
基于ICRITIC-GCN 的空战目标威胁评估 *
2023-05-30 10:17陈美杉钱坤李玲杰刘赢
现代防御技术 2023年2期
陈美杉,钱坤 ,李玲杰 ,刘赢
(1. 海军航空大学,山东 烟台 264001;2. 中国人民解放军92493 部队,辽宁 葫芦岛 125001;3. 中国人民解放军92236 部队,广东 湛江 524000)
0 引言
空战目标威胁评估是一类典型的多属性决策问题[1-3]。解决此类问题,目前可采取的方法主要包括两类:一类是建立具体的威胁评估模型,另一类是基于智能算法的评估方法。其中,建立威胁评估模型时,主要包括属性权重确定和方案排序2 个步骤,属性权重确定的方法主要包括层次分析法[4]、主成分分析法[5]、客观赋权法[6]和信息熵法[7]等,方案排序阶段的方法主要包括逼近理想解排序法(technique for order preference by similarity to ideal solution,TOPSIS)[8]、多 准 则 妥 协 解 排 序 法(vise kriterijumski optimizacioni racun,VIKOR)VIKOR[9]、证据理论[10]等。上述研究普遍存在以下问题:①属性权重的求解过多依赖于专家的先验经验,在实战应用中存在一定局限;②忽略了属性之间的耦合性和相关性,认为属性间是线性无关的,进而通过简单的线性加权来处理;③未能将整体的战场态势看作整体,而是分别单独对每一个样本进行分析,使得评估结果片面而导致不准确。智能算法[11]则是通过将威胁评估问题转化为非线性预测问题,主要有人工神经网络[12]、支持向量机[13]、极限学习机[14]等,但都存在网络结构确定困难、容易陷入局部极值等缺陷。因此,亟待寻找一种综合考虑战场态势关系同时具有较高准确率的威胁评估方法。
考虑到战场目标空间上的拓扑性以及威胁属性的复杂性,传统欧式结构类型的数据在处理此类问题上存在一定的局限性。随着深度学习的不断兴起,图神经网络[15-17]逐渐在一些领域取得不错的成绩,分别为异常流量检测[18-19]、城市交通态势[20]、化学成分结构、基因蛋白数据以及知识图谱等各类拓扑型问题的解决提供了新的思路。此外,目标威胁值估计是将其看作一类回归问题,即预测具体的威胁值,而威胁排序则可以看作一类聚类问题,只需要得到目标所属的威胁等级即可,本文将目标威胁评估简化为威胁排序问题,利用图卷积网络(graph convolution network,GCN)做聚类分析。
本文创新之处在于:①首次利用GCN 解决此类目标威胁评估问题,通过不同度量标准建立目标之间的空间拓扑关系,生成战场目标数据;②改进了传统的指标相关性权重确定方法(criteria importance through intercriteria correlation,CRITIC)确定属性权重,综合以上,提出基于改进的指标相关性权重确定方法(improved CRITIC,ICRITIC)和GCN 的目标威胁评估算法。首先对目标属性值规范化处理,通过ICRITIC 求得属性客观权重,得到邻接矩阵,获得战场态势拓扑结构图,然后利用GCN模型对图进行训练,最后利用训练后的网络对测试目标进行聚类处理得到评估结果。
1 图卷积网络
GCN 的训练是将图数据从空间域转换到频域上来提取深层特征,最后经过激活函数输出目标标签的过程,本节简要说明GCN 的计算及训练过程。
1.1 图结构数据
本文以图结构[21]的形式表示战场目标关系网络,定义图结构数据G= (V,E),以图1 为例说明图数据的关键参数。其中,V表示G上节点的集合,即全体战场目标;E表示G上边的集合,表示目标之间在某种测度上存在关联;A为图G的邻接矩阵,表示根据E生成的关系矩阵;D为A的度矩阵(其为对角矩阵),表示与各点相连接的节点数目。并定义拉普拉斯矩阵为L=D-A,拉普拉斯矩阵主要参与图训练过程中的卷积运算。由上可以得到图1 的参数表示如下:

图1 图结构示意图Fig. 1 Graph structure
1.2 图卷积计算过程
GCN 本质上为一个神经网络层,通过叠加若干个GCN 层提取图数据特征,层与层之间传播过程的数学表述为
式中:I为单位矩阵͂=A+I为添加了自身特征的邻接矩阵͂为͂的度矩阵;H为每一层的特征;W为每一层的待训练权重矩阵;l表示当前为第l层,对于输入层,H(l)=X,σ为非线性激活函数。
如图2 所示,图上每个节点都包含属性特征以及标签(即威胁等级),GCN 模型的任务便是通过训练学习节点自身以及与其相连节点的属性特征更新网络参数,最后使用更新后的网络预测未知节点的威胁等级。
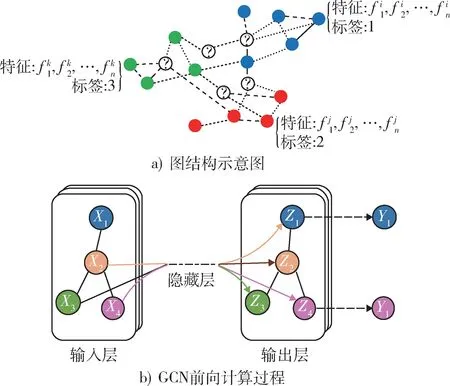
图2 GCN 计算过程示意图Fig. 2 Calculation process of GCN
1.3 监督训练过程
GCN 训练的目标是使任意节点v学习得到一个状态嵌入向量hv∈Rs,它包含v的邻居节点的信息,可以用于产生节点v对应的标签值ov。
将G上所有节点的状态向量、输出向量、特征向量、所有节点的特征向量叠加后的向量表示为H,O,X,XN,GCN 的学习过程表示如下:
式中:F为全局转化函数,用于学习得到状态向量H;G为全局输出函数,用于输出最后的标签O;H为式(2)的不动点,在F为收缩映射的假设下H被唯一定义。根据Banach 的不动点定理可知,GCN 使用如下迭代方法计算状态向量:
式中:Ht为H的第t个迭代周期的张量,按照式(4)的迭代方式将按指数级速度收敛到最终的不动点解。
训练过程中监督学习的损失函数定义为
式中:p为监督节点 数量;ti为节点i的标签;oi为对应的预测标签。
训练过程按如下步骤进行:
(2) 权重W的梯度根据loss计算得到。
(3) 权重W根据上一步得到的梯度更新。
2 目标威胁评估体系
2.1 目标威胁指标
现代空战环境日益复杂,获取敌方目标信息难度加大,进而加大了目标威胁评估难度。空战目标威胁评估需要考虑的因素众多,在评估指标的选择上,不仅要具有代表性,还要在不同角度上体现目标的威胁程度。本文综合考虑机载雷达的探测能力、空空作战特点以及机载设备的信息处理能力,选择目标类型、目标速度、目标进入角、干扰能力、目标高度、敌我距离6 个主要指标,用于目标威胁评估,其指标属性及意义如表1 所示。限于篇幅,本文对于威胁评估指标的数学建模过程不再重述,可参考文献[22]和文献[23]。

表1 指标属性及其意义Table 1 Index attribute and significance
2.2 评估矩阵构建
根据战场态势,确定m个敌方目标构成作战单元集X={X1,X2,…,Xm}和n个目标属性构成属性集U={U1,U2,…,Un},其中第i个目标的第j项属性值为uij,则目标威胁评估矩阵U= (uij)m×n。
2.3 指标的规范化处理
根据评估指标属性及量纲不同,可以将其分为效益型、成本型和固定型3 类。效益型指标与威胁程度正相关,成本型指标与威胁程度负相关,固定型指标始终为一固定的值。其中,效益型、成本型指标的规范化方法如下:
效益型:
成本型:
2.4 基于ICRITIC 的权重确定方法
CRITIC 方法[24]是一种客观赋权法,根据属性内部的差异程度和各属性之间的冲突性来综合衡量属性的客观权重,传统CRITIC 方法过程如下。
定义单个属性包含的信息量为
式中:αj为属性j的标准差,标准差越大,表示该属性所包含的信息量(不确定性)越大,理应分配更大的权 重;rjk为 属 性 间 的 相 关 系 数,表征属性间的冲突性,因此相关系数与信息量呈负相关。αj,rjk的计算过程如下:
式中:uij为目标i在属性j下的属性值。
则属性j的权重为
分析可知,上述传统CRITIC 法存在以下问题:
(1) 标准差存在量纲;
(2) 系数可能存在负值,会出现相关系数越小,反而得到冲突性更大的结论。
针对以上问题,本文提出一种改进的CRITIC法,定义改进后属性j包含的信息量为
式中:ξj为所要求解的差异系数。
(1) 传统CRITIC 法采用标准差表征冲突强度会带来量纲和数量级不一致的问题,本文借鉴分差最大化(maximizing score deviation,MSD)准则[25]构建差异系数计算模型,通过分差最大化求解得到的最优差异系数可以满足属性间差异最大化的要求,计算步骤如下:
定义属性j下目标i与其他所有目标的离差为
定义属性j下所有目标与其他目标的总离差为
构造所有属性的总离差目标函数,使其最大化:
求解并归一化处理得
通过以上将计算得到的改进后的属性信息量Cj′代入式(11)求解属性权重。
3 邻接矩阵构造
利用GCN 网络解决问题时最为重要的一步便是邻接矩阵的构造,例如,Cora 文献引用数据集[26]的邻接矩阵是根据相互之间的引用关系构造,社交关系网络[27]根据两者之间是否存在社交联系构造,蛋白质分子结构预测[28]根据蛋白质内部原子之间的化学键构造等等。
根据战场目标若威胁程度相似或一致,其多属性特征具有相似性,本文基于ICRITIC 的权重确定方法从参数相似性对目标属性构造邻接矩阵,以赋权的欧氏距离表示目标之间的威胁程度距离,目标间威胁程度越相似,其距离越小,表示如下:
式中:ωi为属性i的权重,通过ICRITIC 权重确定方法计算。
以数据集目标为例计算每个目标与其他目标的欧式距离,统计结果如图3 所示。
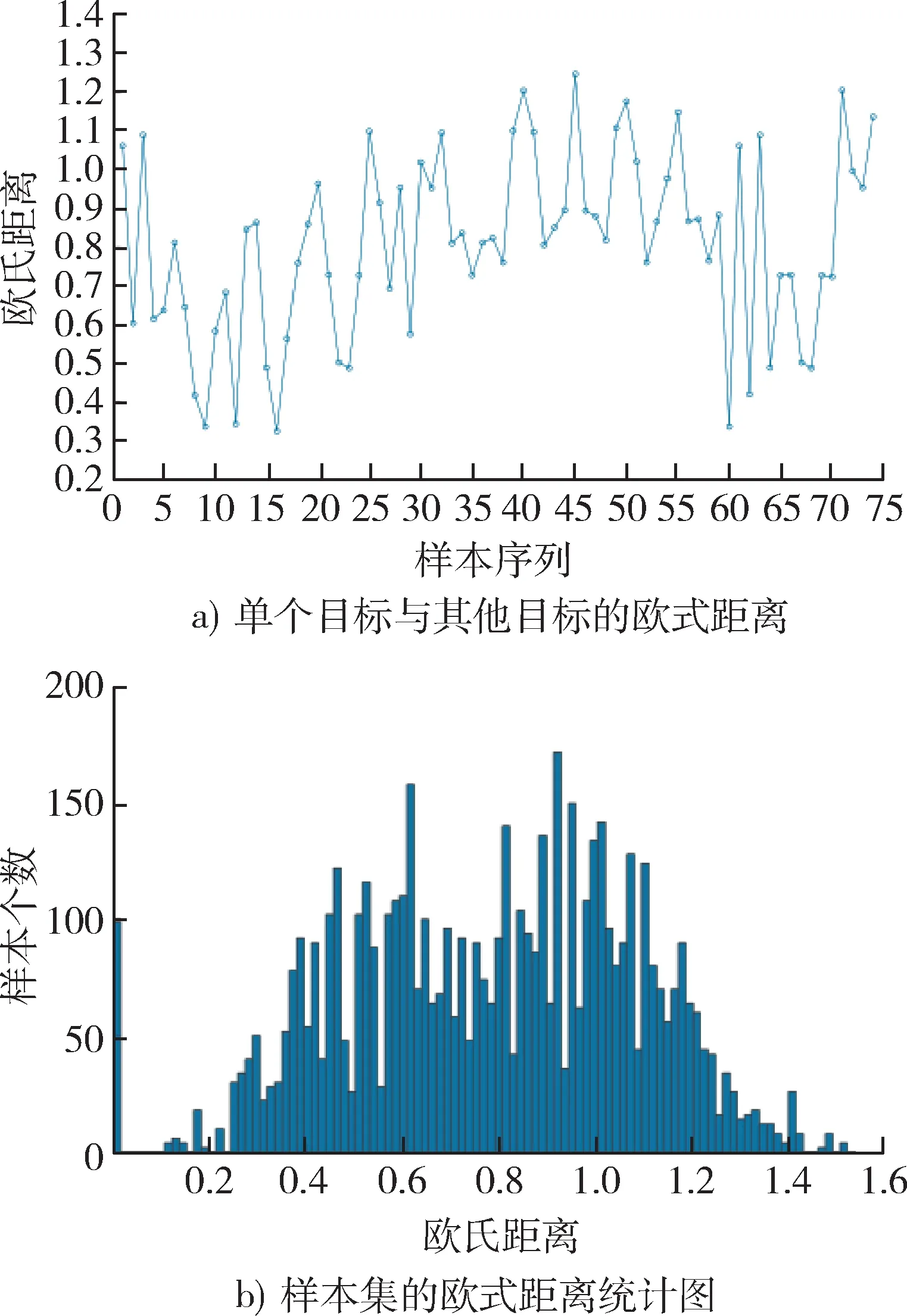
图3 欧氏距离统计示意图Fig. 3 Statistics of Euclidean distance
由图3 可知,欧氏距离可以在一定程度上表示目标之间的威胁程度距离,且归一化后的目标间欧氏距离在一定程度上近似服从正态分布,因此,可根据经验设置一固定阈值,规定目标间的欧氏距离小于该阈值时判定两者存在关联。
4 战场目标威胁评估流程
本文建立了基于ICRITIC-GCN 的目标威胁评估体系,首先计算得到目标威胁评估矩阵,然后确定邻接矩阵,最后通过训练GCN 模型对测试数据进行聚类分析,处理流程如图4 所示。
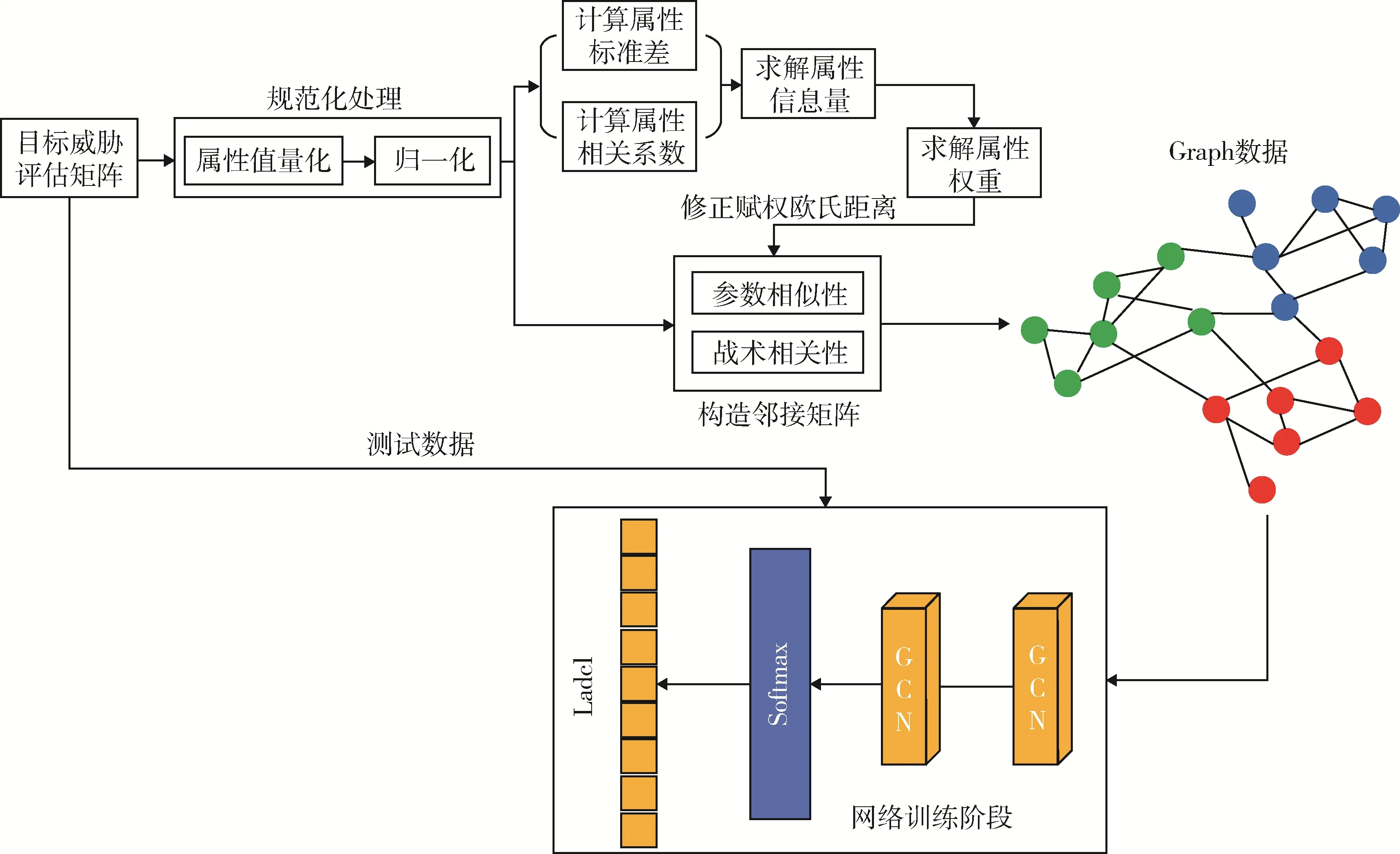
图4 威胁评估处理流程图Fig. 4 Processing flow of threat assessment
选取目标类型、目标速度、目标进入角、干扰能力、目标高度、敌我距离6 个威胁属性,其中,目标速度为效益型指标,目标进入角、敌我距离为成本型指标,目标类型、干扰能力、目标高度在本文中为文本类型数据,视作固定型指标。本文威胁评估算法的具体实现步骤如下:
step 1 构建目标威胁评估矩阵。
step 2 对数据样本进行规范化处理,首先针对不同属性采取不同处理方式:
根据文献[11]对目标威胁属性采用九级量化理论进行量化,分别表示威胁程度极小、非常小、较小、小、中、大、较大、非常大、极大,威胁程度从小到大依次量化为1~9;定量属性使用原始数值,固定型指标的量化准则如下:
(1) 目标类型:大型目标(如歼击轰炸机)、小型目标(如隐身飞机、巡航导弹)、直升机依次量化为3,5,8;
(2) 目标干扰能力:无、弱、中、强依次量化为2,4,6,8;
(3) 目标高度:高、中、低、超低分别量化为2,4,6,8。
定量属性的规范化参照2.3 节的步骤归一化,固定性指标量化后,归一化公式如下:
经过规范化处理,得到目标威胁矩阵为Z=(zij)m×n。
step 3 求解样本威胁等级
根据N级量化,样本的威胁等级zi计算公式如下:
step 4 求解属性权重
基于ICRITIC 方法确定属性权重向量为ω=(ω1,ω2,…,ωn)。
step 5 确定邻接矩阵,生成战场目标拓扑图结构
根据第3 节的方法构造战场目标的邻接矩阵,得到战场态势拓扑图数据G。
step 6 训练GCN 模型。
step 7 测试数据
利用训练好的网络预测未知样本的标签。
5 算例分析
共采集75 组不同威胁值的空战样本,其中大、小型目标、直升机各25 组,选取大、小型目标、直升机各20 组,共60 组作为训练集,其余15 组作为测试集样本。其中测试集样本如表2 所示,全部样本数据参考文献[11]。

表2 测试集样本原始数据Table 2 Raw data of samples in test set

表 3 测试集样本规范化处理后数据Table 3 Data after normalization processing of samples in test set
训练集与测试集均参照第4 节的步骤规范化处理,网络训练部分训练集与测试集均送入GCN 中,其中训练集数据参与监督训练过程,用于损失函数计算,并通过反向传播优化网络参数;测试集不参与监督训练,仅用于测试网络训练效果。
5.1 威胁评估过程
step 1 对原始数据做规范化处理,如表3 所示,得到目标威胁矩阵Z= (zij)m×n。
step 2 基于2.4 节的ICRITIC 方法确定属性权重:
首先计算各属性的差异系数,可得
ξ1= 0.158,ξ2= 0.161,ξ3= 0.154,ξ4= 0.165,ξ5= 0.179,ξ6= 0.183.
根据式(10)计算各属性相关系数矩阵(rij)6×6,可得
然后,根据式(12)得到单个属性的信息量为
C1= 0.536,C2= 0.550,C3= 0.656,C4= 0.498,C5= 0.751,C6= 0.776.
最后,根据式(11)计算得属性权重ω为
ω1= 0.142,ω2= 0.146,ω3= 0.174,ω4= 0.132,ω5= 0.199,ω6= 0.206
step 3 将属性权重ω应用到式(17)得到改进后的欧氏距离,重新构造关联矩阵,与欧氏距离的对比结果如图5 所示。

图5 欧氏距离与赋权欧氏距离对比示意图Fig. 5 Comparison of Euclidean distance and weighted Euclidean distance
step 4 训练GCN 模型:
GCN 模型采用两层图卷积层,根据威胁属性个数设置输入节点为6,隐藏层节点设为16,输出节点设为9,网络参数根据经验设置学习率设为0.1,权重衰减为5 × 10-4,训练共迭代500 轮。
5.2 评估结果分析
算法评估结果的分析主要分为3 个方面:
5.2.1 构造关联矩阵时设定不同的阈值
由图6 可得,阈值的设定会较为严重地影响测试集的识别效果,阈值设定较大时,识别准确率波动较大,即欠拟合情况较为严重;阈值设定较小时,较容易得到稳定的识别效果。分析可知,随着阈值设置增大,与每个目标建立联系的节点数目逐渐增大,当增大到最大值时,便逐渐丧失了其连接相关节点的意义,因此也就失去了分类的能力;但阈值设置较小时,其识别率提升的效果也变得不那么明显,同时网络识别率达到稳定状态所需的训练轮数有所增加;当阈值设置为0 时,识别率陡然下降,可以解释为阈值为0 时,图6 中目标间不存在连接关系,相应的邻接矩阵中没有额外的信息供图神经网络训练和挖掘,因此训练效果较差。

图6 训练集损失率及验证集准确率Fig. 6 Loss rate of training set and accuracy of verification set
仿真可得,当阈值设为0.3 时模型表现最好。根据表4 的对比可知,样本11,12 都是错将威胁等级为2 的目标预测为等级1,相差1 级;而样本6 则是将威胁等级5 预测为等级7,错误地提高了2 个等级。

表4 预测标签与真实标签对比Table 4 Predicted tag vs. true tag
5.2.2 不同距离测度
将阈值设置为0.3,选取不同距离测度在相同实验条件下训练并预测,得到的预测结果如表5 所示。

表5 不同距离测度下的训练效果Table 5 Training effects under different distance measures
由表5可知,在各类距离测度中,赋权欧氏距离的评估效果最为理想,欧氏距离和曼哈顿距离的效果次之,余弦相似度的效果最差;同时,当采用改进后的赋权欧氏距离作为距离测度后,相比欧氏距离评估结果,识别率得到提升,其中样本6的威胁等级评估误差降为1 个等级,样本11 的评估误差降为0,仅样本12的评估等级未发生变化,说明评估效果得到了改善。
5.2.3 ICRITIC 对本文评估模型的影响
保持其他参数不变,选取距离测度为欧氏距离,分别选取不同的权重确定方法训练,则不同方法的识别效果对比如图7 所示。由图7 可知,本文方法在改进差异系数和添加绝对值后,识别率较原有方法有所提高;当仅对差异系数进行改进时,与传统CRITIC 法相比,识别率提高不明显,但达到稳定状态需要的训练轮数更少;当仅对传统方法添加绝对值时,识别效果与未改进时提升并不明显。

图7 不同权重确定方法的识别效果对比Fig. 7 Comparison of recognition effect under different weight determination methods
相应地,对不同权重确定方法的具体属性权重结果进行分析,对比结果如图8 所示。

图8 属性权重确定方法对比Fig. 8 Comparison of attribute weight determination methods
由图8 可知,传统CRITIC 法的属性权重中,目标速度最高,目标类型、目标进入角、高度以及干扰能力次之,目标距离权重最低,这与现实情况不太相符。因为如果目标不在我方作战半径以内或是有向我方抵近的趋势,其速度即便再高也不会对我方造成大的威胁。因此,传统方法中目标距离的权重最低,这显然不符合实际认知。而本文所改进的方法确定的属性中,目标距离权重最高,高度与目标进入角次之,而目标类型、速度以及干扰能力的权重均有所降低。分析可知,只有当目标进入我方作战半径以内时,才能够对我方造成潜在威胁。同时,当目标抵近时,其威胁值不断提高。而目标远离我方时,其一般不具有攻击意图。这在直观上符合作战认知,从而验证了本文改进的属性权重方法的有效性。
5.2.4 与传统方法比较分析
为了验证本文算法的实效性与准确性,分别与TOPSIS 方法、VIKOR 方法等传统排序算法进行对比分析,判定贴近度最高的样本所在的威胁区间为待测样本的威胁等级。其中,TOPSIS 方法中,采用加权欧氏距离计算,权重确定方法根据CIRTIC 方法求解。分别计算各方法的识别准确率以及识别效率,仿真结果如表6 所示。
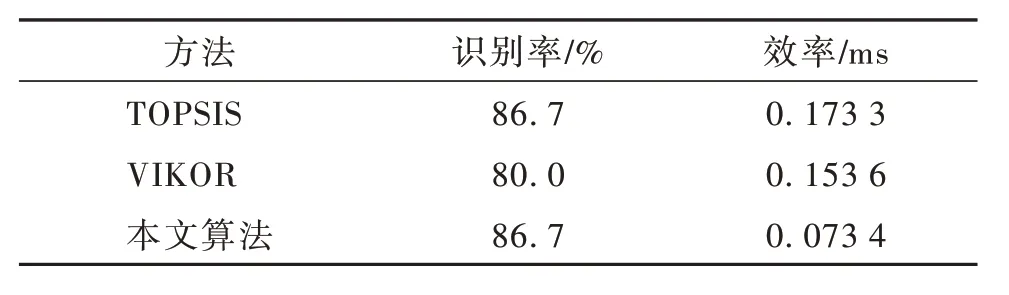
表6 与传统算法比较分析Table 6 Comparison results with traditional algorithms
由表6 分析可知,本文算法在识别率上相较于传统方法,仅高于VIKOR 方法;但在识别效率上,本文算法相较于传统算法,其处理效率显然更高。这是由于本文采用深度学习算法,更适合处理大样本的威胁评估任务。
5.2.5 鲁棒性分析
本节对所提算法的鲁棒性进行分析,通过增加样本数量以及增加训练样本出现误差的概率,测试算法在不同实验条件下的识别率变化情况,以此来检验方法的鲁棒性。通过对同一威胁等级样本的属性值在区间内均匀取值的方法增大样本数量,分别设置样本量为100,500,1 000,2 000,训练集与测试集比例始终为4∶1,增加训练样本误差采用随机更改样本属性值的方法实现,设置样本误差比例分别为1%,3%,5%,7%,10%,12%,仿真结果如图9所示。

图9 识别率随样本数据量增加的变化图Fig. 9 Variation of recognition rate with the increasing data volume of samples
由图9 可知,随着样本误差比例的提高,算法识别准确率呈逐渐降低的趋势。特别是,当样本数据量为100 时,识别率的下降程度最为明显。但当样本数据量增大时,识别率的降低趋势有逐渐放缓的态势。即样本量增加后,算法的参数训练的更加稳定,对样本的误差具有更强的适应能力,这也反映了本文算法具有较强的鲁棒性。
5.2.6 区间分离度调整
本文最初对目标威胁值采用九级量化理论,威胁程度从小到大依次量化为1~9,评估效果如上文所示,通过调整量化的区间分离度,对评估结果进行分析。
由表7 可知,当调整目标威胁值量化标准后,评估效果得到显著改善。在九级量化标准下,正确识别率为86.7%,其中2 个目标的评估误差为1 个等级;在七级量化标准下,由于全部样本的威胁等级个数减少为7 个,威胁等级间的区间变大,识别率提升到93.3%,相比九级量化标准,样本12 的威胁等级得到正确评估,仅样本6 的威胁等级被错误评估,误差等级为1,相比九级量化标准,等级误差有所降低。

表7 不同区间分离度的识别效果Table 7 Recognition effect under different interval separation degree
通过上述算例分析,验证了本文所提方法在解决多个目标的威胁排序问题时的有效性,说明了结合ICRITIC 属性权重确定邻接矩阵,利用GCN 模型预测目标威胁等级是有效的,解决了部分威胁评估方法不能处理数量较多的目标局限性,以及属性权重确定过程中对先验知识过于依赖和人为主观因素的问题。
但本文GCN 算法仍然存在不足之处,与深层卷门神经网络类似,本文算法同样面临是否具有可解释性的困难。但本文算法通过采用图神经网络,将各目标看作单个节点分析,可视化分析结果表明其在空间上具有相似节点聚集的特性。相比卷积神经网络,其具有更强的可解释性,但仍缺少核心理论的支撑。因此,可解释性依然是今后的一项重要研究内容。
在实时对抗过程中,GCN 作为深度神经网络,相比其他深层模型,网络深度更小,参数更少,需要的训练时间更少,更能满足实时评估的作战需求。同时,作为半监督学习方法,作战数据可以作为数据库进行网络学习,使得模型的精度越来越高。因此,能够有效提高评估速度及准确性,便于后续的作战决策和火力分配等相关工作。
6 结论
(1) 基于GCN 对空战目标进行威胁评估,针对空战目标拓扑性的特点构造图结构数据,利用历史评估数据对敌方目标进行监督学习,在不同量化标准下均取得理想的评估效果。
(2) 基于ICRITIC 方法,综合考虑属性间相关性及属性标准差,客观分配权重,辅助GCN 的邻接矩阵构造,有效地解决了传统评估过程中权重过于主观的问题。
(3) 下一步的主要工作将围绕如何融合多个时刻的目标信息,利用GCN 实现动态威胁评估,在实时性方面取得进展,以及解决阈值设定过程中过于依赖经验的问题,寻求利用数学方法得到更可靠的参数设置方法。
猜你喜欢
当代陕西(2020年17期)2020-10-28
红领巾·探索(2020年5期)2020-05-19
小学生导刊(2018年34期)2018-12-18
小学科学(学生版)(2018年9期)2018-09-21
人大建设(2018年5期)2018-08-16
家教世界(2017年11期)2018-01-03
电信科学(2017年6期)2017-07-01
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
延河(下半月)(2014年3期)2014-02-28
