
电力系统知识图谱的研究
2023-08-05 07:23李世明
应用科技 2023年4期
李世明
广东电网有限责任公司 电力调度控制中心,广东 广州 510000
电力作为我国国民经济基础的重要基础行业,其对自身的运行数据进行挖掘尤为重要。在电力大数据时代的今天,我国电网每天都会产生海量的电力数据,但目前对这些数据的挖掘和使用却十分有限,难以高效地辅助调度人员进行决策[1−2]。
目前知识图谱在国内虽然有一些应用(如百度、搜狗等搜索引擎),但是在针对电力调度领域的相关研究还非常少[3]。本文旨在搭建一个电网调度领域的搜索引擎,方便调度人员进行专业的知识检索,从而提高其工作效率。
1 电力系统中数据类型与特点
电力系统在工作时每天会产生海量数据,这些数据包括系统运行时产生的各种信息,也包括各种工作计划、活动记录等。这些数据按照数据规范由低到高可分为结构化数据、半结构化数据以及非结构化数据。典型的数据类型如表1 所示。

表1 电力系统中数据分类
从表1 中可以看出,电力系统中的数据的来源较多,数据结构化程度较高,但数据相互之间的关联性较低[4]。因此需要通过知识图谱将电力系统中的各种不同的数据进行分析归类,从中提取业务知识并建立电力业务间的知识关联,最终实现用自然语言来实现对电网进行描述[5]。
2 知识的抽取与融合
构建知识图谱需要有4 个步骤,分别是知识抽取、知识融合、知识存储和知识图谱搭建。构建步骤如图1 所示。
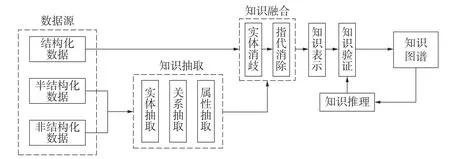
图1 构建知识图谱的步骤
4 个步骤中首先是知识抽取,其最主要的目的是将数据源中的所有数据加工为知识三元组,为后期的数据综合利用、最终构成结构化知识打下基础。采用的知识抽取过程如图2 所示。

图2 电力知识抽取流程
其中关键步骤为从已有的电力系统知识库以及互联网中搜索到的电力系统知识作为训练集合,使用训练集合对神经网络模型进行训练,最后对模型的精准率进行验证。
2.1 实体的抽取
采用长短期记忆网络+条件随机场(long shortterm memory+conditional random field,LSTM+CRF)
经网络模型进行实体抽取,模型分为3 层,分别为词嵌层(word embedding)、长短期记忆网络(long short-term memory, LTSM) 层和条件随机场(conditional random field,CRF)层。其结构模型如图3 所示。词嵌层作为模型的输入层,主要功能是将句子中的单词依据特定规则进行映射,最后将一个句子变为词向量和字向量。LTSM 是循环神经网络(recurrent neural network,RNN)的一种变体,在神经网络的训练过程中,其能够将以前的信息连接到当前任务中,有效地避免了RNN 在循环过程中产生的梯度爆炸与消失的问题[6]。CRF 层的主要目的是对LTSM 层的训练结果,通过已设定约束条件对其进行筛选,提高识别准确度。
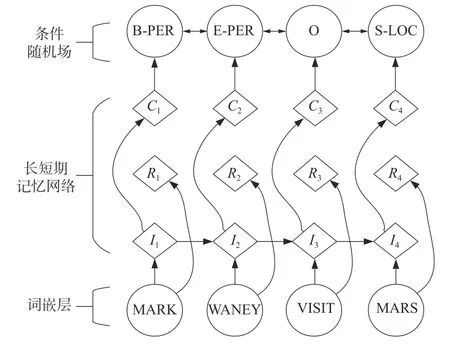
图3 LSTM + CRF 模型
2.2 关系的抽取
脉冲耦合神经网络(pulse coupled neural network,PCNN)模型非常适合于处理自然语言和文本分析、分类等工作[7],适用于知识抽取中的关系抽取。其主要思想是按照自然语句中实体的数量对其进行分段,然后分析每段之间实体的距离与位置之间的关系特征,最终得到实体之间的关系。PCNN 的神经网络结构如图4 所示。
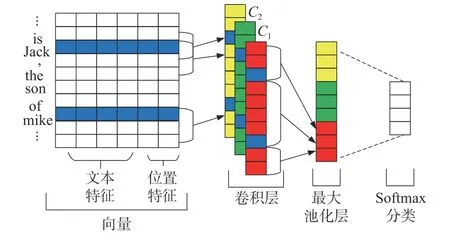
图4 PCNN 神经网络结构
神经网络的第1 层是向量表达层,在该层中,1 个自然语言的句子会按照句子之中的主体(句中关键词,比如电流、电压、频率等)进行分段,对句子中的每个词与主体的距离进行编码,得到位置特征,将文本特征与位置特征进行拼接,从而形成向量。第2 层是卷积层,对上述向量进行卷积计算提取特征。再经过第3 层最大化池化层与第4 层soft max 分类,最终得到主体之间的关系。
3 电力系统知识图谱的搭建
3.1 Neoj4 图数据库
知识的存储有2 种方式,一种是利用常规的关系型数据库如SQL Server 或Oracle 进行存储,另一种是利用图数据模型进行存储。但由于知识图谱数据的特点,将知识作为数据存放在常规数据库中会导致数据库的规模变得很大,并且对数据的操作和查询都会变得非常困难[8−9]。因此一般采用图数据库来存放知识,如NoSQL 数据库,它是一种用图的关系来描述数据之间关系的数据库。在该数据库中,节点代表实体,边代表关系或者属性。Neoj4 是一种较成熟的图数据库,其具有可扩展性强、数据处理效率高以及可支持多核处理器进行并发运算等特点,并且在使用过程中能够有效地保障用户的数据安全[10−11]。
3.2 电力系统知识图谱的搭建
将抽取的电力系统相关知识存入Neoj4 数据库中,形成实体数据库。按照图5 的框架来搭建电力系统的知识图谱。

图5 电力系统知识图谱框架
在图数据库Neoj4 中,实体(如1 个变压器、断路器等)将被用1 个节点来进行表达,节点之间的连线则表示各个实体之间的关系[12−15]。每个节点和边都有属性,属性值按其描述对象性质可动态更新。
经过上述转换,可将电力系统中的各种设备的信息转换为图的形式存储于Neoj4 数据库中。在安装好Neoj4 数据库后,通过Neoj4-import 将区域电网数据与互联网中的数据导入数据库后,所形成的部分电力系统知识图谱如图6 所示。同时,如果日后还需要添加新的知识(新的节点),可通过Cypher 语言以CREATE 语句方式动态更新加入到电力系统知识图谱。
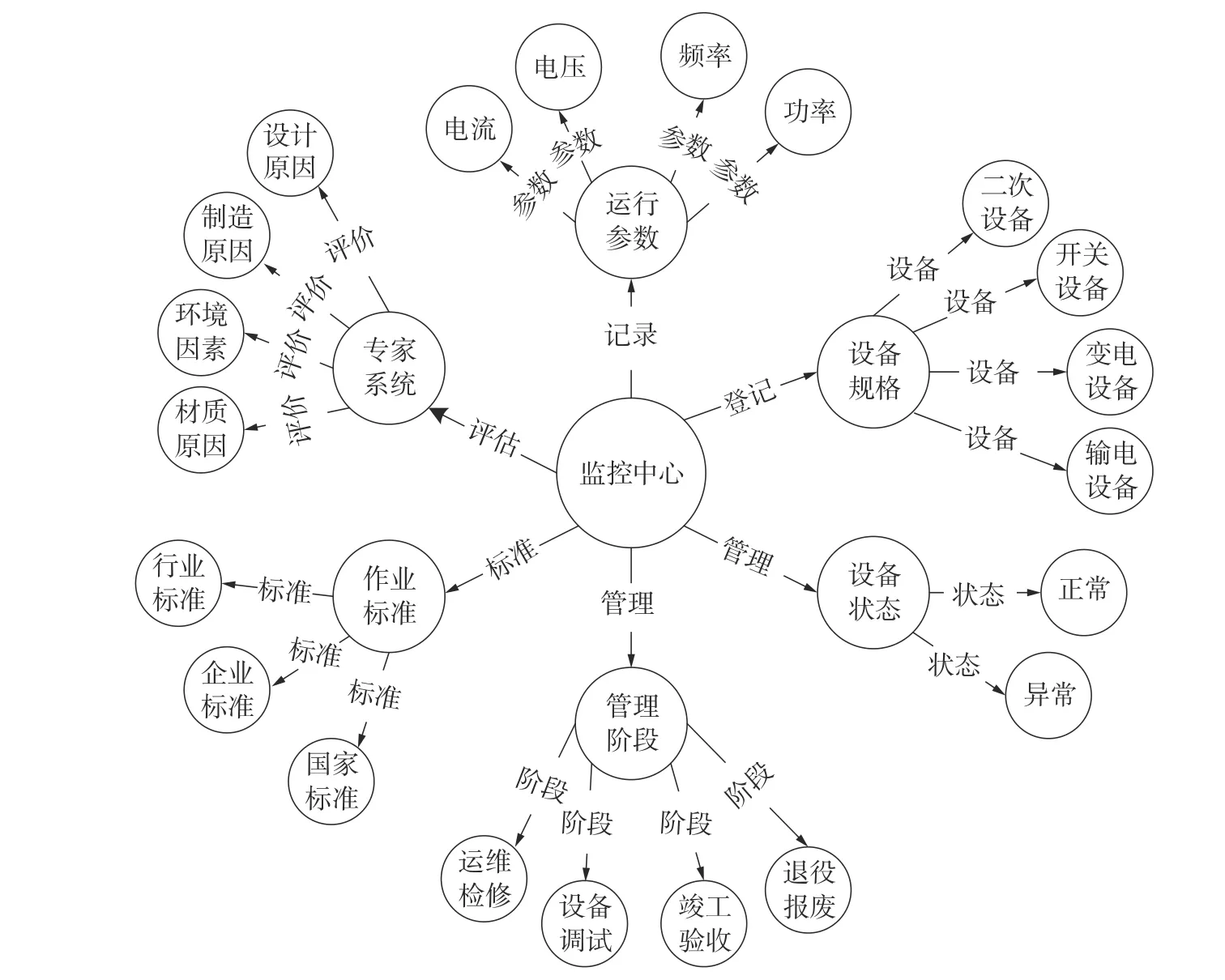
图6 部分电力系统知识图谱
3.3 分类器特征值选取
通过分类器训练进行问句中特征词、特征词表映射,从而获得特征向量。例如对于输入问句“三峡水电站的年均发电量是多少?”,经分词处理后,得到词组“三峡/水电站/的/年均/发电量/是/多少/?”与特征词表特征值进行映射,先设置特征向量全部位置为0,在句中有特征值表中的特征词存在时,设置特征向量中特征词所在位置为1。因问句中有“年均”、“发电量”2 个特征词存在,因而,可得到表2 所示的特征向量。以此类推,将各类训练问句进行转换,从而得到所对应的特征向量。
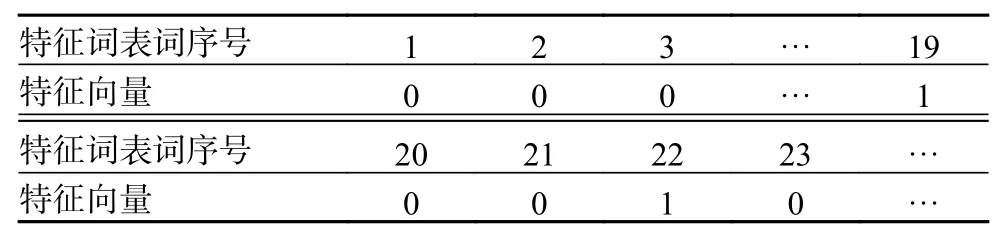
表2 示例问句的特征向量
3.4 知识融合
电力系统中的数据的来源是多样且复杂的,在进行知识抽取的过程中,为了保证抽取知识的有效性,需要对抽取出来的知识进行进一步融合。将知识中表述含义相同但说法不同的主体进行归一化,例如设备故障报告中提到的“工作正常”和“无故障”的表述,其表达的含义是相同的,只是在说法上不同,因此可以对抽取后的知识进行一次字符串的匹配,将这些相同意义的表述进行归一化处理,归一化处理后,重复知识的数量将大幅下降。
4 抽取模型验证及系统功能测试
4.1 数据预处理
本研究采用谷歌(Google)的词向量工具Word2Vec,其特点是能将单词转化为向量。在实际中,使用词汇表通常为百万级以上,处理高维数据会消耗大量计算时间、资源;Word2Vec 词向量可将词与词间的关系很好地表示出来,且维度大幅度降低,同时包含的语义信息更多。应用Word2vec 词向量工具训练数据集,表3 为词向量训练参数。

表3 Word2Vec 训练参数
4.2 数据集构建
搭建电力系统知识图谱先要进行数据集的构造。相关实体从电力领域专业词典中获取,其中有182 341 个词语与电力领域相关,有部分数据集源自某电网电力系统的电力调度产生数据。该数据集包括测试集、训练集。其中测试集包括句子2 590个,字97 780 个;训练集包括句子31 590 个,字1 467 550 个。在进行电力关系分类时,从电力领域专业词典中获取实体,通过百度百科进行相关电力信息、词汇的爬取,并将重复信息去除,从而将出现频率最高并与实际电力领域相符合的测试集、训练集实体数量选取出来,见表4。表5 为电力系统实体关系分类,表6 为测试集、训练集各实体关系数量。
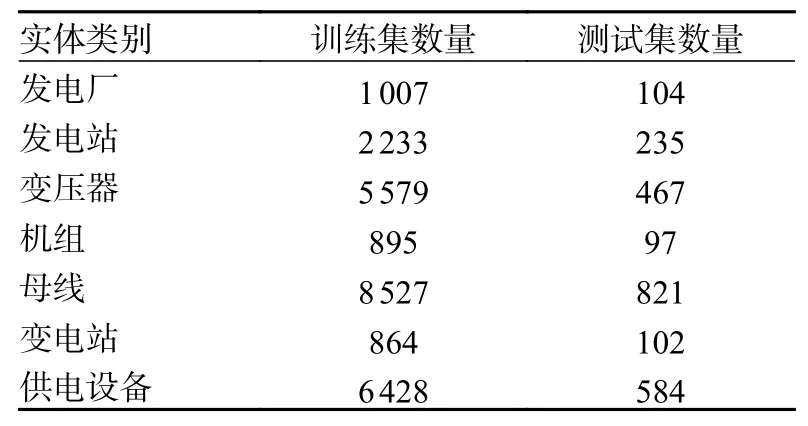
表4 训练集及测试集各实体类别数量
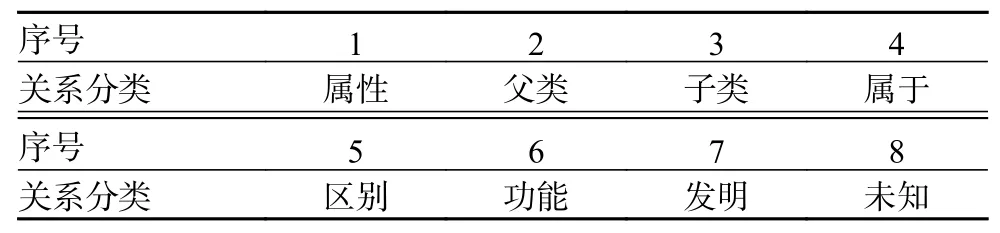
表5 电力实体关系分类

表6 训练集及测试集各实体关系数量
4.3 抽取模型的验证
通过部分电力调度数据以及网络建立训练集与数据集。本次所建的训练集包含48 200 个句子,共2 368 700 个字;测试集包含3 600 个句子,118 700 个字。评价指标为精确率、召回率以及F1值3 大类,训练参数设置如表7 所示。2 种抽取的测试结果如表8 和表9 所示,为表明所选模型的优势,在表格中加入了其他几种神经网络模型训练的结果作对比。

表7 实体抽取与关系抽取训练参数

表8 实体抽取的测试结果%
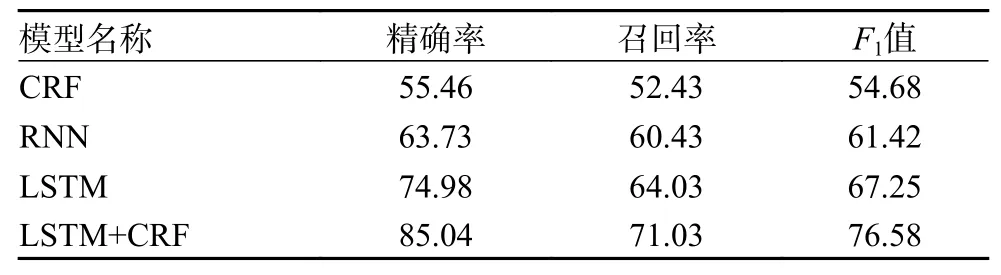
表9 关系抽取的测试结果%
从表8 和表9 中可以看出,LSTM+CRF 模型与PCNN 模型在测试结果上明显高于其他神经网络模型,同时也证明本文选择这2 种神经网络模型的正确性。
4.4 搜索功能测试
以2019—2020 年某变电站的供电数据为基础,数据中包含该站所有设备信息、运行信息等结构类数据,各种工作报表等半结构数据以及缺陷故障分析报告等非结构数据。经过知识提取并存储在图数据库后,形成知识图谱。在原有电力监控系统的基础上,增加了智能检索问答以及故障预警及诊断的功能。
智能检索问答包括标准检索与实体案例2 个方面,测试结果如图7 所示。在检索框中输入“变压器接地电阻大于10 Ω”,在后台的数据库中会按照关键词“变压器”、“接地电阻”来进行搜索,最终搜索结果包含国家关于接地电阻的标准以及实际故障的案例,有针对性地给从业人员提供建议。

图7 智能检索测试界面
5 结论
1)通过对实体抽取的结果进行对比可以发现,采用单一神经网络模型抽取的效果没有采用复合神经网络模型的效率高。
2)采用LSTM+CRF 模型进行实体抽取,PCNN 模型进行关系抽取能够取得较好的效果。
3)通过浏览器实现了电力知识的查询,提高了工作人员的效率。
知识抽取的方法还有很多,并且由于受实际条件限制,本次研究使用的训练样本规模也较小。以后可向这2 个方向进一步提高知识抽取的效率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
