
高速路相邻前车驾驶人意图预测
2023-04-06 04:38袁小慧归文强
测试技术学报 2023年2期
袁小慧,归文强
(1.长安大学 汽车学院,陕西 西安 710064;2.西安航空学院 车辆工程学院,陕西 西安 710077)
在跟车过程中,为了提高自车的舒适性、安全性以及行驶效率,驾驶人调整车速及跟车间距避免相邻车道前车并道至自车之前,同时当相邻车道前车并道至自车之前时,驾驶人必须重新调整车速,以适应新的跟车对象引起的跟车间距的变化。
目前,研究者大多是以换道行为车辆本身作为研究对象,进行意图和行为识别,较少从跟车角度出发,将换道车辆作为相邻车道车辆,对其驾驶行为进行预测。付锐等[1]基于Fisher判别法,以自车与相邻车和当前车道前车相关的4个参数作为特征参数,包括自车车速、自车与当前车道前车的车头时距、相对速度以及自车与相邻前车的相对速度,对相邻前车的两种并道行为类型进行预测,并道行为类型包括相邻前车并道至当前车道前车之前以及自车与前车之间;马国成等[2]基于模糊支持向量机,以自车与相邻前车的7个相关参数作为表征参数,包括实测的自车车速、自车与相邻前车的纵向距离和横向距离、纵向和横向相对车速以及由卡尔曼滤波估计得到的前车相对自车的纵向和横向加速度,对相邻前车的并道意图进行辨识;张海伦等[3]基于公开的NGSIM数据集,建立双层连续隐马尔可夫模型和贝叶斯生成分类器以及双向长短时记忆网络模型,识别并预测相邻前车的驾驶行为,辨识的驾驶行为类型包括并道至自车与本道前车之间以及相邻前车保持原车道行驶;蔡英凤等[4]以自车与相邻车道前车和当前车道前车的7个相关参数作为特征参数,包括相邻车道前车的横向速度和航向角、相邻车道前车和当前车道前车与自车、自车和自车前方车辆纵向相对距离与纵向相对速度、相邻前车与当前车道横向距离,对相邻前车的并道行为进行辨识;Seungwuk Moon等[5]基于模糊决策思想,以自车与相邻前车的侧向距离和相对速度作为相邻前车并道的表征参数,认为侧向距离较小、侧向加速度较大时,相邻前车具有并道意图,该方法具有主观性,不能客观表征相邻前车的并道行为;Ismail Dagli等[6]基于机率理论模型,预测和分析车辆位置,从而识别相邻前车的并道行为。
本文从高速公路实际的驾驶行为数据出发,从本车道跟随车辆的角度,考虑自车与相邻前车以及自车与本车道前车的运动关系,提取相邻车道驾驶行为的表征参数,以此建立预测模型,预测相邻前车的驾驶行为。
1 驾驶意图特征参数的提取
在单向两车道高速公路上,根据相邻前车的并道位置,可将相邻前车的驾驶意图分为4类,如图1 所示。其中,第1类为保持原车道跟车行驶,第2类为并道至前车L0之前,第3类为并道至自车M与前车L0之间,第4类为并道至自车M之后。
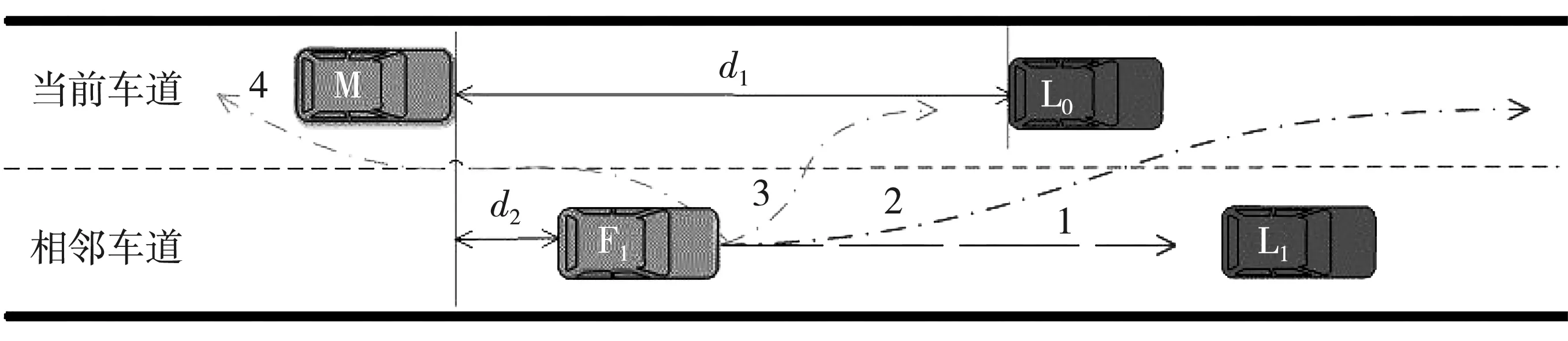
图1 相邻前车的驾驶意图分类
4类驾驶意图下,相邻前车驾驶人具有4类不同的驾驶行为,这会对自车M产生不同的影响。其中,第1类驾驶行为下,相邻前车F1保持原车道跟车行驶,对自车M的影响最小;第2类驾驶行为下,相邻前车F1并道至前车L0之前,自车的跟车目标仍为前车L0,此时,前车L0由于相邻前车F1的并入而改变车速,进而间接影响自车M;第3类驾驶行为下,相邻前车F1并道至M车与L0车之间,M车的跟车目标由L0变为F1,原有跟车状态被打破,跟车间距会突然减小,对M车的影响最大;第4类驾驶行为下,相邻前车F1并道至M车之后,对自车的影响非常小,且该类行为极少出现。因此,本文仅对相邻前车的前3类驾驶意图进行预测。
1.1 试验数据采集与处理
为研究相邻前车的驾驶意图,进行高速公路实车试验,采集自车所在车道以及相邻车道的车辆行驶数据。试验路段为限速120 km/h的双向4车道高速公路,试验里程为58.3 km。共有10名驾驶人参与实车试验,驾驶人年龄介于28岁~45岁之间,均值为35.2岁;驾龄介于3 a~20 a,均值为10.5 a,标准差为5.2 a。试验车辆为配备多种采集设备的大众途安乘用车,设备包括安装于试验车辆前部和后部的毫米波雷达、多通道视频监控系统、加速踏板和制动踏板开度传感器、方向盘转角传感器等。其中,毫米波雷达用于测量自车与前方或后方车辆的间距、相对速度以及相对角度等数据;多通道视频监控设备用于监控整个试验过程中驾驶人面部、操作行为、前方道路和后方道路交通环境,后期可通过回放筛选数据。为保证试验过程能反映真实的驾驶习惯,试验前告知驾驶人试验路线并要求其按照日常操作习惯进行驾驶。
试验后,按照以下原则筛选试验数据:
1)本文基于何民[7]对跟车状态中自由行驶与跟车行为的界定原则,筛选自车与当前车道前车的车头时距小于5 s的相关数据;
2)从视频上看相邻前车是具有并道的意图还是保持原车道跟车行驶的意图,对于具有并道意图的数据,筛选相邻前车驾驶人开启转向灯至有横向偏移之间的数据,并以有横向偏移前2 s内数据作为待分析样本;对于保持跟车行驶的数据,筛选相邻前车与自车的车头时距小于前车与自车的车头时距的数据。
根据以上原则,最终筛选出具有第1类和第2类驾驶意图的行为数据各有25次,包含400组,第3类驾驶意图的行为数据有50次,包含800组样本,每组样本包含某个时刻的相关驾驶行为数据。
1.2 特征参数提取
车辆行驶数据能很好地复现行驶过程,反映驾驶人意图[8-10],因此本文拟从自车车速vM、自车与前车的纵向间距d1、车头时距t1、纵向相对速度v1、自车与相邻前车的纵向间距d2、车头时距t2、纵向相对速度v2等7个参数中提取特征参数。其中,纵向间距d(d1和d2)、车头时距t(t1,t2)、纵向相对速度v(v1,v2)可由雷达采集的相对距离d0、相对速度v0和方位角α0计算得到:d=d0cosα0,t=d/vM,v=v0cosα0。
对所选7个参数进行pearson相关系数检验,发现vM,t1,v1,v24个参数的pearson相关系数均小于0.01,表明这4个参数线性不相关。进行多重共线性检验,其值小于5,表明不存在多重共线性。因此,本文将vM,t1,v1,v24个参数作为相邻前车驾驶意图的表征参数。
2 相邻前车驾驶人意图预测
对相邻前车的驾驶人意图进行预测,本质上是对相邻前车的驾驶意图进行判别分析,即判别其属于3类驾驶意图的哪一类。因此,本文采用常见的两种判别分析方法对相邻前车驾驶人意图进行预测。
2.1 SVM
支持向量机(Support Vector Machine, SVM)一般处理二分类问题[11-14],也可通过构造合适的多类分类器处理多分类问题,其基本思想是确定一个能够划分所有数据样本的超平面,且该超平面到所有数据样本的距离最短。
在构造多类分类器时,常采用的方法有“一对一”和“一对其他”。其中,“一对其他”的分类方法易出现样本不对称现象,且在判别分析时可能出现一个样本不属于任何一类的情况。考虑到待判别的相邻前车的驾驶意图仅有3类,类别较少,计算复杂度不大,本文在进行判别分析时采用“一对一”的判别方法。
在采用“一对一”[15-16]的方法判别相邻前车的驾驶人意图时,需要针对3个类别的驾驶行为数据样本,设计3个SVM分类器,即在每两类样本间均设计一个SVM。在构造含有两类驾驶人意图样本(第i类和第j类)的SVM时,按照式(1)的方法进行最优化计算
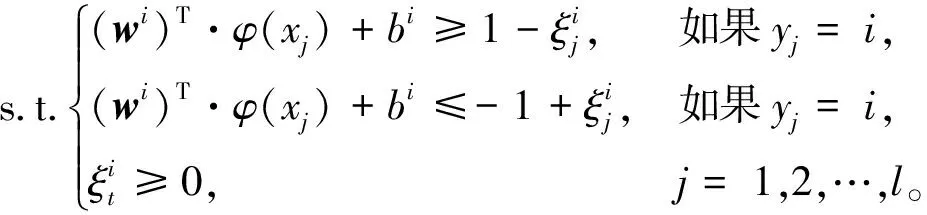
(1)
式中:w和b分别为构造的超平面的法向量和位移项;φ为映射函数;C为惩罚参数;ξ为KKT(Karush-Kuhn-Tucker)乘子。
其决策函数为
fi(x)=(wi)Tφ(x)+bi。
(2)
在预测阶段,采用投票法预测相邻前车的驾驶人意图。首先,初始化各类别驾驶人意图的初始得票数,然后,将待测驾驶人意图样本数据x输入到各决策函数中进行判别,当某分类器ci,j将样本x识别为第i类驾驶人意图时,则第i类驾驶人意图对应得票数加1,当该分类器ci,j将样本x识别为第j类驾驶人意图时,则第j类驾驶人意图对应得票数加1,所有分类器均对样本判别后,将得票数最高的那个类别作为样本x的驾驶人意图。
考虑到相邻前车驾驶人意图的表征参数较少,在构造SVM分类器时,假设3类驾驶人意图两两线性可分,因此,本文在采用SVM算法建立相邻前车驾驶意图预测模型时参数设置如下:SVM的类型设置为SVC,分类时采用“一对一”的分类方法,核函数设置为线性核。
2.2 Fisher判别法
Fisher判别法的基本思想是将原样本数据投影到某个方向,使其投影的类内距离最小而类间距离最大[17-18]。
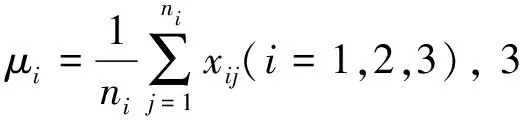
假设投影方向为W=(w1,w2,…,wp),将驾驶人行驶数据样本xij在W上进行投影,得到yij=WTxij(i=1,2,3;j=1,2,…,ni),样本和总体投影后的均值分别为vi=WTμi(i=1,2,3)和v=WTμ。因此,样本投影后的类间离差平方和与类内离差平方和分别为式(3)和式(4),根据Fisher判别法的基本思想,要求投影后的类间距离最大而类内距离最小,即使得式(3)最大,式(4)最小。

(3)
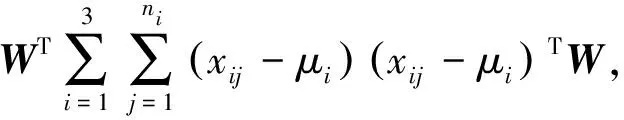
(4)
令
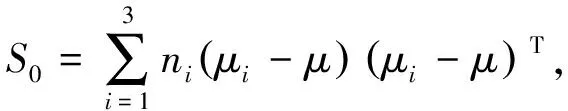
(5)

(6)
则
SSG=WTS0W,
(7)
SSE=WTS1W。
(8)
可将优化条件转化为使式(9)最大。

(9)
令
WTS1W=1,
则
J=WTS0W, s.t.:WTS1W=1。
(10)
采用拉格朗日乘子法进行求解,
L(W,λ)=WTS0W-λ(WTS0W-1),
(11)
dL(W,λ)=(2WTS0-2λWTS1)dW,
(12)
式中:λ为特征值。
令
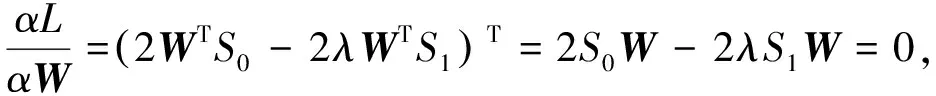
(13)
则
S0W=λS1W,
(14)
当S1可逆时,

(15)
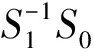
2.3 结果对比
将筛选的第1类、第2类400组驾驶行为数据以及第3类800组驾驶行为数据进行处理,得到自车车速vM、自车与当前车道前车的车头时距t1、自车与当前车道前车的相对速度v1、自车与相邻前车的相对速度v2等4个参数,将数据样本的一半作为训练集,另一半作为测试集,并将训练集作为输入样本,按照相关参数设置进行训练后,建立SVM模型和Fisher判别模型。
Fisher判别模型的判别式有两个
y1=-0.067 3vM+0.924 9t1-0.288 2v1+
0.238 5v2,
(16)
y2=0.005 5vM+0.984 5t1+0.157v1+
0.078 2v2.
(17)
两个正的特征值分别为5.942 2和0.169 9,两个判别式的贡献率分别为0.972 2和0.027 8,累积贡献率为0.972 2和1。根据训练样本中的800组驾驶行为数据,按照判别式得分绘出散点图,如图2 所示。3类驾驶行为意图的分离效果非常好,只是第2类驾驶意图和第3种驾驶意图有个别点混在一起,不易区分。

图2 判别式得分散点图
根据训练样本对800组驾驶行为数据进行判别,可以得到SVM模型和Fisher模型识别结果的分类混淆矩阵,如表1 和表2 所示。

表1 SVM模型对训练集的分类混淆矩阵

表2 Fisher模型对训练集的分类混淆矩阵
由表1 和表2 可知,采用vM,t1,v1,v24个参数建立SVM模型和Fisher模型时,判别准确率均非常高,分别为98.1%和98.3%。此外,SVM模型和Fisher模型对于第3种驾驶意图的识别召回率达到100%,表明这两种模型均能根据由vM,t1,v1,v24个参数构成的驾驶行为数据,100%判别出并道至自车与前车之间的驾驶意图。
利用上述建立的SVM模型和Fisher模型对测试集中的800组驾驶行为数据进行预测,得到对于3类驾驶意图的分类混淆矩阵,如表3 和表4 所示。

表3 SVM模型对测试集的分类混淆矩阵
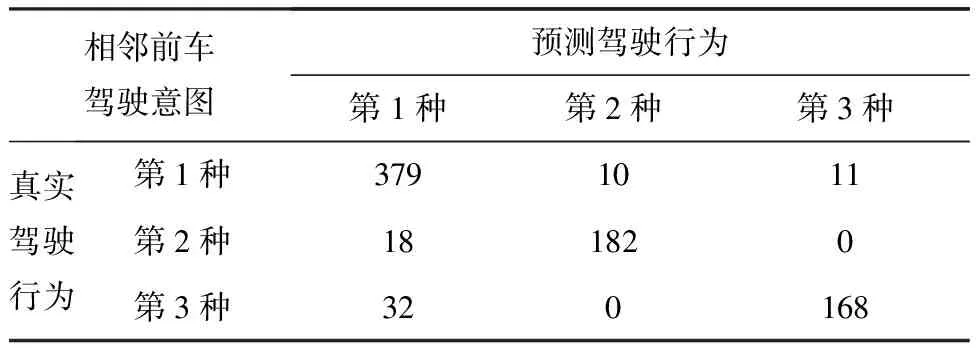
表4 Fisher模型对测试集的分类混淆矩阵
由表3 和表4 可知,SVM模型和Fisher模型对3种驾驶意图的预测准确率分别为94.1%和91.1%。相比Fisher模型,SVM模型对相邻前车的第1类驾驶意图和第2类驾驶意图的召回率和精确率均更高,但是对于相邻前车的第3类驾驶意图的召回率和精确率则略低。
由于相邻前车并道至自车与前车之间时改变了自车的跟车目标,使自车的跟车间距突然减小,对自车的车速影响最大,因此,从对自车的车速控制角度看,Fisher模型能更好地用于相邻前车的驾驶意图预测。
3 结 论
1)根据高速公路试验采集到的自车、自车所在车道以及相邻车道车辆的运动状态参数,获得相邻前车驾驶意图的表征参数,包括自车车速vM、自车与前车的车头时距t1、自车与前车的纵向相对速度v1以及自车与相邻前车的纵向相对速度v2等4个参数。
2)根据上述4个表征参数,采用SVM算法和Fisher判别法对相邻前车的驾驶意图进行建模,得到SVM模型和Fisher模型,其对驾驶意图的预测准确率分别为94.1%和91.1%,能够提前2 s左右预测到相邻前车的并道行为类型,但是Fisher模型在预测相邻前车并道至自车与前车之间的准确率更高。
3)由于相邻前车并道至自车之后的并道情形很少出现,本文在建立相邻前车驾驶意图模型时,未考虑该类驾驶意图,未来可以建立更为全面的相邻前车驾驶意图模型。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
人类工效学(2021年5期)2022-01-15
法律方法(2021年3期)2021-03-16
绥化学院学报(2019年10期)2019-10-12
心理科学进展(2018年8期)2018-02-21
汽车工程(2017年8期)2017-09-15
人民交通(2016年9期)2016-06-01
心理科学进展(2015年5期)2015-02-26
延河(下半月)(2014年3期)2014-02-28
