
无人驾驶方程式赛车环境感知技术
2023-07-13 09:12王立琦张汝波
大连民族大学学报 2023年3期
王立琦,张汝波
(大连民族大学 机电工程学院,辽宁 大连 116650)
近年来,依附于各类学科的深入研究,汽车产业的智能化转型,无人驾驶技术受到了各国学者的广泛关注。2017年,德国大学生无人方程式赛车比赛(FSD)成功举办,使得各大高校组建自己的车队参与投入到无人方程式赛车的研究中来,在全世界范围内开创了大学生无人驾驶方程式赛车竞赛的先河;同年,SAE China成功举办中国首届无人驾驶方程式汽车大赛(FSAC),是中国高校无人方程式汽车竞赛的开端。两大赛事均已无人驾驶技术为主题,旨在由高校学生自行开发制作一辆无人驾驶方程式汽车,为无人驾驶领域培养技术人才,推动无人驾驶技术的发展。
无人驾驶技术可继续分为环境感知、路径规划及跟踪控制三个技术模块。其中,环境感知模块基于车辆部署的传感器来获取外界环境信息,返回前进区域内物体的位置、颜色等信息。而在无人方程式汽车大赛背景下,由于场景空旷、障碍物目标较小及比赛要求,对环境感知的准确度与实时性提出了新的要求。
因此,以FSAC赛事为背景,通过对不同感知方案的特点进行分析,重点分析视觉、雷达及传感器结合三种感知方案的算法内容,总结现阶段存在的感知方法,并结合赛事要求提出现阶段存在或可能存在的问题和挑战,最后对无人驾驶方程式赛车环境感知技术未来的发展方向进行展望。
1 FSAC赛事要求及环境特点
FSAC的设计背景是假定参赛车队在为一家设计公司设计、制造、测试并展示一辆目标市场为未来智能赛车或无人驾驶赛车的原型车或设计理念,并要求赛车具备优秀的加速、制动以及操纵性能,并兼顾安全性和稳定性,从而根据规则评优的赛事。其赛事要求大致如下[1]:
(1)自主驾驶。参赛车辆需要实现自主驾驶,即无需人工干预即可完成任务和挑战。
(2)传感器技术。无人驾驶方程式汽车大赛强调参赛车辆的传感器技术,包括激光雷达、摄像头等,以提高车辆的感知和识别能力。
(3)高精度地图。参赛车辆需要具备高精度地图匹配能力,以实现精准的定位和导航。
(4)多种任务。无人驾驶方程式汽车大赛设置了多种任务和挑战,如自动驾驶、避障、停车等,参赛车辆需要完成各种任务和挑战。
(5)创新思维。无人驾驶方程式汽车大赛鼓励参赛车辆团队发挥创新思维,采用新的算法和技术,提高自己的竞争力。
由于FSAC赛事在能够发挥参赛车队最大的设计灵活性和自由性,充分表达参赛车队和选手们的创造力和想象力,因此对赛车本身的整体设计给予了很大的自主空间。同时,FSAC赛事主要在封闭场地内进行,在赛事事先规定赛道进行比赛,通过视觉感知三种颜色的锥桶标识实现无人赛车的规划与决策,进而完成比赛。因此,针对无人驾驶赛车的眼睛——环境感知技术而言,目前各参赛车队主要讨论的问题包括如何选择传感器的搭配方案和如何设计基于不同传感器的感知算法,从而更精准、快速的感知和识别出赛道中的三色锥桶,进而完成比赛。
2 无人驾驶方程式赛车环境感知技术
环境感知系统是实现无人驾驶方程式赛车关键环节,该系统一般由激光雷达、相机等传感器共同构成。环境感知不仅需要识别到各种工况下的不同障碍物,还需要进行高精度定位及获取物体的语义信息。近年来,无人驾驶车辆对环境感知系统的要求不断提高,这也使得雷达、相机等传感器技术得到迅速发展。目前环境感知方案主要以相机和激光雷达传感器为主,其它传感器辅助进行检测,但基于传感器本身的限制,两种方案在一些方面上互有优劣。因此,使各传感器共同作用将是下一步发展的趋势。本章将针对上述三种方案现状进行概述分析。
2.1 基于视觉的环境感知技术
以相机传感器为主进行目标检测的方法又称为基于视觉的目标检测,即通过相机采集图像从而获取外界信息,凭借其丰富的语义信息、较高的分辨率等优点优于激光雷达传感器,是无人车辆及各高校车队的选择之一。就FSAC赛事而言,相机传感器的检测目标为三色锥桶,因此以下问题需要重点关注:(1)锥桶颜色作为决策标识,需要精准识别语义信息,避免其他干扰;(2)识别的精度问题,三色锥桶个体目标较小,并且可能存在重叠、不完整的情况;(3)检测效率问题,由于赛车在行驶过程中需要对锥桶进行实时检测,所以需要确保检测的实时性问题。
针对上述问题,整理概括国内外专家学者提出的目标检测算法,针对方程式赛车实用背景,分析传统目标检测算法的弊端,并重点分析基于深度学习的目标检测算法的针对上述问题的适应性。
2.1.1 传统目标检测算法
传统目标检测方法以人工提取特征信息,针对特征提取与分类方法进行研究。常用的检测与分类方法包括方向梯度直方图(HOG)、尺度不变特征转换(SIFT),K最邻近法(KNN)、支持向量机(SVM)等。但由于传统目标检测实时响应性不高,检测速度慢,并且传统特征检测主要是通过人为设计,因此泛化能力不佳,在检测特定的目标上需要特殊设计。因此,方程式赛车多采用基于深度学习的卷积神经网络进行解决。对比传统的检测方法,卷积神经网络的最大优点是提取特征能力优秀,不需要人工设计特征,能够根据不同数据的特点自适应获取特征,让模型学习数据的本质,具有非常强的普适性。另外,基于深度学习的目标检测算法模型简单,计算量较小,在实时性上有显著的优势。
2.1.2 基于深度学习的目标检测算法
基于深度学习的目标检测算法按照模式通常分为两大类:一类是基于区域的目标检测算法,又称为two-stage算法,其将目标检测的问题划分为两个阶段,先是通过算法产生候选区域提取特征,然后根据候选区域内的特征进行目标对象的分类和定位。该类算法在无人驾驶方程式赛车目标检测的应用上,主要需要克服检测速度带来的影响。具有代表性的算法包括R-CNN[2]、Fast R-CNN[3]和Faster R-CNN[4]等;另一类是基于回归的目标检测算法,又称为one stage算法,采用回归的思想实现端到端解决目标检测的问题,大幅提高了检测速度。该类算法在无人驾驶方程式赛车目标检测的应用上,主要需要克服面对小目标物体带来的检测精确度以及适用性问题。该类算法典型的代表为SSD[5]和YOLO[6-9]。
2014年,Girshick R等人提出R-CNN算法,第一次实现了深度学习在目标检测领域的应用。R-CNN将候选区域算法和卷积神经网络相结合,使得检测速度和精度得到了大幅提升。但在对原始图片进行候选区域选择时,需要不断对可能包含重复部分进行计算,导致计算量过大,直接影响了计算效率。随后在2015年和2017年,Girshick R再次提出Fast R-CNN算法和Faster R-CNN算法,分别在上述的基础上进行改进,提高了检测性能。但作为two-stage算法 ,其在面对较小物体时的检测性能仍有待提升,且检测速率相对较慢。针对检测物体较小的问题,王忠塬等人[10]提出了一种基于Faster R-CNN的改进方法,设计了基于多卷积核的深度可分离分组卷积Res Net,并使用分组卷积的方式压缩参数量与计算量, 在保证速度的前提下有效的提高了小目标检测准确率。
针对检测速度问题,曹之君等人[11]提出了一种快速目标检测算法,该算法在Faster R-CNN基础上改进网络模型,在RPN网络中引入了反馈机制,并调整训练过程中选择候选区域的数量,减少开销,提高了检测速度,在实时性上有了进一步改善,改进后的算法框架如图1。
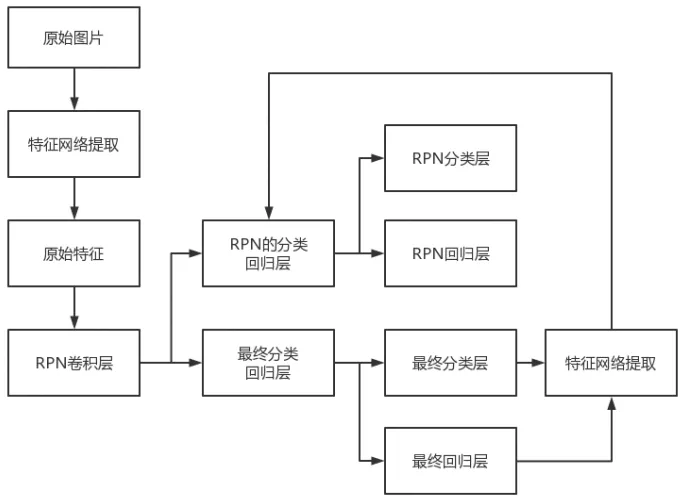
图1 改进Faster-RCNN算法框架[11]
One-stage算法由于其端对端的思想,在实时性上占据着天然的优势,其主要代表方法包括SSD算法和YOLO算法。2015年Joseph Redmon首次提出YOLO算法,这是YOLO系列算法的开山之作,奠定了之后系列的基础,其中YOLO历代算法改进见表1。
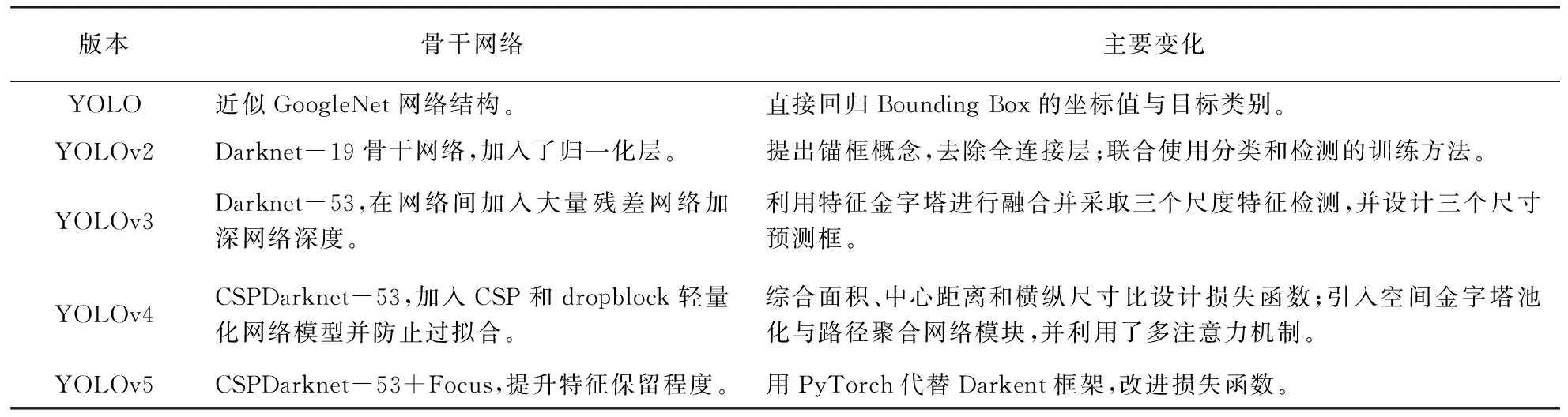
表1 YOLO系列算法的主要变化
在方程式赛车目标检测中,由于Darknet框架的简易灵活等特点,经常通过使用YOLO轻量化模型,对锥桶目标进行检测,一定程度上对性能有所优化。针对小目标检测精度的问题,Li等[12]改进YOLOv3算法,参照ShuffleNet和通道注意力机制的思想构造BackBone,并借鉴残差网络思想实现多尺度目标图像的预测功能。该方法有效利用和融合目标图像的多特征信息,但改进后的模型较为复杂,使得检测速度降低。而Wang等[13]在YOLOv5的基础上引入 DenseNet,增加 Bottleneck 结构数量,压缩了模型的参数量,大大提高检测速度。另外,Ju等人[14]将YOLOv4原始的连续卷积运算被替换为残差连接,从而生成多个不同尺度的特征图,使得能够同时提取待检测目标图像的类别和位置信息,对于密集分布和混合分布的目标检测场景,可以获得较好的检测效果。赵梓杉等人[15]针对锥桶检测设计了YOLOv5锥桶检测模型,直接以FSAC赛事为背景进行实验,通过设计数据集进行训练,调整网络参数,并与YOLOv3进行对比实验,大幅度提升了锥桶检测的速度与准确率。
为了更直观的观察各算法优势,对上述算法在经典测试集进行测试,各算法检测速度和精度对比见表2[4,9,11,15-17]。
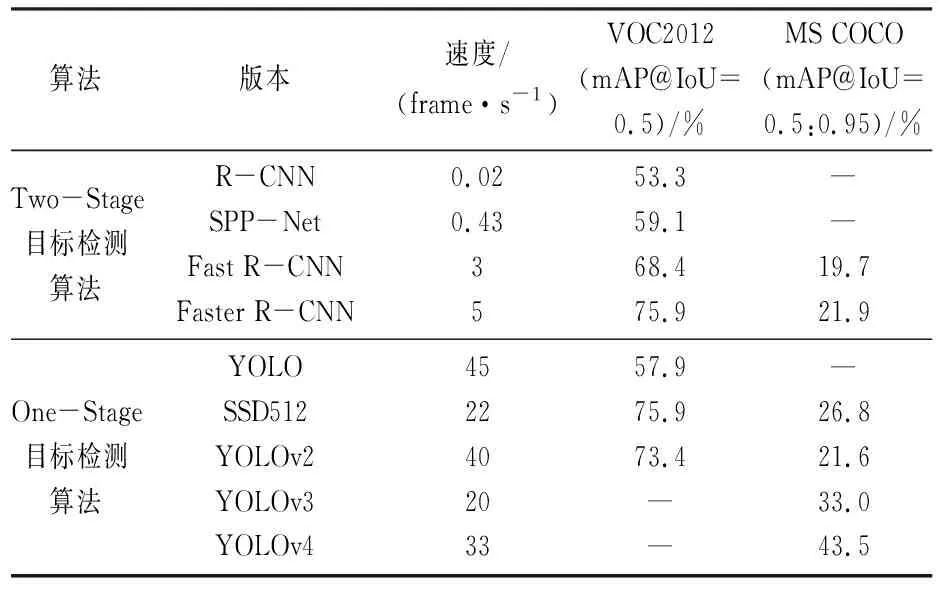
表2 各算法在测试集上的对比
经以上分析介绍,基于视觉的目标检测应用于无人驾驶方程式赛车主要以深度学习的方法为主。其中,one-stage方法具备高响应、高实时性的优势,但在小目标检测方向上存在准确率较低或检测不完全的缺点,可以针对选择数据集进行训练,并在激光雷达的配合下完成检测任务。two-stage方法具备高准确率的优势,但同样没有针对小目标物体进行训练的模型,并且相应计算量过大,实时性较低,一定程度上无法满足方程式赛车的实时性要求。下一步可以继续在检测速率上进行研究,并训练针对性模型,从而完成方程式赛车的感知任务。
2.2 基于激光雷达的环境感知技术
激光雷达是一种非接触式光学测量仪器,其通过自身旋转发射激光,当激光触及目标被反射后,激光雷达接收到物体反射的激光,从而检测目标。激光雷达拥有高精度的测距能力及高响应特性,并且不受光照影响。较视觉传感器相比,激光雷达表达环境中障碍物信息更加精准优秀,在无人驾驶方程式赛车环境感知系统中占据很大的比重。无人驾驶方程式赛车中基于激光雷达环境感知任务可以细化为对点云数据进行处理,从而进行物体检测的任务。
2.2.1 点云分割算法
物体检测主要用以描述范围内物体的轮廓及位置。在方程式赛车中,障碍物即锥桶都是垂直于地面的,且锥桶高度受限,所以雷达安装高度相对较低,地面点云数据将是提取锥桶数据的最大干扰。而点云分割通过将具备同一种属性的点云聚类,从而将目标点云与冗余的点云数据区分开来,达到获取目标点云的目的。但在进行地面点云数据分割过程中,以下问题需要重点关注:地面并不都是平坦的,可能存在部分崎岖不平路段;处理的效率问题,能否满足方程式赛车的实时响应性;分割准确度与完全度问题,由于锥桶目标较小,可能会影响到分割的准确度,或影响道路平面拟合的完整性。
为解决上述问题,总结归纳国内外学者提出的地面点云分割算法,可分为基于地面估计的方法、基于栅格图的方法、基于平面拟合的方法与基于学习的分割方法。
(1)地平面估计算法。地平面估计算法主要以确定地面详细点为主,准确提取地面点云。Byun[18]与Rummelhard[19]等人则采用基于条件随机场的方法,结合高斯模型和迭代期望最大化方法进行预测,实现了对任意地形下精确地面分割。Chen C等人[20]利用不同尺度的曲率信息来判断点云中的地面点和非地面点,并通过分层聚合的方式来获得最终的地面点云。与传统方法相比,该方法能够更好地处理地形变化、建筑物和树木等非地面物体的影响,提高地面点提取的准确性和鲁棒性。以上方法在地表平面估计具备很大的优势,但其劣势也很明显,需要大量的计算时间,无法满足方程式赛车所需的实时响应性。
(2)基于栅格图的方法。基于栅格图的方法的思想是将点云数据栅格化,针对栅格内点云特性进行分割。其中鲁小伟等[21]提出了一种基于二次栅格化的方法进行地面分割。该方法主要针对地面凹凸不平甚至存在坡度的情况。在第一次栅格化划分后,对相邻的栅格内的高度信息设置一定条件进行检测,第二次栅格化在检测出的地面点云上进行栅格划分,划分后采用滑动窗口的方法将连续的、不属于地面点云的高架点进行更新。最终,实现在弯道处以及直道处良好的地面分割效果;邹兵等[22]同样将点云进行栅格化,并计算栅格单元高度差、平均高度,同时在栅格单元引入点云高度方差信息,综合三个分割指标实现地面点云准确快速分割,根据设定阈值对地面与非地面点云进行分割。以上方法的效果均决于栅格划分与阈值设定的优劣,针对于非结构化路面具有良好的效果,阈值设定也更为简单。应用于方程式赛车中需要进行大量实验选取合适栅格和阈值,以避免锥桶与地面高度差过低或锥桶点云目标较小引起的分割不准确问题。
(3)基于平面拟合的方法。基于平面拟合的方法的核心思想是将点云数据拟合为不同平面,从而完成地面分割。在二维空间中该思想主要建立在霍夫变换的思想上拟合直线,在三维点云空间中则通过随机样本一致性(RANSAC)[23]算法拟合平面。RANSAC算法通过随机采取数据点拟合平面,设定阈值判断点云内属于该平面的点,不断迭代,从而实现平面拟合与分割。该算法主要针对地面点云在整体点云数据中占比过大的情况,非常适合用于方程式赛车的地面分割中来,但点云数据过多时,会导致迭代次数增加,对满足实时性产生了挑战。在迭代次数方面,黄瑶[24]在FSAC赛事环境下做了针对性的实验,通过实车测试做了最佳的迭代次数。在提升实时性方面,左勇[25]等人提出了一种LP-RANSAC算法,在基于RANSAC的基础上利用高度最值信息提高了地面点云占比,减少了计算量,并且在分割地面点云的同时仍能保留较好的原始数据特征。
(4)基于深度学习的方法。随着深度学习在各领域内崭露头角,基于学习的点云分割方法也在逐渐被提出。这种分割多为语义分割,即将点云标注不同的语义特征,从而实现分割。文献[26-27]通过将点云数据转换为二维图像,像素与点云相对应,并将图像输入至CNN卷积神经网络中以分割点云中的实例。但该方法需要大量数据集作为支撑,并且针对大规模点云时速率较低。为了解决缺少大量数据集支撑的问题,ZHANG等人[28]提出了一种无监督学习方法,通过使用深度图卷积神经网络(GCNN)的部分对比和对象聚类来学习未标记的点云数据集的特征,但同样存在计算量过大的问题。因此基于学习的点云分割方法仍待进一步研究发展,以轻量化与针对训练为方向,在保留准确赋予语义特征的前提下,提高实时响应性以应用于方程式赛车当中。
2.2.2 点云聚类算法
在进行地面点云数据分割后,原始点云数据中除了存在锥桶数据还存在离散的噪声数据等。这时进行检测仍会由于噪声、物体堆叠、桩桶信息断裂等情况造成误差,因此需要进行聚类分析。其主要思想是选取一个点云,根据距离、密度等特征值设置阈值,通过阈值对其邻近点云进行判断是否可以聚为一类。常用方法包括k-means聚类、DBSCAN聚类与欧氏聚类等。
k均值聚类旨在将点云数据依据平均距离分为k个簇,其算法简单但对初始聚类中心值难以确定。为了解决这个问题,ZHANG 等[29]基于密度选取初始聚类中心的思想对其进行改进,研究结果表明,改进的 K-means 聚类算法具有更高的稳定性和准确性;马克勤等[30]将距离最远的两个样本点作为初始聚类中心,将剩余样本点与已知聚类中心距离最小值组成的集合中选取最大值所对应的样本作为下一个聚类中心,以此达到确定初始样本中心的目的。而在FSAC赛事中,由于赛道两旁的锥桶目标不确定,即无法确定k值,因此常使用该算法来对冗余点云进行简化。
DBSCAN聚类是基于密度的聚类方法,其参数少易于改进,抗干扰能力优秀,并且能够聚类点云数据中的任意形状障碍物。但实时性较低,在点云密度不均匀时容易误检,并且对参数敏感,在多密度的数据集下使用全局参数,无法确保局部的聚类质量。针对上述问题,Kim JH等[31]人提出了一种基于密度的聚类算法,称为AA-DBSCAN。该算法是DBSCAN的扩展,能够更好地识别具有不同密度的簇。AA-DBSCAN通过适应性地调整DBSCAN算法的参数来自适应不同密度的数据集。实验结果表明,AA-DBSCAN在识别具有不同密度的簇方面表现出色,且具有更高的聚类准确性和更快的运行速度。另外,张长勇[32]等人提出一种自适应的DBSCAN算法,针对分析传统DBSCAN算法在密度不均与计算量过大等方面存在的局限性,根据不同扫描距离采用不同参数,并提出“核心点”概念,达到了对不同距离障碍物快速准确聚类的目的。
欧氏聚类是通过距离作为限制条件,通过设定距离阈值进行聚类。该方法聚类效果好,但由于需要对近邻点云比较,带来的计算量大的问题。同时由于点云具有密度近大远小的特点,这也使得固定阈值在密度不均匀的点云聚类中容易产生误差。王凯歌等[33]从改进算法的角度出发,提出给点云赋值来区分目标点云和干扰点云,虽然检测的准确率有所提升,但是计算过程复杂,耗时多。针对实时性问题,Cao Y等人[34]提出一种快速欧几里得聚类(FEC)算法,通过采用具有索引的逐点搜索方案,降低了对kd-tree的调用次数,使得聚类速度得到大幅提升。而在无人驾驶方程式赛车的应用上,黄瑞钦等人[35]针对赛道环境提出改进欧氏聚类的方法,找到感兴趣区域,并利用随机采样算法分离地面和锥桶的点云,最后设计出面向赛道环境的区域划分方法来改进欧氏聚类算法,利用动态阈值聚类分割出锥桶点云,从而完成聚类任务。
通过以上分析介绍,无人驾驶方程式赛车基于激光雷达的环境感知系统主要任务聚焦于地面点云的分割与非地面点云即锥桶点云的聚类两部分。目前大多算法主要关注在三维空间内平面分割、多物体目标识别及语义分割等方向,而FSAC赛事场地平坦,障碍物目标单一,主要关注小目标物体检测的准确性、实时性及地面杂物的干扰问题,后续可以继续根据以上问题改进创新。
2.3 基于多传感器融合的环境感知技术
通过对上述方案的分析,结合方程式赛车环境感知背景,车载相机能够捕捉环境中目标的颜色、纹理、位置等信息,较激光雷达传感器而言具有检测语义特征丰富、价格低廉的优点。但其缺点也较为明显,受到光源影响。此外,单目相机无法提供三维数据信息,而双目或深度相机价格昂贵且检测精度、范围、分辨率等都不如激光雷达传感器。单一传感器存在着各自的优势与劣势,因此将传感器进行组合使用,互相弥补不足,克服在某一领域内单一传感器的局限性,提高感知外界环境信息精度是非常必要的。
2.3.1 多传感器融合结构
多传感器融合技术根据输入融合网络数据的不同,分为数据级融合、特征级融合和决策级融合三类[36]。其中,数据级融合是最基础的融合方式,通过将来自多个传感器的数据进行整理对齐的预处理,直接融合各传感器的原始数据。数据级融合能够最大程度的保留原始数据,同时多源数据之间相互补偿,避免了单一数据的局限性,例如相机与激光雷达融合就可以补偿激光雷达语义信息的不足[37]。但由于原始数据信息类型不同,这要导致了在融合过程中需要大量计算对数据进行时间、空间上的数据对齐。而且融合算法的架构比较固定,不容易在原始架构中增加新的传感器模块。其次,多源数据之间存在互补也存在相互冲突的数据,这也导致数据级融合的噪声过多,抗干扰性较差。这也导致在方程式赛车中,传统的数据级融合方法已经被淘汰,乃至被各种特征融合方式所替代。
特征级融合为中间层融合方式,其通过对各传感器节点的原始数据进行特征提取,并以特征向量的方式来表示物体信息,最后传入特征融合网络完成融合。该方法在特征提取阶段,不同的传感器数据将提取不同的特征。以图像和点云为例,图像数据提取的特征多为检测目标的轮廓、类别、颜色等;激光雷达数据提取的特征多为检测目标的表面信息、三维数据及位置距离信息等。大多数基于深度学习的特征提取通过神经网络来进行,如RoarNet[38]、AVOD[39]、MV3D[40]、F-PointNet[41]等。特征级融合不仅一定程度上保留了原始数据中的重要特征信息,还大大减少了原始数据到融合模块的带宽,对数据进行有效的压缩,提高了系统的实时性。相对数据级融合相比,减少了传入融合模块的数据量,故检测速度大幅提升,但相对会丢失部分细节信息,融合精度不如数据级融合。
决策级融合属于最高级的融合,其通过对多个传感器传入的数据进行决策分析,随后对每个决策信息进行融合,根据决策之间的相关性得出满足实际需要的高级决策[42]。决策级融合在方程式赛车环境感知中具备独特的优势,其模块化的传感器封装,可以使得最终决策结果不因某一传感器故障而发生改变,其次由于其不存在中间数据的融合过程,精简了复杂结构,大大提升了实时性,融合速度更快捷高效。
2.3.2 基于图像和点云融合的目标检测算法
对于方程式赛车来讲,主要需要将图像和激光点云数据相融合,融合方式大概分为2D proposal与3Dproposal,2Dproposal通过将目标检测生成二维的感兴趣区域投射到三维空间,包括基于点的融合方式、基于视锥体的融合方式,3Dproposal直接从二维或者三维空间中预测出三维候选区域,包括基于多视角的融合方式、基于体素的融合方式等[43]。
基于点的融合方式通过将点云投影到平面,使得图像的高语义特征与点云中的点一一对应。基于点云本身语义信息不足,分辨率不高等问题,Point Painting[44]和PI-RCNN[45]模型将图像分支和原始激光雷达点云中的语义特征融合在一起典型模型。这种模型通过思考图像本身具备的高语义信息与雷达所具备的精确的检测范围互相弥补,提出将RGB图像与雷达点云相融合,网络示意图如图2。Yang等在该思想的基础上,针对目标存在遮挡或目标较多的问题,提出基于密集型点的目标检测模型 IPOD[46]。该方法通过将点云投影到图像并使用二维语义关联的方法过滤背景,生成的前景点保留了上下文信息和细粒度的位置信息,在之后的逐点提案生成和包围框回归阶段,使用两个基于 PointNet++[47]的网络进行特征提取和包围框预测,在密集场景具备更好的检测性能。

图2 Point Painting网络示意图[44]
基于视锥体的融合方式通过将二维的感兴趣区域边界框投影到三维空间内,形成视锥体以实现融合。Qi等提出F-PointNet模型将成熟的CNN目标检测算法和pointnet处理点云方法相结合,通过frustum(视锥体)的方式将二维边界框映射到三维空间进行处理,最后利用轻量级回归PointNet(T-Net)网络预测边界框中心,通过三维边界框估计模块获取检测结果,其网络结构如图3。随后WANG等[48]在F-PointNet的基础上进行改进,为提高检测效率提出生成视锥体序列的办法,减少了遍历点云的数量。

图3 F-PointNet网络结构图[41]
基于多视角的融合方式通过利用鸟瞰图法生成三维感兴趣区域,并回归三维检测框。2019年,Gu等[49]将分割结果组合在一起解决道路检测问题的方法,与Melotti等[50]提出的融合一样,将三维检测方案不同分支的权重汇总为一个最终权重,进行候选框的选取。Chen等创新性的提出了一种用多传感器不同视角相融合的模型MV3D,其输入为点云的鸟瞰图、点云的前视图及二维原始图像,通过在鸟瞰图中使用三维区域候选网络获得三维候选区域,并将其分别映射到不同视角中以获得了3个不同的候选区域。随后融合来自3种形式数据特征,并利用定向三维框回归实现检测。但在针对小目标时,点云鸟瞰图中经过下采样之后占据像素少,容易产生漏检的情况MV3D网络结构图如图4。
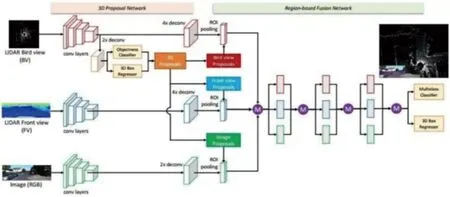
图4 MV3D网络结构图
基于体素的融合方式将点云看作3D空间,并分成一个个体素块,将体素与图像对应融合。Sindagi等人首先提出基于体素进行融合的算法MVX-Net[51],其通过Faster-RCNN算法进行图像特征提取,并将点云投影至图像,与其生成的特征图进行匹配,随后再对匹配完成的图像提取特征。另一方面,在上述过程中同时对原始点云进行了体素化处理,并与上述匹配处理后的特征图进行特征融合操作,逐点进行拼接。最后进行多层的体素特征编码操作,生成三维候选区域进行3D检测。
综上所述,相机与激光雷达组合被用于感知系统具备一定的可靠性与提升,能够使得自动驾驶汽车更好的理解复杂场景。但该技术并不成熟,由于噪声的存在,使得融合时点云与像素的对齐不够准确。其次,现有的大多数方法都以精准为目标,无法达到实时性的要求。在方程式赛车中需要保证以高速度实现高精度感知,因此仍需继续进行研究。
3 无人驾驶方程式赛车环境感知技术发展趋势
无人驾驶系统由于其灵活自主和高智能等优点,已经成为了国内外学者研究的热点问题,目前已经在各种场合进行了实验与模拟,已经取得了不错的成果。但针对于方程式赛车而言,针对于目前动态赛成果尚且不足,在面对更加复杂环境背景下,将带来更多的挑战。无人驾驶方程式赛车环境感知技术目前面临的关键性难题主要包括:
(1)视觉系统检测性能的不稳定性。目前FSAC的赛事大多处于结构化的场地,但仍存在道路环境的复杂多变光照特性与天气状况带来的问题。
(2)多传感器融合。环境感知系统主要通过相机和激光雷达传感器发挥作用,但二者之间的融合算法仍不完善。同时成本相对较高,在恶劣条件下效果较差。
(3)实时性。FSAC动态项目中,主要针对静态障碍物进行检测规划,对实时性相对要求较低。但在未来赛事中,可能出现更多的动态障碍物,要求方程式赛车更加的灵活多变,对实时性提出了更高的要求。
面对上述难点,无人驾驶系统应具备更高的智能感知能力,甚至可以具备一定的认知能力。在硬件方面,需要对各传感器特性充分融合,互补互足。可以考虑使用更多的传感器,如激光雷达、毫米波雷达与相机共同作用。同时,车载计算单元算力有限,应进一步提升算力。在面对无人驾驶系统目标检测、目标跟踪、决策与规划多个任务同时进行时,将进一步压缩算力,对实时响应产生影响。
在算法方面,面对复杂的非结构化环境,可同时利用多传感器共同作用带来的信息,实现更精确、范围更广的感知。多传感器融合算法目前多为基于有监督的方式,需要优秀的数据集进行训练,但目前针对极端情况的数据集较少,且耗费资源。因此。基于无监督的多传感器融合算法将更适合方程式赛车。在实时响应性方面,应尽可能降低算法的复杂度,并根据规则在第一圈感知时即可完成先验工作,为实时计算留出算力空间,以得出更好的检验结果。
4 结 语
方程式赛车属于智能无人驾驶下的一个子集,其具备着智能无人驾驶所具备的自主性、智能性与无人化等特点,同时又有自身所处赛事的背景环境特点,是结合智能感知、自主规划、智能决策多门学科技术的产物[52]。以FSAC赛事为背景,在自动驾驶领域环境感知技术方面对近些年的研究发展进行阐述,并分析算法在无人驾驶方程式赛车上的适用性。在未来,随着FSAC大赛的持续发展,专家学者的不断研究,方程式赛车将成为智能无人驾驶的典型应用实例,也必将推动目标检测与跟踪、slam建图和决策规划等多项技术的蓬勃发展。
猜你喜欢
北京测绘(2022年5期)2022-11-22
汽车实用技术(2022年19期)2022-10-19
作文小学中年级(2022年9期)2022-09-08
汽车观察(2021年8期)2021-09-01
科学(2020年3期)2020-11-26
小哥白尼(军事科学)(2020年8期)2020-05-22
中国交通信息化(2019年1期)2019-03-26
智富时代(2018年9期)2018-10-19
智富时代(2018年9期)2018-10-19
电子制作(2018年16期)2018-09-26
