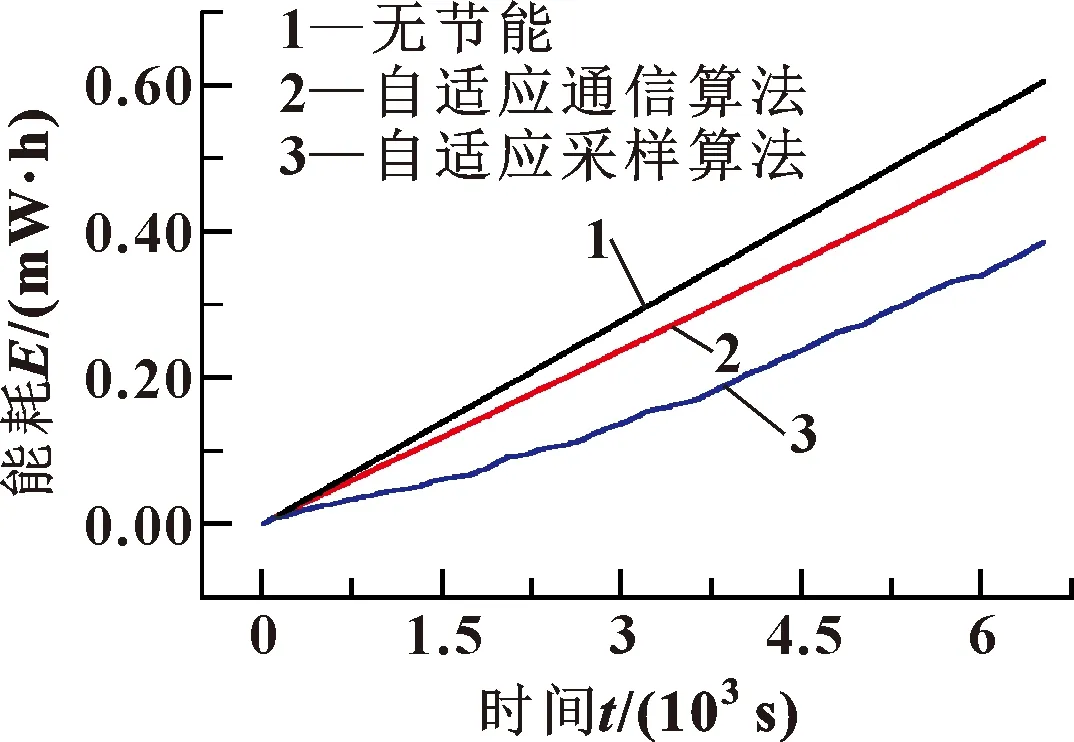
图8 实验室数据集能耗
为验证模型的预测精度,需对结果进行误差分析。文中采用均方差根误差RMSE(Root Mean Square Error)对实验所获取的数据进行统计分析。计算公式为
(16)
其中:ai为实际测量值;fi为协调器获取的值;n为采样次数。
图9和图10分别展示了利用Berkeley数据集和实验室数据集,算法1和算法2与固定采样周期采样结果的误差对比。为便于观察,已将算法1和算法2的结果偏置。εRMSE值如表3所示,其中,实验室数据集在算法2中的εRMSE值为0.089 2。

图9 Berkeley数据集仿真效果
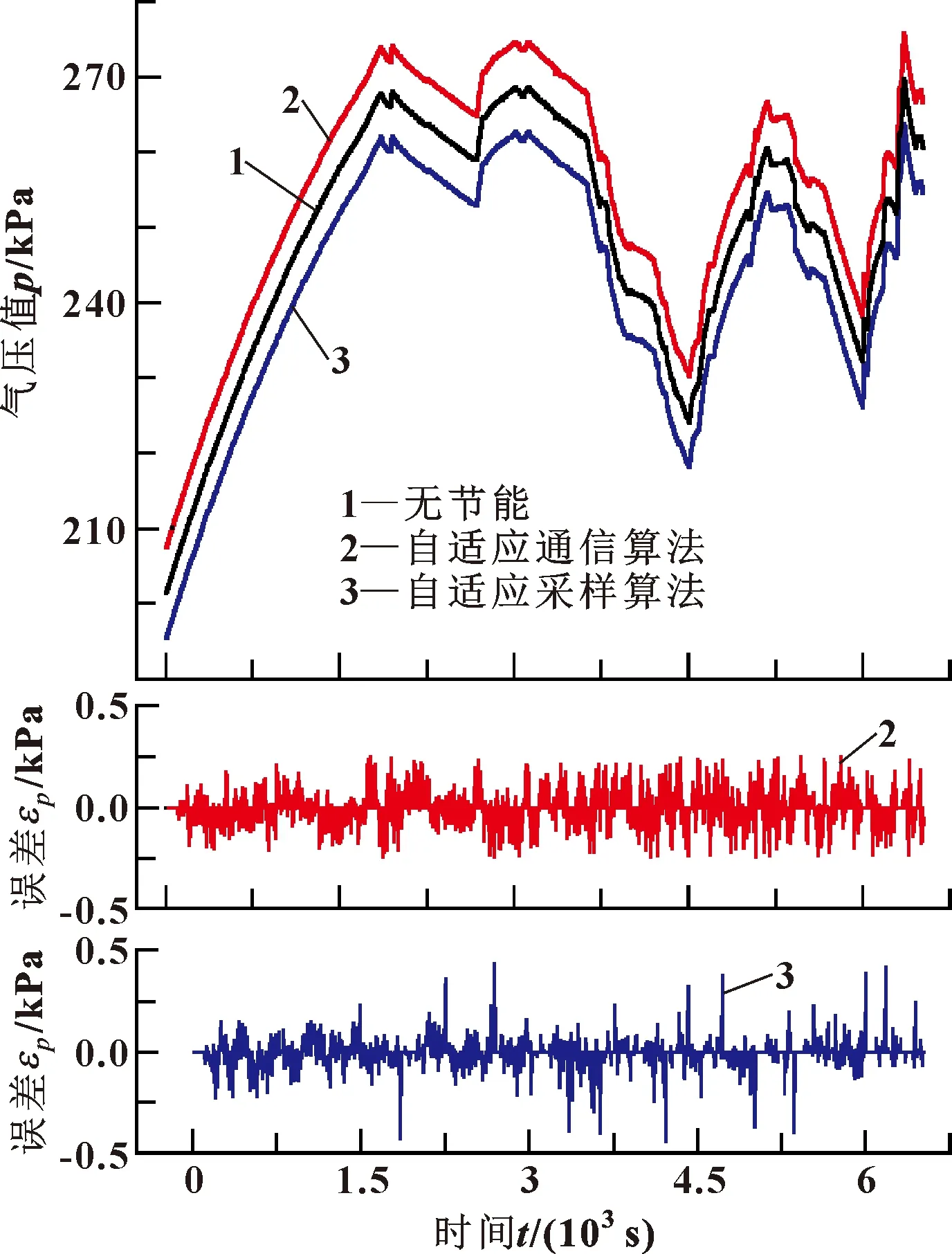
图10 实验室数据集仿真效果
如表3所示,RMSE结果表明:算法1与算法2能达到较好的数据精度;在精度相同的情况下,算法2的节能效果比算法1要好。

表3 各数据集在不同算法下的εRMSE值
为展示数据动态性对采样次数的影响,以实验室的数据集为例,将实际采样数据中对应自适应采样阶段的数据进行一阶差分。以25个采样周期为窗口取一阶差分结果的方差作为x,并取该窗口周期的总采样次数作为y。从图11可以看出:在数据动态性增大时总采样次数增大,自适应采样算法起到了很好的调整采样步长的作用。
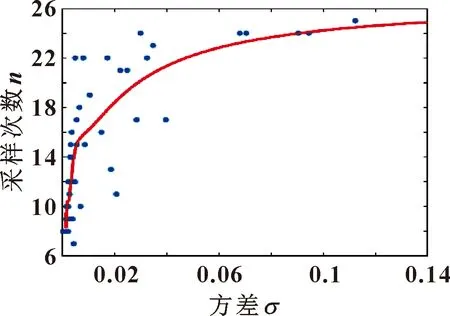
图11 一阶差分数据方差σ与采样次数n的关系
4 结束语
文中提出了一种基于多步预测的无线传感网络自适应采样算法,在确保较好数据精度的同时,实现了终端节点的有效节能。通过在上位机和终端节点间建立自回归预测模型进行同步预测,并根据前向多步预测值与数据变化趋势拟合值间的误差,自适应地改变采样步长。实验结果表明,该算法在保证上位机和终端节点数据一致性以及上位机数据更新实时性的情况下,能达到较好的节能效果。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
成都信息工程大学学报(2021年5期)2021-12-30
建材发展导向(2021年23期)2021-03-08
中国惯性技术学报(2020年2期)2020-07-24
成都信息工程大学学报(2019年2期)2019-08-28
华人时刊(2018年15期)2018-11-10
车迷(2018年12期)2018-07-26
中国老区建设(2016年3期)2017-01-15
山东工业技术(2016年15期)2016-12-01
