
融合时序和空间特征的车辆异常轨迹检测方法
2023-05-05 03:00张安洁
重庆邮电大学学报(自然科学版) 2023年2期
夏 英,张安洁
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
近年来,大量研究人员致力于研究如何处理轨迹数据并使其服务于智能交通、智慧城市等领域[1-3]。基于度量的方法主要根据轨迹段之间的距离进行异常检测。文献[4]提出基于Hausdorff距离进行轨迹划分的异常轨迹检测框架。文献[5]在聚类基础上建立基于离散状态的路径模型。文献[6]结合有向Hausdorff距离进行异常检测,考虑方向差的同时降低计算复杂度。基于度量的方法主要考虑轨迹的距离特征,对轨迹的序列信息考虑不足。
基于统计的方法主要依赖历史数据的支持。文献[7]通过计算网格序列频度来检测异常轨迹。文献[8]提出一种两阶段轨迹异常检测框架,解决寻找局部异常轨迹和绕行问题。文献[9]在网格序列基础上提出新的DIS距离计算轨迹之间的相似度。这类方法未充分考虑到历史数据少、数据规模大等情形。
基于学习的方法主要利用序列建模。文献[10]提出的XGBoost方案是经典的分类算法;文献[11]基于循环神经网络,采用轨迹嵌入捕捉轨迹序列信息;文献[12]基于行驶时间和距离的循环神经网络实现异常检测;文献[13]结合循环神经网络和卷积神经网络检测异常轨迹。基于学习的方法目前较为主流,但循环神经网络存在长距离依赖问题,无法长久记忆。对网格化轨迹进行序列建模仅提取轨迹时序特征,难以充分提取轨迹空间特征,如轨迹偏转角度、行驶距离等[11]。
为充分利用轨迹数据的时空特征,本文提出融合时序和空间特征的车辆异常轨迹检测方法(vehicle abnormal trajectory detection method based on fusing temporal and spatial features, ATD-TS)。该方法具有以下特点:①在编码器部分引入自注意力机制(stacked sequence auto-encoder with self-attention, SSA),解决传统循环神经网络的长序列依赖问题,充分提取轨迹时序特征;②提取轨迹偏转量和行驶距离,并使用全连接神经网络进行特征提取(full connected network with deflection and driving-distance, FDD),以此挖掘轨迹中更多空间信息。
1 相关基础
1.1 原始轨迹
原始轨迹T={p1,p2,…,pn}是记录位置信息的时间序列[14],位置点pi由(loni,lati,ti)表示,其中(loni,lati)是位置经纬度,ti是对应的时间戳。p1和pn是原始轨迹的起点和终点。
1.2 映射轨迹
根据原始轨迹经纬度的空间范围,将空间区域分割成相同大小的网格grid[14],建立网格与原始轨迹点的对应关系,将原始轨迹T={p1,p2,…,pn}映射为tr={grid1,grid2,…,gridn}。
1.3 异常轨迹
在出租车、物流等特定应用场景下,车辆移动轨迹会有预设的正常路径,通过这些路径的概率相对较高,异常轨迹产生的原因可能是主观上的(如绕路行为)或客观上的(如道路拥堵等)。
1.4 行驶距离
已知轨迹起点p1和终点pn,p1和pn的行驶距离s表示为[15]
(1)
(1)式中,dist(pi,pi+1)表示相邻两点之间的空间距离。
1.5 轨迹偏转角
偏转角[16]是相邻两个轨迹运动方向上的夹角。已知由p1、p2、p3这3个点构成的夹角称为开放角θ,开放角的补角称为偏转角β,偏转角与开放角如图1所示。偏转角越大表明运动发生偏转程度越大。β和θ的计算式为
(2)
θ=π-β
(3)

图1 轨迹偏转角与开放角Fig.1 Trajectory deflection angle and opening angle
1.6 轨迹偏转量
轨迹偏转量为轨迹偏转角度的和,计算公式为
(4)
(4)式中:βk表示第k个相邻两轨迹运动方向上的夹角,即轨迹偏转角;n表示一条轨迹有n个偏转角。
2 ATD-TS方法设计
2.1 总体框架
ATD-TS总体框架分为轨迹预处理、轨迹特征提取和异常检测3个组成部分,如图2所示。轨迹预处理将原始轨迹转换为映射轨迹,同时提取轨迹偏转量和轨迹行驶距离;轨迹特征提取在编码器(Encoder)每层引入SSA,构建融合SSA的堆叠序列自编码器模型以提取轨迹偏转量和轨迹行驶距离等空间特征;异常检测融合轨迹偏转量、轨迹行驶距离和轨迹时序特征,输入到多层感知机(multilayer perceptron, MLP)降维后输入softmax层计算轨迹的异常概率,进而对轨迹进行异常检测。
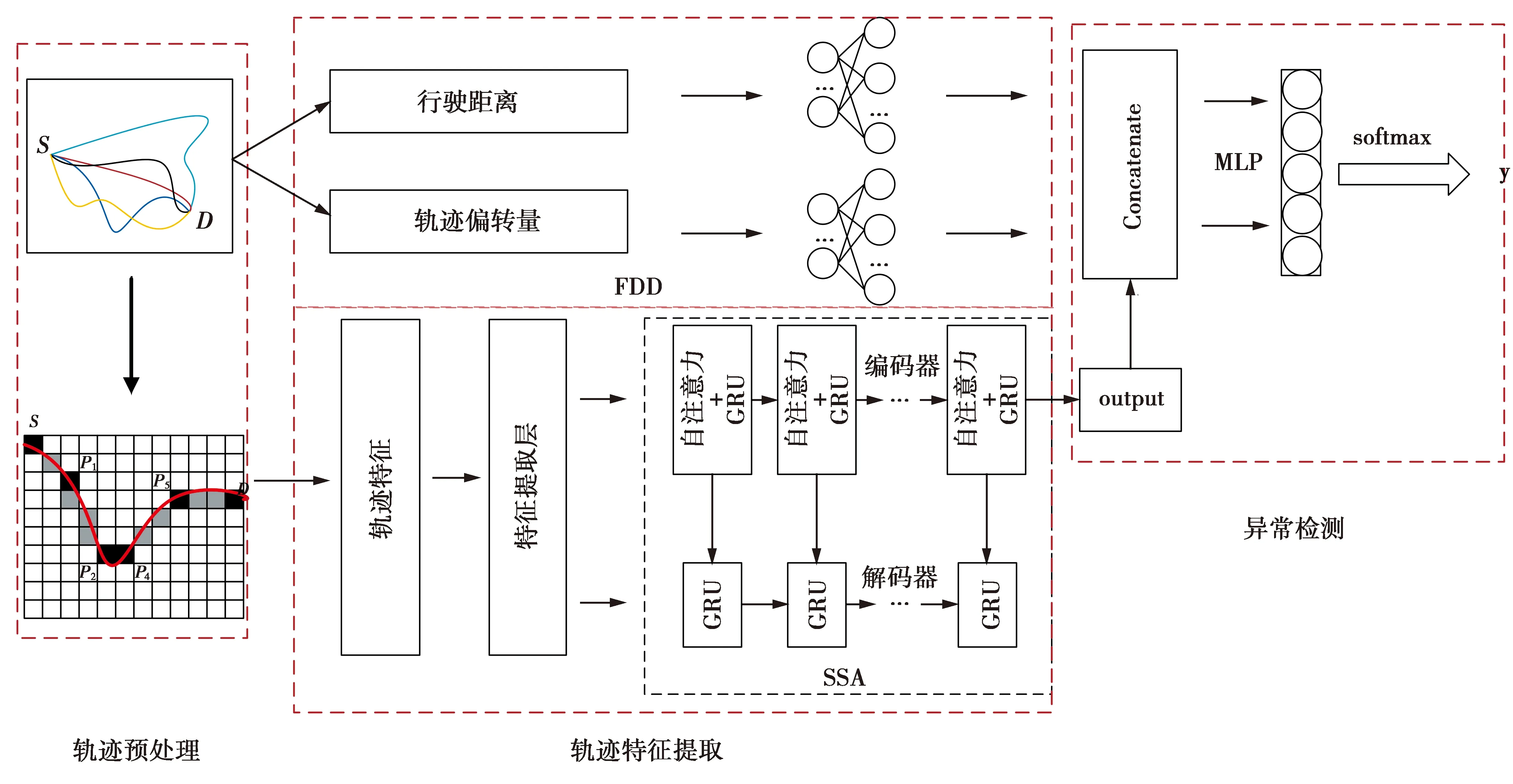
图2 车辆异常轨迹检测总体框架Fig.2 Overall framework of vehicle abnormal trajectory detection
2.2 融合自注意力机制的堆叠序列自编码器模型构建
车辆轨迹数据相邻点有着上下文关系,本文引入自注意力机制结合堆叠的序列自编码器来自适应学习。图3为融合自注意力机制的堆叠序列自编码器示意图。图4为门控循环单元(gate recurrent unit,GRU)结合自注意力机制示意图。
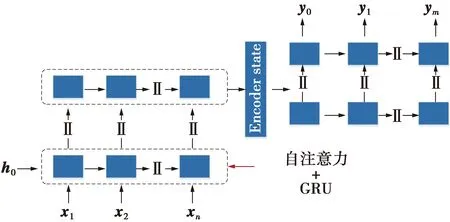
图3 融合自注意力机制的堆叠序列自编码器Fig.3 Stacked sequence auto-encoder fusing self-attention
2.2.1 堆叠序列自编码器
为充分提取轨迹时序特征,采用GRU作为基础单元构建堆叠序列自编码器,其结构如图5所示[17]。堆叠序列自编码器通过编解码过程提高特征提取能力。

图4 GRU结合自注意力机制Fig.4 GRU combined with self-attention
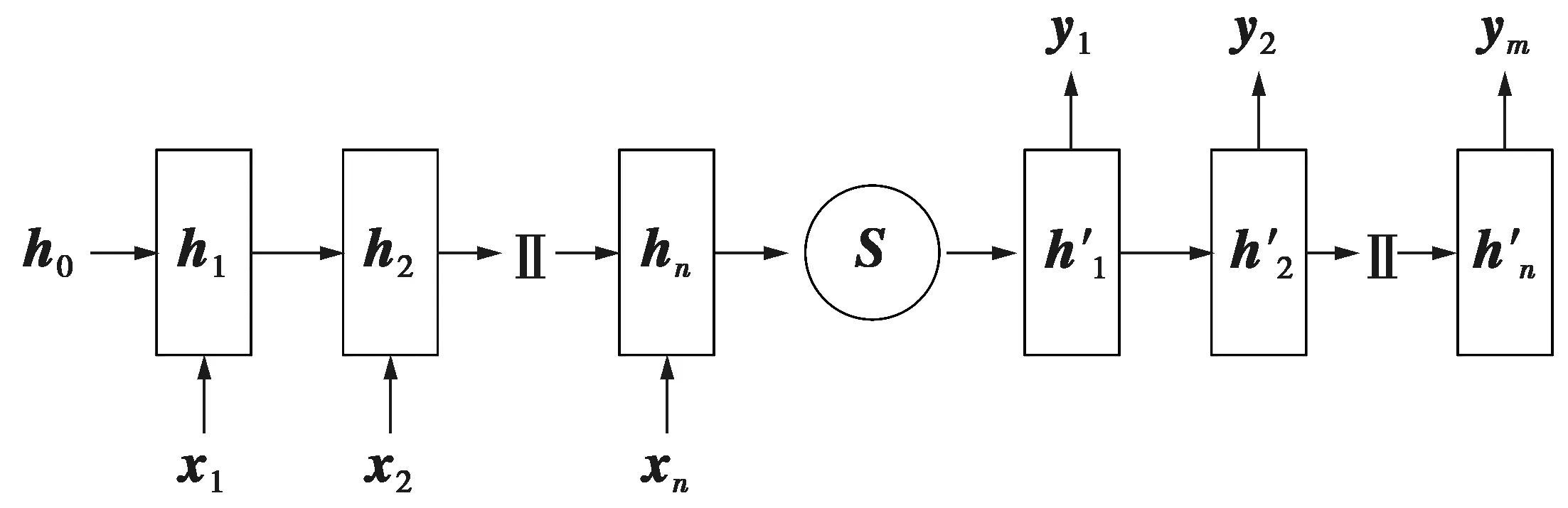
图5 序列自编码器网络结构Fig.5 Network structure of sequence auto-encoder
假设GRUEncoder(·)是编码函数,GRUDecoder(·)是解码函数,对每个时间步骤t、输入xt,轨迹序列编码表示为
ht=GRUEncoder(xt,ht-1)
(5)
获取编码后得到语义向量S,并由解码器解码得
S=f(h1,h2,…,hn)
(6)
(7)
(6)式中:语义向量S作为解码器的初始隐藏状态,并不作用于之后的时刻;f(·)是从编码器隐藏层中总结信息并为解码器生成上下文向量的函数。
单层序列自编码器虽能学习轨迹的上下文关系,但对于轨迹数据更为抽象的内在特征的提取较欠缺,为进一步提高特征提取能力,本文将图3和图4所示结构扩展为四层堆叠序列自编码器,原始数据作为最底层的输入,每一层的输入都是上一层的输出,使用dropout机制避免过拟合问题。
在四层堆叠序列自编码器中,使用局部无监督准则对每一层进行预训练操作,优化堆叠序列自编码器以提高后续分类性能,预训练目标函数为
(8)
(8)式中:n为批量样本个数;xt为输入数据;yt为解码器的拟合分布。利用上述预训练好的编码器对轨迹数据进行特征提取,编码器最后一层输出则可作为最终的时序特征。
2.2.2 自注意力机制
自注意力机制的核心就是在不依靠外来信息的情况下根据输入数据自适应选择最相关的特征[18]。在堆叠序列自编码器的每一层引入自注意力机制,上一层编码器的输出作为自注意力机制的输入,得到的特征向量作为下一层编码器的输入,编码器的输出状态H为
H=(h1,h2,…,hn)
(9)
(9)式中,ht表示t时刻编码状态。注意力向量a的计算公式为
a=softmax(Ws2tanh(Ws1HT))
(10)
(10)式中:向量a的每一个元素代表一个概率;Ws1∈Rda×u以及Ws2∈Rda是可学习参数,da是一个超参数。将H的每个元素与a中对应的元素相乘后相加得到最终的编码状态A为
A=aH
(11)
将编码状态A与输出状态H对应相加以进行特征融合,得到下一层的输入H′,最终堆叠序列自编码器中编码公式可更新为
(12)
2.3 结合偏转量和行驶距离的特征模型构建
在具有相同起点与终点的轨迹中,正常行驶的车辆其轨迹偏转量及行驶距离等特征往往在一定范围内具有一定的相似性。图6为行驶距离实例,图7为偏转角度实例。当发生异常行为时,轨迹行驶距离及偏转角度通常与正常轨迹具有较大差异。正常轨迹的偏转量远低于异常轨迹的偏转量,轨迹偏转量也是异常轨迹检测的一个重要依据。因此,为进一步提高车辆异常轨迹的检测效果,提取轨迹偏转量和轨迹行驶距离特征作为参考指标。
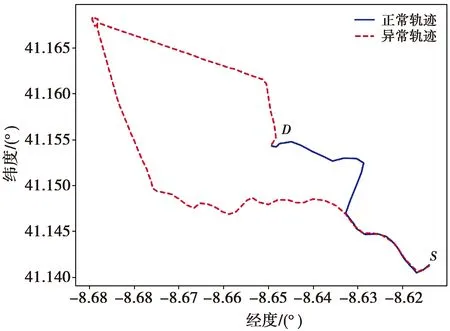
图6 行驶距离实例Fig.6 Driving-distance example
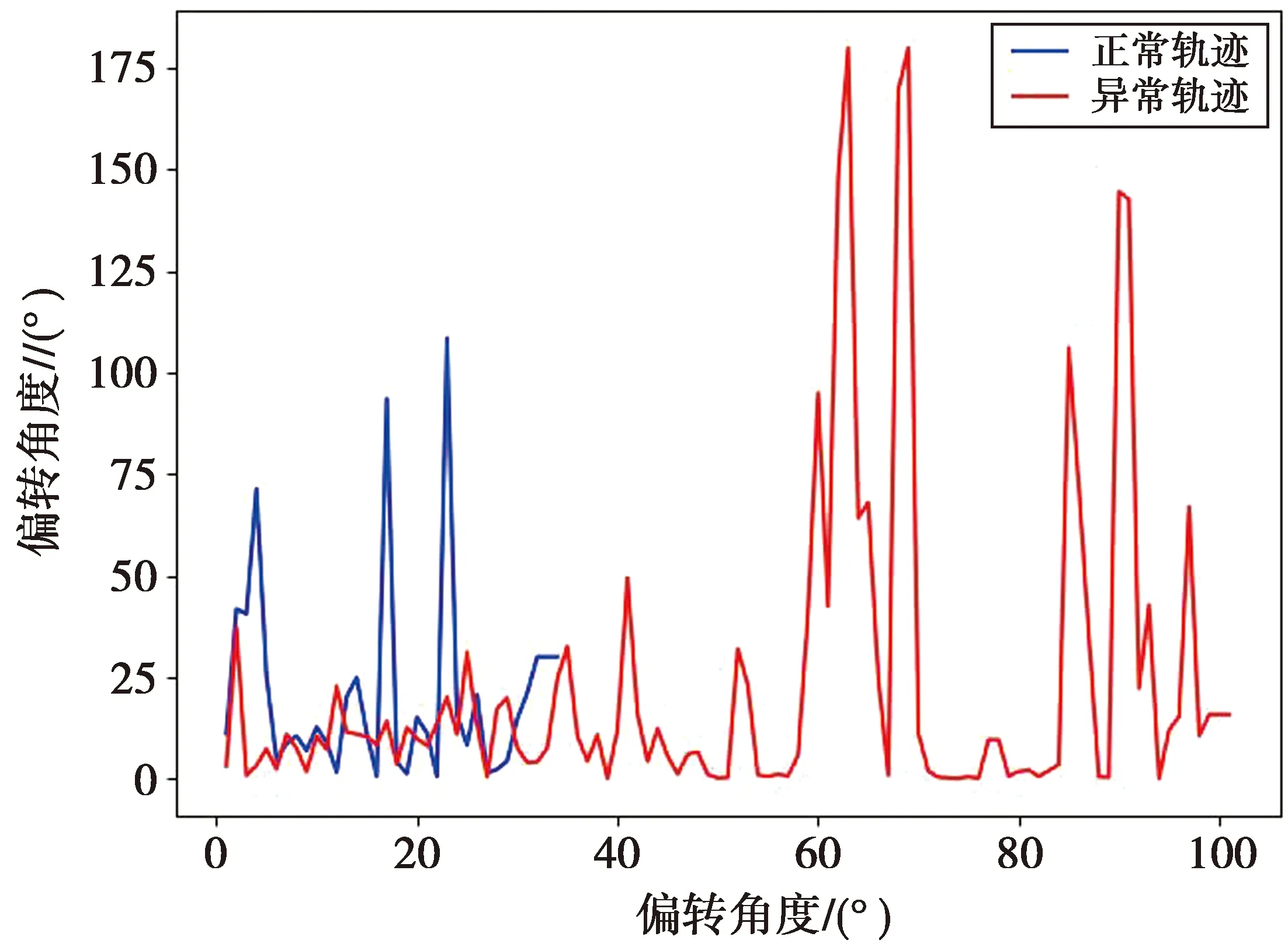
图7 偏转角度实例Fig.7 Deflection example
轨迹行驶距离为轨迹中相邻两点的空间距离之和,Haversine方法[19]能够有效减少相邻两点之间的短距离求解误差,其满足的关系为
cos(φ1)·cos(φ2)·hav(σ2-σ1)
(13)
(13)式中:R为地球半径;φ1和φ2分别表示pi和pi+1的纬度;σ1和σ2分别表示pi和pi+1的经度。
全连接神经网络作为特征提取网络,包含输入层、隐藏层和输出层。将轨迹偏转量和行驶距离作为输入数据分别输入到两个全连接神经网络中,通过隐藏层进行训练得到最终的轨迹偏转量和行驶距离等特征。假设输入特征向量为x,输出为y,则计算公式为
z=Wx+b
(14)
y=f(z)
(15)
(16)
(14)—(16)式中:z为未激活的输出;W和b为可学习参数;f(·)为非线性的激活函数sigmod。
2.4 异常检测
经过特征提取阶段,原始轨迹被表示为一个融合后的特征序列。异常轨迹标号为1(正类),正常轨迹标号为0(负类)。为有效检测异常,利用多层感知机实现特征降维,降维公式为
Mi=σ(Wi·Ei+bi)
(17)
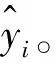
(18)
3 实验与分析
3.1 数据集
实验采用葡萄牙波尔图市的出租车轨迹数据集,包含442辆出租车在2013年1月到2014年6月的轨迹数据,每辆出租车每隔15 s报告其位置。为与传统的异常轨迹检测方法进行对比,在给定源-目的地对(SDPair)之间进行对比试验,抽取5对含有充分轨迹的SDPair。本文采用文献[20]中的方法,每对SDPair包含5%左右的异常轨迹,具体数据描述如表1所示。实验按8∶1∶1划分训练集、验证集与测试集,对原始轨迹进行网格划分,网格大小为100 m×100 m,然后利用唯一标识标记网格,建立网格与原始轨迹点的一一对应关系。

表1 SDPair的轨迹数据信息
3.2 对比方法及参数设置
为验证所提方法的有效性,将本文方法与XGBoost[10]、IBAT[7]、ATDC[9]等方法进行比较。实验在64位Ubuntu18.04操作系统下的Intel Xeon W-2133@3.6GHz CPU上进行,使用Tensorflow框架和python3.6完成神经网络的搭建,堆叠序列自编码器的层数设置为4,词向量降维之后的向量维度为64, dropout机制比例为0.5,神经网络模型优化器为Adam。
3.3 评价指标
实验选用准确率(Accuracy, ACC)及F1评分(F1-score)作为实验定量评估指标,其定义式为
(19)
(20)
(21)
(22)
(19)—(22)式中:P为精确率,表示正确预测为正的占全部预测为正的比例;R为召回率,表示正确预测为正的占全部实际为正的比例;F1为对P与R的综合评估。
3.4 实验结果分析
实验均在同一实验环境下进行,且均选用最优结果。ATD-TS方法与XGBoost、IBAT、ATDC、ATD-LSTM和ATD-GRU 5种异常轨迹检测方法的异常检测效果如表2所示。从表2可知,本文提出的ATD-TS方法无论是在准确率还是F1评分上均有所提升。这表明在捕捉轨迹序列信息的同时,结合轨迹的偏转量和行驶距离信息能够有效提高异常轨迹检测质量。XGBoost方法表现较差的原因是该方法只考虑到轨迹的形状,对于轨迹的序列信息考虑不全;基于统计的IBAT方法优于ATDC方法,原因是使用DIS距离度量的ATDC方法对于异常阈值的选择具有较高要求,在不同数据集上该方法的共通性较弱;同为深度学习的ATD-GRU方法优于ATD-LSTM方法,原因是在同样的参数设置下,GRU捕获时序特征的能力优于长短时记忆单元LSTM。
为验证不同模块对车辆异常轨迹检测的效果,使用ATD-SAE_att表示仅使用融合自注意力机制的堆叠序列自编码器进行异常轨迹检测的方法,ATD-TS在ATD-SAE_att的基础上融合了轨迹偏转量和轨迹行驶距离等空间特征。在参数设置相同的条件下,ATD-GRU表示仅使用门控GRU的方法。ATD-GRU、ATD-SAE_att、ATD-TS 3种方法的消融实验结果如表3所示。

表3 消融实验结果
使用柱形图直观分析ATD-GRU、ATD-SAE_att、ATD-TS 3种方法的准确率和F1评分,结果如图8—图9所示。ATD-SAE_att与ATD-GRU比较,准确率和F1评分均有一定程度提升,SDPair1、4、5检测效果提升更为明显。这是由于SDPair1、4、5比SDPari2、3数据量更大,使得注意力向量和自编码器得到了更加充分的训练。在融合轨迹偏转量和行驶距离之后,与ATD-SAE_att方法相比,ATD-TS又有不同程度的提升,尤其在SDPair1、2、3上提升效果明显,这表明在数据较少时,结合轨迹偏转量和行驶距离信息可有效提高模型性能。
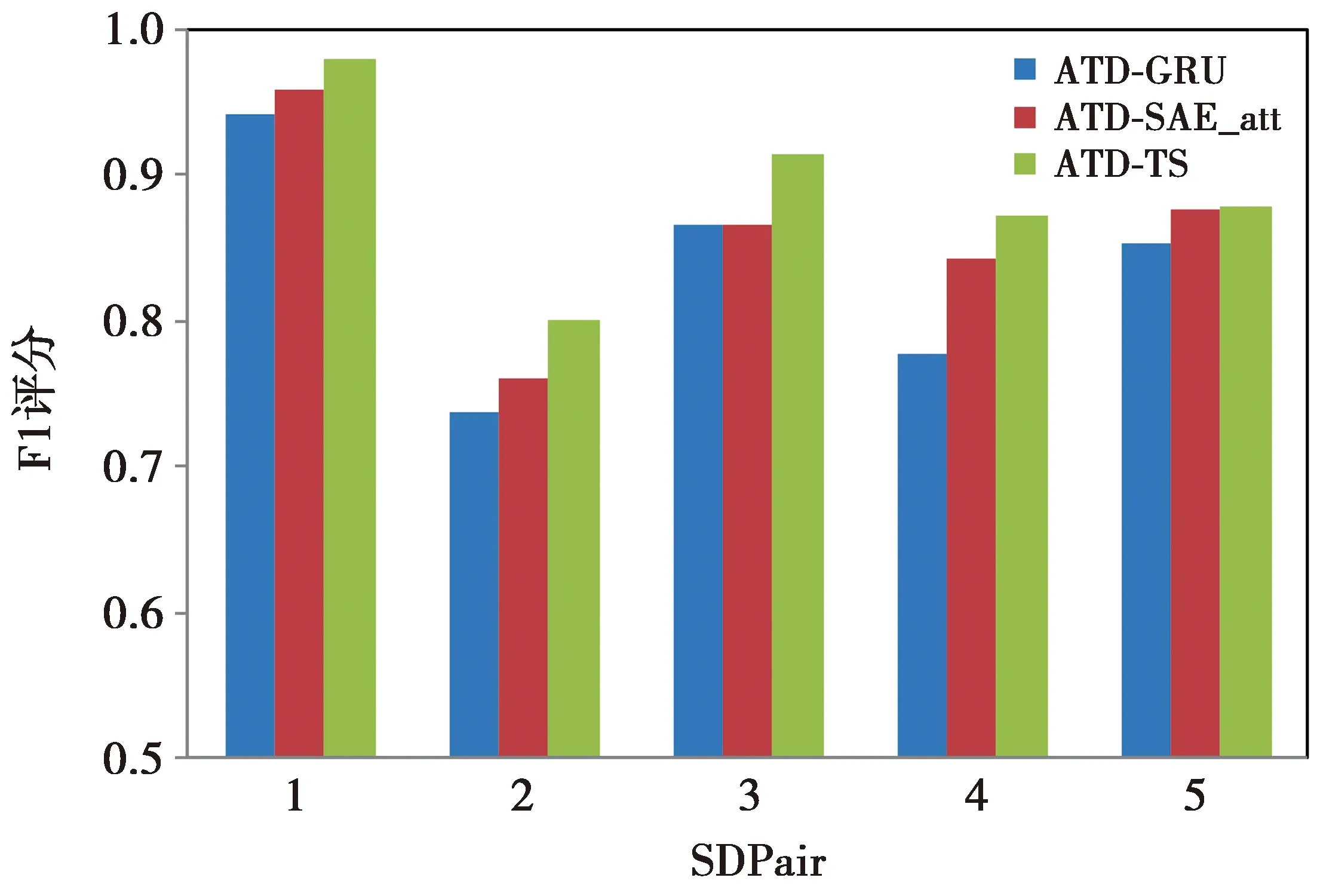
图9 异常检测F1评分Fig.9 Abnormal detection F1 score
为研究轨迹数据中异常轨迹比例较低时算法的有效性,对于实验中选取的5个给定异常轨迹标签的SDPair对,分别设置数据集的异常比例从1%、3%到5%变化,即给定一个数据集,其中正常轨迹数据量不变,异常轨迹的比例按1%、3%和5%抽样,然后重新组合训练集、验证集和测试集。为验证不同情况下的性能,实验采用提出的ATD-TS方法,并使用相同参数,不同异常比例检测结果如表4所示。当异常轨迹的比例从低到高变化时,算法模型的性能也在稳步提升,并且当异常轨迹的比例为1%时,与表2相比,除SDPair5和SDPair3的准确率和F1评分受异常比例影响较大外,其余数据集的检测性能均优于对比算法。这表明即使面对异常轨迹数据比例降低的问题,本文提出的ATD-TS方法仍具有一定优势。
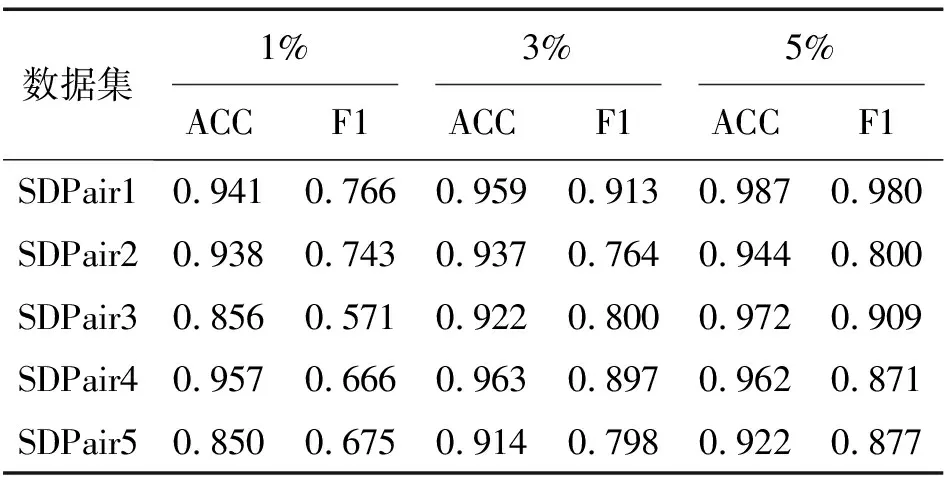
表4 不同异常比例检测结果
4 结束语
本文提出了一种融合时序和空间特征的车辆异常轨迹检测方法,能有效增强轨迹的时空特征提取能力,提高异常轨迹检测性能。在特征提取部分,构建融合自注意力机制的堆叠序列自编码器,提高网格化轨迹时序特征的提取能力,引入全连接网络提取轨迹偏转量和行驶距离等空间特征,最后融合时空特征实现车辆轨迹异常检测。本文ATD-TS方法无论是在数据量较少还是较大的情况下,都具有较高的准确率和F1评分。 未来将考虑结合瞬时速度、加速度等更多运动特征,提升复杂场景下异常轨迹检测准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
电子制作(2018年19期)2018-11-14
成都信息工程大学学报(2018年3期)2018-08-29
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
电子设计工程(2017年20期)2017-02-10
第二课堂(课外活动版)(2016年2期)2016-10-21
电子器件(2015年5期)2015-12-29
噪声与振动控制(2015年4期)2015-01-01
电测与仪表(2014年13期)2014-04-04
