
基于深度学习的车牌识别系统设计
2023-07-11 11:02徐渡李思颖金佳凝徐旖屏
电脑知识与技术 2023年15期
徐渡 李思颖 金佳凝 徐旖屏


关键词:深度学习;YOLOv5s;神经网络;车牌识别;CRNN
0 引言
隨着社会经济的飞速发展,我国各地城市汽车保有量不断增长。汽车在给人们带来便利的同时,也带来了管理上的问题,如道路交通监控、车辆违规记录、停车场车位智能管理[1]等问题。车牌识别技术在城市智能交通和城市智慧停车中具有不可或缺的作用,对于管理车辆信息和规划车辆位置都十分重要。近年来,车牌定位与识别技术获得了较丰硕的研究成果,在车辆管理方面有着较为广泛的应用,但仍具有一定局限性。在现实场景中,大多数车牌识别系统定位算法都存在亮度敏感、执行时间长和精度低等问题,并且当车牌存在损坏和倾斜等情况下,识别效果较差。此外,中国车牌的类型和样式不同于国外,汉字缩写和字符组合的方式也多种多样,识别起来更加复杂,往往需要付出时间的代价。所以,仍需要对车牌识别系统中定位与识别的方法进行设计,以提高系统的准确率和高效性。本文利用深度学习方法,将YOLOv5s 和CRNN进行结合,实现不同场景下车牌的识别,以提高车牌的识别效率和准确率。
1 相关研究
车牌识别技术从诞生发展到现在已有数十年,已是现代智能车位管理中最重要的组成部分。车牌识别系统主要包含车牌定位检测与车牌识别两大部分。随着深度学习的发展[2],基于深度学习的车牌定位算法和基于卷积神经网络的车牌识别算法成为主流。传统的车牌定位算法根据车牌的直观特征可以分为基于字符检测、基于颜色检测、基于文本检测、基于边缘检测和基于连接部件检测五类。这些直观的特征容易受到环境的影响,而深度学习可以通过像素信息提取出更深层的特征,以降低外部因素对车牌识别的影响。基于深度学习的车牌定位检测算法又分为单阶段检测和双阶段检测两类;单阶段检测如YOLO系列的算法在获取车牌图像候选框时会同时获取其分类信息与位置信息,相较于双阶段检测算法如SSD[3]、Faster-RCNN[4]相比,具有结构简单、计算高效、训练速度更快的优点。Laroca等人[5]通过评估和优化不同的YOLO模型,在每个阶段实现最佳速度/精度权衡。在车牌检测阶段,考虑到车牌在图像中可能只占很小的部分,并且交通标志等其他文本块可能与车牌混淆,检测过程采用先检测车辆,然后在车辆图像中检测各自的车牌。在8 个不同数据集上的平均准确率为98.37%,平均召回率为99.92%。
在传统的车牌识别过程中,字符分割对车牌识别的精度有很大影响。即使有一个强大的识别器可以处理各种缩放、不同字体和各种旋转,如果车牌没有正确分割也会被错误识别。随着循环神经网络的提出与发展,其在语音与文本领域中的出色识别性能,使得基于无分割的车牌识别算法成为当前车牌识别的主流算法[6]。Li等人[7]使用LSTM训练递归神经网络(RNN),以识别通过CNN从整个车牌提取的序列特征。每个检测到的车牌都被转换为灰度图像,并调整大小为24×94像素。再以步长为1的24×24像素子窗口,进行滑动窗口方式分割填充图像。每个分割的图像块被送入36类CNN分类器以提取序列特征。将第四卷积层和第一完全连接层连接在一起,形成一个长度为5 096的特征向量。然后使用PCA将特征维数降低到256维,并进行特征归一化。最后,CTC被设计为将预测的概率序列直接解码为输出标签,平均识别率约为92.47%。
综上,本文选择YOLOv5作为检测模块对图像进行定位,采用其中复杂度最小、深度最浅的YOLOv5s 模块作为车牌定位的检测框架,以此来降低模型运行速度对检测程序的影响。由于字符分割对传统的基于字符分割的车牌识别方法影响较大,而且字符分割效果在车牌图像倾斜、光照昏暗等条件干扰时效果并不理想。为了避免车牌分割造成识别中对字符的错分、漏分,影响最终识别结果,本文选用基于RNN改进的CRNN算法进行实现无分割车牌字符的识别[8-9]。
2 算法模型
整个车牌识别的流程框架如图1所示,其中YO?LOv5s网络和CRNN网络为主要组成部分。识别流程首先由YOLOv5s网络定位检测出车牌的有效区域,再检测出车牌区域送入CRNN进行无分割的车牌识别,最终输出识别结果。
2.1 YOLOv5s 车牌检测网络
YOLOv5s主要由Backbone、Neck、Head等部分组成,其网络结构如图2所示。Backbone作为基准网络来进行特征提取,融合了包括Focus结构与CSP结构在内的检测算法结构思路。通过Focus来进行切片操作,从而扩大通道数量。再采用卷积实现下采样,在保留更多图像信息的情况下又不提高模型的计算量。Neck结构由PAN路径聚合和FPN特征金字塔结构组成,作为在Back Bone层与Head层之间的网络,PAN 由下而上传递图像的位置信息,FPN由上而下传递语义信息,从而促进主干网络中不同尺寸网络信息的融合。Head输出层的锚框机制相较于YOLOv4而言,主要改进的是训练过程中的损失函数GIOU_Loss,其公式如(1)所示。
其中,IoU 为预测框(PB)与真实框(GT)的交并比,Ac 为能够将预测框和真实框同时包含在内的最小矩形,U表示预测框和真实框的并集。GIoU 是从PB和GT之间重合的面积来考虑,可以改善IoU 在PB和GT 不相交时梯度不能传递的情况[10]。
2.2 CRNN 车牌识别网络
CRNN 相较于CNN 而言,其模型参数量更加轻量。CRNN网络框架主要由卷积层、循环层、转录层三部分组成,网络模型结构如图3所示。第一层卷积层负责提取车牌字符特征的CNN卷积神经网络,经过车牌定位的含有车牌图像信息的图像被输入到CRNN 网络中,将这些图像缩放到指定大小,经过CNN特征序列映射层进行特征提取操作,得到车牌的图像特征序列,并将其输入到网络的循环层。第二层循环层负责标签序列预测的RNN循环神经网络层。对于卷积层输入过来的图像特征序列,利用长短时记忆网络(LSTM)内部的记忆模块,实现对特征标签的预测,形成特征向量的标签分布。最后,由第三层CTC转录层负责解码,把循环层的预测标签分布情况转化为序列标签,并输出识别出的文本信息。
3 实验结果与分析
3.1實验数据集
本文实验测试采用由中国科学技术大学研究人员构建的公开数据集CCPD数据集进行,其中包含了25万多张车牌图片,图片格式为720×1 160×3,包含了模糊、异常天气、倾斜和光线变化在内的9种不同场景下的车牌图片,具体内容如表1所示。
在实验中,本文车牌检测数据集为随机选取的除CCPD_Np场景外的其他8种场景下的20 000张图片,之后再根据图片中的车牌坐标截取出20 000张图片来用作识别模块的数据集,其中10 000张用作训练集,另外10 000张用作测试集。
3.2 实验环境
本文测试的实验环境是在Windows 64位操作系统下搭建进行的,电脑运行内存为16GB,显卡采用NVIDIA GeForce RTX 3060 Laptop GPU 14GB,处理器采用AMD Ryzen 7 5800H with Radeon Graphics 3.20GHz,在Python3.9 + pytorch torch 1.10 + cuda11.1平台下实现模型的搭建和训练工作。
3.3结果与分析
不同场景下车牌检测效果如图4和表2所示。在测试数据集上,识别准确率达到98.6%、召回率达到91.7%,处理时间为21毫秒。由检测结果可知,在多种复杂场景下,定位检测模块对于车牌定位表现出较好的定位效果与性能。
本文车牌字符训练参根据数据集的划分,设置初始学习率为0.001、初始动量为0.9、epoch设置为100、BatchSize为12,分别对6字符车牌、7字符车牌进行识别,识别测试结果如表3所示。
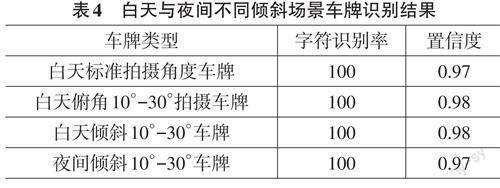
由表4可知,识别模型在6字符车牌的识别准确率能达到97.6%,在7字符车牌识别率能达到93.7%,处理时间达到81毫秒,识别结果较好。在训练好识别模型后,通过人为拍摄白天与夜晚的不同倾斜角度照片来验证模型的性能,如表4所示。在白天标准拍摄角度下的车牌,拍摄角度为正前方拍摄,光线较亮,7 位字符识别全部正确,置信度为0.97。在白天俯角拍摄的车牌,拍摄角度为车辆正前方10°~30°,光线环境较亮,7位字符识别全部正确,置信度为0.98。在白天倾斜拍摄车牌,拍摄角度为车辆左侧10°~30°,光线较暗,7位字符识别全部正确,置信度为0.97。在夜间倾斜拍摄车牌,拍摄角度为车辆斜上方10°~30°,光线较差,7位字符识别全部正确,置信度为0.97。
4 结论
针对已有项目在车牌识别部分使用传统的车牌识别方法达不到现有需求的问题,本文使用YOLOv5 中的轻量级网络YOLOv5s来提高车牌定位效率和准确率,使用CRNN端到端识别网络进行无分割识别,不再从分割字符的角度来进行车牌识别,减少由于分割误差带来的精度影响,一定程度提高识别效率和准确率。实验结果表明:采用基于深度学习的YOLOv5s 和CRNN相结合的识别方法,车牌定位检测模型准确率达到98.6%、召回率达到91.7%,处理时间为21毫秒;识别模型在6 字符车牌的识别准确率能达到97.6%,在7字符车牌识别率能达到93.7%,处理时间达到81毫秒,得到了较好的结果。
猜你喜欢
电子制作(2019年19期)2019-11-23
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
