
面向知识图谱问答的查询图选择模型研究
2023-09-06 04:29贾永辉陈文亮
小型微型计算机系统 2023年9期
贾永辉,陈文亮
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
1 引 言
知识图谱问答是问答领域的重要研究方向之一,它以自然语言问句作为输入,从知识图谱中获取相关实体、关系或者属性值作为答案输出.知识图谱问答的一种代表性方法是基于语义解析的方法,它将问句转换为结构化的语义表示并进一步转成查询语言(如SPARQL[1])从知识图谱中获取答案.在转换为结构化语义表示时,一种典型方法是采用通用语义表示形式,比如λ-DCS[2].由于这种语义表示与底层知识图谱无关,因此在与底层知识图谱映射时经常会遇到本体匹配出错的情况[3].
为了克服上述语义表示形式存在的问题,另一种基于语义解析的解决方案是使用查询图来表示问句的语义[4].查询图是一种与底层知识图谱相关的语义表示形式,它的节点和边分别对应于知识图谱的实体和关系,并额外增加一些自定义的逻辑符号(如比较运算符等).基于查询图的知识图谱问答系统可以被分为两个主要模块:查询图生成和查询图选择[5].其中,查询图生成将输入问句进行解析得到一个候选查询图集合,而查询图选择是从候选查询图集合中选出最优查询图,并返回对应答案作为系统结果输出.可以看出,知识图谱问答系统的性能与查询图选择密切相关,因此本文也主要聚焦于查询图选择.
查询图选择本质上是一个问句和候选查询图匹配的任务.已有的系统在匹配中通常采用多特征打分的方式对查询图进行排序[6].在这些方法中,首先计算查询图和问句之间的语义相似度,比如使用余弦相似度计算.然后将得到的语义相似度得分和其他人工设计的特征组合在一起作为匹配特征,如问句和实体之间的相似度、查询图中节点个数等.最终,这些特征表示通过模型进行打分.这种策略在知识图谱问答中取得了很好的结果.但是,通过对相关实验结果的分析发现这种策略存在两个主要问题:1)使用余弦相似度等方法计算问句和查询图的语义相似度时,由于结构差异在一定程度上丢失了两者之间的交互信息;2)在排序中仅考虑单一候选查询图,而忽略了不同候选查询图之间的关联.
为了解决上述问题,本文提出将问句和查询图的匹配问题转换为问句和查询图序列之间的匹配问题.这种方式一方面降低了查询图编码的复杂性,另一方面更易于建模问句和查询图之间的交互信息.具体地,首先将查询图线性化为对应的查询图序列,这使得问句和查询图都是序列形式,并且可以使用成熟的序列建模方法,比如BERT[7]和GPT-3[8]等.此外,考虑到同一个问题对应的不同候选查询图之间的关联性,本文提出一种基于全局信息的查询图排序模型.在不引入额外人工特征的情况下,本文提出查询图选择的新方法,其综合考虑问句和查询图之间的交互信息以及候选查询图之间的联系.在两个数据集上的实验结果证明了所提方法的有效性.
本文的主要贡献包括:
1)提出一种基于序列匹配的问句与查询图相似度计算方法.在该方法中,查询图被线性化为对应的序列形式,并基于BERT建模问句和查询图之间的交互信息.此外,由于查询图序列已包含了查询图中的所有信息,因此不需要设计额外人工特征对查询图进行编码.
2)提出一种基于全局信息的查询图排序模型,通过得分的全局归一化引入不同候选查询图之间的关联.
3)基于上述改进,提出一个基于全局排序的查询图选择方法.实验结果表明,本文所提方法在WebQuestions(WebQ)和ComplexQuestions(CompQ)两个数据集上的F1值分别达到了55.3和44.4.
2 相关工作
知识图谱问答是自然语言处理领域重要研究方向之一,受到学术界和工业界的广泛关注.在开放领域,一些典型的知识图谱问答系统已经被应用于日常的搜索引擎中;在细分领域,也有许多相关的知识图谱问答系统研究,比如针对电子商务领域的在线商品问答系统[9]以及针对医疗领域的原发性肝癌知识问答系统等[10].在知识图谱问答实现方法中,基于信息检索和基于语义解析是两种主流的实现方式,并衍生出许多有效的方法.
基于信息检索的方法通常以实体链接[11]结果为出发点搜索相关的候选答案,并通过对答案排序选择出最终结果.在对候选答案进行排序时,一个核心点是如何正确识别出从实体到答案之间的关系路径[12].在进行问句和关系路径匹配时,基于神经网络的方法取得了一定的成功[13].比如Bhutani等将候选关系表征为向量,并基于长短期记忆网络计算问句和候选关系之间的相似度[14].此外,基于预训练语言模型的方法也被广泛应用于关系匹配中,有效提升了关系学习任务的性能[15].相比于基于问句和关系进行匹配的方案,基于知识图谱向量表示的方法可以在不显示编码路径的情况下进行答案选择,在知识图谱不完整情况下也具备良好性能[16].
不同于基于信息检索的方法,语义解析方法侧重于问句语义的理解[17].基于语义解析方法的基本思路是将问句解析为结构化的语义表示,然后将其与知识库映射并检索得到结果.比如,Berant等将问句解析为λ-DCS,并通过对齐和桥接操作实现到知识库的映射[18].为了提高复杂问题的语义解析准确率,Sun等设计了一种新颖的骨架语法先将复杂问题转换为多个简单问题进行解析[19].此外,查询图也是一种结构化语义表示形式,在基于语义解析的知识图谱问答中被广泛使用.Yih等首先提出分步骤查询图生成的方法进行语义解析[20].沿着这种思路,Luo等提出从全局角度编码单个查询图,在问句和查询图匹配上证明了查询图结构化信息的有效性[6].在查询图生成模块,Lan等提出基于束搜索的方法进行查询图的构建,使查询图方法更适合多跳复杂问题的处理[21].与已有基于查询图的方法相比,本文侧重于查询图选择阶段的改进,进一步提升了基于查询图系统的性能.
3 方 法
本节主要介绍所提基于查询图的知识图谱问答实现方法.在实现中,系统被分为两个模块:查询图生成和查询图选择.整个处理过程可以形式化描述为:给定一个问句q和一个知识图谱(KB),查询图生成模块将问句q解析为候选查询图集合G;然后查询图选择模块从候选查询图集合G中选出最优查询图g*.最终,查询图g*被转换为SPARQL语句从知识图谱中检索出与问句q对应的答案.
与已有基于查询图的方法相比,本文提出新的查询图选择方法,其不仅简化匹配过程,而且提高系统性能.图1展示所提查询图选择方法,它将查询图线性化为对应的查询图序列,从而将问句和查询图之间的匹配问题转为两个序列之间的匹配问题.在此基础上,本文分别计算问句和每个候选查询图序列的相似度得分,然后利用所有候选查询图序列的之间关联进行全局排序.这种方式可建立候选查询图之间的关联,进而更合理地优化正例查询图和负例查询图对应的得分.
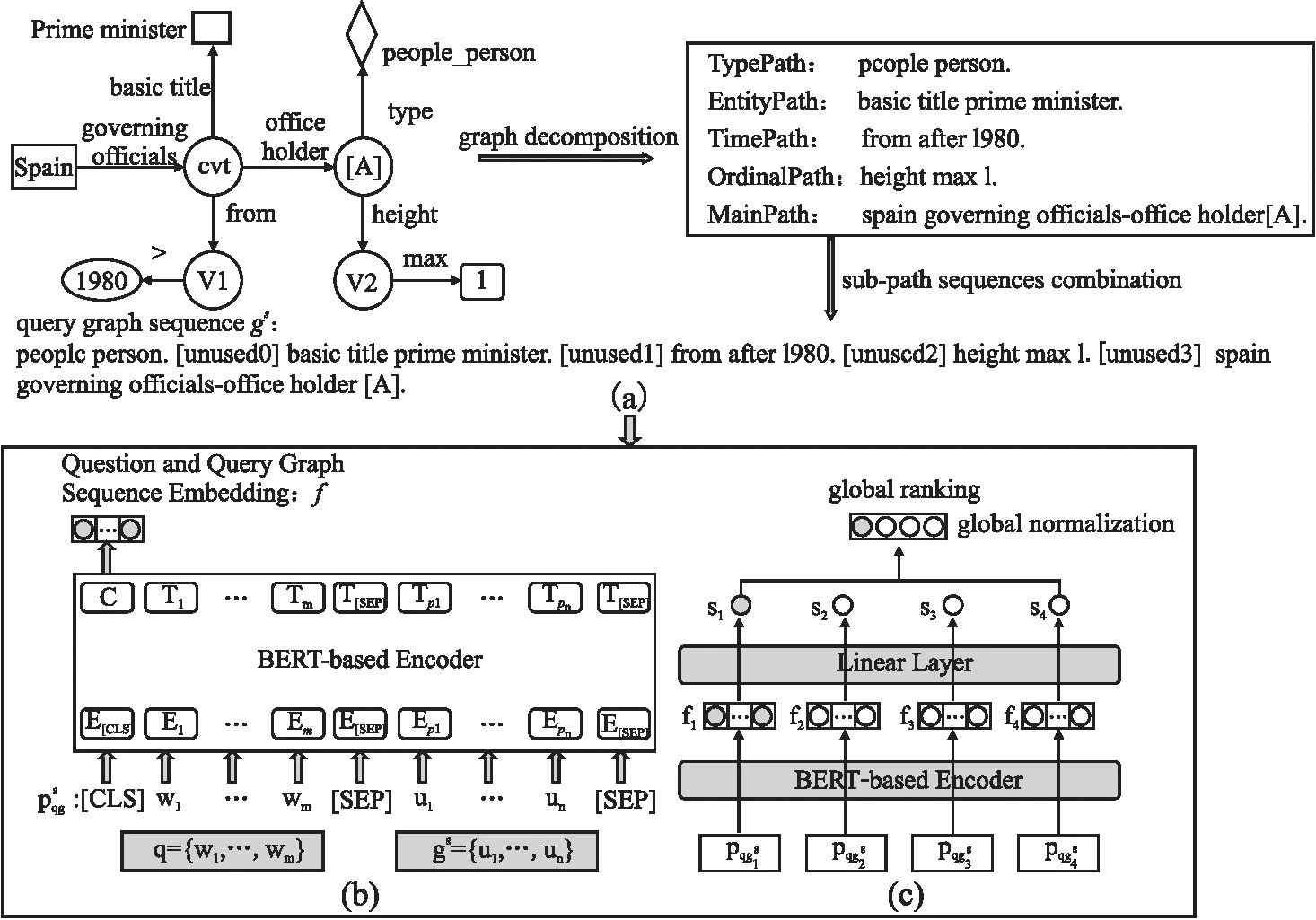
图1 查询图选择系统框架Fig.1 Framework of query graph selection
3.1 查询图生成
查询图生成模块是将非结构化的问句解析为结构化的查询图形式.本文采用分步骤查询图生成方法进行问句解析,下面介绍主要流程.
给定一个问句q,首先通过目标节点链接获取问句中的4种约束,分别对应于实体、类型词、时间词和序数词.对于实体链接,本文通过SMART工具获取<提及词,实体>对,详细情况可阅读参考文献[22].对于类型词链接,通过使用glove词向量[23]计算问句中连续子序列(至多3个词)和知识图谱中所有类型词之间的余弦相似度,并选择得分排在前10的类型词构成<提及词,类型词>对.对于时间词链接,通过使用正则匹配的方法来抽取时间信息.对于序列词链接,通过使用预定义的序数词词典(如largest,highest等)和“序数词+最高级”的模式抽取整型数字.图2(a)展示了一个完成目标节点链接后的实例.
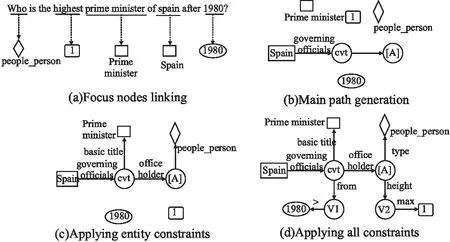
图2 查询图生成过程Fig.2 Process of query graph generation
在得到目标节点链接结果后,首先根据链接到的实体进行一跳和两跳搜索获取主路径,如图2(b)所示.紧接着,将实体约束加到主路径上,图2(c)展示了对应的状态.然后,类型词约束、时间词约束和序数词约束被依次加入到主路径上并完成解析过程,最终一个完整的查询图如图2(d)所示.
通过上述过程,可以获得每个问句对应的候选查询图集合G,该候选查询图集合被用于进行查询图选择.关于查询图生成过程更详细的描述可以阅读参考文献[6].
3.2 查询图选择
由于链接到的实体和对应的关系没有被充分消歧,查询图生成模块会产生超过一个,通常几百甚至上千的候选查询图.因此有必要设计有效的查询图选择方法从候选查询图集合中选出最优查询图g*.在本文的方法中,首先将查询图g∈G转换为查询图序列gs;然后对问句和查询图序列进行交互编码;最后基于全局信息进行候选查询图排序.
3.2.1 查询图转序列
查询图转序列旨在将查询图g转换为查询图序列gs,用于编码和排序.为了尽可能完整地保留查询图的结构化信息,本文根据查询图的结构进行序列转换,整个过程可以被理解为查询图构建的拆解过程.当构建查询图时,首先进行搜索主路径操作,然后在主路径上分别增加类型词、实体、时间词和序数词4种约束.可以看出,一个查询图至多包含5种组成成分,即主路径和4种约束路径,并且每一部分都有相对固定的语义结构.
依据查询图的固定结构,本文选择根据预定义的子路径顺序将查询图转换为对应查询图序列.这种方式不仅能够将查询图中的所有信息都转为序列形式,而且得到的查询图序列具有一定的规律性,更有利于模型编码.在转换过程中,首先根据不同的组成成分将查询图分为不同的子路径,分别为:类型词路径、实体词路径、时间词路径、序数词路径和主路径.比如,图1(a)中实体约束“Prime minister”对应的实体词路径是“basic title prime minister.”.然后,5种子路径序列被组合成对应的查询图序列,其中不同子路径之间通过额外的标识字符[unused0-3]进行分隔.如图1(a)所示,得到的查询图序列为“people person.[unused0] basic title prime minister.[unused1] from after 1980.[unused2] height max 1.[unused3] spain governing officials-office holder [A]”,其中“[A]”是答案字符串.
3.2.2 问句和查询图编码
在查询图g被转换成查询图序列gs后,问句q和查询图g的匹配问题就转换为问句q和查询图序列gs之间的匹配问题.这一转换使得序列编码模型可以更好地编码查询图,并且更自然地建模两个序列之间的交互信息,得到更好的编码特征.在前人的工作中[5],研究者通过设计人工特征来丰富问句和查询图的编码信息,而本文方法可以避免构建人工特征.
为了编码问句和查询图序列,本文选择采用BERT模型作为编码器,用来同时对问句和查询图序列进行编码,并得到对应的特征表示.BERT是一种基于Transformer[24]架构的预训练语言模型,在自然语言处理领域被广泛使用.在已有的序列编码模型中,BERT预训练语言模型在许多任务上都具备良好的表现,同时它还支持面向句子对进行编码.这种基于句子对的编码方式可以自然地建模两个句子之间的交互信息,这尤其适用于本文设计的问句和查询图序列两者之间的匹配任务.在基于BERT实现问句和查询图序列的编码过程中,本文采用句子对形式作为BERT模型的输入,整个编码框架如图1(b)所示.给定问句q={w1,w2,…,wm}和查询图序列gs={u1,u2,…,un},其中wi和ui分别对应问句和查询图序列中的一个字单元,将其按照BERT模型的输入格式进行拼接并形成对应的句子对序列pqgs={[CLS],w1,…,wm,[SEP],u1,…,un,[SEP]}.对于候选查询图集合中的每个查询图g∈G都采用上述方式和对应的问题q形成句子对pqgs,并输入给BERT进行编码.最终使用[CLS]节点的输出向量作为问句和查询图序列的交互语义特征表示,记为f,该语义特征表示在排序模型中被用于计算问句和查询图序列的语义相似度得分.
3.2.3 查询图排序模型
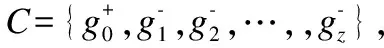

(1)
(2)
其中yi为查询图的标签,正例查询图标签为1,负例查询图标签为0.
4 实 验
4.1 实验设置
4.1.1 数据集
本文在WebQuestions(WebQ)[18]和ComplexQuestions(CompQ)[5]两个广泛使用的知识图谱问答数据集上进行实验.数据集WebQ包含有简单问题和复杂推理问题两种类型的问题,共有5,810个问答对,其中简单问题占比84%,复杂问题占比16%,整个数据类型分布符合用户真实查询场景下的分布情况.数据集CompQ是为复杂推理问答而设计,包含有2,100条复杂问答对.两个数据集都以Freebase[25]作为知识库,在实验中两者均被划分为训练集、验证集和测试集,具体划分情况如表1所示.

表1 数据集划分统计Table 1 Partitions of datasets
4.1.2 参数设置
在问句和查询图序列编码中,本文采用BERT-Base模型作为编码器.在实验过程中,通过比较系统在验证集上的性能进行系统参数设置.对于BERT模型中的参数,设置丢弃率为0.1,隐藏层大小为768.在模型训练中,使用Adam作为优化器,并且设置学习率为5×10-5,最大训练轮次为5次.在每轮训练结束后,在验证集上评价模型的性能,并选择验证集上表现最好的模型作为最终模型在测试集上进行测试.在构建训练数据时,按照1:120的正负比例进行数据组的构建,其中负例从查询图生成得到的候选查询图集合中随机选取.对于评价机制,沿用以往研究中使用的F1值进行模型评价[18].
4.2 实验结果
表2展示本文方法和已有方法在WebQ和CompQ两个数据集上的比较结果.按照是否基于查询图,已有的方法被分为两类,其中“基于查询图”表示使用查询图的系统方法,而“其他方法”表示没有使用查询图的系统方法.在“其他方法”中,Berant等基于λ-DCS实现问句解析,并根据解析结果从知识库中检索出最终答案.Chen等和Xu等基于机器阅读理解的方法实现知识图谱问答,能够以知识图谱作为背景知识检索到对应的答案.而Jain在WebQ上实现了最好的结果,但其在答案选择中额外引入问句复述数据集WikiAnswers来增强问句的表示.

表2 和现有方法的比较结果Table 2 Comparison results with previous methods
在基于查询图的方法中,Bao等、Yih等和Luo等采用相似的分阶段查询图生成方法,即先生成主路径,后进行约束挂载.其中,Luo等结合查询图整体结构提出一种针对复杂查询图的编码策略,从而将查询图编码为对应的语义向量,更有效地实现问句和查询图的语义匹配,也取得了更好的性能.不同于已有的分阶段查询图生成方法,Hu等基于状态转移的策略将问句解析为语义查询图,然后将语义查询图与底层知识图谱进行映射并检索答案.为了降低查询图生成中的搜索空间,Lan等基于束搜索生成主路径,同时考虑约束的挂载,这种方式有效减少了搜索空间,实现了更有效的查询图生成过程,并在CompQ上取得了最好的效果.
从表2中可以看出,相比于已有方法,本文方法在CompQ上实现了最好的结果,并且在WebQ上也排在第2位.同时,与WebQ数据集上最好的Jain方法相比,本文方法在没有引入额外资源WikiAnswers的基础上就实现了与其相当的性能.这显示出本文所提知识图谱问答系统的优越性.此外,当和基于查询图的系统进行比较时,文中实现的系统显著超过了所有基于查询图的方法,这说明本文提出的查询图选择模型是十分有效的.从以上比较可以看出,本文提出的基于全局排序的查询图选择方法是可行的,它可以有效提升基于查询图的知识图谱问答系统性能,并且与其他方法相比,也具有一定的优势.
4.3 讨论和分析
4.3.1 查询图转序列分析
为了探究查询图转序列对系统的影响,本文从两个角度对生成的查询图序列进行分析,其中一方面探究查询图转序列中预定义子路径的有效性,另一方面对查询图序列中的不同组成成分进行消融分析.
在查询图转序列方法中,本文采用预定义子路径顺序的策略生成对应的查询图序列,这种设计初衷是想保留更多结构化的有序信息让模型更易于编码.作为对比,本文进一步采用随机策略的方式将不同子路径组合成查询图序列,表3给出了两种实现方法的比较结果.从表中可以看出,相比于子路径顺序固定的方法,子路径顺序随机化的方式都有一定程度的性能下降,并且在WebQ和CompQ数据集上分别降低了0.7%和0.9%.这种现象表明,本文设计的子路径顺序固定的查询图序列生成方式更加合理.相比于子路径顺序随机的方式,基于子路径顺序固定的方法可以保留更多结构化的信息,使得转换得到的查询图序列具备一定的规律性,而这种规律性也更有利于问句和查询图序列的匹配,取得更好的系统性能.

表3 子路径顺序对系统的影响
在查询图转序列中,本文生成的查询图序列包含了查询图中的所有信息.为了分析查询图序列中不同组分对系统的影响,这里进一步从当前系统中移出相关组成部分进行实验,实验结果如表4所示.其中,“查询图序列”指包含主路径和4种约束路径的完整查询图序列构成的系统,“w/o 约束路径”指在查询图序列中去除约束路径信息的系统,“w/o 答案字符串”指在查询图序列中去除答案字符串的系统.实验结果表明,无论是去除约束路径还是答案字符串,系统的性能都会下降.同时就“w/o 约束路径”对应的结果而言,可以看出系统在WebQ和CompQ数据集上分别下降了1.6%和2.1%,并且在CompQ数据集上下降得更多.这种性能下降的差异与CompQ数据集中包含更多的复杂约束问句相一致,说明复杂问句越多,约束路径越重要.从上述实验分析可以看出,查询图序列中包含的所有组成部分都是必不可少的,都可以在查询图选择中发挥正向作用.
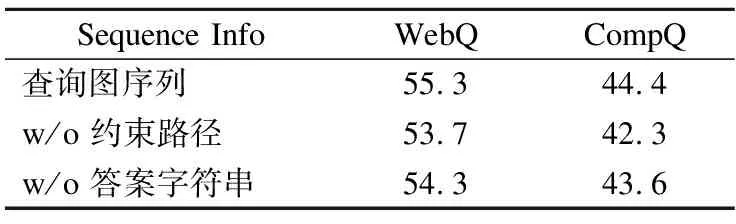
表4 查询图序列中不同组成部分对系统的影响Table 4 Effect of different components in query graph sequence on the system
4.3.2 全局排序的有效性
在本小节中,具体分析全局排序模型在查询图选择中的有效性.作为对比系统,本文选择两种典型的排序模型进行比较:Luo实现的二元排序模型[6]和基于二分类的单元排序模型,其中二元排序方法采用铰链损失函数.
表5展示了3种不同的排序策略在WebQ和CompQ数据集上的比较结果.其中单元排序对每个候选查询图进行二分类,在优化中不考虑候选查询图之间的关联;二元排序在优化中考虑两两候选查询图之间的关联;而本文的全局排序引入了所有候选查询图之间的关联进行优化.表中结果显示,引入候选查询图之间关联的全局排序和二元排序明显优于单元排序模型.这种现象表明在排序中引入候选查询图之间的关联是有效的,这种关联信息有利于查询图选择模型区分正确查询图和错误查询图之间的区别,从而更好地进行优化.此外,相比于单元排序,二元排序和全局排序在CompQ数据集上比在WebQ数据集上取得了更大的提升,这在一定程度上反映出复杂问题可能更需要额外信息来区别候选查询图.从表5中也可以看出,本文提出的全局排序模型在两个数据集上都取得了最好的性能,这说明基于全局信息的排序模型在查询图选择中更加有效,因此有必要在查询图选择模型中引入候选查询图之间的关联.
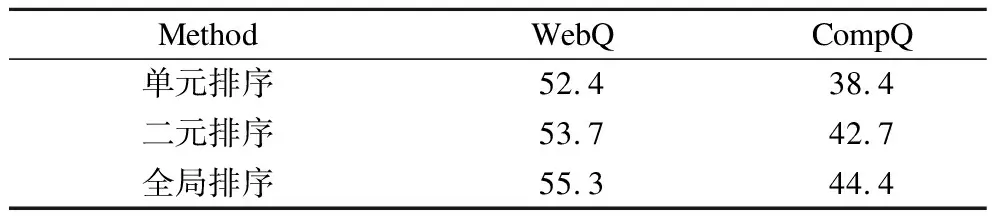
表5 全局排序与其他排序方法的比较实验Table 5 Comparison results of different ranking methods
4.3.3 错误分析
为了更好地帮助改进查询图选择模型,本小节具体分析当前系统在查询图选择模块中出错的原因.当查询图生成模块产生的候选查询图不包含正确答案时,本文所介绍的系统无法选择出正确的查询图并回答问题.因此这里针对正确答案在查询图候选中,但最终回答出错的问题进行分析.针对WebQ数据集,本文随机选取了100条问句进行统计分析,错误情况总结如下:
错误的查询图生成.在查询图能够检索到正确的答案的情况下,本文进一步发现尽管有些查询图能够检索得到正确的答案,但是实际上解析得到的查询图并不能保证是正确的.比如,对于问题“where was david berkowitz arrested?”,查询图生成的候选中包含“david berkowitz places lived-location brooklyn,new york city”.这一候选可以检索到对应的答案“brooklyn,new York city”,但事实上该候选查询图序列在语义上与问句并不完全匹配,因此模型很难选出这样的查询图.在100条问句中,这种错误类型包含45条(45%).对于这种错误,需要进一步提高查询图生成的性能以及增加知识图谱本体的覆盖率,从而减少这种情况的发生.
错误的查询图选择.这种情况下候选查询图中包含有解析正确的查询图,但系统仍然回答错误.这些错误可以总结为两大类.第1类(40%)是系统选择了错误的主路径关系所对应的查询图,导致回答错误;第2类(15%)是系统选择了错误的约束,即约束子路径匹配出错.为了解决这类错误,可能需要在查询图选择中引入更多信息来更好地区分正确查询图和错误查询图之间的区别.
5 结束语
本文提出一种新的面向知识图谱问答的查询图选择方法,将问句和查询图的匹配转换为两个序列之间的匹配任务,并设计一种基于全局信息的查询图排序模型,来提升知识图谱问答系统的性能.在具体实现中,首先通过线性化将查询图转换为查询图序列,然后使用BERT编码问句和查询图序列之间的语义表示.此外,通过全局排序来选择最优查询图,排序模型可以对候选查询图之间的关联进行建模.在WebQ和CompQ两个数据集上的实验表明,本文所提的查询图选择方法能够提高知识图谱问答系统的效果,从而证明了所提方案的有效性.在将来工作中,会进一步考虑引入与查询图相关的额外附加信息来提高查询图语义表达能力,同时进一步优化查询图排序模型.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
少先队活动(2020年12期)2021-01-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
科普童话·学霸日记(2020年1期)2020-05-08
数学物理学报(2019年6期)2020-01-13
小天使·一年级语数英综合(2019年2期)2019-01-10
数学物理学报(2017年5期)2017-11-23
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
新课程学习·中(2013年3期)2013-06-14
