
基于语义分割与实例分割的玉米茎秆截面参数测量方法
2023-06-20 04:40胡小春王令强
农业机械学报 2023年6期
陈 燕 李 想 曹 勉 胡小春 王令强
(1.广西大学计算机与电子信息学院, 南宁 530004;2.广西多媒体通信与网络技术重点实验室, 南宁 530004;3.广西财经学院大数据与人工智能学院, 南宁 530007; 4.广西大学农学院, 南宁 530004)
0 引言
维管束为植物体输送水分、无机盐和有机物质,在“库-源-流”系统中扮演“流”的重要角色[1]。玉米茎秆倒伏与茎秆微观表型,如截面面积、截面不同区域的面积占比、维管束数量和各维管束面积等性状密切相关[2]。机械组织比例等表型性状影响茎秆的机械强度[3],从而影响作物的抗倒伏性能。由于大规模获取茎秆截面微表型参数工作量大、效率低、测量指标有限,作物的倒伏研究主要局限在茎秆的形态学性状和力学指标,而对茎秆的组织解剖学特征研究则较少[4]。
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术。图像分割方法是对图像中属于特定类别的像素进行分类的过程。通过对图像的分割,以充分理解图像中的内容,便于对图像各部分的关联性进行分析。传统的图像分割方法基于灰度值的不连续和相似的性质,易受限于特定的图像特征而欠缺泛化能力;基于深度学习的图像分割技术是利用卷积神经网络(Convolutional neural network,CNN)强大的特征提取能力来理解图像中每个像素所代表的真实物体[5],从而具有较好的稳健性和适应性。基于深度学习的图像分割有语义分割与实例分割,皆可在像素级别区分物体轮廓。TERAMOTO等[6]用基于U-net的语义分割方法识别沟槽剖面图内的水稻根系分布。FETTER等[7]提出一种使用深度卷积神经网络的系统来识别和统计银杏显微图像中的气孔,识别准确率达到98.1%,提供了针对作物微观表型智能化研究范例。刘文波等[8]提出改进SOLO v2的实例分割方法对番茄叶部病害进行分割和识别,可保证算法的实时性和准确性。熊俊涛等[9]用Mask R-CNN对大豆叶片进行实例分割,平均分割准确率达到88.3%。文献[10]列举了深度学习在作物表型研究中具有代表性的工作,为作物表型的智能化识别提供了稳健的解决方案。
基于深度学习方法在特征提取方面的优势明显,无需对特征进行设计就可以实现对图像特征的提取,但目前应用于作物微表型识别或组织解剖学特征的研究还很少。目前对作物茎秆微表型结构参数的获取和分析普遍采用显微镜[11]或作物成像专用电子计算机断层扫描(Computed tomography,CT)[12]获得茎秆截面微表型图像,再利用传统图像分割方法对图像进行处理。徐胜勇等[13]使用基于OpenCV的滤波、边缘检测等操作,对各个组织结构进行独立的阈值分割、拼接等操作,以此为基础测量各种参数,并将各种参数、性状特征进行统计分析。赵欢等[14]利用基于图形学的区带表型解析方法,可获取茎秆不同节间相关表型的多项指标。但此类方法对图像目标与背景色差弱或亮度差异小,存在气泡、过曝或曝光不足时,所获性状参数易出现较大误差。目前仅有文献[15]和文献[16]是基于CNN对作物微表型识别进行研究。WU等[15]利用作物CT成像并基于SegNet 架构的语义分割水稻茎秆微表型,用于提取水稻茎秆性状特征参数。陈燕等[16]基于U-net架构的语义分割对普通光学显微镜成像的小麦茎秆截面的组织结构进行分割和量化,获得小麦维管束和功能区域的表型参数,为获取小麦茎秆的微表型参数提供了较为准确的方法。
虽然语义分割和实例分割都可在像素级别对物体进行分割,但是语义分割只能分割一类对象,导致无法区分同一类别之间的不同对象;而实例分割可针对特定物体的像素进行分类、直接分割出不同个体,从而可区分不同的实例个体。玉米茎秆截面的维管束分布密集,后期需要获得每个维管束的质心、面积性状参数等,除了要识别出维管束,还需区分他们的不同个体。文献[16]提出的语义分割方法可以识别截面的维管束,但相邻较近的个体易被识别为同一个维管束实例。
目前较为成熟的实例分割方法以Mask R-CNN[17]为代表,其分割目标通常为自然场景物体,适用于检测数量少、物体形状尺寸差异较大的目标。但玉米茎秆截面微表型参数的数量大、面积小且分布密集,已有的实例分割方法并不直接适用。而且,以Mask R-CNN为基础的网络普遍存在架构设置不适用、推理速度较慢、占用显存较多的问题[17]。因此,本文选用具有复合扩张能力的EfficientDet[18]作为基础网络架构,增加掩膜分支以实现实例分割,通过减少输出特征图的尺度数量构造新的实例分割网络Eiff-BiFPN,以提高推理速度、减少显存的占用,从而实现对维管束的分割。文献[16]对截面功能区域的分割是以MobileNet作为骨干网络,但文中对小麦的截面只分为2个功能区域,识别难度较低,适合选用较为轻量型的MobileNet网络。由于玉米茎秆截面需要分成表皮、周皮和髓区3个区域,而且不同功能区域之间还具有易混淆性,如果直接将文献[16]的功能区域分割网络用于玉米茎秆截面的功能区域分割,其准确率较低。因此本文选用提取特征能力更强的ResNet[19]作为骨干网络,并与Unet[20]融合成为Res-Unet网络模型用于玉米茎秆截面的功能区域分割。
1 数据集获取与处理
1.1 数据集来源
数据集包含116份不同的玉米种质材料,由广西农业科学院玉米研究所和广西大学提供,品种有美玉27、天桂糯932、福华甜、CML161、CML171、Gui39722、Guizhao18421、PH6WC和昌7-2等,可代表温带和亚热带地区主要的玉米种质资源。各玉米品种在试验田的种植密度每公顷约75 000株,行长3 m,行宽0.65 m,每行种植15株,水肥管理同大田生产。
玉米节间茎秆徒手切片,厚度0.2~0.5 mm,用5%间苯三酚(乙醇与水的体积比为95∶5)和浓盐酸染色,染色时间2 min,steREO Discovery.V20体视显微镜拍照,放大倍数为6.7~15,图像存储格式为TIF,分辨率为1 790像素×1 370像素。共获取图像180幅,其中113幅来自不同种质材料的抽雄期茎秆自顶向下最后3个节间,其余67幅来自剩余3种样本材料处于不同生长期的茎秆。因此,数据集中的图像具有茎秆解剖特征的多样性。
1.2 图像标注
使用Labelme工具对每幅图内维管束的轮廓和功能区域的轮廓进行标注,将玉米茎秆截面分为表皮区、周皮区、髓区3个区域,得到的标注图样例如图1所示。为了全面地验证模型效果,数据集按独立同分布的原则划分,选择156幅作为训练集,其余24幅样本作为验证集。
2 网络结构设计
本文用于玉米截面分割的网络模型由两部分组成,第1部分用于功能区域分割,以ResNet作为基准网络,并与Unet融合成Res-Unet网络,用于检测、分割表皮、周皮和髓区3个功能区域;第2部分用于维管束的分割,以EfficientNet为基准网络,改变BiFPN的连接方式和层数,增加掩膜输出分支,用于检测、分割每个维管束实例。
2.1 功能区域分割网络模型
功能区域分割用语义分割方法。选用ResNet作为骨干网络,并与Unet融合成为Res-Unet网络模型,用于分割截面的表皮区、周皮区和髓区。功能区分割网络模型Res-Unet由解码器和编码器两部分组成,网络结构如图2所示。输入玉米茎秆截面样本的彩色图像,经过图像预处理和图像增强操作之后,通过编码器ResNet对输入图像进行下采样,获取4种尺度分别为16×16×2 048、32×32×1 024、64×64×512、128×128×256的特征图,经过特征融合与拼接后,输出所有功能区域分割后的彩色掩膜。
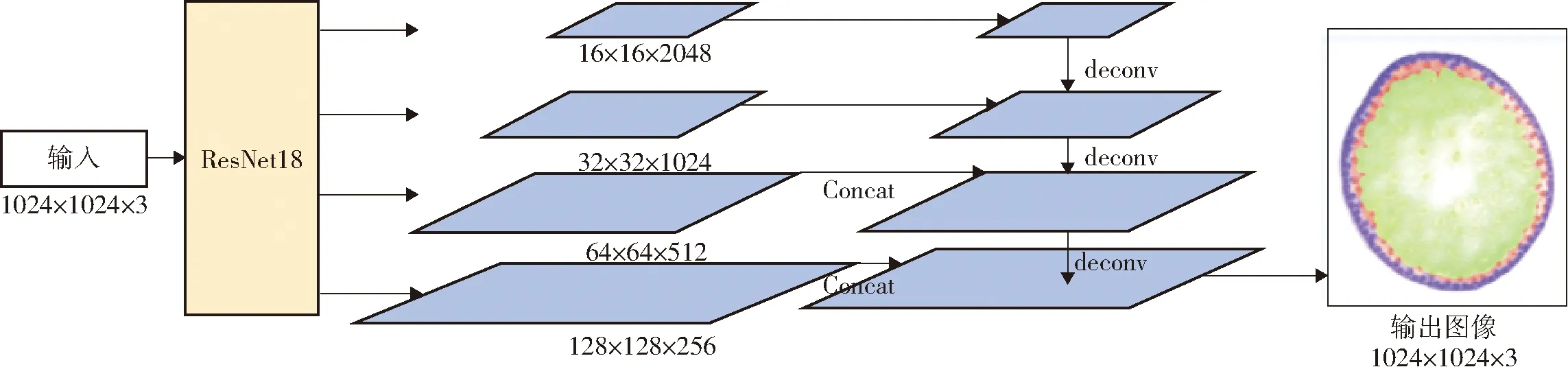
图2 功能区域分割网络模型Fig.2 Architecture of function zone segmentation network
编码器的基础卷积块由残差模块组成,使用恒等映射使卷积层在输入特征的基础上学习新的特征,再提取图像的语义特征,如轮廓、边缘、颜色等信息。解码器对编码器生成的特征图进行拼接,再利用浅层网络中的语义信息辅助位置信息对图像进行分割,并将特征精确定位并映射到图像上。为了减少冗余计算量,根据分割结果将样本图裁剪为该玉米茎秆截面的最小外接矩形截图,作为第2部分模型的输入。
2.2 维管束分割网络模型
维管束分割采用实例分割方法,选用具有复合扩张能力的EfficientNet[21]作为基准网络,在双向特征金字塔BiFPN[18]结构中减少输出特征图的尺度数量,通过改变内部的连接方式以高效提取图像特征,同时添加基于锚框的边界框输出分支(Box head)和类别输出分支(Class head)两部分,然后由检测框(Proposal boxes)输出到掩膜输出分支(Mask head),构建基于目标检测的实例分割网络Eiff-BiFPN,具体结构如图3所示。将图像输入基准网络后,通过BiFPN获得3种不同尺寸的特征图,经过检测输出、分类输出与分割输出分支结构得到最后的维管束分割结果。

图3 维管束分割网络模型Fig.3 Architecture of vascular bundles segmentation network
2.2.1基准网络
深度学习算法大都通过扩大网络规模来提升网络泛化能力,提高预测精度。扩大卷积网络结构只对网络的深度、宽度和分辨率参数进行微调。为了在有限的计算资源内获得更高的精度,同时也为了减少调参的工作量,EfficientNet从网络的深度d、宽度w(通道数)和输入图像的尺寸r(分辨率)3个维度上进行复合扩张。网络深度、宽度和分辨率的缩放存在如下关系
(1)
式中dratio——网络深度缩放系数
wratio——宽度缩放系数
rratio——分辨率缩放系数
φ——缩放系数
设定φ=1,通过网格搜索得到dratio、wratio和rratio的最优解,通过相应的d、w和r构造了最小网络规模的最优模型B0[19]。φ越大,网络的3个维度扩张越多,模型消耗的资源也越大,模型的精确度也越高,φ取值为1~7的整数。
2.2.2改进的BiFPN结构
特征图金字塔(FPN)[22]可对经过骨干网络后得到的不同尺寸的特征图进行多尺度加权的特征提取与融合。BiFPN为双向特征图金字塔结构,除保持FPN自上而下和自下而上的连接外,增加了特征图之间的跨层和跳跃连接。与FPN相比,BiFPN的特征提取能力更强,网络参数更少,运行速度却更快。
文献[19]采用5层BiFPN结构,先将P5进行下采样生成P6和P7,再将P3~P7共5层的特征图进行融合。但由于P6和P7的尺寸只占原输入的1/64与1/128,分辨率太小,在下采样过程中容易丢失小目标的特征信息,P6和P7两层不适用于针对维管束这类小目标的检测任务,因此本文改变了原来的BiFPN结构及其内部的连接方式,只保留3层的BiFPN结构。具体结构如图4所示,仅将P3~P5共3层的特征图进行融合,使网络更好地学习到小目标信息,提升维管束边缘细节的分割效果。其中蓝色箭头和红色箭头为跨层连接,弧线形箭头为跳跃连接。灰色虚线框是一个基本单元,左边白色一列为各层的输入,中间一列为跨层连接,右边一列获得输入的双向连接和同层的跳跃连接,同时右边一列也作为下一个单元的输入。此单元重复堆叠3次即构成一个完整的BiFPN结构,并输出3幅尺寸为32×32×64、64×64×64、128×128×64的特征图。
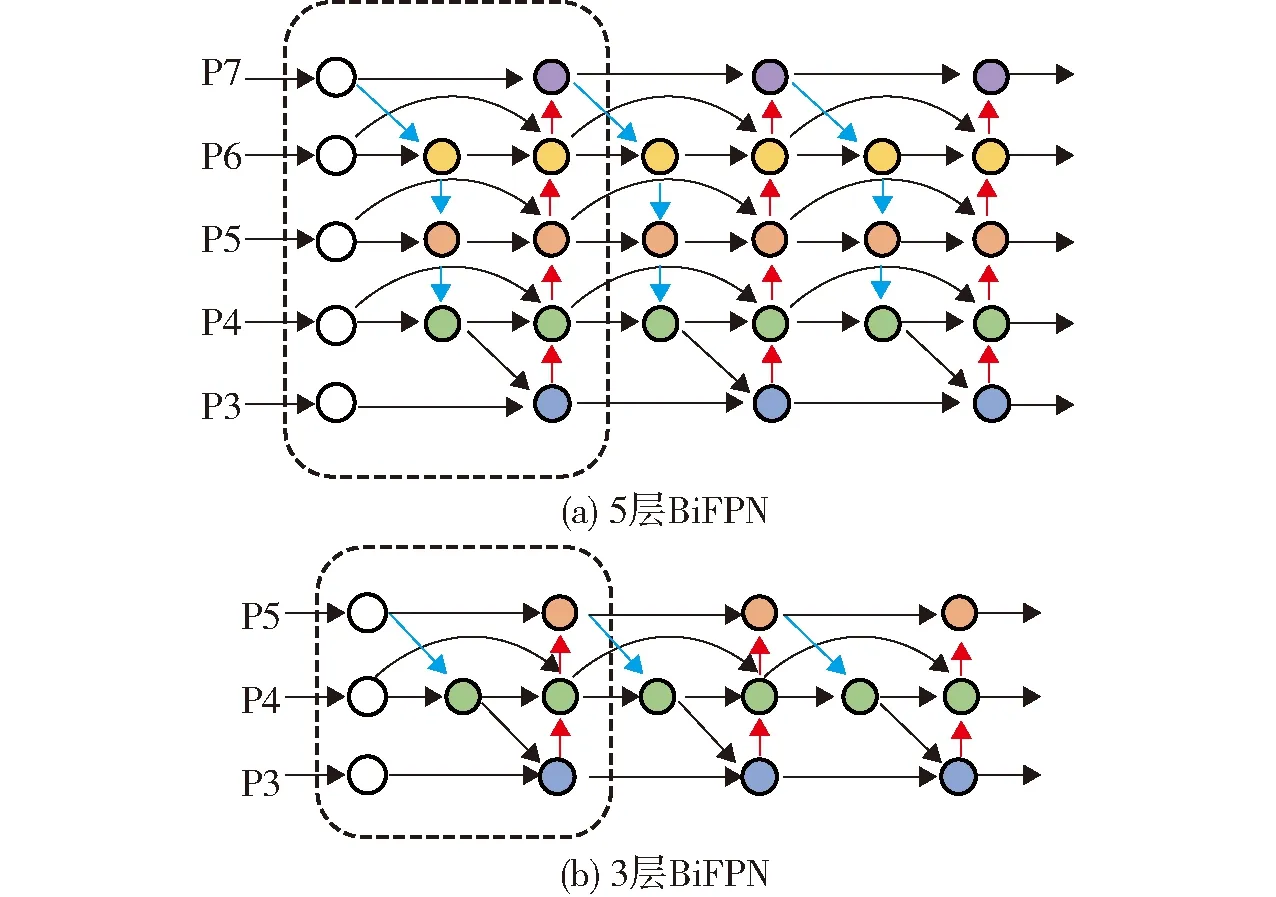
图4 多层BiFPN结构对比Fig.4 Comparison of BiFPN structure with multiple-layers
2.2.3检测输出分支结构
检测输出分支采用基于锚定框的检测方法,包括对应边界框输出头(Box head)和类别输出头(Class head)两部分(图3)。以每个像素为中心生成9个锚框,锚框采用大、中、小3个不同的尺寸,分别为0.5、1、2;3个比例的策略分别为1、21/3、22/3。如特征图的下采样率为8,尺寸为32×32,则该特征图共生成9×32×32个锚框。
经过BiFPN输出的每一层特征图分别输入到对应边界框输出头(Box head)和类别输出头(Class head)进行处理。Box head 输出格式为[bs、a×4,h,w],Class head 输出格式为[bs,a,h,w],其中bs是批量大小,a是特征图中一个像素点锚定框的数量,h是特征图的高。Box head的输出为每个锚框对标注框的4个顶点回归值,Class head的输出则为每个锚框内是否包含维管束的分类结果。当判定锚框包含真实值时,将与标注边界框重合50%以上的锚框标记为正例。
2.2.4分割输出分支结构
经过检测分支后,可获得每个维管束的检测框(Proposal boxes)(图3),然后通过分割输出分支(Mask head)分割出框内的维管束掩膜。分割输出分支由3层卷积组成,将输入的特征图通道压缩至3层,输出检测框区域像素的预测结果。在训练过程中,使用标注框提取出相应特征图内的像素,使用RoIAlign[17]将其全部统一对齐到固定尺寸之后,得到每个检测框内的维管束轮廓掩膜。在推理过程中,选出置信度较高的检测框,将框内的特征图像素送入掩膜输出分支,得到框内维管束轮廓掩膜,再将这些维管束掩膜根据检测框的位置还原回原图像,即可得到图像的维管束实例分割掩膜图像。
3 实验
实验硬件环境为B365M-POWER、32 GB内存、NVIDIA GeForce RTX 3090显卡、24 GB显存、操作系统为Ubuntu 7.5.0,编程语言为Python 3.8,深度学习框架为Pytorch 1.7.0。
3.1 数据增强
由于数据集中样本数量较少,所以在训练阶段需要对原始数据集进行图像增强处理,以提高训练数据集内样本的多样性,增强网络的泛化性能。在功能区域分割部分,使用随机翻转、高斯模糊、亮度对比度变化、自适应直方图均衡等图像增强操作。图像增强处理后再做统一的归一化操作,目的是移除图像中相同部分,凸显图像特征。归一化具体操作将图像RGB三通道内所有像素各减去固定的均值,并除以标准差,将所有像素标准化处理。本文使用的均值和标准差均为ImageNet统计的均值和标准差,分别为[0.485, 0.456, 0.406]和[0.229, 0.224, 0.225]。
3.2 模型训练
骨干网络和特征提取部分的网络权重可通过迁移学习将已在大规模数据集ImageNet上训练好的网络权重迁移过来,以提高网络的收敛速度。整个网络模型的下游解码器和输出分支部分,需要在训练过程中对权重进行微调。
模型训练中,功能区域分割网络的训练最大迭代次数设为100,批量大小为2,图像缩放尺寸为512×512;维管束分割网络训练的最大迭代次数为200,批量大小为1,图像缩放尺寸为1 024像素×1 024像素。
在预置锚框的设置上,采用的3种不同比例尺寸为20、21/3、22/3,3种不同长宽比为1∶1、1.25∶0.8、0.8∶1.25,即在特征图的每一个像素上设置9个不同尺寸、不同长宽比的锚框。在3层BiFPN中,锚框最大边长为95.2像素,最小边长为9.6像素。
3.3 损失函数与优化器
损失函数用于度量预测值和真实值的差距,可衡量模型预测的好坏,在深度学习模型中起到决定网络优化的作用。由于整个玉米茎秆横截面的分割由2个相对独立的网络模型组成,对维管束分割是由检测网络架构增加掩膜分支构成,因此功能区域分割的Res-Unet需要一个损失函数,维管束分割网络中不同的输出分支需要不同的损失函数。
(1)功能区域分割网络使用交叉熵损失函数Lce
Lce(yi,pi)=yilgpi+(1-yi)lg(1-pi)
(2)
式中yi、pi——第i个样本的真实值和预测值
(2)在维管束分割网络中,Class、Box和Mask 3个头分支分别使用不同的损失函数,以评价每个头分支的损失,最后再用3个损失函数的加权和作为维管束分割网络总的损失,以评价整个维管束分割网络的性能。
Class head选用适合于密集型物体检测任务的焦点损失函数focal loss[22],表示为
(3)
式中α、γ——超参数,α∈(0,∞)
Lclass——焦点损失函数
调整参数α以解决前景框和背景框数量不均衡的问题;取γ∈(0,∞),调整γ以提高难区分实例的损失权重、降低简单样本的损失权重。
Box head选用带参数的回归损失函数Huber loss[23],表示为
(4)
式中Lbox——回归损失函数
δ——阈值参数,表示真实值与预测值的偏差
当δ~0时,Huber loss会趋向于平均平方误差MAE;当δ~∞,Huber loss会趋向于平均绝对误差MSE。因此,Huber loss结合了MSE和MAE的优点,相比于最小二乘的线性回归,可降低对异常点的敏感性。
Mask head选用二元交叉熵损失函数BCE loss,表示为
Lmask=-[yilgpi+(1-yi)lg(1-pi)]
(5)
在式(2)的基础上,使用独热编码计算出所有框对所有类别进行二分类概率的均值。
上述3个输出头分支的损失加权和作为维管束分割网络的总体损失Lv,表示为
Lv=WclassLclass+WboxLbox+WmaskLmask
(6)
式中Wclass、Wbox、Wmask——Class、Box和Mask输出头的权重,取1、800、0.2
此外,选用对超参数不敏感的AdamW模型优化器,学习率动态调整器为ReduceLROnPlateau,使每个参数都具有动态学习率,初始学习率设置为10-3,当验证集损失值在10个迭代周期内未下降时,将全局学习率缩小为原来的1/2。
3.4 网络模型评价指标
3.4.1DICE系数
骰子系数(DICE coefficient)是一种集合相似度度量指标,用于表示2个样本的相似程度[24]。取值范围为0~1,其中1表示预测结果和实际结果完全重合,0表示预测结果和实际结果完全不相交,因此DICE系数越接近1表示网络的性能越好。本文用DICE系数从玉米茎秆截面功能区域在像素级别上评价网络模型的分割性能。
(7)
式中DICE——DICE系数,%
XTP——预测为正例的正例像素数
XFP——预测为负例的正例像素数
XFN——预测为负例的负例像素数
3.4.2平均精度
平均精度(AP)表示精确率-召回率(Precision-recall)曲线与坐标轴所围面积。
由于使用单个指标评价目标检测模型有一定的局限性,因此使用AP作为目标检测和实例分割的评价指标。给定一个阈值t(一般取0.5~0.9)用于表示预测框与真实框的重复置信度。如果交并比(IOU)大于t,则预测样本为正例。例如t取值为0.7,则AP70的度量值是表示预测框与真实框的重叠区域大于两种区域并集面积的70%及以上,才能被判定为正例。因此t越大,对应的AP就越小,评价指标就越严格,预测样本被认为是正例就越困难。一般情况下,t越小,对应的AP就越大。
3.4.3平均绝对误差
平均绝对误差(MAPE)是衡量预测准确性的统计指标。MAPE可避免误差相互抵消,能准确反映实际预测误差的大小。
3.5 实验结果与分析
由于功能区域和维管束的分割分别由两个独立的网络完成,因此在对实验结果进行分析时也分别对2个不同的网络模型及其性能进行评价分析。
使用本文方法对玉米茎秆截面功能区域和维管束的分割效果示例如图5所示。图5展示了4种具有代表性的不同品种或不同生长期的玉米茎秆截面分割结果。其中图5b为对功能区域分割的结果,红色为表皮区域,绿色为周皮区域,蓝色为髓区区域;图5c为对维管束分割的结果,图中不同颜色的掩膜代表不同的维管束实例。
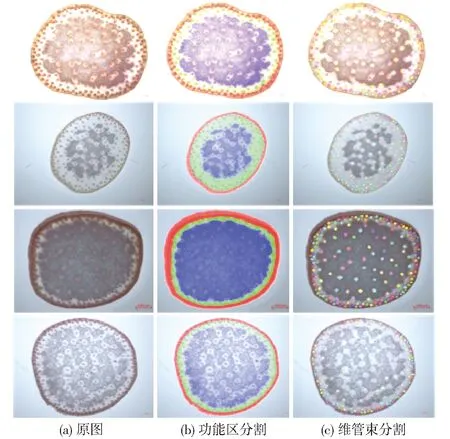
图5 功能区分割与维管束分割结果Fig.5 Results of functional zone segmentation and vascular bundles segmentation
3.5.1功能区域分割网络性能分析
先分析本文所设计的用于功能区域分割网络Res-Unet的性能,再用DICE系数作为功能区域分割性能的评价指标,分析对表皮、周皮和髓区3个功能区域的分割性能。
3.5.1.1网络模型性能分析
主要分析针对骨干网络ResNet不同层数的构造对各功能区域分割的DICE系数,以选择合适的层数搭建实用的Res-Unet网络。
基于不同层数的Res-Unet模型对功能区域分割的DICE系数如表1所示。由表1可看出,当骨干网络为ResNet18时对功能区域分割效果最好,3个区域的DICE都达到84%以上,平均DICE达到88.17%,其中髓区区域的DICE达到93.61%。其中,对表皮区域分割准确率略低的原因可能是部分切片较厚,用显微镜拍摄图像的表皮边缘出现阴影。此外,随着骨干网络层数增加,表1中各区域的DICE没有明显提升,这说明随着网络模型的深度增加,模型出现了过拟合现象。

表1 不同骨干网络下的DICE对比Tab.1 Comparison of DICE under different backbones %
3.5.1.2与其他文献方法对比分析
与文献[16]方法进行对比,结果如表2所示。由表2可得,本文方法在功能区域上的分割性能整体优于文献[16]的方法。

表2 DICE对比Tab.2 Comparison of DICE %
根据表3可知,本文方法所获取的参数在MAPE上与文献[16]相比有明显降低,在功能区域平均面积上降低38.232个百分点。由于文献[16]中有关功能区域划分不一致,表皮区域面积虽然具有一定误差,但尚在可接受范围内,但是对于周皮区域面积与髓区区域面积的获取上几乎呈现出无法识别的状态,与人工标注值误差巨大。

表3 功能区分割网络的平均绝对误差对比Tab.3 Comparison of MAPE in function area segmentation network %
3.5.2维管束分割网络性能分析
先分析本文所设计的用于维管束分割网络Eiff-BiFPN的性能,再用AP作为评价指标分析维管束分割的性能。
3.5.2.1网络模型性能分析
首先分析维管束分割在EfficientNet不同级别缩放系数的性能,再分析在不同层数BiFPN的性能,以选择最合适的结构用于Eiff-BiFPN网络分割维管束。
基于3层BiFPN使用不同缩放系数的EfficientNet训练,维管束分割AP性能如表4所示。由表4可知,系数为B4的分割效果最好。
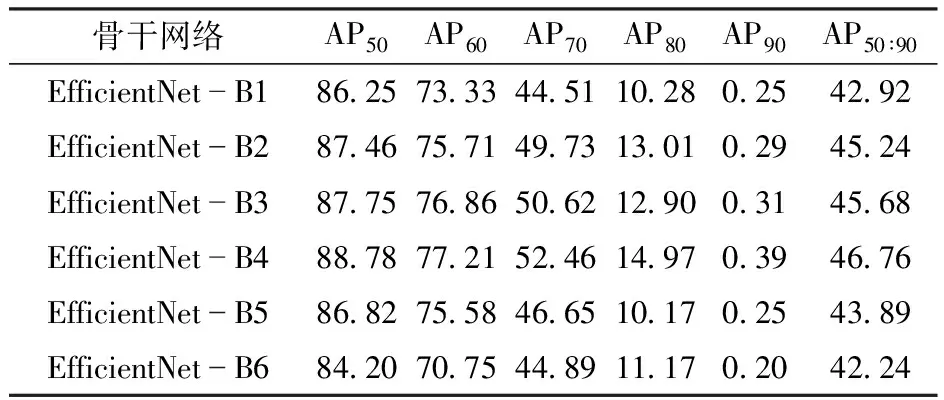
表4 不同骨干网络的维管束分割网络的AP (使用3层BiFPN)Tab.4 AP of vascular bundles segmentation network under different backbones (with three layers BiFPN) %
基于EfficientNet-B4,使用不同层数的BiFPN做训练,维管束分割AP性能如表5所示。由表5可知,3层BiFPN的特征提取效果最好。

表5 不同BiFPN结构的维管束分割网络的AP (以EfficientNet-B4为骨干网络)Tab.5 AP of vascular bundles segmentation network under different of BiFPN (with EfficientNet-B4 as backbone) %
骨干网络缩放系数越小、BiFPN特征图层级越少,网络越容易因为缺少充分利用数据而出现欠拟合的现象;骨干网络缩放系数越大、BiFPN特征图层级越多,网络越容易因为训练数据中的细节和噪声而出现过拟合的现象。通过对比实验分析,骨干网络为EfficientNet-B4、使用3层BiFPN的网络能够获得最好的分割结果。
3.5.2.2网络模型预测结果可视化分析
为直观体现维管束分割任务的效果,利用验证集的24个样本的维管束数量和维管束平均面积分析预测结果和原始标注的拟合程度,如图6所示。从图6a可见,两个数值回归到最小二乘法拟合直线上。图6b为测试集中每个样本的维管束平均标注面积和预测面积的曲线,从图中可见,大部分样本的预测值与标注值较为接近,部分甚至几乎一致,但也有少部分差异较大,其中差异最大达到0.019 7 mm2,这与人工标注原始图像存在一定误差有关。
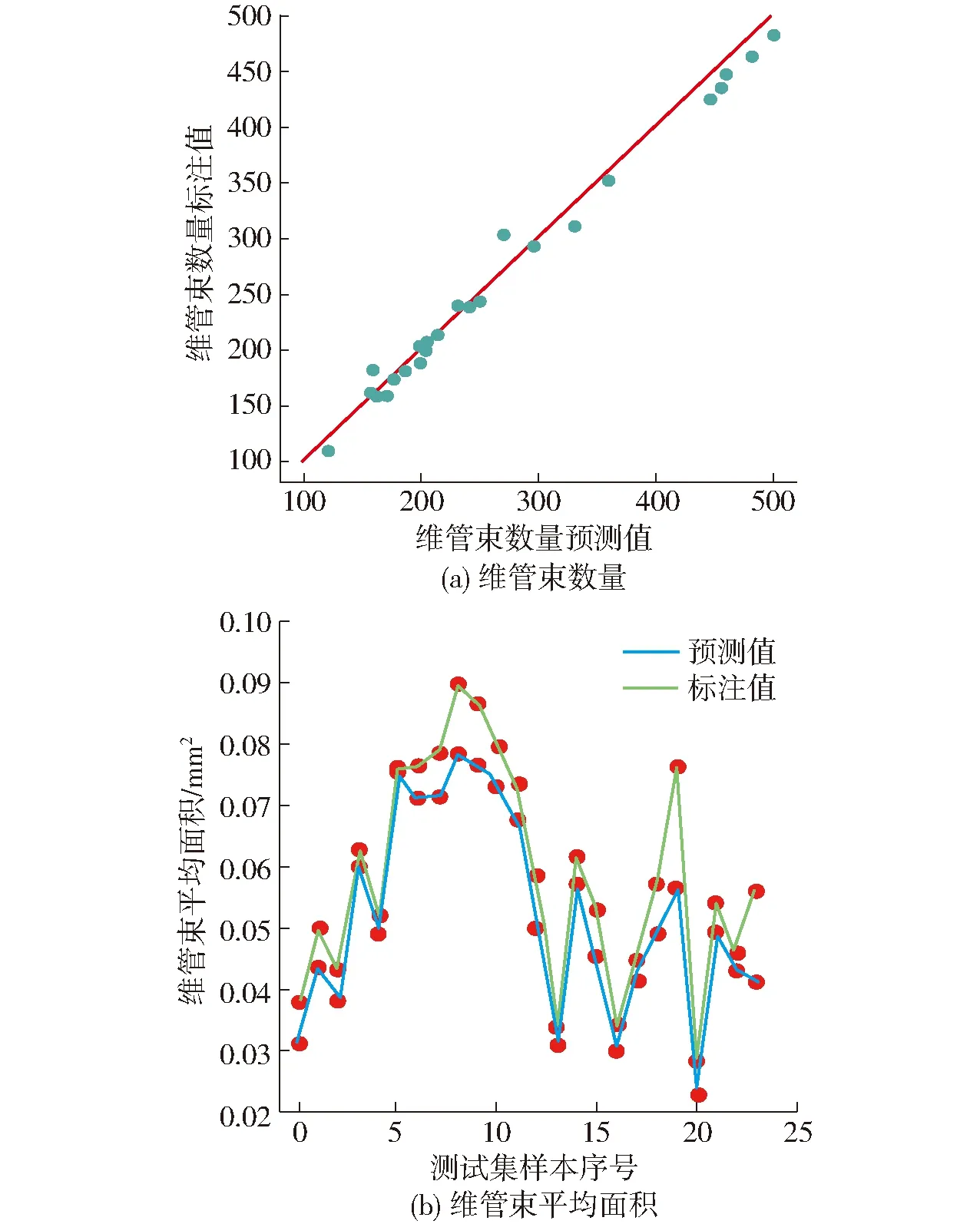
图6 维管束数量与面积的预测结果Fig.6 Prediction results of vascular bundle number and area
3.5.2.3与其他文献方法对比分析
选择在维管束数量、维管束面积方面与文献[16]的方法对比。由于玉米的茎秆截面微表型形态比小麦复杂,文献[16]网络模型无法对玉米茎秆截面微表型特征进行良好的训练和拟合。根据表6可知,本文方法所获取的参数在MAPE上与文献[16]相比有明显降低,在维管束数量和面积上分别降低16.268、1.768个百分点。

表6 维管束分割网络的平均绝对误差对比Tab.6 Comparison of MAPE in vascular bundle segmentation network %
从表7可见,在AP50∶70上本文方法更优,其中只有AP70值略低。

表7 AP值对比Tab.7 Comparison of AP %
在维管束的分割任务上,与应用最广泛的实例分割网络Mask R-CNN模型进行对比,比较的指标除了AP之外,还对存储内存占用量和推理内存占用量两方面进行比较,结果如表8所示。

表8 所需内存对比Tab.8 Comparison of memory
在存储内存占用量和推理内存占用量方面,本文方法均比Mask R-CNN所需要的内存少。其中,Mask R-CNN推理单幅图像占用的显存就超过 24 GB,因此必须使用压缩图像算法才能完成维管束的分割任务。而本文方法在不使用压缩算法处理的情况下,单幅图像推理占用显存仅为13 GB,节省50%。因此,即使是在推理阶段,Mask R-CNN方法的实用性也较差。
4 结论
(1)在功能区域分割任务中,平均DICE达到88.17%;在维管束实例分割任务中,AP50达到88.78%,AP50∶70达到72.80%。
(2)与常用的实例分割网络Mask R-CNN相比,本文方法在不同阈值下的AP指标表现更佳,且不需用压缩算法即可完成推理,所需存储内存占用量更少,获取参数的平均绝对误差更低。
(3)与文献[16]相比,本文方法的功能区域分割网络更适用于玉米茎秆,DICE系数更高;在维管束数量和面积上分别降低16.268、1.768个百分点,在功能区域平均面积上降低38.232个百分点。
猜你喜欢
江西农业大学学报(2022年3期)2022-07-07
河北农业大学学报(2021年5期)2021-11-10
新疆农业科学(2020年9期)2020-10-13
河南农业科学(2019年9期)2019-09-24
农业机械学报(2019年4期)2019-04-29
畜牧与饲料科学(2018年5期)2018-06-13
儿童故事画报·发现号趣味百科(2015年7期)2015-10-23
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
土壤与作物(2013年3期)2013-03-11
