
基于BERT-BiLSTM-CRF模型的地理实体命名实体识别
2023-04-06 10:22汤洁仪李大军
北京测绘 2023年2期
汤洁仪 李大军 刘 波
(东华理工大学 测绘工程学院, 江西 南昌 330032)
0 引言
构建新型基础测绘体系的首要任务是建成以地理实体为核心的基本国家地理实体数据库[1]。地理实体是在空间数据库中表达一个现实的世界中实际存在地理对象其所有的信息。互联网中存在着大量与地理实体相关的信息,但从互联网上收集到的数据存在格式不统一、质量不整齐和文本信息不完整等特点[2],如何从非结构化的文本中抽取出结构化的地理信息一直是人们亟须解决的问题。
命名实体识别(named entity recognition,NER)是知识抽取的基本任务之一,主要是从文本中抽取出具有特定意义或者指代性强的实体,如人名、地名、组织机构名、日期时间、专有名词等[3]。命名实体识别的方法主要可分为基于规则的方法、基于统计模型的方法和基于深度学习的方法[4]。Aitken等[5]运用归纳逻辑编程(inductive logic programming,ILP)技术在自然语言数据中获得了信息提取规则,在有371个句子的数据集中,得到的F1值可达66%,但基于规则的信息抽取存在耗时较长、成本高且可移植性较差等问题;张雪英等[6-7]以可扩展标记语言(eXtensible markup language,XML)为标注元语言,基于规则的方法构建了地理实体标注体系利用软件设计了基于深度信念网络(deep belief networks)的地质实体识别模型,有助于解决地理实体相关标准和规模化标准数据匮乏的问题,但本方法对标注的标准依赖性较高且数据库存在不均衡等问题;陈婧玟等[8]基于条件随机场(conditional random field,CRF)模型对双语料库中的地质文本中的时间信息进行抽取,但相对于特定领域而言,抽取的效率及分词的效果不如通用领域的好,无法准确识别并提取到专有名词;王若佳等[9]人利用BiLSTM-CRF模型对中文电子病例中的五种实体进行识别,当数据集较小时识别的效果较好,但在大规模数据集和自建语料库中表现尚待进一步研究;王子牛等[10]利用结合基于双向Transformer大规模预训练语言模型(bidirectional encoder representation from transformer,BERT)和BiLSTM-CRF模型对中文实体进行识别在人民日报数据集上得到很好的效果;BERT模型在许多公开数据集的自然语言处理任务中均取得了不错的F1值,但在专业领域中的效果尚未体现。
因此,本研究在前人研究的基础上,利用爬取的百度百科中与地理实体相关的信息构建语料库,基于BERT-BiLSTM-CRF模型将其应用于地理实体领域的命名实体识别,并对比了BiLSTM模型与BiLSTM-CRF模型对人名、地名和机构名三种实体的抽取结果,为后续知识抽取和应用奠定基础。
1 基于BERT-BiLSTM-CRF模型的地理实体命名实体识别
1.1 BERT模型
Devlin J等[11]提出了基于双向Transformer模型的BERT模型,在多个NLP任务中取得了很好的结果,可以通过对所有层的上下文信息进行预训练,从而为问题回答和语言推理等创建最先进的模型。BERT作为词嵌入层,是一个预训练的语言表征模型,也是基于Transformer模型的编码(Encoder)。即将文本中的每个字符作为原始的词向量通过查询字向量表将文本中的每个字转换为一维向量输入到模型中,模型输出则是输入各字对应的融合全文语义信息后的向量表示。
Transformer模型[12]最早是在2017年由谷歌提出来的,用于NLP领域,采用Encoder-Decoder架构,每个Transformer都包含多头注意力机层(multi-head attention)、全连接层(FeedForward)、残差链接和归一化层(Add & Normal)。相较于其他NLP模型,不同于循环神经网络(recurrent neural network,RNN)相关模型只能从左向右依次计算或者从右向左依次计算,Transformer支持并行化的语言处理,在Encoder端可以支持并行处理整个序列,并且得到输出,极大地节约了训练时间。
1.2 BiLSTM模型
BiLSTM-CRF模型是由Lample G.等人[13]提出,以双向长短时记忆(bidirectional long short-term memory,BiLSTM)模型的结果作为CRF的输入,通过CRF引入标签间的状态转移矩阵,在四种不同国家语言的开放语料中都取得了很好的结果。BiLSTM模型[14]是由前向LSTM和后向LSTM组合而成,长短时期记忆(long short-term memory,LSTM)模型是一种特殊的RNN,主要为了解决长序列过程中的梯度消失和梯度爆炸的问题,因而引入了储存单元、输入门、遗忘门和输出门的控制机制[15]。单向的LSTM-CRF模型只能学习序列的单向信息,不能做到学习句子上下文的全部信息。BiLSTM结构由前向和后向的两层LSTM神经网络组成,它们的输入相同,能够通过前后两个方向的LSTM进行信息的特征提取,实现对整个语句或文本的上下文信息关联[16]。
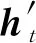
1.3 CRF模型
CRF模型善于处理长距离的上下文信息,但无法处理标签间的依赖信息。设两组随机变量X=(X1,X2,…,Xn),Y=(Y1,Y2,…,Yn),线性链条件随机场的定义为P(Yi|X,Y1,…,Yi-1,Yi+1,…,Yn)=P(Yi|X,Yi-1,Yi+1),i=1,…,n,(其中当i取1或n时只考虑单边),用于序列标注问题的线性链条件随机场,是由输入序列来预测输出序列的判别式模型。CRF相比其他概率图模型能够利用更加丰富的标签分布信息,能通过邻近标签的关系获得一个最优的预测序列,例如:B-PER后面不可能接B-LOC,并弥补BiLSTM的缺点,能够更好地利用上下文信息,确保最终预测结果的有效性和合理性,提高标注效果。
1.4 基于BERT BiLSTM-CRF的地理实体命名实体识别模型
BERT BiLSTM-CRF模型是将BERT模型与BiLSTM-CRF模型结合起来,首先利用BERT预训练模型获取地理实体描述特征,将语料库中的每一个输入字符词嵌入(Embedding)为包含字符向量、句级向量和位置向量的初始向量输入到BiLSTM模型中,充分学习句子序列的上下文信息得到包含所有字符的字典,最后输入到CRF模型中根据句子逻辑和上下文信息得到每个字符标注的概率分布,得到各个序列中字符的最可能的标注。模型如图1所示。
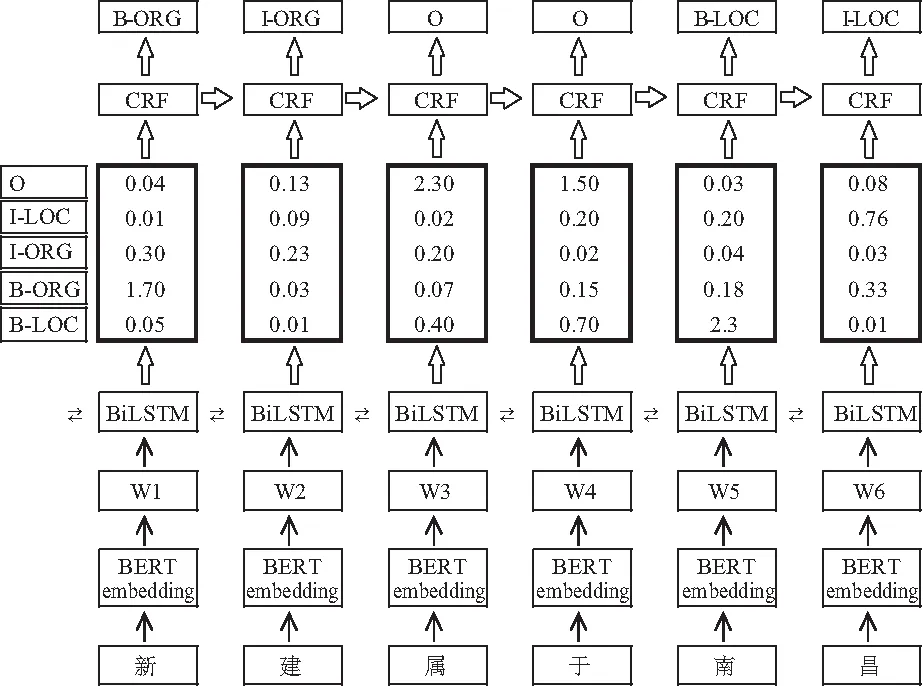
图1 BERT-BiLSTM-CRF模型结构图
2 实验分析
2.1 实验数据
百度百科中蕴含大量丰富的地理信息,且百度百科词条数据结构十分固定,主要可分为标题、概述框、信息框、同名消歧、缩略图、词条统计、标签七个部分。本研究利用网络爬虫技术中的Request和Beautiful Soup库,研究区域为江西省南昌市新建区,从百度百科中获取到基于百度地图与研究区域兴趣点(point of interest,POI)数据相关的概述框部分的非结构化文本(如图4所示)构成数据集,其中含有文本概述6 307行,共计369 714个字符。

图2 百度百科词条示例
2.2 标注方法
在命名实体识别任务中,首先需要对初始的文本进行标记化(Tokenization),将输入的文本分割成一个个字符(token),配合词典映射成向量使计算机正确识别文本并且不会存在遗漏的问题。一般情况下,汉语中的特征类别有字和词2种,基于字粒度的Tokenization表示将句子切分成单个的汉字,例如:我是中国人按照字粒度可切分为我/是/中/国/人。可以看出,基于字粒度的切分鲁棒性较强且词表大大减少,但一个单字在本质上不具有语义意义,减少词表使得输入长度大大增加,从而使得输入计算更加耗时耗力。基于词粒度的Tokenization可以将我是中国人切分为我/是/中国人,与人类阅读时的习惯性切分一致。词粒度的切分一方面能够很好地保留完整的词的含义,另一方面能够很好地保存词的边界信息,可以避免由于标签偏移和关键词语义信息丢失等对后续的序列标注及NER任务结果的影响。综上所述,本文选择的字符特征为词汇与标点符号,将原始文本经过预处理后进行序列标注。目前实体命名较为常用的序列标注方法有三种:BIO(B-begin,I-inside,O-outside)三位标注法、BMES四位序列标注法(B表示一个词的词首位值,M表示一个词的中间位置,E表示一个词的末尾位置,S表示一个单独的字词)、BIOES(B-begin,I-inside,O-outside,E-end,S-single)五元标注法。本文采取的为BIO标注法,即B表示该实体的起始位置,I表示该实体的非起始位置,O表示不属于任何实体。
2.3 评价体系
实体抽取的效果是通过计算模型的精确率P(Precision)、召回率R(Recall)和F1值[12]得到的,P表示正确预测的实体占全部识别出的实体的比例,R表示正确识别的实体占应识别实体比例,F1是结合了P和R的综合评价指标。计算公式如下。
(1)
(2)
(3)
其中,TP表示数据集中正确预测为正类的词数目,FP表示数据集中错误预测为负类的词数目,TN表示数据集中正确预测为负类的词数目,FN表示数据集中错误预测为负类的词数目。
3 实验过程与结果
3.1 数据预处理
百度百科网页的文本主要是由用户对知识及信息进行归纳编辑,是对实体进行的概括性的描述,内容为非结构化,通常所含信息量较大且真实性强,但可能存在句子不规范、信息冗余、信息错误和缺失等问题。因此需要对数据集进行预处理,将数据集中不相关、视为噪声的内容删除,去除无用的符号(空格、特殊符号及数字角标等),文本只保留有用信息。
3.2 构建语料库
在真正使用模型进行关系分类前,需要构造相应的标注语料库。这些语料数据往往因为没有相应的知识库而难以构造,因此只能使用人工标注的方式来进行。本研究从文本中识别人名、地名和机构名三种实体类型,其中人名表示为PER,人名的首字标记为B-PER;地名表示为LOC,地名的首字标记为B-LOC;机构名表示为ORG,机构名的首字标记为B-ORG,数据集标注如表1所示,由此得到自构建的标注语料库,语料划分如表2所示。
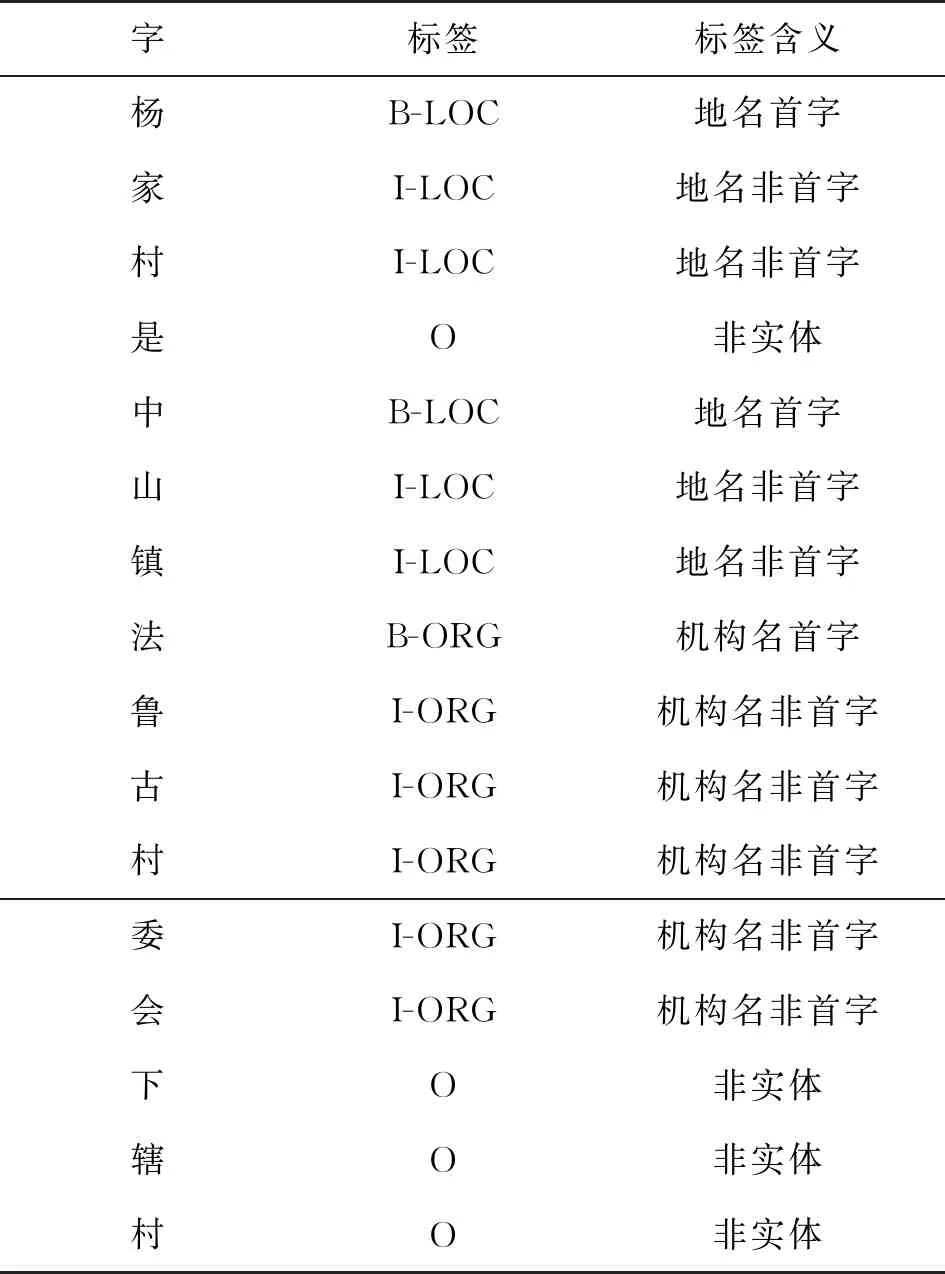
表1 数据集实体标注实例

表2 语料数据划分
3.3 模型训练与结果
本实验采用TensorFlow框架进行模型搭建,将上述实验语料按照7∶2∶1的比例分成了训练集、测试集和验证集,实体识别结果如表3所示。
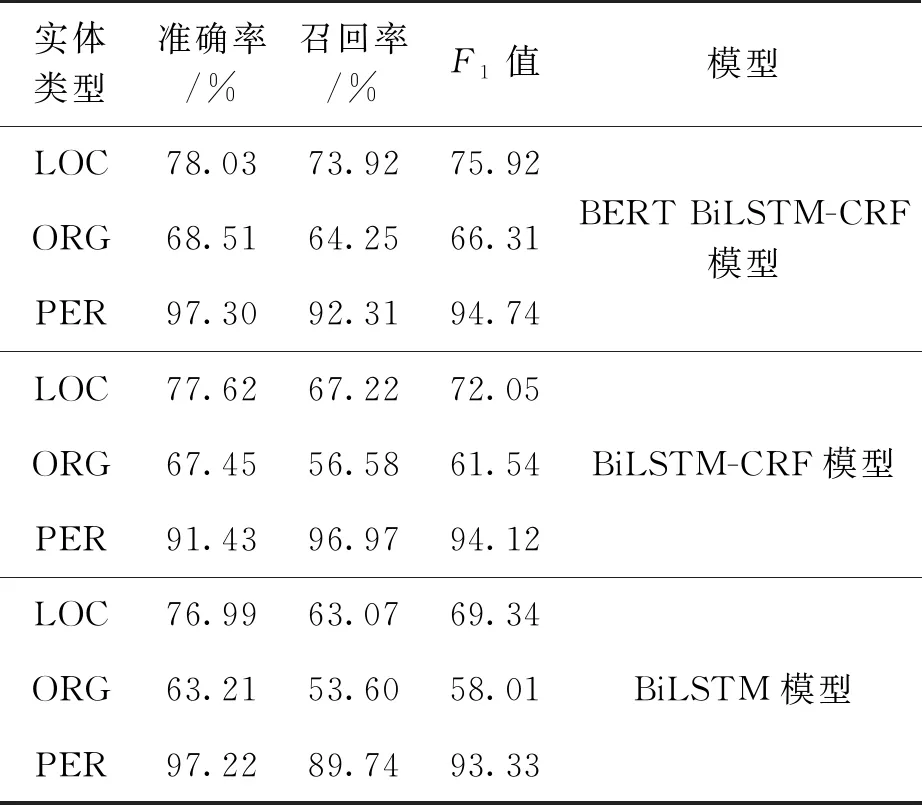
表3 不同模型的命名实体识别结果
从识别结果可以看出,BERT BiLSTM-CRF模型与其他模型相比在对三类实体识别中效果更好,对机构名类实体的识别效果在准确率、召回率及F1值三方面都有一定的提高。三种模型均对人名识别的准确率和F1值都达到了90%以上;从准确度和F1值来说,BERT BiLSTM-CRF模型对三类实体的识别效果均高于BiLSTM-CRF模型和BiLSTM模型;从召回率来看,BERT BiLSTM-CRF模型对地名类和机构名类实体的识别效果要优于其他两种模型,相差最大,可达10.85%;由此可见,BERT BiLSTM-CRF模型从识别效果和稳定性两方面都优于其他两种模型。
4 结束语
本研究将深度学习领域的BERT BiLSTM-CRF模型应用于地理实体的命名实体识别任务中,为了证明BERT模型的有效性,本实验基于自建的标注语料库在BERT BiLSTM-CRF模型、BiLSTM-CRF模型和BiLSTM模型的实验结果进行对比。在BiLSTM-CRF模型和BiLSTM模型中没有BERT Embedding层,而是使用了传统的Word Embedding层,将每个字符通过One-hot独热编码为低维稠密的字向量,将文本训练转化为字向量输入到模型中。BERT模型通过Embedding将语料库中的可利用的语义信息迁移过来,并对后续任务进行调整,提高了模型的输出效果和逻辑性。实验结果表明,BERT BiLSTM-CRF模型对三种实体的识别效果均优于其他两种模型,可以适用于命名地理实体的识别场景中。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
天津外国语大学学报(2020年1期)2020-03-25
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
语言与翻译(2015年4期)2015-07-18
