
机器学习在宇宙线粒子鉴别中的应用*
2023-07-27 10:58刘烨牛赫然李兵兵马欣华崔树旺
物理学报 2023年14期
刘烨 牛赫然 李兵兵 马欣华 崔树旺†
1) (河北经贸大学管理科学与工程学院,石家庄 050061)
2) (河北师范大学物理学院,石家庄 050024)
3) (中国科学院高能物理研究所粒子天体物理重点实验室,北京 100049)
4) (四川天府新区宇宙线研究中心,成都 610000)
基于热中子探测器实验模拟数据,使用决策树(decision tree,DT)、随机森林(random forest,RF)和BP神经网络(back-propagation neural network,BPNN)构建了宇宙线粒子鉴别机器学习模型,对每种粒子分别使用不同的机器学习算法基于模拟数据进行模型训练,并针对算法进行超参数调整,将每种算法的AUC 值和Q 品质因子作为粒子成分鉴别的评价指标.实验结果表明,不同机器学习模型对粒子预测精度影响很大.在测试检验中,经过交叉网格搜索方法调参后的决策树鉴别模型对中成分(碳氮氧和镁铝硅)比较敏感,鉴别模型AUC 值均在0.95 以上,Q 品质因子均大于6;经交叉网格搜索方法调参后的随机森林鉴别模型对于宇宙线粒子鉴别的效果最好,所有粒子鉴别模型的AUC 值均大于0.92 且Q 品质因子均在4 以上;BP 神经网络算法只对质子和铁核比较敏感.本研究对宇宙线粒子鉴别和筛选提供了新的方法和选择,可为热中子探测器后续开展宇宙线能谱测量提供新思路.
1 引言
宇宙线是唯一来自外太空的物质样本,本质是高能带电粒子流,能量从keV 到EeV 跨越17 个量级,并且在传播过程中会与星际物质相互作用产生少量次级核子和反质子、反电子、伽马光子、中微子等次级宇宙线粒子[1-3].在宇宙线研究领域中,宇宙线能谱结构和次级宇宙线粒子成分的精确测量是解决宇宙线起源、加速、传播机制等问题的关键[4,5].目前,多个实验已经测量到了宇宙线能谱中的“膝区”结构,但是“膝区”的确切位置及成分存在较大差异[6],因此精确鉴别宇宙线中的粒子成分十分重要,是开展相关科学研究的重要基础和前提.
传统宇宙线成分鉴别大多基于多变量分析方法完成,该方法需要人工选取特征,耗费人力资源的同时容易丢失数据信息[7],而机器学习方法能直接在原始数据的基础上进行分析,节省人力资源的同时尽可能挖掘数据的信息.机器学习是人工智能的分支之一,是统计学、人工智能和计算机科学交叉的研究领域,可以通过学习多源、复杂的数据内在模式和结构,挖掘隐藏在数据背后的信息,并用于解决分类、回归、聚类等复杂问题[8].随着机器学习的不断完善和计算能力的提升,机器学习算法也逐渐帮助科研人员分析和处理大量的物理学相关数据.Herrera 等[9]评估了人工神经网络(ANN)、极端梯度提升树(XGBoost)、支持向量机(SVM)和K 近邻(KNN)算法对超高能宇宙线成分的分类效果,并使用五折交叉验证的方法对算法的超参数进行优化,结果表明极端梯度提升树对所有成分都表现出优异性能,准确率和f1 评分均为0.97,且运行时间最短,支持向量机的准确率和f1 评分均为0.94,但是运行时间较长,人工神经网络和K 近邻算法效果稍差;Pang 等[10]在高能核物理领域利用卷积神经网络(CNN)模型,将不同状态方程下相对论流体力学演化末态的粒子分布作为神经网络输入,将演化使用的和物质状态方程种类作为标签做监督学习,将寻找QCD 相变临界点的任务转化为两个相变区域分类问题;高泽鹏等[11]使用LightGBM 决策树算法训练初始化过程中有无形变效应给出的反应末态的自由质子、带点碎片及π+,π-的pt-y0谱,通过碰撞末态数据反推初态结构,分类的准确率在60%—70%之间,同时,此研究还通过LightGBM 决策树算法计算了特征重要性,发现弹靶快度区形变的带电碎片敏感于弹靶核的初始形变,与相关理论分析相一致.
本研究以热中子在探测器模拟数据为研究对象,以粒子的原初能量、天顶角、电子数、中子数及芯距5 个量作为特征,应用决策树(decision tree,DT)、随机森林(random forest,RF)和BP 神经网络(back-propagation neural network,BPNN) 3 种机器学习算法,构建了3 种宇宙线粒子鉴别模型,并调整3 种算法的超参数以提高其对宇宙线成分鉴别能力,然后使用相关评价指标对这3 种模型的结果进行评估,得到了性能最优的鉴别模型.最后,用验证数据验证了最优鉴别模型的精度和泛化能力,为后续开展宇宙线能谱精确测量提供依据和参考.
2 研究方法
本文选择决策树、随机森林和BP 神经网络3 种常用的机器学习算法建立宇宙线粒子鉴别模型.实验中,首先通过宇宙线粒子在探测器上的坐标计算出粒子的芯距,并选择宇宙线粒子原初能量(E0)、天顶角(theta)、中子数(neutron_total)、电子数(MIPs_total)和芯距(core_distance),5 个量作为成分敏感特征值,然后将5 种成分的数据混合在一起,定义模型输出值若为“0”则对应目标成分,若为“1”则对应其他成分,并将数据按4∶1∶5的比例随机的划分为训练集、测试集和验证集,分别用于模型的训练、测试和泛化能力的检验,并且在训练过程中根据模型和粒子成分鉴别的评价指标,不断的对模型的超参数进行调整,筛选出最优鉴别模型.本文中机器学习模型的训练、测试和验证均基于Python 语言中scikit-learn 和Pytorch库实现,技术路线图如图1 所示.

图1 宇宙线成分鉴别模型技术路线图Fig.1.Technical roadmap of the cosmic rays component identification model.
为评估各机器学习鉴别模型对数据集分类的效果,本文使用算法AUC 值和宇宙线研究领域中的Q品质因子作为检验算法分类效果的评价指标.AUC 值等于ROC 曲线下方面积,是机器学习中一个通用的评价算法性能的指标,用于权衡正确分类的收益和错误分类的代价之间的关联[12].ROC曲线分别以假正率(FPR)和真正率(TPR)为x轴和y轴:
其中,TP 表示真正类,即被模型预测为正类的正样本数;FP 为假正类,即被模型预测为正类的负样本数;TN 为真负类,即被模型预测为负类的负样本数;FN 为假负类,即被模型预测为负类的正样本数.
热中子探测器模拟数据鉴别是一个分类问题,但不能只使用统计学中常用的准确率判别模型分类好坏,因此本文使用高能物理领域中一个常用的评价指标Q品质因子对模型区分效果进行衡量[7],其定义为
其中 Perp为挑选目标成分的保留率,Pere为宇宙线其他成分的保留率.
2.1 数据集建立及预处理
本文使用的热中子探测器模拟数据由CORSIKA 软件模拟生成,该软件包含多种粒子反映模型,可以模拟粒子到达不同海拔高度的相关信息,包括粒子种类、能量、天顶角等,这些参数已经得到了实验证实,应用在众多宇宙线相关领域的实验中[13].热中子探测器模拟分为两部分,首先利用CORSIKA 软件模拟宇宙线在大气中级联簇射过程,产生宇宙线粒子原初能量、天顶角、方位角及粒子位置等信息,然后利用Geant4 工具包开展热中子探测器响模拟.最终热中子探测器模拟数据为质子、氦核、铁核、镁铝硅、碳氮氧,每种成分各4000 个事例,能量范围为1—10 PeV,天顶角0°—60°,方位角为0°—360°.
冗余特征可能会造成模型效率低或者过拟合等问题[14],因此本文在构建特征过程中首先根据粒子位置信息计算出粒子到探测器中心的芯距,并用其代替粒子其他位置信息,作为特征加入到模型训练和测试过程.因此,本文在建模过程中使用宇宙线粒子的原初能量、天顶角、电子数、中子数及芯距5 个量作为特征.
2.2 机器学习模型构建
2.2.1 决策树模型构建
决策树算法(DT)是一种经典的机器学习算法,因其结构简单、学习成本低且可解释性强,在机器学习领域有着广泛应用,常用的决策树算法有ID3,C4.5,CART 算法等[15].决策树的构建过程就是根据数据的不同特征,将数据划分到不同区域,使得同一区域的数据尽可能是同一种类型.决策树算法构建过程是选择具有较强分类能力的特征生成决策树,ID3 算法是采用信息增益作为选择选择特征的度量,而C4.5 算法采用信息增益比[16].但由于决策树算法具有强大的建模能力,因此会产生过拟合的问题,CART 算法在特征选择时以基尼系数为度量,然后对所有属性可能进行遍历,选择划分子集后基尼系数最小的节点进行分支,这样可以简化树的结构,避免过拟合问题[17].在信息论中,信息熵用于描述变量分布的不确定性,决策树在划分子树时以信息熵为基础,进行相关计算,然后选择特征划分子树.对于离散型随机变量D,其信息熵为
式中,K为样本类别总数,|Dk|为第k类样本的数目,|D|为数据集D的数目.使用特征A对变量D的条件熵为
则选择A构建子树的信息增益、信息增益比和基尼系数分别为
本文建模过程中,使用交叉网格搜索方法,对树的深度最小分割样本数和最小分割叶子节点数等主要超参数进行调整.交叉网格搜索方法是指定超参数取值的一种穷举搜索方法,用于搜索算法的最优超参数组合.通过将需优化算法的超参数运用交叉验证的方法进行优化,即将各个超参数可能的取值进行排列组合,列出所有可能的组合结果生成“网格”,然后将各组合用于算法训练,并使用交叉验证的方法对表现进行评估,将平均得分最高的超参数组合作为最佳的选择,返回给算法[18].决策树算法使用交叉网格搜索方法进行调整超参数时,将表1 所示的超参数设置在指定范围内,将参数cv 设置为4,其他参数默认,搜寻最佳超参数组合.决策树算法鉴别各种成分最佳超参数如表1 所示.

表1 决策树鉴别不同成分最佳超参数Table 1. Optimal hyperparameters of decision tree identifying different components.
2.2.2 随机森林模型构建
随机森林算法(RF)是一种监督机器学习算法,广泛用于解决分类和回归问题.本质上,其是由多个决策树集成之后构建的,使用Bagging (自助聚类)方法训练而成,通过随机有放回的抽样方式选取数据构建分类器,最后 通过组合学习得到的算法提升算法整体效果[19].随机森林结构如图2所示.

图2 随机森林算法建模流程图Fig.2.Flow chart of random forest algorithm modeling.
随机森林算法可以看作是对原有决策树算法的整合和改进,能够很好地处理变量间的非线性关系,有着分类准确率高、抗噪能力优异、抗过拟合能力较强以及能够平衡非平衡数据的误差等优点;此外,随机森林算法能够在观测变量较少的前提下完成分类任务,适合宇宙线粒子这种非平衡数据的分类[20].本文使用随机森林算法建立宇宙线粒子成分鉴别模型过程中,使用交叉网格搜索方法进行算法超参数调整,调整结果如表2 所示.
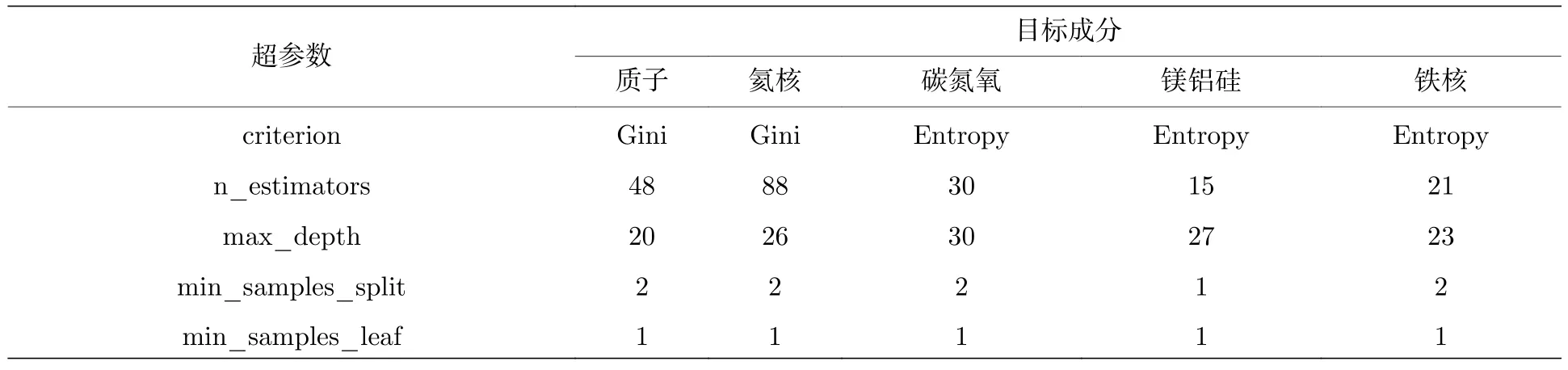
表2 随机森林鉴别不同成分最佳超参数Table 2. Optimal hyperparameters of random forest identifying different components.
2.2.3 BP 神经网络模型构建
人工神经网络算法(ANN)是一种常用的非线性数据建模算法,通过学习寻找并建立输入数据和目标数据之间的映射关系,十分适合解决非线性和不确定性问题.BP 神经网络,即前馈神经网络是一种多层前馈的人工神经网络,其基本原理是输入信号前向传播,误差反向传播[21].在前向传播过程中,输入信号经过输入层和隐藏层处理后,到达输出层后输出.若输出结果与预期结果不一致,则根据预测误差,使用梯度下降算法(gradient descent)调整各层网络的权重和偏置,使得算法输出结果无限逼近预期结果,直至得到损失不再降低或达到指定循环次数,该过程称为反向传播[22].BP 神经网络结构一般分为3 层,即输入层、隐藏层和输出层,输入层负责接收输入数据并转换为信号,输出层负责输出模型结果,隐藏层负责建立二者的映射关系.本文BP 神经网络结构示意图如图3 所示.

图3 本文BP 神经网络结构示意图Fig.3.Structure diagram of BP neural network in this paper.
隐藏层第j个神经元的输出值为Oj,计算公式为
输出层第k个神经元的输出值为Ok,计算公式为
其中,nj和nk分别为隐藏层第j个神经元和输出层第k个神经元的输入;αij和λj分别为输入层第i个神经元到隐藏层第j个神经元的权重和偏置;βjk和γk分别为输入层第j个神经元到隐藏层第k个神经元的权重和偏置;N和M分别代表输入层和隐藏层的神经元个数;φ和ψ分别代表隐藏层和输出层的激活函数.
本文使用BP 神经网络进行建模过程中,首先对数据进行预处理以消除极端数据对于模型训练的影响,数据预处理原理为
其中xscalered为标准化后的数据,xmax和xmin分别为数据的最大值和最小值.
然后,确定BP 神经网络的拓扑结构.本文中神经网络的输入和输出层均设置为一层,输入层和输出层神经元个数分别设置为5 个和2 个,隐藏层节神经元数由Kolmogorov 公式a计算得出[23],其中Nh为隐藏层神经元数,Nin为输入层神经元数,Nout为输出层神经元数,a为取值范围为1—10 的常数.实验中选取宇宙线粒子5 个特征敏感值输入网络,故Nin为5;实验中在输出层中通过Softmax 函数计算并输入数据标签为“0”和“1”的概率,故Nout为2.因此隐藏层节点数的取值范围是Nh∈[3,13] .然后,为了确定最佳隐藏层节点数,采用控制变量法,使用动态调整学习率算法,初始学习率设置为0.01,每迭代2000 次,学习率变为原来的0.7 倍,其余条件不变,只改变隐藏层节点个数,并通过损失函数图像确定迭代次数,进行模拟实验.以鉴别氦核为例,采用BP 神经网络算法核验结果如表3 所示.

表3 BP 神经网络(鉴别氦核)隐藏层节点核验结果Table 3. BP neural network (identifying helium) hidden layer nodes verification results.
综合考虑AUC 值和Q品质因子,确定隐藏层节点数为13,因此本文使用的BP 神经网络结构为5-13-2 的拓扑结构,对热中子探测器中的氦核模拟数据进行鉴别.表3 给出本文根据评价指标确定BP 神经网络算法鉴别氦核最佳拓扑结构的核验结果,BP 神经网络鉴别其他成分最佳超参数组合的确定方法同上,结果如表4 所示.

表4 BP 神经网络鉴别不同成分最佳超参数组合Table 4. Optimal hyperparameters of BP neural network identifying different components.
图4 为3 种宇宙线粒子鉴别模型鉴别氦核的10 折交叉验证检验图,可以看到10 折交叉验证过程中3 种模型训练和测试的准确率之差均不超过0.2,即3 种模型均不存在严重的过拟合问题.

图4 三种宇宙线鉴别模型鉴别氦十折交叉验证核验图Fig.4.Results of three cosmic rays identification models identifying helium using 10-fold cross validation method.
3 结果与讨论
本文在训练过程中将目标成分向“0”方向训练,其他成分向“1”方向训练,并输出相应的概率.为了描述3 种机器学习算法对目标成分(target)鉴别的结果,定义临界值Tc来计算目标成分鉴别的纯度(purity)和效率(efficiency),计算公式如下:
以鉴别目标成分氦核为例,3 种鉴别模型将粒子种类判定为氦核的概率如图5 所示,综合考虑氦核纯度及效率后本文选择临界值Tc为0.5,即: 1)在BP 神经网络鉴别模型中,T≤ 0.5 时,氦核鉴别效率及纯度分别为36.0%,52.8%;2) 在决策树鉴别模型中,T≤ 0.5 时,氦核鉴别效率及纯度分别为83.3%,80.1%;3) 在随机森林鉴别模型中,T≤0.5 时,氦核鉴别效率及纯度分别为79.3%,95.7%;由此可以看出,随机森林算法鉴别氦核纯度较高,达到94.5%,鉴别氦核的效率在79%左右.

图5 三种宇宙线粒子鉴别模型鉴别氦核概率分布图Fig.5.Probability distribution of three cosmic rays identification models identifying helium.
与模型鉴别氦核过程类似,其他成分鉴别效率及纯度如表5 所示.1) 在利用BP 神经网络鉴别模型和随机森林鉴别模型鉴别各成分时,重成分(铁核)鉴别的效率及纯度较高,其中神经网络算法效率和纯度分别为82.8%和87.5%,随机森林鉴别模型鉴别铁核的效率和纯度分别为91.1%和93.5%;2) 在利用决策树鉴别模型鉴别成分时,对于中成分(镁铝硅、碳氮氧)鉴别效率及纯度较高,效率和纯度均可以达到90%以上;3) 利用3 种鉴别模型鉴别轻成分(氦核、质子),决策树与随机森林鉴别模型鉴别轻成分效率在74%以上,纯度在77%以上,而神经网络鉴别模型鉴别轻成分效率,尤其是对氦核的鉴别效率与纯度并不高,对质子鉴别效率与纯度在64%以上.

表5 三种宇宙线粒子鉴别模型鉴别不同成分效率及纯度Table 5. Efficiency and purity of three cosmic rays identification models identifying different components.
随后,本文根据各成分鉴别结果得到算法分类效果检验的评价指标AUC 值与宇宙线研究领域中的品质因子Q值(如表6 所示),结果表明: 1) 随机森林算法在各成分判别中纯度均可达到90%以上,Q品质因子较高,即对宇宙线各成分鉴别能力比其他两种算法要好;2) 决策树算法在中成分(镁铝硅、碳氮氧)鉴别正确率可达90%以上,Q品质因子在6 以上;在轻成分和重成分中的鉴别正确率达85%以上,Q品质因子在3 左右;3) 神经网络算法在重成分(铁核)鉴别中具有一定优势,判别正确率达到87%,Q品质因子为2.96.

表6 三种宇宙线粒子鉴别模型鉴别不同成分AUC 值及Q 品质因子Table 6. AUC and Q quality factor values of three cosmic rays identification models identifying different components.
客观来讲,天顶角、能量以及簇射芯位在阵列中的位置等相关参量也都会受到原初宇宙射线的重建精度的影响,本文目前在算法建模中采用的参量还比较理想化,未将以上参量进行综合考量,下一步我们将在此基础上继续优化和修正机器学习算法模型.
4 结束语
本文将决策树、随机森林、BP 神经网络算法应用在宇宙线粒子分类问题中,并针对不同算法进行超参数优化调整,以提高算法判别的正确率及鉴别效率.实验结果表明,机器学习算法在宇宙射线粒子成分鉴别领域有较大的应用前景.目前本文只考虑了BP 神经网络、决策树和随机森林算法对于宇宙线粒子成分分析的高效率,还未使用其他算法对宇宙线粒子成分进行分析,而且训练和模拟所用参数过于理想化,因此,下一步研究工作中将加入更接近实验中实际探测的观测量,进一步优化机器学习算法,提升粒子鉴别能力,并将继续深入探索其他机器学习算法在宇宙线粒子鉴别中的应用.
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
粉末冶金技术(2021年3期)2021-07-28
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电影(2018年8期)2018-09-21
童话世界(2017年29期)2017-12-16
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中学生数理化·高二版(2016年6期)2016-05-14
郑州大学学报(医学版)(2015年1期)2015-02-27
