
基于CNN-GRU-CTC的藏族学生普通话发音偏误检测
2023-10-11 06:15梁青青周小燕赵春艳
兰州文理学院学报(自然科学版) 2023年5期
梁青青,周小燕,赵春艳
(兰州文理学院 传媒工程学院,甘肃 兰州 730000)
普通话作为中国这一多民族国家的通用语言,在推广文化教育、提升全民族素质、繁荣社会经济、促进各民族、各地区之间的交流发挥着非常重要的作用[1].作为藏族学生,他们不仅要精通藏语,还要掌握普通话,这不仅可以提高藏族学生的语言表达能力,还有利于他们适应新时代复杂多变的社会结构.由于大部分藏族学生从小就用藏语交流,加上汉字储备量不够,导致藏族学生在学习普通话时存在不会发音、发音不准确、自信心不足等问题[2]近年来,计算机辅助语音训练系统 (Computer Assisted Pronunciation Training System,CAPT )因可以帮助学习者及时发现和纠正错误发音,避免重复错误发音形成习惯[3],提高学习者的学习效率而受到学者的关注.
计算机辅助语音训练系统的关键技术之一是精确的语音识别技术.卷积神经网络(CNN)不仅可以显著提高语音识别的准确度,而且已经成功应用于CAPT中.IBM、微软、百度等多家机构相继推出了自己的CNN模型,在英文领域识别准确率达到95%,科大讯飞语音研究院王海坤等[4]提出了深度全序列卷积神经网络的语音识别框架,并为汉母语人群开发了普通话在线训练系统.
基于上述研究,本文针对以藏语为母语的学习者发音偏误问题进行研究,提出基于CNN-GRU-CTC的端到端的发音偏误检测方法[5],设计并录制了藏族学生的普通话发音偏误语料库.该语料库覆盖了所有音节,设计了64种偏误类型,录制了7 200句语音语料进行测试,通过实验精确找出具体的发音偏误,并给出反馈,为他们提供面向计算机辅助发音训练系统的技术.
1 语料库设计
1.1 汉语发音特点
汉语属于汉藏语系,现代汉语是语素-音节文字.从记录的语音单位来看,一个汉字和一个音节是相对应的.一个汉字的读音就是一个带调音节.除了零声母外,音节由声母和韵母构成,而韵母又包括韵头、韵腹和韵尾.一个音节可以没有辅音声母,也可以没有韵头和韵尾,但都有声调和韵腹.构成音节的汉语拼音有23个声母,24个韵母,阴平、阳平、上声和去声4个声调.
1.2 藏语特点
藏语是由字母组合形成的拼音文字,每个字母都有自己的发音.字母的组合是由音与音之间的拼合而组成的.藏语有30个辅音字母和4个元音字母,即所有藏文字都是由这34个字母组成的.
1.3 文本语料设计
发音偏误检测需要对藏语发音者与汉语普通话发音偏误情况进行分析,文本语料库应具备以下条件:①文本语料库应覆盖汉语普通话中所有由声母、韵母和声调组合而成的音节;②藏语在发音时浊辅音和辅音韵尾趋于简化,在构建文本语料库时需要对这两种情况做到全覆盖;③需要考虑声调发生变化的情况,例如:由2个三声的字组成词时,第1个字通常需变为二声;一些词语及句子中存在声调变成轻声的情况.
1.4 语音语料的录制
(1)录音者应该尽量选择普通话发音不是很好的且藏语为母语的学生,他们平时说普通话较少,发音更容易出错,对发音偏误检测更具有代表性;
(2)录音者在说普通话时应存在一定的口音,这样对偏误检测覆盖更广泛;
(3)录音环境选择无背景噪声的专用录音棚,录音设备选择专用麦克风,通过电脑软件提示声音的频率和音量大小,保证声音大小前后一致,增加对检测的准确度;
(4)音频语料的采样率设置为44.1 kHz,采样大小为16位.
按照以上要求,本文设计了1 200句以藏语为母语的学生学习普通话的文本语料,并以此建立藏族学生学习普通话的偏误语音语料库.语料库由6名(3男3女)藏族的大一学生参与录制.
2 模型建立
采用基于语音识别的框架,分别考察发音音素偏误和发音声调偏误.
2.1 发音偏误整体检测流程
文中使用基于自动语音识别(Automatic Speech Recognition,ASR)框架来进行发音偏误检测[6],具体检测的流程如图1所示.系统首先输入要检测的语句,将学习者的语音通过ASR检测器来进行检测识别,同时通过发音字典得到声学模型的建模单元和语言模型建模单元间的映射关系,以及对应的标准化转录[7];然后,系统根据识录是否一致来判断发音的正确性;最后,根据二者不同向发音者反馈纠正方法.

图1 发音偏误检测流程
2.2 发音偏误CNN-GRU-CTC模型的建立
卷积神经网络(CNN)由输入层、隐含层和输出层组成,隐含层包括CNNV卷积层、ReLU激活层、Pool池化层、FC全连接层,具有学习能力[8].本文利用深度全序列卷积神经网络进行建模.它将一句语音转换为一张图像作为输入,避免语音信号进行傅里叶变换后使用滤波器来提取特征导致频谱上信息的丢失.该模型由5部分组成,具体结构如图2所示.
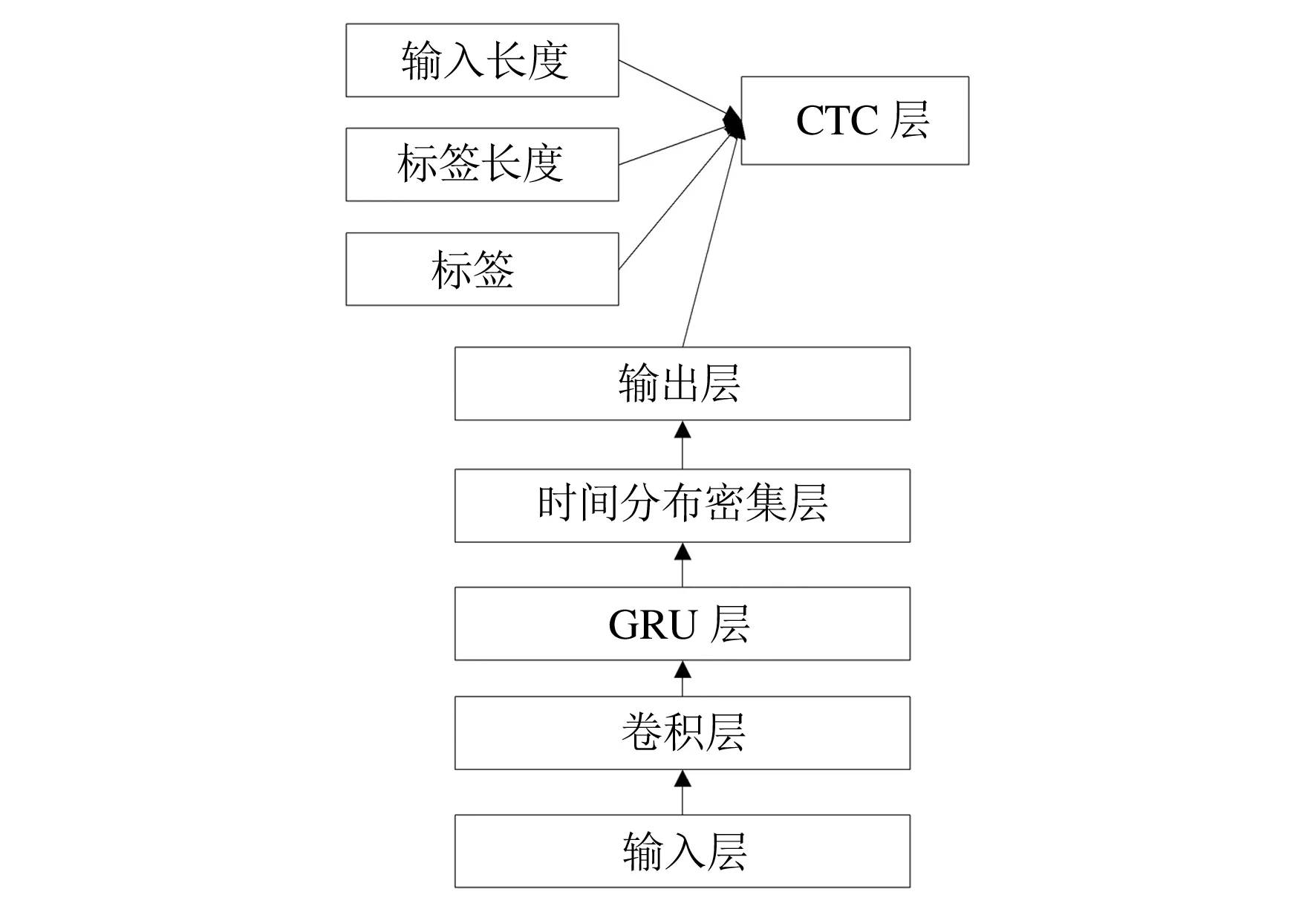
图2 CNN- GRU-CTC结构
第1部分为输入层,输入完整包含原始频谱信号的二维语谱图.由于使用梯度下降算法进行学习,该数据不能直接放进卷积神经网络进行训练,因此,需要对其进行标准化处理.为了使批处理中的所有语句长度相同,需要对输入数据进行零填充;第2部分是卷积,主要对输入数据进行特征提取,这一部分包含了6个CNN层,2个最大池化MaxPool层,然后是对其进行归一化处理.这部分通过对输入层的数据进行提取和处理,得到详细的声学特征参数;第3部分是GRU层,它可以更好地捕捉深层连接,并改善梯度消失问题,用来获得更详细的时间声学特征;第4部分是时间分布密集层(MLP)层[9],该层输出值被传递到Softmax逻辑回归进行分类输出;最后一部分是CTC输出层,用来生成预测音素序列.
3 实验及结果分析
3.1 模型训练
该模型将标准发音库作为训练集,将偏误发音库作为测试集,语谱图作为整个模型的输入特征参数[10].首先对语音信号进行加窗、分帧和提取语谱图.本实验使用的窗函数为汉明窗,以20 ms为一帧,帧移为10 ms.卷积层是由3个卷积-卷积-池化对组成,卷积层参数包括卷积核大小、步长和填充,6个卷积层的卷积核大小设置为3×3,步长为2×2.MaxPool最大池化层左右是特征融合和降维,每个池化层的池化窗口大小设置为2×2.训练过程中学习率 (Learning Rate)设置为0.008,批次大小(Batch Size)设置为16,数据轮次(Epoch)设置为300次,采用 Tensorflow和Keras工具包来实现模型训练.
3.2 评价指标
实验的结果共有4种:①正确接受(True Acceptance,TA).一个待测试正确发音样本,经过算法对比被检测为正确发音;②错误拒绝(False Acceptance,FA).一个待测试正确发音样本,经过算法对比被检测为错误发音;③错误接受(False Acceptance,FR).一个待测试错误发音样本,经过算法对比被检测为正确发音;④正确拒绝(True Rejection,TR).一个待测试错误发音样本,经过算法对比被检测为错误发音.
根据这4种检测结果对系统的性能通过错误接受率(False Acceptance Rate,FAR)、错误拒绝率(False Rejection Rate,FRR)、检测准确率(Detection Accuracy Rate,DAR)来衡量.FAR(式1)表示发音者的错误发音被系统认为正确的百分比,FFR(式2)表示发音者的正确发音被系统认为错误的百分比,DAR(式3)表示系统的检测结果与发音者的发音结果一致的百分比,这3个评计算公式为:
(1)
(2)
(3)
3.3 实验结果
在上述3个评价指标中,在保证较高正确率的前提下,降低另外两类错误率.实验结果表明,在该模型下,系统检测准确率为88.55%,错误拒绝率为7.16%,联合错误率为14.94%,与文献[11-13]相比各个指标都取得了较好效果,不同模型实验结果如表1所列.同时本文的数据不需要手工标注和强制对齐数据,该模型可以检测声母、韵母和声调偏误,检测范围更广.
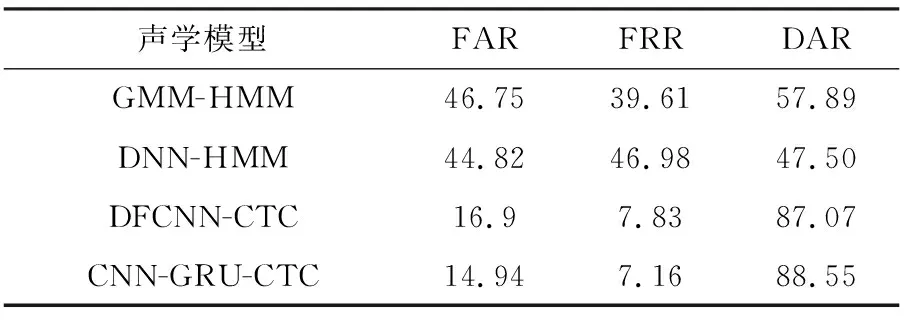
表1 不同模型实验结果
为了分析具体的发音偏误情况,本文将发音偏误分为声母偏误、韵母偏误和声调偏误3种类型,并对其做了统计,对比情况如图3所示.
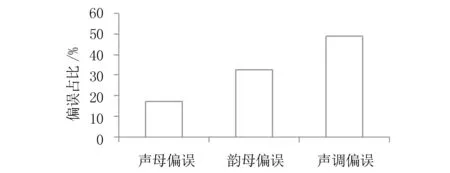
图3 3类偏误占比对比
从图3可知,藏族学生在学习普通话时声调的偏误最多,其次是韵母,声母相对比较容易掌握.虽然汉语和藏语都属于同一个语系,但是这两者的声调系统差异较大,在学习中需要加强.
由于声调的偏误较多,本文在阴平、阳平、上声、去声和轻声中分析了每种声调的偏误情况,结果如图4所示.
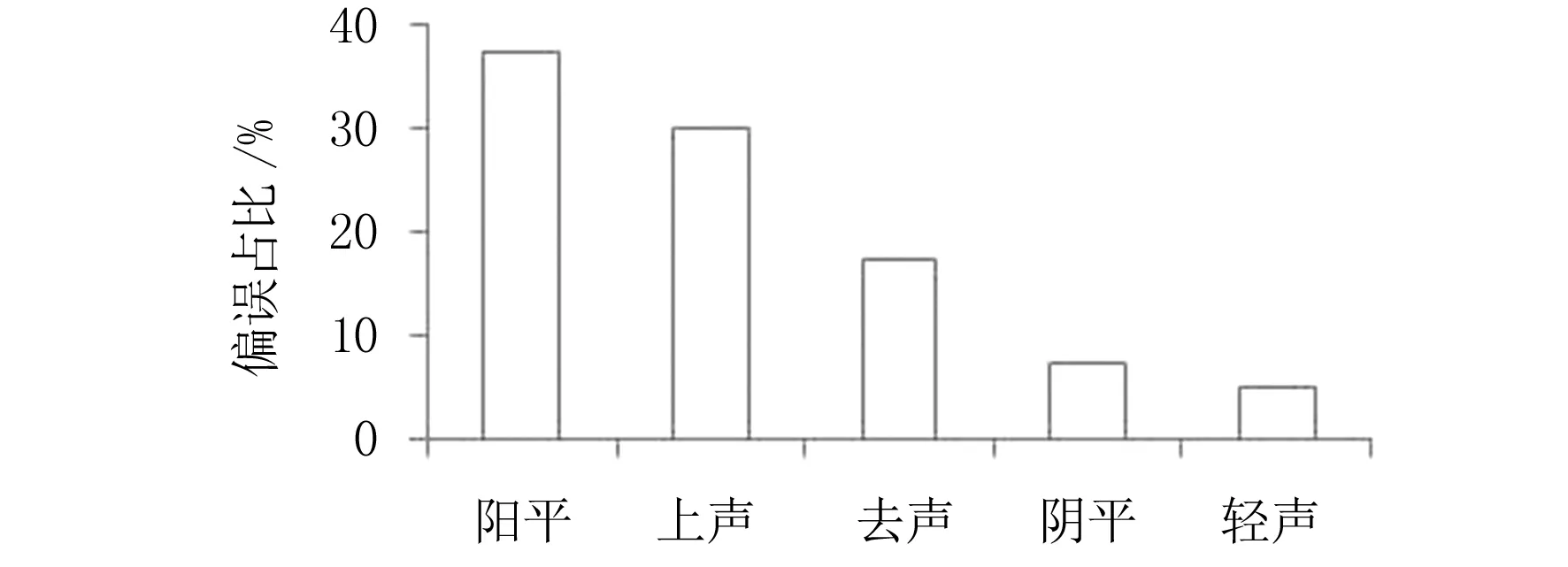
图4 5种声调发音偏误检测结果
从图4可知,藏族学生在学习普通话时,对阴平、上声和去声的区分程度较差,在学习的过程中需要对这3种声调进行加强.阴平和轻声相对比较容易感知,学习起来比较容易.
实验中藏族学生对普通话的21种声母感知检测如图5所示.实验结果表明,藏族学生在普通话发音中,存在n与l、g与k、h与f分不清楚的情况,舌根前音z、c、s 和舌根后音zh、ch、sh也容易被混淆,这些声母在学习中本就是难点,因此这几种情况需要特别加强练习.

图5 21种声母发音偏误检测结果
38种韵母发音偏误统计结果如图6所示,本实验重点研究前10种偏误情况,这10种韵母发音偏误的统计结果如图7所示.结果显示,错误频率最高的为“Ng”,也就是日常的“嗯”字,该音容易被发音为“en”.另外发音偏误主要集中在韵尾为“ng”的情况,也就是普通话中的后鼻音,多数情况下这种音节容易被发音为前鼻音,以上结果需要在学习时加强关注.

图6 38种声母发音偏误检测结果

图7 10种高频韵母发音偏误检测结果
4 结论
本文设计并录制了藏族学生学习普通话的发音偏误语料库,建立了基于CNN-GRU-CTC模型的发音偏误检测系统.实验结果表明该方法可以有效提供发音偏误信息,为藏族学生学习普通话提供帮助.今后我们会选择更多来自不同方言区的人加入语料录制,继续完善语料库建设,将其它深度学习方法应用到发音偏误检测上提高检测精度.
猜你喜欢
今日农业(2022年16期)2022-11-09
作文周刊·小学一年级版(2022年28期)2022-05-30
小天使·一年级语数英综合(2020年9期)2020-12-16
汉字汉语研究(2020年2期)2020-08-13
作文周刊·小学一年级版(2020年28期)2020-08-06
小天使·一年级语数英综合(2019年10期)2019-11-10
小学生学习指导(低年级)(2019年9期)2019-09-25
作文周刊·小学一年级版(2019年28期)2019-09-07
海外华文教育(2017年8期)2017-11-07
海外华文教育(2016年4期)2017-01-20
