
数据要素市场化配置效率的区域差异、动态演进与收敛性
2023-07-11 10:14王家明冯连勇林承耀
统计与决策 2023年10期
王家明,冯连勇,李 波,林承耀
(1.山东石油化工学院 经济管理与文法学院,山东 东营 257061;2.中国石油大学(北京)经济管理学院,北京 102249)
0 引言
随着数字中国建设的推进,数据要素在经济高质量发展过程中的关键性逐步显现。从实践层面来看,数据要素在市场中如何确权、市场结构与创新绩效等问题制约着其驱动作用的充分发挥[1]。从理论层面来看,数据要素作为全新生产要素,其生产效率以及对经济社会高质量发展的边际贡献率如何?数据要素与经济社会高质量发展其他影响因素之间的关系如何?这些问题均有待进一步探讨[2]。
从数据要素市场化配置效率测度的角度来看,部分学者认为数据要素出现较晚,其市场化配置效率无法测度[3,4];还有部分学者提出采用测算传统要素市场化配置效率的DEA或索罗余值等模型进行测算,但此类方法的适用性有待进一步商榷;还有部分学者基于实证角度进行了探索,构建指标体系与评价模型进行分析。现有研究为本文测度数据要素市场化配置效率提供了参考,但仍存在以下不足:第一,数据要素市场化配置效率的科学量化问题。数据要素涉及面广、发展变化速度快,但现有研究大多以单一指标进行衡量,其科学性与系统性不足。第二,较少有对数据要素市场化配置效率进行区域差异及来源、动态演进、收敛性分析的相关研究。
本文以2006—2020年中国31个省份数据要素市场化配置的基础数据为研究样本,将经典TOPSIS 模型改进为PFHWD-TOPSIS模型对数据要素市场化配置效率进行测度。进一步运用Dagum 基尼系数、核密度估计方法、σ收敛与β收敛模型对区域差异及其来源、分布动态演进及收敛性进行分析。本文旨在对现有理论研究做出有益的探索与补充,对数据要素市场化配置的实践应用提供参考与借鉴,具有一定的理论意义与实践价值。
1 模型、指标与数据
1.1 PFHWD-TOPSIS模型
本文运用TOPSIS模型对数据要素市场化配置效率进行测度,鉴于此模型应用较为广泛,通过毕达哥拉斯矩阵进行展示。
(1)引入模糊数来构造毕达哥拉斯模糊矩阵。毕达哥拉斯模糊矩阵R=(cj(xi))m×n,其中,cj(xi)=(μij,vij)为方案集中xi(i=1,2,…,m)在评价属性集中cj(j=1,2,…,n)下的评估值。
(2)计算正理想解和负理想解。
(3)分别计算各项方案与正理想解和负理想解的混合加权距离。PFHWD(xi,X+)和PFHWD(xi,X-)分别表示xi(i=1,2,…,m)方案与求得的正理想解和负理想解的混合加权距离,其计算公式如下:
(4)计算方案的贴近度。在使用混合加权距离测度时,若使用传统贴近度的计算方法往往会出现某个方案不能同时满足与正理想解最近且与负理想解最远的情况,故本文借鉴已有研究提出了一种新的计算方案xi的贴近度函数ζ(xi)(i=1,2,…,m)[5,6],公式如下:
(5)结果排序。根据式(5)中所求贴近度ζ(xi)的大小,对方案X={x1,x2,…,xm} 进行排序。由于需要对数据进行总体基尼系数测算,进一步进行核密度估计,故对最终的函数值ζ(xi)进行处理作为优化贴近度值,公式如下:
1.2 Dagum基尼系数
Dagum(1997)[7]提出了按子群对基尼系数进行分解的方法,弥补了传统基尼系数和Theil指数的缺陷,定义如公式(7)所示:
其中,G表示总体基尼系数,k为划分的区域数,n为所有省份数。
总体基尼系数G可分解为区域内差异贡献Gω、区域间差异贡献Gnb和超变密度贡献Gt,他们之间满足以下关系:
其中,Gjj为区域j的基尼系数,Gjh为区域j和区域h之间的基尼系数,Djh表示区域j和区域h之间数据要素市场化配置效率的相互影响。,函数F是区域数据要素市场化配置效率的累计概率密度函数,djh表示区域之间数据要素市场化配置效率的差值。
1.3 核密度估计方法
参考已有研究,本文运用核密度估计方法研究数据要素市场化配置效率动态演进情况[8],假定随机变量X的密度函数为:
其中,x为均值,N是观测值的个数,h为带宽,K(*)为核函数,X1,…,Xn是各省份的数据要素市场化配置效率,其表达式为:
1.4 σ 收敛与β 收敛
(1)σ收敛检验方法。σ收敛可理解为不同区域数据要素市场化配置效率的离散程度随时间推移而变化的过程[8]。本文采用变异系数法进行计算,公式为:
其中,j=1,2,3 表示区域;i=1,2,3,…,31 表示省份;Nj表示第j区域内省份的数量;Qij表示j区域内i省份数据要素市场化配置效率。
(2)β收敛检验方法。绝对β收敛的计量模型为:
其中,i=1,2,…,N表示第i个地区,t=1,2,…,T表示时间,μi和ηt分别为地区效应和时间效应,εit为随机干扰项。
为了提高预测的精确性,添加控制变量,包含地区生产总值(GDP)、科技发展水平(TECH,科技经费投入/GDP)、城镇化率(URBAN,城镇人口总数/人口总数)、产业结构(IS,第三产业产值/GDP)、金融发展水平(FIN,金融产业增加值)、对外开放(OPEN,进出口总额/GDP),构建如下模型:
1.5 数据要素市场化配置效率测度指标体系
结合已有研究,本文从数据要素市场化基础、数据要素市场化开发、数据要素市场化规模三个方面构建数据要素市场化配置效率测度指标体系[9],如表1所示。

表1 数据要素市场化配置效率测度指标体系及综合权重
1.6 数据来源及说明
本文选取我国2006—2020年31个省份(不含港澳台)的面板数据作为研究样本,对数据要素市场化配置效率进行测度。本文数据来源于历年《中国统计年鉴》《中国科技统计年鉴》以及各省份统计年鉴、各类统计公报和中国经济社会大数据研究平台。对极少数未发布与缺失数据,通过差分法、线性回归等方法验证补齐,同时结合周边地区均值进行转换、补充与验证。
2 实证结果分析
2.1 整体分析
现有对数据要素市场化水平的研究鲜少对其标准进行研究,且尚未形成统一的梯度划分标准。因此,本文结合优化后的贴近度测度结果,以0.2999作为间隔划分为6个梯度,如表2 所示(数量表示2006—2020 年位于此梯度区间内的省份总数)。

表2 梯度分布表
数据要素市场化配置效率位于第二梯度的省份数量最多(135 个),随后是第三梯度(129 个)、第一梯度(94个)、第四梯度(50 个)。可以看出,2006—2020 年我国31个省份中有86%处于中等水平。但第一梯度、第四梯度的省份数量则出现断崖式分布,说明省份数据要素市场化配置效率分布差距较大。整体来看,各省份数据要素市场化配置效率均呈波动上升趋势。2006 年,各省份数据要素市场化效率停留在第三梯度至第六梯度;2010年,东部地区的部分省份数据要素市场化配置效率进入第二梯度,同时,仍然存在第六梯度的省份如新疆、青海和云南;2015年,各省份的数据要素配置效率水平都在第四梯度以上,东部地区较多省份进入第一梯度,中部地区进入第一梯度的省份有四川、重庆、湖北和江西;2020年,我国各省份的数据要素配置效率都在第三梯度以上,数据要素市场化配置效率位于第一梯度的省份范围进一步向西部地区移动,整体效率相较于2015年均有显著提升。
2.2 区域差异及其来源
全国及三大地区数据要素市场化配置效率的区域差异及其贡献率如下页表3所示。

表3 区域差异及其贡献率
2.2.1 总体差异
从下页图1 可知,样本期内数据要素市场化配置效率的总体区域差异呈现下降的趋势。从演变过程来看,数据要素市场化配置效率的总体基尼系数的演变过程为在2006—2008 年与2016—2018年呈现小幅下降趋势,2009—2016年与2018—2020年呈现快速下降趋势。2006年数据要素市场化配置效率总体基尼系数值为0.1924,是样本期内最大值,2008—2016 年骤降至0.0926,年均递减率为9.2%;随后从2018 年的0.0889 降至2020 年的0.0683,达到样本期内最小值。从整体层面上看,数据要素市场化配置效率的总体差异在下降,同时,区域间差异的贡献率最高,样本期内在70%上下浮动[10]。由此可见,数据要素发展在样本期内仍然存在区域间的数据鸿沟,单纯依靠改善发展落后地区的信息基础设施条件,难以缩小区域间的数据要素差异。在数字经济循环中,依靠数字技术可以采集分析各区域之间的生产要素数据信息,通过合理布局发达地区与落后地区的生产要素配置方案,进而打破单核同心圆空间生产模式,弱化生产要素在城乡之间和区域之间分布的不均衡性,削弱生产要素流通的空间壁垒,推动经济活动由单向流动转为多向流动。

图1 总体差异及其贡献率
2.2.2 区域内差异
如下页图2 所示,2006—2020 年,东、中、西三大地区数据要素市场化配置效率区域内差异整体呈现波动下降趋势。东部地区变化相对平稳,2006—2012 年表现为缓慢下降趋势,2012—2014年小幅下降,并于2014年达到样本期内最小值,随后缓慢上升且持续到2015年,直至2020年区域内差异稳定在0.032~0.034。中部地区整体呈缓慢下降的趋势,2006—2012 年呈缓慢下降趋势,2012—2016年的中部地区区域内差异下降幅度略微增加,2016—2019年呈缓慢下降趋势且介于0.038~0.042,之后又由0.0388下降至2020 年的0.0340,达到样本期内最小值。西部地区区域内差异整体表现出急剧下降趋势,2006—2013 年以9.36%的年均递减率中小幅度下降,2013—2015年急剧下降,2015—2018 年下降速度相对平缓,保持在0.095~0.100,2018—2020年以8.10%的年均递减率从0.0952中小幅度下降至0.0623。整体来看,2006—2020 年,东、中、西部地区区域内数据要素市场化配置效率差异均在下降,并且区域内数据要素市场化配置效率的极差分别为0.016、0.055、0.225。样本期内,西部地区基尼系数值要大于东部地区和中部地区,均值分别为0.1711、0.0612 和0.0384,这说明西部地区内部数据要素市场化配置效率不均衡现象最为突出,随后是中部地区和东部地区。

图2 区域内差异
2.2.3 区域间差异
如图3 所示,2006—2020 年,东、中、西部地区数据要素市场化配置效率区域间差异总体呈下降趋势,其中,东-中部地区差异平缓下降,2009—2014 年区域间差异缩小情况较为明显。从东部地区和西部地区差异来看,2006—2009年缓慢下降,2009—2015年急剧下降,2015—2018年区域间差距仍在缩小但速度并不快,2018—2020 年从0.1382 降至0.1045,降幅约为24.4%。中部地区和西部地区区域间差异变化与东部地区和西部地区区域间差异变化较为相似,呈现下降趋势,2013—2015年与2018—2020年,中部地区和西部地区数据要素市场化配置效率差异缩小较为明显。

图3 区域间差异
2.3 动态演进趋势
本文运用核密度估计方法考察数据要素市场化配置效率分布的位置、形态和延展性特征(见图4)。

图4 数据要素市场化配置效率核密度估计图
2.3.1 全国核密度估计结果
由图4(a)可以看出,在样本期内数据要素市场化配置效率的区域差异经历了“上升—下降”的过程。各省份数据要素市场化配置效率存在两个峰值,且随着时间推移核密度估计曲线总体向右移动,说明数据要素市场化配置效率整体呈上升趋势。从2018年的核密度估计曲线可以看出,峰值较之前逐步上升,两个波峰距离逐渐逼近且均向右上方移动,说明数据要素市场化配置效率整体提升,到2020年曲线整体向右移动,两个波峰距离继续逼近,函数宽度缩小,说明数据要素市场化配置效率总体提升且区域差异进一步缩小。
2.3.2 三大地区核密度估计结果
由图4(b)可以看出,东部地区核密度曲线在样本期内均存在两个峰值,东部地区数据要素市场配置效率在各省份之间存在较为明显的梯度,其中,主峰较为靠右且高度大致表现为“大幅下降—逐渐上升”的变化趋势,具体表现为,2006—2009年主峰高度下降,2009—2020年主峰高度逐渐上升,到2020年介于1.8~2.0。由图4(c)可以看出,中部地区核密度曲线在样本期内总体右移。从整体上来看,核密度曲线在2006年、2009年、2012年均有两个波峰,主峰相对靠右,小峰相对靠左。主峰在2009—2009 年峰值上升且保持稳定直至2020 年,波峰介于1.75~1.80,小峰在2009—2012 年峰值上升且波峰之间的距离不断缩小。由图4(d)可以看出,整体来说,西部地区核密度曲线存在两个波峰,且在样本期内大致表现为2006—2009 年主峰波峰大幅上升,2012—2015年主峰波峰小幅下降,2015—2018年主峰波峰小幅上升,2018—2020年主峰波峰再次下降,其主峰宽度总体呈现变窄的趋势。小峰位于主峰右侧,在2009—2018 年小峰与主峰之间的间距逐渐缩小,2018—2020年小峰峰值显著降低且波峰右移。
2.4 收敛性分析
2.4.1σ收敛
根据σ收敛结果绘制图5,可以看出:样本期内,全国总体呈波动下降趋势,2020 年比2006 年下降约0.235,下降幅度达到约66.27%。从区域层面来看,东部地区在2012—2013年下降速度较快,2014—2015 年小幅回升,2020 年相较于2006 年下降了0.0341,降幅约为34.4%。中部地区在样本期内整体呈下降趋势,2020 年相较于2006 年下降0.1115,降幅约为64.5%。西部地区总体呈持续下降趋势,明显下降阶段为2013—2015年,2020年相较于2006年下降了0.3945,降幅约为77.5%。值得注意的是,在2019—2020 年,西部地区σ收敛系数下降速率高于全国数值并于2020 年小于全国σ收敛系数值,中部地区σ收敛系数也在同年低于东部地区的数值。由此可见,全国及中西部地区σ收敛系数在样本期内均表现出逐年下降趋势,东部地区数据要素市场化配置效率差异的收敛现象并不显著,西部地区收敛速度明显高于中部地区,存在“追赶效应”。

图5 数据要素市场化配置效率σ 收敛趋势
2.4.2β收敛
在进行了σ收敛后,本文分别进行了全国及东、中、西部地区数据要素市场化配置效率的绝对β收敛检验和条件β收敛检验(见表4)。
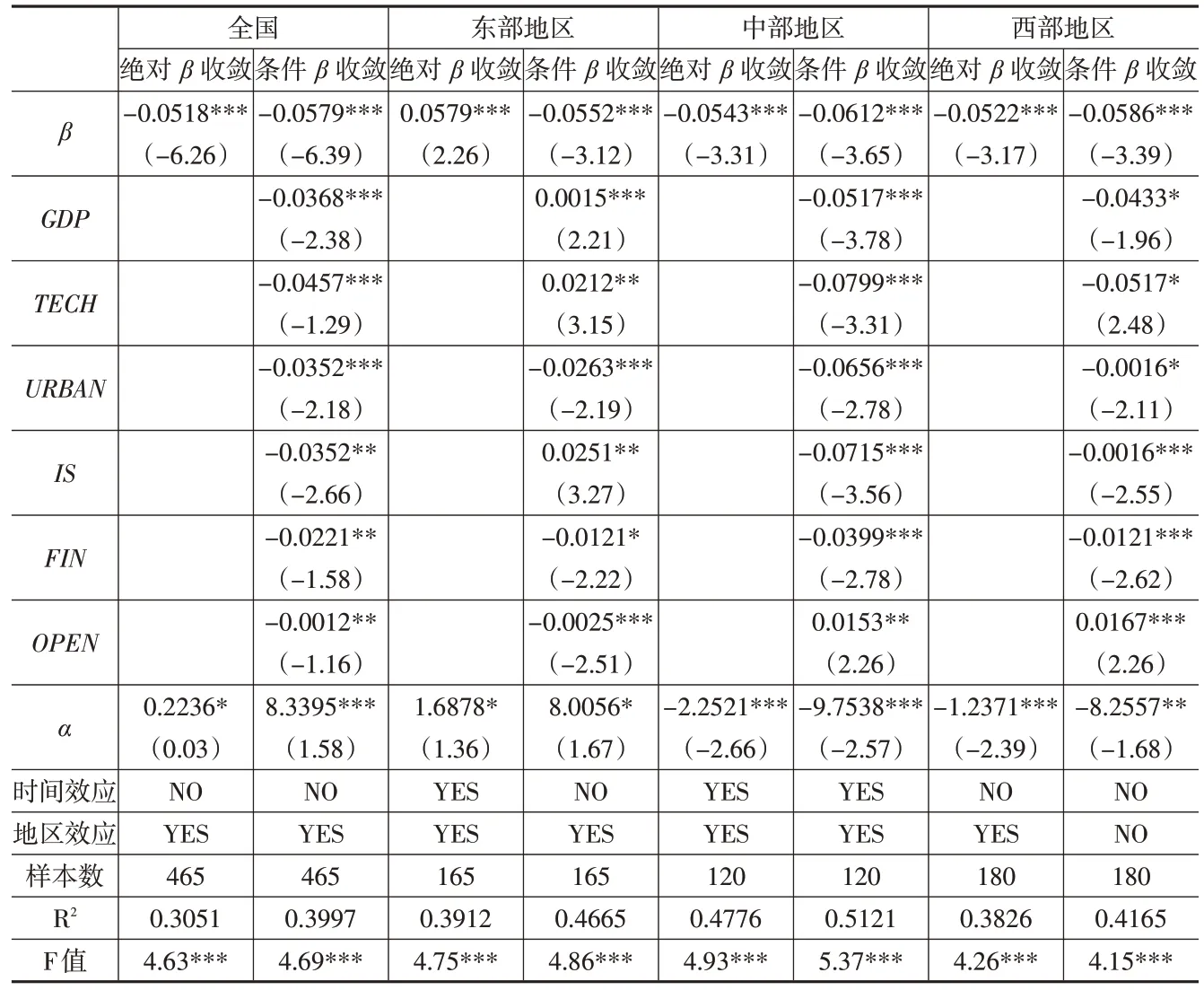
表4 绝对β 收敛和条件β 收敛检验结果
(1)绝对β收敛分析
全国、中部地区和西部地区的绝对β收敛系数均小于0,且均通过了1%水平的显著性检验,表明全国以及中西部地区数据要素市场化配置效率均存在绝对β收敛现象。在地区生产总值、科技发展水平、城镇化率、产业结构、金融发展水平、对外开放等影响因素相似的情形下,各省份数据要素市场化配置效率随着时间推移最终会收敛至同一稳态水平。从全国来看,绝对β收敛速度为0.0921,从区域来看,东部地区不存在绝对β收敛趋势,中部地区和西部地区的绝对β收敛速度分别为0.1057 和0.0936,中部地区具有较快的收敛速度,而西部地区收敛速度相对较慢。与数据要素配置效率较高的省份相比,科技资源配置效率较低的省份具有更快的增长速度,区域差距逐渐缩小。
(2)条件β收敛分析
全国及三大地区条件β收敛系数都显著为负,且均通过了1%水平的显著性检验,在考虑除初始值以外的其他异质性影响因素的条件下,全国及三大地区数据要素市场化配置效率均存在条件β收敛。全国和东、中、西三大地区内各省份的数据要素配置效率都朝着各自稳态水平发展,不同区域条件β收敛速度由大到小依次为中部地区(0.1391)、西部地区(0.1225)、全国(0.1186)和东部地区(0.1057)。在考虑了地区生产总值、科技发展水平、城镇化率、产业结构、金融发展水平、对外开放这些因素之后,收敛速度也随之发生了改变。特别地,东部地区的绝对β收敛分析结果并未呈现收敛趋势,条件β收敛分析结果呈现收敛趋势。
全国以及三大地区中各个控制变量的系数和显著性各不相同。城镇化率回归系数在全国以及东、中、西三大地区均为负,全国以及东中部地区通过了1%水平的显著性检验,西部地区显著性相对较弱。这说明城镇化水平提升有助于全国以及东、中、西三大地区的数据要素市场化配置效率空间收敛,且可以促进区域间差距缩小。金融发展水平回归系数在中西部地区显著为负且通过了1%水平的显著性检验,东部地区通过了10%水平的显著性检验,数据要素发展中金融业增加值对中西部地区引进信息设备、技术、人才等提升效率相较于东部地区更为显著[11]。地区生产总值回归系数在全国以及中西部地区为负,全国和中部地区通过了1%水平的显著性检验,西部地区通过了10%水平的显著性检验,而在东部地区具有正向作用[12]。科技发展水平回归系数在全国以及中西部地区为负,且在全国与中部地区负向作用更为显著,西部地区次之,在东部地区具有一定正向作用[12]。产业结构回归系数在全国、中部和西部地区显著为负,东部地区为正。可能的原因是,数字经济时代背景下东部地区用户规模达到临界容量后,正向因果累积循环的反馈机制将产生“马太效应”,能够持续降低生产的边际成本,促使部分企业规模经济大范围凸显,进而扩大区域内差距。第三产业占比提高对全国以及中西部地区第三产业的发展具有促进作用,对缩小东部地区数据要素市场化配置效率的差异有抑制作用[13]。开放水平回归系数在全国和东部地区为负,在中西部地区均显著为正,表明对外开放水平的提升不利于中西部地区数据要素市场化配置效率差异的缩小。可能的原因是,国内外数据要素相关产业发展水平差距较大,外商资本的进入对数据要素相关产业的冲击力度较大。
3 结论
本文以2006—2020年我国31个省份的数据要素市场化配置基础数据为研究样本,对数据要素市场化配置现状、区域差异及其来源、演进趋势及收敛性进行研究,得出以下结论:
(1)2006—2020 年,各省份数据要素市场化配置效率呈波动上升趋势,但具有明显的异质性特征,总体差异、区域内差异和区域间差异均呈现波动下降趋势。
(2)全国以及中西部地区的σ收敛系数在样本期内均表现出逐年下降趋势,东部地区数据要素市场化配置效率差异的σ收敛现象并不显著,西部地区σ收敛速度明显高于中部地区,存在“追赶效应”。全国以及中西部地区数据要素市场化配置效率存在绝对β收敛现象,全国以及三大地区均存在条件β收敛现象。
(3)地区生产总值、科技发展水平、城镇化率、产业结构、金融发展水平、开放水平对全国以及三大地区数据要素市场化配置效率的影响呈现异质性特征,其中的阈值效应、回弹抵消效应可作为未来的研究方向。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
应用数学(2020年2期)2020-06-24
当代水产(2019年11期)2019-12-23
草原歌声(2019年3期)2019-10-17
中国石油石化(2019年14期)2019-08-27
数学年刊A辑(中文版)(2018年2期)2019-01-08
新农业(2017年2期)2017-11-06
天津商业大学学报(2015年4期)2015-02-28
中国土地科学(2014年4期)2014-03-01
河南科技(2014年3期)2014-02-27
