
基于残差注意和非对称损失的行人属性识别
2023-04-06 04:38胡红梅张丽红
测试技术学报 2023年2期
胡红梅,张丽红
(山西大学 物理电子工程学院,山西 太原 030006)
行人属性识别(Pedestrian Attribute Recognition, PAR)的目的是挖掘给定图像的目标人物属性,如性别、年龄和服装风格等。行人属性可以对行人的外观特征进行精细表征,被广泛应用于智能监控、视频图像检索、行人重识别等诸多领域,具有广阔的市场应用前景[1]。但由于应用场景的不确定性,导致属性复杂样本识别精度较低和属性分布不平衡,行人属性识别面临着巨大的技术挑战。
为了应对这些挑战,早期通常采用传统手工提取特征的方法,如支持向量机(Support Vector Machines, SVM)。近年来,基于深度学习的行人属性识别方法被很多学者深入研究。Liu等[2]提出利用多方向注意力机制模块的网络来定位细粒度的属性并增强行人图像的特征表示;Guo等[3]利用同一图像的不同空间变换之间视觉注意区域一致性的假设,提出用注意一致性损失来获得鲁棒属性定位;受特征金字塔网络的启发,Tang等[4]利用挤压和激发(Squeeze-and-excitation networks, SE)块[5]和空间变压器网络(Spatial Transformer Networks, STN)[6]构建了属性定位模块,以增强属性定位;另外,还有通过挖掘属性间关系的方法,如Wang[7]提出的通过长短期注意力机制将行人属性识别问题转化成为一个序列预测问题,期望挖掘出不同属性间的关系。最近,Tan等[8]也提出使用图卷积网络(Graph Convolutional Network,GCN)来关注属性关系,通过扩展神经网络以使用图结构来处理数据,以捕获属性关系的上下文关系[9]。虽然以上提出的注意力机制或采用GCN的方法提高了属性识别性能,却增加了参数数量,导致图像中行人属性复杂样本识别精度较低和属性目标大小分布不平衡问题并没有得到很好的解决。
为解决上述问题,本文提出一种基于残差注意的行人属性识别网络。该网络以Resnet50[10]作为骨干网络提取出具有语义信息的行人属性特征,采用属性类别残差注意模块(Attribute Category Residual Attention Module, ACRAM)加强对属性所在区域的识别并挖掘不同属性之间的内部联系。同时,对分类器的权值进行归一化并引入一种非对称的损失函数[11]以降低行人属性样本分布不平衡的影响,这种非对称损失能够动态降低权重和容易分类的负样本,丢弃可能错误标记的样本,提高属性识别精度。
1 网络框架
本文提出的基于残差注意的行人属性识别网络整体框架如图1 所示,包括特征提取模块、属性类别残差注意模块和多头注意特征融合模块3部分。首先,特征提取模块采用基于Resnet50的主干网络来提取具有一定语义信息的行人属性特征,将得到的行人属性特征通过1×1卷积解耦成多个不同的子特征,提取出具有空间依赖性和语义相关性的自注意力特征;然后,属性类别残差注意模块可以有效地捕获来自不同属性类别的小对象所占据的不同空间区域,以关注行人属性的关键部分并挖掘不同属性之间的内部联系;最后,特征融合模块将这些多分支的残差注意特征相融合,同时,将融合后的特征输入分类器得到最终的属性预测。为了更好地加快模型的收敛速度,网络中对分类器的权值进行归一化(Batch Normalization, BN)并采用非对称损失函数来降低行人属性样本分布不平衡的影响。

图1 基于残差注意的行人属性识别网络整体框架
2 属性类别残差注意网络结构
属性类别残差注意网络结构主要是通过空间自注意力机制提取分辨率更高的行人属性局部特征。该网络为行人的每个属性类别提取最大池化特征,并结合属性类别未知的平均池化特征加强对属性所在区域的识别和挖掘不同属性类别之间的内部联系,对局部细粒度的行人属性具有更好的识别效果。
在行人属性识别网络图1 中,对于给定的行人图像I,通过一个特征提取骨干网络φ获得特征张量x,其中d,h和w为特征张量x的维数、高度和宽度。
x=φ(I;θ),
(1)
式中:θ是主干网络的超参数。首先,采用Resnet50作为特征提取骨干网络来提取行人的整体特征,输入图像的分辨率为224×224,提取得到2 048×14×14维的特征;然后,将提取到的特征通过全连接层(1×1卷积)变成c×h×w维的子特征,c是属性类别。
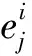
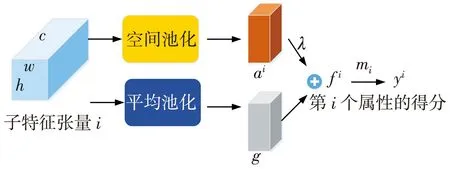
图2 残差注意模块原理框图
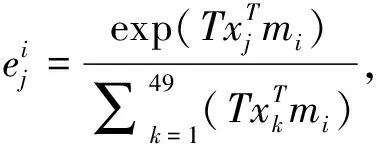
(2)

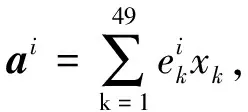
(3)


(4)
实验发现,将g视为主要的特征向量可以取得良好的属性识别效果,ai视为属性类i的残余特征。通过添加这两个向量得到第i个属性类别残差注意特征
fi=g+λai,
(5)
式中:λ是结合全局平均池化和最大池化分数的超参数。以上就是属性类别残差注意模块,它不仅依赖于一个位置的残余特征,还依赖于所有位置的残余特征。直观地说,当输入的行人图像中有多个来自同一个属性类别的小对象时,属性类别残差注意比单独的全局平均池化或者全局最大池化具有明显优势。最后第i个属性的得分yi定义为

(6)
式中:mi∈R2 048是第i类分类器的参数。
3 多头注意力机制
为了避免对控制得分准确性T调参,进一步提出多头注意力机制并将其扩展应用于网络分支。残差注意多个分支采用不同的超参数T,但共享相同λ,注意力分支的数量用H表示,为避免调参,当选择固定参数H=1时即单头注意力机制。除了使用H=1外,本文还使用H=2,4,6和8,具体如下:
当H=2,T1=1和T2=∞;
当H=4,T1∶3=1,2,4和T4=∞;
当H=6,T1∶5=1,2,3,4,5和T6=∞;
当H=8,T1∶7=1,2,3,4,5,6,7和T8=∞.
不同的T值可以给分支带来多样性从而产生更好的识别效果,简而言之超参数T可以不用调参。将不同注意力分支的特征进行融合再输入分类器得到最终的属性识别结果,此过程分别如式(7)和式(8)
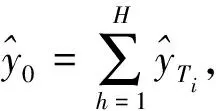
(7)
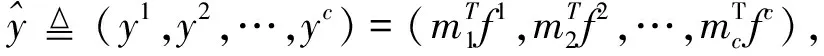
(8)
式中:Ti是第i个注意力头的参数,c是属性数量。为了在训练过程中加快模型的收敛速度,将分类器的权值进行归一化。引入归一化还可以解决以下两个问题:① 归一化操作能够让不同属性识别任务在同一位置的注意力权重保持在相同的尺度上;② 归一化操作得到的注意力权重可以反映出特征空间对于不同属性识别任务的相对重要性。
4 多标签非对称损失函数
损失函数对于多属性分类通常利用二进制交叉熵损失函数来估计预测值和真实值之间的不一致程度[12],定义如下
log(1-pij),
(9)
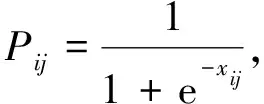
(10)
式中:N表示样本数量;L表示属性数量;yij表示第i个样本第j个属性的真实标签;pij表示第i个样本第j个属性的预测概率;xij表示第i个样本第j个属性。虽然所有属性都被公平地考虑了,但在行人多属性识别中正负样本的比例差异较大,训练网络对小比例的属性识别性能较差。因此,Zhu等[13]采用加权二值交叉熵损失函数对网络模型进行优化,即在二值交叉熵损失函数中引入加权因子来平衡正负样本比例。该损失函数公式为
(1-yij)·log(1-Pij),
(11)
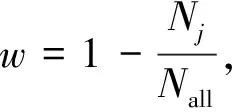
(12)
式中:w为属性负样本占所有样本的比例;Nj为训练集中属性的正样本数;Nall为训练集中训练的属性样本数量。属性正样本和负样本之间的比例不平衡问题虽然被考虑到了,但样本分类难度被忽略了。在训练后期大部分简单样本可以被正确分类,只有少数复杂样本可能被错误分类,但是简单样本占损失函数的大部分,且梯度方向受简单样本影响较大,而简单样本不能提高分类精度。为了解决这一问题,文献[14]引入简单属性和复杂属性的权重,增加损失函数中复杂属性在总体损失函数中的比例,提出了一种适合于多属性分类的焦点损失函数公式如下
e1-w·(1-yij)·Pijr·log(1-Pij),
(13)
式中:r是聚焦参数,其范围设置为0到5。为更好地解决行人属性识别中样本不平衡问题,本文提出了一种适合多属性分类的非对称损失如式(14)。该损失函数引入了额外的非对称机制即概率位移转移如式(15),它对非常容易分类的负样本进行硬阈值化,即当负样本的概率很低时将被完全丢弃。非对称损失在正负样本上具有不同操作能够动态地降低权重和容易分类的负样本,使得优化过程更多地关注正样本,并且还能够丢弃错误标记的负样本以更好地提高属性识别精度。

(14)
Pm=max(Pij-m,0),
(15)
式中:Pm是概率位移转移,r+和r-分别是正聚焦参数和负聚焦参数,m(m≥0)是概率边际可调超参数,加号前面是正损失部分,加号后面是负损失部分。可以看到,概率位移相当于将损失函数向右移动一个因子m,因此,在Pij
5 实验结果及分析
5.1 数据集
本文采用公开PETA[15]数据集和PA100k数据集,部分数据集中的行人样本如图3 所示。其中,PETA数据集的19 000张行人图像主要从不同的室内和室外场景捕获所得,每个行人有61个二值属性和4个多类别属性,包括年龄、性别、发型、携带物、鞋子类型等属性。实验选取了35个相对正负比例平衡的属性进行训练,分辨率范围17×39 到169×365像素不等。实验随机将图像分为训练集9 500张,验证集1 900张,测试集7 600张。

图3 数据集的部分样本
PA100K[2]数据集通过室外监控摄像头捕获所得,是行人属性识别中最大的数据集。此数据集包括10万个行人图像,每张图像具有26个常用二进制属性,属性包括全局属性和局部属性,性别、年龄等特征等为全局属性; 手提包、手机、上装等特征为局部属性。图像分辨率范围为50×100至758×454像素。整个数据集随机被分为3个数据子集进行评估,其中80 000张训练图像,10 000张验证图像和10 000张测试图像。
5.2 评估指标
在实验评估方面,采用了基于标签和基于样本的两种评估准则来衡量模型性能。
1)平均精度(mean accuracy, mA)是基于标签的评估标准,也是属性识别算法中最常用的性能度量指标[16]。针对多属性识别中属性样本不平衡问题,平均精度可以防止网络模型偏向于一些权重比例较高的正样本。具体公式为
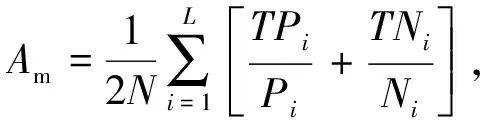
(16)
式中:N表示样本数量;L为属性数量;Pi和TPi分别表示属性的正样本数量和正确识别的正样本数量;Ni和TNi分别表示属性的负样本数量和正确识别的负样本数量。它独立地处理每个属性,而忽略了属性之间的相关性。因此,李等[17]提出了一种基于实例的评价标准,该标准更符合人类对行人属性的预测。
2)准确性(Accuracy, Acc)、精确率(Precision, Prec)、召回率(Recall, Rec)和F1值4种评价指标是基于实例的评价标准。具体定义为

(17)

(18)

(19)
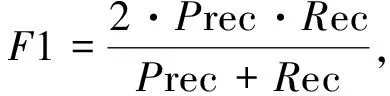
(20)
式中:N表示样本数量;Yi为第i个实例的真实标签;f(xi)为第i个实例的预测标签;|·|表示集合中的属性数。基于实例的评价准则是以每个属性样本实例为单位评估,其中F1指标是精确度和召回率的调和平均,能够综合来评价属性识别能力,在多标签图像分类中具有重要作用。
5.3 实验对比与分析
为有效评估所提出方法的可行性,分别在两个最常用的行人属性数据集PETA和PA100K上进行了实验,表1 和表2 是分别在PETA 数据集和PA100k数据集上本文方法与其他8种基于深度学习的行人属性识别方法的实验结果对比,并突出显示了最好的性能。
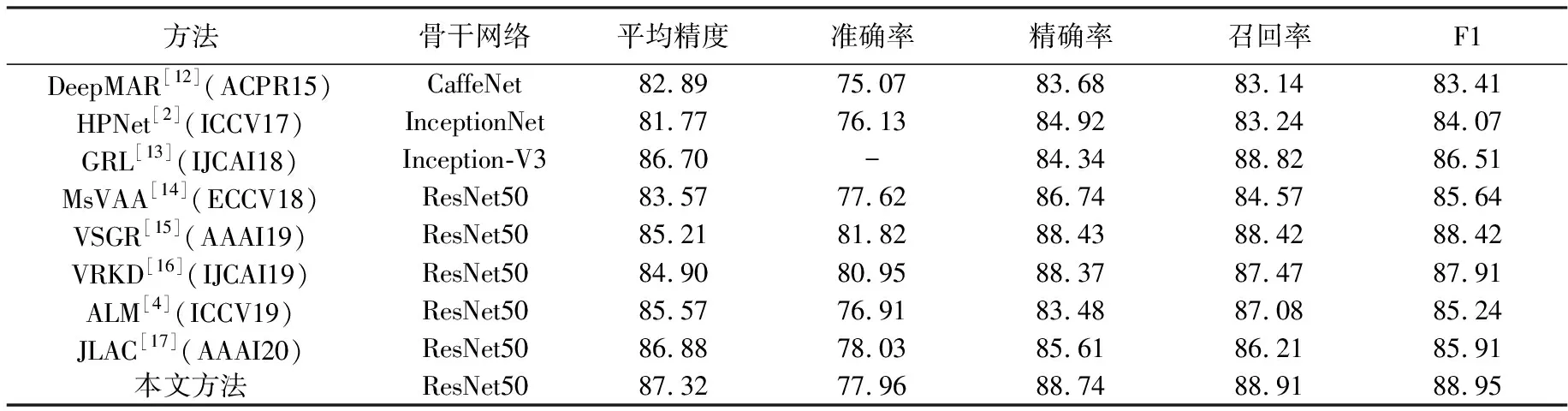
表1 本文模型与其他不同模型在PETA数据集上得到的属性识别性能对比结果

表2 本文模型与其他不同模型在PA100k数据集上得到的属性识别性能对比结果
从表1 看出,本文所提出的方法在PETA数据集上的性能优于其他方法,具体地说在基于标签和3个基于样本的评价指标达到了最高值,识别准确率略低于其他方法,但相对于其他多数方法仍有明显优势,该结果验证了本文模型在行人属性识别任务中的有效性。
表2 是本文模型与其他不同模型在PA100k数据集上得到的属性识别性能对比结果,可以看出,本文方法有3个基于样本的评价指标达到了最高值,其中属性的识别准确率达到80.95%。
表3 和表4 分别是本文模型与不同损失函数结合在PETA和PA100k数据集上的比较结果,引入本文所提出的非对称损失函数后,在各项指标上均有不同程度的提升。这是由于此损失函数可以动态降低权重和容易分类的负样本,同时丢弃可能错误标记的样本,以提高属性识别精度。实验结果表明,本文所提出的非对称损失函数可以有效提升行人属性识别模型的判别能力。

表3 本文模型与不同损失函数结合在PETA数据集上的比较结果

表4 本文模型与不同损失函数结合在PA100k数据集上的比较结果
本实验采用224×224尺寸图像作为骨干网络Resnet50输入,模型的参数更新采用随机梯度下降法(Stochastic Gradient Descent, SGD)实现,网络训练时设置的动量(Momentum)和权值衰减参数(Weight decay)分别为0.9和0.000 5。通过对图片进行随机擦除、随机裁剪、水平翻转和其他操作的数据增强处理,增加各类属性样本的数量以提升网络的泛化能力。在训练时输入图片的批量大小为64,可训练的迭代次数为30,学习率为0.01。本文方法在PETA数据集和PA100k数据集上训练的总损失函数曲线如图4 所示,从图中可以看出,随着迭代次数增加,模型趋近收敛。由于网络对具有不同学习难度及收敛速度的属性赋予不同的权重,缓解了行人属性识别任务的负迁移问题,因此,本文方法在行人属性识别方法中具有明显优势。
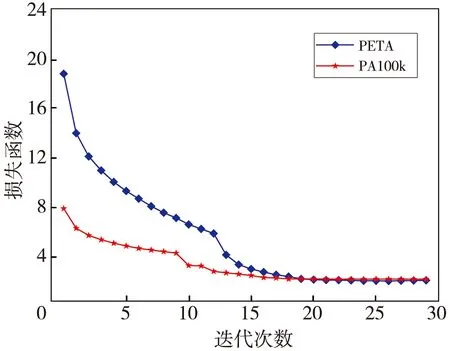
图4 损失函数曲线
5.4 属性识别可视化
为了进一步验证本文方法的有效性,从测试数据集中选取了不同视角和场景下单个行人样本进行实验,属性识别结果如图5 所示,每个行人图像右侧是其对应的属性预测结果,其中横线下半部分蓝色标注的为小目标细粒度属性识别。从图5 可以看出,行人正面比背面的属性信息更为丰富全面,且一些行人小目标属性也能检测出来,如围巾、眼镜属性均被检测出来。综上所述,本文方法可以有效提高属性识别准确率。

图5 可视化效果
6 结束语
本文提出了一种基于Resnet50和属性类别的残差注意力机制相结合的行人属性识别方法。该方法为行人的每个属性类别提取最大池化特征,将其与属性类别未知的平均池化特征相结合,能够关注属性存在的关键区域并挖掘不同属性类别之间的内部联系;其次,本文还引入了一种新的非对称损失,这种损失可以动态地降低权重和容易分类的负样本,同时丢弃可能错误标记的样本,以提高识别精度和收敛速度。属性类别残差注意网络结构简单也容易实现,并且没有引入额外的训练数据,通过实验,验证了本文方法的合理性和有效性。在两个行人属性数据集上,实验结果表明,本文的方法较于其他方法具有明显优势。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
意林(2021年5期)2021-04-18
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
新校长(2016年8期)2016-01-10
河南科技(2015年8期)2015-03-11
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
