
基于半监督深度学习的雷达收发组件故障诊断
2023-10-11 12:59陈毓坤陆宁云
系统工程与电子技术 2023年10期
陈毓坤, 于 晖, 陆宁云,*
(1. 南京航空航天大学自动化学院, 江苏 南京 211106; 2. 中国电子科技集团公司第三十八研究所, 安徽 合肥 230088)
0 引 言
军事用途的相控阵雷达一般置于偏远边疆,要求全天候工作,在连续大负荷工作模式和恶劣环境下,元器件故障不可避免会发生,维修计划之外的突发性故障轻则影响雷达探测性能和数据有效性,重则引起任务中断,设备使用效能下降而维护成本剧增。T/R组件是相控阵雷达中故障频次最高的部件之一[1],由于其故障成因繁多,难以建立准确的故障模型和专家知识库。雷达系统的数字化,以及信号处理技术和机器学习的发展,为基于数据的雷达故障诊断方法研究提供了良好的条件。
深度学习模型作为智能模型的典型代表,被广泛应用到复杂系统的故障诊断中[2-4]。按训练数据有无标签,深度学习算法可分为有监督学习[5]、无监督学习[6]和半监督学习[7]3种。有监督学习需要大量带标签数据训练模型以得到特征与故障标签间的映射关系。小波变换[8]、傅里叶变换[9]、经验模态分解[10]等信号处理技术常被用于对数据进行特征提取,筛选与故障状态强相关的特征输入深度学习模型以进行训练。文献[11]引入小波包能量熵和多尺度位移熵计算不同故障下变速箱振动信号的特征矩阵,然后基于阈值自适应深度置信网络(deep belief network, DBN)提取故障特征,对提取的特征进行故障分类。文献[12]直接将轴承振动数据输入DBN,利用堆叠受限玻尔兹曼机(restricted Boltzmann machine, RBM)学习特征表示并实现故障识别,避免了手动特征提取和选择。但在实际应用中,大部分样本没有标签,监督学习不再适用。
无监督学习不需要先验信息,根据数据的分布规律进行聚类。传统的无监督学习算法有主成分分析(principal components analysis, PCA)[13]、聚类算法[14]等。现阶段主要有两类深度学习模型被用于无监督特征提取,一类是利用自编码器(auto-encoder, AE),从抽象后的数据中尽可能无损地重现原始数据[15];一类是基于概率型的RBM及其改进算法,使其达到稳定状态时原数据出现的概率最大[16-17]。由于缺少标记数据的指导,难以保证模型准确性。
半监督学习是将监督学习和无监督学习相结合的一种方法,利用大量无标签样本自主学习特征分布,辅以少量带标签样本实现模式识别。近年来,基于半监督深度学习的故障诊断方法得到广泛关注与研究。文献[18]针对电力系统中隐匿虚假数据入侵攻击的真实数据与模拟数据的差异性问题,首先基于DBN对海量目标域无标签样本进行特征自学习,然后用仿真得到的源域有标签样本对模型进行再训练,并结合迁移学习方法提高检测精度。文献[19]设计了一种基于深度卷积AE的半监督模型,根据AE的编码特征直接诊断健康状况,降低了故障诊断对标记数据的依赖。文献[20]先用大量带标签的燃气轮机正态分布数据训练卷积神经网络,再通过迁移学习重建模型映射规则,对少量样本数据集提取特征,最后基于支持向量机(support vector machines, SVM)实现监督故障诊断。文献[21]整合RBM、长短期记忆网络、前馈神经网络等多层深度神经网络,从输入数据中自动学习抽象特征,用于预测涡轮风扇发动机的剩余使用寿命。文献[22]在自我训练方法中使用伪标签策略,在对抗训练方法中使用监测数据,进行半监督学习。
半监督学习突破了传统方法只使用一种样本的局限,既充分利用了大量无标签样本数据资源,又避免了人工标记耗费的大量时间和精力,以及只使用少量有标签样本训练造成的学习器泛化性能低下的问题。鉴于雷达装备的实际监测数据大部分是无标签的,无具体故障类型,很难被直接应用于深度学习模型,本文提出一种自适应优化的半监督深度学习方法,用于雷达T/R组件故障特征提取及智能诊断,主要创新点在于:① 利用DBN自主学习深层特征的优势和深度AE无监督重构输入数据的特点,直接从原始数据提取故障特征,增强了故障诊断智能性,解决了有标签样本稀缺的问题;② 针对基于深度学习模型进行故障识别时难以快速确定各隐层节点数量的问题,采用烟花算法(firework algorithm, FWA)优化网络结构参数,进而提升故障诊断准确性。
1 雷达T/R组件原理与故障模式
相控阵雷达具有扫描速度快、探测距离远、可靠性高等优点[23],应用前景广阔。天线阵面子系统是相控阵雷达最重要的子系统之一,也是其具备先进性能的关键所在,系统结构如图1所示。

图1 相控阵雷达天线阵面子系统结构图Fig.1 Structure diagram of phased array radar antenna array subsystem
该系统由成百上千个单元或子阵组成,并通过T/R组件实现发射信号的功率放大、接收信号的低噪声放大、天线波束的相移及幅度控制[24]。T/R组件是相控阵雷达的核心部件,构成模拟收发通道,发射通道包含功率放大器、上变频器,用于放大射频信号功率;限幅器、低噪声放大器和下变频器是构成接收通道的主要器件,实现含噪接收信号的放大和变频[25],图2给出了T/R组件的结构框图。
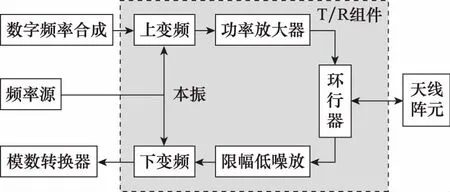
图2 T/R组件结构图Fig.2 Structure diagram of T/R module
现代相控阵雷达的T/R组件是高度集成的,将多个T/R组件和数字收发通道集成设计,形成一个最小可维修单元,称为T/R模块。通常是对一个模块,而不是单个T/R组件进行换件维修,因此只需将故障隔离到某个T/R模块。雷达机内测试能够通过逻辑值对模块故障进行报警,1代表正常,0代表故障,但不能指示详细的故障原因,难以给设备排故提供充分的依据,致使维修维护工作效率低下,有时误更换正常的元器件,造成资源浪费。为了明确具体的故障类型,还需要分析运行中采集的状态数据,挖掘蕴含的故障信息。
依据雷达从实际运行维修中返回的数据以及专家知识,T/R模块的常见故障模式有电源欠压、电源过压、发射通道故障、接收通道故障、发射和接收通道故障,故障表现如表1所示。

表1 雷达T/R模块故障模式Table 1 Fault modes of radar T/R module
2 T/R模块特征提取与故障诊断方法
鉴于雷达系统中的有标签数据十分稀缺,本文提出一种基于FWA优化的DBN-AE半监督深度学习方法,将无监督特征提取和有监督分类器学习进行结合。该方法的主要流程如图3所示,实现步骤如下。

图3 本文提出的特征提取及故障诊断算法流程Fig.3 Flowchart of feature extraction and fault diagnosis of the algorithm proposed in this paper
步骤 1对T/R模块的故障模式进行定义和编码。
步骤 2数据集构建:选取样本数据和能表征模块性能的状态变量,进行数据预处理,并划分训练集和测试集。
步骤 3模型初始化:建立一个多层RBM模型,根据样本特征维数确定输入层节点数,初始化连接权重。
步骤 4无监督特征提取:采用预处理后的无标签样本和有标签样本对底层堆叠RBM进行逐层预训练,使得模型参数适应所有样本的特征表达,挖掘深层特征。然后,将预训练好的RBM逐层展开,构建深度AE重构输入特征。
步骤 5网络结构优化:通过FWA最小化重构特征和原始特征之间的误差,自适应优化网络参数,保存确定的网络权重和偏置值,作为下一步DBN有监督训练的初始参数。
步骤 6有监督分类器学习:利用有标签训练集对预训练好的RBM模型和Softmax分类层进行有监督再训练,并反向微调权重和偏置。
步骤 7将测试集输入训练好的DBN,进行故障诊断。
2.1 RBM无监督预训练
2006年,Hinton等首次提出了DBN[26],DBN是由多个RBM[27]堆叠而成的概率生成模型。RBM模型的基本结构如图4所示。

图4 RBM结构Fig.4 RBM structure
对于一个包含n个可视层单元、m个隐藏层单元的RBM,其能量函数为
(1)
式中:vi∈{0,1}表示第i个可视层神经元的状态;bi为可视层单元vi的偏置;hj∈{0,1}表示第j个隐藏层神经元的状态;aj为隐藏层单元hj的偏置;wij为vi与hj的连接权重;θ=[a,b,w]为RBM的网络参数。基于式(1)定义的能量函数,可视层与隐藏层之间的联合概率密度分布为
(2)
式中:Z=∑v∑he-E(v,h|θ)为归一化因子。通过式(2),得到可视层向量v的独立分布为
(3)
隐藏层和可视层神经元的激活概率分别为
(4)
(5)
P(v)值最大时,RBM结构下的概率分布与输入数据较为一致,因此预训练优化目标函数为
(6)
为简化计算,利用对比散度算法[28]求解RBM的最优参数θ,参数更新公式如下:
(7)
式中:ε为预训练学习率;m为动量因子;t是迭代次数;〈·〉d和〈·〉r分别表示数据分布和模型分布的数学期望。
2.2 基于DBN-AE的无监督特征重构
DBN特征提取的质量在很大程度上决定其故障诊断的性能,因此在将DBN模型用于分类之前,有必要验证RBM提取的高层特征能否表征原始特征。本节将从RBM隐含层单元对数据重构的角度验证所提模型的特征提取能力。
为观察原始数据经RBMs无监督学习后的输出特征状态,最高层RBM的输出不经过分类器,直接将隐含层重构数据逐层展开,建立一个深度自编码器,称为DBN-AE。基于DBN的重构网络结构示意图如图5所示。其与传统DBN最主要的区别是:DBN输出的是标签,属于有监督学习;DBN-AE是无监督学习,编码和解码过程没有带标签数据参与,输出的是与输入特征维度一致的重构特征。
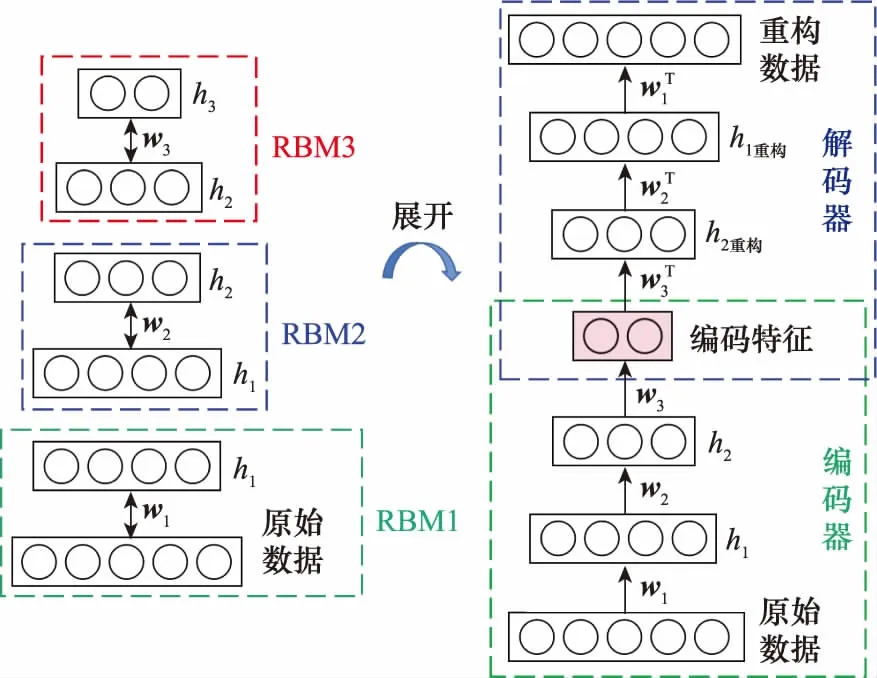
图5 DBN-AE结构示意图Fig.5 Structure diagram of DBN-AE
RBMs的前向学习过程可以看作是AE的编码过程,设输入数据为x,可以用编码形式简单描述为
h=1/(1+exp(-wx-b))
(8)
而RBM隐层单元的重构相当于AE的解码过程[29],对应的解码函数定义为
(9)
式中:w为连接权重;b和c为对应的偏置参数。
在网络的编码、解码重构中,信号被压缩、重整,重构信号与原始信号会存在一定的差异,两者的差异大小可用于衡量DBN-AE的特征提取能力。本文用均方误差(mean square error, MSE)量化这一差异。设经过l层堆叠RBM的编码输出为ul(x),解码输出,即对初始样本的重构为yl(x)。基于重构数据与原数据之间MSE的代价函数表示为
(10)
式中:n为样本的数目。这一误差越小,重构信号与原始信号的一致性越高,表明模型提取的深层特征越能够在一定程度上表征原始特征。使用反向传播(back propagation, BP)[30]算法对整个网络进行调参,采用梯度下降方法最小化代价函数,对参数求偏导:
(11)
式中:θ=[w,b,c],1≤k≤l,更新参数展开得
(12)
迭代更新各层参数直至误差处于稳定收敛状态,获得特征提取模型。
基于DBN-AE的特征重构步骤如下。
步骤 1数据预处理。
步骤 2将原始数据输入第一层RBM的可视层单元v1,通过无监督贪婪学习算法自底向上逐层优化各层RBM的连接权值和偏置,直到所有的RBM都学习完成。这一过程对应AE的编码过程,最高层RBM的隐藏层为得到的编码特征。
步骤 3将RBM隐层单元的重构逐层展开,这一过程相当于AE的解码,编码部分和解码部分的权重矩阵互为转置,得到与原始特征对应的重构特征。
步骤 4基于BP算法对DBN-AE网络的权重和偏置进行微调,使可视层单元和重构可视层单元之间的差异最小,得到能够表征原始特征的编码特征,实现无监督特征自学习。
2.3 基于FWA优化DBN-AE模型参数
为了快速确定网络结构参数,本文运用FWA,通过最小化DBN-AE网络的重构数据和原始数据的误差,自适应选取网络全局最优结构参数,进一步提高其无监督特征提取性能。
FWA[31]是模拟烟花爆炸现象而提出的一种群体智能优化算法,通过爆炸进行寻优,每个烟花的位置信息等同于解空间中的一个可行解。FWA具有局部搜索和全局搜索能力自调节、可并行运算、耗时短等优点,在路径规划[32]、参数优化[33]、模式识别[34]等领域得到广泛应用。
第一次迭代时,先随机生成N个初始烟花,逐一根据其相对于其他烟花的适应度值执行爆炸操作,产生火花。对于烟花xi,其爆炸半径Ri和爆炸火花数量Si的计算公式分别为
(13)
(14)
式中:Er和En分别是爆炸半径和爆炸数目常数,可控制爆炸半径和爆炸产生的火花数量;f(xi)是适应度函数;ymin=min(f(xi))(i=1,2,…,N)是当前烟花种群中适应度最好的个体的适应度值;ymax=max(f(xi))是适应度最差的个体的适应度值;eps是近似0的常数。
接着,将烟花对应维度的数值进行位移,模拟真实烟花爆炸产生火花的过程:
(15)

为了避免陷入局部最优解,烟花算法引入变异算子产生高斯变异火花。在烟花种群中随机选择一个烟花xi,对其维度k执行高斯变异操作:
(16)
式中:g服从均值为1、方差为1的高斯分布,即g~N(1,1)。
将超出边界的火花映射到可行域内的映射规则如下:
(17)
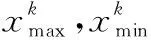
最后,从初始烟花、爆炸火花和高斯变异火花中选择一定数量的个体作为下次迭代的初始烟花。先选取适应度值最优的个体,再用轮盘赌的方式选择剩余N-1个。个体xi被选中的概率为
(18)
式中:R(xi)为个体xi与其他个体的欧式距离之和。
由式(18)可知,分布较分散的个体被选中的概率更大,有利于找到全局最优解。
2.4 基于有标签数据的有监督再训练
经过上述预训练过程,得到底层RBMs和编码特征,然而此时还不能进行直接分类。要实现故障诊断,还需在顶层添加分类层和标签,对增加的分类层进行训练。
底层RBMs的初始权重和偏置直接采用无监督训练中得到的值,最高层以softmax模型作为分类器。设DBN含l个RBM,初始样本为x,根据前向传播算法,最后一层RBM输出向量为ul(x):
(19)
第i个样本经前向l层RBM学习后,属于类别yi,yi∈(1,2,…,c)的概率为
(20)
式中:V为参数系数,选取概率最大的类别作为分类器输出。网络第l层的代价函数为
(21)
式中:λl={wl,bl,cl,Vl};1{·}为逻辑指示函数。当yi=q时,1{yi=q}的值为1,否则值为0。为使代价函数值最小,采用BP算法[29]将网络输出与真实数值标签之间的误差自顶向下BP至每一层,微调参数直至训练集准确率稳定收敛,至此半监督DBN模型的整个训练过程完成。
不同于传统DBN直接用带标签数据训练分类器,本文提出的算法在底层RBMs和AE无监督学习得到的特征的基础上,再加入标签数据进行有监督再训练,完整的过程如图6所示。
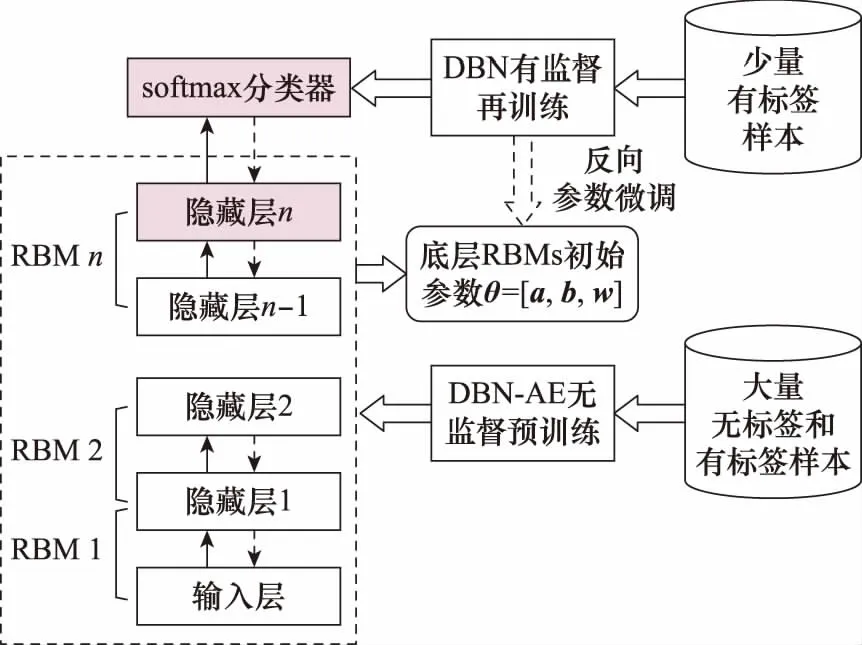
图6 DBN模型的半监督训练过程Fig.6 Semi-supervised training process of DBN model
3 实验结果与分析
3.1 数据集描述和故障编码
本文选用某型相控阵雷达在2019年3月至9月的在线监测数据,采样间隔为1 min,以其中一个8通道T/R模块为研究对象,可供采集的状态量如表2所示。
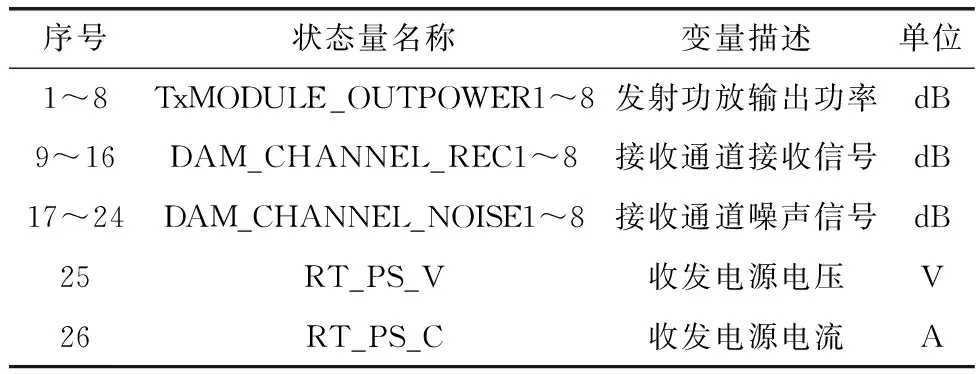
表2 雷达T/R模块监测变量Table 2 Monitored variables of radar T/R module
在无监督特征提取实验中,选取10 000组有标签和无标签样本进行预训练,其中1 800个样本有标签,包含正常状态和5类故障状态在内的6类数据各300组,故障类型如表1所示,其他为无标签样本。每个样本包含26个特征,按4∶1的比例划分训练集和测试集。
在有监督故障分类实验中,采用1 800组有标签样本训练分类器,为6种工况分别添加标签C=[1,2,3,4,5,6]。在每种工况下选取250个样本作为训练集,以50个样本作为测试集。
3.2 基于FWA-DBN-AE的特征提取结果和分析
DBN-AE的训练参数如表3所示,输入层为T/R模块的26个原始状态量,输出层为重构的26个特征,隐层数选择4。深度神经网络的分类错误率会随着深度增加而降低,但增加到4层以上时,泛化性能反而下降[29]。为兼顾算法的收敛速度与稳定性,设置学习率为0.1,初始动量为0.5,在误差平稳增加时动量变为0.9。

表3 DBN-AE训练参数Table 3 DBN-AE training parameters
采用FWA优化DBN-AE各层节点数,FWA的基本参数如表4所示,变量维数为要寻优的网络参数数量,适应度函数取模型重构特征与原始特征的MSE,如式(10)所示。寻优得到编码部分各隐层神经元最佳数量依次为11-37-26-9,解码部分隐层节点数依次为26-37-11。

表4 FWA基本参数Table 4 Parameters of FWA
为了验证FWA优化深度置信重构网络的有效性及所提方法的特征提取能力,将其与经粒子群优化(particle swarm optimization, PSO)算法优化的PSO-DBN-AE、未优化的DBN-AE和单一DAE对比,其中PSO算法的参数设置为:初始粒子数为20,加速度因子c1=0.5,c2=0.9,惯性权重μ=0.5,变量上、下界分别为50和1,迭代50次,DBN参数均与本文方法保持一致。
本实验采用训练误差、测试误差和训练时间指标衡量各模型的特征提取性能,训练误差和测试误差分别指模型在训练集和测试集上输出的重构特征与原始特征之间的MSE。为了消除算法随机性,将每个算法都重复运行10次,取10次结果的平均值,结果如图7和表5所示。
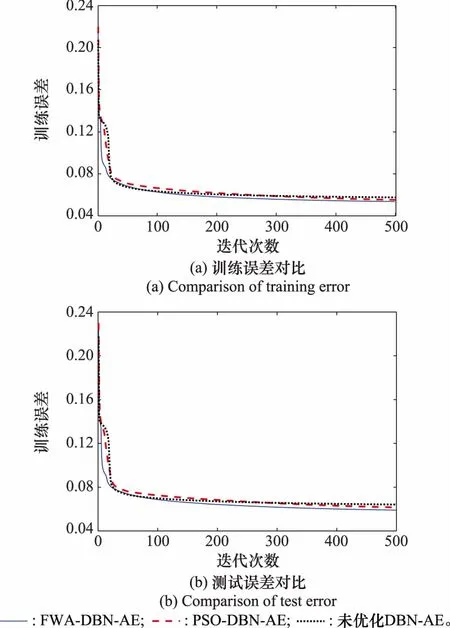
图7 不同无监督特征提取算法特征重构误差对比Fig.7 Reconstruction error comparison of different unsupervised feature extraction algorithms

表5 不同无监督算法特征提取指标对比Table 5 Comparison of feature extraction indicators of different unsupervised algorithms
由图7可以看出,随着迭代次数增加,各模型的训练误差和测试误差都在不断减小,FWA-DBN-AE的收敛速度更快,拟合效果更好。
由表5可以看出,FWA-DBN-AE算法的训练误差和测试误差最小,重构特征更接近于实际值,在训练集上的MSE值为0.053 8,在测试集上的MSE值为0.059 2。相比单一DAE、未经优化的DBN-AE和PSO-DBN-AE,测试误差分别降低了22.41%、10.57%和3.9%;且其测试误差也最接近训练误差,说明拟合效果较好,基本不存在过拟合情况。在时间复杂度上,DBN的训练时间受神经元数量影响,神经元数目越多,训练时间越长,相比未优化的DBN-AE和DAE,本文方法的训练时间增加了30~50 s,但特征提取效果大大提升。
综合均方根误差和训练时间,FWA优化的DBN-AE特征提取性能最优。因此,对于雷达T/R模块数据,FWA能够提升DBN-AE的无监督特征提取性能和训练效率。
3.3 基于半监督DBN的故障诊断结果和分析
DBN模型的隐层层数为4,输入为无编码26个特征,输出为样本分别属于6种状态的概率值,取值最大的状态作为诊断结果。底层堆叠RBM的隐层节点数、初始权重和偏置值采用第3.2节预训练中得到的最优参数。综合考虑精度和时间,将DBN反向微调的迭代次数设为300次。
为了评估模型的故障诊断能力,采用总体准确率和单一故障识别准确率作为评价指标。总体准确率是指分类正确的样本数与所有样本数的比值。单一故障识别准确率指在某类单一故障下,被正确识别的样本与该类别样本总数的比值,可以通过混淆矩阵进行可视化。在T/R模块测试集上的故障分类准确率变化曲线和混淆矩阵分别如图8和图9所示。
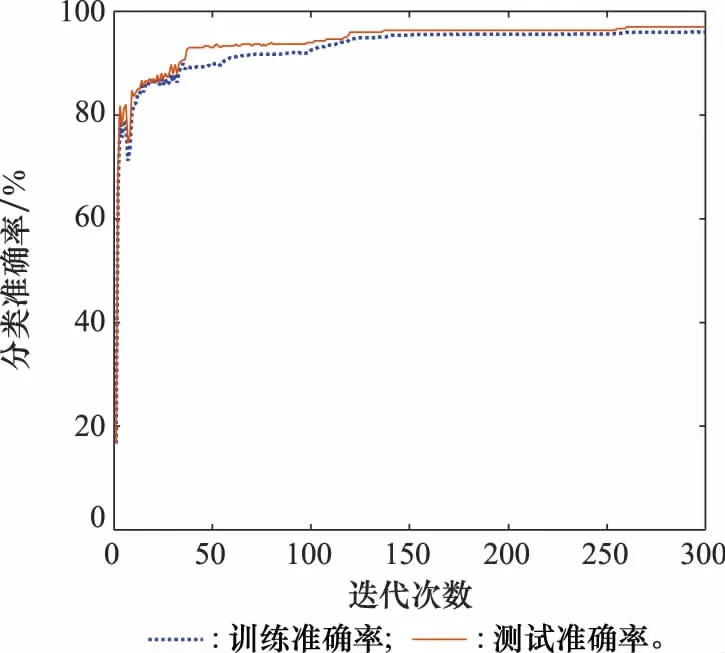
图8 半监督DBN故障分类准确率变化Fig.8 Fault classification accuracy curve of semi-supervised DBN
模型在训练集和测试集上的总体准确率分别为96.6%和96%,其中正常模式和发射通道故障的识别率为100%,电源过压、电源欠压、发射和接收通道故障的识别率达到94%以上,说明所提算法对于雷达T/R组件故障具有良好的识别能力。
第3.2节的实验从RBM隐层单元重构数据与原始数据的一致性出发验证了DBN的特征提取能力,本部分实验将从一个完整的DBN,即特征提取和有监督分类器组合的角度,验证模型在T/R模块故障诊断中的逐层特征提取能力。由于原始数据和模型每层提取的特征维数都比较高,为便于在一张图中观察,利用PCA降维方法显示各层特征的前2个主成分PC1和PC2,图10给出了原始特征的分布图。
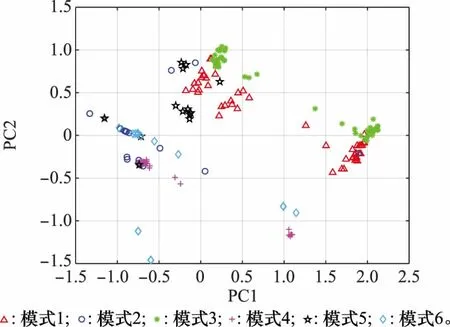
图10 原始特征二维PCA映射散点图Fig.10 Two-dimensional PCA mapping scatter plot of original features
图10中6类故障数据的特征重叠在一起,相互交叉,难以区分。采用DBN模型进行故障特征提取后的可视化结果如图11所示。
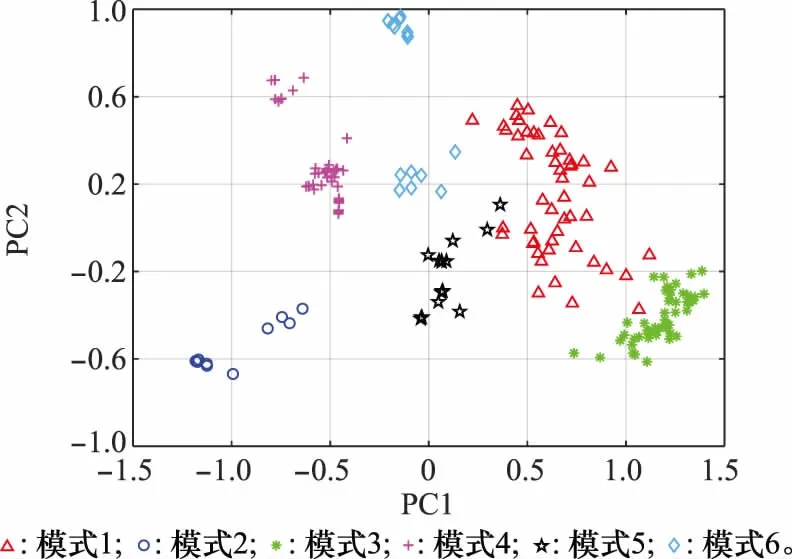
图11 DBN故障特征提取二维PCA映射散点图Fig.11 Two-dimensional PCA mapping scatter plot of DBN fault feature extraction
由图11可以看出,与原始故障特征相比,半监督DBN提取的特征具有更好的可分性,最终6类故障数据被完全分散开,有利于分类器进行识别。以上结果表明,本文方法能够自适应地从原始数据中逐层提取有效故障特征,无需人工参与,并在一定程度上提高了特征分类的准确率。
3.4 算法中无监督预训练的有效性分析
为更加充分地验证本文所提半监督算法中无监督预训练的有效性,将其与其他6种分类方法在T/R模块数据集上的故障诊断准确率进行比较,其中包括2种半监督深度学习方法:PSO-DBN-AE、DBN-AE,以及只使用有标签样本进行训练的4种有监督方法:单一DBN、DBN-ELM、SVM和朴素贝叶斯。其中,DBN训练参数与FWA-DBN-AE保持一致,PSO-DBN-AE的参数设置和第3.2节相同;SVM的核函数为径向基函数,误差精度设置为1×10-3。
每个算法重复运行10次,取10次结果的均值,各算法的故障诊断结果如表6所示。

表6 不同算法故障诊断结果对比Table 6 Fault diagnosis results of different algorithms %
通过表6的对比可知,本文所提方法的故障诊断准确率最高,在训练集和测试集上的准确率分别为96.67%和96%,与同为半监督深度学习的PSO-DBN-AE、DBN-AE方法相比,训练准确率分别提升了1.93%和2.33%,测试准确率分别提升了2%和2.67%;与单一DBN、DBN-ELM、SVM和朴素贝叶斯有监督学习方法相比,训练准确率分别提升了3.07%、2.47%、4.5%和6%,测试准确率分别提升了3.33%、2.67%、5.67%和6.67%。在模型训练效率方面,DBN的网络结构虽然比SVM、朴素贝叶斯复杂,但采用对比散度算法逐层预训练,对参数分布有较好的预估计,能避免陷入局部最优,且模型收敛速度快。从图8可以看出,算法在第180代左右已经收敛,这说明模型一旦训练完成,诊断时间很短,具有良好的工程应用前景。
相比直接将DBN用于分类,提前用大量无标签样本基于DBN-AE进行预训练,学习通用特征表达,有助于提高诊断的准确率。由于经过前期的无监督特征自学习,模型参数适应所有样本的特征表达,提高了DBN高层特征的通用性,从而改善了模型的故障诊断性能。其准确率优于传统的有监督学习算法和其他半监督深度学习算法。
4 结 论
本文针对相控阵雷达系统采集的有标签数据稀缺的问题,提出了一种基于FWA-DBN-AE模型的雷达T/R模块故障诊断方法,将无监督特征提取和有监督分类器学习相结合。首先,利用RBM自主学习相关特征的优势,对大量无标签和有标签样本进行预训练,然后通过隐层重构的方式逐层展开RBM建立DBN-AE网络,以较低的失真度重构输入数据,从而实现特征提取;接着,以提高重构信号与原始信号的一致性为目标,运用FWA优化网络结构;最后,利用少量有标签样本再训练新增的分类层,得到T/R模块故障诊断的最优模型。
实验结果表明,该半监督深度学习方法不仅能取得较高的故障识别精度,并且简化了特征提取过程,具有直接从原始数据自动提取故障特征的能力。FWA能自适应地确定网络结构,节省了大量时间和精力,并进一步提升了模型的特征提取性能和故障诊断准确率,相比单纯的有监督故障诊断方法具有更好的泛化性。
猜你喜欢
摄影世界(2022年1期)2022-01-21
知识经济·中国直销(2018年12期)2018-12-29
电子制作(2018年19期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
商周刊(2017年6期)2017-08-22
自动化学报(2017年11期)2017-04-04
山东大学法律评论(2016年0期)2016-08-16
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
