
视觉标签的语义三元组检测模型
2023-05-12 12:07王思涵陈俊洪林大润刘文印杨振国
小型微型计算机系统 2023年5期
王思涵,陈俊洪,林大润,刘文印,杨振国
(广东工业大学 计算机学院,广州 510006)
1 引 言
语音识别是机器人识别人类需求的重要方式之一,人类可以与机器人交谈并驱使机器人提供服务[1,2].传统的神经网络语音识别方法[3]依赖于大量标记的文本数据进行训练.但是,在人机交互的场景下,获得文本标签较图像或者视频来得困难.基于视觉标签的语音三元组识别网络旨在采用图像或视频,而不是文本作为真实标签来训练语音模型.
近年来,研究者们通常使用动态时间扭曲(DTW)[4]从测试的语音中检索所需要的关键字.但是,这种方法无法同时处理来自多个不同语种或者不同发音者的情况.随着深度学习的日渐成熟,相当多的深度学习技术,例如MTL-DNN[5]和CNN[6],已经开始被研究者们用于语音关键字检索任务.尽管它们取得了很好的性能,但无论是哪一种神经网络,都需要大规模数据集和文本标记数据进行训练.因此,Kampe等人[7]提出了使用图像代替文本标签进行语音网络的训练从而识别关键字,这种技术虽然降低了文本标注的工作量,但是它存在以下问题,首先,图像无法捕捉动态效果,特别是对于动作识别等任务表现较差.其次,图像无法得知物体相互之间是否存在联系.这促使本文利用视频标签替代图像标签来检索语音中的关键字,从而识别动作三元组.
本文提出了一种基于视频标签的多头自注意力语音模型,它可以从说话者语音中识别由主体物体、动作和受体物体组成的语义三元组,该模型包含视频和语音两个模块.在视频模块,本文利用预训练的I3D模型[8]和Mask R-CNN[9]分别从视频中提取动作和物体特征.随后,使用两个XGBoost[10]模型将物体特征分类为主体物体和受体物体.本文将使用从视频中提取的三元组作为语音模型的软标签,而不使用文本标签,目的是用单个视频标注多个语音,降低了单个文本标注单个语音的工作量;除此之外,利用视频这种动态时序方式可以提供更好的指令表达形式,为示范学习[11]提供了扩展的基础.在语音模块中,本文构建了一个基于视频软标签的语音识别网络,该网络将序列网络和残差模块连接到多头自注意力机制网络中,目的是对语音的上下文信息进行建模并提取关键信息,最后网络输出概率值最高的3个对象和动作,并由其组成三元组.本文通过使用视频模块生成的视频标签替代文本标签可以使语音模型的标签更容易获得.本文的主要贡献总结如下:
· 本文设计了一个基于视觉标签的语音模型,它可以利用视频中的信息指导语言模型从而学习动作序列.
· 本文提出了一个基于多头自注意力机制的语音模型,它能更好提取上下文信息的序列网络,以及提出了对抗梯度消失及爆炸的残差模块
· 本文扩展了MPII Cooking 2数据集的语音数据,它可以用于对比使用视频标签的基准.
· 本文将提出的语音网络部署在UR10e机器人上,使该机器人可以通过语音执行人机交互.
本文的其余部分安排如下:在第2节中,回顾了该领域的相关工作;在第3节中,详细介绍了所提出的方法;实验报告则在第4节;最后,在第5节中进行了总结.
2 相关工作
2.1 关键字检索
关键字检索是语音识别的一个子分支,该任务的目的是从一段人类语音提取出一个或多个关键字.动态时间扭曲(DTW)[4]是一种传统的方法,它通过计算目标关键字和语音的翘曲距离达到检索的目的.但是,它无法处理存在不同的发音者或者不同语种的情况.近年来,随着深度学习的发展,Chen等[12]设计了一个基于LSTM的深度神经网络模型,它能够使用少量的计算机资源实现关键字检索.Mir等[13]提出了将检索匹配问题转换为图像的二进制分类,从而在关键字识别方面获得更好的准确性.Yuan等[14]则通过时序上下文学习单词的嵌入式,从而使得嵌入式更容易获得.Ram[15]通过更低维属性来表示更广的特征,从而获得更好的语音特征.然而,这些方法均需要大量文本标签数据进行训练,这给模型带来了巨大的局限性.为了解决这个问题,研究者们已经提出了很多的半监督方法来避免收集大量的文本标签数据的工作.例如,Palaz等[16]设计了一个神经网络,它使用更容易获得的无序文本标签去定位和分类词组,并最终在检索关键字任务上评估它的性能.Duong等[17]引入了一种注意力模型,它无需进行转录即可将语音翻译成文本.然而,以上这些方法的使用场景存在着很大的局限性,因此,本文提出了一种能广泛获取标签且易于部署的半监督方式来解决上述问题.
2.2 视觉标签
为了减轻对文本标记数据的依赖性,许多的研究者引入了视觉标签去做类似的任务.Yang等[18]提出将视频和语音同时映射到同一个公共空间,使它们可以被相互检索.Stewart[19]则提出可以结合视频特征和音频特征来识别语音,这使得语音模型更加具有鲁棒性.Ephrat等[20]实现了在无声的视频中重建语音序列,使其可以用于人脸视频的识别.最近,Kamper 等人[7]则提出了使用图像作为文本标签来训练语音模型,从而无需人工标注.然而,图像只能表达场景的静态情况,难以表达动作和序列信息,这促使本文将图像扩展为视频作为软标签.
2.3 多头自注意力机制
近年来,多头注意力机制已经被证明能在时序任务上获得很高的精度,因此,它已经被广泛应用于各种场景.例如,Cho等[21]在机器翻译任务上结合了定位信息和多头自注意力模型,大大提高机器翻译的准确性.Long等[22]则将多头自注意力模型引入社交媒体的情感分析任务中.Wang等[23]通过多头自注意力机制提高了声学场景下语音识别的准确性.Dong等[24]在语音识别上应用多头自注意力机制,从而提升了模型训练的速度.此外,Chiu等[25]发现了使用多头自注意力机制作为编码器和解码器之间的中间组件,可以在语音识别精度上取得很好的结果.受多头自注意力机制的启发,本文使用并改进了多头自注意力机制,从而可以更好的提取关键字识别的上下文联系,从而提升识别的精度.
3 方 法
本文提出的方法的概述如图1所示,它由视频模块和语音模块组成.其中,视频模块旨在获得视觉标签,这将在第3.1节中介绍,其次是在第 3.2 节中介绍本文的语音模块.
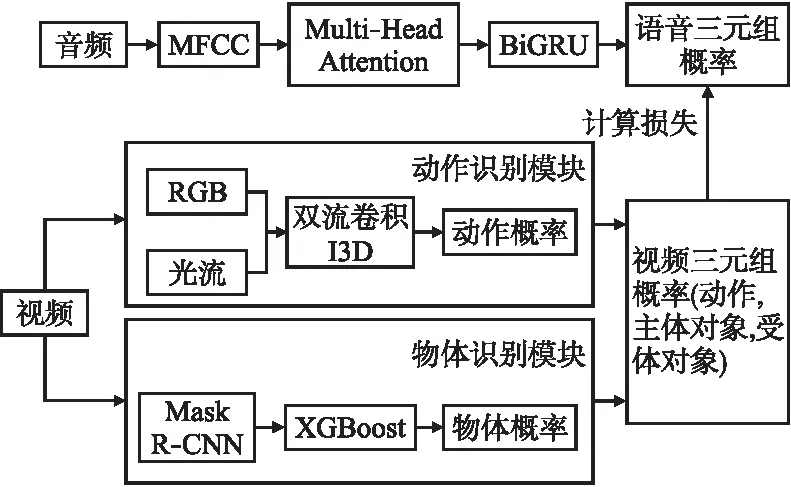
图1 框架概述Fig.1 Overview of our framework
3.1 生成视频标签的视频模块
视频模块旨在从视频中提取三元组特征作为视觉软标签.因此,本文将视频网络分为两个模块:第1个模块提取动作特征;第2个模块则提取主体对象和受体对象特征.由于动作特征在时间和空间上的表现有所不同,所以本文采用基于Inflated 3D ConvNet(I3D)网络的双流卷积网络架构作为提取动作特征的第一个模块.相比而言,I3D与传统的双流卷积网络不同,I3D通过扩展额外的时间维度将2D卷积核和池化核膨胀扩充为3D,这使得2D模型的特征权重可以直接应用于3D模型,极大地减少了在模型上的训练时间.在该网络中,本文首先在Kinetics数据集上对I3D进行预训练,并且针对本文的任务在MPII 2数据集上进行了微调.网络的输入图像被重新调整为为224×224×3,并分别输入到空间流和时间流中.最后,这两个流分别输出时间和空间动作特征,将两个特征连接并分类映射到N维的向量上,从而形成一个向量作为动作特征概率,其中N维的大小为所有动作和物体的总和.
在第2个模块中,本文使用在COCO数据集上预训练并在MPII 2数据集上进行过微调的 Mask R-CNN 来识别对象.更具体地说,首先使用该模型生成大量关于对象的候选边界框.然后本文引入RexNet-101[31]来提取对象特征并过滤掉不相关的边界框.最后,将网络输出对象标签、掩码、边界框和置信度分数进行合并作为物体特征输出.为了更进一步地细分对象信息,本文将对象特征和动作特征进行融合,并将它们传递到两个XGBoost[32]模型中,同动作特征概率的识别一样,分别将它们映射到N维的向量上以预测主体物体和受体物体的概率.
给定动作特征,主体物体特征和受体物体特征的概率,本文将它们映射到 M×N 矩阵.其中 M 表示三元组(动作,受体,主体)的个数,即M=3.N表示动作,主体物体和受体物体的个数的总数.随后,本文将该矩阵作为视觉标签用于后续语音模型的训练.注意:视频模块仅在语音模型训练时存在,当语音模型进入测试阶段时,由于不再需要软标签,所以视频模块将被剔除.
3.2 多头自注意力语音模型网络
现有的深度学习关键字检索模型通常使用Mel Frequency Cepstrum Coefficient(MFCC)来提取语音特征,这些特征会直接被送入神经网络进行预测,如CNN[6]、RNN[1]等,但是这样做会使其模型很容易忽略语音之间的上下文关系.多头自注意力机制在自然语言处理(NLP)[31]中被首次提出,并被广泛应用于很多场景,例如机器翻译[22]、情感分析[23],它可以被用于提取上下文信息并同时减少噪声的干扰.这些工作促使本文引入多头注意力机制提炼语音上下文之间的关系,从而提升关键字检索的准确率.
为此,本文设计了一个多头自注意力语音机制模型(MASN),它由多头自注意力模块、残差模块和预测模块组成,细节模块如图2所示.
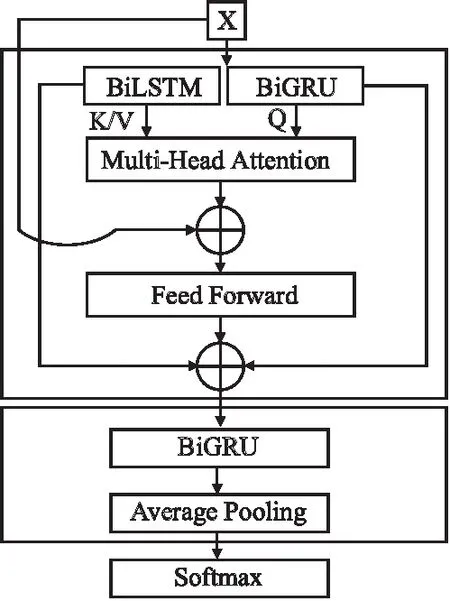
图2 语音模型框架概述Fig.2 Framework of the speech network
3.2.1 多头自注意力机制
为了更好的提取和利用语音上下文之间的关系,本文将多个序列网络的输出输入到多头自注意力机制中.更具体地说,给定一段语音,首先提取它们的MFCC特征,表示为X=(x1,x2,…,xT)其中T是频率,本文将该特征输入 BiLSTM和BiGRU中提取语音特征,如公式(1)、公式(2)所示:
Lq=BiLSTM(X)
(1)
G=BiGRU(X)
(2)
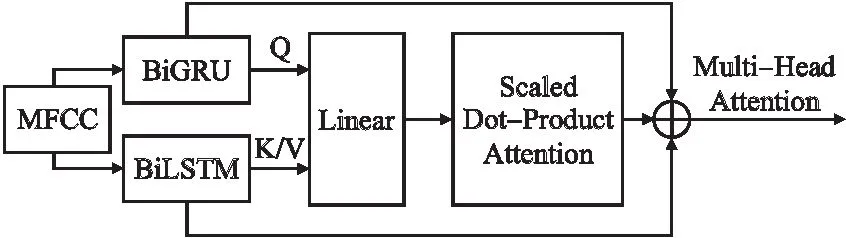
图3 多头自注意力模型结构Fig.3 Multi-Head Attention structure
在获得语音特征后,本文将其输入到图3所示的多头自注意力机制它具有3个输入向量Q,K,V,其中Q表示查询向量,K表示关键向量,V是值向量,如公式(3)~公式(5)所示:
Q=WqLq
(3)
K=WkG
(4)
V=WvG
(5)
其中Wq,Wk,Wv是训练参数矩阵.给定序列模型的序列特征,本文可以将它们作为多头自注意力的不同维度的输入向量.由于键值K,V将被用于检索Q,因此需要减少K,V之间的偏差,这促使本文将一个共享的序列特征同时输入到K和V中.例如,BiLSTM模型得到的序列特征作为查询向量,BiGRU模型得到的序列特征则作为关键向量和值向量.它们不同组合的影响将在实验部分进行讨论.对于计算多头自注意力模型中一个头的dot-product attention如公式(6)所示:
(6)
其中dk的维度和Q的维度相同.本文可以计算多个头并将它们集中到同一个矩阵中,并归一化到一个线性函数进行计算,生成多头自注意力模型的输出.多头注意力将被输入到一个全连接的前馈网络,它包含了两个线性变换计算和一个ReLU激活函数.
3.2.2 残差模块
为了解决序列网络和多头注意力模型训练过程中梯度消失或爆炸的问题,本文引入了如图3所示的残差机制,表示为“Res-M”,它也可以强化关键信息帧在多头自注意力模块和序列模块的传输,如公式(7)所示:
Res-M=M+G+Lq
(7)
3.2.3 预测模块
由于语音中存在许多被动句,这导致了三元组的提取容易受到干扰,为了处理这个问题,本文引入三层BiGRU来从句子中提取时间特征,并进行预测.除此之外,为了防止模型过拟合,在BiGRU中引入了ReLU激活函数、归一化和平均池化.最后,BiGRU采用Softmax函数计算三元组的概率.本文采用交叉熵损失函数(cross-entropy loss)来计算视觉软标签和预测标签之间的损失,如公式(8)所示:
(8)
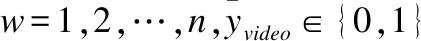
4 实 验
4.1 数据集
本文在MPII Cooking 2[33]数据集上进行实验,该数据集由不同人录制的273个烹饪视频组成.由于每个视频包含一系列不同的操作,所以官方根据动作分类将视频分割成一个个小片段,本文随机选择其中的4,000个小片段作为训练集训练视频模块,而另外2,000个则作为测试集输出视频软标签.在此次实验中,本文分别选择了7类动作、8类主体对象和21类受体对象.在这之中,使用“-”表示主体物体或者受体物体缺失的情况.表1总结了本次实验所用到的动作、主体物体和受体物体的类别.
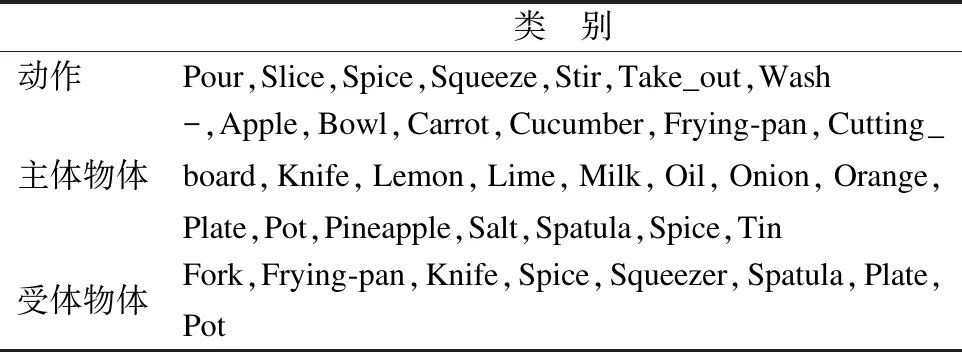
表1 动作,主体物体和受体物体的分类信息Table 1 Categories of actions and objects
4.2 参数设置
4.2.1 视频参数设置
在视频模型的处理中,本文将视频调整为224×224×3,并输入到在Kinetics数据集上预训练,使用MPII 2数据集中的1000条数据进行了微调的I3D模型.获取最后一层的分类概率作为动作概率,大小为1×N.随后使用在COCO数据集上预训练并在MPII 2数据集的1000条进行了微调的Mask R-CNN模型,并使用两个XGBoost进行分类,分别获取其分布概率,大小均为1×N.将3个分布概率合并为3×N的分布概率矩阵.
4.2.2 语音参数设置
在原始语音的预处理中,本文使用MFCC从原始语音中提取39维特征进行表示.BiGRU和BiLSTM在多头自注意力模型之前使用,它们含有400个隐藏单元,dropout比率设置为0.2.多头自注意力模型的输出将被输入到带有3 层 BiGRU 的预测模型中,并使用Softmax进行进行分类.本文选择Adam进行优化,并且学习率设置为0.001.
4.3 基线
本实验对比的基线包括传统语音模型和深度学习方法,其方法详述如下所示:
· CNN[6],使用卷积神经网络(CNN)提取语音特征从而进行分类.
· Monolingual FFN[27],是前馈神经网络的变体,它使用瓶颈特征层来提取语音额层间信息.
· Monolingual ResNet[28],使用残差网络层改进Monolingual FFN,进而从多个维度提取层间信息.
· DTW(Dynamic Time Warping)[29]是一种传统的数学方法,它计算目标关键字和语音的翘曲距离从而检索到指定的关键字.
· Vggish[30]是 CNN 的变体,它将语音向量压缩到64 维从而浓缩关键的音频信息.
4.4 使用视觉软标签的语音模型性能评估
本文结合I3D和Mask R-CNN作为视频模型,在此基础上,将不再使用任何文本标签的情况下训练语音模型.不同的语音模型使用视觉软标签的性能如表2所示.可以从中观察到如下情况:1)与其它深度网络相比,CNN、ResNet 和 Vggish 等卷积网络需要在大规模数据上进行预训练,因此,它们无法在数据量较小的情况下获得比较好的性能;2)DTW表现得也并不尽如人意,它在计算翘曲距离时忽略了局部细节,从而导致整体的性能不好;3)与上述方法相比,Monolingual FFN展示了相对较好的性能,这得益它的瓶颈特征层可以从层间提取信息;4)本文所提出的多头自注意力语音网络(MASN)获得了最好性能,这得受益于该网络能通过多头自注意力模型和残差模型提升关键字的权值比重,从而能更好的提取存在上下关联的关键字.
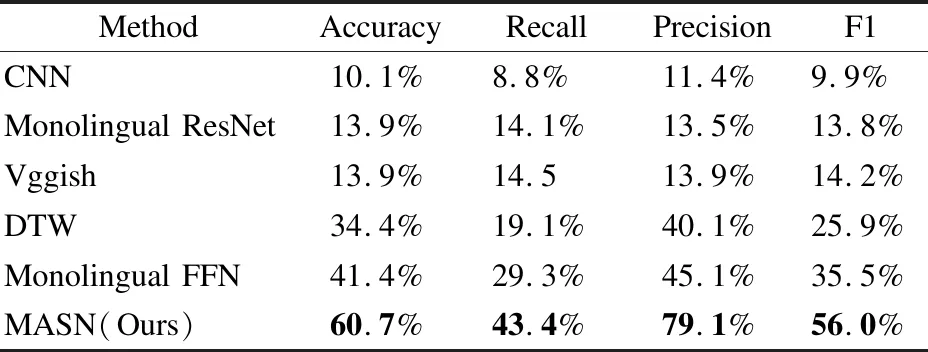
表2 不同的语音模型使用视觉软标签的性能Table 2 Performance on different speech models with visual grounding
4.5 多头自注意力机制性能评估
多头自注意力机制可以更好地提取上下文特征以提高关键词检索的性能,因此本文对比了不同模型是否添加Attention的性能,包括CNN、BiLSTM和BiGRU,其性能如表3所示.从表中可以获得如下观察:1)非序列模型CNN在数据资源较小的关键词检测中表现不佳,因为它们通常需要依赖于大量的预训练工作才能获得稳定的性能.但是,得益于多头自注意力机制的上下文理解能力,即便是性能较差的CNN也可以提高近一倍的性能;2)单个BiLSTM或BiGRU模型很容易会受到噪声干扰,从而导致识别效果较差,而引入的多头自注意力层可以很好的提高抗干扰能力以获得更好的性能.
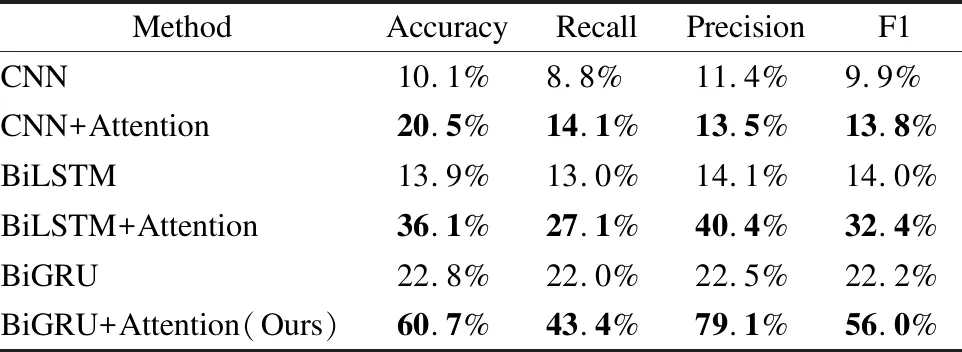
表3 多头自注意力机制结合不同模型的表现Table 3 Different model with multi-head attention
4.6 不同序列模块性能评估
表4总结了集成不同序列模型时的语音模型的性能,从表中可以获得如下观察:1)添加了序列模型的多头自注意力机制的性能优于没有添加序列模型时的性能.其原因可能是序列模型可以加深关键字信息,这使得多头自注意力模型可以更好的整合关键字上,从而更好的提取上下文信息;2)同时使用BiGRU和BiLSTM的混合序列模型的性能优于只使用BiGRU或BiLSTM的单序列模型.原因可能是虽然BiGRU和BiLSTM的训练参数虽然有所不同,但它们属于同源网络.因此,它们可以作为两个网络分支相互学习,使模型更具有鲁邦性;3)BiGRU的训练参数比BiLSTM少,在数据量较小的情况下更容易拟合参数.因此,BiGRU的单序列模型往往比BiLSTM的单序列模型更容易获得较好的性能.

表4 集成不同序列模型时语音模型的性能Table 4 Performance of integrating different sequence models
4.7 残差模块性能评估
为了评估残差模型的有效性,本文以两个性能良好的混合序列模型作为基础,如表5所示.从表中可以观察到通过残差层的连接,两个混合序列模型的性能都有所提升,这可能是由于残差层可以提高关键词的权重,有利于关键词的检索.此外,随着训练次数的增加,无残差模块的网络导致了梯度消失,从而反而会使性能有所下降.
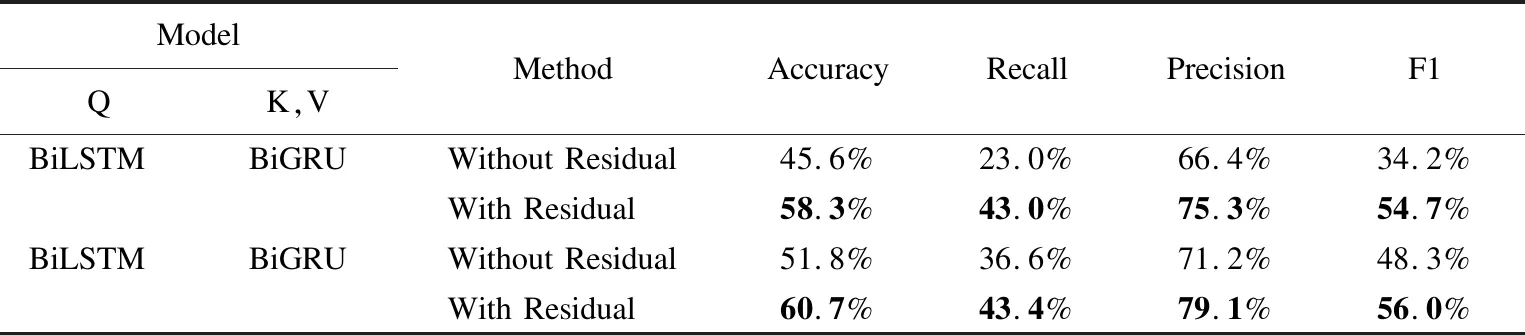
表5 不同混合模型添加残差块时的性能Table 5 Performance on different visual models
4.8 不同视觉模块对语音模型的影响
为了评估不同视觉模块对语音模型的影响,本文使用不同的视觉模块并结合本文的语音模块进行比对.在视觉模块上,使用Mask R-CNN识别对象,使用stack flow、CNN、CNN3D[26]、two-stream[27]和I3D[8]分别识别动作.从表6中可以观察到,首先,stack stream和CNN的性能比较差,原因可能是它们只考虑了动作特征,而没有考虑是否它是否与物体特征相匹配检测特征.其次,CNN3D、two-stream和I3D表现较为良好,这可能得受益于它们能提取的特征较多,能更好的动作特征和物体特征融合起来.最后,I3D表现最好,这是因为I3D平衡了动态场景和物体的捕捉能力,这有利于提升与动作相关的物体的概率.
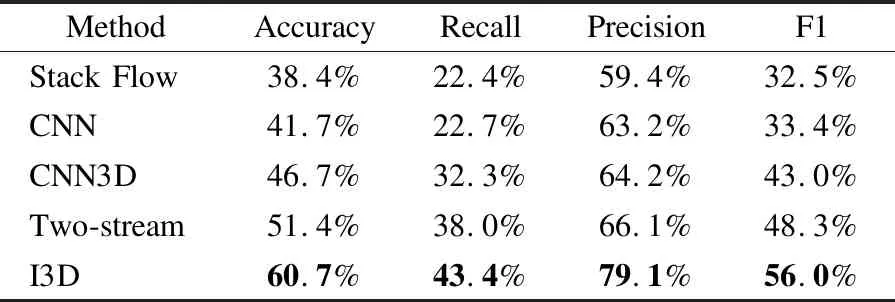
表6 使用不同视觉标签时语音模型的性能Table 6 Performance on different visual models
4.9 使用不同标签时语音模型性能评估
为了研究使用不同标签时的语音模型的性能,本文分别使用图像、视频和文本作为语音模型的标签,指导语音模型的训练.表7总结了使用不同标签时的性能,本文的语音模型使用视频作为标签时的性能,用MASN进行表示;使用文本作为标签时语音模型的性能,用MASN_TEXT进行表示,以及使用图像作为标签时的性能,用MASN_IMG进行表示.CNN_IMG从每个短视频中选择一个关键帧作为输入,所有方法使用的训练样本数均为2500个.MASN_IMG的识别准确率较低,可能的原因是它不能从图片中正确识别动作,并且无法将动作与对象关联起来,从而导致它们经常只能正确识别主体对象或者受体对象,而无法识别整体.此外,使用文本作为标签是该任务精度所能达到的上限,可以从表中发现MASN的性能相当接近MASN_TEXT,这表明使用视频作为标签具有很高的可行性.

表7 使用不同标签时语音模型的性能Table 7 Performance of our approach with different number of labels
4.10 机器人部署
为了验证模型的有效性,本文在UR10e机器人上部署了本文提出的语音模型.首先将人类语音作为输入,然后通过语音模型MASN识别由主体对象、动作和受体对象组成的语义三元组.在识别到三元组后,本文通过之前的工作[11]执行命令.对于主体物体和受体物体,使用在预训练的Mask R-CNN来识别现实世界中出现的相应对象,并根据[34]抓取的位置进行抓取.对于动作,本文应用动态运动原语(DMP)[35]系统生成机器人执行的轨迹.图4显示了机器人根据语音进行操作的示例.
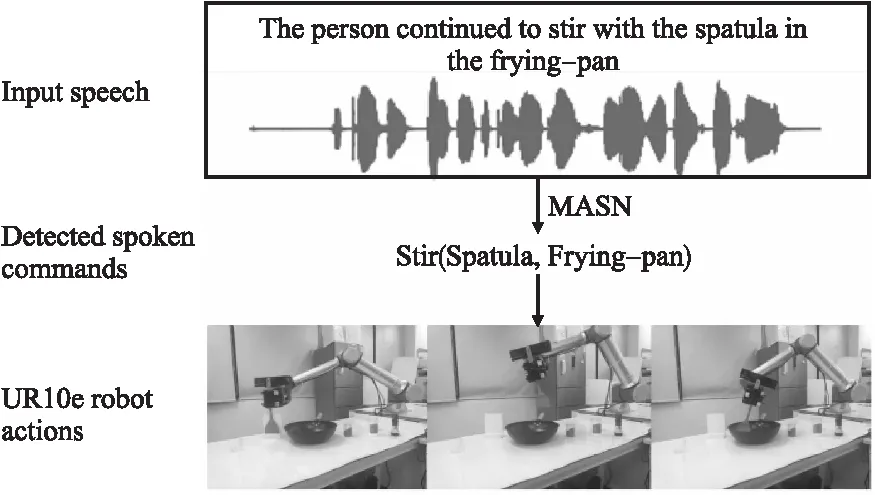
图4 UR10e 执行操作示例(顶部是输入语音样本,中间是检测到的语音命令,底部是执行机器人的例子)Fig.4 Example of performing manipulations by UR10e using our proposed framework.(The top is the input speech sample.The middle is the detected spoken commands,and the bottom is an example of executing the robot)
5 结 论
本文提出一种基于视觉标签的语音三元组检测模型框架 MASN,它在训练语音模型期间不需要太多的文本标签,而是以视觉标签为基础从语音中检测三元组关键字.该框架由两个模块组成,即视频模块和语音模块.第1个模块利用I3D和Mask R-CNN以及 XGBoost预测主体物体、动作和受体物体的概率,并合并这些概率作为语音模块标签用于语音模型的训练.第2个语音模块引入了多头自注意力机制,它结合了序列模块和残差模块分析语音的上下文信息,从而识别三元组特征.本文在MPII Cooking 2数据集上进行的大量实验和论证发现,与现有的语音模型相比,本文的方法可以使用视觉标签来替换文本标签,并且在识别精度上取得了更加优异的性能.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
山西大学学报(自然科学版)(2021年1期)2021-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年10期)2016-05-17
计算机工程与设计(2015年1期)2015-12-20
计算机工程(2015年8期)2015-07-03
