
基于Vine Copula函数的风浪要素联合概率分布模型
2023-08-31 10:41王望朱金康锐李永乐
土木与环境工程学报 2023年4期
王望,朱金,康锐,李永乐
(西南交通大学 桥梁工程系,成都 610031)
海洋环境恶劣,往往存在大风和巨浪的组合作用,同时,跨海大桥具有基础结构尺寸大、主跨轻柔、阻尼小、刚度小等特点,导致跨海大桥对风浪等海洋环境荷载非常敏感,极端风浪荷载成为威胁跨海大桥安全的主要因素之一。目前,跨海大桥多灾害作用的研究中通常研究单一灾害(如风、波浪、地震、冲刷等)对桥梁结构的作用,未能很好地考虑各灾害之间的相关性。特别是风浪要素,其包含了众多影响跨海大桥动力特性的参数,如风速、风向、波高、波向、波浪周期等,各参数是随时间变化的随机变量,且相互之间具有不同的尾部相关结构(即非线性)。因此,构造风浪要素的联合分布函数是研究海洋环境中风浪耦合效应及进一步探究风浪各要素对跨海大桥动力响应特征影响规律的基本前提。
Copula 函数将多维联合分布分解为相应的边缘分布和Copula 函数之积,可以灵活地表示两两随机变量之间的相关结构。近年来,Copula 函数在土木工程领域逐渐得到关注。Li 等[1]基于C-Vine Copula理论,研究了阿拉斯加南部海岸风浪相关性,并由建立的模型推算了特定重现期的长期荷载。Zhang 等[2]采用椭圆Copula 和三维Placket Copula 建立了风速、风向和温度的三维联合分布。Bai 等[3]采用混合二维Copula 来描述风浪环境变量的相关性并与采用单一Copula 的情况进行对比,研究表明,混合Copula 能更好地描述多维变量之间复杂的相关关系。Wang 等[4]基于Copula 理论,提出了一种利用气象资料研究大跨桥梁风温联合作用的方法并应用于常泰长江大桥。Zhang 等[5]基于非对称Copula 函数,模拟了海洋环境要素的相关关系,侧重于捕捉环境要素的非对称相关关系。Li 等[6]在浮式风力发电机组的概率疲劳评估研究中,基于Copula 函数建立了多维概率模型,用来定义风浪环境参数相关性。Vanem[7]对特征波高和波浪周期的同时进行了多维分布研究,结果表明,使用非对称Copula 函数能较好地模拟非对称的相关关系。Yang 等[8]基于三维Copula 函数建立了风速、风暴潮和暴雨的联合概率分布,提出了一种有效的PSO 算法来估计边缘分布和联合分布的参数,并与极大似然法和对数似然法进行对比验证。Wang 等[9]通过建立挪威Sulafjord 的短期近海数据和桥址区数据之间的定量关系,推算了桥址区长期风浪数据,从而建立了风浪联合分布。Zhang 等[10]通过基于Copula 的多维概率模型,研究了考虑多种环境因素的近海结构长期荷载,由此建立了多种常见海况参数之间的联合概率模型。Xu 等[11]将Copula 函数应用于海洋结构可靠度的分析,描述了波高、波峰和平均风速3 个近海环境参数之间的相关性,研究表明,该方法可用于考虑长期疲劳荷载和极端响应的海洋结构可靠度分析。陈子燊等[12]采用非对称Archimedean Copula 函数分析极端波况下波高、风速和周期的三变量联合概率分布,计算了“或”重现期、“且”重现期和二次重现期,探讨了规范设计值的安全性并给出了建议。Copula 理论不仅在海洋环境要素相关性研究方面有广泛的应用,在结构可靠度等其他领域也有重要的应用。陈建兵等[13]基于Copula理论,建立了混凝土参数之间的相关性模型,由生成的样本计算了混凝土本构全曲线。樊学平等[14]基于R-Vine Copula 理论对大跨桥梁主梁检测点失效概率的相关性进行了研究,建立了检测点的相关性模型。刘月飞等[15]基于桥梁检测点的极值应力数据,建立了描述检测变量非线性相关的Vine Copula 模型。宋帅等[16]将混合Copula 方法应用于桥梁系统地震易损性分析中,准确描述了构件地震需求的非对称相关关系,简化了联合分布模型的建立过程。
综上所述,以上基于Copula函数的海洋环境参数联合分布的研究极大促进了跨海桥梁的建设,但是目前相关研究多针对二维及三维的海洋环境参数,这对准确模拟复杂多变的海洋环境来说是不够的。如前所述,海洋风浪要素中的风速、风向、波高、波向、波浪周期对于跨海大桥的动力响应均有重要影响,然而,目前针对风浪要素多维联合分布的研究还鲜有报道。笔者在单一Copula 函数的基础上,基于Vine Copula理论建立了海洋风浪要素中风速、风向、波高、波向、波浪周期五维变量之间的联合分布模型,从而准确刻画了风浪要素之间的相关关系。首先,建立风浪各个要素的边缘概率模型,采用均方根误差(RMSE)进行拟合优度评价;在得到风浪各要素边缘分布的基础上,基于Copula 理论,建立风浪要素两两之间的二维联合概率分布模型,通过AIC 信息准则和均方根误差RMSE 进行拟合优度评价,并考察风浪要素两两之间的相关性;基于Vine Copula理论,采用C-Vine结构构建了风浪要素中风速、风向、波高、波向、波浪周期五维变量之间的联合概率分布模型。通过AIC 准则对模型进行拟合优度评价。
1 边缘分布
1.1 数据说明
采用位于中国东海的连云港海洋观测站2016—2020 年波浪和风场观测数据,数据由中国国家科技资源共享服务平台——国家海洋科学数据中心(http://mds.nmdis.org.cn/)提供数据支撑。选用的风浪要素包括10 m 高度处最小平均风速、特征波高、波浪周期、风向和波向,测量频率为每小时测量一次,站点的经纬度为34°47′0″N 119°26′0″E,最大风速为22 m,达到强风等级,最大波高为2.4 m。风浪数据信息如表1 所示。需要说明的是,笔者在进行数据处理时发现,海洋站的观测数据中有很少一部分数据存在缺失的情况,即有个别或多个要素的数据没有观测到。针对这种情况,将缺失的样本数据予以剔除,尽可能多地保留其余数据样本,最后得到的样本总量为29 363 个。

表1 风浪要素数据信息Table 1 Information of wind and wave data
1.2 边缘分布
首先,需要建立风浪要素的边缘分布模型。研究中发现,风速、波高、波周期样本具有单峰分布的特征(图1(a)~(c)),采用常见的单峰分布模型进行拟合,包括Weibull、广义极值分布(GEV)、含有尺度参数和位置参数的t分布等。风向和波向具有多峰分布的特征(图1(d)、(e)),采用混合模型进行拟合,包括混合Gaussian 分布、混合Gamma 分布、混合Weibull 分布。

图1 风浪要素概率分布直方图及最优边缘概率分布曲线Fig.1 Histogram of wind and wave data and the optimal marginal probability distribution curve
1)Weibull 分布
式中:λ为尺度参数;k为形状参数。
2)广义极值分布(GEV)
式中:ξ、β、μ为分布函数参数;ξ为形态参数;σ为尺度参数;μ为位置参数。
3)含有尺度参数和位置参数的t分布
式中:ν、σ、μ 均为分布函数参 数,其 中:ν为形态参数;σ为尺度参数;μ为位置参数。
4)混合Gaussian 模型
5)混合Gamma 模型
当采用上述概率分布模型对风浪要素进行拟合时,概率分布模型的参数估计采用极大似然法。另外,为了评价不同概率分布模型的拟合效果,采用AIC、BIC 和RMSE 对概率分布模型进行拟合优度评价,并据此选取最优的概率分布模型。AIC、BIC 和RMSE 的计算 式为
式中:xi为样本值;n为样本数量;f(xi)为备选边缘分布函数的密度函数;k为备选边缘分布函数中分布参数的数量。
式中:xi为样本值;n为样本数量;f(xi)为备选边缘分布函数的密度函数;k为备选边缘分布函数中分布参数的数量。
式中:n为样本数量;Pc为多维Copula 联合分布理论频率值。RMSE 值越小,拟合的效果越好。
通过观察风向概率直方图(图1(d))可以看出,风向的概率分布有3 个较为明显的峰值,因此,采用的混合概率模型中应包含3 个单峰分布,故采用混合维度为3 的混合模型(3 个单峰分布函数混合)来拟合。与风向类似,波向频率直方图(图1(e))也有多个峰值,分别采取二维和三维混合模型对波向的概率分布进行拟合,通过对比RMSE 发现,三维混合模型的概率拟合效果较好。表2 和表3 给出了风速、波高、波浪周期、风向、波向5 个风浪要素的最优边缘概率分布类型和相应参数。此外,图1 还给出了这5 个风浪要素样本的直方图及最优边缘概率分布曲线。由图1 可以看出,选取的最优边缘概率分布曲线对5 个风浪要素样本的拟合效果较好。拟合优度评价结果表明:风速、波高、波周期的最优拟合分布分别为Weibull 分布、广义极值分布(GEV)、含有尺度参数和位置参数的t分布;而风向和波向的最优拟合分布均为混合Gaussian 分布。

表2 风速、波高、波周期最优边缘概率分布Table 2 The optimal marginal probability distribution of wind speed,wave height and wave period

表3 风向、波向边缘分布Table 3 The marginal distribution of wind direction and wave direction
2 二维联合分布
2.1 二维Copula 理论
根据Sklar 定理[17],多维联合分布和其边缘分布可以写为
式中:Fi(xi)为随机变量xi的边缘概率分布函数;C(·)为Copula 函数;θ为Copula 函数的参数。
将海洋环境变量定义为一个n维随机变量X=(x1,x2…xi…xn),基于Copula 理论,联合概率密度可以表示为
式中:Fi(xi)、f(xi)分别为随机变量xi的边缘概率分布的分布函数和概率密度函数;c为Copula 密度函数。
由式(10)可得二维联合分布概率密度函数公式
式中:c为二维Copula 函数的密度函数。
由式(11)可知,为了研究风浪要素之间的二维联合概率分布,首先应建立风浪要素两两变量之间的Copula 函数。选取风速—波高、波高—波周期、风速—风向、波高—波向4 个随机变量对来研究并建立二维Copula 函数。目前,研究风浪要素联合分布的大多数文献均将这些变量对作为研究对象。其次,这些变量对中的两个变量之间往往存在较大的相关性,而这些相关性在进行结构(如海上风机、跨海桥梁等)的动力响应分析时又至关重要。样本数据经过式(12)可以变换为范围0~1 的标准分布,样本的标准分布忽略了样本数值大小的差异,只保留数据的相对大小关系,以便于更清晰地研究数据之间的相关性。图2 是风速—波高经验Copula 频率直方图,可以看出,风速和波高具有较强的尾部相关性。

图2 风速—波高标准分布二维频率直方图Fig.2 Binary frequency histogram of standard distribution of wind and wave
式中:U为将样本变换为范围为0~1的标准分布后的随机变量;n为样本个数;R为样本点在所有样本中的排序。
常用的二维Copula 函数类型有:Gaussian、T、Clayton、Gumbel、Frank,如表4 所示。

表4 5 种典型的Copula 函数Table 4 Five typical Copula functions
2.2 拟合优度评价
要进行拟合优度评价,首先要计算经验Copula,经验Copula 可以通过式(13)计算[18]。
式中:n为样本的大小,对每一个1≤i≤n,满足u1i≤u1,u2i≤u2时,I(u1i≤u1,u2i≤u2)=1。
对应三维的情况,经验Copula 可通过式(14)计算。
式中:n为研究样本的大小,对每一个1≤i≤n,满足u1i≤u1,u2i≤u2,u3i≤u3时,I(u1i≤u1,u2i≤u2,u3i≤u3)=1。
为了对选取的Copula 函数进行拟合优度评价,选用均方根误差(RMSE)作为评价标准来评价模型的优劣。
Sn越小,说明拟合的Copula 模型与经验Copula越接近,拟合效果越好。
建立二维联合分布可以对多种Copula 函数分别进行参数估计,采用贝叶斯框架和基于残差的高斯似然函数进行参数估计[19]。
贝叶斯分析已在多个领域应用于参数估计。当获得新信息时,贝叶斯理论更新假设的先验概率,将所有建模的不确定因素归因于参数,通过式(16)估计模型参数的后验分布。
在缺乏参数先验分布的有效信息时,可以采用均匀先验,假设残差不相关,同方差、均值为零的高斯分布,那么似然函数就可以通过式(17)表示。
通过AIC、BIC 及RMSE 对不同类型的Copula模型进行拟合优度评价,拟合优度评价结果见表5,参数估计值见表6。风速—波高的最优联合分布为θ=0.846 1 的Gaussian Copula;波高—波浪周期的最优联合分布为θ=0.465 3 的Gaussian Copula;风速—风向的最优联合分布为θ=-1.145 7 的Frank Copula;波高—波向的最优联合分布为θ=0.541 0 的Gaussian Copula。图3 为θ=0.846 1 的Gaussian Copula 函数图像。

图3 Gaussian Copula(θ=0.846 1)概率密度图Fig.3 Probability density of Gaussian Copula (θ=0.846 1)
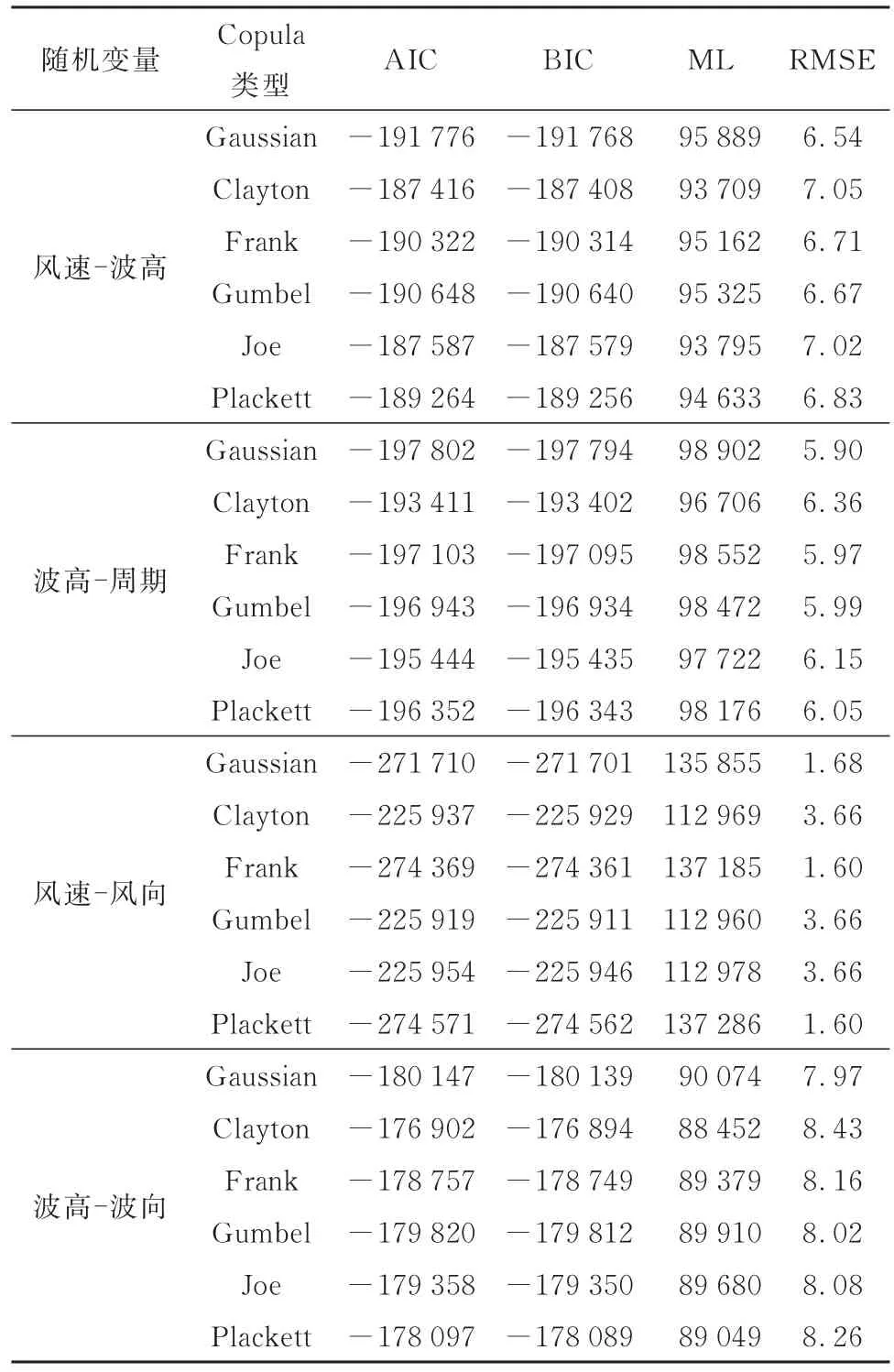
表5 二维Copula 拟合优度评价Table 5 The performance evaluation of 2-dimensional Copula distribution

表6 最优二维Copula 分布及拟合参数Table 6 The optimal 2-dimensional Copula distribution and fitting parameters
由图2 和图3 可以看出,Gaussian Copula 能较好地模拟风速—波高的相关性。此外,样本数据的二维频率直方图可以表示联合分布的经验图像,与图4 不同的是,图3 只表示两随机变量之间的相关关系,略去了两随机变量之间数值大小的影响,通过图3能更清晰地了解二者的相关关系。图4 则表示出两随机变量之间联合分布的图像,保留了样本数值大小的信息。通过二维频率直方图和联合分布的概率密度图可以直观比较本文选取的二维Copula 模型的拟合效果,如图4 所示。由图4 可以看出,对于风速—波高、波高—周期、风速—波向,其二维联合概率密度图与经验图像的峰值和形状都比较接近,说明相关性模拟较为合理,较好地考虑了风浪要素之间的相关性。同时,从图4 也可以看到波,高—波向的联合分布与经验直方图的峰值大小存在一定差异,这是由于该样本波高—波向之间的相关性比较复杂,采用单一的Copula函数模拟它们之间相关性的效果有限,在后续研究中,可以采用混合Copula 函数来进行模拟,并优化拟合效果。由于不同海域的风浪要素之间的相关关系可能会有较大的差异,本研究侧重于探究建立风浪联合分布的方法和思路,因此未对波高—波向的二维联合概率模型作进一步优化。

图4 风浪要素两两变量之间的频率直方图及最优二维Copula 函数Fig.4 Binary frequency histogram of wind and wave data and the corresponding optimal 2-dimensional Copula distribution
3 多维联合分布
可以采用多维Copula 函数建立多维随机变量的联合分布,但可供选用的多维Copula 函数类型有限,且灵活性较弱。Joe[20]提出了采用Vine Copula来构建多维随机变量的联合分布的方法,Vine Copula 具有结构多样灵活的优点。
3.1 Pair-Copula 理论
Bedford 等[21]提出了通过Pair-Copula 构建多维随机变量联合分布概率模型的方法,基于条件概率可以将多维随机变量分解成一系列的Pair-Copula结构,分解时采用的逻辑结构不同,可以构造出不同的模型。Pair-Copula 结构推动了Copula 理论在多维随机变量应用中的发展。
根据条件概率,多维联合分布概率密度函数可以表示为
由式(19)可以得到二维随机变量的联合概率密度函数为
式中:a,j=1,2 …n,且a≠j;ca j(Fa(xa),Fj(xj))为xa和xj的二维Copula 密度函数。
由式(20)可以推导xj已知的情况下xa的条件概率密度
由式(21)可得在n维随机变量u已知的条件下,任意随机变量x的条件密度函数
式中:ua是n维随机变量u中的一个分量;u-a是n维随机变量u中去掉ua之后的n-1 维分量。
以三维联合分布为例说明分解过程,根据式(19),三维的联合分布函数可写为
由式(22)可以得到
代入式(23)即可将多维联合分布分解为Pair-Copula 结构和边缘分布的概率密度函数的乘积
3.2 Vine 结构
高维Copula 函数可以通过R-Vine 结构来建立。基于两两随机变量之间的相依组合,结合条件概率可以建立多维Copula 函数。R-Vine 中有两类特殊的Vine:C-Vine 和D-Vine,这两类Vine 有各自的逻辑结构,用于建立高维变量之间的联合分布。
C-Vine 结构的特点是每层树都有一个主节点,主节点连接其他所有节点。为方便阐述构造原理,图5 给出了四维的C-Vine 结构图,该C-Vine 的结构有3 棵树,每棵树有一个主节点,主节点和其他节点(node)相连形成边(edge),边在下一棵树中作为主节点,以此类推,直到连接所有树的节点。对任意维n维C-Vine,有n-1 棵树,有n(n-1)/2 条边,每条边对应一个Pair-Copula 结构。

图5 四维C-Vine 分解结构Fig.5 Decomposition structure for four-dimensional C-Vine model
D-Vine结构的特点是每层树的节点依次相连,呈直线状。图6给出了四维D-Vine的结构,该D-Vine结构有3棵树,每棵树中节点一次连接,形成边,边在下一棵树中成为节点,用同样的方式类推,直至连接所有节点。对任意维n维D-Vine,同样有n-1棵树,有n(n-1)/2条边,每条边对应一个Pair-Copula结构。

图6 四维D-Vine 分解结构Fig.6 Decomposition structure for four-dimensional D-Vine model
C-Vine 的多变量分解结构的确定需要先确定根节点和其他节点的顺序,C-Vine 的根节点通常选取与其他变量相关性最强的节点,可以采用Aas等[22]与Dißmann 等[23]提出的序惯估计法来确定。
1)从第1 层树开始,计算所有随机变量两两组合的经验Kendall 相关系数τ,如表7 所示,选取和其他随机变量的相关系数τ之和最大的随机变量作为根节点,这样就确定了第1 层树的结构。

表7 经验Kendall’s τ 矩阵及Kendall’s τ 之和Table 7 The empirical Kendall’s τ and the sum of it
2)选择第1 层树中二维随机变量的Copula 函数种类并使用极大似然法估计参数θ。
3)结合第2)步确定的Copula 函数及参数θ,通过式(25)将原随机变量转换为条件随机变量,即树2 的随机变量。
式中:v-j为v中除去vj的n-1 维向量,F(x|v)为条件分布函数,Cxvj|v-j为连接F(x|v-j)与F(vj|v-j)的二维Copula 函数。
4)使用确定树1 结构的方法确定剩余的所有树。
采用C-Vine Copula 构建多维联合分布,图7 给出了最优C-Vine 的构造,1~5 分别表示风速、波高、周期、风向、波向,五维C-Vine Copula 有4 层树,在第1 层树中,随机变量2(波高)与其余4 个变量分别通过二维Copula 连接,形成4 条边;在第2 层树中,这4 条边作为节点,选取一个主节点,再一次通过二维Copula进行连接,以此类推,直至连接所有节点。

图7 维C-Vine Copula 结构Fig.7 The optimal five-dimensional C-Vine model
由式(10)和图7 可得,五维随机变量(x1,x2,x3,x4,x5)的C-Vine 联合概率密度函数如式(28)所示。
式中:Fi(·)为每个随机变量的累积分布函数;F·|·(·|·)为条件分布函数;c·,·(·,·)为Copula 密度函数;c·|·(·|·)为Copula 密度函数。
可以通过比较AIC 值进行C-Vine Copula 模型的拟合优度评价,AIC 的值越小说明拟合效果越好。一般来说,C-Vine 和D-Vine 均可用于构建数据的联合分布,具体采用哪一种模型应该取决于数据本身,通常应通过试算来最终确定较优的模型。分别采用C-Vine 和D-Vine 来构建风浪联合分布模型,并对比两种模型的AIC 值,发现C-Vine 能更好地模拟该海洋站点的风浪联合分布模型。因此,最终采用C-Vine 来构建风浪的联合分布模型。此外,采用序惯估计法得到风浪联合概率分布的C-Vine 模型。通过序惯估计法得出的最优根节点顺序为2、1、4、5、3(1~5 分别表示风速、波高、周期、风向、波向),AIC 值为-27 508,如表8 所示。采用遍历所有根节点顺序的方法(即考虑了所有可能的根节点顺序),对由序惯估计法得出的C-Vine 风浪联合概率分布模型进行拟合优度评价。五维随机变量的根节点顺序共有=60 种,针对每一种根节点顺序,首先采用AIC 准则建立相应的C-Vine 模型,并通过AIC值的大小对60 个C-Vine 模型进行排序,结果如表9所示。限于篇幅,仅给出了前20 个较优的C-Vine模型及相应的根节点顺序。通过比较发现,通过序惯估计法建立的C-Vine 模型的AIC 值在60 种情况中排第3,并且其AIC 值与前面2 个模型的AIC 值非常接近(相差0.31%以内)。因此,序惯估计法能高效且准确的找出较优的C-Vine 联合概率模型,该模型能很好地描述风浪要素间的相关关系。随着变量维度的提升,根节点的组合会迅速增加,采用遍历所有根节点顺序的方法会极大地增加计算负担,由此也体现出序惯估计法的优越性。
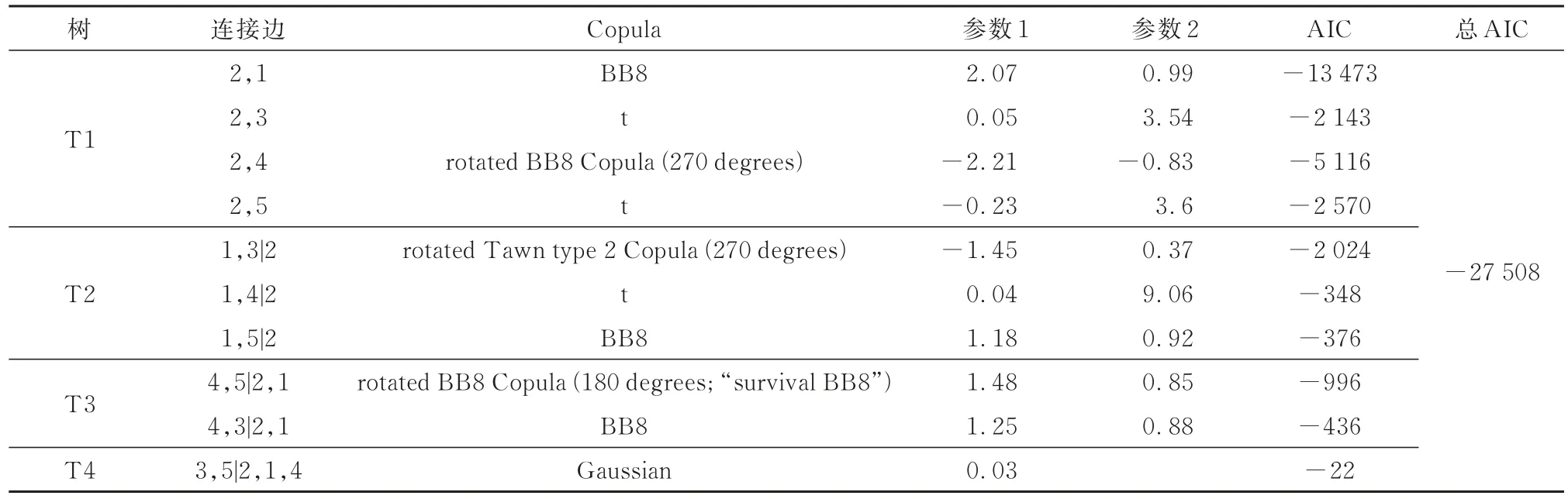
表8 最优C-Vine 参数及AIC 值Table 8 The optimal C-Vine parameters and AIC values

表9 不同C-Vine 模型的根节点顺序和AIC 值Table 9 The root node order and AIC value of different C-Vine models
通过建立的C-Vine 模型仿真了风速、波高、波浪周期、风向和波向五维随机变量之间的累积概率密度(CDF)。为了更直观地观察拟合效果,以风速、波高、风向为例,结合式(14),图8 给出了其三维联合分布的累积概率密度,黑色网格是原始数据的经验Copula 图像,彩色图像是由C-Vine 模拟产生的图像。由图8 可知,建立的C-Vine 模型能较好地模拟风速、波高、风向的相关关系。

图8 三维累积概率密度图Fig.8 Diagram of three-dimensional cumulative probability density
4 结论
基于Vine Copula 函数研究了中国东海连云港海洋观测站的风浪要素之间的联合概率分布,得出以下结论:
1)风速、波高、波周期的概率分布为单峰分布,最优拟合分布分别为Weibull 分布、广义极值分布、t分布;而风向和波向的概率分布为多峰分布,最优拟合分布均为混合Gaussian 分布。
2)风浪要素中两两随机变量之间的联合概率分布研究表明,风速-波高、波高—波周期、风速—风向、波高—波向4 个二维变量对的最优二维联合概率分布分别为Gaussian Copula、Gaussian Copula、Frank Copula 和Gaussian Copula。
3)建立的C-Vine 模型可以较好地刻画风速、波高、波浪周期、风向和波向五维随机变量之间的联合概率分布。
4)采用Vine Copula 函数建立了东海连云港海洋观测站风浪要素之间的联合概率分布模型,对于中国其他海域海洋观测站风浪要素之间的联合分布规律还有待进一步研究。但该研究方法和思路可为中国其他海域海洋观测站风浪要素之间的联合分布研究提供借鉴。
致谢:感谢中国国家科技资源共享服务平台——国家海洋科学数据中心(http://mds.nmdis.org.cn/)提供数据支撑。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
海洋工程(2021年5期)2021-10-27
海洋通报(2021年3期)2021-08-14
中国港湾建设(2021年2期)2021-02-27
装备制造技术(2020年3期)2020-12-25
小雪花·小学生快乐作文(2020年3期)2020-10-13
水利技术监督(2019年6期)2020-01-01
汉语世界(The World of Chinese)(2019年3期)2019-07-01
科技视界(2016年19期)2017-05-18
中国工程咨询(2017年3期)2017-01-31
