
面向图注意力网络的突发热点事件联合抽取
2023-05-12 12:06徐子路朱睿莎余敦辉邢赛楠
小型微型计算机系统 2023年5期
徐子路,朱睿莎,余敦辉,2,邢赛楠
1(湖北大学 计算机与信息工程学院,武汉 430062) 2(湖北省教育信息化工程技术中心,武汉 430062)
1 引 言
在日常生活中,交通事故、自然灾害、卫生安全等突发社会事件经常发生,这些事件对我们的生命、健康或生态环境会造成大规模的破坏,因而受到社会各阶层人员的广泛关注.特别是在当前的互联网时代,以社交网络或新闻网站为传播载体的突发社会事件在经过传播发酵以后会产生社会热点事件.年初“丰县生育8孩女子”事件不仅在网上掀起轩然大波,广大网友参与其中发表个人的观点,还引发了相关法律界人士对拐卖妇女儿童“买卖同罪”的探讨.如何自动从文本中提取此类事件,准确快速地抽取出事件触发词及其事件元素,有助于决策者分析舆情态势、引导社会舆论.
突发热点事件提取(Eventextraction,EE)分为2个子任务[1-3]:1)事件触发词(trigger,用来标识事件的谓语,一般以动词和名词居多)提取,即通过触发词判断事件的种类和子种类;2)论元抽取,其目标是将事件的参与者和属性(包括事件发生的时间、地点、人物等信息)标注在已识别事件中.
目前突发热点事件抽取所针对的对象包含简单事件和复杂事件,对于部分的简单事件可以直接从一句话中抽取出事件相关信息.如例1所示.
例1.6月10日(A1,Time),河北省唐山市路北区某烧烤店(A2,Location)多名男子(A3,Object1)殴打(EM1,Denoter:Judicial)女生(A4,Object2)事件引发关注.
触发词抽取主要从文本中抽取事件的触发词实例并判定其事件类型.从例1中可抽取一个由触发词“殴打”触发、事件类型为Judicial(司法行为)的事件实例EM1.论元抽取主要抽取特定类型事件的论元并判定其角色.从例1中可抽取事件实例EM1的4个论元A1、A2、A3和A4,并识别其角色分别为Time(时间)、Location(地点)、Object1(事件参与者客体1)和Object2(事件参与者客体2).
而对于事件相关信息包含在多个句子中的部分复杂事件而言,事件抽取任务存在一定的挑战,此时句子级事件抽取将无法抽取出全部论元.如例2所示.
例2.(S1:19日17时(A1,Time)许,三门峡市义马市气化厂一车间(A2,Location)发生爆炸(EM2,Denoter:Disaster/Accident).)(S2:应急管理部官方微信20日发布通报称,截至20日16时,事故造成12人死亡(A3,Object1),3人失联,13人重伤(A4,Object2).)
在例2中,S1包含了事件的触发词(“爆炸”)、事件的论元角色Time和Location,但是只抽取出了部分事件论元.在S2中补充了事件实例EM2的论元角色Object1(12人死亡)和Object2(13人重伤).S1和S2组合将事件中包含的事件论元和在事件中所发挥的作用全部提取出来,构成一个完整的事件.
针对现有研究主要聚焦简单事件抽取,而突发热点事件往往属于复杂事件——其事件论元分散存在于多个句子之中,从而导致简单事件抽取方法不再适用的问题,本文提出了一种基于图注意力网络(Graph Attention Network,GAT)[4]的突发热点事件联合抽取方法.该方法通过抽取出新闻主旨事件以后对整篇新闻做事件抽取,利用候选事件与新闻主旨事件的事件向量相似度以及事件论元相似度对该新闻主旨事件进行补全从而完成抽取工作.实验结果表明,该方法在篇章级事件触发词抽取和论元角色抽取任务上的F1指标分别达到83.2%、59.1%,验证了该方法在突发热点新闻数据集上的合理性和有效性.
2 相关工作
事件抽取主要有基于模式匹配的方法、基于机器学习的方法以及基于深度学习的方法[5].当前主流的方法是基于深度学习的方法,文献[6]使用卷积神经网络模型(Convolutional Neural Network,CNN)自动挖掘事件隐含特征,并取得了良好的效果.文献[7]针对传统的卷积神经网络模型可能会在捕捉句子中最重要信息的同时忽略一些次重要的信息的情况,提出了一种动态多池化的卷积神经网络模型,使该模型可以在中英两种语言的事件中抽取多个事件并获得更好的表现.文献[8]针对汉语中词汇间没有自然的分隔符所导致的触发词抽取不完整这一客观问题,提出NPN模型(Nugget Proposal Networks).该模型将字级别信息和词级别信息进行融合,从而提升中文事件检测的效果.文献[9]是循环神经网络(RecurrentNeuralNetwork,RNN)在事件抽取中的首次应用,设计了一种基于双向循环神经网络的联合框架,该联合框架结合词向量、实体类型嵌入向量等来表征句子级特征,并将结果送到事件联合抽取模型中进行训练,实现触发词和论元角色的联合抽取.文献[10]针对前人在设计模型结构时没有用好句法的特点,以及对潜在论元元间的关系没有很好的建模,提出了可将依存关系融入框架的 Dependency-Bridge RNN 结构,将依存关系编码到RNN的输出中,同时提出了关于论元元素间关系建模的Tensor-BasedArgumentInteraction方法.文献[11]将生成对抗网络(Generative Adversarial Networks,GAN)[12]融入到事件抽取领域中,利用生成模块和对抗模块相互博弈学习的零和博弈思想,通过生成一些虚假的特征信息来提高模型的学习效果.分析不难看出,受限于需要大量的人工操作,上述方法无法完全发挥出模型的性能.同时,句子级顺序建模的方法在捕捉特征远距离上的依赖时,效果不是很好.相对于顺序建模,通过句法弧来建模的方法,可以使触发词与论元角色在一个句子中的距离缩短.
为此,近年来很多学者陆续利用图卷积网络(Graph Convolutional Network,GCN)[13],通过引入句法弧信息来进行建模.文献[14]提出了JMEE(Jointly Multiple Events Extraction)模型,该模型使用单词的向量表示作为图结构中的节点,通过图卷积网络来聚合节点之间的特征.通过句子中字段的语义依存关系与图结构(Graph)的联系,将其用图来表示,同时将GCN方法应用在该图上,捕捉了更为深层次的语义特征.文献[15]为了解决当前用于事件检测的神经网络模型只考虑了句子的序列表示,没有考虑句子中句法表示的问题,提出了一种集成语法信息的实体提及池化机制.这些研究让GCN大放光彩的同时,也放大了它的局限性:对于不同的邻居节点难以实现分配不同的学习权重,同时也难以处理有向图.
在中文突发热点事件抽取中,文献[16]提出了一种将Lattice(点阵)机制与双向长短期记忆(BiLSTM)网络结合的模型,通过命名实体识别任务反馈增强事件抽取模型性能.文献[17]提出一种基于双向长短期记忆网络-条件随机场(BiLSTM-CRF)的事件抽取模型,在学习字粒度语义信息的基础上结合序列标注来对中文突发热点事件进行抽取.
基于现有的研究近况来看,对突发热点新闻的事件抽取仍有如下问题:1)事件抽取仍以单句提取事件为主,无法抽取分布在多句里的复杂事件;2)已有的事件联合抽取工作大多以ACE2005数据集为基础进行实验,但该数据集的标注样例过于陈旧,且标注数据仅限于句子级别,无法满足中文突发热点事件常存在于篇章级文本里的特点.
3 基于图注意力网络的突发热点事件联合抽取模型
3.1 模型框架
本文提出了一种基于图注意力网络的篇章级突发热点事件抽取方法.该方法的总体架构分为3个阶段,如图1所示.1)事件句抽取.通过TextRank算法将包含新闻主旨的事件句提取出来,作为整篇新闻的代表事件;2)篇章级事件抽取.通过Stanford Parser工具对语料进行预处理,自动获取语料的词性标注、依存句法解析等信息.利用词向量训练工具对事件文本进行词向量的学习,将得到的词向量结合词性标记向量作为输入,通过Bi-LSTM模型得到句子的强化特征.然后将通过NLP工具得到的依存句法树引入到图注意力网络中,将学习得到的隐藏特征用于触发词分类和事件论元抽取;3)突发热点事件补全.将事件句里抽取出来的事件信息作为主事件,抽取该篇突发热点新闻里的次要事件.通过次要事件和主事件之间的论元相关性,对主事件进行补充.
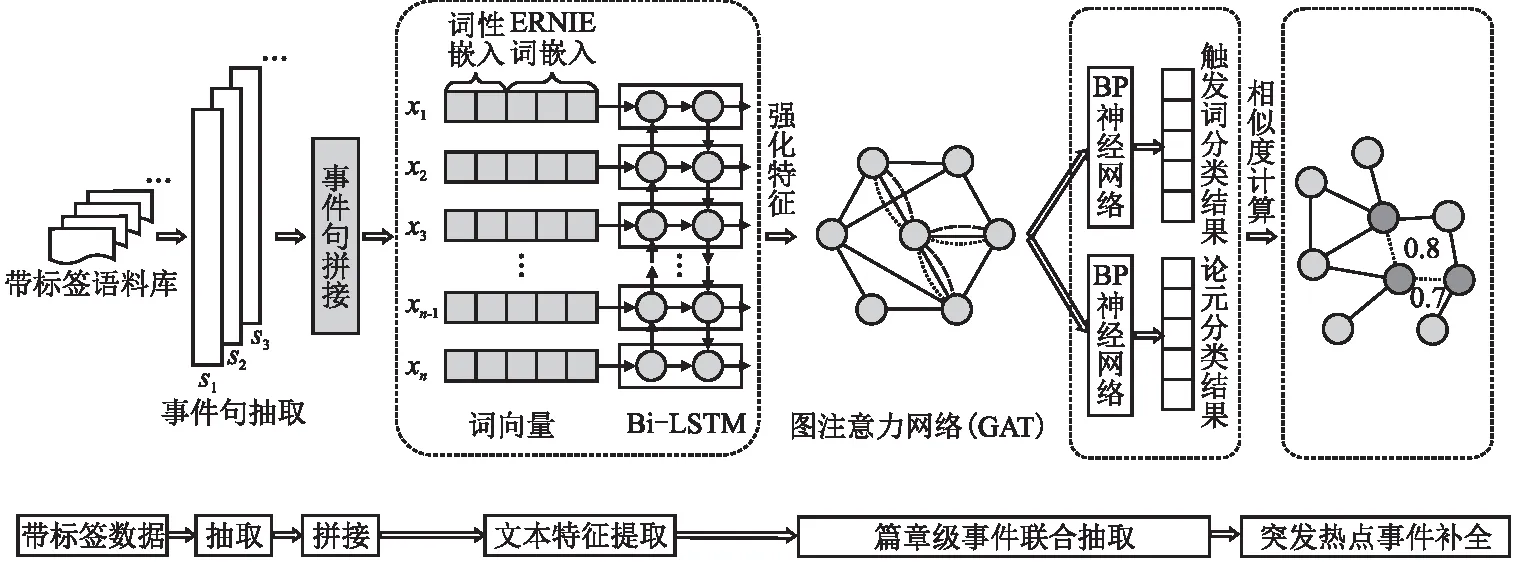
图1 基于图注意力网络的突发热点事件联合抽取框架Fig.1 Model framework
本文的贡献如下:
1)提出一种基于图注意力网络(GAT)突发热点事件抽取方法,利用句子成分之间的依存关系进行事件联合抽取.在抽取出新闻主旨事件以后对整篇新闻做事件抽取,利用候选事件与新闻主旨事件的事件向量相似度以及事件论元相似度对该新闻主旨事件进行补全.
2)通过句子成分之间的依存关系以及句子之间的潜在联系,结合序列标注的思想设计了一个中文事件字级别的建模方法,进而获取到更加全面的事件信息.
3)该方法在DUEE1.0数据集上进行触发词抽取和论元角色抽取任务时的F1指标分别达到83.2%、59.1%;在中文突发事件语料库上进行触发词抽取和论元角色抽取任务时的F1指标分别达到82.7%、58.7%,验证了该方法在突发热点新闻数据集上的有效性.
3.2 基于TextRank的事件句抽取
由于事件句包含了该事件的触发词和事件论元角色,通常作为整篇新闻文章的摘要出现在文本的段首或段尾里.为了自动的从大量新闻文本里找出事件句,这里使用TextRank算法来进行识别.TextRank是利用投票机制实现对文本重要成分排序的方法,通过将文本单元分割成若干个组成单元(单词或句子)来建立图模型的一种基于图的排序算法.主要有以下几个步骤:
1)将一个含有n个句子的文本或文本集定义为S=[s1,s2,s3,…,sn],构造关于S的图GTextRank=(V,E),其中V中的每个节点对应句子集S中的一个句子.
2)对句子进行分词、去除停用词以后得到si=[wi1,wi2,wi3,…,wim],其中wij是保留后的候选关键词.
3)对给定的两个句子si、sj,根据句间的内容覆盖程度计算相似度,如果相似度大于给定阈值,认为两句话语义相关,就把两句话连起来,也就是边的权值.
4)不断迭代传播权重计算各句子的得分,由此得到图GTextRank中的边集E.
将所有的句子得分进行倒序排序,抽取重要度最高的T个句子作为新闻的事件句.
3.3 基于图注意力网络的篇章级事件抽取
3.3.1 数据预处理
通过引言里的例1、例2不难看出,中文突发热点事件的事件文本通常是由长句子组成的.此时继续使用常规的句子级顺序建模方法在捕捉特征远距离上的依赖时无法产生很好的效果,但依存句法树中蕴含的句法信息能够捕捉单词间的长距离关系.通过对依存句法树建模,学习文本的句法依存特征,能够帮助关系抽取模型更准确地理解实体对之间的语义关系[18].因此在开始抽取中文突发热点事件之前,需要先对事件文本进行依存句法分析,获取语料的词性标注、依存句法树等信息.
但依存句法分析得到的是只能从父节点指向子节点且节点本身无法指向自身的树形结构,这时的依存关系是单向的.针对树形结构存在的问题,将根据如下的规则来将依存句法树扩充依存句法图:以句中的词为图中的节点,忽略句法分析中“Root”指向根节点的弧,以词与词之间的依存关系生成图中的边.由于依存句法图关注的是词与词之间的依存关系,不关注句法结构(如主谓等结构关系),故在依存句法树中不需要存储弧的标签信息(如“nsubj”等)[19].
首先,将事件文本s的依存句法树定义为无向图G=(V,E).其中V是依存句法树中节点的集合,节点个数为n,节点集合V中每个vi对应事件文本s中的单词表示wi.E是边的集合,每条边(vi,vj)∈E来自于词wi和词wj的有向句法弧,这个句法弧(vi,vj)的标签类型是K(wi,wj).在原有的依存句法树的基础上,通过添加具有类型标签K′(wi,wj)且和原来的有向句法弧方向相反的反向弧(vj,vi),以及对所有的vi添加一个自循环弧(vi,vi)来实现对无向图G=(V,E)的扩充.此时的无向图G代表了事件文本中触发词和论元之间的依赖关系.
之后,为了减少图注意力网络的参数量,在得到无向图时需要将其分解为3种类型标签type(vi,vj)的参数矩阵:1)E中存在的原始边K;2)自环;3)E中原始边的反向弧K′.同时,由于形容词、副词等词性对于事件触发词和论元的影响较小,而名词等词性对于事件触发词和论元的影响较大.为了体现不同边关系的词对当前词的重要性不同,在构建参数矩阵时为不同边关系的相邻词赋予不同的权重.
3.3.2 文本特征提取
为了将事件触发词以及论元从事件文本中抽取出来,需要把事件文本转换特征向量表示.为此,使用ERNIE预训练模型[20]将输入的事件文本转换成定长的向量表示.为将一个含有n个词的事件文本定义为s=[w1,w2,…,wn],其中wi表示事件文本中的第i个词.
同时,由于不同的词性在事件文本中代表着不同的组成部分.结合事件抽取而言,作为触发词抽取出来的文本绝大多数是动词(例1里的“殴打”、例2里的“爆炸”),但作为论元角色抽取出来的文本通常是数量词、名词等组成的词组(例2里的论元角色“死亡人数”——“12人死亡”、“受伤人数”——“13人重伤”).合理的运用词性与句子之间的依赖关系有助于缩小触发词和论元角色的抽取范围,故除了词向量之外,本层的输入还包括词性向量.通过使用Stanford Parser工具来获得事件文本中每个词的词性标签,之后在随机初始化的词性POS标记标签嵌入矩阵中查找对应的嵌入向量,得到句子中每个词的词性向量.
最后,通过将上述的两种向量连接得到事件文本中每一个词token转换为实值向量后的xi,输入向量表示为X=[x1,x2,…,xn].之后,由于Bi-LSTM模型可以更好地捕捉句子中的上下文关系,便利用Bi-LSTM模型来编码得到的输入向量X.将事件文本表示X编码为:
(1)
(2)
3.3.3 突发热点事件抽取
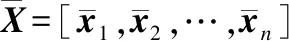
(3)
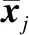
在节点更新完毕以后,为了实现事件触发词与论元的联合抽取,需对触发词抽取和论元抽取模块进行联合训练.由于两个模块不存在明显的主、辅任务之间的区别,本模型采用了较为朴素的联合学习思想.通过将两个模块的损失函数进行直接相加,形成联合损失函数.
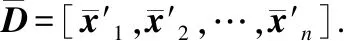
(4)
f是一个非线性激活函数.之后,接上一个softmax层将得到的类别向量归一化进行类别分类:
(5)
对于每个触发词-元素对,本文将通过特征提取后的触发词向量和元素向量进行拼接,经过一层全连接网络,最终同样使用softmax函数进行元素角色分类.其计算如公式(6)所示:
yoi=softmax(Wo[T,Ei]+bo)
(6)
其中,T表示触发词,Ei表示第i个候选元素,yoi表示第i个元素在触发词触发的事件中角色类别输出,Wo和bo是输出层的权值向量和偏置项.
3.3.4 算法执行过程
给定基于依存句法树扩充的依存句法图G=(V,E),V表示点,E表示边,节点的个数|V|=N为句子中字的个数N
算法1.基于图注意力网络的篇章级事件联合抽取
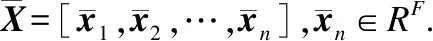
输出:触发词的分类结果yt,论元分类结果yo.
for(每篇文本s∈D)
Step1.执行ERNIE预训练模型,得到s=[w1,w2,…,wn]
Step2.结合每个词的词性向量,连接s得到实值向量序列X=[x1,x2,…,xn]
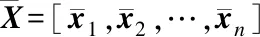
Step4.通过依存句法分析得到文本的依存句法树DPTree
Step5.得到文本的依存句法图G=(V,E)←DPTree
Step6.生成词之间的邻接矩阵∑Mt=G,t∈type(vi,vj)
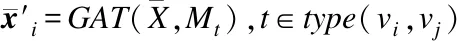
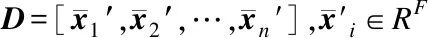
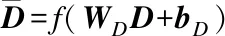
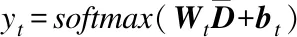
Step11.将通过特征提取后的触发词向量和元素向量进行拼接,经过一层全连接网络,最终同样使用Softmax函数进行元素角色分类:yoi=softmax(Wo[T,Ei]+bo)
end for
3.4 突发热点事件补全
一篇突发热点新闻文本可能包含很多个事件,但不是所有的事件都是围绕新闻主旨来描述的.因此,这一阶段在将该篇新闻文本里的所有事件抽取出来以后,需要对每个事件进行分析以判断其是否属于当前新闻主旨的事件链集合.将一篇新闻文本抽取出来的所有事件定义为事件集合:
Events={E,E1,E2,E3,…,En}
(7)
对于其中任意一个事件Ei以及新闻主旨事件E,其事件相关性计算如公式(8)所示:
score=sim(Ei,E)=cos(SVi,SV)+cos(Ei,E)
(8)
式(8)中,sim(Ei,E)取决于事件Ei、E的向量相似度(事件向量化表示以后的余弦相似度)与论元相似度(事件论元在该新闻文本里的TF-IDF余弦相似度)之和,表示事件Ei与新闻主旨事件E存在于同一个事件链里的可能性.计算事件Ei、E的向量相似度时,先通过预训练词向量模型获取两个事件文本的句向量SVi和SV,之后对句向量求余弦相似度.在得到所有事件Ei对于新闻主旨事件E的相似度得分score以后,保留其中高于平均值的得分事件作为新闻主旨事件E的补全事件.
4 实验结果与分析
4.1 数据集
由于突发热点事件多出现于微博、知乎等社交媒体上,参考国务院颁布的《国家突发公共事件总体应急预案》,并结合实验所用数据集自身的数据特征,将突发热点事件大致分为5大类,即灾害/事故类、卫生安全类、司法行为类、金融类、竞赛类.为了评估该联合抽取方法在中文事件抽取上的有效性,将分别在DuEE1.0数据集和中文突发事件数据集(ChineseEmergenciesCorpus,CEC)上进行实验.DUEE1.0是百度发布的包含65个事件类型的1.7万个具有事件信息句子(2万个事件)的中文事件抽取数据集,事件类型以具有较强代表性的百度风云榜热点榜单为评选对象确定.中文突发事件数据集(ChineseEmergenciesCorpus,CEC)从网络上采集5类(地震、火灾、交通事故、恐怖袭击、食物中毒)突发事件的新闻报道合计332篇.
由于DuEE1.0只包含句子级以及篇章级的事件句,不包含对热点事件的补充新闻文本或者与热点事件无关的新闻文本.而CEC的每个事件语料都是包含该事件的新闻报道,因此选择在DuEE1.0训练集上进行模型训练,在DuEE1.0测试集和CEC数据集上验证事件抽取模型的效果.
4.2 实验设置
本文实验中文本特征提取层使用的ERNIE词向量为PaddlePaddle官方提供的预训练模型ERNIE 1.0 Base,包含12层的transformer,隐藏层维度为768维.使用的依存句法分析工具为斯坦福大学自然语言处理组开发的深度学习NLP工具包:Stanza.利用Stanza来进行分词、词性标注和生成依存句法分析树的工作.实验在判断触发词检测预测的正确性方面遵循了已有研究工作的标准.对所有实验而言,在文本特征提取层中,ERNIE词向量的维度是768维,单词位置嵌入的维度是50维.在事件联合抽取模块中,单层的Bi-LSTM网络输入维度为768+50=818,输出维度为300,丢失率dropout=0.5;GAT层数n=1,输入特征维度为300,输出特征维度为50,多头注意力机制的个数k=4.在实验中,batch的大小为64,模型的非线性激活函数采用ReLU,优化器采用结合了随机梯度下降的更新规则来反向传播来计算梯度.
和通常的中文信息抽取任务一样,本文在事件抽取任务和事件补全任务上通过准确率P(precision)、召回率R(recall)和F1值来汇报模型性能.
4.3 实验结果分析
4.3.1 事件抽取对比实验
本实验的目的在于验证联合模型在提取句子级别特征时的有效性.为了验证联合模型在篇章级事件抽取的效果,将其与以下5种主流的事件抽取算法进行比较.
1)DMCNN[7]:使用了pipeline方法,加入了位置特征向量、事件类型特征向量来加强句子整体感知.
2)JRNN[9]:首次将RNN模型应用到事件联合抽取任务.并进一步强化了句子中的各种事件元素等依赖关系感知,如使用触发词记忆向量、论元记忆矩阵等特征.
3)dbRNN[10]:提出能将依存关系融入框架的Dependency-Bridge RNN结构,并同时提出Tensor-Based Argument Interaction方法来建模论元元素间的关系.
4)JMEE[14]:用图卷积网络(GCN)模型生成每个单词(图中节点)的向量表示并完成对句法树对建模的同时,通过使用句法上的捷径弧(shotcutarcs)来解决对句子中的长距离依赖.
5)GCN-ED[15]:利用句子中句法表示,提出了一种集成语法信息的实体提及池化机制.
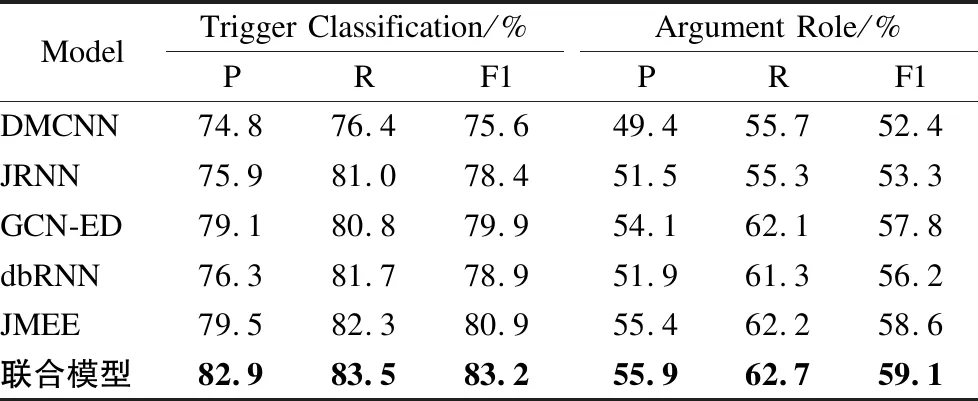
表1 本文联合抽取模型与其它模型的整体性能比较Table 1 Comparison of overall performance between the model in this paper and other models
表1列出了几个模型在测试集上的性能.由于实验数据集使用的是中文数据集DuEE1.0和CEC,故所有对比模型中的词向量都替换为了ERNIE词向量,在相同的实验环境下实验.从表中可以看出,与其他方法相比较.本文的联合模型在触发词抽取时,F1值平均提升了4.5%.在论元抽取时,F1值平均提升了3.4%.对比其他使用了句法信息的方法,联合模型在将句法树扩充为了句法图的同时还对不同词性邻居节点的权重进行了调整.不仅优化了句子之间的结构信息,还利用了图注意力网络可以更好聚合带权节点信息的特点.
4.3.2 事件抽取消融实验
1)不同词向量对联合模型分类效果的影响
词向量作为作为深度学习模型的初始特征输入,很多模型的最终效果很大程度上取决于词向量的效果.本文为了验证ERNIE预训练模型在中文词向量训练上的有效性,分别使用了Word2Vec[22]、GloVe[23]、BERT[24]预训练模型以及ERNIE预训练模型对输入的原始句子进行编码.之后将编码后的句子送入到后续模块中以完成分类任务,作为对比实验的静态词向量Word2Vec、GloVe的向量维度均为300维.不同词向量的实验效果如表2所示.
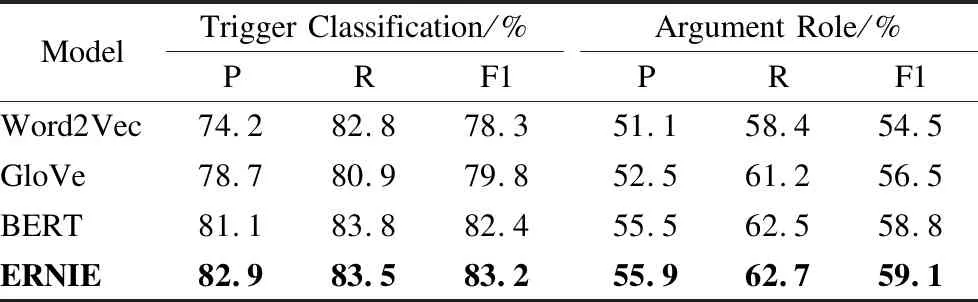
表2 不同词向量对实验效果的影响Table 2 Effects of different word vectors on experimental results
根据表2中的数据所示,BERT预训练模型和ERNIE预训练模型所展现出来的模型效果均优于传统的Word2Vec和GloVe方法.传统的Word2Vec和GloVe方法都是静态的词向量,然后根据文本来获取词嵌入矩阵,在触发词抽取任务和论元抽取任务上的表现差别不大.而同样为transformer类型的BERT预训练模型和ERNIE预训练模型,ERNIE预训练模型的实验效果则优于BERT预训练模型.相较于BERT预训练模型,ERNIE预训练模型通过对先验语义知识单元进行建模,在一定程度上增强了模型语义表示能力.本实验表明,ERNIE预训练模型可以有效的提升联合模型的触发词和论元抽取效果.
2)强化特征对联合模型分类效果的影响
由于本文在使用图注意力网络之前先将词向量送入到一个Bi-LSTM模型中进行强化训练得到强化特征.为了验证Bi-LSTM模型捕捉的句子中上下文关系对联合模型的必要性,本文与直接使用词向量作为节点特征来进行对比.不同节点特征的实验效果如图2所示.
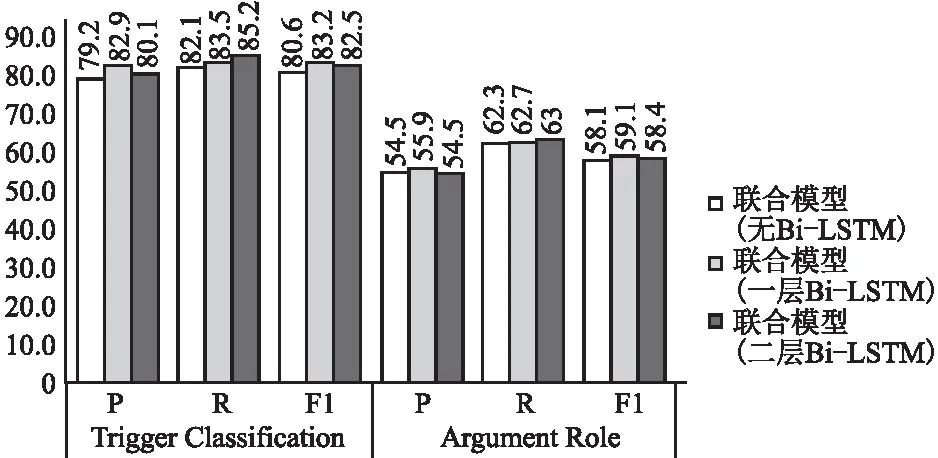
图2 强化特征对联合模型分类效果的影响Fig.2 Influence of reinforcement features on classification effect of joint model
根据图2中的数据所示,在加入强化特征以后联合模型的分类效果取得了一个较大的提升,但是将Bi-LSTM模型不断堆叠以后的效果并不理想,甚至模型效果反而变差了.虽然Bi-LSTM模型得到的强化特征可以很好的捕捉句子中的上下文关系,从而使传入GAT模型中的初始节点特征优于仅使用词向量的初始节点特征.但是不断堆叠的Bi-LSTM模型也会使联合抽取模型的参数量不断增加,从而导致在优化模型参数时的效果并没有一层的Bi-LSTM模型效果好.
3)分词结果对联合模型分类效果的影响
与以往研究的事件抽取模型不同,本文模型主要针对的是中文数据集.中文与英文的一个基本差异在于,中文的基本构成单位是字,每个字都是独立的意义单元;而英文的基本单位是字母,字母不是意义单元,只用来拼写,完全没有意义,只有词才是独立的意义单元.为了验证分词结果是否会对联合抽取模型的分类效果产生影响,下面将对按照字向量的模型与按照分词结果组合词向量的模型进行比较.不同分词方式的实验效果如图3所示.
根据图3中的数据所示,基于字的中文NLP任务可以得到比基于词更好的结果.这是因为ERNIE模型在对词、实体等语义单元的进行掩码以后,模型学习到了概念更为完整的语义表示,实现了同一词在不同上下文环境下的不同语义表示.从而使同一个字出现不同的场和会产生不同语义的词向量.同时由于联合抽取模型使用了基于依存句法分析的图注意力网络,故即便不进行分词也能通过依存句法树之间的关系正确找到触发词和论元.
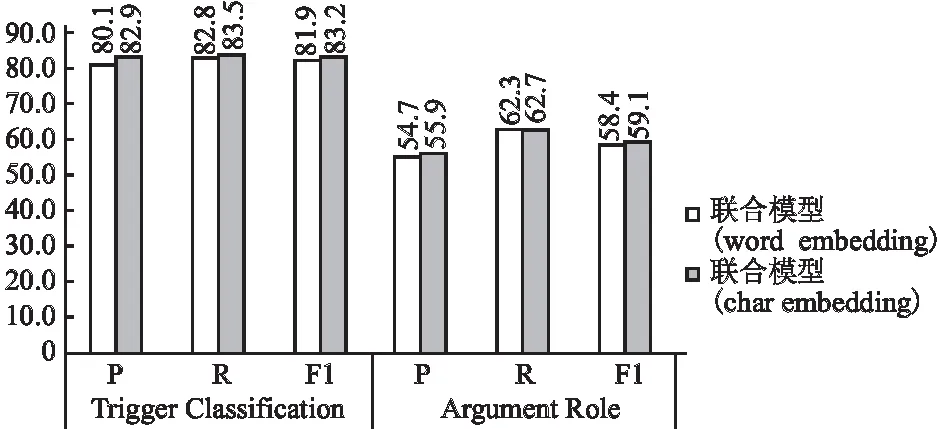
图3 分词结果对联合模型分类效果的影响Fig.3 Influence of word segmentation results on classification effect of joint model
4)不同边关系矩阵对联合模型分类效果的影响
由于联合抽取模型的依存句法图是由依存句法树扩充而来的,依存句法图中的边就是依存句法树里的句法弧.而不同类型句法弧连接的邻居节点对当前节点的重要程度是不一样的,所以为不同的邻居赋予不同的权重.为了验证权重矩阵的有效性,下面将句法弧类型权重矩阵与普通权重矩阵进行比较.不同权重矩阵的实验效果如图4所示.
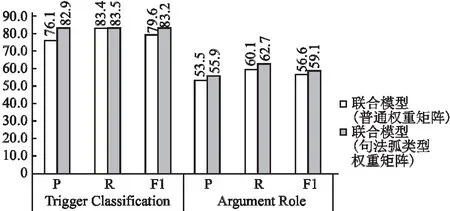
图4 不同边关系矩阵对联合模型分类效果的影响Fig.4 Influence of different edge relation matrices on classification effect of joint model
普通权重矩阵采取的是只要存在句法弧便将权重设置为1.而这样的方法可能会因为错误的句法边导致联合抽取模型的分类效果变差.根据图4中的数据所示,句法弧类型权重矩阵不仅可以体现不同类型的邻居节点对当前节点的重要性,还有助于减轻错误的句法边对模型的影响.
4.3.3 突发热点事件补全结果
在通过DuEE1.0数据集训练好联合抽取模型以后,将在CEC数据集上验证联合抽取模型的有效性,同时对事件抽取结果进行补全.按照模型框架里的3阶段,对CEC数据集中的每一篇新闻报道,先抽取新闻主旨的事件句.之后对整篇新闻文本做事件抽取,按照第3章提出的补全规则对新闻主旨事件做补全.由于CEC数据集已有对事件关系的标注,在补全时认定与已知新闻主旨事件存在关系的事件为候选补全事件.补全的评价标准采用了精准度(P)、召回率(R)和F1-measure(F1值),表3列出了本文方法的事件抽取结果在CEC数据集中不同事件类型语料上的性能.
从表3中可以看出,联合模型在CEC数据集中不同事件类型语料上的性能与在DUEE1.0数据集上的性能基本持平.在触发词抽取任务上的精准度、召回率、F1值平均为81.3%、84.0%、82.7%;在论元抽取任务上的精准度、召回率、F1值平均为55.2%、62.7%、58.7%;在事件补全任务上的精准度、召回率、F1值平均为92.6%、91.1%、91.8%.由于在事件补全任务上的良好性能,验证了该3阶段事件抽取方法在突发事件新闻文本里信息聚合的有效性.
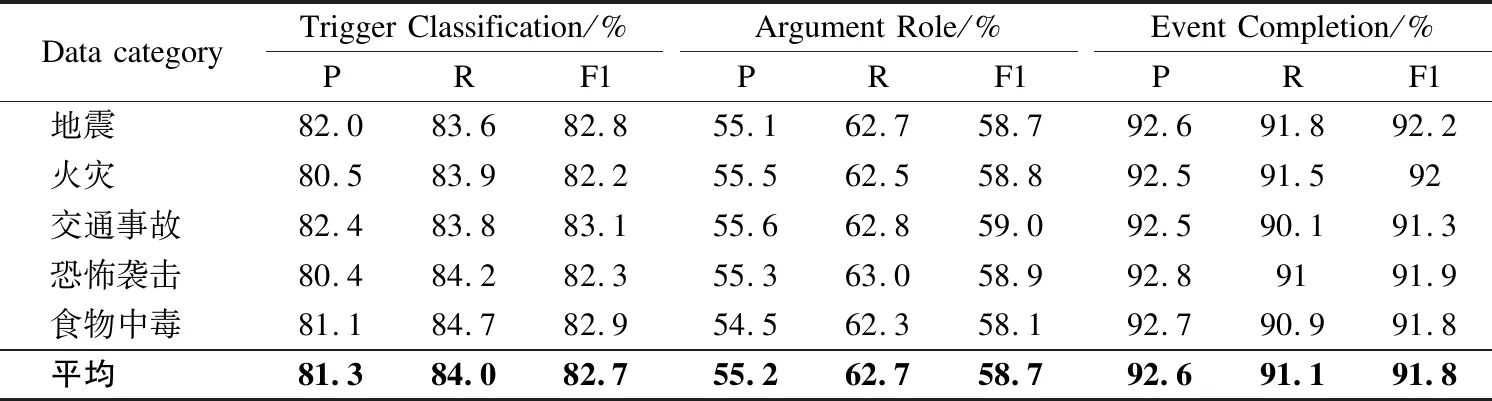
表3 联合模型在CEC数据集上的性能表现Table 3 Performance of joint models on CEC datasets
5 结束语
本文实现了一个基于3阶段的篇章级事件抽取方法,方法首先通过TextRank算法将包含新闻主旨的事件句提取出来,作为整篇新闻的代表事件.然后通过将依存句法树扩充成图,得到节点之间的邻接矩阵.使用图注意力网络(GAT)对每个节点的特征进行训练,将得到的特征分别送入到触发词分类器和论元分类器中分类,实现篇章级事件的联合抽取任务.最后,对整篇新闻文本做事件抽取,利用候选事件与新闻主旨事件的事件向量相似度以及事件论元相似度对该新闻主旨事件进行补全.通过实验验证了该方法的有效性,在未来的事件抽取研究中可以围绕以下两个方面展开:1)针对论元抽取,可以进一步研究中文事件论元抽取存在的难点,解决中文事件论元抽取性能低的问题;2)针对事件补全,现阶段只是判断了事件之间是否存在联系进行了简单的补全.下一阶段可对事件关系进一步划分,总结事件的前因后果,使事件的相关信息更全面且直观.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中华诗词(2021年3期)2021-12-31
大连民族大学学报(2021年2期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
韶关学院学报(2017年4期)2017-04-13
海外华文教育(2016年3期)2017-01-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
