
基于应变能的砂土液化势BP神经网络模型评估
2023-05-08 09:27胡记磊沈文翔NIMAPirhadi万旭升路建国
三峡大学学报(自然科学版) 2023年3期
胡记磊 王 璟 沈文翔 NIMA Pirhadi 万旭升 路建国
(1.三峡库区地质灾害教育部重点实验室(三峡大学),湖北 宜昌 443002;2.三峡大学 土木与建筑学院,湖北 宜昌 443002;3.西南石油大学 土木工程与测绘学院,成都 610500)
地震作用下,当饱和土体中的超孔隙水压力增长到一定程度时,土体由固态转变成悬浮态,从而引起土体发生液化[1].全世界破坏规模最大的地震,均出现了饱和松散或中密等砂土发生液化的现象.由地震引发的砂土液化对人类财产和生命安全存在着巨大的威胁,因此,对砂土抗液化性能的研究十分必要.
常用于评价砂土液化势的方法有3种.首先是由Seed等[2]提出的抗液化剪应力法.此外,Dobry[3]发现砂土中孔隙水压力的发展完全依赖于剪切应变,为此提出了基于应变的评估法.第3种方法是基于能量耗散提出的能量判别法[4-10].此方法通过研究土体初始参数和土体液化所需能量之间的关系来进行砂土液化势评估.与前两种方法相比,能量法同时考虑了应力和应变,其方法计算简单,尤其是对分析复杂的振动情况时更能体现它的优越性.
人工神经网络(artificial neural network,ANN)方法由于在处理非线性问题上的优势,因此基于能量判别法构建的ANN 液化判别模型具有良好性能.Baziar等[8]提出了新的基于多元线性回归的关系,强调了开发ANN 模型的必要性.Chen等[11]提出了一种基于地震波能量的方法,采用反向传播神经网络来评估液化势.Zhang等[12]基于302组室内试验数据,利用多元自适应回归样条方法(multivariate adaptive regression splines,MARS)建立了液化过程中地震能量耗散与土体初始参数之间的回归模型.Javdanian[13]也基于大量循环试验和离心机试验数据,通过神经模糊数据分组算法建立了土体液化应变能与密实度等土体参数的关系式.
在使用ANN 方法进行液化势评估时,初始参数中的土体细粒含量Fc值的大小对液化势评估结果的影响尚不清楚.Zhang等[12]通过实验室测试证明了液化势与Fc值密切相关.Liu等[14]通过对海洋沉积物进行实验测试提出了用Fc的临界值来评估液化势.此外,Maurer等[15]通过分析2010-2011年坎特伯雷地震的7000个案例历史发现,当土体中的Fc值较高时,液化评估结果的可靠性反而较弱.同样Tao[16]通过实验室测试结果证明了当Fc的值高于28%时,Fc值对砂土液化势的影响也随之减弱.但是目前已有的基于能量判别法构建的砂土液化判别模型中并未考虑Fc临界值的影响,仍然使用细粒含量Fc的全部范围值进行模型构建,这可能会对模型的精度产生一定的影响.
此外,岩土工程存在参数不确定性,考虑不确定性更加符合工程实际.可靠性方法在处理和量化参数不确定性上具有绝对的优势.其中,响应面法作为一种非线性系统可靠性分析方法,通过近似构造一个具有明确表达形式的多项式来表达隐式功能函数,其优点在于通过这种方法可以寻找在考虑了输入变量值的变异或不确定性之后的最佳响应值[17].但是,常用的二次多项式响应面法不能模拟高度非线性现象,如砂土液化问题,而ANN 响应面法可以很好地解决高阶非线性问题[18].此外,蒙特卡罗模拟(Monte Carlo simulation,MCS)作为定量分析中风险评估的经典方法,也常被应用于液化势评估.响应面法计算速度快,但需要足够多的输入变量数据,因此本文将MCS方法与ANN 响应面法相结合,从而实现大批量采样,可以对参数快速进行敏感性分析[19],以此探究参数不确定性对液化势的影响程度.
本文使用了两个数据集来研究Fc值范围对基于能量耗散提出的ANN 液化势评估模型的影响,并通过基于蒙特卡罗模拟MCS的ANN 响应面敏感性分析讨论了参数不确定性对砂土抗液化能力的作用.
1 研究方法
1.1 基于能量判别法的判别模型
许多研究者基于能量概念根据实验室测试结果对砂土液化势评估方法进行了深入地研究.Figueroa等[20]提出了两个方程用来评估循环三轴试验中的单位能量(E).凯斯西储大学在基于能量的液化评估问题上进行了广泛的研究[6,21],他们基于试验结果,提出了土体应变能W、应变幅γ与土体初始参数σ'c和Dr之间的关系.在构建模型时,通常采用W的对数形式,即lgW.本质上来说,这两种形式都代表应变能,将W取对数仅仅是由于统计学原理,对数化之后使计算变得更加简便.Hossein 等[22]使用遗传编程(Genetic Programming,GP)、线性遗传编程(Linear Genetic Programming,LGP)和多表达式编程(Multi Expression Programming,MEP)3 种方法开发了基于能量判别法来进行砂土液化势评估的方程,具体形式如下:
基于GP开发的方程:
基于LGP开发的方程:
基于MEP开发的方程:
Zhang等[12]使用与Baziar等[8]相同的5个输入参数开发了一个MARS模型来评估lgW.其方程如下所示:
式中的参数表达式参见文献[12].
1.2 BP神经网络
ANN 是一种强大的数据统计处理,已被用于许多复杂的岩土工程问题.砂土液化的影响因素很多,且各影响与砂土液化势之间存在高度的非线性关系,在液化势判别中使用传统的经验法误差较大[23].ANN 在处理多元非线性问题上的独特优势使其更适用于砂土液化问题.
尽管目前有多种神经网络模型,但Back Propagation(BP)神经网络是最有能力和最常用的,它具有较好的容量和能力以高精度逼近任何函数[24].BP神经网络首先需要构建一个多层感知器(Multilayer Layer Perceptron,MLP)模型,该模型结构包括输入层,两个或两个以上的隐含层以及输出层.其次,利用BP算法对已经构建的MLP 模型进行训练.BP 算法由正向传播和反向传播组成.正向传播时,输入向量从输入层传递到隐含层,再传向输出层.对于输入向量x=(x1,x2,…,x m),输出向量y=(y1,y2,…,y p)可以通过式(5)计算:
式中:m是输入单元的数量;k是隐藏层的神经元个数;p是输出单元的数量;x i是第i个输入单元;w hi是输入单元i和隐藏神经元h之间的权重;w jh是隐藏神经元h和输出神经元j之间的权重;w ho是神经元h的阈值(或偏差);w jo是神经元j的阈值;fhidden是隐藏层的传递函数;foutput是输出层的传递函数.
如果网络在输出层不能得到期望的结果,将进入反向传播过程.误差反向传播阶段主要有两个步骤.首先在模型学习中将通过训练样本学习得到的预测值与样本期望值进行对比,并通过式(6)计算其误差值.其次将正向传播中产生的误差在网络中反向传播,并通过式(7)生成权值修正量.如此反复迭代,当误差收敛到期望精度时,模型完成预测.
式中:E(w)为整体误差函数和y j分别表示第j个训练样本的期望输出值和实际输出值;ΔW kj为平均权值修正量;η为学习率;∂E为每一步误差的偏积分;∂W kj为每一步权值修正量的偏积分.
在使用能量法构建BP 神经网络来评价砂土液化势时,首先是构建多层感知器,与应变能相关的土体参数等变量作为输入层,应变能作为输出层,隐含层的层数由精度最高的模型决定.其次,利用BP 算法进行模型的学习,最后生成用于评价砂土液化势的BP神经网络模型.
2 实验设计和建模
2.1 数据集与模型构建
根据实验室测试结果,包括、Dr、Fc、Cu、D50与曲率系数(Cc)6个参数被认为是基于应变能概念估算砂土抗液化能力建模中影响最大的因素[6,8-9,16,22,25-27].
本文使用两个数据集构建了两个ANN 模型.第一个数据集包含403 个样本,其中284 个样本为Baziar等[8]的实验数据.为了更好体现模型性能,将数据集分为3 组,其中包括测试集(60 个)、验证集(60个)和训练集(283个).在每个数据集样本的选择上,考虑数据本身统计特征之后进行随机抽样.3组数据集的统计特征见表1~4.第二个数据集包含309个样本,由第一个数据集中Fc值低于28%的样本构成.其中,大约15%的样本(44个样本)被选中用于测试,等量样本用于验证,以及221个样本用于训练模型,抽样方式与第一个数据集相同.由于篇幅限制,第二个数据集的数据统计特征不在此多做赘述.

表1 第一个数据集所有数据的统计特征
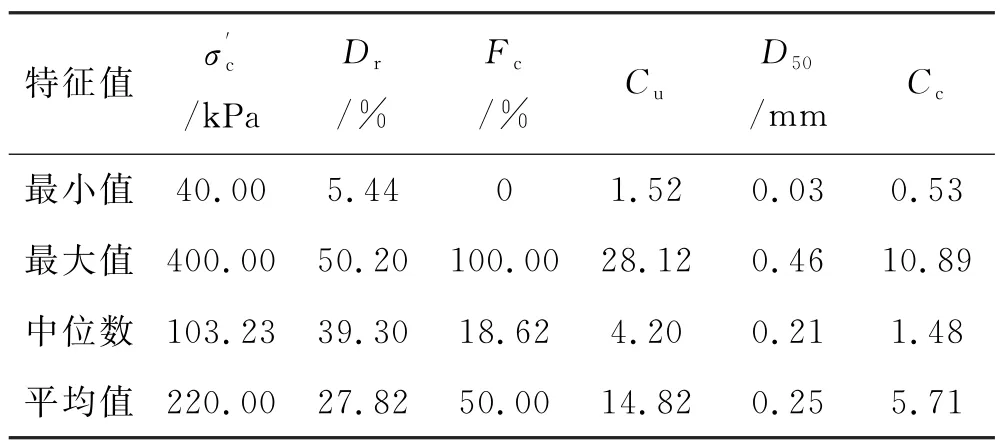
表2 数据集1中抽取的训练集的统计特征

表3 数据集1中抽取的验证集的统计特征

表4 数据集1中抽取的测试集的统计特征
MLP模型主要包括输入层、隐含层以及输出层3个部分.利用上述两个数据集分别进行神经网络模型训练可以得到两个MLP模型.
2.2 敏感性分析
本文通过改变上述提到的6个参数的平均值和变异系数(Coefficient of Variation,COV)或标准偏差(ν),使用蒙特卡罗法结合响应面分析法对参数进行敏感性分析,以此来研究参数不确定性对抗液化能力的影响.基于MCS的ANN 响应面敏感性分析的过程如图1所示.

图1 敏感性分析的程序流程图
MCS需要大量的样本来呈现保证可靠性分析结果的准确性,但是提供大量的样本既耗费时间也需要资金.为了克服这一不足,采用第二个ANN 模型为MCS提供一个响应面,以便能够进行敏感性分析.表5~6总结了两个数据集所有参数的统计特征,包括均值、最小值、最大值、COV 均值以及COV 值.值得一提的是,在每个变量的参数敏感性分析过程中,其他5个变量的平均值和平均变异系数COV 值固定不变.
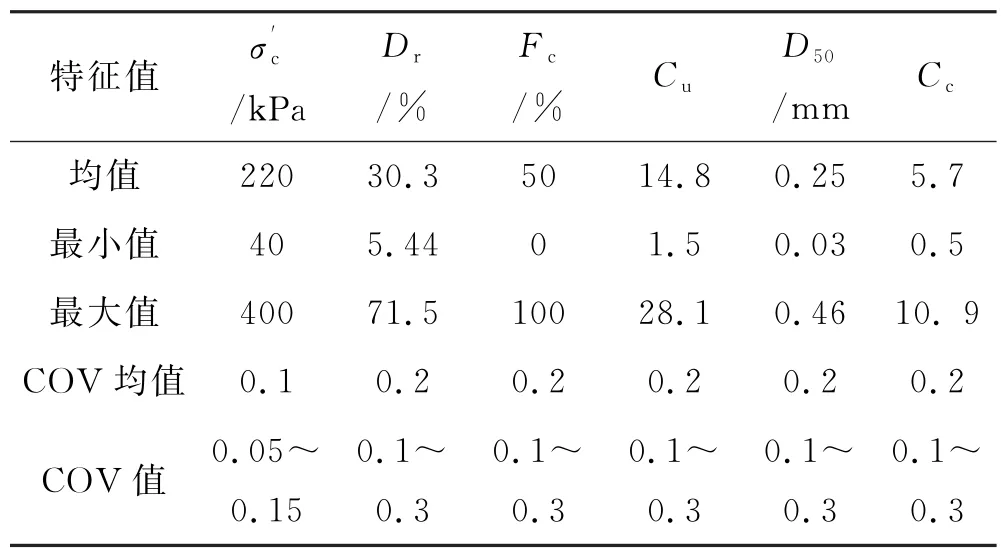
表5 第一个数据集中所有参数的统计特征
此外,为了通过MCS模拟进行敏感性分析,需要定义相关系数(ρ).由于输入参数之间的独立性,因此所有参数之间的ρ设为0.为了估计累积概率密度函数,可靠性分析的概率选择为2.9.
3 结果分析
3.1 模型性能对比
相关系数(R)是测试网络性能的最常用和最有效的工具.表7 给出了两个ANN 模型的相关系数R,其值均大于90%,说明本文构建的两个ANN 模型为高精度拟合模型.

表6 第二个数据集中所有参数的统计特征

表7 两个ANN 模型的相关系数
为了验证模型的通用性,选择Dief[28]的20个基于Nevada砂和Reid Bedford砂实验室测试结果用于验证.这20个样本没有参与两个ANN 模型的训练,仅用来验证模型的泛化能力.将其与现有的模型一起进行验证,所有模型预测的结果见表8.
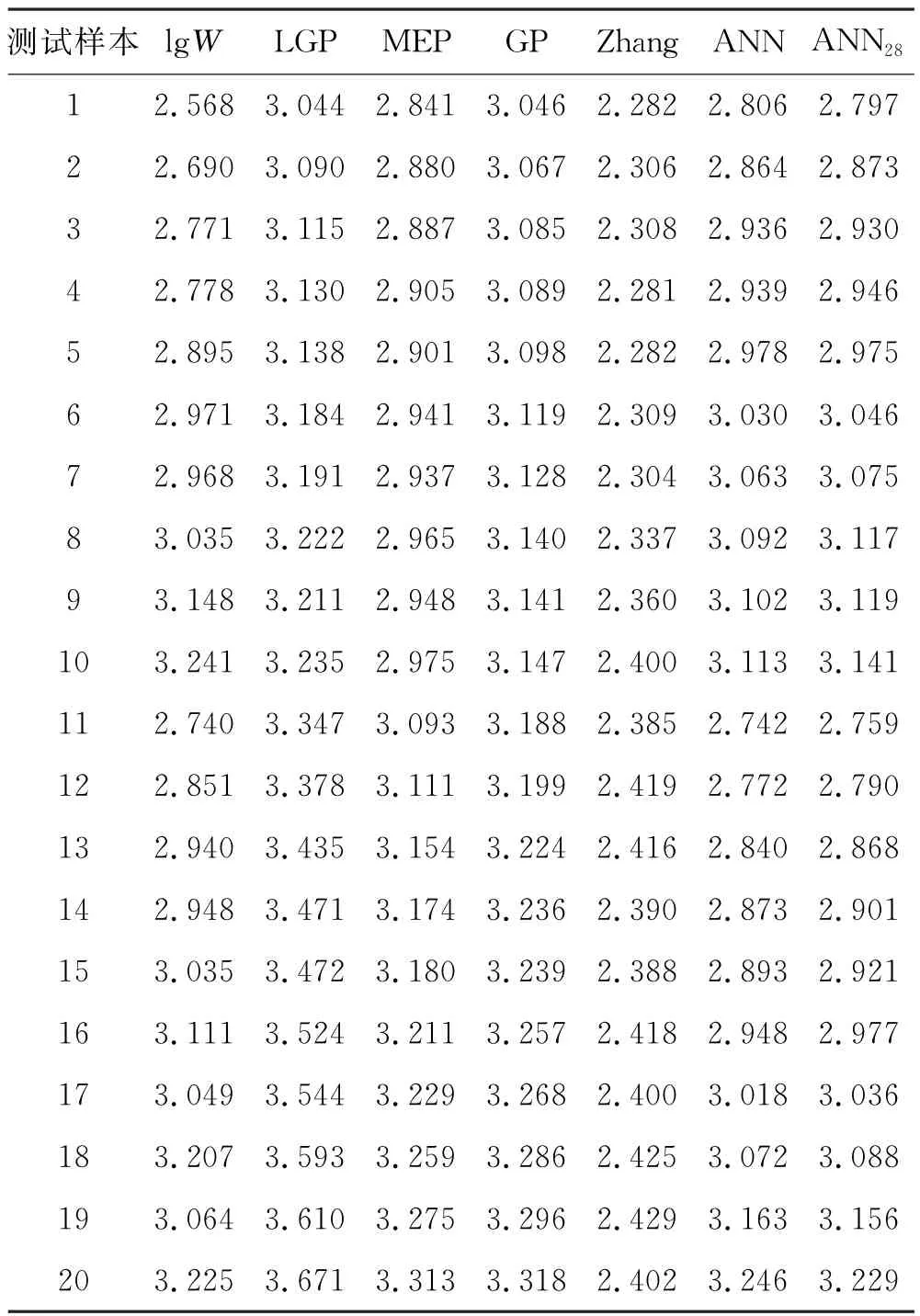
表8 6个模型对20个样本的lg W 值预测结果与真实值对比
为了更好反映出模型的学习能力和泛化能力,除了本文所构建的两个ANN 模型之外,也对上述1.1节中给出的4个模型进行了学习和训练,以此进行对比.6 个模型的均方根误差(ERMS)、平均绝对误差(EMA)和R2三个指标在表9中进行了对比.从表9可以看出,两个ANN 模型显示出更高的一致性,与其他可用模型相比,两个ANN 模型预测精度较高.此外,两个ANN 模型的R2分别为0.76和0.81,均高于其它4个模型结果.此外,ANN 模型的RMSE 和MAE值分别为0.12 和0.10,ANN28的RMSE 和MAE值分别为0.11和0.09,表现最好.
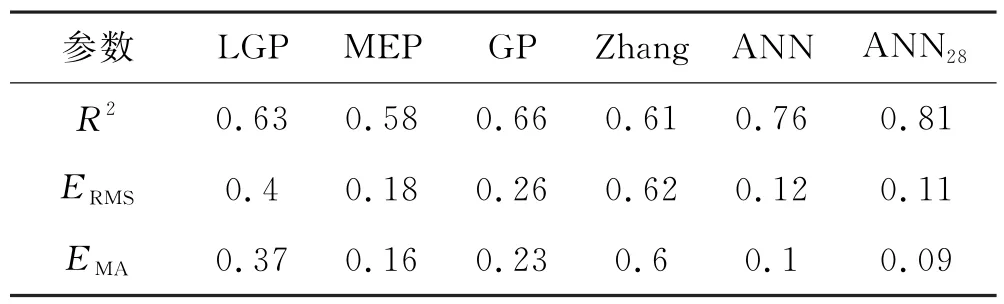
表9 6个模型预测性能评价指标对比
图2展示了ANN 模型的预测值与lgW的实际值对比.基于图2和表6可以看出,本文所提出的两个ANN 模型的泛化能力较强,即模型预测值与实际值差异较小.值得注意的是,在两个ANN 模型之间,包含Fc值小于28%数据集的ANN28模型预测精度更高,说明Fc值对于W存在不同程度的影响.此外,由于剔除了Fc值大于28%的样本,因此ANN28模型是基于较少的样本量开发的.
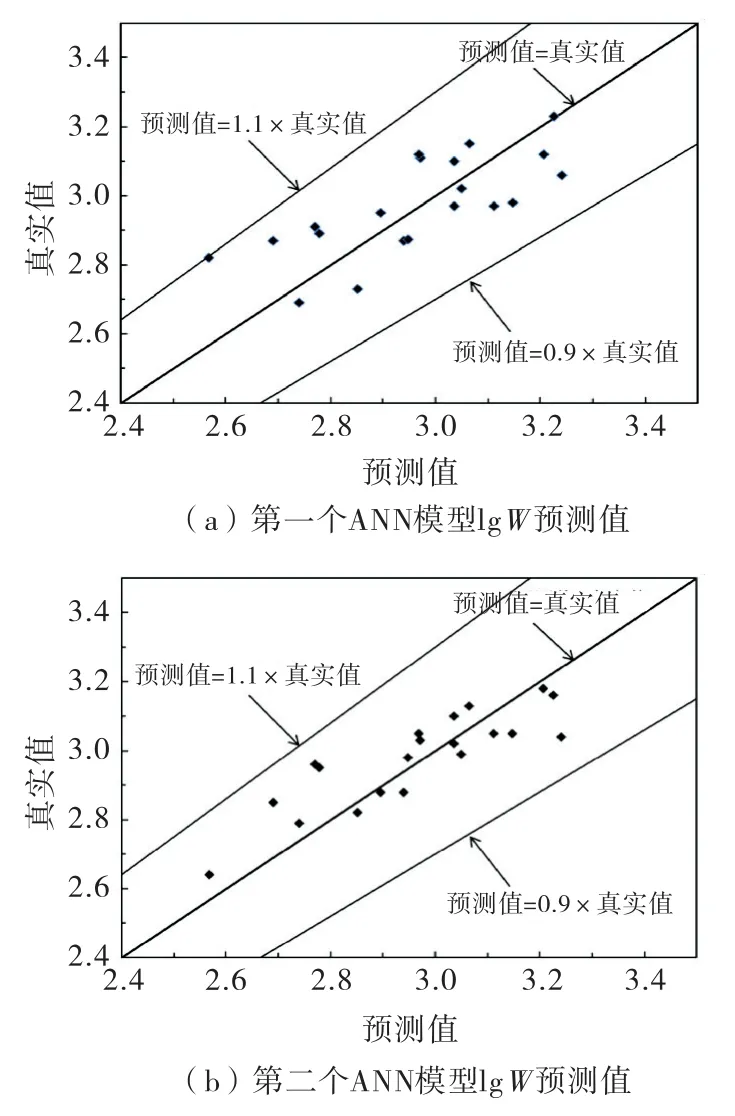
图2 ANN 模型的预测值与lg W 的实际值对比图
3.2 参数不确定性对W 值的影响
图3绘制了每个参数与lgW>2.9概率的关系图.从图3可以明显地看出除了Fc之外的5个变量的值及COV 值对概率P(lgW>2.9)均存在影响,而Fc值及其COV 值的变化对概率P(lgW>2.9)的影响较小.例如当从44到250时,P(lgW>2.9)增长15%,在超过250时,P增长到75%.值得一提的是,当Cc的COV 增加10%时,结果显示P增加约2.5%,在Cc从0.74到10.89的范围内P上升约58%,这体现了参数Cc对W的影响不容忽略.

图3 试验参数对P(lg W>2.9)的影响
4 结论
本文基于应变能概念,使用实验室测试数据,开发了两个ANN 模型对砂土抗液化性能进行评估,讨论了Fc的值和参数不确定性对砂土抗液化能力的影响.其中,在数据试验部分对以往的研究进行了改进,即设计验证集来避免模型过拟合和按照参数统计特征进行抽样.总结如下:
1)ANN 是评估土壤液化的强大工具,具有高非线性的特点.通过设计验证阶段并考虑参数统计特征对数据进行抽样,提高了模型精度.
2)第二个ANN 模型能够更加准确地预测lgW.由于与第一个ANN 模型相比仅考虑了Fc小于28%的样本,这表明当Fc值小于28%时可以改善模型的预测准确率.
3)参数的不确定性对砂土抗液化性能有较大影响,其中参数Cc对W的影响较大,应在预测W值时加以考虑.因此,作者建议使用概率模型而不是确定性模型来考虑和量化这些参数不确定性的影响.
猜你喜欢
河北水利(2022年4期)2022-05-17
黑龙江水利科技(2020年8期)2021-01-21
陶瓷科学与艺术(2019年3期)2019-07-26
中学生数理化·八年级物理人教版(2017年10期)2018-01-22
摄影之友(影像视觉)(2017年11期)2017-11-27
重庆交通大学学报(自然科学版)(2017年3期)2017-05-17
工业设计(2016年4期)2016-05-04
——结构相互作用的影响分析
中国房地产业(2016年24期)2016-02-16
中国铁道科学(2015年1期)2015-06-26
化工设计(2015年1期)2015-02-27
