
基于CLIP 的多模态视频文本检索系统
2023-08-09 15:26叶柯陈相余麻福旦
计算机应用文摘·触控 2023年15期
叶柯 陈相余 麻福旦
摘 要:计算机视觉(Computer Vision,CV)与自然语言处理(Natural Language Processing,NLP)技术已逐渐趋于成熟,结合视觉和语言的多模态领域技术将成为学界和业界的研究热点。文章使用CLIP 预训练模型,结合图像与语言两种模态信息,进一步将图像拓展至视频,利用 Fmpeg 处理视频,并对视频与文本信息进行嵌入(embedding)和余弦相似度匹配,从而实现利用纯文本检索视频中符合该文本语义的片段。
关键词:多模态;CLIP;FFmpeg 处理;文本检索视频
中图法分类号:TP311文献标识码:A
1 引言
随着社交媒体和视频分享平台的迅猛发展,人们每天都生产大量的视频内容,这些视频包含丰富的视觉信息。然而,要从庞大的视频库中检索到与特定文本语义相关的片段却变得愈发具有挑战性,除了用人眼进行人工检索这种费时费力的解决方案外,传统的基于文本的检索方法难以充分利用视频中的视觉信息,而基于视觉的方法又难以理解文本语义。因此,将视觉和语言进行融合的多模态技术成为解决这一难题的关键。
综上所述,高效可用的多模态视频文本检索具有广泛的应用前景和重要的实际意义,可以为大规模视频内容的管理和组织提供强有力的工具。
2 发展现状
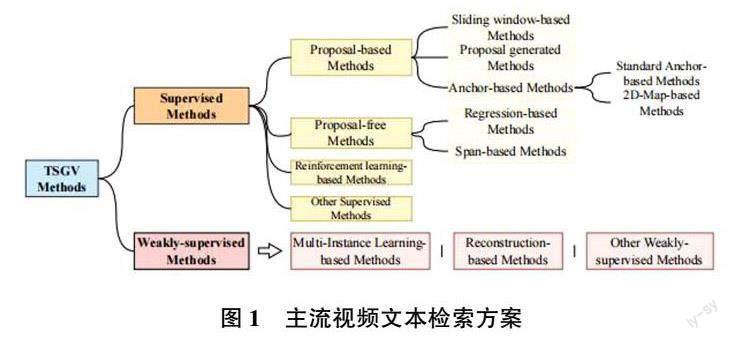
近年来, 深度学习和预训练模型快速发展,Zhang[1] 总结了视频文本定位任务的基本概念和当前的研究现状,并对主流的解决方案进行了分类。主流视频文本检索方案如图1 所示。
目前,视频文本定位方案通常需要经过训练,以便模型能够学会正确地定位视频中的文本。例如,Gao[2] 第一次提出了视频文本定位的范式,利用滑动窗口的方式截取视频片段并与标签进行匹配,随后Yuan[3] 去掉了滑动窗口算法,引入attention,Zhan 在VSLNet[4] 中引入了query?guide?highlight 机制,进一步提升了检索精度;为了训练这样的模型,其采用了使用标注的start 和end 标签来指示文本在视频中的位置。在标注数据集时,标注人员根据视频中出现的文本内容和时间点,手动标注出文本的起始位置和结束位置。基于此,在训练过程中模型可以通过学习这些标签来理解文本在视频中的位置关系。
然而,这种训练方式往往导致模型的泛化性较差,即在面对新的、未见过的视频场景时,模型无法准确地进行文本定位。并且训练过程产生的成本通常较高,故期望能够采用无监督的方式进行视频文本定位,不仅可以保证更好的鲁棒性,而且更能节省人工标注等数据及相关的训练成本。在多模态方面,OpenAI 通过对比学习的方式训练得到CLIP 模型,作为预训练模型,它可以同时理解图片和文本的语义信息,且能够在没有任何特定任务标注的情况下,学习到跨模态的语义表示,这使得CLIP 在图像分类、文本分类、图像生成描述等[5] 多种任务上都有出色表现。本文利用CLIP 预训练模型,将图片拓展为视频,实现zero?shot 的视频文本检索。
3 系统构建
3.1 前端设计
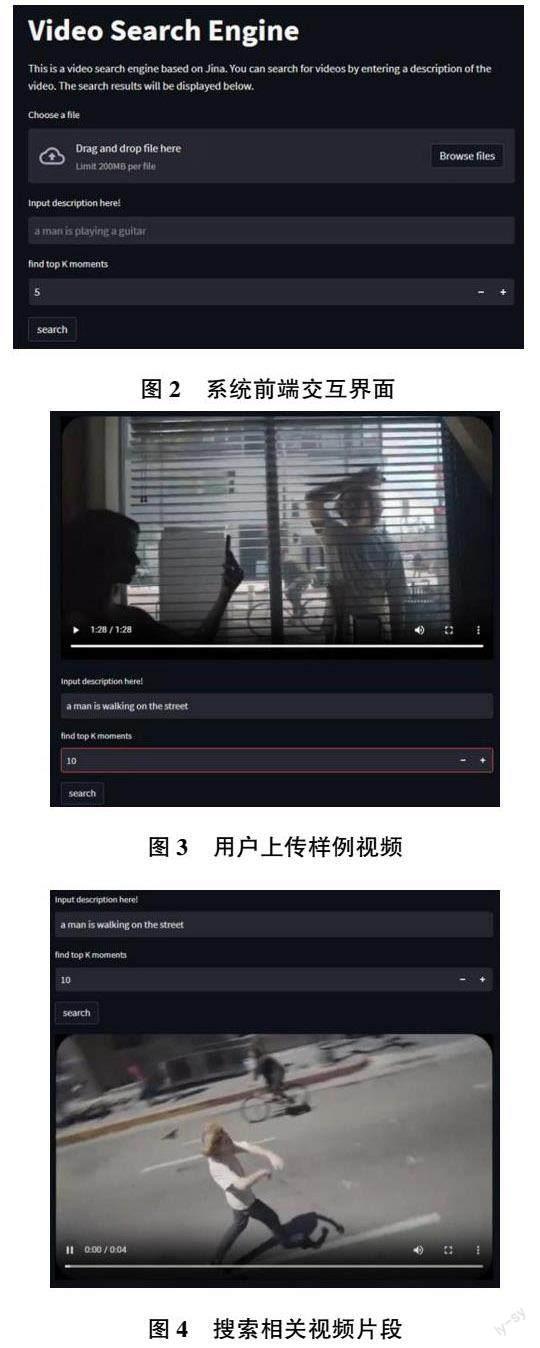
系统前端使用Streamlit 框架搭建。Streamlit 是一个用于构建数据科学和机器学习应用程序的开源Python 框架,其具有简单的API 和直观的设计,便于构建交互式应用程序,可使用少量代码创建数据可视化和用户界面;页面可以即时显示和预览应用程序的变化,进行快速调试和实验;同时,Streamlit 的自动化布局功能使得构建应用程序界面变得更加简单和高效,其开源的组件化模式具有可重用性、模块化开发、易于维护和更新、可测试性以及灵活性和可扩展性等优点。系统前端交互界面如图2 所示。
3.2 后端设计
使用Python 进行后端开发,并使用FFmpeg 对上传的视频进行处理。FFmpeg 是一个开源的多媒体处理工具集,提供了多种音频和视频处理功能,它可以用于转换、编辑和流式传输多媒体内容,支持几乎所有常见的音频和视频格式。前端Streamlit 为Python框架,简单易用,可直接与后端交互,故在后端进行模块化功能编程时,在前端框架中通过函数接口的方式来调用后端算法和模型,在一定程度上降低了系统的耦合度,并且采用并行的策略调用后端算法,这使得系统可以实现多线程的监听,可以有效防止函数接口堵塞等待问题。
用户自行上传视频,进行预处理后,输入目标视频片段相关的文本即可进行检索,如图3、图4 所示。
由此可见,基于CLIP 预训练模型实现的zero?shot视频文本检索任务无需经过训练,仅通过推理,便可以准确地提取视频片段中的人物行为信息,显示出其优秀的泛化性和用于视频文本检索的巨大潜力。除对行为信息的视频检索外,本文同样对视频中个体特征的识别进行了相关实验。
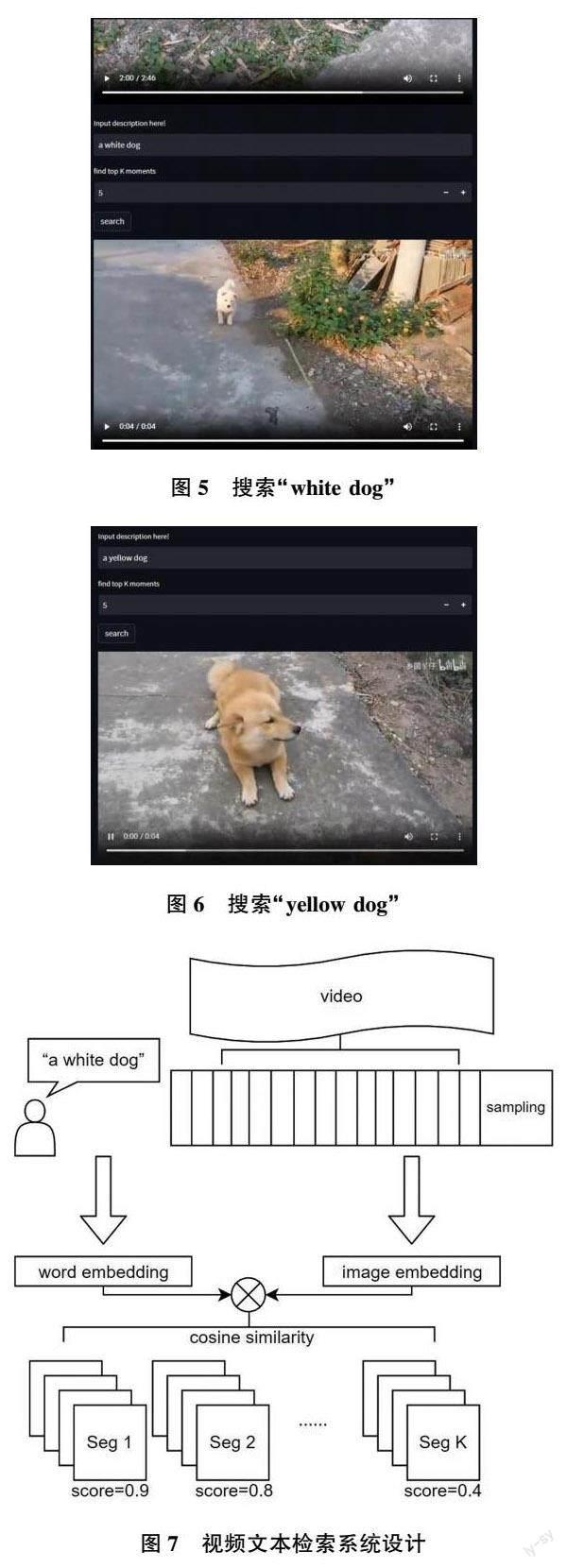
对于同一个视频,用户可以通过文本描述想要检索的个体特征,如“white dog”“yellow dog”,实现语义级别的视频片段定位,如图5、图6 所示。
3.3 视频文本检索系统设计
首先,利用FFmpeg 对用户上传的视频进行裁剪,离散地抽取视频中若干帧,这可以有效地减少视频特征中的冗余信息以及计算量。其次,利用CLIP 对抽得的帧进行特征提取和嵌入向量,用户输入文本信息后,再利用CLIP 将文本进行特征提取得到嵌入向量。
最后,将文本特征与视频特征进行匹配,计算cosine?similarity,根据用户前端控制的top?k 来决定索引返回的视频片段数量,然后根据相似度计算得到视频片段并与文本匹配分数进行降序反馈和显示。视频文本检索系统设计如图7 所示。
4 结束语
针对近年来视频数据爆炸式增长的状况,本文基于CLIP 预训练模型,利用文本实现视频检索,大幅降低人工进行视频检索的成本。未来,随着硬件算力的增长,该模型将会有更大的使用空间,相信在相关技术更加成熟后,这套系统可以被应用到社会更多行业中。例如,公安部门可以利用文本在海量的监控视频中寻找关键片段;利用辅助剪辑的功能帮助视频后期相关人员在若干小时的拍摄素材中寻找想要的片段等。
参考文献:
[1] ZHANG H,SUN A,JING W,et al.The Elements of TemporalSentence Grounding in Videos: A Survey and FutureDirections[J].IEEE Xplore,2022,45(8):10443?10465.
[2] GAO J,SUN C,YANG Z,et al.tall:temporal activity locali?zation via language query (supplemental material)[J].IEEEXplore,2017,21(10):5267?5275.
[3] YUAN Y,MEI T,ZHU W.To Find Where You Talk:TemporalSentence Localization in Video with Attention Based LocationRegression [ J]. Proceedings of the AAAI Conference onArtificial Intelligenc,2018,33(1):9159?9166.
[4] ZHANG H, SUN A, JING W, et al. Span?based LocalizingNetwork for Natural Language Video Localization [ J ].Publisher:Association for Computational Linguistics,2020,21(5):6543?6554.
[5] RADFORD A,KIM J W,HALLACY C,et al.Learning Transfer?able Visual Models From Natural Language Supervision[J].International Conference on Machine Learning,2021,10(139):8748?8763.
作者简介:
叶柯(2002—),本科,研究方向:多模态、文本生成、目标检测。
猜你喜欢
电影文学(2016年19期)2016-12-07
戏剧之家(2016年22期)2016-11-30
科教导刊(2016年26期)2016-11-15
知音励志·社科版(2016年8期)2016-11-05
戏剧之家(2016年19期)2016-10-31
戏剧之家(2016年19期)2016-10-31
科学与财富(2016年28期)2016-10-14
