
基于CBAM-DDcGAN的锌渣红外与可见光图像融合
2023-06-07 00:17秦浩,熊凌,陈琳
武汉科技大学学报 2023年3期
秦 浩,熊 凌,陈 琳
(1.武汉科技大学冶金自动化与检测技术教育部工程研究中心,湖北 武汉,430081;2.武汉科技大学机器人与智能系统研究院,湖北 武汉,430081)
随着智能制造技术的发展,热镀锌生产线中捞渣机器人的智能化水平也在不断提高。锌渣精确识别是实现智能化捞渣的关键,单独依靠红外或可见光成像设备无法适应捞渣现场恶劣的工业环境,而红外与可见光图像融合是特殊场景下获得高质量图像的一种有效手段,融合图像能够同时呈现出锌池液面的热辐射信息与高分辨率的锌渣分布细节信息。
红外与可见光图像融合的传统方法主要包括基于多尺度分解的方法、基于稀疏表示的方法和基于混合模型的方法等。随着视觉显著性检测概念的提出,出现了越来越多的相关融合算法。Ma等[1]提出基于视觉显著图(visual saliency map, VSM)与加权最小二乘优化(weighted least square,WLS)的红外与可见光图像融合方法,利用多尺度分解将输入的红外图像和可见光图像分为基础层和细节层,利用视觉显著图融合基础层,利用加权最小二乘优化法融合细节层,再通过多尺度逆变换得到融合图像。Li等[2]提出一种基于潜在低秩表示(latent low-rank representation, LatLRR)的多级图像分解方法MDLatLRR,将源图像分解为低秩部分和显著部分,采用不同的策略对两部分分别进行融合,最后通过特征图重建得到融合图像。Zhang等[3]提出一种基于红外特征提取和视觉信息保存的红外与可见光图像融合算法。尽管传统图像融合方法日趋成熟,但融合规则通常需要人工设计,具有实现难度和较高的计算成本。
近年来,基于深度学习的红外与可见光图像融合方法不断出现。Liu等[4]提出一种基于卷积神经网络(convolutional neural network, CNN)的红外与可见光图像融合方法,利用CNN计算权重高斯金字塔,对源图像进行拉普拉斯分解,计算各层拉普拉斯系数并进行融合,最后重建得到融合图像。Zhang等[5]提出一种基于CNN的通用图像融合框架IFCNN,首先利用两个卷积层从多张图片中提取特征,再根据输入图像类型选择适当的规则对特征图进行融合,最后使用两个卷积层重构特征图得到输出图像。Xu等[6]提出一种可适用于多种图像融合任务的端到端的无监督图像融合网络模型U2Fusion,用于保护融合图像与源图像之间的相似性,解决了基于深度学习的图像融合任务中真值图像获取以及指标设计等问题。Ma等[7]利用生成对抗网络(generative adversarial network, GAN)的特性,提出FusionGAN图像融合方法,利用网络中的生成器提取源图像信息得到融合图像,判别器使融合图像具有更多的可见光信息,通过生成器和判别器的对抗训练来提升融合图像质量,避免了手动设计融合规则的缺陷;之后,Ma等[8]又提出基于双判别器生成对抗网络的融合方法DDcGAN,同时保留两种源图像的信息,进一步提升了图像融合效果。
在热镀锌实际生产中,锌液温度达到600 ℃以上,由于安装距离的限制,红外相机捕捉锌液表面热辐射信息的能力不足,而可见光图像又存在光照不均匀、部分区域被遮挡等问题。传统红外与可见光图像融合算法通常采用固定的模型提取图像特征,大都针对公共数据集设计融合规则。锌渣图像集目标与背景区域相似度较高,源图像中缺少明显的识别目标,与公共数据集的差异较大,故采用传统算法时图像融合效果一般。利用卷积神经网络实现红外与可见光图像端到端的融合,在充分提取图像特征的同时,既能减少图像融合过程中的计算量,又能避免融合规则的设计。
考虑到热镀锌生产线中的锌渣红外与可见光图像的特殊性,本文提出一种结合卷积注意力机制模块(convolutional block attention module, CBAM)[9]与双判别器生成对抗网络的锌渣图像融合方法(记为CBAM-DDcGAN)。CBAM-DDcGAN网络包含一个生成器和两个判别器,将红外与可见光图像输入生成器得到融合图像,通过判别器和生成器的对抗训练来更新生成器的参数,从而获得更多的源图像信息,而且生成器的内部卷积层采用密集连接方式,以最大程度地保留提取到的源图像特征;同时,将CBAM引入GAN中,增强不同模态的图像像素与全局依赖关系的表达,对全局特征和局部特征赋予不同权重,达到增强关键特征的效果,提升图像融合质量。本文最后通过锌渣图像数据集进行算法验证,并与其他主流图像融合方法进行对比分析。
1 CBAM-DDcGAN网络模型
1.1 DDcGAN融合网络框架
该融合网络主要由生成器G和两个判别器Di、Dv构成,网络总框架如图1所示,基本原理如下:将红外图像i与可见光图像v输入到生成器G生成融合图像f;将红外图像i与融合图像f输入判别器Di,将可见光图像v与融合图像f输入判别器Dv;以i和v作为真值图像对融合图像f进行判别,通过判别器和生成器的对抗训练来更新生成器的参数,使融合图像f获得更多源图像的信息,以达到判别器无法区分二者的效果。
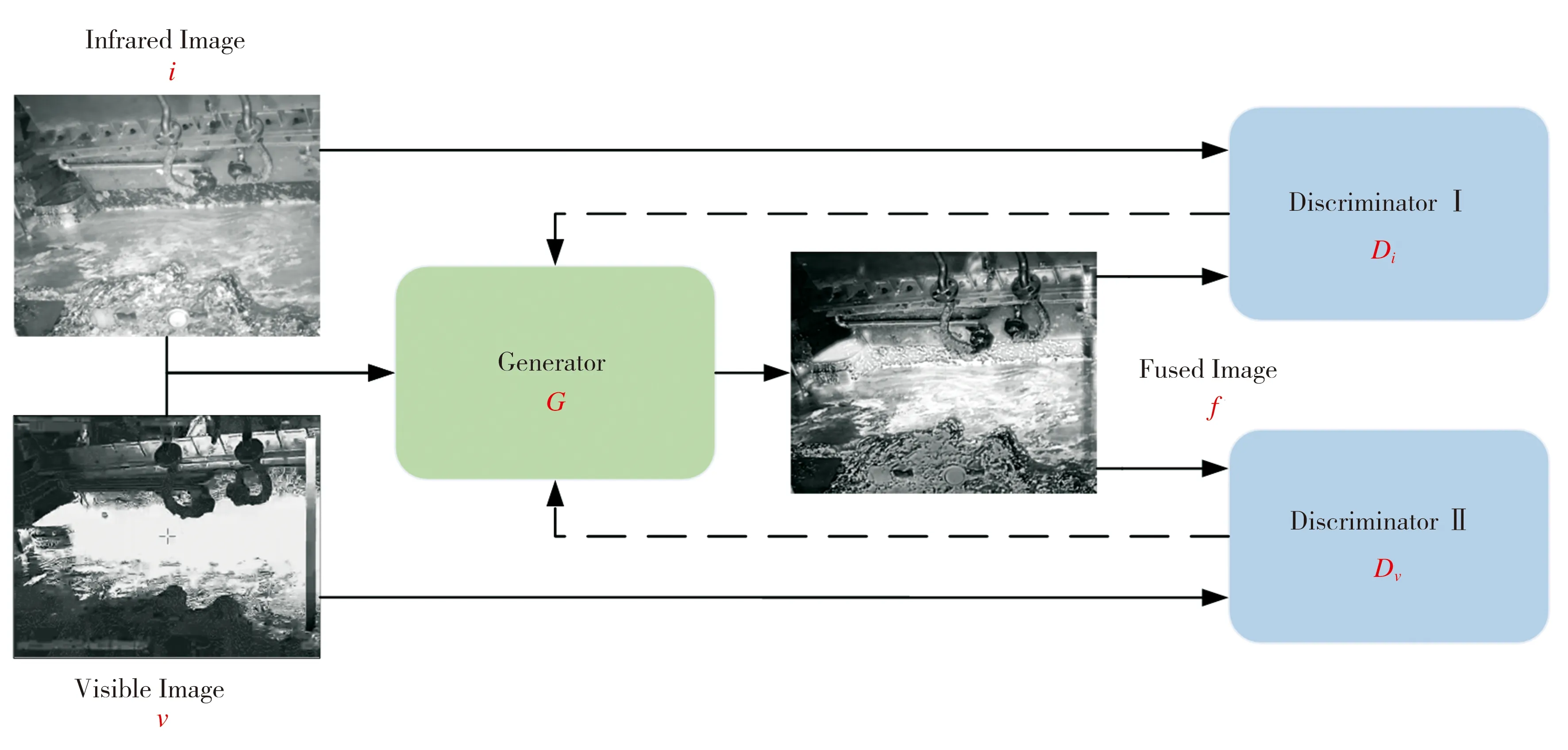
图1 DDcGAN总体框架
1.2 生成器模型
生成器G采用在无监督学习情况下特征重构能力较强的编解码结构,如图2所示。红外与可见光图像经通道连接后,形成双通道图像并输入到编码器Encoder中进行特征提取,提取到的特征输入到卷积注意力机制模块来寻找关键特征,之后进行特征融合与特征重构。特征提取模块的卷积层用Densenet结构代替常规的卷积层连接方式,其中n为卷积层输出通道数,卷积层步长都为1,均使用3×3卷积核得到48个特征图。CBAM利用卷积注意力机制给予输入特征图中的显著像素以更多的权重,从而输出更能表达原始图像的特征增强图。编码器输出的特征图进入特征融合模块进行图像融合,再输入解码器Decoder,解码器中卷积层的大小均为3×3,最后一个卷积层的激活函数为tanh函数,融合后的特征图在解码器中进行特征重构,最后通道数降至1,输出融合图像。在整个编解码网络中,最后一个卷积层之外的每个卷积层后面都使用批量归一化层(batch nomalizatio, BN)和带泄露线性整流函数(LeakyReLU)层来提高模型训练时的稳定性。
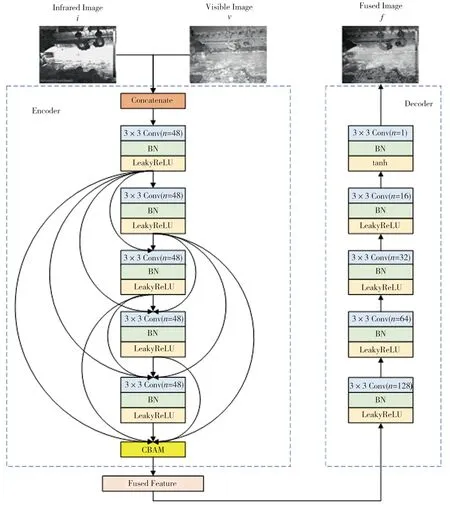
图2 生成器的网络结构
1.3 卷积注意力机制模块
本文使用的卷积注意力机制模块CBAM结合了通道注意力和空间注意力两个子模块,强调空间和通道两个维度上的关键特征,其网络结构如图3所示。CBAM的给定输入为编码器提取的特征F,先经过通道注意力模块,将所输出的通道注意力一维卷积和输入特征图F做逐元素乘法操作,得到经过通道注意力增强的输入特征图F′;再经过空间注意力模块,将所输出的空间注意力二维卷积与该模块的输入特征图F′做逐元素乘法,得到CBAM输出的最终特征图F″。
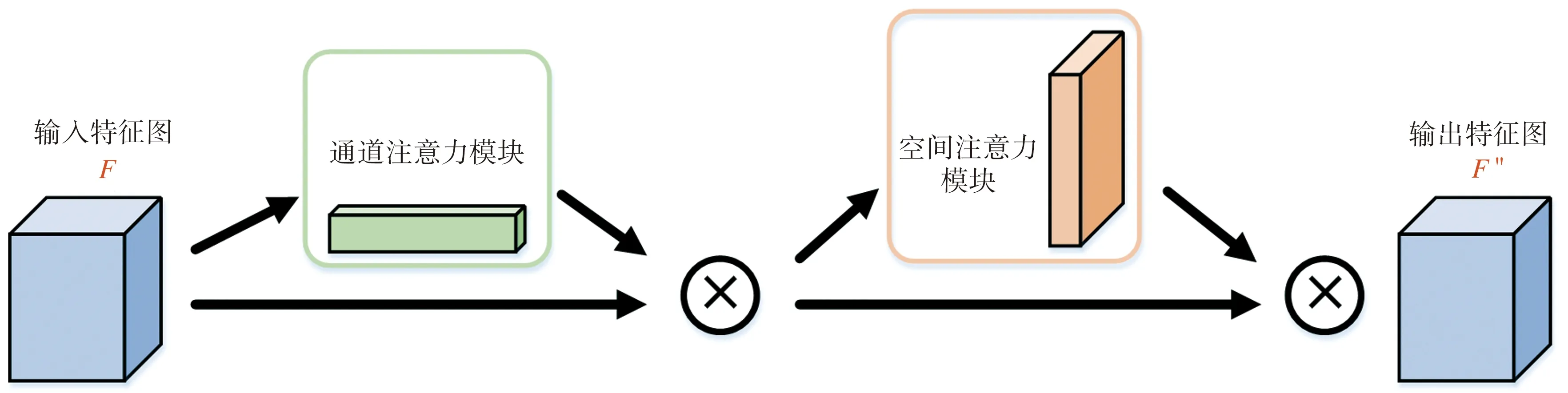
图3 卷积注意力机制模块
通道注意力模块的网络结构如图4所示。首先将输入特征图F分别经过平均池化层和最大池化层以聚合输入特征图的空间信息,得到平均池化和最大池化特征,再分别通过一个共享网络,共享网络由多层感知机(multilayer perceptron, MLP)和一个隐藏层组成。将共享网络输出的特征做逐元素求和,经过sigmoid激活操作,产生F的通道注意力一维卷积Mc(F)。

图4 通道注意力模块
空间注意力模块如图5所示,其输入为经过通道注意力增强的特征图F′。首先,将F′通过最大池化和平均池化来聚合特征图的通道信息,生成两个二维特征图,分别表示特征图在通道中的平均池化特征和最大池化特征;然后通过标准的卷积层进行连接和卷积操作,经过sigmoid激活函数生成F′的空间注意力二维卷积Ms(F′)。
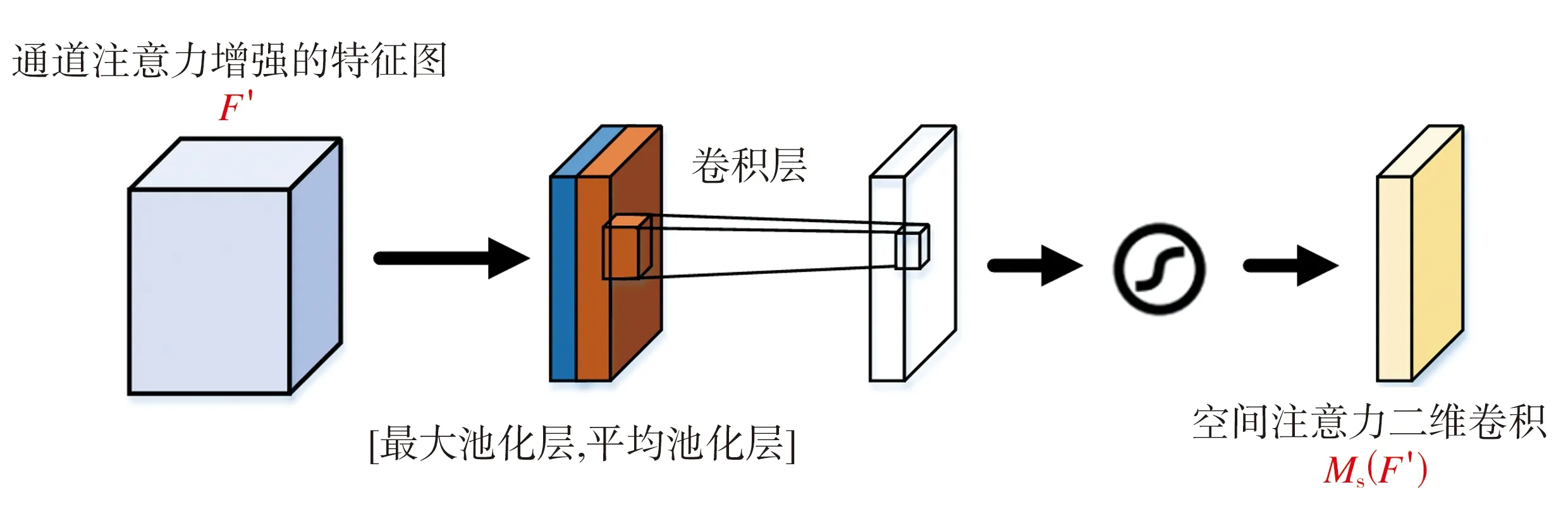
图5 空间注意力模块
卷积注意力机制的整体过程可以表示为:
Mc(F)=σ[MLP(AvgPool(F))+MLP(MaxPool(F))]
(1)
F′=Mc(F)⊗F
(2)
(3)
F″=Ms(F′)⊗F′
(4)
式中:AvgPool和MaxPool分别代表平均池化和最大池化操作,MLP代表多层感知机,⊗代表逐元素乘法操作,σ代表sigmoid激活函数,f7×7代表卷积核大小为7×7的卷积运算。
1.4 双判别器模型
生成器G根据设计的损失函数使生成的融合图像f尽可能多地保留红外图像i的高亮信息和可见光图像v的纹理细节信息。GAN网络中的判别器是用来与生成器进行对抗,在对抗训练过程中指导生成器的参数更新,使融合图像中的信息更加丰富。红外图像与可见光图像的成像机理不同,本文针对两种图像的模态差异设计了两个判别器Di和Dv,将融合图像与红外图像和可见光图像分别进行判别。判别器网络架构如图6所示,双判别器内部共享相同的网络结构,输入分别为红外图像与融合图像或者可见光图像与融合图像。判别器包括4个卷积层,第1层到第3层中的卷积核大小均为3×3,步长设置为1,最后一层为tanh激活函数与全连接层(fully connected layer, FC),判别器会从输入的图像中提取特征并进行特征分类,全连接层将特征进行整合,tanh激活函数生成一个标量(Scalar),代表判别结果,即输入图像来自源图像而非融合图像的概率。

图6 判别器网络结构
2 损失函数
生成器的目标是要在融合图像中尽可能多地保留源图像的丰富信息,使得判别器无法对二者进行区分。生成器的损失函数由生成器与判别器之间的对抗损失Ladv(G,D)和生成器自身的内容损失Lcon构成。对抗损失的计算如式(5)~式(7)所示:
Ladv-i,f(G,Di)=E[log(1-Di(G(v,i)))]
(5)
Ladv-v,f(G,Dv)=E[log(1-Dv(G(v,i)))]
(6)
Ladv(G,D)=Ladv-i,f(G,Di)+Ladv-v,f(G,Dv)
(7)
这里E代表期望。
在图像复原过程中,图像中的一点点噪声可能就会对复原结果产生非常大的影响,因此需要通过内容损失函数来保证图像的光滑性。内容损失Lcon的设计结合Frobenius范数和全变分模型,前者从像素强度方面来约束融合图像与红外图像的相似度,后者能有效消除图像复原过程中可能产生的伪影,使融合图像尽可能多地继承可见光图像的信息,Lcon的计算如式(8)所示:
η||G(v,i)-v||TV]
(8)
式中:η代表平衡像素强度与可见光信息的权重系数,下标F代表Frobenius范数,下标TV代表全变分(Total Variation)范数,G(v,i)代表生成器生成的融合图像,φ(x)代表提取x的特征图。
3 实验与结果评价
3.1 数据集与实验设置
在训练阶段,从经过矫正配准的锌渣图像数据集中选取10对不同场景下的红外与可见光图像作为基础训练数据,通过滑窗方式裁剪原始图像进行数据增强,最终得到3060对分辨率为84×84的红外与可见光图像作为本文实验的训练集。在训练过程中,批次大小设为12,优化器选择Adam Optimizer,训练阶段总共包含255个epoch,初始学习率设为0.0001。实验环境配置如下:操作系统为Win10专业版,显卡为GeForce RTX 3080Ti,内存为16 GB,采用TensorFlow和OpenCV深度学习开源框架搭建网络环境。
在测试阶段,选取锌渣红外与可见光图像作为测试集,输入训练好的生成器进行图像融合。
3.2 对比实验
本文选取多种传统图像融合算法和基于深度学习的图像融合算法进行对比实验,对比算法包括VSM-WLS[1]、红外特征提取(IR-Feature)[3]、CNN[4]、MDLatLRR[2]、U2Fusion[6]、FusionGAN[7]、IFCNN[5]。部分实验结果如图7所示,图中(a)~(d)代表所选取的4幅状态或区域不同的锌渣图像,红外图像中较暗的部分为待捞渣区域,高亮部分为锌渣分布较少的区域,图中第三到第十行均为不同算法得到的融合图像。

图7 不同算法的图像融合效果对比
从图7可以发现,几种算法得到的融合图像有明显差异。由于锌渣图像的特殊性,红外特征提取算法的融合策略在部分区域产生红外与可见光特征相互干扰、融合特征选择错误的问题,导致融合图像对比度失真现象严重;VSM-WLS、CNN、MDLatLRR、U2Fusion和IFCNN算法有效避免了上述问题,融合图像具有较好的对比度,能够突出锌液中的待打捞区域,背景的纹理信息也较为充分,但对于液面区域的细节纹理信息恢复不够全面,无法有效体现液面待打捞状态。图7(b2)和图7(c2)中存在光照不均匀的区域,上述几种方法在融合过程中不能较好地克服这个问题,无法正确判断高强度光照区域,导致在图7(b3)~图7(b8)和图7(c3)~图7(c8)中,本该打捞的厚渣区域呈现出错误的高亮信息,这会对后续的捞渣作业产生不利影响。FusionGAN与本文方法是利用生成对抗网络的原理完成图像融合任务,通过判别器反复对融合图像与可见光图像进行比较,能够较好地解决光照不均匀的问题,得到较高质量的融合图像。FusionGAN使用单判别器,导致融合图像更趋近于红外图像的像素分布,缺乏纹理细节信息,且融合图像过于平滑,视觉效果模糊。本文算法在生成对抗网络的基础上采用了双判别器分别与红外图像和可见光图像进行判别,融合图像具有较好的对比度,在突出待打捞区域的同时又包含了丰富的纹理细节信息,整体图像更倾向于真实的锌渣液面,便于人眼观察识别。
以上定性评价方法具有主观意识强、易受外界环境干扰等缺陷,需要与客观的定量评价标准相结合来对融合图像进行综合评价,本文选取的定量评价指标如下[10-15]:
(1)信息熵(entropy, EN)
EN是一种衡量图像中信息量多少的指标,熵值越大表示融合图像的信息越丰富,融合效果越好。
(2)互信息(mutual information, MI)
MI用来衡量融合图像获取自源图像的信息量,互信息的数值越大表示融合图像保留了更多的源图像特征,融合效果也更好。
(3)差异相关性总和(sum of the correlations of differences, SCD)
SCD是一种衡量融合图像包含源图像互补信息量的指标,值越大表明融合图像包含源图像的互补信息量越多,融合效果也就越好。
(4)图像融合质量指数(quality assessment of fused images, Q(a,b,f))
Q(a,b,f)是一种较为新颖的融合图像客观非参考质量评估指标,它利用局部度量去估计来自输入的关键信息在融合图像中的表现程度,其值越高表示融合图像的质量越好。
(5)峰值信噪比(peak signal to noise ration, PSNR)
PSNR用于衡量图像有效信息与噪声的比率,能够反映图像是否失真,PSNR值越大表示融合图像的质量越好。
(6)结构相似度(structural similarity index measure, SSIM)
SSIM是衡量两幅图像相似度的指标,SSIM将失真建模为亮度、对比度和结构3个不同因素的组合,用均值作为亮度的估计,用标准差作为对比度的估计,用协方差作为结构相似程度的度量。SSIM的数值范围为-1~1,越接近1表示两张图像越相似。
表1为不同融合算法在锌渣数据集上的定量评价指标统计结果,表中数值为多幅融合图像指标的平均结果,最优值用粗体显示,次优值用斜体显示。从表1可以看出,相比于其他算法,本文算法有4个指标达到最优,1个指标达到次优。这表明本文算法针对锌渣数据集达到了较好的融合效果,融合图像信息量最多,包含源图像的互补信息最多,并且融合图像的细节特征较为丰富,更符合人眼视觉的感知特性。
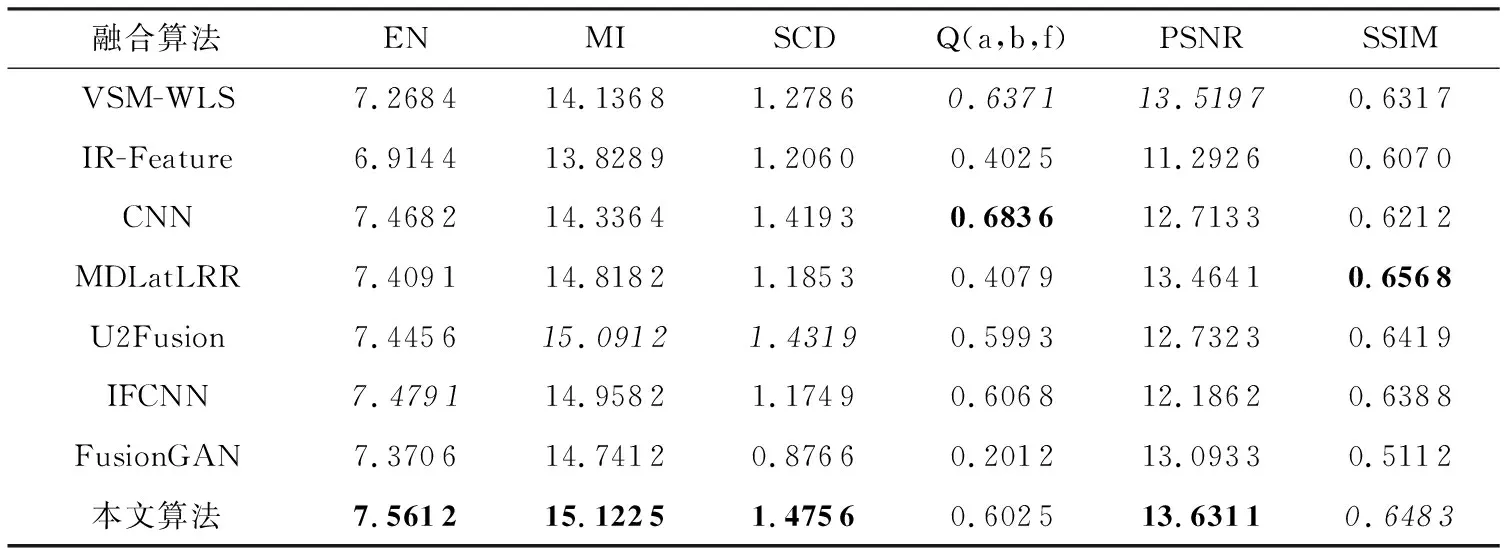
表1 不同算法所得融合图像的定量评价指标
表2为不同算法融合多张图像所需的平均时间,可以看出几种算法在运行效率上存在一定差异。由于CNN算法是直接利用卷积神经网络提取源图像的深度特征来生成融合图像,故而所需时间远多于其他算法;IR-Feature算法所需时间虽然最短,但由图7可知,其融合图像存在明显失真,无法保证融合质量;其余算法所需时间基本处于同一量级。以上结果表明,本文算法在提升图像融合质量的同时还能够兼顾运行效率,具有较为全面的性能表现。

表2 不同算法融合图像的平均时间
3.3 消融实验
为了进一步验证本方法中卷积注意力机制模块和双判别器的有效性,下面使用锌渣图像数据集进行消融实验,采用4种不同的融合模型:①无卷积注意力机制模块且单判别器(no_CBAM &single_dis)、②无卷积注意力机制模块且双判别器(no_CBAM &double_dis)、③有卷积注意力机制模块且单判别器(CBAM &single_dis)、④有卷积注意力机制模块且双判别器(CBAM &double_dis)。同时,还对不同网络模型训练阶段所需时长Ttrain进行统计分析,以验证本文方法的实用性。
表3所示为4种模型在锌渣图像数据集上的客观评价指标及Ttrain。双判别器能够丰富融合图像的特征信息,CBAM机制有助于选择关键特征,二者原则上都能一定程度地提升图像融合质量。然而,由表3中数据可以发现,双判别器网络no_CBAM &double_dis在融合图像的部分性能指标上反而劣于单判别器模型no_CBAM &single_dis,其原因在于,工业场景存在光照不均匀的情况,低温的厚渣区域由于强光照射,在图片中变成了高温区域,从而导致红外图像中出现冗余和错误信息,最终影响了网络模型的融合性能。双判别器模型的优势在于特征提取能力强,与CBAM机制相结合,才能更好地突出红外与可见光源图像中的关键信息,抑制冗余和错误信息,使融合图像保留更多有效的红外热辐射信息与可见光纹理信息,从而提升图像的融合质量。另外,本文算法结合了双判别器模型和CBAM模块,增加了网络模型复杂度,导致模型训练阶段时间有所延长,但增加幅度较小,且不会对测试阶段造成影响,得到的融合图像在各项指标上均有一定的提升,验证了算法的有效性和实用性。

表3 消融实验结果
4 结语
本文提出了一种结合双判别器生成对抗网络与卷积注意力机制的红外与可见光图像融合算法,用于热镀锌生产线上锌池捞渣工艺中的锌渣识别阶段,以改善恶劣的工业环境下红外或可见光成像设备无法提供清晰图像的情况。该算法在生成对抗网络中使用双判别器结构,使融合图像尽可能多地保留红外与可见光源图像的特征信息;同时引入卷积注意力机制,在特征提取过程中增强对关键特征的表达,从而提高红外与可见光图像的融合质量。与其他主流图像融合算法相比,本文算法获得的融合图像既能通过丰富的热辐射信息确定厚渣的位置,又包含了锌渣的纹理细节信息,其主观可视性和定量评价指标都得到一定程度的改善,能够为智能化捞渣作业后续的目标识别和检测等任务提供有效的技术支撑。
猜你喜欢
环球时报(2022-05-23)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
金桥(2021年4期)2021-05-21
电子制作(2019年11期)2019-07-04
电子制作(2019年7期)2019-04-25
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
光学精密工程(2016年3期)2016-11-07
第二课堂(课外活动版)(2016年2期)2016-10-21
