
基于数据挖掘的“互联网+”软件设计
2023-06-17 08:23孙玉翡
中国新技术新产品 2023年7期
孙 畅 曹 慧 黄 丹 孙玉翡 李 野
(1.齐齐哈尔工程学院健康与护理系,黑龙江 齐齐哈尔 161006;2.齐齐哈尔工程学院信息工程系,黑龙江 齐齐哈尔 161006)
互联网+给各行各业提供了极大的便利[1]。通过与互联网对接,可以集合更丰富的信息资源和数据,从而提高决策判断依据的全面性和可信性[2]。但是,互联网上的信息非常丰富,海量的数据会造成大幅度冗余。为了更好地利用互联网+技术,经常要配套使用数据挖掘技术[3]。随着二胎政策的放开,新生儿的出生率提高,这就加大了助产行业的技能需求。助产技能的传统培训方式存在效率低、效果差、成本较高以及需要依赖大量的人工和昂贵的设备等缺点。因此,该文提出基于“互联网+”的软件设计思路,借助互联网上可以提供的各种资源完成助产技术培训。基于互联网中丰富的相关资源,该文还将在软件设计中引入“数据挖掘”技术,以提高软件的性能。
1 互联网信息的数据聚类
互联网+技术最突出的特点就是可以充分利用互联网提供的丰富信息。但是,互联网信息也有真伪信息共存、冗余信息多以及有用信息少的问题。因此,为了使“互联网+”软件更好地利用互联网的特点,规避互联网的不足,必须要对互联网信息进行数据挖掘。数据挖掘技术的重要前提就是对同一类别或近似类别的数据进行聚类。
为了实现数据聚类,出现了均值聚类的方法。该方法对每类数据类别设定一个特定的表征值,这个值就代表这个数据类。当要执行一个新数据类别的判断时,就计算新数据和各个数据类别表征值的距离,距离最小的那个类别就是新数据所属的类别。
在均值聚类的过程中,每个数据类别的表征值设定非常重要,它决定了新数据类别判断的准确性和可信度。在正常情况下,每个数据类别的表征值是类内各数据的中间值位置。但是,对不同的聚类问题来说,类内数据中间值并不一定就是最准确的表征值,还需要根据设定的条件进行进一步优化和调整。如果在调整过程中,无论如何更新处理,表征值的合理位置都不再变化或者变化非常小,那么可以确认这个表征值是合理的。
因此,均值聚类方法具体的实现流程如下:1) 先将已知数据确定分割为多个类别,每个数据类别设定一个表征值,这个表征值先以数据类别的中间值作为初始值。2) 根据各个类别表征值的初始值计算每个数据类别内的数据以及与这个表征值之间的距离。并以计算结果和事先设定的判定依据进行比较,如果比较所得的误差大于或等于设定好的域值,就要更新表征值的位置。3) 反复执行上一个步骤的处理,直到每个数据类别的表征值都不再变化为止,那么这个表征值确定可以代表对应的数据类别。
在这个过程中,确定每个数据类别的表征值后,可以形成下面的类别表征值集合,如公式(1)所示。式中:C为全部数据类别表征值的集合;Ck为第k个数据类别的表征值;k为表征值和数据类别的序号;K为数据集合包括的全部类别。
根据表征值可以将各个数据归入各个数据类别,进一步设定每个数据类别的中心,从而计算每个数据类别中的数据与这个中心的距离,如公式(2)所示。
式中:Ck为第k个数据类别的表征值;J(Ck)为1 个数据类别中全部数据与类中心之间的距离和;xi为这个集合中的任意一个数据;μk为第k个数据类别的中心。
随着数据的不断更新,数据聚类就体现为全部数据聚类的一个距离计算,由此可以得到各个聚类距离和,当这个和达到最小值时,全部数据的聚类过程结束,这一过程的描述如公式(3)所示。
式中:J(Ck)为1 个数据类别中全部数据与类中心之间的距离和;J(C)为全部数据类别中全部数据与类中心之间的距离和;k为表征值和数据类别的序号;K为数据集合包括的全部类别。
2 互联网信息的数据挖掘
有了数据聚类作为基础,互联网信息就可以进行进一步的数据挖掘。数据挖掘领域有很多技术和算法,AP 算法一般与均值聚类配合使用,以完成进一步的数据挖掘任务。AP 算法的核心思想就是检索每个数据的多次出现频率项,这个项体现了这个数据在整个互联网中被采信的程度。因此,数据对应的多次出现的频率项是该数据被再一次访问或使用的重要的先验知识。
显然,一个数据多次出现的频率项的数值越高,其再次被采信的可信度也越高;一个数据多次出现的频率项的数值越低,其再次被采信的可信度也越低。在AP 算法中,个数据多次出现的频率项具有以下属性:1) 如果一个集合不是数据多次出现的频率项的集合,那么它的上一级集合也不可能是数据多次出现的频率项的集合。2) 如果一个集合是数据多次出现的频率项的集合,那么它的上一级集合也是数据多次出现的频率项的集合。
根据上面的属性,通过不断地延伸一个数据集合内数据多次出现的频率项的集合,就可以构建完整的AP 算法。AP 算法的突出优势如下:1) 不管数据集合的规模是大还是小,也不管数据集合在后续发生何等规模的改变,数据对应的多次出现的频繁项都可以被准确确定并且可以支持进一步的剪枝处理。2) 各个集合的上下关联关系与阈值的设定有统计学意义,而这一个阈值对应最小可信度,这给整个算法提供了非常高的可信性。基于AP 算法的数据挖掘过程如图1 所示。

图1 基于AP 算法的数据挖掘过程
根据上述的AP 算法,给出一个具体的数据挖掘实例:一个新的数据集合中存在{数据项A数据项B数据项D}并且存在这样的一系列子集合:{数据项A},{数据项B},{数据项D},{数据项A数据项B},{数据项A数据项D},{数据项B数据项D}。这样可以计算出各个集合对应的置信度关系:数据项A∧数据项B→数据项D,由此推导出置信度为2/2=1;数据项A∧数据项D→数据项B,由此推导出置信度为2/4=0.5;数据项B∧数据项D→数据项A,由此推导出置信度为2/3=0.667;数据项A→数据项B∧数据项D,由此推导出置信度为2/4=0.5;数据项B→数据项A∧数据项D,由此推导出置信度为2/4=0.5;数据项D→数据项A∧数据项B,由此推导出置信度为2/5=0.4。
如果已经在AP 算法中设定了阈值为0.6,那么可以挖掘出各数据项的关联关系,见表1。

表1 各数据项的关联关系
3 互联网+软件设计结果与测试
在数据聚类和数据挖掘的基础上,将互联网资源接口引入其中,进行互联网+的软件设计。主要是以助产培训为目的,因此涉及的就是如何建立软件平台,借助数据挖掘算法从互联网选择最适合助产培训的视频资源和文本资源。
从用户对软件使用的角度来看,其一般需求可以分为以下2 类:1) 用户的第一类需求。获得互联网+软件平台的使用权。因此,用户应该可以在互联网+软件平台进行注册,包括基本信息的录入、登陆安全的设定等。用户通过注册就可以获得互联网+软件平台的资源访问权。当然,这种访问权限的高低与用户等级有统计学意义。而用户等级的配置设置为一般型和特殊型,一般型通过注册即可以获得,所得权限为访问互联网+软件平台的基本权限。特殊型用户须由后台管理员审核确认。2) 用户的第二类需求。如何从互联网+软件平台中获得自己想要的资源。这取决于3 个方面的因素,一是用户提供的检索词的准确性,即能否最准确地对自己的需求进行描述;二是软件平台资源的丰富程度,该文的软件平台嵌入了互联网资源,资源相当丰富;三是软件平台数据挖掘算法的有效性,挖掘算法的效果越好,能得到的资源越准确。
根据上述需求,该文对互联网+软件平台的功能架构设计如图2 所示。由图2 可知,该文设计的互联网+软件平台的主要功能分别针对用户和管理员进行设计。其中,用户对应的功能设计包括用户帐号注册功能、用户帐号维护功能、助产培训资源浏览功能、助产培训资源查询功能、助产培训资源下载功能以及助产培训资源预订功能。管理员对应的功能设计包括用户信息管理功能、助产培训资源管理功能、助产培训资源推荐功能以及系统其他维护功能。其中,助产培训资源推荐功能就是通过AP 数据挖掘算法实现的。
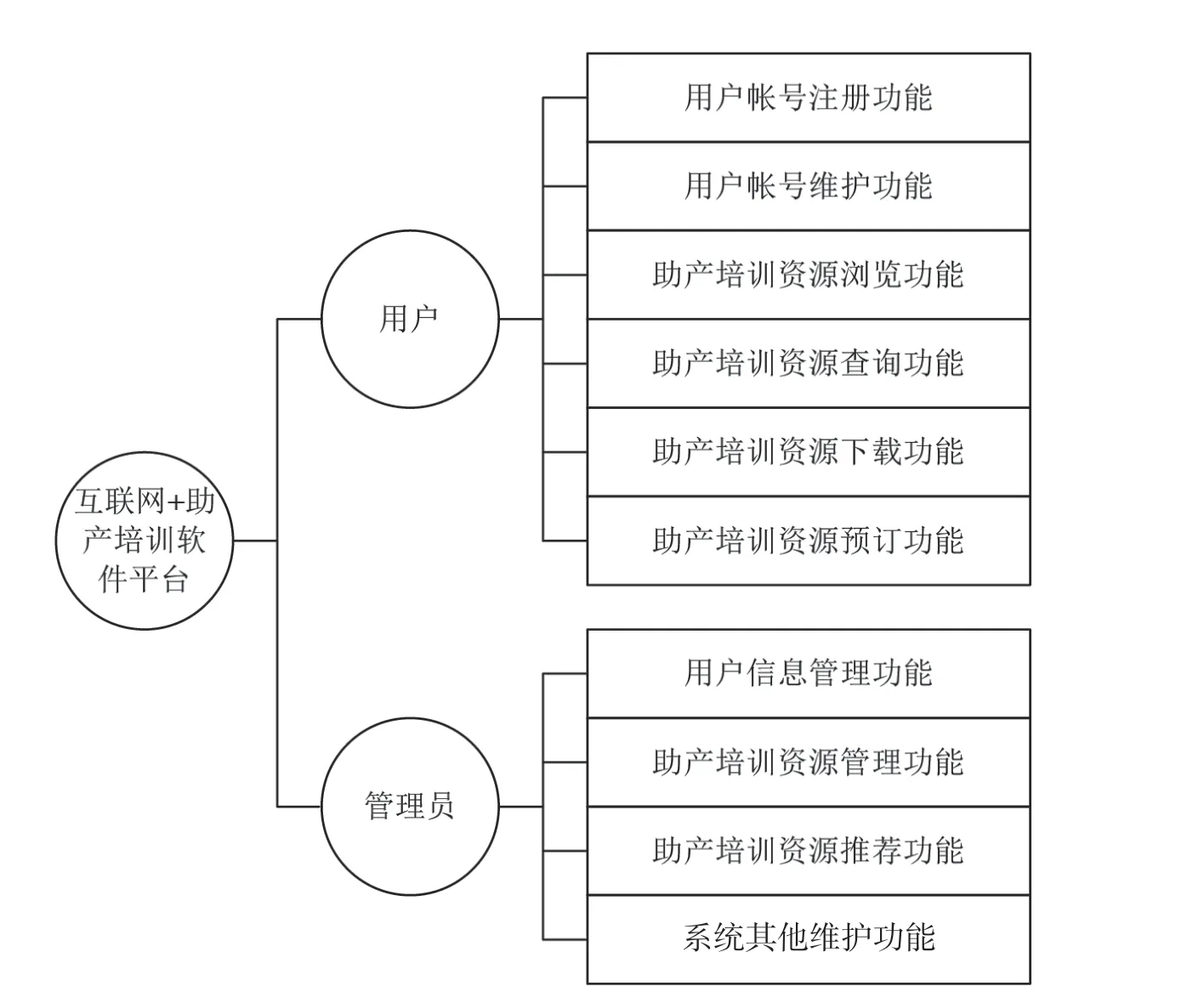
图2 互联网+软件平台的功能架构设计
采用B/S 模式设计用户与管理员之间的关联关系,既便于用户和管理员的对接,又便于访问互联网资源。
AP 算法可以完成用户需求的推荐,是整个软件平台的核心功能。为了实现从用户需求到最终资源的推荐,需要建构各项功能的ER 数据库关系,如图3 所示。由图3 可知,该文设计的互联网+软件平台的各功能模块对应形成的ER 数据库模块及关联关系如下:1) 用户可以直接访问平台提供的互联网接口,从而可以从互联网上获得助产培训的文本信息或助产培训的视频资源。2) 用户也可以利用预订功能预订助产培训资源,管理员会根据用户需求和AP数据挖掘算法,从互联网中资源总库中找到用户最需要的培训资源,形成新增助产培训资源发送至互联网端,从而被用户访问。
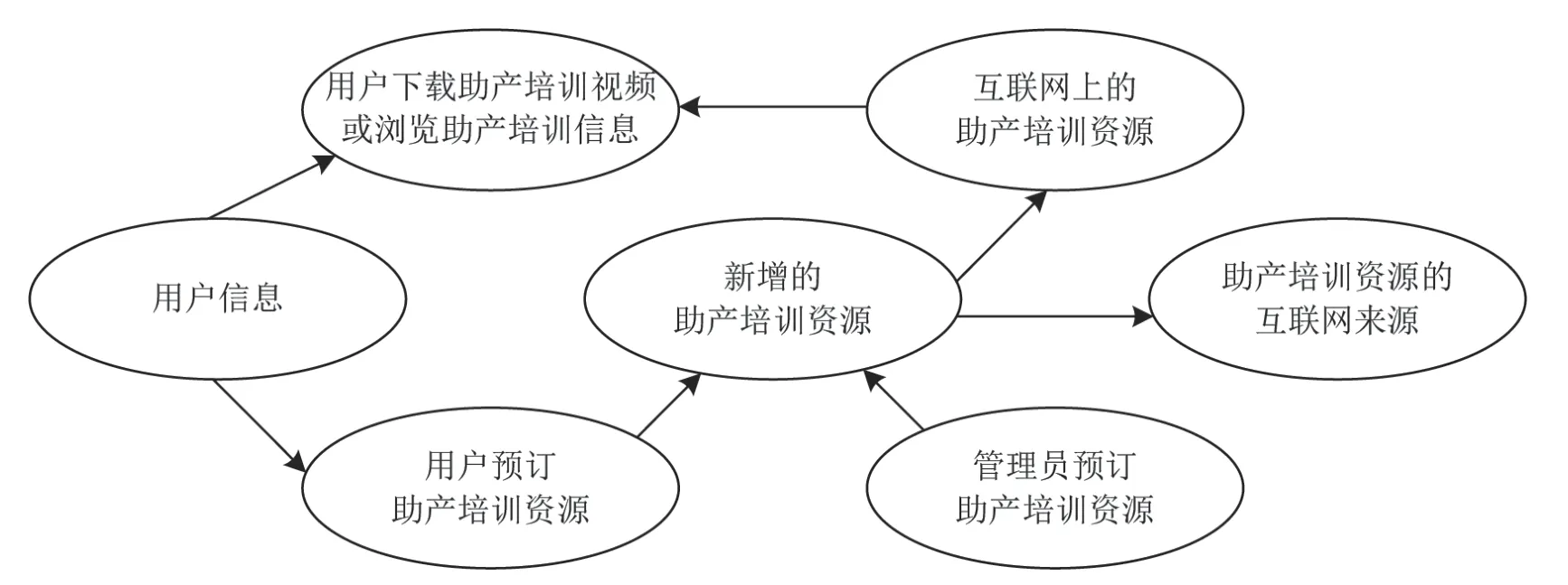
图3 互联网+软件平台的ER 数据库关系图设计
4 结语
借助互联网+技术可以充分利用丰富的互联网资源,但是互联网中数据信息规模过于庞大,需要借助数据挖掘算法来进行整理、归类和分析。首先,该文阐述了聚类分析方法的实现过程,给出了聚类分析的流程,给进一步的数据挖掘算法使用奠定了基础。其次,阐述了AP 数据挖掘算法的原理,并给出了基于数据多次出现的频率项的挖掘过程,通过一个案例计算了不同挖掘结果的置信度。最后,进行了基于数据挖掘的互联网+软件设计,给出了软件平台的各个功能模块设计,构建了各个模块之下的ER数据库关系图。
猜你喜欢
中国应急管理科学(2022年1期)2022-04-18
智慧健康(2021年33期)2021-03-16
中华养生保健(2020年3期)2020-11-16
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
中国优生优育(2014年8期)2014-01-20
